車載雙目視覺動態級聯修正實時立體匹配網絡
2023-01-14 14:48:40何國豪翟涌龔建偉王羽純張曦
智能系統學報 2022年6期
何國豪,翟涌,龔建偉,,王羽純,張曦
(1.北京理工大學 機械與車輛學院,北京 100081;2.北京理工大學 重慶創新中心,重慶 401120)
隨著智能駕駛技術的快速發展,車用視覺傳感器及其數據處理方法也得到了廣泛的關注。與單目相機相比,在沒有其他傳感器輔助的情況下,雙目相機也可以獲取環境的深度信息。所以雙目視覺相關技術也得到快速發展。
從雙目立體圖像獲取環境深度信息的關鍵步驟是視差估計,也稱為立體匹配。雙目立體匹配需要解決的關鍵問題是如何對左右兩目圖像進行特征提取并進行相似性匹配。正確的相似特征匹配才能帶來正確的視差與深度計算結果。傳統的立體匹配算法,例如圖割 (graph cuts,GC)[1]、區塊匹配(block matching,BM)、半全局匹配(semi-global matching,SGM)、半全局區塊匹配(semi-global block matching,SGBM)[2]遵循匹配代價計算、匹配代價聚合、視差計算和視差優化四步進行相似特征的搜索與匹配。雖然不需要大量的運算資源,但大多需要較長的運行時間,且無法得到理想的結果[3],匹配空洞較多。
隨著卷積神經網絡(convolutional neural networks,CNNs)的發展,部分學者發現使用卷積核計算匹配代價比人造代價函數計算的匹配代價更準確[4],于是開始出現使用CNN 計算圖像的相似性,以及計算每像素點視差大小的方法,如匹配代價卷積(MC-CNN)[5],半全局匹配網絡(SGMNet)[6]。但這些方法僅僅是用CNN 網絡替換了傳統方法的代價計算與聚合步驟,仍需進行圖像后處理才能得到視差輸出結果[7],所以匹配空洞仍然存在[8]。
為了獲取稠密的立體匹配結果,減少匹配空洞,近來端到端的學習網絡開始應用到立體匹配方法中。GC-Net[9]是第一個端到端的立體匹配深度學習網絡,該網絡使用了一個3D 的編碼-解碼器完成立體匹配任務。PSM-Net[10]應用了一個緊湊沙漏狀的全3D 卷積網絡來得到最終的視差圖。GA-Net[3]對GC-Net 進行了改進,GA-Net 在3D 卷積階段集成了傳統SGBM 匹配算法結果的特征圖。以上的方法都有較深的3D 卷積核或者大量3D 特征融合計算,要求配以高性能硬件才能達到想要的效率,否則需要較長的運算時間。為了減輕計算負擔,一些網絡開始加入了替代3D 卷積網絡的結構,例如AA-Net[11]和AARTStereo[12],但又出現了特征提取效果差、特征代價融合不完備、場景通用性不強等問題。
針對上述學習網絡層數深、計算量大、特征融合效果不佳、場景通用性不強等問題,本文針對車載實時需求,提出了一種端到端的級聯多尺度融合與動態融合的雙目立體匹配網絡。
