基于雙語信息的中外建筑設計數據挖掘研究
2022-12-26 13:41:44吉林建筑科技學院孫恒
中國建設信息化 2022年23期
文|吉林建筑科技學院 孫恒
0.引言
當前,隨著時間的推移,建筑的設計與施工越來越復雜,再加上現代科技與物質技術的飛速發展,使建筑設計的研究也由靜態到動態的發展[1]。現如今,大量新的建筑被建造出來,龐大的信息也隨之更新,使得建筑設計者需要從海量數據中獲取其所需要的信息,不僅增加了信息獲取的難度,也使得海量數據資源利用價值受到負面影響[2]。當前,在許多方面,數字技術的發展都取得了很好的效果。同時,它也在潛移默化地促進著建筑業的發展。不僅在設計上,在施工、經營等方面也能夠充分展現其對建筑行業發展的促進作用。但由于數字化技術的局限性,使得其在建筑設計領域中應用未能實現,大部分建筑設計者仍然在使用傳統工作方式。同時,目前,我國建筑規劃中關于設計數據、經驗積累等方面尚不完善,無法滿足數據挖掘的需求[3]。因此,針對上述諸多問題的存在,引入雙語(中文、英文)信息技術,開展對中外建筑設計數據挖掘的相關研究。
1.中外建筑設計數據采集與數據庫建立
為向后續數據挖掘提供更加充分的數據資源,對中外建筑設計數據通過爬蟲技術進行數據采集,實現了準確的、大覆蓋范圍的、大存儲量的數據自動采集,其中采集范圍包括中外建筑本身的設計信息,如建造日期、規模、建設工程概況等。并建立數據庫,為后續操作提供依據。建筑設計數據庫是基于可擴展的建筑設計中的相關信息構建而成[4]。根據擴展元模型的邏輯,對輸入到數據庫當中的中外建筑設計數據進行組織、描述和存儲。通過對數據庫的建立,能夠在極大程度上為建筑設計決策提供更具實體化的數據模型,并存儲可擴展的建筑設計戰略產生所需的信息。由于中外建筑設計數據本身存在冗余度低、獨立性強以及可擴充性強等特點。因此,能夠為后續建筑師、業主和用戶之間的共享提供便利條件[5]。在實際應用中,可將建筑設計形態數據、空間數據、環境心理數據等數據按關系數據模式進行數據結構化處理。以中外建筑設計數據中的屬性數據為例,其數據庫的基本結構如表1 所示。
按照上述格式,完成對其他不同屬性數據庫的建立。將用于描述物的基本元數據稱為物元數據,對數據庫當中得到物元數據用M 表示,一維物元是以某一物Om為對象,構成如下述公式表示的有序三元組:
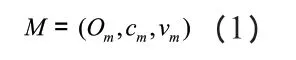
公式中,cm表示特征值;vm表示以物Om為對象的關于特征值的量值。對于多維物元而言,其包含的特征有:cm1,cm2,……,cmn,除此之外,還應當包含對應的量值,因此其表達式為:
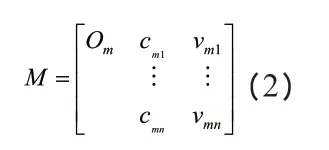
