融合語句復雜度的軟件錯誤定位輕量級方法*
2022-12-22 12:01:42何海江
計算機工程與科學 2022年12期
何海江
(長沙學院計算機工程與應用數學學院,湖南 長沙 410022)
1 引言
調試和測試是軟件生命周期中的重要活動,這其間,開發人員為移除軟件故障,耗時且費力。軟件出現故障,首要任務是找到導致出錯的代碼。代碼審查和靜態檢查固然是有效的故障定位方法,但前者人工耗費大,后者難以發現深層次的邏輯錯誤。VS Code、IDEA和Eclipse等開發平臺提供的斷點調試方法,不能確定代碼檢查順序,完全依賴程序員的編程經驗來查找錯誤。因此,人們開始研究自動化的軟件錯誤定位[1,2]技術,其中基于程序譜的軟件錯誤定位SBFL(Spectrum-Based Fault Localization)技術最受關注。現代軟件的規模越來越大,而CPU、內存等資源始終受到限制,SBFL這一類輕量級方法更有實用價值。
SBFL可應用于文件、類、方法(函數)、代碼片段、語句(代碼行)和謂詞等程序實體。本文聚焦于語句級故障定位,只討論相關技術。人們提出了許多SBFL方法[2],然而,這些方法在定位故障語句時,僅考察語句覆蓋結果和測試用例通過與否,故而其性能受到限制。為克服這一缺陷,一系列結合程序譜、代碼靜態特征、代碼動態特征的搜索方法[3]得到發展。然而,這些方法要么獲取程序特征的代價大,要么只在方法級、類級和文件級上驗證性能。
為了能輕量地定位到故障語句,本文提出了一種語句級軟件錯誤定位的排序學習方法。在表征語句時,除語句的SBFL可疑度值外,還選擇了3類輕量級特征:(1)局部變量數、邏輯操作符數和函數調用數等語句靜態屬性;(2)結構化類別;(3)變量譜。在排序學習過程中,使用跨項目的方式訓練排序模型。數據集包含使用Java、C和C++ 編程語言開發的22個項目,包括753個帶故障的版本,故障語句全部來源于程序員實際的編程活動,項目規模有大有小,版本所含錯誤個數有多有少。實驗結果表明,將SBFL可疑度值分別與3類語句特征結合后,即使與表現最佳的SBFL方法相比,新方法都能大幅度減少待排查的語句。3類輕量級特征中,尤以語句靜態屬性最能改善錯誤定位模型的性能。同時也發現,一些在小規模數據集或者人工注入故障版本上得到驗證的SBFL方法,表現并不好。
2 基于程序譜的軟件錯誤定位
基于程序譜的軟件錯誤定位技術僅需收集2類信息:(1)測試用例的執行結果:成功或失敗;(2)程序運行時,是否覆蓋語句。形式上,每條可執行語句的運行特征可用四元組〈aep,aef,anp,anf〉表示。對程序的每一條語句,aep和aef分別表示測試用例覆蓋它并且程序運行結果成功或失敗的數目;anp和anf則分別表示測試用例未覆蓋它并且程序運行結果成功或失敗的個數。
SBFL方法將程序譜轉換成不同的語句可疑度計算公式(簡稱為SBFL公式)。SBFL公式可看作映射函數,將特征向量映射成一個實數值(可疑度值)。當故障發生時,依據這些映射函數逐一計算可執行語句的可疑度值,將語句按照可疑度從大到小排序。排查故障代碼時,從順序表頂端開始逐一排查語句,直到發現錯誤代碼。
DStar2[4]、GP02[5]、GP10[5]、GP13[5]、Tarantula[6]、Ochiai[6]、NaishO[7](即Naish1[8])、NaishOp[7](即Naish2[8])、Wong1[9]、Wong2[9]、Wong3[9]、SBI、Overlap、RussellRao、Jaccard、Dice、Zoltar、M2、Goodman、Anderberg、Kulczynski1、Kulczynski2和Ample,都是研究人員提出的SBFL公式。SBI公式在文獻[10]中有相應的描述;從Overlap到Ample,這11個公式在文獻[7,8]中有相應的描述。