首先采用了一個高效的三階段降采樣特征提取模塊,該模塊使用了基于全局深度卷積的可學習注意力模塊和可學習空間金字塔池化模塊,不但可以在較淺的網絡中提供一個理想的多尺度融合特征,還能對每個分辨率尺度的特征圖提供可學習的融合權重,從網絡深度與卷積參數數量上緩解了運算負擔,加速了運算過程。之后,借鑒了AART-Stereo 對于3D 卷積網絡的替代方案,采用多階段分辨率輸出結果進行融合,使用低分辨率結果優化高分辨率的輸出,并且還計算了每一階段的動態視差代價以完成3 像素點誤差修正,用于最后的視差回歸。最后,在公開KITTI 立體匹配數據集[13]上完成了對本文方法的驗證。
1 相關技術
1.1 視差估計
視差指的是兩張圖像上相關聯的兩個像素點在像素坐標系下的位置差異。如果對圖像對進行預處理,那么位置差異就指在水平方向上的像素坐標差值。如果在圖像對的左目圖像 (u,v)處找到一個像素點,與它相對應的點在右圖中的(u-d,v)處找到,就稱視差值是d,隨即可以由fb/d得到深度值Z,其中f是焦距,b是雙目相機基線長度。視差估計就是對圖像對的左圖上所有像素點進行視差計算,得到一張稠密視差圖的過程,該過程也稱為立體匹配。
1.2 高效CNN 模塊
分組卷積[14]是減少每秒浮點運算次數(floating-point operations per second,FLOPS)并增加卷積網絡效率的最常用的方法。對于一組輸入輸出,若將輸入卷積通道分為G組,參加運算的卷積核總參數量將會減少到原先參數量的1/G。在分組卷積中,若輸入通道數C等于輸出通道數N也等于分組數G,則可將這樣的分組卷積操作稱為深度可分離卷積[15](depth-wise separable convolution,DS-Conv)。深度可分離卷積是一個精度與速度共存的卷積方法,雖然參與運算的卷積核參數減少了,但是通常會獲得比常規卷積更優秀的結果。
最近的研究發現,卷積神經網絡每一層的卷積核有內在的關聯性,意味著可以將該層內的所有卷積核用一個到兩個卷積核配以一定的權重大小來描述[16]。藍圖分離卷積(blueprint separable convolution,BS-Conv)就采用這樣的思路。在本文提出的特征提取模塊中就運用藍圖分離卷積完成特征提取,顯著減少了運算參數量與運行時間。
1.3 注意力模塊
注意力模塊已經廣泛運用在了卷積神經網絡中,特別是擁有大量層數的網絡結構。網絡結構越深,提取到的特征相比原始輸入就越抽象,越難找到原始輸入中感興趣的區域,這也是過深的網絡結構反而會出現網絡性能下降的原因。注意力模塊通常是一個加入先驗知識或者從網絡較淺層提取出的一個權重分布,將該模塊應用到網絡的深處,可以強化網絡在深層處的有效特征表示,同時抑制無效特征和噪聲。這樣能夠強化網絡的魯棒性,使網絡有更強的場景通用性以及更高的運算準確率[17]。
