面向PMVS 算法的自動(dòng)兩級(jí)并行翻譯方法
2022-12-13 13:51:34劉金碩黃朔鄧娟
計(jì)算機(jī)工程 2022年12期
關(guān)鍵詞:方法
劉金碩,黃朔,鄧娟
(1.武漢大學(xué)國家網(wǎng)絡(luò)安全學(xué)院 空天信息安全與可信計(jì)算教育部重點(diǎn)實(shí)驗(yàn)室,武漢 430072;2.武漢大學(xué) 計(jì)算機(jī)學(xué)院,武漢 430072)
0 概述
基于面片的三維多視角立體視覺(Patch-based Multiple View Stereo,PMVS)算法將已知內(nèi)外參數(shù)的多幅圖像作為輸入,重建出真實(shí)世界中物體/場(chǎng)景的三維模型。由于該算法原理以及圖像分辨率和規(guī)模的增大,會(huì)導(dǎo)致計(jì)算時(shí)間過長(zhǎng),因此可將其并行化,使輸入圖像分別在CPU 和GPU 上處理來降低計(jì)算時(shí)間。目前,加快計(jì)算速度的并行編程方法主要有MPI[1-3]、OpenCL[4-5]、OpenMP[6-8]、OpenACC[9]和CUDA[10-12]。然而,手動(dòng)或半自動(dòng)翻譯大量串行程序仍是一個(gè)巨大的挑戰(zhàn),一些已有的自動(dòng)翻譯工具的加速效率不理想,并且翻譯效果甚至比人工翻譯的結(jié)果差很多,因此亟須開發(fā)和改進(jìn)從串行程序到并行程序的自動(dòng)翻譯方法[13-15]。
目前,研究人員已提出許多自動(dòng)并行翻譯工具與方法。BASKARAN等[16]提出一種基于Pluto[17]和ClooG[18]的C到CUDA的自動(dòng)轉(zhuǎn)換框架,以生成目標(biāo)CUDA代碼。PPCG[19]是一種基于多面體編譯技術(shù)的源到源編譯器,結(jié)合仿射變換以使用代碼生成器提取數(shù)據(jù)并行性。Bones[20]是一種基于骨架的源到源的自動(dòng)并行化方法,用于將C轉(zhuǎn)換為5種類型的目標(biāo)代碼。此外,還包括Cetus[21-23]、Par4All[24]和ROSE[25-26]等工具。Cetus和ROSE支持CPU粗粒度并行化與OpenMP;Pluto和Par4All支持OpenMP和CUDA。劉松等[27]根據(jù)程序的控制流和數(shù)據(jù)依賴信息將源程序代碼映射成可計(jì)算單元圖,從中提取出可并行執(zhí)行的非規(guī)則代碼段。李雁冰等[28]基于開源編譯器Open64,提出一種面向異構(gòu)眾核處理器的并行編譯框架,將程序自動(dòng)轉(zhuǎn)換為異構(gòu)并行程序。王鵬翔等[29]對(duì)Intel編譯器、Open64編譯器和GCC編譯器3個(gè)典型編譯器自動(dòng)并行化的效果進(jìn)行評(píng)估。丁麗麗等[30]提出一種能夠處理分支嵌套循環(huán)的依賴測(cè)試方法,并通過檢測(cè)距離向量判斷循環(huán)是否存在依賴。高雨辰等[31]對(duì)循環(huán)并行方式進(jìn)行分析。
這些自動(dòng)并行翻譯工具與方法一般遵循解析源代碼、執(zhí)行并行化分析、重構(gòu)適合GPU 并行化的循環(huán)結(jié)構(gòu)和優(yōu)化生成目標(biāo)代碼4 個(gè)步驟。它們多數(shù)僅用GPU來執(zhí)行計(jì)算密集型任務(wù)。然而,盡管GPU 具有出色的加速能力,但CPU 必須等待GPU 完成其計(jì)算任務(wù),這樣就浪費(fèi)了多核CPU 的計(jì)算資源。針對(duì)這些問題,本文提出一種面向PMVS算法的自動(dòng)兩級(jí)并行翻譯方法。基于ANTLR(Another Tool for Language Recognition)[32-33]的分析器自動(dòng)識(shí)別圖像處理算法源C 程序中的可并行化循環(huán)結(jié)構(gòu),映射成多線程CPU 代碼和CUDA 代碼,對(duì)于高分辨率圖像在CPU 和GPU 上進(jìn)行分別處理,以降低圖像處理算法的總計(jì)算時(shí)間。