Tarantula、Zoltar、Kulczynski2、RusselRao、Ochiai、Ample、M2、Jaccard 和Anderberg,這9個SBFL公式的值都處于0~1,其余14個SBFL公式的值可歸一化到[0,1]。例如式(1)是Overlap公式常規的計算方法,其值區間為[0,+∞),經過式(2)的歸一化處理后,其值區間為[0,1]。

(1)
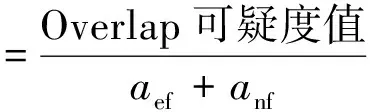
(2)
Lucia 等人[11]對比了將近40 種SBFL,發現Ochiai公式的故障定位能力相對突出,任何一種SBFL方法都無法在多數項目(程序)中超過其它方法。Pearson等人[12]在6個項目、323個版本的實際故障數據集上的實驗數據也證實了這一點。
3 基于搜索的軟件錯誤定位
特定的項目,受軟件規模、測試套件、單個或多個故障、編程語言等因素的影響,可能出錯方式與其它項目迥異。以表征語句可疑度的SBFL公式為特征集,機器學習技術可為項目搜索到對應的最優故障代碼判別模型。MULTRIC(MULtiple ranking meTRICs for fault localization)[13]組合25個SBFL公式,LTR-sbfl[14]將非故障語句與故障語句兩兩組合成復合樣本,再由排序學習算法訓練映射函數。然而,這些方法和傳統的SBFL方法相似,可疑度只依賴于測試用例執行結果和程序實體覆蓋信息,錯誤定位效果受到嚴重制約。若要提升性能,程序邏輯復雜度、故障語句類型和測試用例集等因素都應該考慮。由此,研究人員拓寬思路,引入表征軟件的其它視角的數據,開發了許多基于搜索的軟件錯誤定位方法[3]。
這些搜索技術的特征,除SBFL公式外,還包括:多個變異技術、源代碼復雜度和文本相似性特征[10],方法存在時長、程序元素改變頻率等代碼變化測度[15],函數級代碼復雜度[16],長短期記憶網絡自動化學習代碼的語義特征[17],項目開發報告形成的歷史譜[18],語句類別[19]和測試用例的全部覆蓋信息[20]。PRINCE(PRecise machINe-learning-based fault loCalization tEchnique)和CombineFL[21,22]綜合多類特征,集成SBFL、變異測度、切片、棧跟蹤、謂詞變化、代碼復雜度、故障報告和開發歷史,比較這些靜態特征和動態特征對排序學習算法訓練模型的影響程度。但是,這些方法多用于文件級、類級和方法級(函數級)故障定位,大部分方法的語句級特征獲取代價大。
4 集成靜態屬性和程序譜的方法
調試時,程序員需要定位到故障語句,不能僅限于類或方法。自動化程序軟件修復[1]這類應用也只能運用語句級故障定位技術。同時,為使得技術能應用到代碼量具有一定規模的工業軟件,本文聚焦于語句級的輕量方法,要求代碼特征及可疑度值的計算代價極小。受到搜索式軟件錯誤定位和軟件復雜性度量研究工作[23]的啟發,本文提出了一種集成程序譜和代碼行靜態屬性的排序學習方法,由線性排序支持向量機構造語句級的錯誤定位模型。語句的其它輕量特征:結構化類別和變量譜,也能夠方便地集成到搜索算法中。
程序譜特征來源包括文獻[13]的25個SBFL公式,再加上近年來被多次比較的一些SBFL公式。設定程序只包含單個故障,文獻[8]從理論上證明了6組SBFL公式具有等價性質,因此移除了幾個公式,最終選擇第2節列出的23個SBFL公式為排序學習的程序譜特征。為加快學習算法收斂速度,將這些SBFL的可疑度值歸一化到[0,1]。