1.4 全局特征融合
為了拓展學習網絡的感知域,獲得多尺度的特征圖,在特征提取框架中做代價與特征融合是至關重要的。池化操作是最常用的降采樣與特征融合操作,不同的池化核大小和池化核步長可以獲得不同尺度的特征圖。空間金字塔池化模塊(spatial pyramid pooling,SPP)對輸入特征圖采用不同大小的池化核,進行池化操作之后,又將獲得的所有特征圖上采樣到相同大小,完成多尺度特征融合以得到多尺度特征圖。在通道端,全局平均池化(global average pooling,GAP)可以將每一個輸入通道的特征進行融合,獲取一個基于通道的權重圖。
但是,不管是空間金字塔池化模塊還是全局平均池化模塊都是不可學習的,所以無法對不同尺度或不同通道特征的重點性進行區分。本文針對這種情況,給予池化模塊可學習的參數。在上文提到的深度可分離卷積操作中,若卷積核的大小等于輸入特征圖的大小,則稱為全局深度卷積(global depth-wise convolution,GDC)。此類卷積可以看作全局加權池化,其輸出大小與全局平均池化相同;不同的是,全局深度卷積會賦予每個輸入通道一個可學習的卷積核,對不同通道特征的重要程度進行區分[18]。
2 立體匹配網絡
根據雙目立體匹配需要解決的問題,如準確地進行特征選擇與匹配等,以及本文提出的應用場景,結合上文介紹的當下較先進的模塊,本文提出了一個具有淺層高效的多尺度特征提取模塊、輕量化3D 卷積網絡以及多尺度動態融合模塊的立體匹配網絡,網絡結構如圖1 所示,圖中?代表動態視差計算操作,⊕代表像素逐點相加。
2.1 特征提取模塊
目前著眼于實時性的立體匹配網絡,通常因為采用過分簡化的特征提取模塊,導致無法提供有效的高質量特征圖。因為本文想利用不同分辨率尺度的特征圖來完成視差回歸,所以一個良好的特征提取框架是十分必要的。若僅僅進行簡單的降采樣以滿足后續視差回歸所需的輸入大小,不但無法節省運算時間,反而會造成精度丟失。
基于這樣的想法,本文將語義分割領域以及光流領域常用的空間金字塔池化模塊加入到了特征提取網絡中。不同的是,本文為該模塊輸出的不同尺度特征圖都賦予了可學習的參數,不但拓展了網絡的感知域,還提供了參與融合的多尺度特征圖所對應的權重,增強了場景通用性。為了減小運算負荷以及規避梯度消失問題,對本文提出的可學習空間金字塔池化模塊進行了測試,最終選定僅僅在第一階段降采樣時采用該模塊。本文提出的網絡一共有三階段降采樣,獲取了對應到原圖大小的1/4、1/8 和1/16 的特征圖。該可學習空間金字塔池化模塊均為2D 池化操作,模塊中僅僅加入了少量的卷積核來引入可學習參數。整個特征提取框架中的卷積操作都采用藍圖可分離卷積進行,所以運行耗時短。本文的特征提取模塊如圖2(a)所示,并與幾款當下較先進的立體匹配網絡的特征提取模塊做了比較。