1 自動(dòng)兩級(jí)并行翻譯方法
1.1 總體結(jié)構(gòu)
本文提出的一種用于PMVS 算法的自動(dòng)兩級(jí)并行翻譯模型如圖1 所示,以源C 程序?yàn)檩斎耄?jīng)過基于ANTLR 的解析、數(shù)據(jù)依賴性分析、循環(huán)數(shù)組私有化和映射階段,把可并行化的程序分別映射到多核CPU 和GPU 架構(gòu)上,最終輸出生成多線程CPU 和GPU 兩級(jí)代碼。
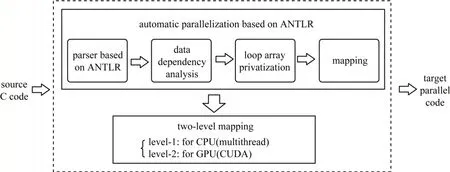
圖1 自動(dòng)兩級(jí)并行翻譯模型Fig.1 Automatic two-level parallel translation model
自動(dòng)兩級(jí)并行翻譯方法的主要步驟如下:
1)通過ANTLR 解析源C 代碼。首先掃描源代碼,然后可以自動(dòng)生成擴(kuò)展Backus-Naur 范式(Extended Backus-Naur Form,EBNF)語法描述,最后根據(jù)EBNF 描述,ANTLR 為抽象語法樹(Abstract Syntax Tree,AST)生成相應(yīng)的詞法分析器。
2)分析數(shù)據(jù)依賴關(guān)系。分析從分析器中提取的循環(huán)信息。如果找到流依賴項(xiàng),則包含這些依賴項(xiàng)的循環(huán)語句是不可并行的。如果發(fā)現(xiàn)數(shù)據(jù)之間的反依賴和輸出依賴,則在第3 步處理循環(huán)結(jié)構(gòu)以消除依賴。如果沒有數(shù)據(jù)依賴,這樣的循環(huán)語句是可并行的。
3)循環(huán)數(shù)組私有化。需要消除變量重用引起的反依賴和輸出依賴。循環(huán)數(shù)組私有化技術(shù)將與循環(huán)迭代相關(guān)的存儲(chǔ)單元本地化,使其與其他循環(huán)迭代的存儲(chǔ)單元的交互分離。
4)映射。首先,將可并行化的循環(huán)結(jié)構(gòu)映射到CUDA 架構(gòu)和CPU 多線程架構(gòu);然后,生成對(duì)應(yīng)的CUDA 代碼和CPU 多線程代碼;最后,多核CPU 創(chuàng)建相應(yīng)數(shù)量的線程,一個(gè)線程負(fù)責(zé)GPU 調(diào)度,其他線程執(zhí)行分配給CPU 的并行任務(wù),同時(shí)GPU 執(zhí)行分配給它的任務(wù)。
1.2 基于ANTLR 的源C 代碼解析
ANTLR 是一種可根據(jù)輸入自動(dòng)生成語法樹并可視化顯示的開源語法分析器,其前身是PCCTS,它為包括Java、C++、C#在內(nèi)的語言提供了一個(gè)通過語法描述來自動(dòng)構(gòu)造自定義語言的識(shí)別器、編譯器和解釋器的框架。ANTLR 使用EBNF 規(guī)則生成源C代碼的語法描述,根據(jù)語法的屬性,對(duì)源程序執(zhí)行詞法分析和句法分析,然后生成AST。ANTLR 提供了一種遍歷AST 的機(jī)制,可以幫助提取循環(huán)相關(guān)信息。使用ANTLR 解析C 源代碼以生成AST 并提取循環(huán)相關(guān)信息的流程如圖2 所示。
