基于gcFor est算法的惡意URL檢測
2022-12-13 10:56:02濤李思鑒何智帆姚興博
機電信息 2022年23期
劉 濤李思鑒 何智帆 周 宇 姚興博
(1.深圳供電局有限公司,廣東 深圳 518133;2.南瑞集團(國網電力科學研究院),江蘇 南京 210000;3.南京農業大學人工智能學院,江蘇 南京 210095)
0 引言
惡意URL(Malicious URLs)是網絡犯罪的重要途徑,它作為釣魚網站、網絡惡意程序和腳本的載體,為網絡違法犯罪活動提供了可乘之機[1]。這些惡意URL有著和一般URL幾乎一致的特征,一般不易被檢測出,且具有誘導、欺騙的特征,對用戶和企業的隱私、數據和財產等安全問題造成很大威脅。隨著網絡攻擊形式逐漸多樣化,惡意URL變得更加復雜、隱蔽且更具危害性,這就要求網絡安全研究人員研究更加高效的檢測方案以實現對其有效檢測。因此,對惡意URL的高效識別與檢測至關重要[2]。
傳統的惡意URL檢測方法包括黑名單技術[3]、啟發式技術[4-5],隨著新型惡意URL的逐漸復雜化,傳統技術的檢測水平逐漸下降,且具有誤報率高、更新復雜等特點,無法滿足網絡安全的需求。
近年來,機器學習為惡意URL的檢測提供了新的研究方向。其中具有代表性的算法為k近鄰算法(KNN)[6]、Random Forest[7-8],此類算法常被用于一般的惡意URL檢測場景。但是隨著時間的推移以及惡意URL的逐漸復雜化、隱蔽化,這種分類模型往往不能達到預期的分類效果,變得誤判率高且穩定性隨時間下降。而gcForest算法[9]由于其易訓練、可擴展、效率高的優點,在惡意URL檢測領域具有很大的發展空間。