具體而言,將其代入到中外建筑設計當中,一維物元M1可表示為:M1=(窗戶,形狀,圓形)。該方法采用了基于可擴展的基本元素表示方法來表示數據,便于后續對其進行識別和挖掘。可擴展模型使數據的格式一致,而數據化的轉化則使數據變成可被計算機識別的數據。建筑是一種從宏觀到微觀的物質元素及其構成的復合結構。在應用數據挖掘技術時,由于特殊的條件和操作的原因,無法挖掘出每個物元和其特征量,所以可以選擇若干個物元進行挖掘。在一個范圍較大的物元當中,通常都會包含多個小物元,例如在建筑當中包含多個立面,并且在同一個立面上也能夠存在多個窗臺及窗戶。因此,在實際應用中,數據類型劃分的越詳細,則后續分析能夠越全面,挖掘和計算的精度也會隨之提升。
表1 中外建筑設計數據資源屬性數據庫基本結構
2.基于雙語信息的中外建筑雙語資源抽取
在完成對中外建筑設計數據資源數據庫的建立后,將其作為基礎,利用雙語信息技術,實現對雙語資源的抽取。從雙語網頁當中挖掘雙語資源,將其看作是信息抽取。在這一過程中,將數據庫當中包含的數據進行結構化處理,并變化成表格的形式[6]。將原文本輸入到提取模塊,以固定的形式輸出信息。從不同的文件中提取出信息點,并以相同的格式進行整合。以統一格式整合的信息,其優點在于便于核對和對比。在抽取過程中,以Dom 樹葉子節點為單位小片段,便于提高抽取的精度。圖1 為以Dom 樹葉子節點為單位的雙語資源基本結構圖。
將圖1 所示的結構作為雙語資源提取的規則,在提取的過程中,增加一個序列概念,令下述表達式為一個項集:
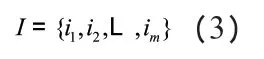
公式中in,為項目,n 的取值為1,2,……,m。在數據庫當中包含上述項集共s 個,針對s 的元組數目支持度進行計算。
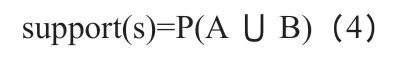
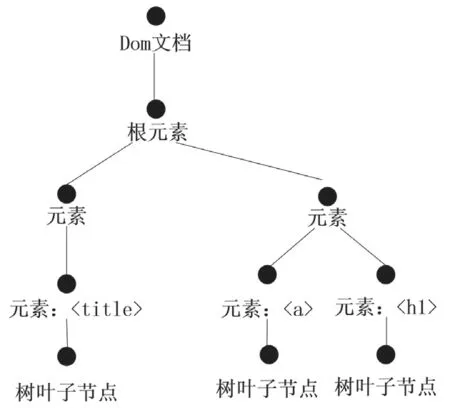
圖1 以Dom 樹葉子節點為單位的雙語資源基本結構圖
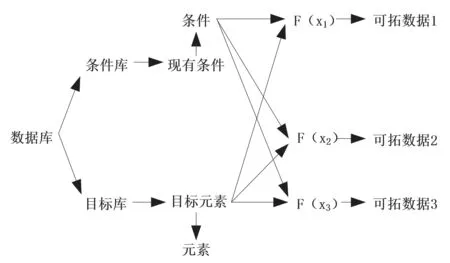
圖2 中外建筑形態構成相容可拓數據挖掘示意圖
公式中,support(s)表示序列s 的支持度;A 和B 表示抽取條件。通過上述計算得出最小支持度為smin,若某一序列s 的支持度>smin,則稱s 為頻繁序列,將其提取用于后續挖掘。針對漢語與外語雙語提取時,符合外語和漢語特征的信息可以被直接提取,而雙語片段中僅出現某一語言特征的情況較少。針對這一問題,在外語特征集合中存在兩個及以上元素同時出現時,需要考慮到語言特征的優先級問題。分別定義外語和漢語的單詞的優先級順序,優先級從高到低。以分隔符區分部分為單位,當多個部件包含單一語言特征時,以高優先權的部件為其語言信息。順序主要考慮到外語特有的特征,用于表示外語單詞以及外語發音等。
