融合人格特征的概率推薦模型
2023-01-17 09:32:20沈鐵孫龍付曉東劉利軍
計算機與生活 2023年1期
沈鐵孫龍,付曉東,+,岳 昆,劉 驪,劉利軍
1.云南省計算機應用技術重點實驗室(昆明理工大學),昆明650600
2.昆明理工大學信息工程與自動化學院,昆明650500
3.云南大學信息學院,昆明650504
近年來,互聯網的蓬勃發展致使網絡信息量呈指數級增長,網絡大數據給人們帶來嚴重的信息過載問題,導致用戶難以準確獲取與其需求相符合的信息。推薦系統能夠根據用戶歷史行為數據,分析其潛在偏好,為用戶提供個性化推薦,成為緩解信息過載問題的有效手段。目前,推薦系統已應用于電子商務(如Amazon、阿里巴巴)、社交網絡(如Facebook、Twitter)、電影推薦(如Netflix)、音樂推薦(如Last.fm)、新聞推薦(如GoogleNews、今日頭條等)等領域。
現有推薦系統主要是基于歷史信息的推薦,以用戶評分矩陣作為主要的用戶偏好信息[1]。用戶評分具有主觀性,不同用戶打分標準不同,進而不同用戶對同一商品的評分不可比較,導致推薦效果不佳[2-3]。同時用戶評分矩陣通常較為稀疏,而推薦系統模型期望稠密輸入,稀疏輸入帶來性能下降,因此現有推薦算法普遍面臨評分矩陣稀疏,難以分析提取用戶偏好的問題[2],也造成了實際推薦效果不佳。多數推薦平臺為用戶提供了交互接口,如點贊、評論等。在線評論是用戶對項目感受的具體反饋,這些反饋信息通常以非結構文本形式存在,合理分析用戶評論信息能夠對項目特征及用戶偏好進行精細刻畫。基于用戶評論、基于用戶隱式反饋信息的推薦算法在解決冷啟動、推薦準確性以及可解釋性等方面具有重要潛力[4]。然而當前受到文本信息挖掘技術、用戶潛在特征建模技術等方面的限制,基于評論信息分析的推薦算法進展并不明顯[3]。
目前的研究廣泛認為基于模型的推薦系統推薦效果優于基于歷史信息的推薦系統推薦效果,特別是在稀疏數據上效果更好[5]。以模型為基礎的協同過濾推薦算法需分析提取“用戶-項目”特征矩陣以進行用戶推薦。用戶特征不同直接導致用戶偏好不同,但以模型為基礎的協同過濾推薦算法僅考慮分析提取影響項目特征的關鍵因素而未考慮分析提取影響用戶特征的重要因素,這類傳統模型往往將用戶潛在特征向量隨機初始化,并賦予一個假定的正態分布,導致這些推薦系統模型中沒有任何一項數據變化可以對用戶潛在特征建模結果產生直接影響。另外基于用戶的推薦系統模型往往將用戶的評論、評分的信息直接近似作為用戶特征,傳統推薦系統中這些數據引用方式和這些數據本身不足以支撐獲取用戶的本質特征。這些特征的近似也不能滿足個性化推薦的需求。沒有對用戶本質特征的分析,推薦結果無法匹配用戶個性。用戶特征模型的不完整,同時也導致了冷啟動問題和數據稀疏問題,需要大量的用戶數據和歷史行為信息才能為用戶推薦滿意的項目[6]。
針對上述問題,提出一種融合人格特征提取的推薦算法。構建人格特征提取神經網絡,從評論信息中獲取人格特征進行用戶建模,將人格這種非結構數據轉換為結構數據。輸入用戶評論及評分信息,輸出用戶人格得分。人格是一種心理構造,可用于描述和解釋人類的行為。通過人格模型的引入,解決推薦系統“用戶-項目”模型面臨的用戶特征缺失問題,提取人格特征作為用戶本質特征,為個性化推薦系統的改進提供了新的思路。本文主要工作包括三方面:
