基于復合尺度與多粒度聯合特征的行人重識別
2022-12-30 07:51:46程俁博雷景生
計算機工程與設計 2022年12期
程俁博,雷景生
(上海電力大學 計算機科學與技術學院,上海 201300)
0 引 言
行人重識別屬于行人檢索方向的子問題,主要研究在由不同攝像頭的監控區域下、不同時段拍攝的行人圖像庫中,檢索到與目標人物為同一類的行人圖像[1]。近些年來,深度學習方法逐漸取代傳統的方法。
在特征表示方面,大部分算法通過利用不同的深度學習網絡提取特征,然后進行度量學習計算相似度,目前主流算法主要有利用特征金字塔[2](DPFL)、多尺度模型[3](MuDeep)、3D空間語義模型[4](SAN)等模型提取特征,當遇到遮擋或者光照的干擾時,全局特征的判別能力減弱,因此漸漸開始局部特征的研究。常見的局部特征提取思想包括人體姿態導向模型[5](PDC)、屬性學習模型[6](APR)、結構化表征學習[7](PSRL)、特征切塊模型[8](PCB)和多分支模型[9](MGN)等,提取不同粒度下的具有表征能力的深度特征。同時,隨著注意力機制的提出與發展,很多專家學者將注意力模型[10-12]用在了行人重識別實驗上,并取得了良好的識別效果。
考慮到只采用端到端的方式會割裂尺度與粒度間的關系,造成信息的丟失。本文采用ResNet50[13]作為基礎骨干網絡,提出一種不同尺度與不同粒度信息相結合的算法策略,設計出多分支網絡,對基礎網絡的最后三層卷積輸出做不同尺度的提取,兼顧不同層的信息,且骨干網絡的最后輸出切分為不同粒度,分別提取具有表征能力的特征,然后利用全局池化、卷積歸一等操作,對不同粒度信息進行更加深度的特征提取,增強網絡對多粒度表征信息的識別能力。
1 行人重識別方法研究
1.1 行人重識別網絡架構
本文所提出的行人重識別架構主要由3個部分組成,分別是基礎骨干網絡(backbone)、復合尺度模塊(composite scale module)和多粒度模塊(multi granularity module)。
如圖1所示。Backbone為ResNet50網絡,提取到行人特征后,復合尺度模塊和多粒度模塊共同進行深度特征提取融合。復合尺度模塊由3個分支組成,分別為P0、P1、P2分支,分別從網絡不同深度提取行人特征。多粒度模塊由P3、P4分支組成,分別提取不同粒度下的行人顯著特征,作為全局特征的補充。最后將復合尺度模塊與多粒度模塊的特征融合,形成最終用于身份識別預測的特征。
