基于模糊粗糙集的公共文化服務效能評估方法
2022-12-11 13:33:12高全力邵連合
計算機技術與發(fā)展 2022年12期
郭 帥,高全力,邵連合
(西安工程大學 計算機科學學院,陜西 西安 710048)
0 引 言
構建現代公共文化服務體系是近年來國家公共文化發(fā)展的重要戰(zhàn)略內容,與民生、文化的發(fā)展息息相關[1]。對公共文化機構的服務效能進行評估是提高各級場館服務能力、改善場館效益的有效手段。如何對不同級別、不同領域的文化機構進行客觀合理的評估對提高公共文化服務質量有著重要的意義[2]。公共文化領域的服務效能評估研究已有十余年之久,評估多以場館基礎建設為主要內容,對評估場館服務供給能力的研究較少。服務效能與社會環(huán)境、文化發(fā)展密切相關,受時間、地理、人群等多個維度的影響,波動較大,常規(guī)的績效模型難以準確評估,并且缺少統一的公共文化服務效能的指標體系和評估標準[3-4]。因此,構建統一的指標體系、簡化評估過程、提高評估準確度是當前亟待解決的問題之一。構建面向公共文化機構的服務效能評估模型,對服務效益給出準確評估,對文化機構優(yōu)化服務效益,保障服務質量有著重要意義。
目前針對公共文化服務效能的評估多從投入產出的角度進行分析,基于數據的相對權重對機構服務效益進行評價。具有代表性的評估方法包括,曹國鳳等[5]使用六何分析法對公共數字文化服務效能的評估動因、評估主體、評估客體、評估指標、評估過程及評估優(yōu)化策略進行分析,驗證了服務效能評估是考核公共數字文化服務成效的重要手段。寇垠等[6]從多個方面對公共文化服務效能評價體系的研究進行歸納,以用戶滿意度為核心優(yōu)化績效評估體系。周靜等[7]以數據報道和館情評析為核心,對公共文化服務效能的評估進行了研究。得出全國公共圖書館評估逐漸轉變?yōu)橐孕転閷虻慕Y論,為評估提供了研究方向。司光亞等[8]針對效能評估體系中指標之間存在影響以及評估過程主觀性較強的問題,提出基于仿真大數據的構建指標體系的方法,為效能評估指標構建提供了理論依據。朱美霖等[9]從投入產出的視角構建了公共圖書館的服務效能評估指標體系,基于因子分析法對評估模型的關鍵指標進行提取,與第六次全國公共圖書館評估結果進行對比,驗證了模型合理性。朱劍鋒等[10]基于數據包絡分析(Data Envelopment Analysis,DEA)理論,構建了公共文化服務績效評價框架,選用C2R模型和超效率模型對公共文化服務的特點進行分析,在相關數據集上對分項和綜合績效評價進行了研究。Wang Wenling等[11]基于DEA超效率松弛度量模型分析了影響公共文化服務效能的主要因素,根據分析結果提出了政策方面的建議。