(1)將人格這一心理學領域概念引入推薦系統,并將其作為影響用戶特征表示的主要因素進行用戶特征模型建模。
(2)設計人格提取神經網絡模型,用于獲取用戶評論中反映的BIG FIVE 人格得分。
(3)設計融合人格感知的協同學習框架,將用戶人格特征和項目的評論文本語義分析特征融合到概率推薦模型中,根據學習結果進行推薦,并在真實數據集上進行了全面的驗證。
1 相關工作
1.1 推薦系統模型
個性化推薦的目標是通過對影響用戶偏好的自身及外界因素進行分析建模,以獲取用戶潛在的興趣內容并推薦給用戶[7]。以所用方法來進行劃分,目前主流的推薦方法主要包括基于內容的推薦算法(contentbased recommender)[7]、協同過濾算法(collaborative filtering)[8]、混合推薦算法(hybrid recommender)[9]。
基于內容的推薦算法通過抽取各個項目的屬性特征,分析用戶歷史行為構建用戶對項目的偏好向量,然后計算用戶偏好向量與候選項目特征向量的相似性,向用戶推薦相似度高的項目。該方法特征提取困難,局限于文本資源推薦,很難挖掘用戶潛在興趣[3-4]。
基于協同過濾的推薦算法可分為兩個類別:基于內存的推薦(memory-based methods)與基于模型的推薦(model-based methods)[10]。其中基于內存的推薦僅僅將“用戶-項目”歷史評分記錄作為數據源,沒有利用用戶的上下文信息。研究發現僅僅依靠“用戶-項目”歷史評分記錄作為依據,在實際應用場景中其準確性與適用性都存在很大問題[11]。
基于模型的協同過濾推薦又可稱為隱語義模型(latent factor model)。使用統計和機器學習技術,從“用戶-項目”評分矩陣中分解出兩個低階矩陣,分別表示用戶和項目的隱藏特征矩陣,通過隱藏特征預測用戶評分[12-14]。已有多種模型被用于基于模型的協同過濾方法,如貝葉斯模型[15]、矩陣分解模型[10]、潛在語義分析模型[16]、深度學習模型[10]等。基于矩陣分解的方法,如SVD(singular value decomposition)[5]、NMF(non-negative matrix factorization)等,根據高維用戶-項目評分矩陣學習用戶、項目的低維向量表示,并將其用于推薦任務。此類方法在處理大規模數據時有良好表現。為了緩解協同過濾算法數據稀疏性和冷啟動問題,研究人員將深度學習模型引入推薦領域用于隱藏特征的學習。文獻[6]將2 層受限玻爾茲曼機(restricted Boltzmann machines,RBM)用于協同過濾,該文獻首次提出基于深度學習的協同過濾模型。文獻[10]利用用戶信息、歷史行為等多源異構數據,將深度神經網絡用于YouTube 視頻推薦系統的候選集生成模塊和精排模塊,推薦效果顯著提升。Google提出Wide&Deep 學習模型[17]用于手機APP 推薦,該模型聯合訓練一般的線性模型(wild)和多層感知機模型(deep),使其同時具有記憶能力和泛化能力。目前的研究廣泛認為基于模型的推薦結果優于基于歷史信息的推薦,特別是在稀疏數據上效果更好[18]。
1.2 推薦系統信息源