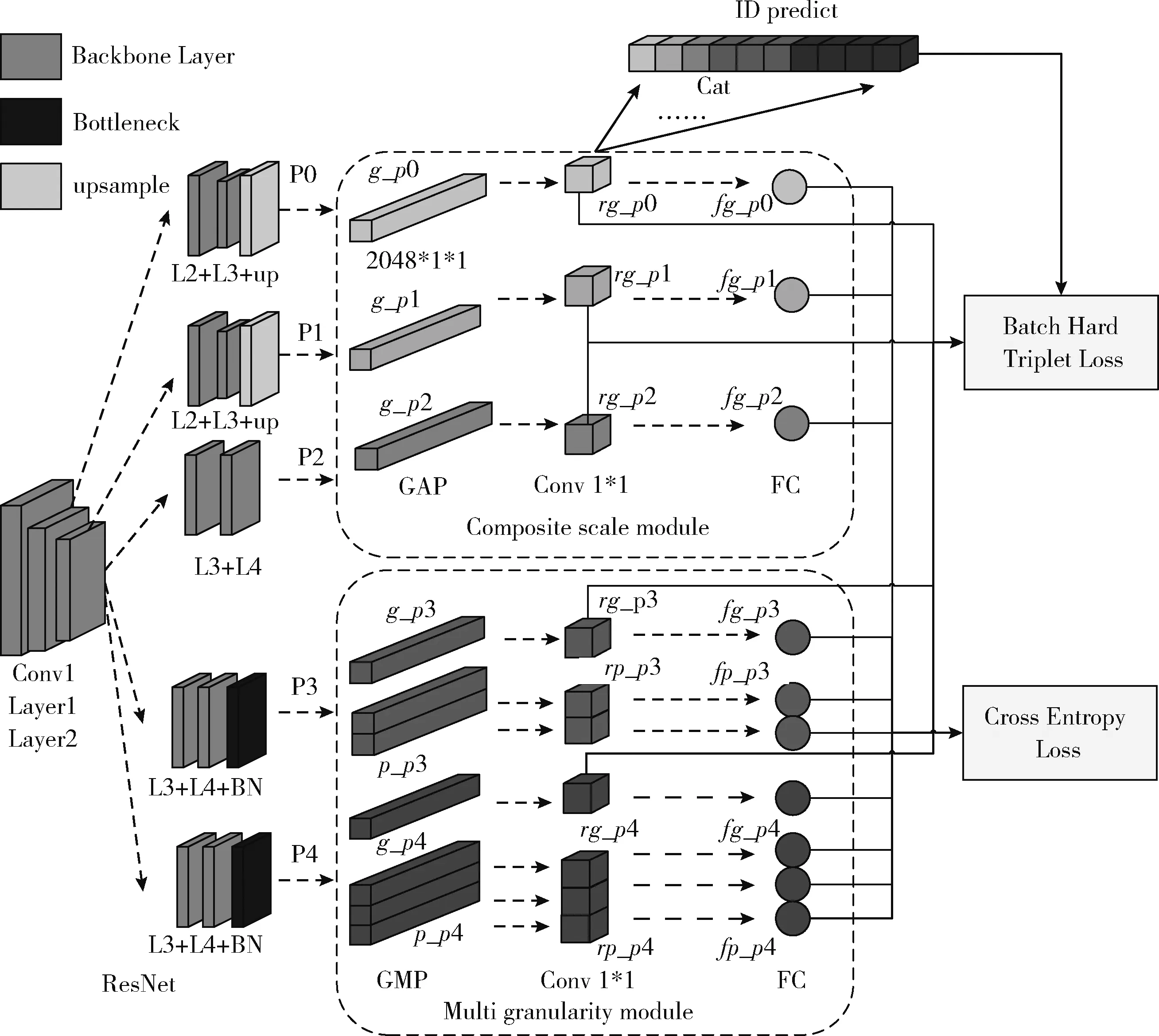
圖1 行人重識別總體架構
為了深度提取更多行人特征,本文的基礎網絡采用ResNet50網絡的前5層,即Conv1至Layer4,復合尺度模塊的分支P0,聯合Layer1、Layer2和上采樣層輸出特征,提取低層網絡的特征,作為高層特征的補充,然后通過GAP(global average pooling)將特征降為2048×1×1大小,然后經過1×1卷積、批量歸一化、全連接等操作,得到最終的特征表示fg_p0。分支P1與分支P2與P0類似,不同的是,分支P1特征來自于Layer2、Layer3和上采樣層,分支P2特征來自于Layer3和Layer4,實現了不同尺度的特征提取。
為了通過空間注意力機制捕捉到網絡多通道之間的關系,避免細微特征的遺漏,多粒度模塊的分支P3由Layer3、Layer4和Bottleneck層組成,通過GAP和GMP(global max pooling)將提取后的特征分為大小為2048×1×1的g_p3和大小為2048×2×1的p_p3,然后經過1×1卷積、批量歸一化、全連接等操作,得到最終的特征表示fg_p3和fg_p0。分支P4的特征信息與分支P3相同,區別在于GAP和GMP后分為2048×1×1大小的g_p4和2048×3×1的p_p4。在conv1×1卷積后,將rg_p0至rg_p4所有特征連接起來,用于用戶ID預測,同時利用批次難樣本三元組損失[14](batch hard triplet loss)和交叉熵損失函數(cross entropy loss)對全局特征和細粒度特征進行聯合訓練,使得各個分支聯合學習,提高網絡泛化能力。
1.2 復合尺度模塊
復合尺度模型[15]是指對輸入圖像的不同深度層次的采樣,通常多尺度下的粒度包含的特征信息也會不一樣,一般而言,在細粒度特征圖譜中能看到更多的顯著細節,在粗粒度采樣中能看到特征的趨勢性。特征金字塔通過利用一組不同分辨率圖像提取特征,每個層級都能提取到不同尺度特征表示,且特征表示的語義信息較多。
復合尺度模塊從ResNet50網絡的不同深度進行多次采樣,其中包括Layer2層、Layer3層以及Layer4層,然后將不同尺度的特征分別進行粗粒度提取和細粒度劃分或其它等操作,最后將通過不同尺度的特征信息融合,實現網絡對信息的最大化利用。由表1可以看出,不同分支的輸入大小不同,由于卷積核和感受野的大小不同,會形成尺度不同的特征圖,在復合尺度模塊通過上采樣層將維度統一為2018×H×W,后再進行其它操作。