由于各地區(qū)經濟、文化發(fā)展的多樣性,公共文化機構發(fā)展傾向有所不同,目前常用的評估方法主要以統一的指標體系加以權重調整得到評估分數,缺乏對場館自身發(fā)展特色的考量。而專家經驗判斷主觀性較強,且難以保證評估時效性。因此,該文提出基于模糊粗糙集和多輸入神經網絡的評估模型,通過模糊粗糙集對不同地區(qū)的場館評估指標進行約簡,保證指標數據代表性的同時消除冗余信息,使用CRITIC賦權法計算機構采集數據的客觀權重,結合多位專家針對當地公共文化發(fā)展特點所賦予的指標權重輸入神經網絡,訓練得到機構服務效能評估模型。模糊粗糙集的約簡較好地解決了網絡訓練中收斂速度的問題,多輸入網絡能夠保證有效融合專家經驗和客觀權重數據,得到更加準確的評估結果。
1 基礎理論
1.1 SFRS模型
相似模糊粗糙集(Similar Fuzzy Rough Set,SFRS)是一種對模糊數據和不確定性對象進行分類的理論,利用對象屬性數據之間的相似度進行分類,是一種用來表示等價關系的特殊形式化語言。一個知識表達系統可以被看作一個關系數據表。
設存在非空有限對象集合U={x1,x2,…,xn}和非空有限屬性集合C={c1,c2,…,cn},集合U和C構成一個二元決策空間,在該空間中,存在矩陣V,表示所有屬性值,Vc為列向量,表示屬性c的所有取值,即屬性c的值域,對象i在屬性j下的屬性值為Vij(i=1,2,…,n;j=1,2,…,m)。上述關系用信息函數表示為f:U×C→V,即對于每個x∈U,c∈C,都有f(x,c)=Vc。
定義1:?x,y∈U,?cj∈C,j=1,2,…,m,對象間的模糊關系R如下:
(1)
其中,α表示對象x和y之間的相似性,若大于α則表示對象相似。
定義2:?xs,xt∈U,?cj∈C,j=1,2,…,m,在模糊關系R下,xs與xt之間的隸屬函數值為:
(2)
根據定義1和定義2,可證明兩個對象之間存在如下性質:
①自反性:
Rxx=1
②對稱性:
Rxy=Ryx
故R為模糊相似關系。
定義3:所有與xi模糊相似的對象構成的集合稱為xi的模糊相似類,表示為F:

j=1,2,…,m}