本文對URL的特性展開針對性研究,并對機器學習模型訓練過程中的特征工程技術與分類算法展開實驗,結果表明,gcForest算法訓練出的模型在準確率、精確率、召回率、F1-score等各方面遠優于一般機器學習算法,能實現對惡意URL的高效檢測。
1 總體處理框架
機器學習的一般流程包括數據集獲取、數據集預處理、特征工程、選取算法訓練模型、模型調優與應用等步驟。因此,惡意URL高效檢測的機器學習模型包括以下步驟:
(1)獲取由正常URL和惡意URL組成的數據集,并分析其特征;
(2)對數據進行預處理,劃分訓練集、測試集,去除冗余信息;
(3)開展特征工程,對URL數據集進行分詞、特征提取,并轉化為詞向量形式;
(4)部署gcForest算法,輸入URL數據進行模型訓練;
(5)選取評估指標,通過測試集對模型進行評估,判斷其是否符合標準;
(6)將訓練完的模型導出并應用,實現對新的URL的檢測,判斷其是否為惡意URL。
以上步驟的流程圖如圖1所示。
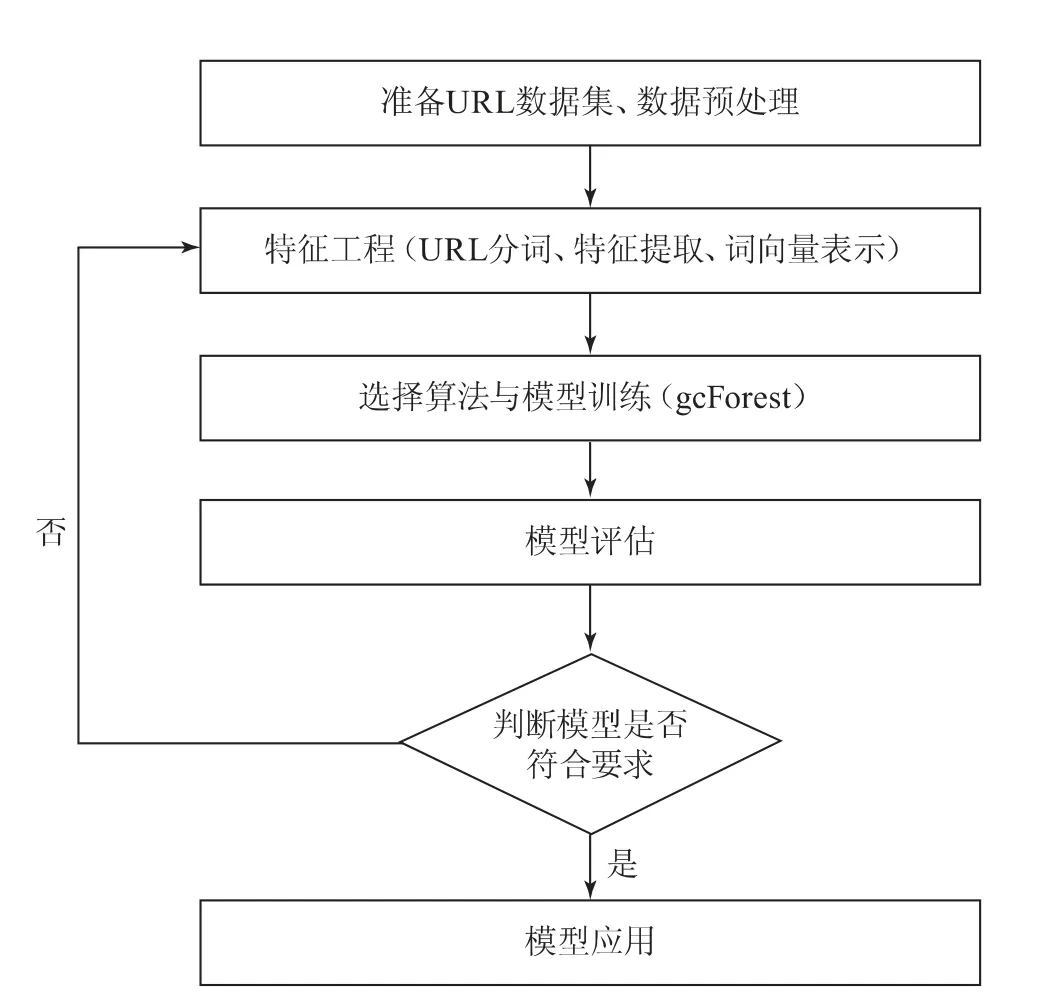
圖1 基于gcForest的惡意URL檢測模型開發流程圖
其中,最為關鍵的部分為特征工程和機器學習算法選取與模型訓練。在特征工程部分,本文對原始的URL數據進行分詞、特征提取、詞向量表示,最終作為機器學習模型訓練的數據輸入。在算法選取與模型訓練部分,本文利用gcForest研究在惡意URL檢測方面的應用,通過準確度、精確率、召回率、F1-score等多項指標對其進行評估,并將其與傳統的k近鄰算法(KNN)和Random Forest算法進行對比。最終,將模型導出并應用于惡意URL的檢測。