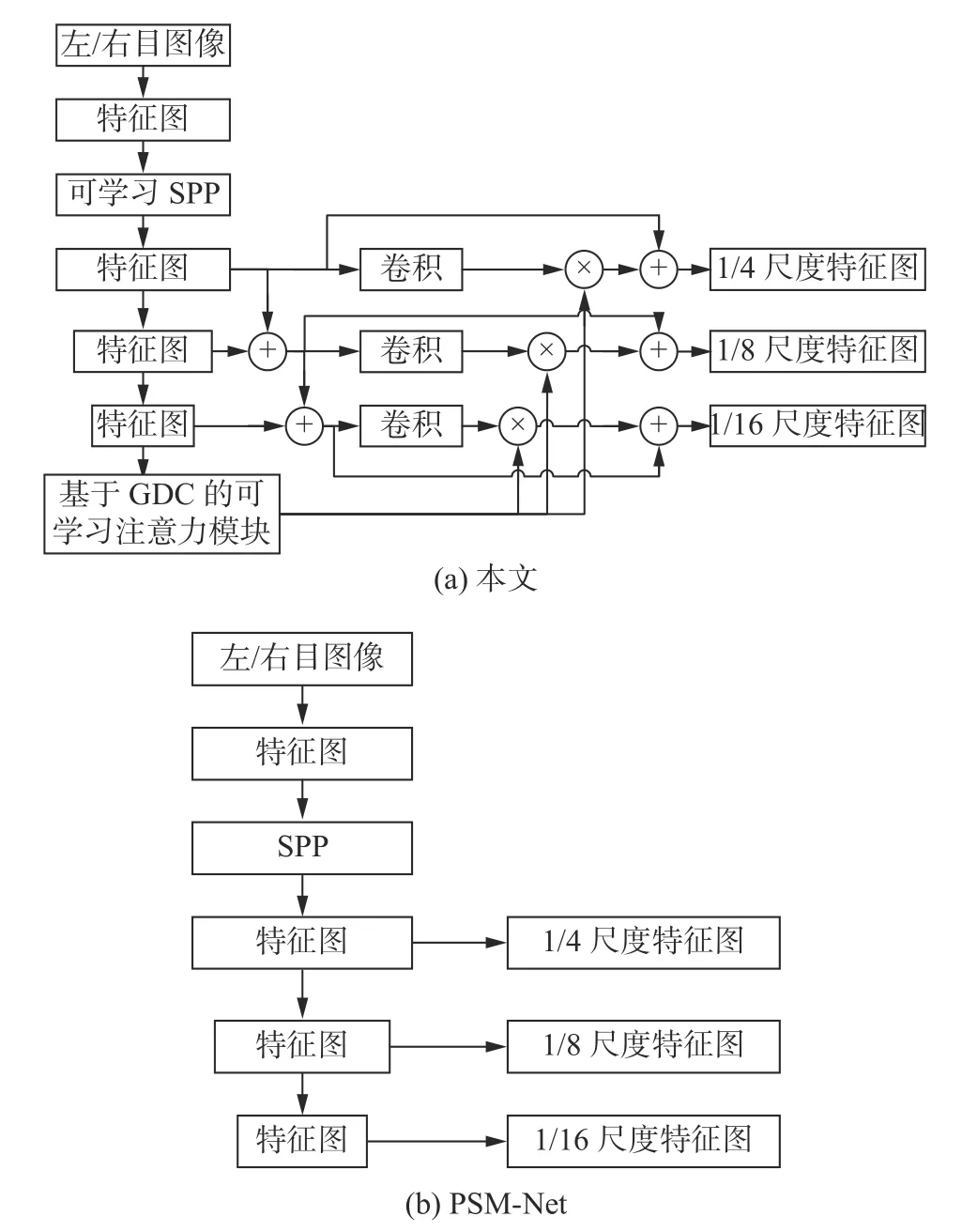
圖2 特征提取模塊Fig.2 Feature extraction module
為了可以充分發揮空間金字塔池化模塊的性能,本文將經過該模塊之后的每一層特征圖都逐點相加到了下層的特征圖上。在后續測試中可以發現,圖2(c)的AART-Stereo 網絡由于過分簡化了特征提取步驟,盡管有特征聚合模塊(圖中FA),卻仍然會導致較差的結果。
2.2 GDC 注意力模塊
本文受到全局深度卷積和注意力模塊功能的啟發[19],提出了一個基于全局深度卷積的通道端可學習注意力模塊,如圖3 所示。

圖3 注意力模塊Fig.3 Attention module
圖3 中,AVG 代表全局池化。第三階段降采樣的特征圖經過第一次卷積后對每通道進行全局池化,將每個通道的特征圖處理到1 ×1大小后,再采用1 ×1大小的卷積核進行全局深度卷積。由上文所述的全局深度卷積的特性,即輸入通道數等于輸出通道數等于卷積分組數,可以給該注意力模塊上每個維度一個可學習的權重參數,用來體現不同通道特征的重要性。注意力模塊隨后被分別施加在3 個階段的降采樣當中,用來體現每一階段降采樣結果的重要程度。
經上述處理之后,得到一C×1×1大小的向量,簡化去除第二維即等價變換成C×1大小的一維向量。因為本文想要將該向量應用到每一階段的降采樣當中,所以C需要滿足C=C1+C2+C3,其中Ci是第i階段降采樣后的通道個數,每一階段的降采樣結果只融合注意力模塊內分割出的對應部分。
三階段降采樣特征提取結果將采用式(1)進行重新整合:
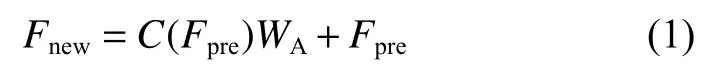
式中:Fpre代表融合注意力模塊之前的特征圖;Fnew是融合注意力模塊之后的特征圖;C(*)代表卷積操作;WA為由注意力模塊分割獲得的權重。由于WA的維度與Fpre的通道數相同,式(1)中的乘法操作是由Fpre每個通道的張量乘以WA內對應索引上的權重完成的,給該通道上的所有值賦予一個權重。
2.3 動態代價與特征融合的3D 卷積模塊
本文提出了一個級聯特征融合與動態修正代價融合的方法,對特征提取階段得到的不同尺度特征圖進行級聯融合,級聯方向從最小分辨率的特征圖到最大分辨率的特征圖。在底層,由于沒有更小尺度的特征提取結果,匹配代價張量通過插值法進行回歸構造,完成視差結果的上采樣。流程如圖4(a)所示。
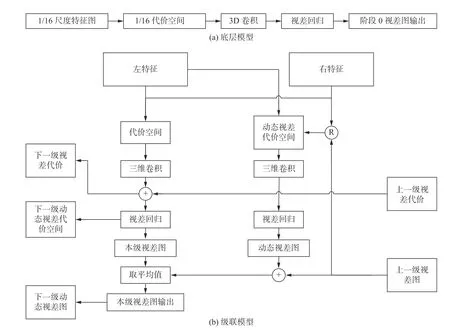
圖4 新型的 3D 卷積網絡級聯模型Fig.4 Novel 3D-CNN with cascade fusion module