(3)
其中,γ表示模糊相似性,為[0,1]區(qū)間內的取值,越靠近1則對象間的相似性越強。
粗糙集模型的屬性約簡依賴于下近似關系,即模糊相似類的集合包含關系,經典粗糙集模型認為分類必須完全相同時屬性才可進行約簡,導致在實際計算中分類結果極易受到異常數據影響。因此在模糊粗糙集的經典算法上進行推廣,綜合考慮了模糊決策的下近似和上近似,將模糊粗略近似與自我信息的概念相結合,使模糊粗糙集算法適用于屬性約簡[12-14]。同時結合變精度粗糙集理論,認為在分類比例區(qū)間內的近似關系即為正確分類[15]。因此在此基礎上建立集合X的上、下邊界,表示為β和α。通常上下界的關系為0<β<α<1。顯然,α下邊界是包含度相對比較大的等價類之并,而β上邊界是包含度相對比較小的等價類之并。盡管約定0<β<α<1,但事實上,為了達到多數包含的現實需要,往往取α為一個非常接近1且小于1的正數,而β則取一個非常接近0且大于0的正數。
定義4:?X∈U,?R∈C,則?X={x1,x2,…,xn}?U下近似集和上近似集分別為:
(5)
上近似表示最大相似范圍,是知識庫中集合的并集。下近似集表示最小相似范圍,是知識庫中集合的交集,通常用POSU(X)表示,屬性約簡主要是以下近似集作為依據。
定義5:X為屬性集合C產生的模糊相似類集合,X=U/C={X1,X2,…,Xn},設刪除屬性ci后的指標集為Ri?U,以Ri為屬性集計算得到的模糊相似類與F(x)的差異稱為近似分類質量,定義為:
(6)
近似分類質量可以表示指標ci的重要度,若不等于1則表示該屬性不可被約簡。在實際計算中,近似分類質量越小,表示屬性重要性越高,因此可根據近似分類質量值計算約簡屬性集權重。設約簡后屬性集R={c1,c2,…,cn},則屬性權重向量W表示為:
(7)
在對象集合中,所有屬性值的最優(yōu)集合成為理想決策D,理想決策的屬性值dj=V(j=1,2,…,n),對象x與理想決策D的距離被稱作貼近度,貼近度越小,對象方案越理想,其定義為:
(8)
1.2 DNN神經網絡
神經網絡是使用數學模型模擬人腦對數據的處理過程,分為訓練和評估過程,能夠根據數據自主學習,逼近任意的非線性函數。在數據挖掘、模式識別、信號處理等多個領域都得到廣泛應用。DNN神經網絡也稱作深度神經網絡,與BP網絡不同,每個節(jié)點和下一層所有節(jié)點都有運算關系,因此也叫全連接神經網絡,由輸入層、輸出層和隱藏層構成,全連接神經網絡通常有多個隱藏層,增加隱藏層可以更好分離數據的特征。