2 實驗原理
gcForest[9]即多粒度級聯森林算法,是一種基于決策樹的集成方法,其思想是通過隨機森林的級聯結構進行學習。gcForest的性能較之深度神經網絡有很強的競爭力,將其用于惡意URL檢測模型中,可以達到極佳的性能。本部分將介紹gcForest應用于URL分類問題的原理以及實現方法。
gcForest采用的多層級結構如圖2所示,每層(layer)由4個隨機森林組成,包括2個隨機森林和2個極端隨機森林,每個森林都會對數據進行訓練并輸出結果,這個結果被稱為森林生成的類向量。同時由圖2可知,每層都會輸出2個結果,即每個森林的預測結果與4個森林的預測的平均結果。
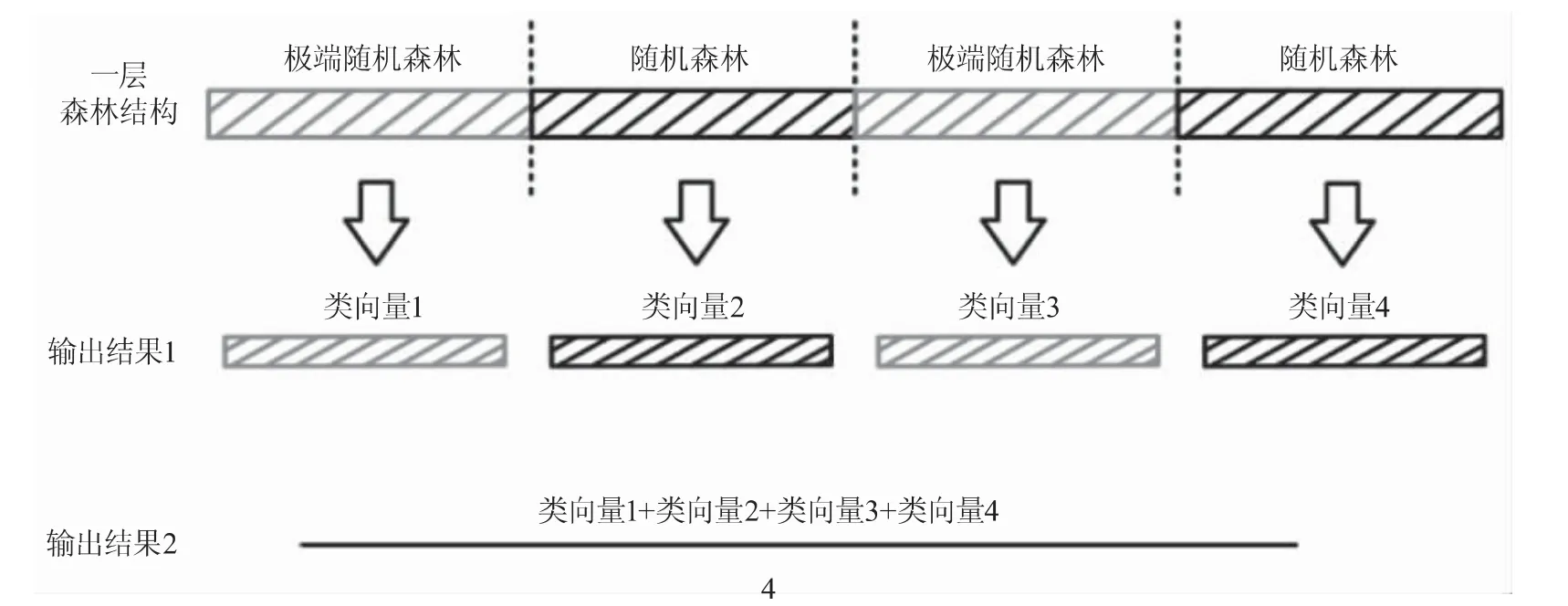
圖2 每層隨機森林結構及輸出結果示意圖
如圖3所示,為防止過擬合,先對輸入給每個森林的訓練數據進行k折交叉驗證。同時,由于每一層結構(layer)都會生成4個類向量,故將上一層的4個類向量以及原有的數據作為新的訓練數據,輸入下一層進行訓練,如此疊加,最后一層將類向量進行平均,作為預測結果。
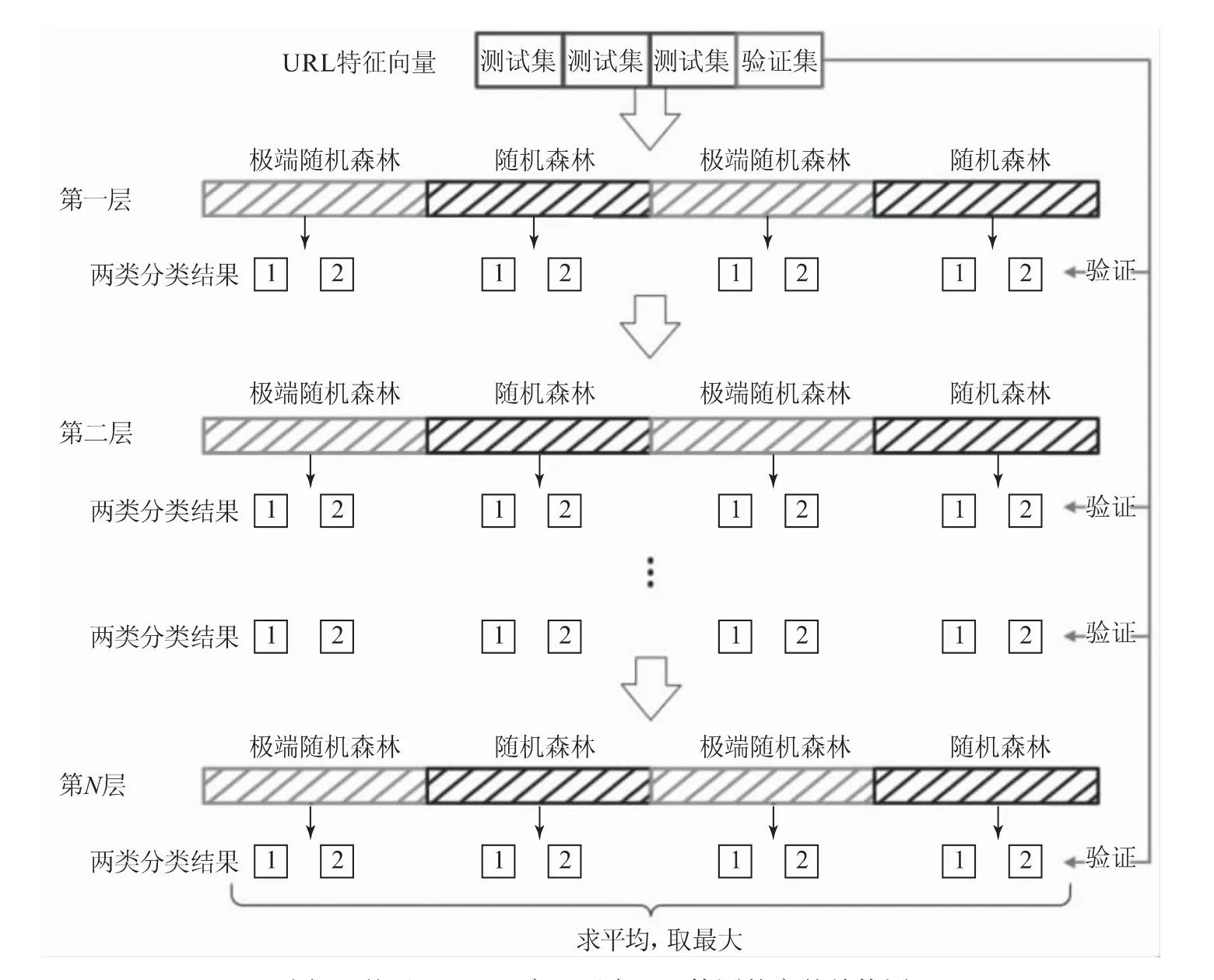
圖3 基于gcForest實現惡意URL檢測的完整結構圖
3 實驗及結果
3.1 環境配置
實驗平臺為Windows 10,64位操作系統,CPU為i5-10200H,2.40 GHz,GPU為NVIDA GeForce GTX 1650,內存為16.0 GB。Python版本為3.9.12,pandas為1.3.4,conda為4.12.0。
3.2 模型評估指標