結構復雜的代碼中更容易隱藏錯誤。因此,本文將如表1所示的4種語句類別作為表征語句的特征,特征值為0或者1。為簡化問題,并不執行重疊計數,任一語句只屬于某一類,若循環(或return)語句包含條件判斷,判其為循環(或return)語句。

Table 1 Structural types of statements
文獻[19]也用到了語句類別,與本文做法有2點不同:(1)劃分的類別不同;(2)類別被處理為一個實值,與單個SBFL可疑度值加權相加。
除程序譜、語句的結構化類別外,本文提出的基于排序學習的輕量方法,還可以集成語句靜態屬性、變量譜等特征。
4.1 程序語句的靜態屬性
一般來說,越復雜的程序語句(代碼行),其導致軟件出現故障的概率越大。代碼復雜度與軟件質量屬性緊密聯系,可分為內在復雜度和外在復雜度,軟件的內在復雜度容易獲取,外在復雜度獲取代價大[23]。軟件工程領域的代碼復雜度研究成果繁多,常見的有代碼行數、圈復雜度、類繼承層次、模塊扇入扇出、程序運行時間和可執行模塊大小等。目前,還沒有出現以語句為單位的代碼復雜性測度,而本文的目標是定位到故障語句,因此設計了如表2所示的語句內在靜態屬性來表征語句復雜度。
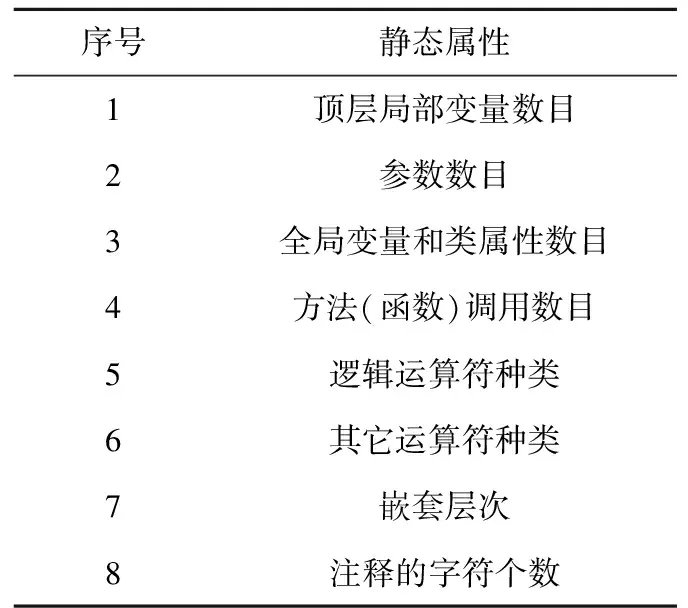
Table 2 Static attributes for statement complexity
文獻[10,15]都使用方法內參數數目和方法內類屬性數目作為特征,前者還統計了方法內的運算符個數。位于同一方法中的語句并不能被方法級(或者類級)復雜度區分開來,因此本文在語句上計算此類代碼復雜度。一般來說,邏輯運算符相比其它運算符,給語句帶來更大的復雜度,因此本文拆分了運算符種類。無論全局變量,還是類屬性,影響的程序功能點要多于方法參數,而方法參數影響的程序功能點又多于局部變量,將變量分成3種類型,更能提高語句復雜性的辨識度。至于語句塊內定義的局部變量,并不明顯增加代碼的認知障礙,故而排除在外。
對于序號1~4的特征,同名變量不重復計數;序號5的邏輯運算符限于&&、||和!,序號6不統計賦值運算符。不屬于方法(函數)的語句,其序號1和2的特征值皆為0。C程序的語句只有全局變量,沒有類的屬性。長注釋的相應代碼應進行更多檢查。若語句屬于以下復合語句:assert、synchronized、do while、while、switch、throw、try catch、if、for,則其嵌套層次加1;其它情形,嵌套層次不變。嵌套層次會遞歸計算。
如某個類的方法annotation有如下10行代碼:
1 floatannotation(Configconfig,Typetype,floatr){
2 floatdesc=0,ac=0;/*(2,0,0,0,0,0,0,0,0,0,1)*/
3for(inti=0;i<10;i++){/*(0,0,0,0,0,2,0,1,0,0,0)*/
4desc+=cevf(config,r);/*(1,2,0,1,0,0,1,0,0,0,1)*/
5if((desc>100&&desc<200)‖
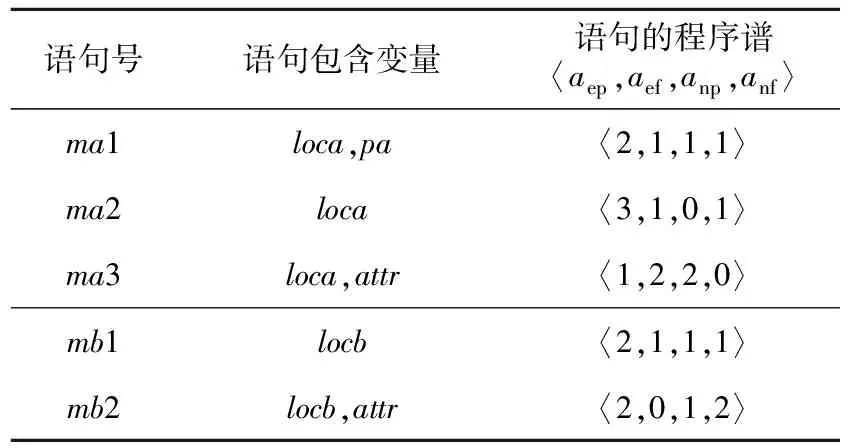
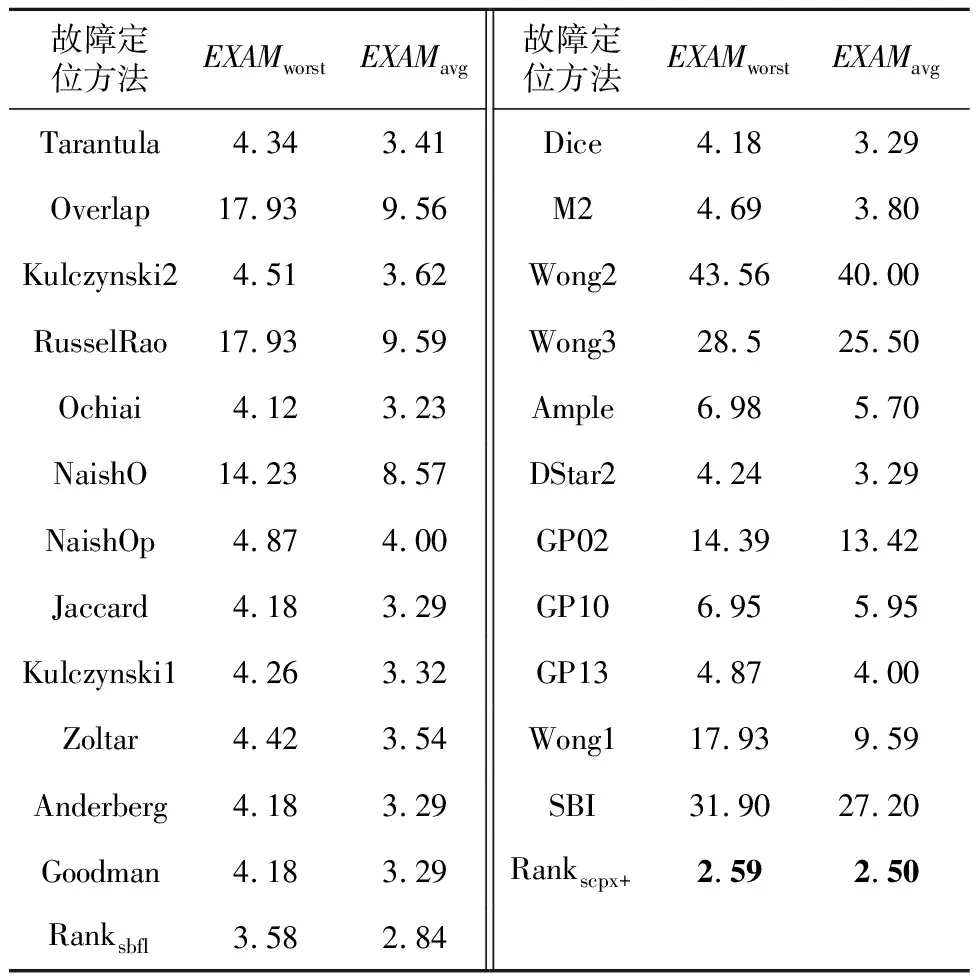
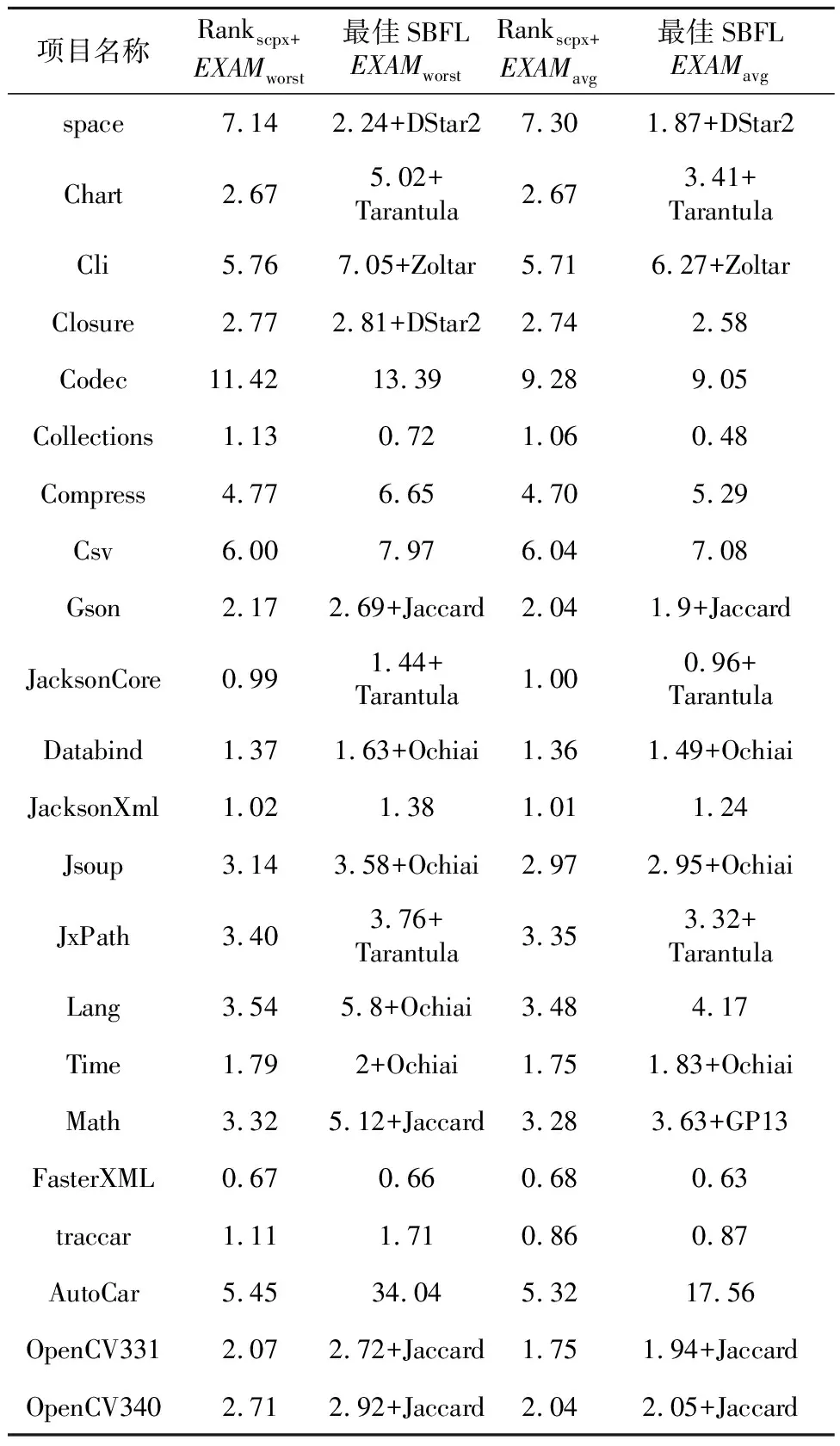