2 公共文化服務效能評估模型
為更好地評估公共文化機構的服務供給能力,該文提出一種公共文化服務效能評估模型,如圖1所示,由以下四個部分構成。
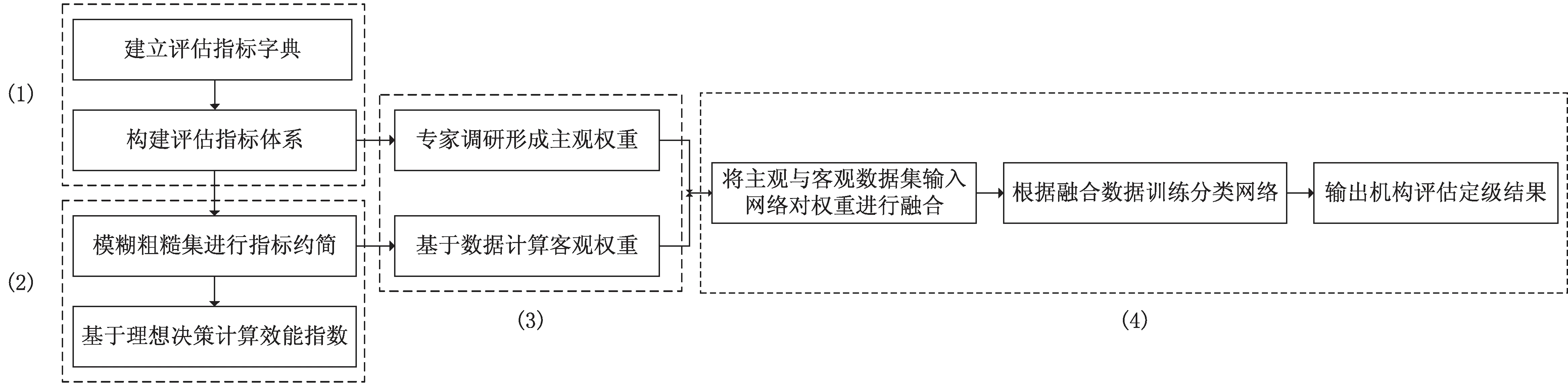
圖1 公共文化效能評估模型評估過程
(1)構建模型評估的指標體系。指標體系直接影響評估的過程與結果,為確保指標的科學性與合理性,指標維度和指標項的確定借鑒了國際圖書館績效評價指標體系、全國第六次縣級以上公共圖書館評估定級標準等權威機構頒布的指標體系,與多家公共文化部門專家咨詢和分析,確定效能評估的主要影響因素。
(2)通過模糊粗糙集理論進行指標約簡,提取主要影響因素,剔除稀疏指標項。指標集的約簡增強了數據的表征能力,簡化模型網絡結構,提高模型泛化能力。同時可根據評估對象與理想決策的貼近度計算出評估對象的排名和相對效能指數。
(3)指標權重的確定受多種因素影響,在評估時主觀性指標強調服務效益與用戶主觀感受,客觀性指標體現建設與發(fā)展能力,主客觀權重的結合能有效提高評估的準確性與合理性。主觀權重由專家參照相關評估標準和地方文化發(fā)展特點確定,客觀權重采用CRITIC法計算得到。
(4)使用多輸入神經網絡構建評估模型的數據融合和結果輸出。神經網絡能夠以較高的精度擬合函數模型和提取數據特征,因此使用兩個輸入網絡分別對使用主客觀權重計算出的評估數據樣本進行融合。然后通過分類網絡對機構的服務供給能力進行定級。
2.1 文化服務效能評估指標框架構建
評估指標體系是評估模型研究的基礎,經典評估方法中為了保證評估的合理性和適應性,通常會構建規(guī)模龐大的指標字典來保證評估結果的綜合性。在實際評估中,由于場館自身發(fā)展受多種因素共同作用,不同場館的基礎建設存在差異,指標數據的可獲得性無法保證,導致最終的采集數據存在數據集稀疏、誤差較大等問題。同時,主觀性指標通常需要專家進行標度,難以適應強調實時性的數字化評估。因此,借鑒《全國第六次縣級以上公共圖書館評估定級標準》、ISO11620績效指標等標準化指標體系,與公共文化領域多位專家共同探討,以數據代表性和可獲得性為前提,構建了適用于數字化評估的公共文化服務效能指標體系(見表1),指標從資源建設、資源使用、效率、發(fā)展和影響力五個維度來評價場館服務效能。

表1 公共文化服務效能評估指標