表1 網絡不同分支參數
1.3 多粒度模塊
在提取行人特征時,可以分為粗粒度全局特征和細粒度局部特征[9],粗粒度模塊可以捕獲行人的全局特征,通過身上最顯著的特征信息,可以區分不同行人的身份。但是在復雜的場景中,僅利用粗粒度信息是很難達到行人重識別的目的,在粗粒度層面,很多細粒度的特征被忽略,因此,為了更深度全面地挖掘行人的特征,一些研究者通過將人體語義進行分割對齊,計算語義之間的距離,從而判斷語義的類間相似性。分塊策略又名軟分割策略,是指通過全局池化的方法將特征圖橫向分為幾個模塊,PCB模型通過將人體特征橫向切割成6部分,HPM[16](horizontal pyramid matching)模型將特征圖橫向分為8個部分,本文利用軟分割策略,由表1可知,將行人特征圖片分為一級粗粒度、二級粒度和三級粒度,粗粒度特征與細粒度特征相結合,更全面地挖掘信息并保留表征力強的特征。多粒度模塊如圖2所示。

圖2 多粒度模塊
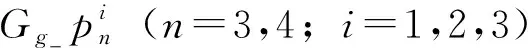
1.4 損失函數
目前交叉熵損失函數和三元組損失函數廣泛的應用于分類問題和度量學習中,在深度reID領域中,交叉熵損失函數和三元組損失函數常應用于基于特征學習和度量學習的模型方法中。在全局特征提取過程中,使用交叉熵損失函數訓練網絡,而在基于細粒度的部分特征網絡中,為了避免因為背景干擾和遮擋導致等原因的粒度不對齊問題,使用交叉熵損失函數,從而更好地擬合網絡模型并且避免無意義的訓練過程。交叉熵損失函數如式(1)所示
(1)
式中:C為類別數目,Wk表示行人重識別網絡W的第k行參數,fi是第i個樣本的特征表示,yi是第i個樣本的所屬類別,b為矩陣的偏移項。
三元組損失函數常應用于度量學習,在深度行人重識別任務中,三元組損失函數能解決“類間相似、類內差異”的問題,但是存在著收斂速度慢,容易過擬合的問題,因此針對這種情況,使用批次難樣本三元組損失函數TriHard既能夠保留三元組損失函數的特性,也能夠從多個維度約束網絡,提高效率,達到良好的訓練效果。
批次難樣本三元組損失函數的數學表達式為

(2)
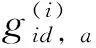
最終的損失函數是由以上兩者中損失函數進行組合,表達式為