非底層則使用級聯模型,首先采用與底層相同的方法得到完整的視差結果。與底層結構不同的是:1)上層將采用下層獲得的視差結果進行均值融合,如圖4(b)所示;2)由于在視差估計任務中,通常采用3 像素點誤差(3-pix err),即用估計的視差值大小與真值大小相差3 個像素坐標以上的像素點所占的比例來評判算法的性能,所以本文將左右圖特征以及下層得到的視差特征融合成一個代價張量,并采用一維向量[-2,-1,0,1,2]來處理該代價張量,獲取動態視差代價張量,再進行插值回歸,如圖4(b)所示。這樣的操作將得到一個5 通道的動態視差補償結果,每個通道張量的寬、高與原始圖像大小相同。張量上每一點的值代表著該點動態視差補償大小取[-2,-1,0,1,2]其中某個值的概率。
本文將動態視差補償結果與下層的視差輸出結果進行疊加融合,可以修正得到一個新的視差輸出,來達到修正視差輸出的目的。最后,將動態處理后得到的輸出以及之前均值融合并插值回歸得到的該層原始輸出進行逐點相加再求均值,就得到了本層的最終輸出。
2.4 視差回歸
當采用端到端的卷積神經網絡進行立體匹配任務時,一定會在得到最終視差結果之前得到一個降采樣的代價張量,通常這個代價張量如式(2)所示:

式中:S指的代價張量的大小;B為批大小;C為通道數;D為視差等級,即人為規定的視差上限值;W與H分別代表張量的寬與高。
式(2)中第三維D表示視差維度,共192 維,對D維的所有代價張量做softmax 操作后,Di對應的Wi×Hi張量上某點的數值大小將對應原圖中該像素點視差大小為i的概率值。由此可以得到完整視差圖:
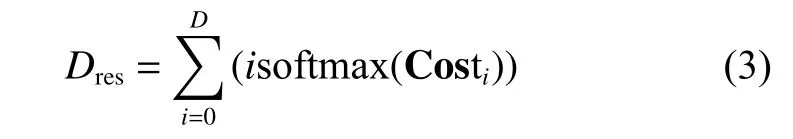
式中 Costi代表每一個視差值的代價張量。動態視差補償圖的回歸方式與式(3)回歸方法同理。
3 實驗與結果分析
本文在KITTI 2015 Stereo[13]數據集上完成了對上文所提出的網絡中的模塊的驗證與測試,網絡總體效果如圖5 所示,圖中(a)與(b)兩組圖中的上、中、下3 個部分分別代表網絡輸出結果圖,真值圖以及誤點圖。本文網絡輸出結果的平均3 像素點誤差率為3.92%,AART-Stereo 網絡輸出結果的平均3 像素點誤差為7.85%。
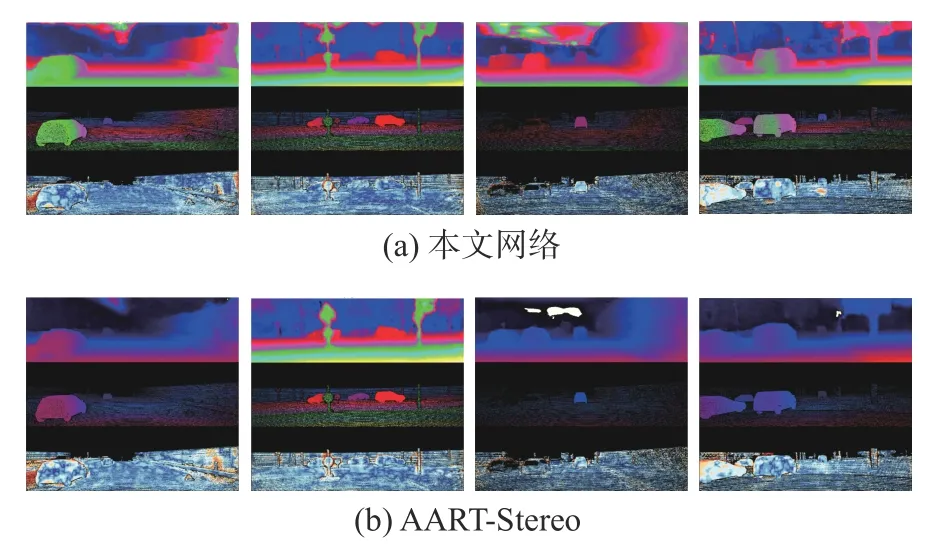
圖5 網絡輸出結果樣例Fig.5 Output example of a network
3.1 數據集
KITTI 是真實城市環境的數據集,通過一輛家庭乘用轎車在城市道路下行駛采集數據并處理后得到。與電腦合成的數據集(如SceneFlow Stereo 數據集[20])相比,KITTI 數據集包含了更多的光照變化、明暗對比、過曝光等在現實世界中使用視覺傳感器常出現的場景[21]。鑒于本文的目標是提出一個能夠在智能駕駛領域使用的實時立體匹配網絡,所以KITTI 數據集是十分合適的一個選擇。