2.2 基于模糊粗糙集理論的指標約簡
場館的服務效能受社會因素和文化發(fā)展的影響,不同地區(qū)評估指標的傾向存在一定程度上的差異,且部分冗余的指標信息會對評估結果造成影響。因此需要根據不同地區(qū)場館的采集數據對指標集進行約簡,在保證指標評估精度的同時,確保指標體系為最小指標集。在該模型中,參與評估的場館為對象集合U,場館三級指標為屬性集合C,Vij表示場館在某一個指標上的數據,使用全國第六次公共圖書館評估定級作為決策依據。
算法1:基于SFRS模型的指標約簡。
輸入:場館與指標集決策矩陣;
輸出:約簡指標集T。
1.對數據進行z-score標準化處理
2.計算場館的模糊相似類F
3.初始化約簡指標集T=Φ
4.從原始指標集刪除指標C-{ci},得到指標集Ri
5.計算約簡后的場館模糊相似類FRi
6.計算近似分類質量VRi
7.若近似分類質量VRi>下近似集精確度,則該指標不影響分類結果,可被約簡,否則該指標不能被約簡,放入約簡指標集T
8.重復步驟4~7,直到遍歷完所有指標
2.3 CRITIC客觀權重計算
CRITIC客觀權重賦權法是一種基于指標間的對比強度和指標沖突性來描述指標客觀權重的計算方法。該方法在計算時考慮了指標間的數據關聯和數據波動程度,從數據本身的客觀屬性計算權重,較常見的熵權法、標準離差法在實際應用中效果更好。數據的對比強度是指單一指標在不同對象之間的差異性,由于衡量該指標波動的程度,波動越大則相對權重會越高。指標沖突性是指兩個指標之間的相關性,若兩個指標之間相關性較低,表明沖突性較強,相對權重會更高,相關性較強,表明沖突性較弱,相對權重會更低。
2.4 多輸入DNN神經網絡模型
在公共文化效能評估計算過程中,需要綜合考慮專家主觀經驗與指標客觀權重,通常專家經驗與客觀數據對于場館的評估重心并不完全一致,在訓練時所提取的數據特征也存在差異,因此選擇多輸入神經網絡作為權重融合的模型,結構如圖2所示。
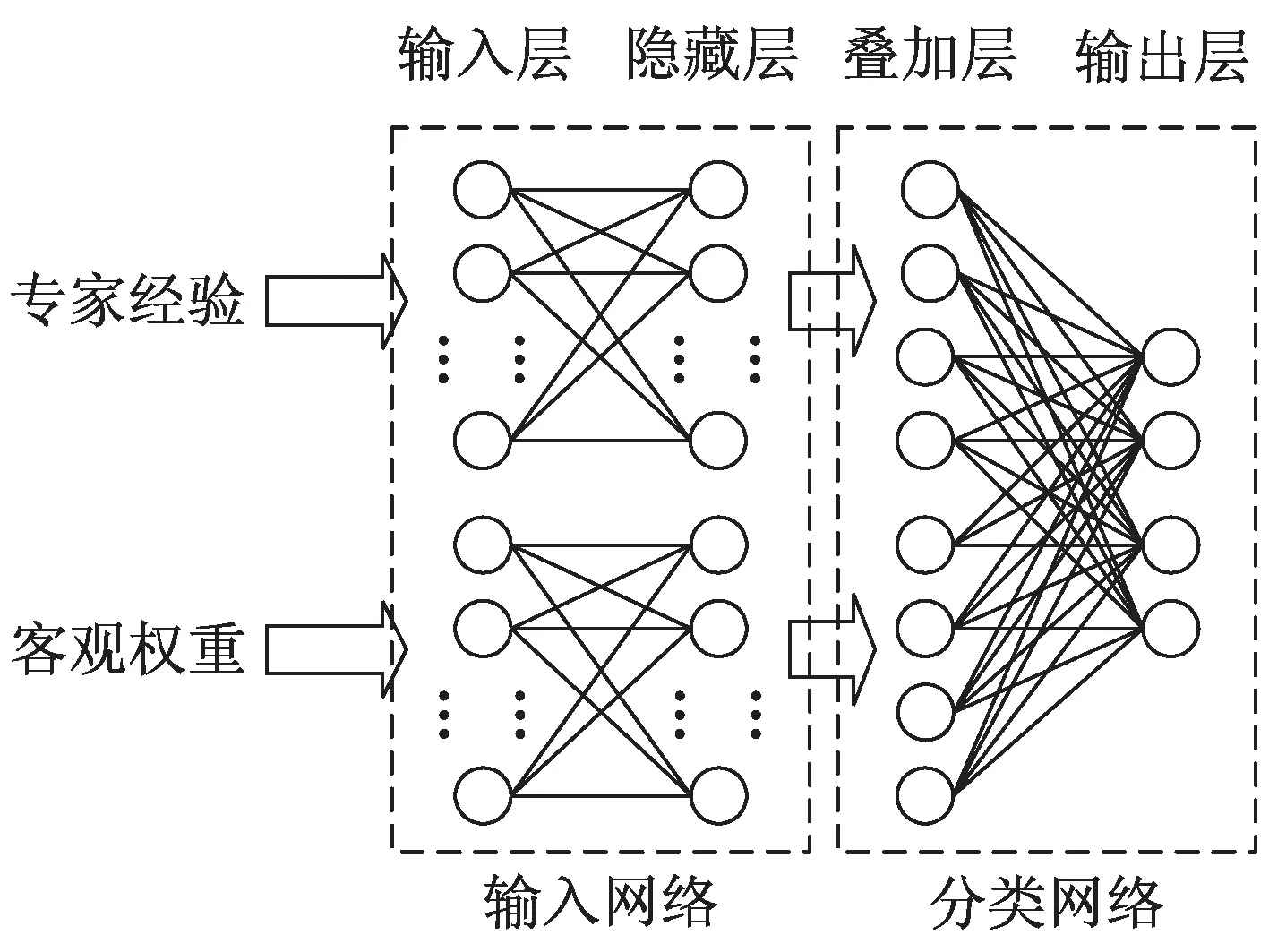
圖2 多輸入神經網絡結構
訓練過程如下:
(1)神經網絡輸入維度取決于指標維度,訓練指標由模糊粗糙集理論對原始指標體系約簡得到,指標約簡能夠降低數據維度,同時保證網絡模型的收斂速度和泛化能力。約簡指標集的數量為兩個網絡的輸入節(jié)點數量。
(2)網絡輸入由兩部分組成,一個輸入接收由專家經驗評估的權重向量,另一個接收由CRITIC客觀賦權法根據場館數據計算得到的指標權重向量。