若以基于何種信息進行用戶推薦來劃分個性化推薦方法,可將個性化推薦算法分為基于評分的推薦算法、基于評論的推薦算法、融合評分及評論的推薦算法和利用其他歷史信息的推薦算法等。基于評分的推薦算法面臨數據稀疏、冷啟動等問題,近年來許多研究者將評論信息融入協同過濾算法解決上述問題。研究人員綜合考慮了評分信息以及評論信息,提出了一種矩陣分解推薦模型(probabilistic matrix factorization,PMF)[16]。該模型假設存在一個用戶特征矩陣和一個項目特征矩陣,通過概率模型方法求解出這兩個矩陣,并將兩個矩陣的乘積作為用戶的最終評分預測矩陣。但該模型未考慮造成用戶特征差異的影響因素,假設影響用戶特征的影響因素隨機,隨機初始化用戶特征參數。文獻[19]提出一種綜合考慮評論文本以及項目和用戶特征矩陣的模型。該模型在文獻[16]的基礎上使用卷積神經網絡將用戶對項目的評論文本特征向量與項目特征矩陣結合,從而提升了模型預測的準確率。
文獻[20]提出一個混合了自注意力機制和自編碼器的協同過濾推薦模型,通過基于物品的協同過濾實現來挖掘物品與物品之間的局部依賴關系,同時采用注意力網絡來為用戶不同的歷史交互物品和目標物品的相似度計算分配不同的權重。該方法采用注意力機制來分配不同相似度計算的權重,以獲得最終的推薦結果,可為推薦結果帶來一定效果提升,但使用的核心方法本質上依然是傳統的基于近鄰的協同過濾推薦方法,并未直接獲取到用戶特征這一直接影響推薦結果關鍵信息。文獻[21]采用一種融合序列的生成對抗網絡生成模型來重現用戶喜歡的項目序列,從而實現推薦,一定程度上緩解了傳統詞嵌入方法中相似項目向量之間的聯系不強的問題。文獻[22]從內容推薦入手,提出一個基于多層注意力表示的推薦模型,利用用戶屬性信息和歌曲的內容信息挖掘用戶對歌曲的偏好特征,利用注意力網絡提升了推薦性能。
上述研究在進行推薦時都假設影響用戶偏好的用戶特征的影響因子是隨機的,沒有考慮到有影響因子直接會對用戶偏好造成影響,往往采用獲取實際的推薦結果逆推的方式擬合這種影響,不利于解決冷啟動等推薦系統面臨的問題。這些研究僅考慮項目特征對推薦結果的影響,而未考慮不同用戶特征對推薦結果的影響,沒有對用戶特征進行表示,更沒有考慮引入人格、情感等作為用戶特征表示的影響因子。
1.3 人格與推薦系統
人格是一種持續伴隨著個體的行為及人際交互模式[7],在一段時間內它是穩定且可以預測的。相關研究[7-8]表明人格會影響個體的興趣以及偏好,研究顯示,人格與個體的偏好具有很強的關聯性。具有相同人格的個體可能具有相同的偏好以及行為模式[12],這為結合人格因素進行用戶建模及偏好預測工作提供了可能。人格模型的引入在四方面對推薦算法有促進作用[10,17,22]:(1)人格得分可直接用于用戶潛在特征的構建,有助于表示用戶特征;(2)心理學領域對BIG FIVE 人格特征模型進行過廣泛、深入的驗證[21],證明該模型確實可用于客觀、準確的人格表示,而人格因素直接對用戶偏好產生主要影響[7],將人格模型應用于推薦系統,能夠合理表征用戶偏好,為用戶做出合理、客觀的推薦;(3)BIG FIVE 五項人格特征得分包含了不同用戶間人格的豐富對比關系,利用多維度的對比關系能夠合理區分不同用戶的不同偏好取向,為用戶做出多樣性推薦;(4)通過人格模型將用戶的潛在特征聯系起來,能夠提升推薦系統推薦結果的可解釋性(人格相似的用戶更可能被推薦相同的項目)。人格不僅能反映個人行為,還會對人類偏好產生重要影響[5]。但人格這一重要數據在推薦系統的應用上存在兩個難點,導致當前人格推薦系統研究較少:(1)人格信息難以獲取,難以識別。