LTotal=λ1LSoftmax+λ2LTriHard
(3)
式中:λ1和λ2分別為交叉熵損失函數和批次難樣本損失函數系數。
2 實驗結果與分析
2.1 實驗環境
本文實驗所采用的硬件平臺和軟件環境如下,操作系統為Ubuntu 18.04,CPU為Intel?CoreTMi5-7500 Processor,GPU為NVIDIA TITAN XP-16 GB,深度學習框架為Pytorch 1.2,Python版本為3.6.8。用于訓練和測試的輸入圖像大小為384×128,基本數據增強方法包括隨機擦除、Dropout等,優化器是Adam,在訓練過程中,P=8,K=16,BatchSize為128,迭代次數為1000,在訓練期間采用Warmup策略,并且采取端到端的訓練方式。模型的主要評估指標包括Rank@k(k=1,3,5,10) 和mAP(mean average precision)。
2.2 實驗數據集
本文實驗分別采取了在目前行人重識別領域的3個主流公開數據庫上進行模型實驗的有效性驗證,分別是Market-1501數據集、DukeMTMC-reID數據集和CUHK03-detected數據集。
Market-1501數據集[17]由6個攝像頭拍攝,共含1501位行人、32 668個行人矩陣框,其中訓練集有751人,12 936張行人圖像;測試集有750人,9732張行人圖像,以及3368張查詢圖像。
DukeMTMC-reID數據集[18]由8個攝像頭拍攝,共含1812位行人,36 411張行人矩陣圖片,其中訓練集有702人,116 522張圖像;測試集有702人,117 661張圖像。
CUHK03-detected數據集[19]是在中國香港大學校園采集的大型數據集,由10個攝像頭共同拍攝,覆蓋多個時段。其中,訓練集767個行人,7365張行人圖片;測試集700個行人,5223張圖片;1400張查詢圖片,剩下的11 188張行人圖片作為Gallery圖庫。
2.3 評價指標
行人重識別研究普遍利用平均精確均值(mAP)和首中準確率(Rank@1)兩種評價指標反應網絡的精準度。
平均精確均值可以反映模型在收到Query請求后,返回的正確檢索結果在返回列表中的排名,可以全面衡量行人重識別模型的性能,如式(4)所示
(4)
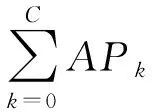