KITTI 2015 Stereo 數據集包含了200 對大小為376×1 240 的用于訓練的RGB 雙目圖像對。相對應的,每組圖像對都有一個稀疏的視差真值,該真值通過激光雷達獲取并經過后處理得到。數據集中還有另外200 對RGB 雙目圖像對用作測試,這些圖像對沒有對應的真值,測試結果可以上傳到KITTI 官方進行評估。
3.2 實驗設置
數據集與運行環境:訓練集、驗證集以及測試集的比例為4∶1∶4。沒有特殊說明時,網絡運行在配置為RTX 2 060 GPU,8 GB 內存,AMD 銳龍4800H 的電腦上。
圖像:輸入為經過預處理的雙目相機左右目圖像,即縱向像素坐標已經對齊。為了滿足網絡運行要求,減輕運算負擔,在圖像送入網絡前對其進行
裁剪:由于本文的網絡采用三階段降采樣來輸出3 個不同分辨率尺度的結果,且底層的大小是原始輸入的1/16,所以經裁剪的圖像長寬大小必須是16 的整數倍。最終本文選擇使用256×512 大小的圖像用作網絡輸入。
訓練基本參數:本文在數據集上進行300 個周期的訓練,每個周期中采用1 的批大小進行訓練。
優化器:對于回歸問題來說,Adam 優化器是最常用的優化器之一,它對訓練過程中的學習率可以自適應地調整并且可以有效防止過擬合。本文根據Adam優化器作者的建議設置Adam優化器的參數β1=0.9,β2=0.999,weight decay=0.0001[22]。同時,由于發現有的作者會在使用Adam 優化器的同時采用手動定義每個循環學習率的方式而不是使用自適應調整,本文會在后文對這兩種方式進行比較,并加入常用的SGD 優化器進行對比。
損失函數:由于本文的方法通過三階段不同分辨率尺度進行插值回歸并輸出,所以需要將三階段的輸出損失相加來定義最終的損失大小。本文在默認Adam 優化器下對均方誤差損失(MSE)、L1損失、平滑L1損失進行了比較,總損失函數為
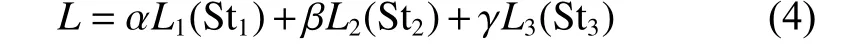
式中:Sti(i=1,2,3)代表第i尺度的輸出;Li是第i尺度所采用的損失函數。在計算總損失函數大小時,每一種損失函數不與其他損失函數共用,即在一種計算方法中,Li的類別相同。為了強調每一階段輸出的重要程度,本文將每階段的輸出值做了加權處理,其中 α、β、γ取值分別是0.33、0.66、1。整網運算結果如表1 所示。

表1 損失函數測試Table 1 Loss function test %
需要明確的是,盡管Huber 損失與平滑L1損失[23]通常被認定為相同的損失函數(δ通常取值為1),但是Pytorch 對這兩種損失函數有不同的實現:
Huber 損失:
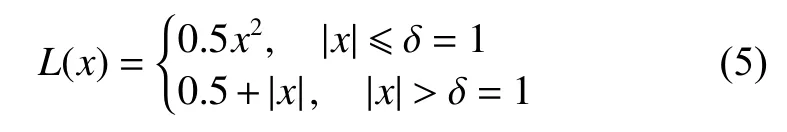