文獻[9]提出一種基于性格(temperament)的建模模型,該模型根據Keirsey 理論[8]將信息空間劃分為32 個性格段。實驗結果表明,基于性格的信息過濾方法在準確率和有效性上均優于基于內容的信息過濾方法。文獻[10]提出一個基于人格的音樂推薦系統,該系統通過心理學揭示的人格特質與音樂偏好的聯系來進行音樂推薦。這些研究獲取人格特征的信息需求量遠遠大于推薦系統通常能夠提供的信息量。往往需要通過調查問卷等方式獲取人格特征信息,這些研究并未利用在線用戶評論文本中隱藏的豐富人格信息。(2)目前尚未有研究者建立一個將包括人格在內的情感數據應用于推薦系統建模的合理模型,如何將人格數據引入推薦系統模型并與推薦任務產生關聯是一個新的挑戰。
本文擬采用BIG FIVE 人格模型對推薦系統用戶特征進行刻畫。大五人格模型(BIG FIVE model)是現代心理學中描述最高級組織層次的五方面的人格特質,這五大人格特質構成了人的主要性格[5],它由五個基本特征組成:開放性(openness)、盡責性(conscientiousness)、外傾性(extraversion)、宜人性(agreeableness)、神經質性(neuroticism)[10]。在心理學實驗中每個人格特征由1~7 之間的實數評分確定。心理學研究發現,從個人性格發展的角度上來說,“BIG FIVE”人格特質通常處于長期穩定狀態,即使經歷重大人生事件,成人的性格特質也不會發生太大的變化[17]。“BIG FIVE”模型是一種已在心理學界被廣泛引用的人格模型,也是自20世紀80年代以來人格研究者們在人格描述模式上達成一致共識的最終成果[23]。人格特征數據的應用為推薦系統用戶建模提供了一個新的視野,它滿足作為推薦系統用戶表征數據的三個條件:(1)共同性。心理學研究[24]指出人格會影響個體的興趣以及偏好,人格與個體的偏好具有很強的關聯性。具有相同人格的個體可能具有相同的偏好以及行為模式。(2)特異性。在心理學實踐中[6],不同的BIG FIVE 人格特征常常作為不同對象心理特征的重要區分指標。(3)穩定性。相關心理學研究[7-8]表明人格是一種持續伴隨著個體的行為及人際交互模式,在一段時間內它是穩定且可以預測的。
由于人格因素直接影響人類偏好的重要特性,本文將人格模型用于用戶特征建模,補充推薦系統“用戶-項目”特征模型中缺失的用戶特征信息,同時增強項目特征提取性能。最后,本文通過理論分析與實驗驗證了方法的合理性和有效性。
2 融合人格特征的特征提取及推薦
2.1 模型框架
本文討論輸入不完整的評分矩陣R∈RN×M,以及用戶評論C和項目評論X,用提出的模型計算分析,輸出預測評分矩陣R*。
由于基于模型的協同過濾推薦系統中用戶特征建模的缺失,本文提出一種融合人格特征提取的推薦算法,根據用戶的評論信息及歷史行為信息,結合人格提取神經網絡提取用戶人格得分,作為用戶特征模型的主要影響因子;同時對項目的評論信息進行特征提取,作為項目特征模型的主要影響因子。結合提出的協同學習框架將用戶特征和項目特征整合到概率推薦模型中,向用戶推薦更符合其偏好的項目。
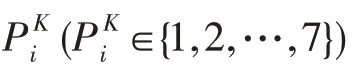

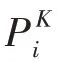
圖1 融合人格特征的概率矩陣模型Fig.1 Probability matrix model incorporating personality characteristics