Rank@n表示模型返回列表中n張圖片中屬于目標類別的概率,首中準確率(Rank@1)表示查詢結果中排名第一的圖像為目標類別的概率。
2.4 實驗結果與結果仿真
2.4.1 實驗結果
本次實驗主要在3大主流數據集CUHK03-detected、DukeMTMC-reID 和Market-1501上進行實驗測試,圖3為模型在3大數據集上的結果。其中關于損失函數,出于“首先確定行人的身份問題,再進行細節的確認和特征辨別”的思想考慮,因此實驗環境中損失函數的參數設置為λ1=1和λ2=2。
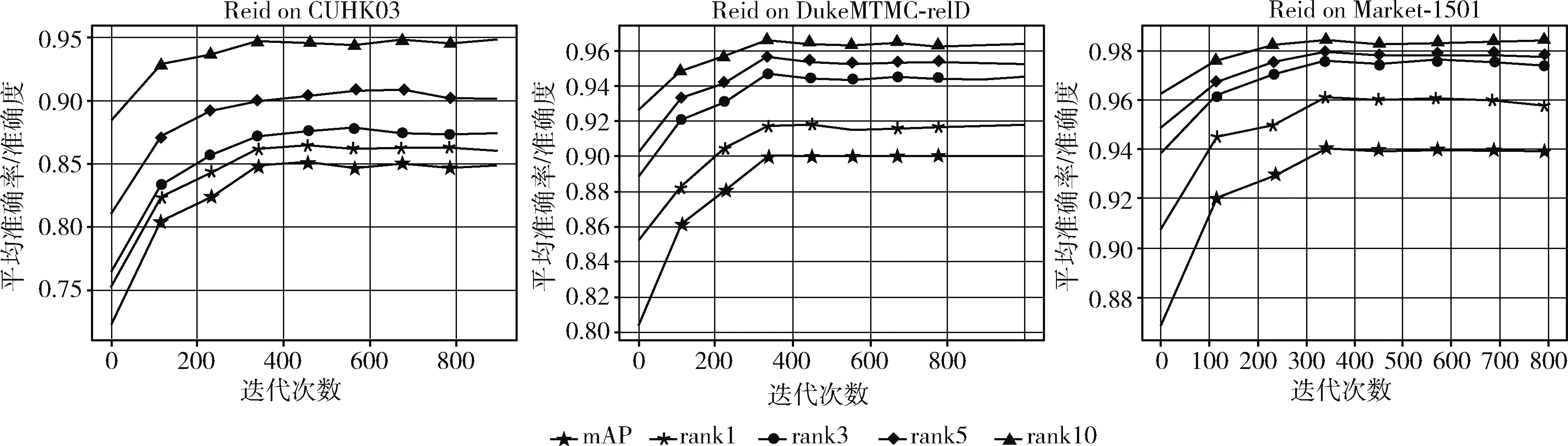
圖3 算法在數據集上的性能表現
實驗結果由圖3可以發現,在CUHK03-detected數據集上,Rank@1=85.24%,Rank@3=87.57%,Rank@5=90.36%,Rank@10=94.57%,平均準確率mAP=86.48%。在DukeMTMC-reID數據集上,Rank@1=91.89%,Rank@3=94.48%,Rank@5=95.20%,Rank@10=96.36%,平均準確率mAP=90.11%。在Market-1501數據集上,Rank@1=96.21%,Rank@3=97.60%,Rank@5=97.86%,Rank@10=98.53%,平均準確率mAP=94.12%。
2.4.2 消融實驗
本算法模型主要分為3個部分,即多尺度模型、多粒度模型和聯合部分,為了探討不同部分對于算法模型識別率的影響,實驗分別對多尺度模型和多粒度模型存在的必要性做了驗證,結果見表2~表4。其中,RK表示re-ranking技巧,是指基于k階導數編碼的方式,計算出行人圖像特征的杰卡德距離,然后將圖片的馬氏距離與杰卡德距離加權求和得到最終的結果,對需要識別測試的圖庫中的圖片進行重新排序,從而提升性能指標。
由表2~表4實驗結果可以發現,與基礎網絡ResNet50相比,復合尺度模塊、多粒度模塊以及聯合特征對行人重識別的效果有所提升。
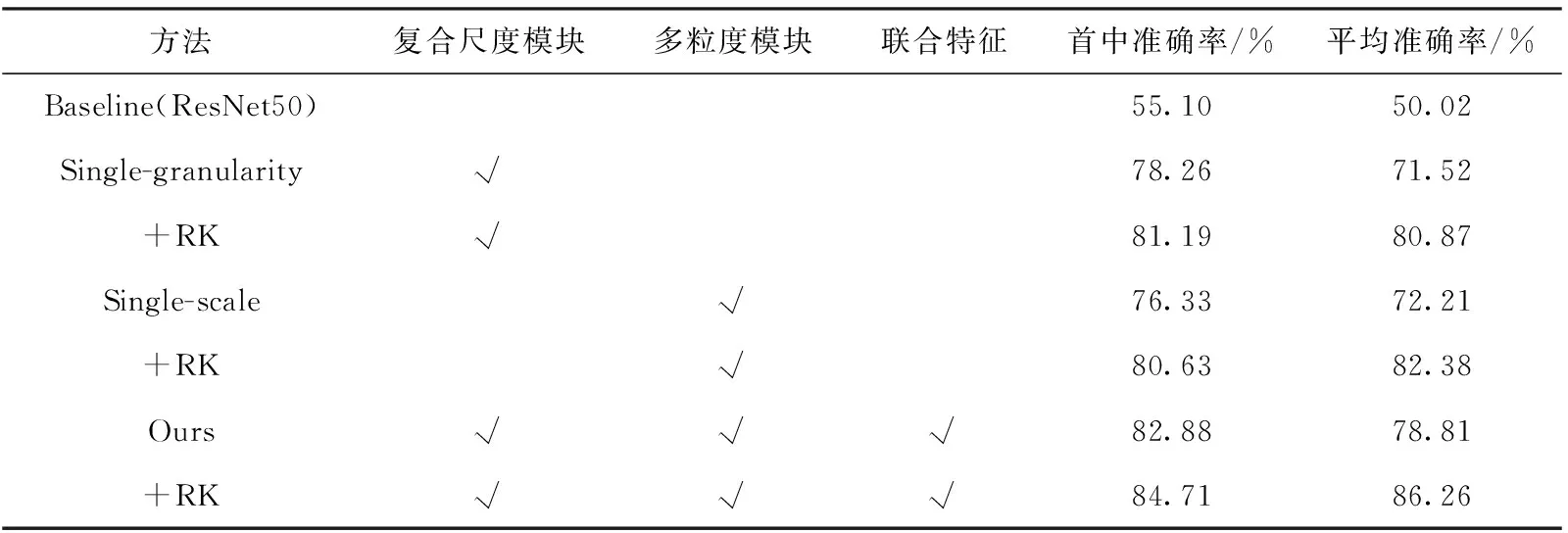
表2 CUHK03-detected數據集的消融實驗結果
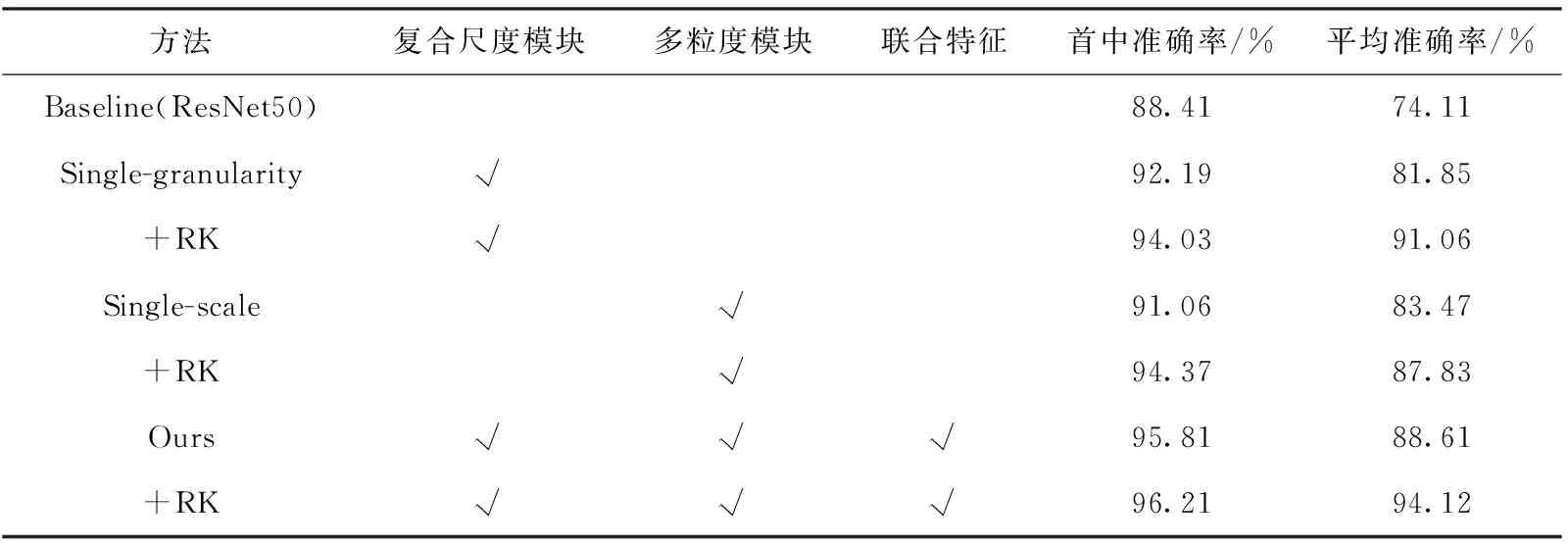
表4 Market-1501數據集的消融實驗結果