本文使用準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1-score、maro avg和weighted avg這6種指標來評估模型的分類能力[10]。
準確率(Accuracy)表示分類正確樣本占總樣本的比例,是最直觀的評價指標,其公式為:
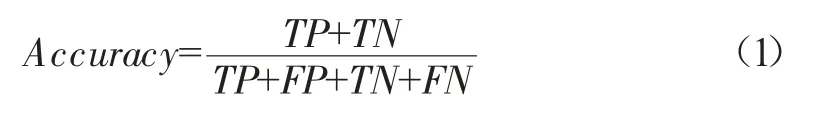
式中:TP表示預測為正樣本且實際為正樣本;FP表示預測為正樣本而實際為負樣本;TN表示預測為負樣本且實際為負樣本;FN表示預測為負樣本而實際為正樣本。
精確率(Precision)表示所有預測結果為正例樣本中真實為正例的比例,其計算公式為:

召回率(Recall)表示在所有真實為正例的樣本中預測結果為正例的比例,其計算公式為:

F1-score是對模型精確率和召回率的加權平均計算,反映了模型的穩健性,結合精確率和召回率計算公式如下:
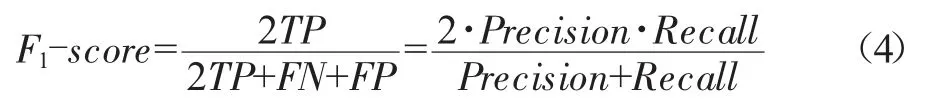
maro avg為宏平均,其計算方式是對某個指標求其所有類別指標值的算術平均,以精確率Pi為例,Pi的maro avg計算公式如下:
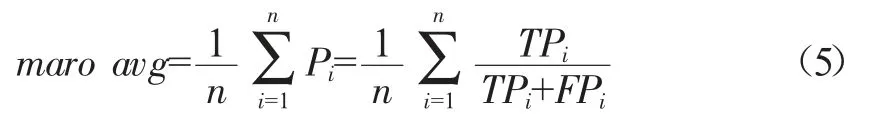
weighted avg為加權平均,其計算方式是對某個指標求其所有類別指標值的加權平均,記Si表示支持第i類的樣本數,以精確率Pi為例,Pi的weighted avg計算公式如下:
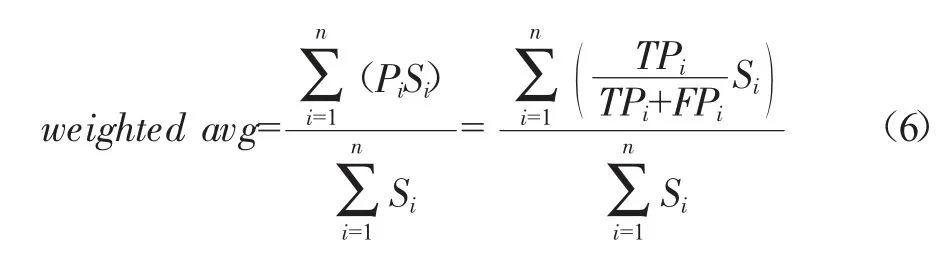
3.3 數據集準備