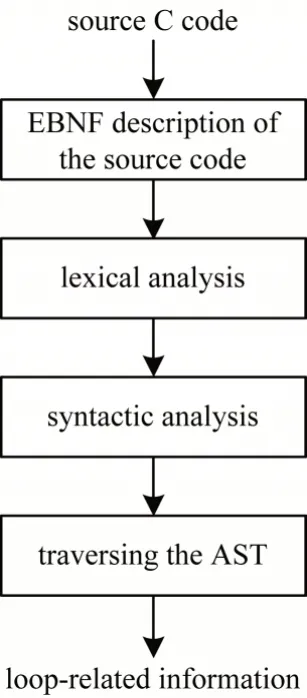
圖2 使用ANTLR 解析C 源代碼的流程Fig.2 Procedure of parsing source C code using ANTLR
首先,利用ANTLR 創(chuàng)建串行源代碼的EBNF 描述。EBNF 描述的語法可以用四元組表示如下:

其中,Vn是非終結(jié)符號(hào)的有限集合;Vt是終結(jié)符號(hào)的有限集合;S是起始符號(hào)語法;P是生產(chǎn)集,也包括規(guī)則集;Z是源代碼。語法中最重要的是P,用“A:a”的形式表示,其中,A 是生產(chǎn)的左側(cè)部分,表示非終端符號(hào),a 是生產(chǎn)的右側(cè)部分,表示終端符號(hào)。ANTLR 中EBNF 使用的語法符號(hào)如表1 所示。

表1 EBNF 語法符號(hào)Table 1 EBNF syntax symbol
然后,執(zhí)行詞法分析,匹配輸入流中的字符,掩蓋或過濾不相關(guān)的內(nèi)容,并生成用于語法分析的標(biāo)記。為了達(dá)到這個(gè)目的,ANTLR 在詞法分析的語法中增加了一系列過濾方法。在源代碼中,空格、制表符、回車符和換行符等字符通常是無意義的冗余字符。ANTLR 提供了skip()方法來跳過這些無意義的符號(hào),例如,在使用WS:(''|' t'|' n'|' r')+{skip();}遍歷這些字符時(shí),將調(diào)用skip()方法以跳過相應(yīng)的字符。在源代碼中的注釋在編譯時(shí)毫無意義,在生成最終文檔時(shí)需要重新使用。ANTLR 提供了一種在編譯時(shí)隱藏注釋的渠道機(jī)制,例如,使用COMMENT:'/*'.*'*/'{$channel=HIDDEN;}可以將匹配的注釋塊放入HIDDEN 通道中,而不會(huì)出現(xiàn)在后續(xù)的語法分析中。
其次,分析上一步語法中的標(biāo)記,ANTLR 在默認(rèn)情況下無上下文規(guī)則,可以添加規(guī)則參數(shù)以實(shí)現(xiàn)上下文信息的傳遞,以彌補(bǔ)上下文無關(guān)文法的不足。例如,使用規(guī)則參數(shù)的代碼片段確定變量分配的類型是否滿足要求:

在變量聲明語法中,定義規(guī)則參數(shù)idList[$type.text],因此在以下語法中,idList 攜帶類型信息。為了提取與循環(huán)相關(guān)的變量信息,將返回值添加到循環(huán)語句聲明的語法表達(dá)式中,以便可以直接從各種循環(huán)聲明中提取與變量相關(guān)的信息。在while 語句聲明中添加返回值int 的示例代碼具體如下:
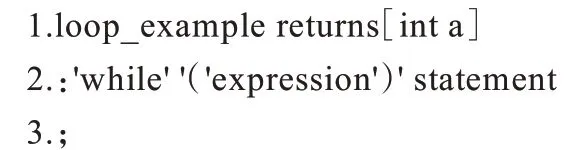
最后,AST 是在語法分析后形成的,以樹的形式存儲(chǔ)句子的數(shù)據(jù)結(jié)構(gòu),樹上的每個(gè)節(jié)點(diǎn)代表源代碼中的結(jié)構(gòu)。串行C 代碼抽象語法樹的遍歷主要用于遍歷循環(huán)結(jié)構(gòu)。本文使用ANTLR 提供的Visitors 方法來遍歷AST,并重載visitForStatement()方法。該方法存儲(chǔ)循環(huán)嵌套級(jí)別和與循環(huán)相關(guān)的變量信息source C 代碼,包括變量名稱、變量類型和存儲(chǔ)循環(huán)位置的行號(hào),并將收集的變量信息移交給下一個(gè)階段進(jìn)行處理。