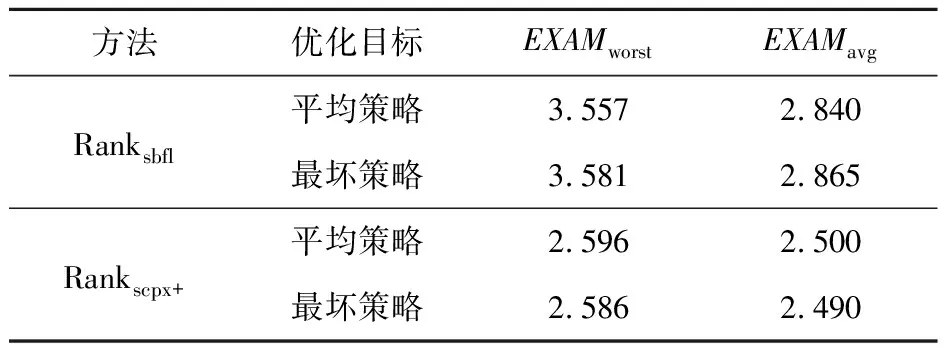
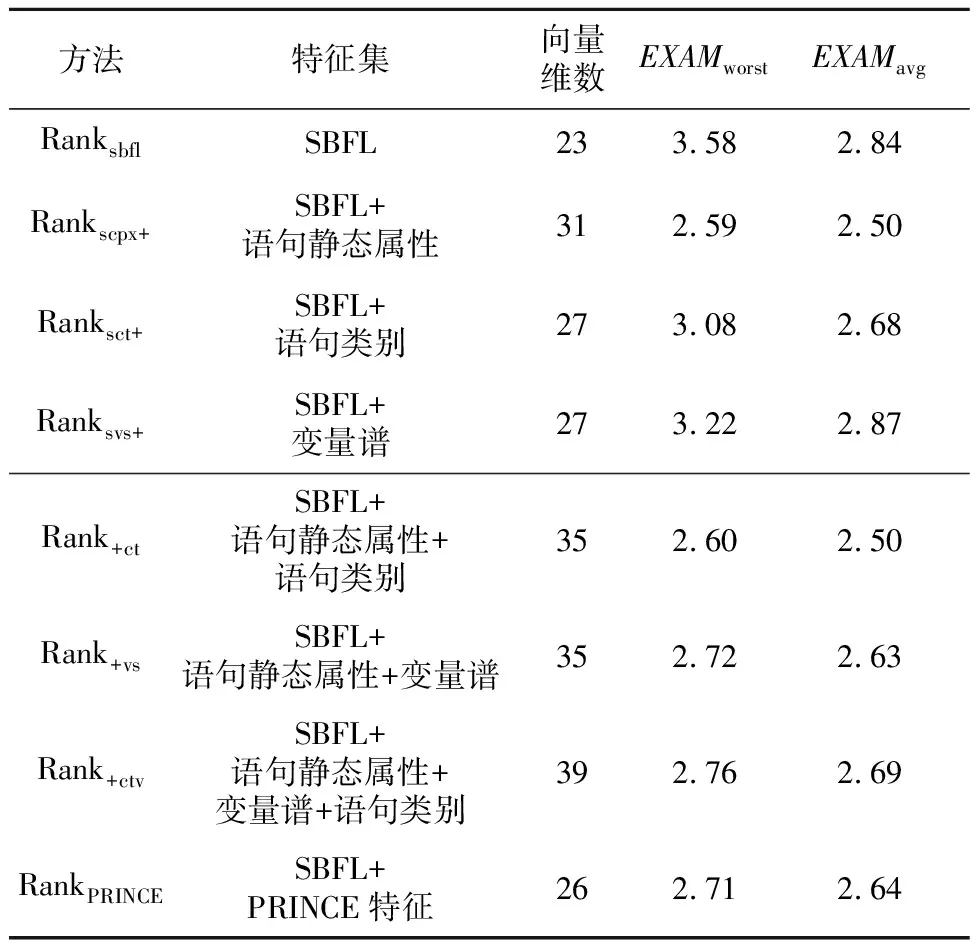
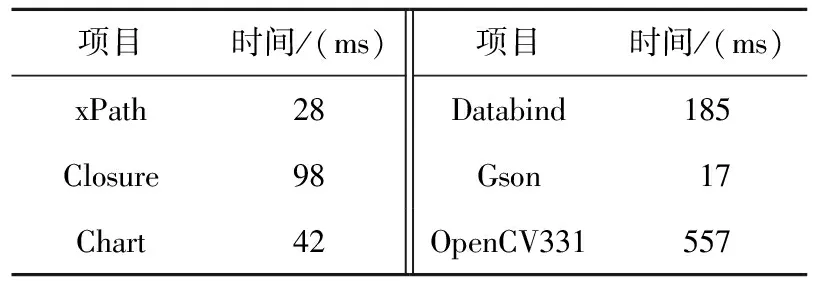
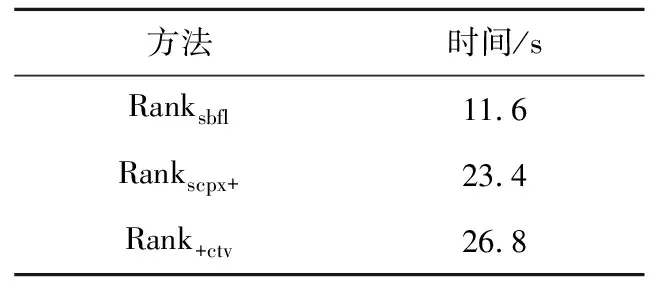
6 (desc>r&&ac 7ac=devf(type);/*(1,1,0,1,0,0,2,0,0,0,1)*/ 8 } 9returndesc+ac-pfVoc;/*(2,0,1,0,0,2,0,0,0,1,0)*/ 10 } 該方法有參數config、type和r,有頂層局部變量desc和ac(注意,第3行的i是定義在for語句塊的局部變量),pfVoc為方法所屬類的屬性,cevf和devf是方法(函數)名稱,則對應行的特征向量可從注釋中觀察到,11維特征向量中前7維屬于語句靜態屬性(所列未包含注釋字符數),后4維屬于語句結構化類別。例如,第5、6行屬于同一條語句,有2個頂層局部變量,2種關系運算符(&&和‖),2種其它運算符(<和>),屬于條件語句,是for語句的從句,所以它的特征向量為:(2,1,0,0,2,2,1,0,1,0,0)。 歸一化處理時,序號1~3的特征除以20,而序號4~7的特征除以10。 就作者所知,用于錯誤定位的語句級輕量特征,除語句類別[19]和變量譜[24]外,只有PRINCE的3個特征[21]:(1)語句的字符數;(2)運算符個數;(3)加權變量數。這3個特征同樣屬于語句級靜態屬性。在PRINCE中,運算符包括10類:算術、邏輯、關系、位、指針、數組[]、賦值、復合賦值、sizeof、函數調用();變量的權分為3類,基本數據類型的權為1,數組類型的權為數組元素個數,struct和class的權為其所有屬性的權的累加值。為了與本文方法比較,將上述3個特征簡稱為PRINCE[21]特征。本文的實驗數據有C++程序,許多項目采用新的Java、C++語法規則,基于這2個原因,本文采用微調方式計算PRINCE特征值。在計算操作符數時,除文獻[21]統計的10類運算符外,另加入源代碼解析工具能夠統計的其它運算符。在計算加權變量數時,3類數據類型的權統一為1,因為指針、map、set、list等數據類型的元素個數獲取代價非常大。文獻[21]作者也承認,他們無法統計這些數據類型的元素個數。Java和C++類的對象屬性值自然也難以累加。 變量僅限于全局變量、類屬性、方法參數和頂層局部變量。變量譜定義為變量所屬語句程序譜的平均值,表3是一個簡單例子。 Table 3 Example of variable spectrum 某個類有方法ma和mb,attr是類的屬性。方法ma有3條可執行語句(ma1,ma2和ma3),頂層局部變量為loca,參數為pa。方法mb有2條可執行語句(mb1和mb2),頂層局部變量為locb。測試套件有5個測試用例,3個成功,2個失敗。依定義,變量loca在語句ma1、ma2、ma3出現過,其譜等于〈(2+3+1)/3,(1+1+2)/3,(1+2)/3,(1+1)/3〉=〈2,1.33,1,0.67〉。同理,locb的譜等于〈2,0.5,1,1.5〉,attr的譜等于〈1.5,1,1.5,1〉,pa只在ma1中出現,其變量譜等于ma1的程序譜〈2,1,1,1〉。 得到變量譜集合后,選擇語句內最大可能引入故障的變量譜經歸一化處理后當作語句的變量譜特征(4維向量),算法1描述了詳細步驟。 算法1計算語句的變量譜特征 輸入:Aep,Aef,Anp,Anf:語句的程序譜四元組; VARS:語句的變量集合; FT,PT:測試套件失敗、成功測試用例數。 