(3)將計算得到的數據結果分別輸入神經網絡,由于兩部分數據在權重表示上傾向不同,客觀權重更傾向于場館基礎建設和業(yè)務數據,專家經驗傾向于文化傳播和服務數據,因此兩部分網絡的隱藏層和節(jié)點數的選擇并不相同,不同的網絡結構能更好地提取各自部分的數據特征,保證分析模型的綜合判別能力。
(4)兩個輸入網絡的處理結果會在疊加層進行連接,將輸出合并在一起由最后的分類網絡對場館的評估結果進行分類。
(5)分類網絡的結果表明了場館在經過主客觀權重融合計算所評估的等級,模型評估結果與國家公共圖書館定級標準進行對比,誤差大于閾值時,會計算模型損失,調整網絡參數繼續(xù)訓練直到輸出滿足要求。
(6)輸出部分為DNN分類網絡,訓練標簽為4種定級標準的one-hot數據,在訓練中發(fā)現對于分類結果相對獨立的評估模型中,輸出層激活函數和損失函數選擇sigmoid和binary_crossentropy的組合在分類準確度和模型損失結果上優(yōu)于softmax和categorica_crossentropy。
3 仿真實驗
3.1 SFRS模型參數優(yōu)化
選擇《2019中國公共圖書館事業(yè)發(fā)展基礎數據概覽》中陜西地區(qū)111家公共圖書館的統計數據作為公共文化服務效能評估模型數據集,樣本數據涵蓋場館基礎建設、人員構成、特色文化發(fā)展等多個維度共計86項統計指標,滿足模型評估的基本數據需求。由于統計數據單位不統一,且各地區(qū)基礎建設和發(fā)展差異較大,為避免預處理后小數據特征被抹除,因此選擇零均值標準化方法對數據進行標準化處理:
評估模型中模糊粗糙集和分類網絡都涉及數據降維和距離計算,該方法能較好地避免距離計算過程中極端值和異常值對數據整體的影響。模糊粗糙集模型計算時需要預置模糊相似度和分類精度兩個參數,在不同維度數據中,參數的選擇對計算結果有較大影響。為保證獲得較好的約簡效果,通過控制變量,逐一調整參數值獲得最佳計算結果,參數變化對結果的影響如圖3所示。

圖3 模糊粗糙集參數
從圖中可以看出模糊相似度在0.9,下近似精確度為(0.85,1.0]時可以獲得較為穩(wěn)定的約簡結果。使用該參數對原始指標集42個指標進行約簡得到16項三級指標,可表示原始指標集90%以上精度。使用CRITIC法計算客觀權重得到原始輸入數據,如表2所示(保留三位有效數字)。