1.3 數(shù)據(jù)依賴分析
數(shù)據(jù)依賴關(guān)系是指程序中語句的部分順序關(guān)系,反映了維護(hù)程序語義所需的固有順序。影響程序并行性的是對(duì)數(shù)據(jù)的讀寫訪問,因此并行翻譯中需要考慮數(shù)據(jù)依賴關(guān)系。
根據(jù)對(duì)同一內(nèi)存區(qū)域的讀寫操作,數(shù)據(jù)依賴關(guān)系可以由流依賴關(guān)系、反依賴關(guān)系和輸出依賴關(guān)系組成。在循環(huán)結(jié)構(gòu)中:流依賴關(guān)系指的是一個(gè)存儲(chǔ)單元在一次迭代中寫入,然后在后續(xù)迭代中讀取;反依賴關(guān)系指的是在一個(gè)迭代中讀取一個(gè)存儲(chǔ)單元,然后在隨后的迭代中寫入一個(gè)存儲(chǔ)單元;輸出依賴關(guān)系指的是一個(gè)存儲(chǔ)單元是一次迭代寫入,然后在后續(xù)迭代中再次寫入。
假設(shè)在循環(huán)語句F(循環(huán)結(jié)構(gòu))中,I是迭代空間,i(i∈I)是I中一次迭代的循環(huán)控制變量。在迭代i下,RReadi表示所有讀取變量的集合,而表示所有寫入變量的集合。那么F可以并行化的充要條件如式(2)所示:
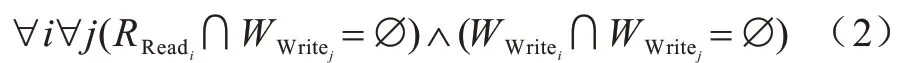
式(2)表示該循環(huán)結(jié)構(gòu)不存在流依賴關(guān)系,并且不存在反依賴關(guān)系或者輸出依賴關(guān)系,其中,i,j∈I并且i≠j。如果F中存在流依賴關(guān)系,則應(yīng)滿足以下條件:

其中:i,j∈I并且i>j。在相同的存儲(chǔ)區(qū)域上進(jìn)行寫入操作,并且需在讀取操作之前執(zhí)行。這個(gè)寫入操作和讀取操作類似于生產(chǎn)者和消費(fèi)者之間的關(guān)系,包含流依賴關(guān)系的循環(huán)結(jié)構(gòu)不能在GPU 上并行執(zhí)行。
如果F中存在反依賴關(guān)系,則應(yīng)滿足以下條件:

其中:k,l∈I并且k<l。對(duì)同一存儲(chǔ)區(qū)的讀取操作發(fā)生在寫入操作之前,這是由于重復(fù)引用同一存儲(chǔ)區(qū)引起的。自動(dòng)并行翻譯可以通過創(chuàng)建一個(gè)臨時(shí)存儲(chǔ)區(qū)來實(shí)現(xiàn)。如果輸出依賴項(xiàng)存在于F(循環(huán)結(jié)構(gòu)F包含輸出依賴關(guān)系)中,則應(yīng)滿足以下條件:

其中:m,n∈I并且m≠n。在同一存儲(chǔ)區(qū)域上的寫入操作至少發(fā)生2 次。對(duì)于反依賴關(guān)系和輸出依賴關(guān)系,都可以通過創(chuàng)建一個(gè)臨時(shí)存儲(chǔ)區(qū)來實(shí)現(xiàn)自動(dòng)并行轉(zhuǎn)換。具體地,以從解析器中提取的與循環(huán)相關(guān)的信息為輸入,然后對(duì)輸入進(jìn)行數(shù)據(jù)依賴關(guān)系分析。通過數(shù)據(jù)依賴關(guān)系分析,如果找到數(shù)據(jù)之間的反依賴關(guān)系或輸出依賴關(guān)系,則將包含這些依賴關(guān)系的循環(huán)結(jié)構(gòu)傳遞到下一個(gè)循環(huán)數(shù)組私有化階段進(jìn)行處理。如果找到流依賴關(guān)系,則會(huì)標(biāo)記諸如無法并行化的循環(huán)結(jié)構(gòu)之類的語句。如果找不到數(shù)據(jù)依賴關(guān)系,則可以直接并行化這種循環(huán)結(jié)構(gòu)。