輸出:變量譜特征。 fori=1 to|VARS| EFi=Aef[VARSi]/FT; EPi=Aep[VARSi]/PT; NPi=Anp[VARSi]/(Anp[VARSi]+Anf[VARSi]); NFi=Anf[VARSi]/(Anp[VARSi]+Anf[VARSi]); VARS排序結果賦值給L,排序依據為:EF降序優先,EP升序次之,NP降序再次之,NF升序最次之; var←L的首個元素; returnEF[var],EP[var],NP[var],NF[var]; 經算法1處理后,表3中4個變量依變量譜排序后,L={loca,attr,pa,locb},var=loca。因此,取loca的譜歸一化向量為語句ma1、ma2和ma3的變量譜特征,取attr的譜歸一化向量為語句mb2的變量譜特征。在計算語句的靜態屬性時,已經存儲了各語句的變量信息,加之變量譜可由語句的程序譜轉換,無須額外負擔,因此,語句的變量譜特征計算代價極小。 Kim等人[24]首先提出了變量譜,將SBFL公式的程序譜用變量譜替換,計算可疑度后定位軟件錯誤。與此不同的是,本文將變量譜作為表征語句的特征。 排序學習算法選用LibLinear的線性RankSVM,適合大規模樣本和特征的數據集[25]。令PS為訓練集,其元素由同一版本成對的故障語句與非故障語句構成(xi和xj)。RankSVM的優化目標[25]如式(3)所示: (3) 其中,w是樣本(語句)的權向量,也就是RankSVM學習到的錯誤定位模型,C是模型的平衡因子。非故障語句判為錯誤語句,或者錯誤語句判為非故障語句,模型盡力減小這些誤判引起的誤差實數值,另外模型還必須保持泛化性,兩者的平衡由C來調節。令某條語句的特征向量為x,則該語句的可疑度值等于w*x,*為內積運算。語句的w*x值越大,表示其包含故障的可能性更大。特征集除程序譜外,另包含語句靜態屬性,則x的維數等于23+8;另包含語句類別,則x的維數等于23+4;另包含變量譜,則x的維數為23+4。 為驗證本文方法的有效性,采用跨項目的方式構造錯誤定位模型。將項目按比例劃分為訓練集、驗證集和測試集,同一項目的所有版本同時分配到某個子集。不同項目的可執行語句數大不相同,構造訓練集時,從所有版本中統一取β條語句。構造驗證集和測試集時,收集的所有可執行語句都被納入。 RankSVM的優化目標無法最小化錯誤定位評價指標,利用排序模型的平衡因子C和驗證集來調整錯誤定位性能誤差。算法2描述了搜索最優錯誤定位模型的過程。 算法2搜索最優錯誤定位模型 輸入:錯誤定位評價指標EXCHK;項目集合PRJS;項目版本納入訓練集的語句條數β;平衡因子C;平衡因子搜索次數γ。 輸出:最優錯誤定位模型BestW。 將PRJS按比例隨機劃分訓練集、驗證集和測試集; TRAIN←從訓練集每個版本中抽取β條可執行語句; VALID←從驗證集抽取所有可執行語句; TEST←從測試集抽取所有可執行語句; EXCHKmin=1;//1是最大值 BestW=0,C=1; forj=1 toγ W←learn model inTRAIN; EXCHKnow←compute byWonVALID; ifEXCHKnow EXCHKmin=EXCHKnow; BestW=W; C=C/2; returnBestW; /*基于BestW計算當前測試集的性能*/ 所有實驗在一臺配置為Intel Core i7-8700 3.2 GHz CPU和16 GB 物理內存的計算機上完成,操作系統是Windows 10。 