2.2 基于深度學習的人格預測
為了解決文本中的人格發掘問題,目前大多數研究都聚焦于使用人為手段從文本中提取特征,將其添加到人格特征中[16]。這些人為設計的聯系往往是文本淺層特征的提取,并沒有直接從用戶評論文本本身獲取豐富的深層特征。因此需要設計模型對文本中體現的用戶人格進行提取。
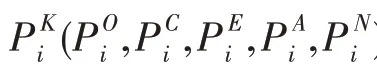
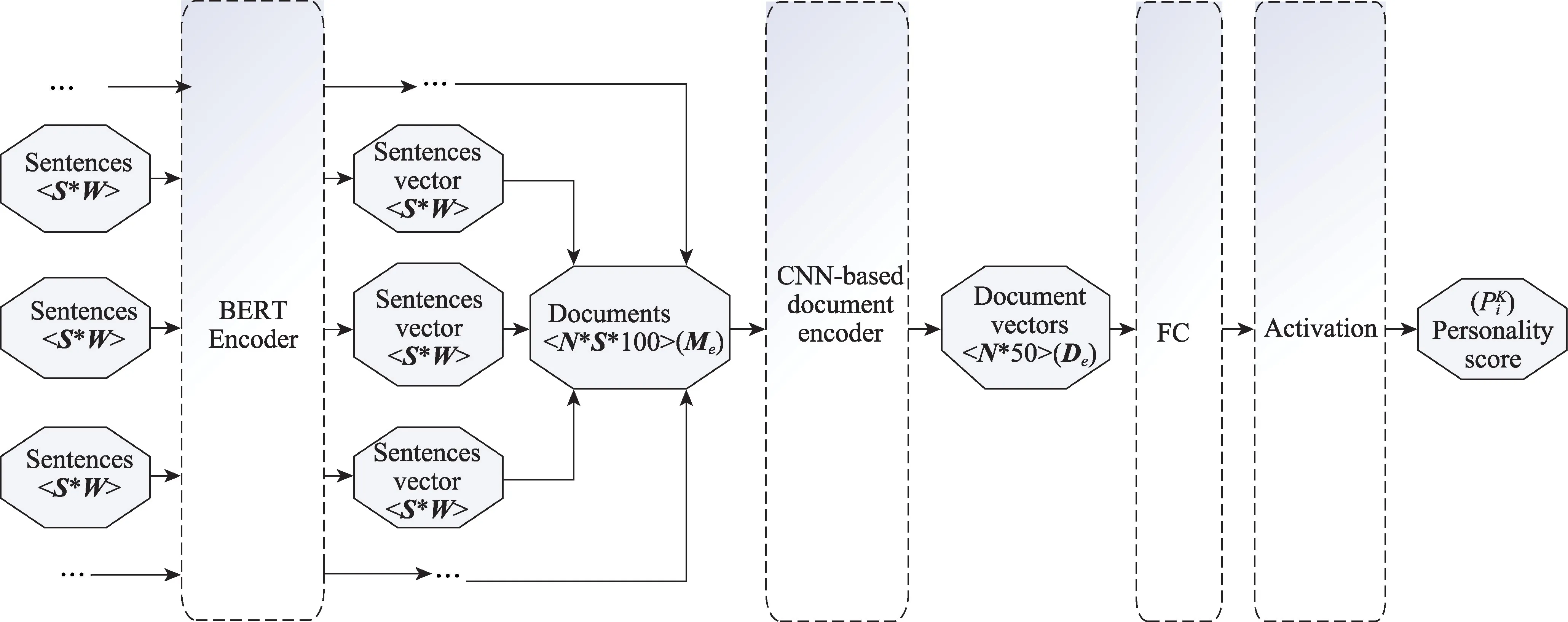
圖2 Personality-nn 神經網絡結構圖Fig.2 Personality neural network frame diagram
2.2.1 文本預處理
由于具有不同人格的用戶在使用標點符號、表情以及大小寫時有不同的使用習慣,不對這些特殊字符進行特殊處理。用戶常在一個單詞末尾使用多個重復的字符來加強情緒表達(例如“I’m happyy!”和“I’m happyyyy!”),并且重復數量不同可能會顯示不同人格傾向,在預處理過程中保留這些單詞,但如果重復字母數量過多則在后續的詞嵌入訓練中可能會被視為多個不同的單詞進而影響預測的準確度,因此設定一個英文單詞后面最多可以含有5個重復的字母,如果超出這個閾值,則最多保留5個重復字母。
2.2.2 詞嵌入
為了更好地對用戶評論所包含的深層語義信息進行建模,采用谷歌發布的BERT 模型進行文本詞嵌入,它用Transformer 的雙向編碼器表示。與其他語言表示模型不同,BERT 旨在通過聯合調節所有層中的上下文來預先訓練深度雙向表示。因此,預訓練的BERT 表示可以通過一個額外的輸出層進行微調,適用于問答任務和語言推理等任務,無需針對具體任務做大幅架構修改[10]。使用Google 官方的uncased_L-12_H-768_A-12 作為預訓練模型。使用personality 數據集進行訓練,personality 數據集包含了用戶ui的歷史評論數據xj以及心理學專家對其進行的BIG FIVE人格評估得分。加載personality 數據集中用戶評論數據X進行訓練。之后將同一個用戶的所有評論聚合成段落,構建詞嵌入矩陣Me。
2.2.3 對深層語義信息的有監督學習
與其他的情緒提取文本處理任務不同,用戶評論所顯示的人格信息受時間因素影響極小,在很長的時間序列(例如一年)內不會產生較大波動[7],并不適宜采用更有利于捕獲長期語義特征的RNN(循環神經網絡)模型。在捕獲短周期語義信息的任務中,CNN 模型比RNN 模型效果更好[12]。因此,本文提出一種基于CNN(卷積神經網絡)的段落編碼模型,將同一個用戶的所有評論通過該神經網絡進行編碼,模型如圖3 所示。該模型參考基于CNN 網絡的Iception 模型[13]設置,段落編碼網絡包含了4 個CNN模塊和一個池化模塊(MaxPooling),一個級聯層和一個全連接層。其中一個卷積模塊包含兩個卷積層,第一層分別含100 個大小為1 和大小為5 的卷積過濾器(Conv)。在第一個卷積層之上是批正則化層(batch nomalization)以及一個ReLU 函數激活層(ReLU activation)。第二個卷積層分別包含50 個大小為3 的卷積過濾器和50 個大小為5 的卷積過濾器。其中每個卷積核的步長都設置為1。之后將這5部分特征整合輸出到全連接層得到項目文本的最終向量表示矩陣De。