3.基于建筑相容度計算的可拓數據挖掘
針對中外建筑設計數據資源的挖掘需要解決其差異對比與相互依存關系同時存在的問題。數據資源可能是元素矛盾也可能是構成矛盾。針對不同的矛盾問題,對其進行相容可拓數據挖掘。通常情況下,建筑形態的組成是不協調的,即在建筑的設計中,形態元素與現有的環境不相適應。針對建筑物形態相容的問題,采用可擴充數據挖掘技術,將物體形態元素或現有條件轉化為可拓形式,并對其進行相應的相容性分析,以此獲得相關的建筑形狀信息,從而幫助建筑設計者做出相應的決策[7]。圖2 為中外建筑形態構成相容可拓數據挖掘示意圖。
圖2 中,F(xn)表示相容度函數,n 的取值為1,2,3。F(xn)的表達式為:
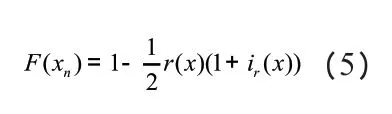
公式中,r(x)表示中外建筑設計數據所有子集之集;ir(x)表示某一目標元素子集。根據上述公式,計算得出提取到的設計數據資源與對應目標元素的相容度,根據具體數值劃分可拓數據資源類別,完成對中外建筑設計數據的挖掘。由于建筑空間的特殊性,可拓數據挖掘技術在每個建筑中都具有獨特的定義,即使是同樣的兩個空間,在內部的布置和使用上也會有所不同。因此,傳統的可擴展數據挖掘方法不能完全復制傳統的方法,應將其分類,并挖掘出可以提升創意水平的關鍵要素。在使用功能相近或類似的房間中,其空間特征的相似性較大,但差異較小。兩者之間的相似之處在于滿足這種使用需要,而差異性則是不同于其它建筑空間的創新之處。可拓數據挖掘技術可以從建筑空間數據中提取創新性的知識,從而發掘創意的新視角,幫助建筑師在繼承傳統建筑的同時,創造出新的空間。對未來建筑空間的解讀,就是對建筑空間發展的趨勢進行梳理與預測。在建筑設計案例庫的基礎上,利用可擴展數據挖掘技術,可以從海量的歷史資料中獲得相關的信息,并對其進行預測,從動態的空間數據中發掘規律,尋求空間創新的突破口。
4.數據挖掘效果分析
從中外雙語資源中挖掘實驗所需的數據,采用正確率、召回率以及F-測試度三個指標實現對基于雙語信息的數據挖掘方法(實驗組)、基于大數據的數據挖掘方法(對照組A)和基于區塊鏈的數據挖掘方法應用性能進行衡量。下述為三個指標的計算公式:
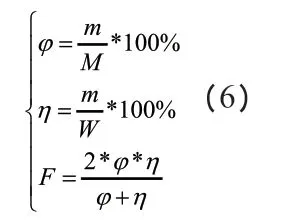