1.4 循環(huán)數(shù)組私有化
在串行C 代碼中,重復(fù)使用相同的變量會(huì)給自動(dòng)并行轉(zhuǎn)換帶來巨大困難。變量的使用使得存儲(chǔ)地址具有數(shù)據(jù)依賴關(guān)系、反依賴關(guān)系和輸出依賴關(guān)系。循環(huán)數(shù)組私有化可以消除這些依賴關(guān)系。循環(huán)語句中存儲(chǔ)單元的顯式表示形式是變量和數(shù)組。變量也可以看作是數(shù)組的一種特殊表示形式,表示只有一個(gè)元素?cái)?shù)組。在串行C 代碼中,全局?jǐn)?shù)組通常用于存儲(chǔ)數(shù)據(jù),從而減少了存儲(chǔ)空間。全局?jǐn)?shù)組將在循環(huán)語句中的每次迭代中使用。循環(huán)數(shù)組私有化在每次迭代中使用新的存儲(chǔ)空間來私有化原始重用空間,因此不存在交叉迭代依賴項(xiàng)。
除了數(shù)組的初始化之外,循環(huán)語句中數(shù)組重新分配的位置可以分為3 類:1)在當(dāng)前迭代中為數(shù)組分配新值,然后在下一次迭代中使用;2)在循環(huán)外為數(shù)組分配一個(gè)值,并在迭代中重用;3)先分配數(shù)組,再在同一迭代中重復(fù)使用。
第1 類的示例代碼具體如下:
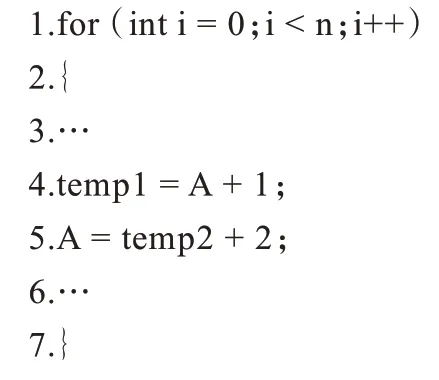
在此循環(huán)語句中:當(dāng)i=0 時(shí),在第5 行為數(shù)組A分配值“temp2+2”;當(dāng)i=1 時(shí),在第4 行的語句“temp1=A+1”中使用數(shù)組A。這是一個(gè)具有流依賴關(guān)系的循環(huán),因此該循環(huán)不能通過循環(huán)數(shù)組私有化來翻譯。
第2 類的示例代碼具體如下:

在此代碼段中,除在循環(huán)第5 行中使用的循環(huán)語句外,為數(shù)組A分配了值“1”。在這種情況下,數(shù)組A可以私有化,對(duì)第2 類的數(shù)組私有化代碼具體如下:

第3 類的示例代碼具體如下:

在此循環(huán)語句中,當(dāng)i=0 時(shí),首先在第4 行中為數(shù)組A賦值“temp2+2”,然后在第5 行的語句“temp1=A+1”中對(duì)其進(jìn)行調(diào)用。在同一迭代中分配并重用該數(shù)組。在這種情況下,可以將數(shù)組A私有化,對(duì)第3 類的數(shù)組私有化代碼具體如下:

循環(huán)語句私有化的第一個(gè)條件是迭代之間不存在流依賴關(guān)系,第二個(gè)條件是在循環(huán)外重新分配數(shù)組,或者在相同迭代中使用之前重新分配的數(shù)組。結(jié)合反依賴關(guān)系和輸出依賴關(guān)系的條件,采用數(shù)組私有化的必要條件如式(6)所示:
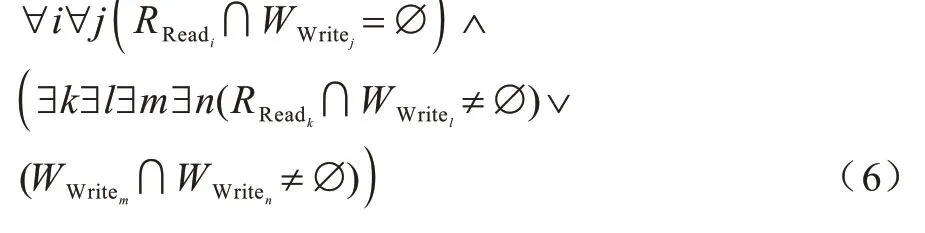
其中:i,j,k,l,m,n∈I并且i>j,l>k,m≠n。式(6)表示不存在流依賴關(guān)系,但是存在反依賴關(guān)系或者輸出依賴關(guān)系。
1.5 兩級(jí)并行映射
為了不浪費(fèi)任何計(jì)算資源,需要獲得目標(biāo)的兩級(jí)并行化代碼CPU 多線程和GPU CUDA,RAHTP將可并行化的循環(huán)結(jié)構(gòu)映射到C 多線程代碼和CUDA 代碼,具體如下:

標(biāo)記為“parallel”的是經(jīng)過解析的可并行代碼塊。“kthread”表示應(yīng)該在CPU 上創(chuàng)建的線程數(shù),“ctasks”和“gtasks”分別表示將在CPU 和GPU 上處理的任務(wù)。如第1 行~第14 行所示,循環(huán)函數(shù)包括可并行化的循環(huán)結(jié)構(gòu),CPU 創(chuàng)建相應(yīng)數(shù)量的線程,其中一個(gè)線程負(fù)責(zé)GPU調(diào)度,而其他線程則執(zhí)行并行任務(wù)。如第15行~第21行所示,CUDA 內(nèi)核處于CPU 線程的調(diào)度之下,并且包含相同的可并行循環(huán)來執(zhí)行。映射的實(shí)現(xiàn)過程具體為:首先,將循環(huán)結(jié)構(gòu)的串行代碼映射為CUDA 并行代碼,創(chuàng)建CUDA 核心kernel 函數(shù),在GPU 上運(yùn)行;其次,在CPU 上創(chuàng)建線程來調(diào)度GPU 和執(zhí)行串行代碼。
在圖像處理算法中,把高分辨率輸入圖像分割成塊。對(duì)于同一個(gè)可并行化循環(huán)語句,一部分圖像塊會(huì)在CPU 上并行處理,而其他塊會(huì)在GPU 上處理,如圖3所示。
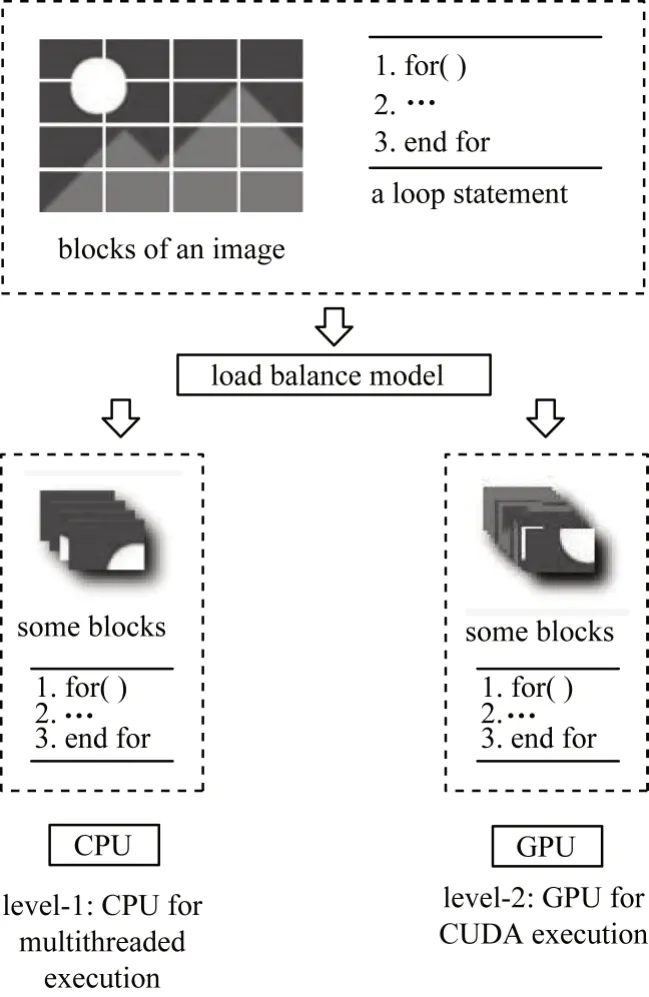
圖3 圖像兩級(jí)并行處理Fig.3 Two-level parallel processing for the images
2 實(shí)驗(yàn)結(jié)果與分析
使用8核Intel i7-9700 CPU 和12GB顯存的Nvidia Tesla p4 GPU,編譯器是NVCC 10.0。實(shí)驗(yàn)主要包括以下3 個(gè)部分:1)將本文方法與其他自動(dòng)并行翻譯方法在Poly-Bench/C4.2.1 的10 個(gè)基準(zhǔn)測(cè)試程序上進(jìn)行有效性驗(yàn)證;2)選擇PMVS 算法進(jìn)行圖像處理,將本文方法與其他自動(dòng)并行翻譯方法進(jìn)行性能比較;3)驗(yàn)證線程數(shù)目對(duì)本文方法的影響。
2.1 基準(zhǔn)實(shí)驗(yàn)
將本文方法與PPCG、OpenACC 這兩種自動(dòng)并行翻譯方法進(jìn)行比較。PolyBench 是俄亥俄州立大學(xué)創(chuàng)建的一組基準(zhǔn)測(cè)試套件,包含30 個(gè)帶有靜態(tài)控制流的數(shù)值計(jì)算,提取自線性代數(shù)計(jì)算、圖像處理、物理模擬、動(dòng)態(tài)編程、統(tǒng)計(jì)信息等應(yīng)用領(lǐng)域。
從PolyBench/C 4.2.1 中選擇10 個(gè)程序作為基準(zhǔn)測(cè)試,其中,correlation、covariance 是數(shù)據(jù)挖掘領(lǐng)域的程序,jacobi-1d、jacobi-2d 是stencils計(jì)算程序,nussinov、floyd-warshall 是動(dòng)態(tài)規(guī)劃程序,atax、bicg、doitgen、mvt 是線性代數(shù)核函數(shù)程序。這些測(cè)試程序包含可并行化的循環(huán)結(jié)構(gòu),具有良好的數(shù)據(jù)重用性,適合作為自動(dòng)并行翻譯方法的測(cè)試基準(zhǔn)。輸入數(shù)據(jù)集為L(zhǎng)ARGE_DATASET。每個(gè)算法設(shè)置的任務(wù)數(shù)量為1 000。測(cè)試程序信息如表2 所示。每種自動(dòng)并行翻譯方法對(duì)每種算法的執(zhí)行時(shí)間與加速比如圖4所示。