表2 約簡指標集
根據約簡結果可以看出,不同場館的基礎性建設,如實體和電子館藏建設、場館建筑面積等方面與政策投入存在較強關聯,發(fā)展差別不大;但在個性化服務方面,如特殊群體基本設施建設、公共文化弘揚等方面則呈現差異,這類指標反映了場館在面向公眾服務方面所進行的投入,更能體現出公共文化機構在履行職能方面的能力。
3.2 多輸入神經網絡模型
約簡后的指標集包含16個指標,則神經網絡的兩個輸入層節(jié)點數均為16,輸入網絡對數據進行降維,拼接層將兩個輸入網絡的輸出合并在一起,進行分類訓練,輸出結果為場館的定級。公共文化定級分為4個等級,所以輸出層節(jié)點個數為4。在訓練中發(fā)現,部分等級場館數據樣本較少,訓練中對該類場館特征提取不足,難以準確評估。在數據中增加高斯白噪聲是常見的數據增強方式,一定程度的噪聲數據加入能夠提高分類或預測模型的穩(wěn)定性[16]。因此,為解決樣本數據不足的問題,為原始數據添加信噪比為40的高斯白噪聲對數據進行增強,提高模型泛化能力,同時對原始數據集劃分70%為訓練數據集,20%為校驗數據集,10%為測試數據集。在數據輸入網絡選擇Relu函數為激活函數,分類網絡選擇Sigmoid函數為激活函數。binary_crossentropy作為損失函數,epoch為5 000次。模型分類的訓練準確度和校驗準確度如圖4所示,使用測試數據集對評估模型進行測試,實驗結果使用F1-score進行評價,其中Precision指精準率,表示模型預測的某一類別中,預測正確的比例;Recall指召回率,表示模型對某一類別的樣本數據正確預測的比例;F1-score是對精準率和召回率的加權調和平均,聚焦在較低的值上,能夠更加準確地評價模型的整體性能;Accuracy指模型精確度,表示模型在所有樣本數據中預測結果正確的比例,與其他模型的對比測試結果如表3所示。
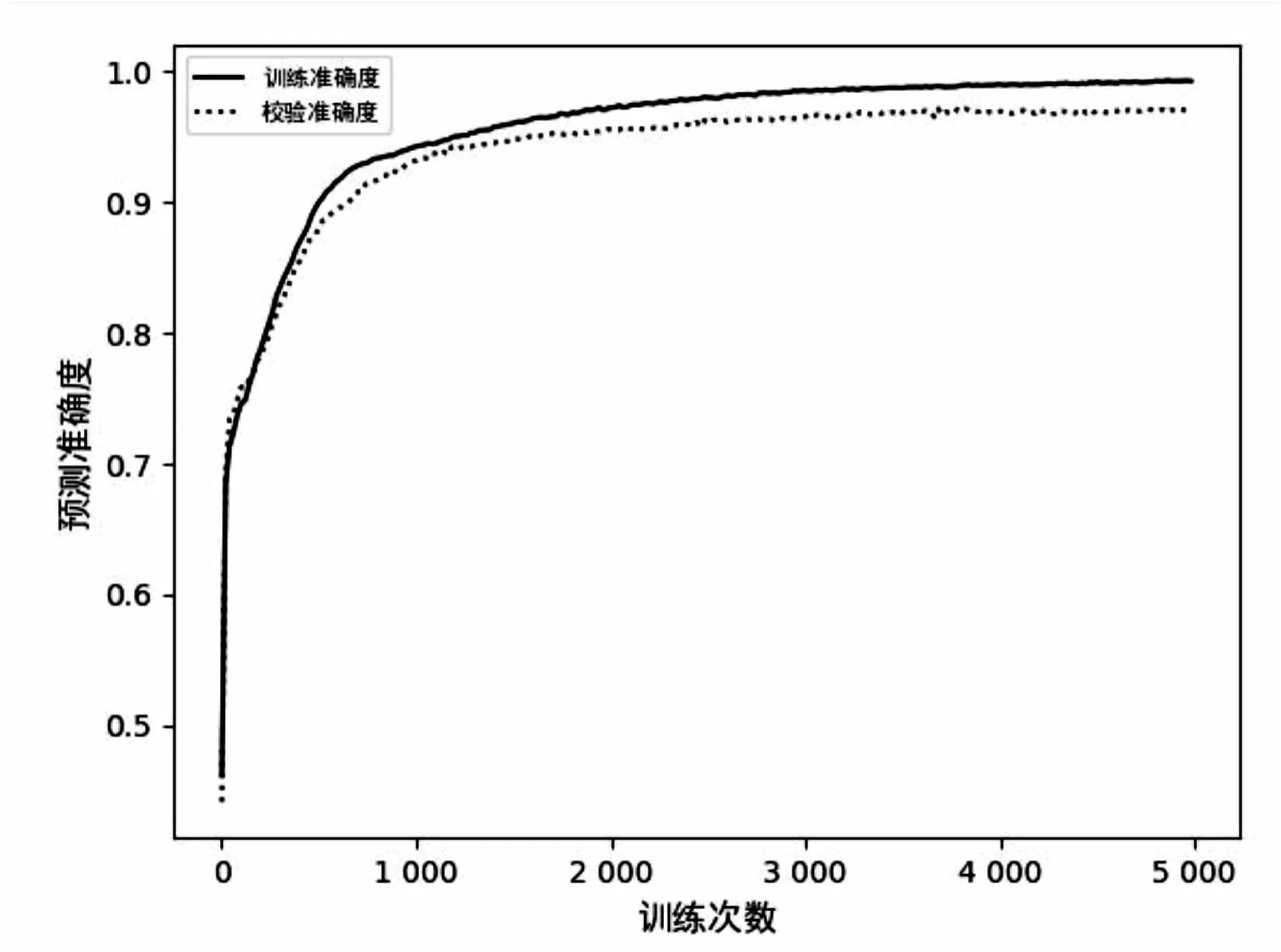
圖4 訓練準確度趨勢
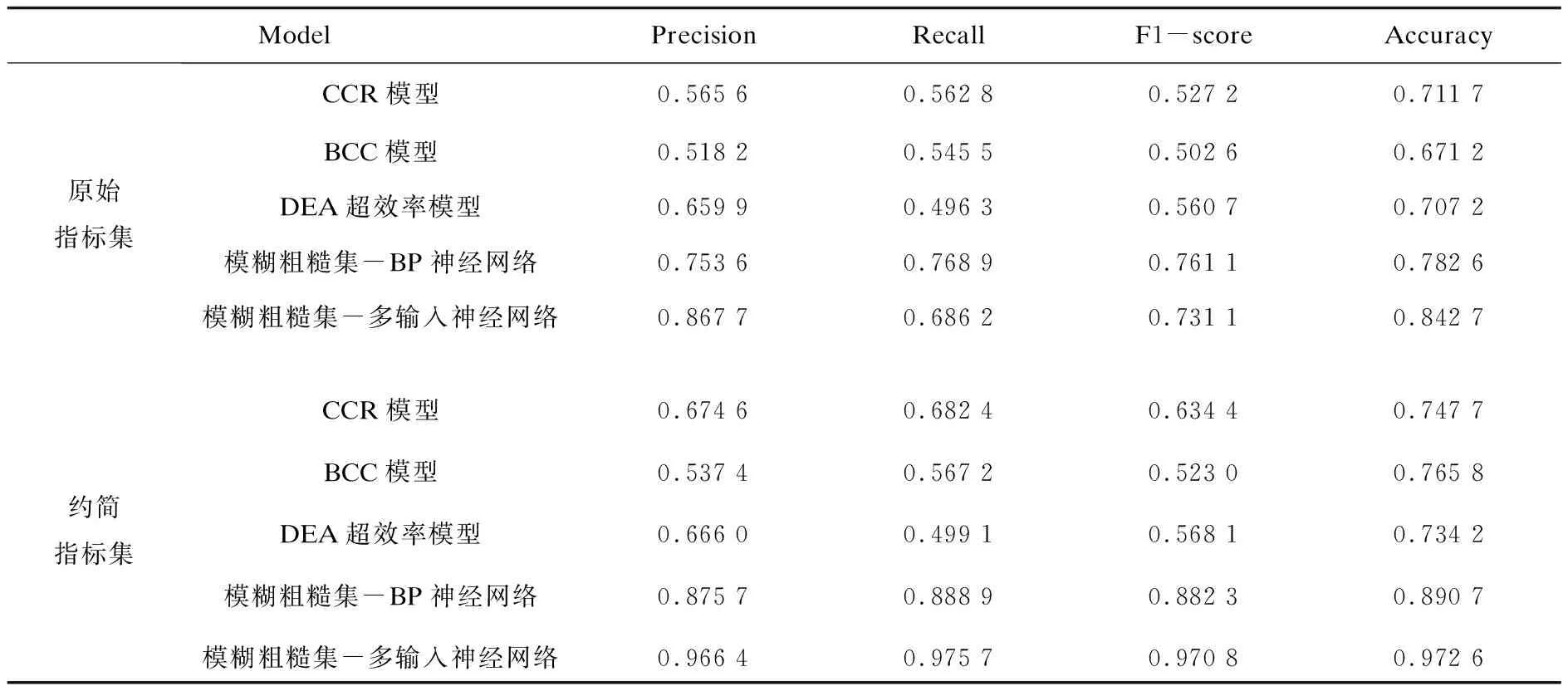
表3 模型評估定級準確度對比實驗結果
從實驗結果中可以看出,經過模糊粗糙集約簡的指標集能夠顯著提高評估準確性。此外,融合神經網絡的評估模型能夠有效結合主客觀權重,使評估定級的結果更加準確。DEA模型使用約簡指標集能夠提高3%~7%的準確度,融合神經網絡的評估模型能夠提高10%~13%的準確度。多輸入神經網絡較BP神經網絡準確度提升了8%。由對比實驗可以得出,指標集約簡和多輸入網絡結構在實驗數據集中能夠有效提高評估模型精度。