在CUHK03-detected數據集上,通過表2可以發現,在rank@1和mAP指標上,與baseline相比,復合尺度模塊分別提升了20.16%和21.50%,多粒度模塊分別提升了21.23%和22.19%。本文模型與baseline模型相比,rank@1和mAP分別提升了27.78%和28.79%,同時利用reran-king技巧,使效果再度提高1.83%和7.45%,最終達到了84.71%和86.26%,因此可以看出reranking技巧提升效果明顯。
在DukeMTMC-reID數據集上,通過表3可以發現,在rank@1和mAP指標上,與baseline相比,復合尺度模塊分別提升了5.52%和3.24%,多粒度模塊分別提升了5.19%和9.64%。本文模型與baseline模型相比,rank@1和mAP分別提升了6.23%和10.24%,同時利用reranking技巧,使效果再度提高2.35%和11.15%,最終達到了91.89%和91.19%。
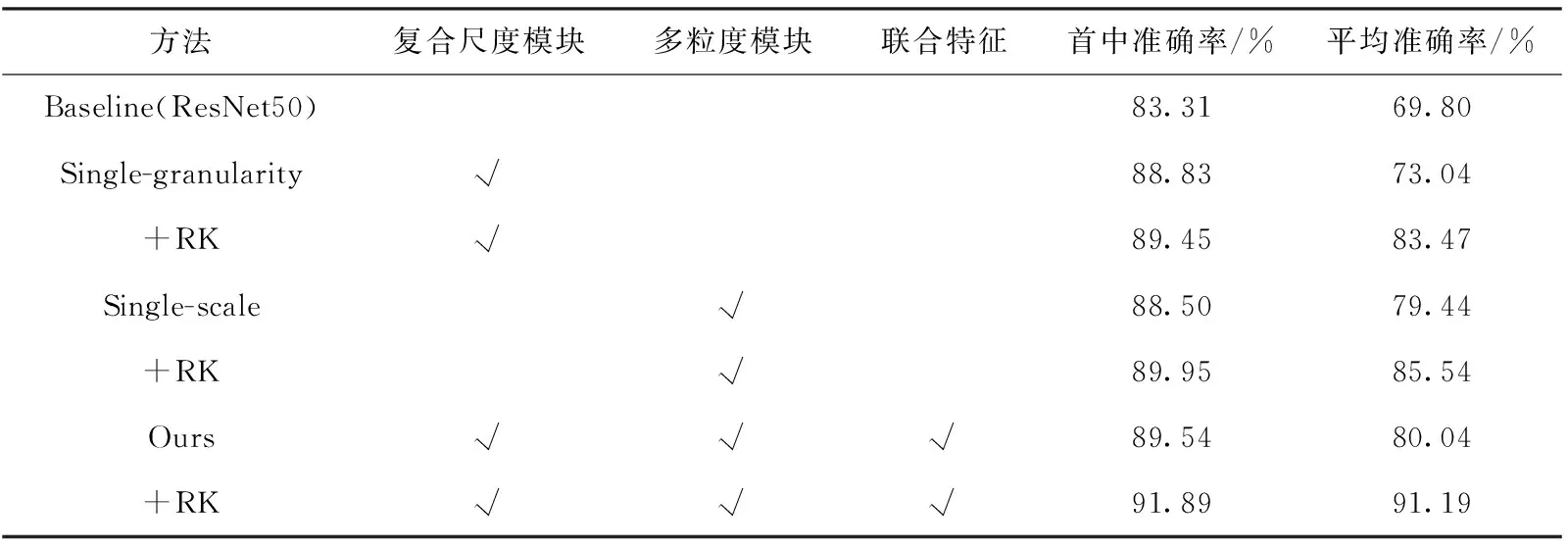
表3 DukeMTMC-reID數據集的消融實驗結果
通過表4可以發現,與baseline相比,多粒度模塊和單尺度模塊對實驗效果有所提升,在rank@1和mAP指標上,復合尺度模塊分別提升了3.75%和7.74%,多粒度模塊分別提升了2.65%和9.36%。本文模型與baseline模型相比,rank@1和mAP分別提升了7.40%和14.50%,同時利用reranking技巧,使效果達到了96.21%和94.12%。
2.4.3 實驗結構討論
本模型所選用的基礎骨干模型為ResNet,初始的參數權重是在imageNet上預訓練過的,為了驗證本Backbone的性能,實驗選用ResNet家族性能較為優越出眾的變體網絡SE-ResNeXt50[20]作為基礎網絡進行對比實驗,同時P3和P4分支的BottleNeck替換成SE-ResNeXt BottleNeck模塊,由于SE-ResNeXt50網絡參數較多,擬合難度較大,因此在實驗部分迭代次數為1500。
由消融實驗部分可知,多粒度模型存在具有其必要性,但是分塊策略的具體數量需要確定,因此為了探究實驗中采用的軟分割數目的有效性,在多粒度模塊中進行粒度的測試實驗,鑒于ReID深度學習領域,經典方法PCB和HPM不同分割策略的出色性能表現,本文也對6等分和8等分策略進行了驗證,P3和P4分支的分別采用了“1-2-3”等分粒度、“1-2-4”等分粒度、“1-3-4”等分粒度、“1-6”等分粒度和“1-8”等分粒度,其中“1-6”和“1-8”粒度的劃分實驗,取消了P4分支,只保留P0至P3分支,同時,“1-2-3”等分策略即為ResNet50實驗結果,因此不再贅述。