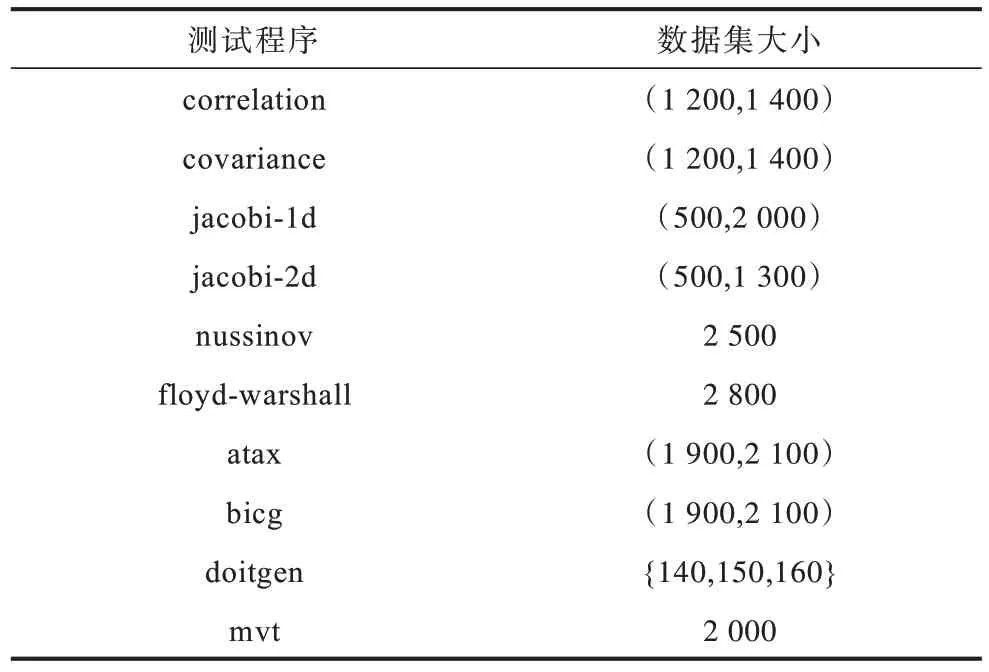
表2 測(cè)試程序信息Table 2 Test program information
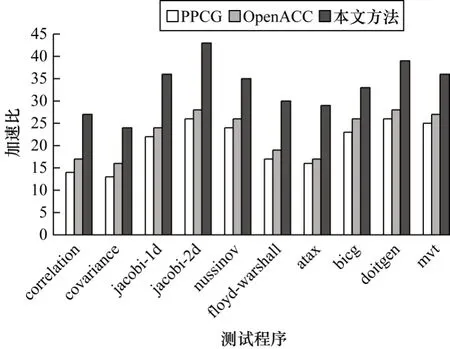
圖4 基準(zhǔn)實(shí)驗(yàn)結(jié)果Fig.4 Benchmark experimental results
在圖4 中,加速比是指CPU 串行和并行方法的執(zhí)行時(shí)間之比,在10 個(gè)測(cè)試程序的運(yùn)行中,PPCG、OpenACC、本文方法分別平均獲得了19.81、22.25、31.62 的加速比,可以看出本文方法的加速比最高,PPCG 和OpenACC 的性能接近。本文方法有最高加速比的原因是使用了GPU 以外的CPU 多線程,在GPU 上執(zhí)行任務(wù)的同時(shí),一部分任務(wù)會(huì)在CPU 上執(zhí)行,降低了所有任務(wù)的總執(zhí)行時(shí)間,而PPCG 和OpenACC 只在GPU 上執(zhí)行任務(wù)。通過基準(zhǔn)實(shí)驗(yàn),證明了本文方法比其他自動(dòng)并行翻譯方法具有更優(yōu)越的性能。
2.2 圖像處理算法實(shí)驗(yàn)
將PMVS 算法作為圖像處理示例算法進(jìn)行分析與研究。PMVS 是圖像處理領(lǐng)域的使用2D 圖像重建3D 場(chǎng)景的算法,從不同角度使用同一對(duì)象的多個(gè)2D 圖像進(jìn)行3D 建模,基于匹配點(diǎn)還原場(chǎng)景的立體信息。PMVS 包括許多可并行處理的過程,包括高斯函數(shù)的Harris 差分(Harris-DOG),可以從2D 圖像序列中提取特征點(diǎn)。PMVS 算法流程如圖5 所示。
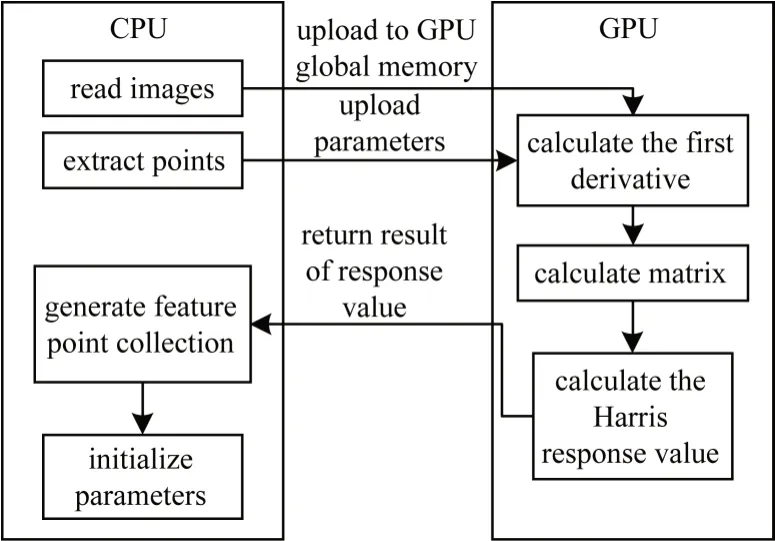
圖5 PMVS 算法流程Fig.5 Procedure of PMVS algorithm
對(duì)于輸入數(shù)據(jù)集,選用10 張不同分辨率的圖片進(jìn)行實(shí)驗(yàn),分別為100×120像素、520×560像素、1 136×1 250 像素、6 230×6 582 像素、12 175×14 210 像素、22 450×26 712 像素、47 565×48 865 像素、64 174×69 210 像素、73 212×72 520 像素、81 511×94 753 像素。基于PMVS 算法,將本文方法與PPCG 和OpenACC 進(jìn)行對(duì)比,實(shí)驗(yàn)結(jié)果如圖6 所示。
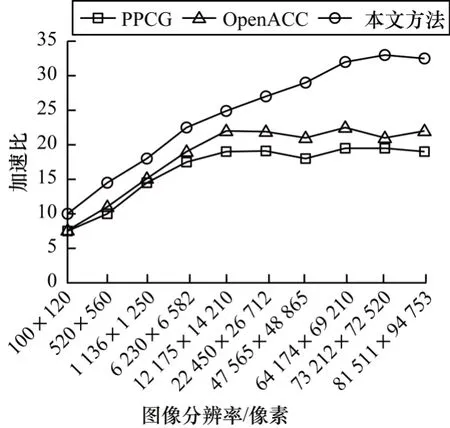
圖6 PMVS 實(shí)驗(yàn)結(jié)果Fig.6 PMVS experimental result
在圖6 中,圖像分辨率從100×120 像素到81 511×94 753 像素逐漸增加。PPCG 和OpenACC 的加速比先是增加,因?yàn)镚PU 并行效率隨著輸入數(shù)據(jù)的增大而提升,當(dāng)圖像分辨率達(dá)到12 175×14 210 像素時(shí),加速比達(dá)到最大,分別是19.47 和21.76,此后圖片再增大加速比也不再增加,在最大值附近波動(dòng)。