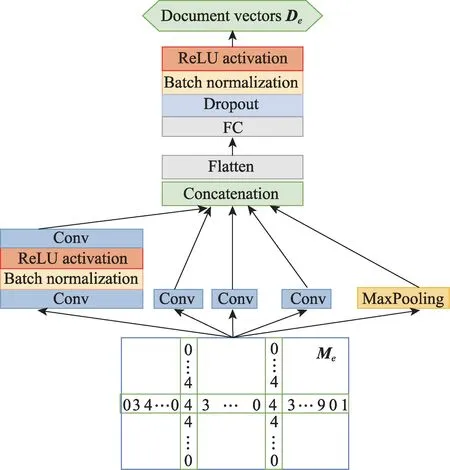
圖3 基于CNN 的段落編碼模型Fig.3 CNN-based document encoder
2.2.4 模型訓練及預測
本文使用均方誤差(mean square error,MSE)作為模型訓練的目標函數,公式如式(1)所示:
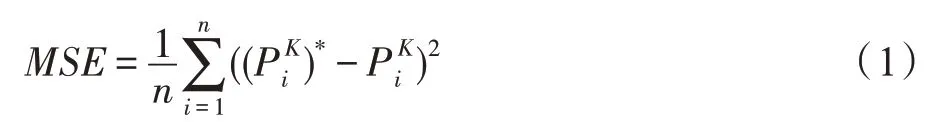
其中,n表示用戶總數,表示用戶第K項人格特征的預測得分(K∈{O,C,E,A,N}),表示用戶i第K項人格特征的真實得分。使用相同的網絡模型設置針對5 項人格得分訓練5 個神經網絡。
訓練完成后,從神經網絡模型中提取段落編碼模型的輸出作為每個用戶所有評論的最終深度語義信息特征向量。將這些特征輸入到常見的四種回歸模型中,從而預測用戶人格得分。
2.3 人格與文本向量的矩陣分解
2.3.1 Per-BERT MF 的概率模型
本小節設計了一個考慮人格和文本向量的矩陣分解模型(personality and BERT matrix factorization,Per-BERT MF)。圖1 展示了Per-BERT MF 的總體模型,該模型在進行用戶建模時考慮其評論文本的文本向量以及該用戶的人格得分。假設針對當前“用戶-特征”模型存在一個潛在用戶特征矩陣U∈R,以及一個潛在項目特征矩陣V∈R,當前任務是找到用戶和項目的潛在特征模型矩陣U以及V,它們的乘積(U)TV構成了預測的評分矩陣R*。
定義2所有用戶對項目的評分信息用R∈RN×M表示。
定義3用戶ui對所有項目的評論信息用ci(i=1,2,…,n) 表示。所有用戶評論的集合用C表示,即C={c1,c2,…,cn}。
定義4項目vj獲得的所有用戶評論信息用xj(j=1,2,…,m) 表示。所有項目獲得的評論集合用X表示,即X={x1,x2,…,xn}。
R與U、V滿足以下概率模型:
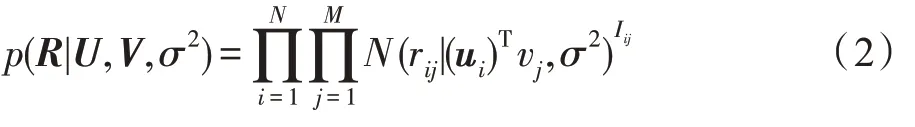
其中,N(x|μ,σ2)表示均值為μ,變量為σ2的高斯正態分布的概率密度函數。Iij是一個指示函數,當用戶對項目進行過評分時,Iij為1,否則為0。
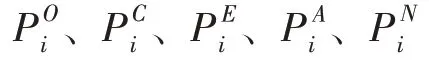

因此用戶潛在特征的條件概率分布模型如下:
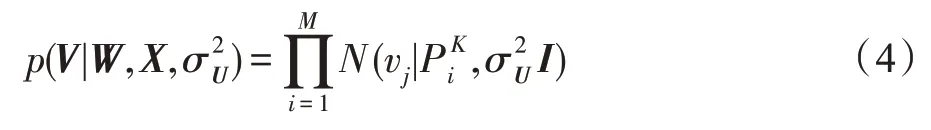
另外,一個項目的潛在特征模型由三部分組成:(1)使用BERT 模型,將vj的評論文本xj向量化作為內部權重矩陣W。(2)項目vj的評論文本xj。(3)高斯分布的噪聲參數。因此項目的潛在特征模型表示如下:

對于每一個W中的權重,使用均值為零的高斯分布作為先驗概率(這是最常用的先驗概率模型)。
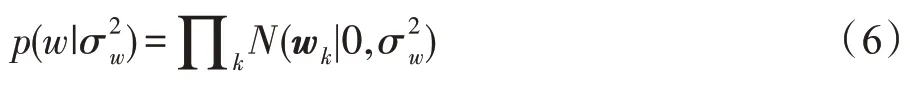
因此,項目潛在特征矩陣的概率模型表示如下:

2.3.2 模型最優化方法
使用最大后驗估計[22]將用戶潛在特征矩陣與項目潛在特征矩陣優化目標函數計算如下:
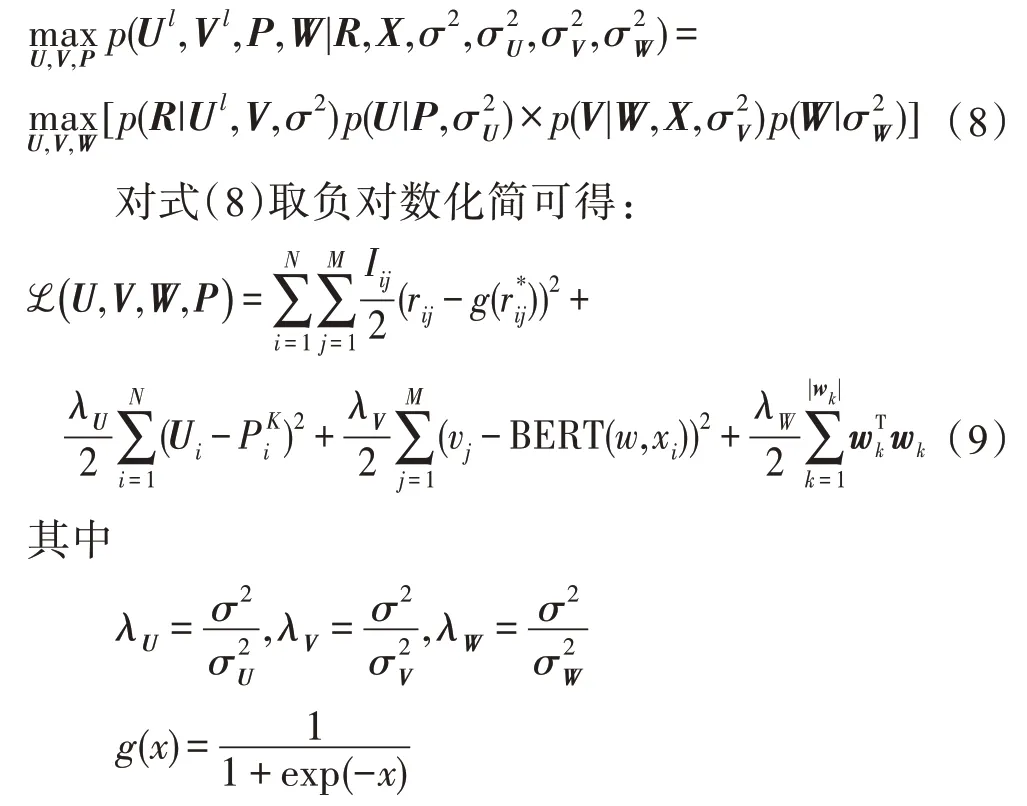
采用坐標下降法[23],優化潛在特征向量。計算V或U的最優解:
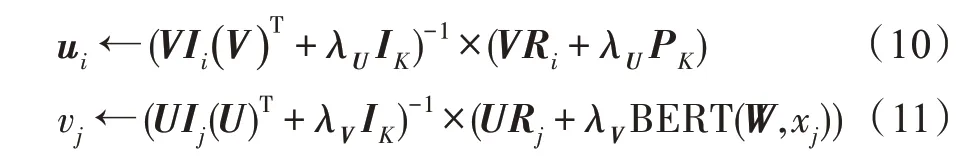
W詞嵌入權重矩陣與BERT 模型內部的神經網絡隱層以及激活函數密切相關。當U與V固定時,可以將損失函數看作具有正則項的平方誤差函數:
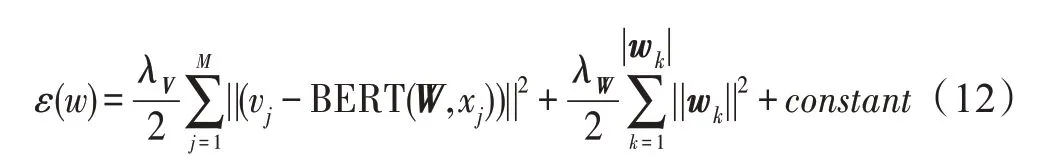
通過反向傳播算法,對權重矩陣W進行優化。
Per-BERT MF 算法的學習過程如算法1 所示:
算法1Per-BERT MF 算法
輸入:用戶-項目評分矩陣R、用戶評論文本C、項目評論文本X、用戶人格評分P。
輸出:潛在用戶特征矩陣U、潛在項目特征矩陣V。
1.隨機初始化U、V、權重矩陣W
2.fori≤ndo
3.根據式(3)、式(4)初始化U
4.end for
5.forj≤mdo
6.根據式(5)、式(6)、式(7)初始化V
7.end for
8.repeat
9.fori≤ndo
10.根據式(10)更新ui
11.end for
12.forj≤mdo
13.根據式(11)更新vj
14.end for
15.repeat
16.forj≤mdo
17.根據式(12)更新W
18.end for
19.until convergence
20.until 訓練結束
算法1 中,通過步驟1~6 對項目、用戶進行表征。之后根據表征結果采用最小化損失函數值的方式,更新項目及用戶潛在矩陣,最終輸出用戶、項目的低維表征矩陣。
用戶的最終預測評分可表示為:
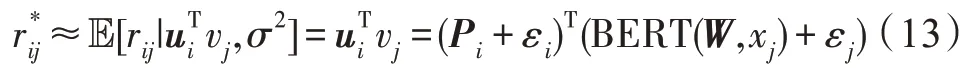
3 實驗與分析
為驗證提出的融合人格的用戶偏好預測模型的性能,本文使用上述人格預測模型獲得的用戶人格得分結合用戶評分及評論數據使用Per-BERT MF 模型生成用戶偏好預測,并對其準確性進行驗證。
3.1 實驗數據及設置
本文采用亞馬遜數據集[20]對Per-BERT MF 模型的評分與實際評分誤差、準確率、F1 值、AUC(area under curve)等性能指標進行評估與驗證。本文使用的3 個亞馬遜數據集,分別是游戲數據集、電影電視數據集以及改進工具數據集。采用如下預處理步驟對這3 個數據集進行統一預處理:(1)刪除停用詞以及出現詞頻高于0.5 的單詞;(2)計算每個單詞的tfidf(term frequency-inverse document frequency)分數,并截取其中排名最高的20 000 個單詞作為詞匯表;(3)截取每項評論中的前200 個單詞。數據集信息統計如表1 所示,這3 個數據集各有特點:游戲數據集用戶數量最大,項目數量也最多,但用戶的平均評論數較少,平均每名用戶僅進行了9.5 條項目評價。與之相比,電影和電視數據集項目數量最少,但每名用戶平均發表了18.6 條評論。而工具數據集與其他兩個數據集相比,用戶數量與項目數量的比值最小,該數據集中每個項目平均僅有1.6 名用戶對其進行評價,而在電影與電視數據集中每個項目平均有8 名用戶對其進行評價。
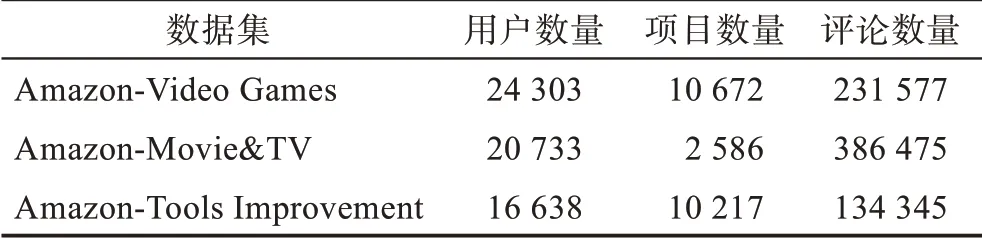
表1 數據集信息統計Table 1 Statistics of datasets
另外,在模型訓練中,參考文獻[22]的設置,通過嘗試,設置丟棄率為0.2,學習率設定為0.001,批處理尺寸設置為128。