無論是包含單個故障的版本,還是多故障的版本,本文都采用EXAM來度量其錯誤定位性能,其定義如式(4)所示: EXAM= (4) 當有多條語句可疑度值相等時,最理想的情況下,檢查其中一條語句就定位到故障,稱為最優策略;最壞的情況下,所有語句都檢查完后才找到故障,此時性能記為EXAMworst;平均策略的性能EXAMavg為最優策略和最壞策略的平均值。 實驗參數的設置,采用以下策略:針對算法2,參數β=100,γ=30;線性RankSVM的參數全部取默認值。實驗共有22個項目,按5∶3∶3的比例隨機劃分為訓練集、驗證集和測試集,任意項目的所有版本只能處于同一子集內。參數β過小,模型適應性差,β過大,模型將擬合規模大的項目,絕大多數版本至少有100條可執行語句,故而設β=100。訓練集選取可執行語句時,先取所有故障語句,再取故障語句的近鄰,不足的部分,隨機從其它類(C++、Java)或者函數(C程序)中選取。參數γ的取值可參考文獻[25]。為減小訓練集、驗證集和測試集劃分的隨機性影響,算法2重復執行500次,后文實驗數據是500次結果的平均值。 實驗數據集來自于SIR、Pairika OpenCV、Defects4j和Bears。SIR軟件項目基礎資源庫是軟件錯誤定位領域知名的基準測試集[26],實驗收集了實際故障的C語言項目space,有29個錯誤版本。OpenCV是一個輕量、高效、跨平臺的計算機視覺和機器學習軟件庫。Pairika從OpenCV的7個模塊中提取而得[27],它超過49×104行代碼和11 129個測試用例,被構造為C++程序的故障診斷基準數據集。實驗收集了OpenCV 331和OpenCV 340,共19個錯誤版本,所有錯誤皆為實際故障。Defects4j是軟件測試領域廣泛采用的基準數據集[28],其網站當前為2.0版本,實驗收集了16個Java項目:Chart、Cli、Closure、Codec、Collections、Compress、JacksonCore、Gson、Csv、Databind、JacksonXml、Jsoup、JxPath、Lang、Math和Time,這些項目共有641個錯誤版本,所有錯誤皆為實際故障。通過持續集成的手段識別故障版本和修正版本,Bears[29]為自動化修復程序社區建立的一個基準數據集。實驗收集了3個Java項目:FasterXML、traccar和AutoCar,共有64個錯誤版本,所有故障語句皆來源于實際編程。 在VirtualBox v6.1和Ubuntu 18.04環境下,執行SIR、Defects4j和Bears的測試用例,獲得語句的程序譜。使用Gcov采集SIR的C程序的代碼行覆蓋數據。使用Cobertura采集Defects4j和Bears的Java程序的代碼行覆蓋數據。Pairika的測試用例執行結果在Windows 10環境下獲取,使用開源軟件OpenCppCoverage采集代碼行覆蓋數據。 有少部分代碼中多條可執行語句排在一行,此時取可疑度最大值作為整行代碼的可疑度值。很多故障代碼屬于缺失型,修正版里添加了正確語句,此時無法獲取這些缺失語句的程序譜,本文實驗采用以下簡單做法:如果缺失語句后有代碼,則以其后一行指代故障;否則,以缺失語句前一行代碼指代故障。 Pairika、Defects4j和Bears的類非常多,為減少收集程序譜的時間,每個版本只記錄最多30個文件的代碼行覆蓋數據。具體策略包括2個步驟:首先執行一遍所有測試用例,統計每個文件的被覆蓋行數目;后續選擇文件時,先加入帶故障的文件,不足部分,優先挑選被覆蓋行數最多的文件。 