平滑L1損失:
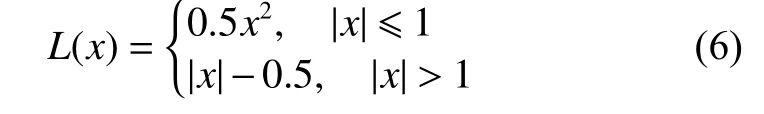
顯然,Huber 損失與平滑L1損失是MSE 與L1損失的折中方案,其收斂速度快于L1損失,慢于MSE。根據研究,Huber 損失與平滑L1損失可以顯著地緩解在回歸問題中網絡過擬合的情況,并且收斂速度也能夠接受[24]。
學習率:Adam 優化器作者推薦初始學習率為0.001。如上文所述,Adam 優化器可以在訓練過程中對學習率進行自適應的調整,但部分作者仍采用自定義學習率的方式完成優化。本部分將對這兩種情況進行對比,并且加入最常用的SGD優化器進行自定義學習率的比較。自定義學習率:在前100 個周期中,采用0.001 的學習率;在101~200 個周期中,采用0.000 5 的學習率;在201~300 個周期中,采用0.000 05 的學習率。結果如表2 所示。

表2 學習率測試Table 2 Learning rate test %
可以看出,對Adam 優化器手動設置學習率很難使最終結果達到理想效果,效果不如簡單的SGD 算法,而Adam 自適應調整的特性可以讓模型更快地收斂到更精準的位置。
3.3 網絡結構缺省性能測試與分析
如前文所述,本文在第一階段降采樣中使用了可學習空間金字塔池化模塊,并且在后文的3D特征融合中也加入了復雜的動態融合機制。這些模塊會引入相應數量的計算參數,可能會影響網絡的整體表現,如運行時間、結果精度等。本文在同一環境下對比了未加入本文模塊的網絡,以及加入了本文模塊的網絡,評估了網絡運算結果的3 像素點誤差。結果如表3 和圖5 所示。
表3 中Ours-1 代表使用一次可學習金字塔池化,Ours-3 代表使用3 階段可學習金字塔池化。從表3 可以注意到,在第一階段降采樣加入了可學習空間金字塔池化模塊之后,網絡整體運算精度得到大幅度提升。保留該模塊,再加入本文設計的輕量化3D 特征融合與動態修正模塊,精度又出現了大幅度提升。鑒于可學習空間金字塔池化模塊的良好性能,嘗試對3 個階段的降采樣都采用該模塊進行多尺度特征提取與融合。最終發現,由于參數引進過多,層數過深,并且除藍圖可分離卷積以外又缺乏處理較深網絡的其他結構,導致精度出現了大幅衰減。
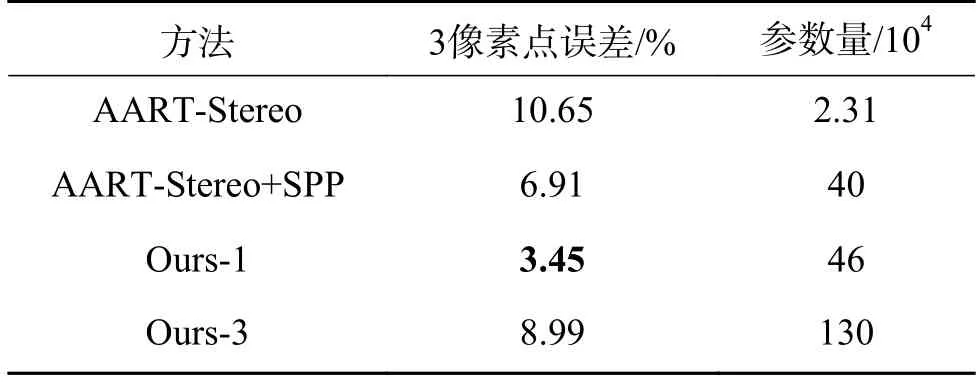
表3 不同網絡的精度與參數量測試Table 3 Accuracy and parameter quantity of different networks
3.4 時間對比
在3.3 節中,對網絡的整體運算精度進行了測驗,發現本文提出的網絡有大幅度的精度提升。但是由于引入了額外的運算參數,運行時間可能出現增加。本節比較了本文提出的網絡與一些相似的端到端立體匹配網絡的運算時長,主要對比了在特征提取、視差回歸以及網絡整體所消耗的時間。所有的測試都以相同的訓練環境與參數設定運行在Nvidia RTX 2 060 GPU 上,結果如表4所示。