在數據集的選取上,本實驗中所需的URL數據集來源于kaggle,網址為:https://www.kaggle.com/taruntiwarihp/phishing-site-urls。先對URL數據進行初步篩選,并按照8:2的比例劃分訓練集和測試集,得到數據集情況如表1所示。
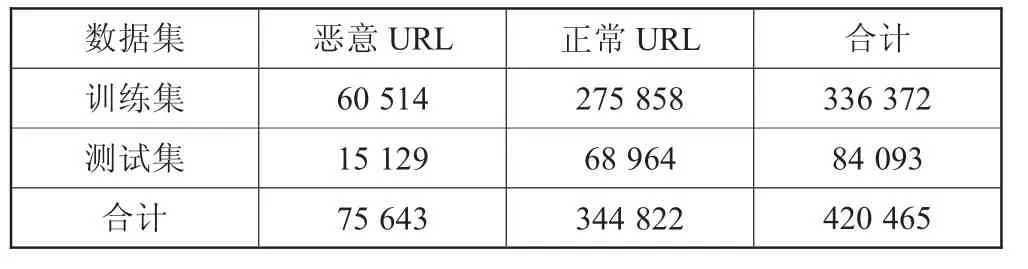
表1 URL數據集
3.4 特征工程
由 于URL中 的 協 議 部 分 中 如“http”“https”和“www.”等字段對URL分類基本無影響[6],因此,在對URL分詞前可先將這些部分去除掉,以提高分類效率。去除協議部分后的部分URL如表2所示。

表2 去除協議部分后的URL舉例
其次,由于URL是緊密連接的字符與符號,因此要對其進行分詞,以此為基礎才能實現對URL的詞向量表示。如表3所示,經過對比測試常用的分詞工具發現,基于正則表達式Re工具可以實現對URL的最準確分詞,其效果遠優于Jieba或Nltk等分詞工具。

表3 分詞結果對比
最后,本文借助sklearn中的TfidfVectorizer工具,完成對URL的文本特征提取和詞向量表示工作,以作為機器學習分類算法的數據輸入。
3.5 檢測結果
將上述預處理數據作為初始訓練數據輸入gcForest,進行模型訓練即可得到分類模型。使用gcForest模型得到的訓練結果評估如表4所示。
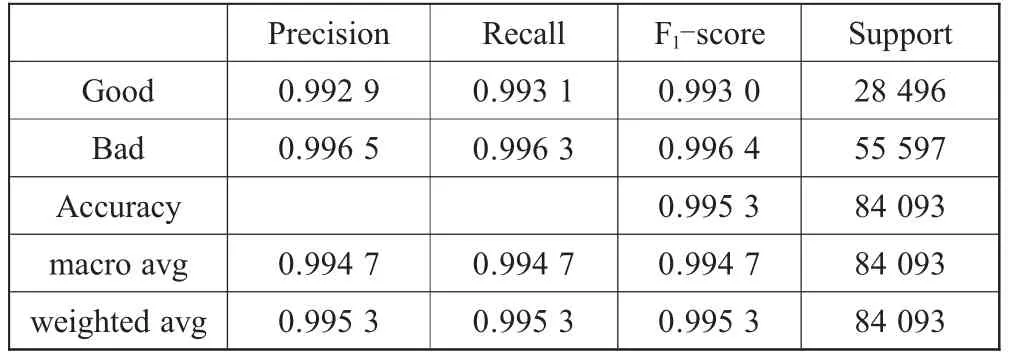
表4 基于gcForest的惡意URL檢測訓練結果評估