在語句特征的采集與計算過程中,本文使用Eclipse的抽象語法樹Parser解析源代碼。在解析C程序和C++程序時,調用了CDT組件,解析Java程序時則調用了JDT組件。 為驗證語句靜態屬性對錯誤定位模型的影響,定義特征集僅限23個SBFL公式的方法為Ranksbfl,集成程序譜和表2代碼行靜態屬性的方法為Rankscpx+。表4對比了各故障定位方法在753個版本上的平均性能,最小值加粗表示。 對排序學習算法來說,EXAMworst以最壞策略為算法優化目標計算而得,EXAMavg以平均策略為算法優化目標計算而得。Ranksbfl和Rankscpx+的EXAM值如此,如非特別說明,后文其它排序學習算法的EXAM值亦如此。 以往小數據集或者人工注入故障數據集的部分研究成果并不受支持。如NaishO表現并不好,Wong2和Wong3更是糟糕。總體來看,比較23個傳統SBFL方法,Dice、Jaccard、Anderberg、Goodman和Ochiai表現優異,Kulczynski1、Tarantula、Kulczynski2、Zoltar和DStar2也很不錯。從表4可看出,相比表現最好的SBFL,Ranksbfl都有足夠的競爭力。特征集加入語句靜態屬性后,Rankscpx+性能顯著提高,EXAMavg減少了37.1%(SBFL的Ochiai最優),EXAMworst減少了22.6%(Ochiai最優)。 Table 4 Comparison of EXAM among sereval fault localization methods 表5列出了Rankscpx+與項目表現最佳的SBFL的性能比較。最佳SBFL列,未帶加號表明多個SBFL同時取得最佳效果,帶加號則只有一個SBFL取得最優性能,加號后是該SBFL的名稱。 針對單個項目比較EXAMworst,除項目space、FastXML和Collections外,Rankscpx+都要比最優SBFL性能高;而以EXAMavg為評估標準,則Rankscpx+也在13個項目上勝出。不同編程語言的語句,特征計算方式有差別。數據集只有一個C項目space,它拉低了Rankscpx+的性能。 這些項目的編程語言、測試用例數目、可執行語句規模和故障類型等都大相徑庭,在驗證集上獲得最優的模型,在測試集上的性能并非最佳。表6的結果顯示,分別以最壞策略和平均策略為優化目標,Ranksbfl的性能差別不大,Rankscpx+的性能更是接近。這也提示我們,增加合適的特征,從更多角度表征語句,錯誤定位模型的性能還會提升。 相比于傳統SBFL方法,以及基于SBFL的搜索方法Ranksbfl,Rankscpx+的性能提升明顯。將Rankscpx+的特征子集由語句靜態屬性替換為語句 Table 5 Performance comparison on a single project Table 6 Comparison of fault localization methods by two strategies 結構化類別(簡稱語句類別)、變量譜后,或者將語句類別和變量譜加入到Rankscpx+的特征集,表7展示了這些算法的性能。另外,RankPRINCE指集成23個SBFL公式和3個PRINCE特征的方法。 語句的3類輕量特征對錯誤定位模型性能都有幫助,語句靜態屬性表現最優,語句類別次之,變量譜再次之。從表7可觀察到,變量譜的作用并不突出,集成SBFL和變量譜后,Rank+svs的EXAMavg值甚至比Ranksbfl的還差。