由表5可以發現,在Market-1501數據集上,首先對于不同的Backbone網絡,本模型采用的ResNet和SE-ResNeXt50對比,可以看到ResNet50網絡具有良好的性能表現,而在分類任務中性能優越的SE-ResNeXt50出現了精度下降的現象,rank@1和mAP相較于ResNet50分別下降3.85%和0.84%,具體分析可能是如下原因:①網絡較為深入,難以進行訓練;②數據集信息較少,在SE block中壓縮操作中丟失部分特征信息;③網絡模型復雜,參數量較多,對不同的特征學習分類,出現了過擬合現象。同時由于SE-ResNeXt50網絡的大型架構和參數計算,使得網絡訓練時間較長,迭代次數也比ResNet50多較多。同時,在水平劃分粒度實驗中可以發現,對于多分支多粒度網絡,當深層的輸出特征使用較多的分塊策略時,效果往往也有所提升,而對于分支較少的細粒度模型而言,往往是較大的分塊策略使得平均準確率較高,而較多的分塊會破壞細粒度特征原有的語義信息。綜上,考慮速度與精度問題,本文最終選擇Backbone為ResNet50、分塊策略為“1-2-3”的組織架構。

表5 Market-1501數據集上不同結構的實驗結果
2.4.4 實驗結果可視化
為了驗證本模型中的復合尺度模塊和整體算法的有效性,對網絡最后提取的特征圖進行可視化處理,可視化實驗選取了3大數據集中的圖片,通過通道像素值絕對值相加[21]的辦法,最終得到原始圖像、基線方法和本文的可視化結果,由于本文網絡為多分支結構,因此可視化采用信息量較大的P3分支的粗粒度特征,高層映射為ResNet50網絡的最終輸出特征。實驗結果如圖4所示。

圖4 可視化的特征激活圖像
由圖4可以發現,由于圖像存在的清晰與模糊問題,基線方法在模糊的圖片上,網絡的注意力集中在某一區域,并非全局特征,因此會遺漏很多重要的表征信息,而在較為清晰的圖像上,基線方法表現的比非清晰圖像更具有全局性,但是本文方法無論是在模糊圖像還是清晰圖像,都關注到了全局特征,并且不放過細節和不受環境干擾,將行人圖像提取的較為完整。