由表4可知,該模型的分類準確率(Accuracy)達到了99.53%,在保留兩位小數的情況下,該模型對惡意URL識別的精確率(Precision)、召回率(Recall)、F1-score均達到0.996以上;而對正常URL識別的精確率(Precision)、召回率(Recall)、F1-score能達到0.992以上。因此,該模型在惡意URL檢測的應用中具有極高的準確度與穩定性,具有很大的應用價值。
此外,本文將基于gcForest算法訓練出的模型與KNN和Random Forest算法模型進行對比,結果如圖4所示。
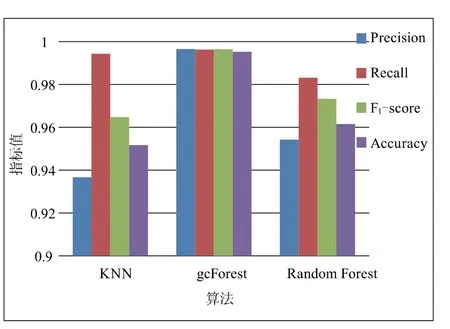
圖4 不同學習算法分類URL結果對比
gcForest在準確率、精確率、召回率、F1-score、macro avg和weighted avg指標下均遠高于傳統的KNN算法,其中準確率提升4.40%,精確率提升3.17%。而對比gcForest底層的Random Forest算法,其在精確率上帶來了3.42%的提升,衡量模型穩定性的F1-score提升了2.31%。由此可以得出,gcForest在惡意URL檢測方面具有遠優于傳統機器學習算法的性能。
4 結論
本文將gcForest算法應用于惡意URL檢測,訓練出能夠準確且高效識別惡意URL的機器學習模型,并從原理出發,系統介紹了基于gcForest算法的惡意URL檢測模型訓練過程。本文的機器學習模型準確率達到99.53%,遠高于傳統的機器學習分類算法,且其精確率、召回率、F1-score、maro avg和weighted avg值均高于0.99,具有很好的檢測效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