4 結束語
在公共文化服務效能評估中,常見的評估指標體系無法對發(fā)展方向各異的場館服務效益進行綜合評估,且指標規(guī)模大導致評估過程繁雜、數據采集困難等問題。該文借鑒全國公共圖書館評估定級標準和ISO11620國際圖書館績效評價指標等標準體系,與公共文化領域相關專業(yè)人員結合各級場館實際發(fā)展水平,共同研討總結了適用于數字化評估的指標體系,能較好地保證在不同等級場館中的數據獲得性問題。
針對實際評估中場館采集數據稀疏、指標信息冗余的問題,通過模糊粗糙集理論基于原始數據集進行指標約簡,消除數據樣本不完全、信息冗余的指標項。由于模糊粗糙集理論存在不確定性參數,通過實驗模擬得到適用于數據樣本的參數值對指標集進行約簡。同時基于指標項的最優(yōu)集計算場館的相對效能指數,為評估決策提供參考依據。
在服務效能評估中,專家經驗得到的主觀數據與采集場館基礎建設所得到客觀數據對場館的服務效能有不同的反饋,為全面的評估場館效益,提出采用多輸入神經網絡模型,使用兩個輸入網絡分別處理主客觀數據,然后合并網絡輸出進行場館定級預測。該方法較傳統評估方法結合了主觀評判與客觀計算,評估維度更高,可應用于公共文化相關效能評估系統中,提供面向場館服務數據的實時評估,具有一定的應用前景。
由于可供研究的數據樣本較少,目前僅使用陜西地區(qū)公共圖書館相關數據進行驗證,應用于其他地區(qū)時模型中的部分參數適用性需要基于數據樣本進行確定,在之后研究中會在其他地區(qū)的數據樣本上繼續(xù)優(yōu)化,提高模型適用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
今日農業(yè)(2019年14期)2019-09-18 01:21:54
今日農業(yè)(2019年12期)2019-08-15 00:56:32
今日農業(yè)(2019年10期)2019-01-04 04:28:15
今日農業(yè)(2019年15期)2019-01-03 12:11:33
今日農業(yè)(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
光學精密工程(2016年6期)2016-11-07 09:07:19