3類輕量特征對 Table 7 Effect of three kinds of features on fault localization methods performance 語句內在復雜度的貢獻作用存在負相關因素,導致特征集加上語句類別、變量譜后,Rankscpx+性能反而下降。即便集成SBFL、語句復雜度、語句類別和變量譜,Rank+ctv的性能還不如Rankscpx+的。或許這些特征拆得更細,能降低這種不利影響。相比RankPRINCE,Rankscpx+的特征集更豐富,性能也提高不少。 語句的特征獲取時間復雜度低。表8是幾個具規模代表性項目的時間開銷,項目時間是其所有版本的平均值,單位為ms。在對應時間內,完成3項任務:解析源代碼、計算語句特征向量和存儲特征到文件。即使是OpenCV331這樣規模的程序,獲取特征的時間也不到1 s。 Table 8 Time overhead of feature acquisition 排序學習最優模型的求解時間開銷也不大,表9是3個算法以EXAMworst為優化目標的錯誤定位模型搜索時間,單位為s。對應時間內,完成3項任務:讀入特征集、劃分訓練集/驗證集/測試集和求解最優錯誤定位模型。算法的時間為500次求解過程的平均值。 最優錯誤定位模型的訓練在調試活動前完成。語句可疑度值的計算開銷僅限于特征獲取和模型特征與權向量線性內積運算,后者時間可忽略不計。因此,本文方法夠輕量,能夠實時地推薦可能出故障的語句序列。 Table 9 Time cost of solving the optimal model 數據集由22個項目組成,代碼用3種流行的編程語言開發,各項目的故障并非人工注入,而是在實際開發項目時產生的,錯誤定位模型由跨項目形式訓練而得。基于程序譜的搜索方法能幫助開發人員、自動修復軟件并定位到故障語句,然而,源代碼固有的故障相關信息被忽略,如何挖掘語句靜態屬性,研究提升錯誤定位性能的算法很有意義。本文設計了語句級代碼復雜度的特征集。實驗結果表明,集成程序譜和語句的這些靜態屬性后,通過排序學習算法獲得的錯誤定位模型,能顯著減少待排查的語句數目。語句其它2類輕量特征:結構化類別和變量譜,有助于改善SBFL搜索方法的性能,但比語句靜態屬性遜色不少,與其組合后,顯現負面作用。實驗還發現,一些在小數據集或者人工注入故障數據集上的結論并不成立。 實驗數據集的項目大小不一,編程語言各異,故障類型多樣,這些因素都制約了錯誤定位方法性能。擴充數據集,增加表達語句復雜性的靜態屬性,都是后續研究工作的重要內容。4.2 變量譜特征
4.3 排序學習軟件錯誤定位模型
5 實驗結果及分析
5.1 實驗數據集及語句特征計算
5.2 本文方法與傳統SBFL方法及基于SBFL的搜索方法對比
5.3 結構化類別、變量譜和語句靜態屬性對比
6 時間復雜度
7 結束語
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28當代陜西(2019年10期)2019-06-03 10:12:04人大建設(2019年12期)2019-05-21 02:55:44瞭望東方周刊(2017年42期)2017-12-05 18:49:38數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54環球時報(2017-03-30)2017-03-30 06:44:45汽車維護與修理(2016年10期)2016-07-10 08:17:41中國衛生(2015年3期)2015-11-19 02:53:32汽車維修與保養(2015年6期)2015-04-17 03:31:50