本實驗將最終測試評估結果可視化,如圖5所示,左側為查詢行人圖像,右側為Gallery圖庫中檢測到的匹配圖像,白色框表示查詢出錯,ID不為同一人。由圖5可以發現,匹配的行人圖像準確率較高,模型的識別效果較好,在錯誤的識別分類中,Gallery庫中存在與Query圖像較為相似的穿著打扮,如相同顏色的衣服和款式,這同時也說明,細粒度模塊的存在使網絡不僅注意到了全局特征,也注意到了局部信息的表征效果。因此本模型具有較高的準確率和有效性。

圖5 行人重識別效果可視圖
2.4.5 與主流算法比較
為了驗證本算法的有效性,將本文算法與當前幾種主流算法識別性能進行比較,如表6所示,這些對照方法的網絡參數均為最優值,對照組包括OSNet、PCB等經典的深度學習算法,同時包括最新的Top-DB-Net、OGNet和CBN模型等。

表6 本文算法與主流算法評價指標比較/%
由表6可發現,在CUHK03-detected數據集上,與最新的算法OGNet相比,rank@1提高了22.28%,mAP提高了24.41%,與經典細粒度算法MGN雖然rank@1只有0.78%的提升,但是在mAP方面卻提高了18.21%,與最新的Top-DB-Net相比,rank@1和mAP分別提升了16.08%和12.81%;在DukeMTMC-reID數據集上,與經典分塊策略模型的PCB相比,rank@1提高了7.84%,mAP提高了13.94%,與最新的CBN相比,rank@1提高了7.04%,mAP提高了12.74%;由于在Market-1501數據集上,大量的算法使得性能達到了飽和,但是本算法與分塊策略模型HPM相比,rank@1仍提高了1.61%,mAP提高了5.91%。因此,本文所提算法具有較高的精確度,并在目前主流算法中有一定的優勢。
3 結束語
本文提出了一種基于復合尺度與多粒度聯合特征的行人重識別算法。利用復合尺度模塊提取不同深度的全局特征,通過多粒度模塊將復合尺度的全局特征進行多粒度劃分,使得網絡能夠在不同的粒度中進行區域的顯著特征提取,利用不同尺度信息補充了單一粒度信息的不完整性,最后對粗粒度語義信息進行全局平均池化和細粒度語義信息全局最大池化,以增強特征的判斷力。針對損失函數,利用批次難樣本三元組損失函數進行樣本約束,有效地解決身份丟失問題。通過不同的數據集實驗,說明本文方法具有良好的泛化性以及較強的識別能力。接下來的工作是探索本方法在跨模態領域中的研究,進一步提高精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