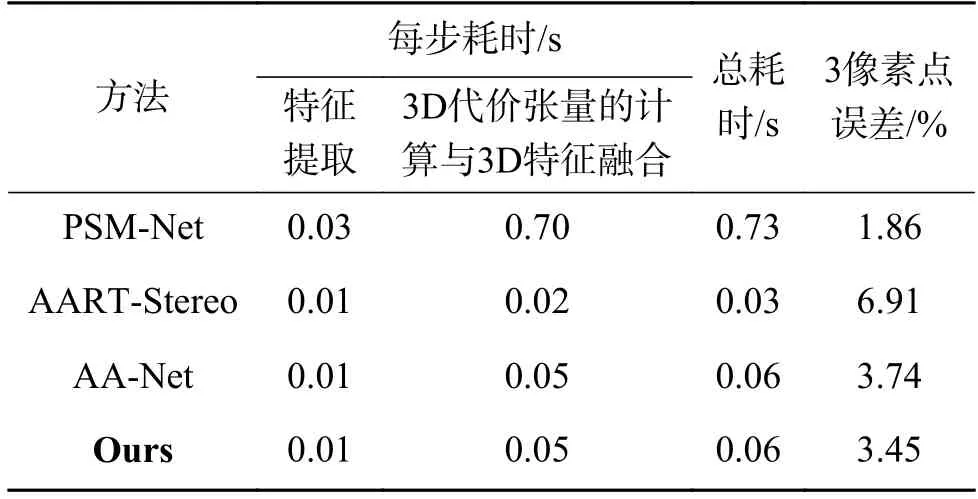
表4 耗時測試Table 4 Time consumption test
可以發現,每種方法耗時最多的步驟都是3D 代價張量的計算與3D 特征融合,因為該操作涉及3D 卷積網絡的計算。PSM-Net 使用了一個全3D 卷積網絡的緊湊沙漏結構完成代價張量的計算與特征融合,所以運算時間較長,但特征融合完備,運算精度高。本文提出的網絡采用動態視差補償機制以及多分辨率尺度級聯互補機制,可以在不損失大量精度的情況下替代部分3D 卷積網絡,大幅度減少了運算參數量,加速了運算過程。
3.5 KITTI 數據集結果分析
本文在KITTI Stereo 2015 數據集上對該數據集提供的用于測試的200 組RGB 圖像對進行了測試驗證,結果如表5 所示。
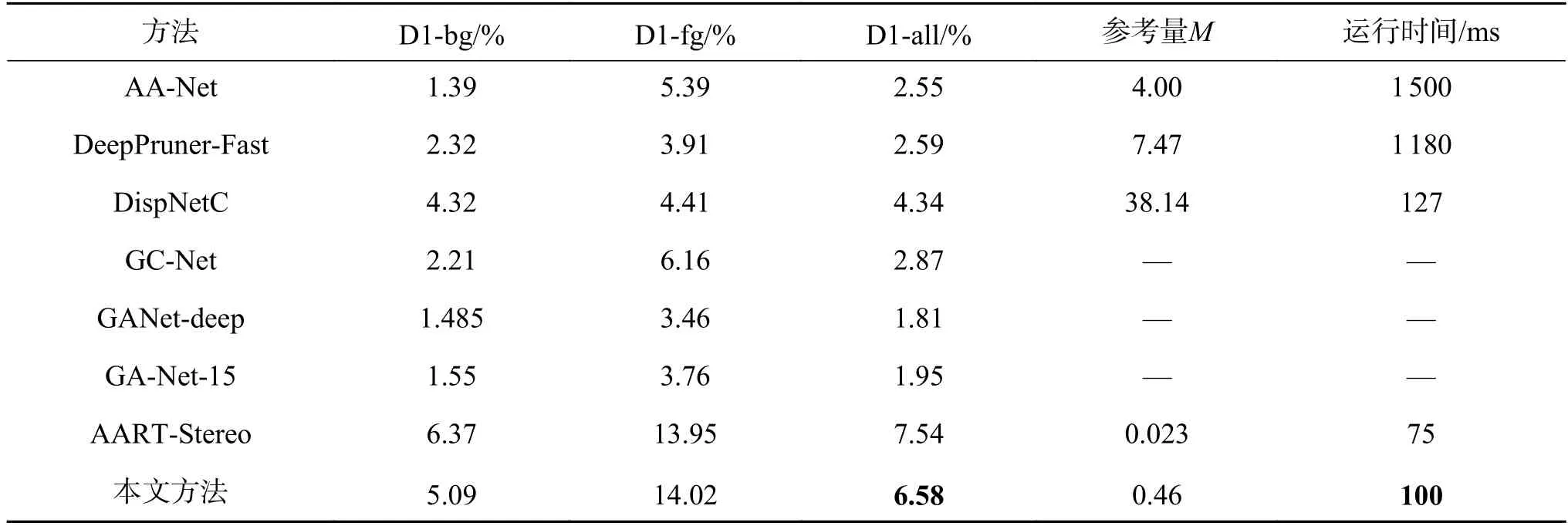
表5 不同網絡在KITTI 數據集上測試Table 5 KITTI stereo 2015 benchmark results
測試結果顯示,通過改進特征提取方案,增加動態視差修復與多尺度結果融合后,本文提出的網絡總3 像素點誤差為6.58%,這個精度與當下較先進的網絡相當,但需求的運算量更小。表中提到的AA-Net 與DeepPruner-Fast[25]也都可以滿足運行的實時性要求(<0.1 s/f),但根據Chang 等的研究[12],這些網絡的實時性都需要高性能計算硬件的保證,無法運行在如NVIDIA Jetson TX2 等車載運算設備上,難以滿足車載需求。本文也將常見的網絡部署到TX2 設備上進行驗證,運行結果如表5 時間一欄所示。表5 中未給出運行時長的方法意味著對應網絡將無法在TX2 計算環境中運行。由表5 可知,本文提出的網絡由于擁有較少的參數,可以部署在NVIDIA Jetson TX2 上進行實時地運行。
4 結束語
本文提出了一個動態級聯修正的實時立體匹配網絡。該網絡融合了三階段降采樣特征提取框架、基于全局深度卷積的注意力模塊以及3D 動態融合與修正模塊,可以在短時間內提供高質量多尺度特征圖,并區分各尺度重要性,同時完成實時的特征融合與輸出修正以輸出最終的立體匹配結果。與其他模型相比,本文的模型有更少的參數量以及較高的準確率,可以在車用計算平臺上完成實時運算并滿足車載使用精度要求。在未來,我們將探索人類先驗知識在本文提出的網絡中的應用,在降低網絡計算復雜度的同時還可以強化網絡的效果,為車載深度估計提供新的技術手段。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