本文方法也呈現(xiàn)相同的趨勢(shì),但是在每一種圖像分辨率上,加速比都大于PPCG 和OpenACC,最高值在64 174×69 210 像素附近,達(dá)到32.03,這是因?yàn)楸疚姆椒ㄊ褂昧藘杉?jí)并行策略,輸入圖像的一部分在CPU 上處理,降低了整個(gè)圖片的處理時(shí)間,并且隨著圖像分辨率的增加,分配在CPU上處理的任務(wù)也會(huì)增加,當(dāng)圖像分辨率達(dá)到64 174×69 210 像素時(shí),CPU 發(fā)揮最大性能,當(dāng)再增加圖像分辨率時(shí),任務(wù)會(huì)串行執(zhí)行,總執(zhí)行時(shí)間不會(huì)再縮短,最大加速比穩(wěn)定在32.15 左右。通過圖像處理實(shí)驗(yàn)證明了在處理高分辨率圖像時(shí),本文方法比其他自動(dòng)并行翻譯方法的效率更高。從100×120 像素開始,隨著圖像分辨率的增加,加速比的增幅不斷提升,當(dāng)圖像分辨率達(dá)到64 174×69 210 像素時(shí)性能最優(yōu)。
2.3 多線程實(shí)驗(yàn)
為確定線程數(shù)目對(duì)本文方法的影響,通過改變CPU 線程數(shù)目評(píng)估本文方法的性能,實(shí)驗(yàn)條件與設(shè)置同圖像處理算法實(shí)驗(yàn),輸入圖像分辨率分別為520×560 像素、12 175×14 210 像素和64 174×69 210 像素,實(shí)驗(yàn)結(jié)果如圖7 所示。
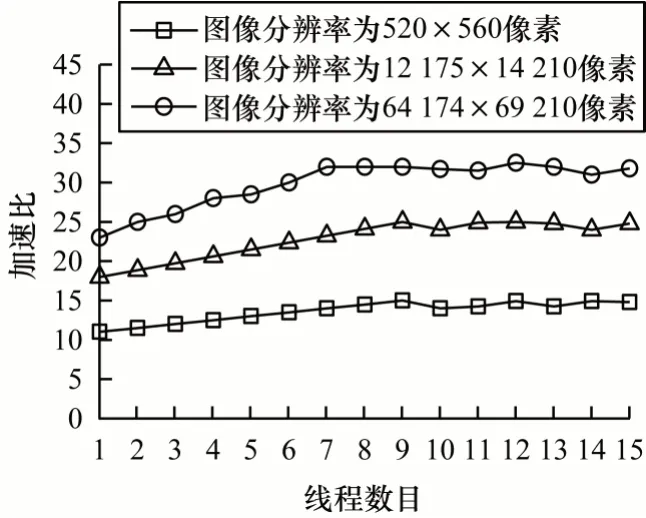
圖7 多線程實(shí)驗(yàn)結(jié)果Fig.7 Multi-thread experimental results
在圖7 中,加速比是指CPU 串行與本文方法執(zhí)行時(shí)間之比。3 種不同分辨率的圖像呈現(xiàn)相同的變化,當(dāng)線程數(shù)目從1 增加到8 時(shí),三者的加速比都持續(xù)增加,圖像分辨率為520×560 像素的圖像加速比從11.83 增加到14.67,圖像分辨率為12 175×14 210 像素的圖像加速比從19.13 增加到24.61,圖像分辨率為64 174×69 210 像素的圖像加速比從23.24 增加到31.62,這是因?yàn)槎嗑€程并行執(zhí)行任務(wù),可以提高CPU的負(fù)載能力。當(dāng)線程數(shù)目達(dá)到8 時(shí),因?yàn)镃PU 核心數(shù)目為8,所以此時(shí)CPU 并行能力最強(qiáng),加速比最高,之后隨著線程數(shù)目增加,超過了CPU核心數(shù)目后,加速比不再增加。因此,當(dāng)線程數(shù)目等于CPU 核心數(shù)目時(shí),本文方法達(dá)到最優(yōu)性能。
3 結(jié)束語
本文提出一種用于PMVS 算法的自動(dòng)兩級(jí)并行翻譯方法,可自動(dòng)將串行C 程序轉(zhuǎn)換為CPU 多線程和CUDA 的兩級(jí)并行程序。經(jīng)過本文方法并行化后,PMVS 算法可使高分辨率圖像在CPU 和GPU 上分別進(jìn)行處理,降低了算法計(jì)算時(shí)間。實(shí)驗(yàn)結(jié)果表明,與其他自動(dòng)并行翻譯方法相比,本文方法能更有效地提升圖像處理算法的性能。后續(xù)將在任務(wù)分配過程中考慮CPU 與GPU 之間的任務(wù)負(fù)載量,使CPU與GPU 達(dá)到負(fù)載均衡狀態(tài),進(jìn)一步提升圖像處理算法的性能。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(bào)(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