公式中,j 表示數據挖掘結果的正確率;m 表示正確挖掘結果數量;M 表示總挖掘結果數量;h 表示召回率;W 表示所下載網頁當中總的翻譯對數;F 表示測試度,即以正確率和召回率為依據的測試結果量化數值。在需要進行數據挖掘的中外建筑設計數據資源中,人為引入建筑專業術語125對和標準外語單詞355 個。在實驗過程中,分別設置兩種數據挖掘條件,一種為提取規則匹配雙語對,另一種添加一次規則后匹配雙語對。針對兩種條件下,三種挖掘方法的各項指標進行計算,并將計算結果繪制成曲線圖。其中,圖3 為三種挖掘方法在提取規則匹配雙語對條件下的正確率j指標對比圖。
圖4 為三種挖掘方法在添加一次規則后匹配雙語對條件下,召回率h 指標對比圖。
圖5 為兩種條件下,三種挖掘方法的綜合測試度F 指標的對比結果。
結合上述三組對比結果可以看出,實驗組無論是正確率j、召回率h,還是綜合測試度F 的指標數值均明顯高于另外兩組對對照組的挖掘方法。具體而言,實驗組的正確率、召回率和綜合測試度的數值均隨著雙語對數的增加而增加,最低數值也超過了96%,而另外兩組對照組挖掘方法的各項指標均低于實驗組挖掘方法的最低值,相差較大。
因此,綜合實驗結果以及具體分析得出,本文提出的方法在實際應用中能夠有效提高對中外建筑設計數據挖掘的正確率、召回率以及綜合測試度,且三種指標的最低數值也超過了96%,達到提升中外建筑設計數據利用價值的目的。
5.結束語
本文基于雙語信息技術的應用優勢,將其應用到對中外建筑設計數據挖掘當中,提出了一種全新的數據挖掘方法。通過將該數據挖掘方法與另外兩種挖掘方法對比得出,新的挖掘方法綜合性能明顯更高。將新的數據挖掘方法應用于實際,可為建筑設計者提供更科學和合理地獲取設計數據資源的方法,進而促進設計者的設計效率。由于時間限制,本文研究有待在今后繼續深入探究,例如,對數量不斷增加的挖掘數據需要為其建立空間更大的數據庫等,以此實現對數據挖掘的進一步完善。
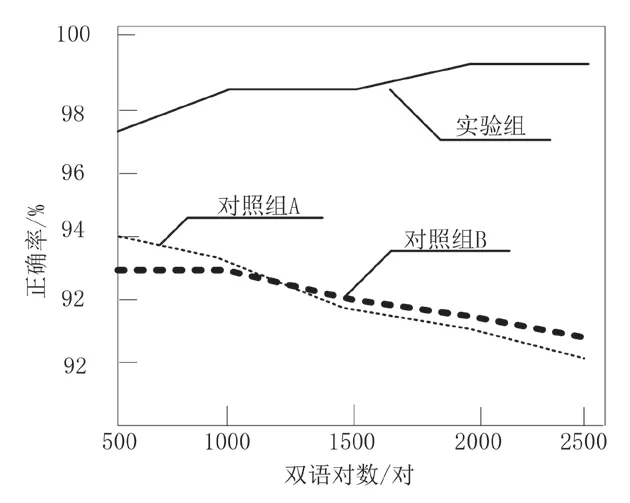
圖3 三種挖掘方法相同條件下正確率j 對比圖
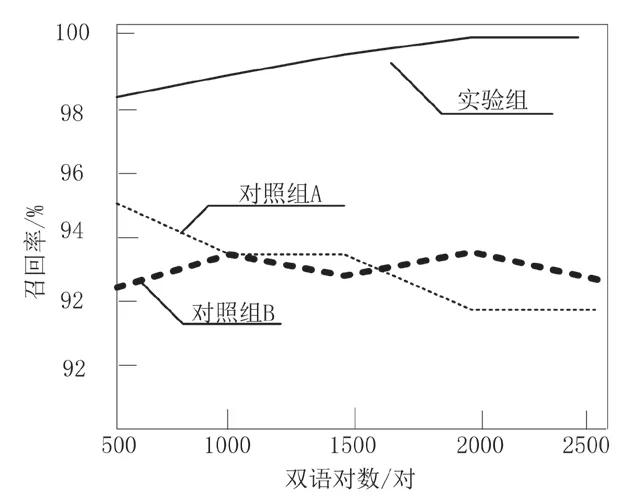
圖4 三種挖掘方法相同條件下召回率h 對比圖
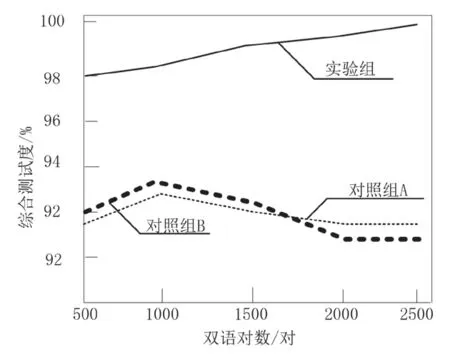
圖5 三種挖掘方法綜合測試度指標F 對比圖
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
建材發展導向(2019年10期)2019-08-24 06:25:04
現代裝飾(2017年9期)2017-05-25 01:59:43
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
中國房地產業(2016年2期)2016-03-01 01:25:34
財經(2016年6期)2016-02-24 07:41:51
信息通信技術(2015年6期)2015-12-26 01:16:46