實驗運行硬件環境為:4 核Intel?Xeon?E3-1225CPU,3.8 GHz 主頻,16 GB 內存,GTX2070super顯卡PC 主機。實驗運行的軟件環境為:Windows 10操作系統,TensorFlow2.4,Pytorch1.8,Python3.8.2。
3.2 基線模型
為驗證模型的有效性,本文使用八種推薦算法與Per-BERT MF 進行對比。
(1)PMF(概率矩陣分解)是一種標準的評分預測模型,通過概率模型預測用戶和商品特征。處理稀疏且不平衡的數據,向用戶提供推薦結果時效果良好。
(2)SVD++將傳統的奇異值分解模型進行了擴展,在奇異值分解模型的基礎上添加了一組項目特征以對項目相似性進行建模。
(3)ConvMF(卷積概率矩陣分解)將CNN(卷積神經網絡)集成到PMF 中。大量實驗結果表明,即使在評級數據非常稀疏的情況下,ConvMF 仍顯著優于目前最先進的推薦模型[5]。
(4)DeepCoNN(深度矩陣分解)[17]提出了一個從評論文本中共同學習項目屬性和用戶行為的深度模型。該模型被命名為DeepCoNN(deep cooperative neural networks),在幾個基準數據集上進行的實驗證明了該模型的有效性。
(5)NARRE(neural attentional rating regression with review-level explanations)模型利用自注意力機制為每個評論賦予權重。實驗證明該模型表現優于大部分的基準模型以及DeepMF 等神經網絡模型[18]。
(6)TARMF[20]模型使用一個基于自注意力機制的雙向遞歸神經網絡,從評論文本中分別提取出用戶和項目的文本特征,從矩陣分解模型中抽取隱藏特征。在學習過程中將這兩個特征彼此互相近似來互相學習,最終獲得缺失評分預測。
(7)ANR(aspect-based neural recommender)[21]提出的模型在預測級別方面的重要程度時,使用了共同關注的方法(co-attention),可以同時關注用戶和物品之間的細粒度關系。
(8)CARL(context-aware neural model to learn user-item representations)[22]使用一種融合上下文感知的神經網絡模型預測用戶的項目評分。
3.3 預測誤差
本文采用均方誤差(MSE)對實驗結果中評分預測值與真實值的誤差進行評估。MSE 是所有項目真實評分和預測評分誤差的平方和的平均值,公式如下:

其中,n表示用戶評價數量,rij表示用戶i對項目j的真實評分,表示用戶i對項目j的預測評分。MSE值越小說明模型預測得分越接近真實值。
另外,本文采用點擊率預估方法(click-through rate prediction,CTR)[21]對模型的推薦效果進行評估。使用AUC、Precision、F1 指標對本文模型及其他對比模型進行比較。實驗數據集中評分位于1~5 的區間內,根據評分的分布將CTR 模型中的推薦閾值設置為3.5(例如實驗模型預測用戶Ui對項目Vj的評分為4.5 分,大于推薦閾值3.5,是正樣本,則CTR 模型預測用戶Ui會對項目Vj進行點擊,進而進行推薦。反之,則為負樣本)。
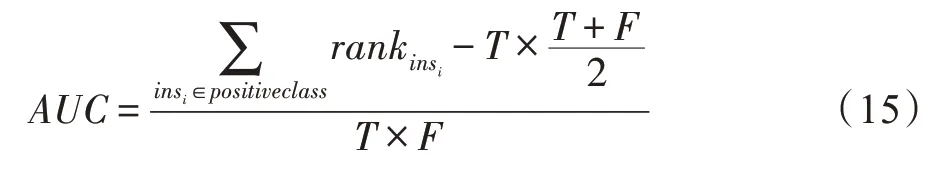

Precision、Recall、F1 的公式如下:

其中,TP表示把正樣本成功預測為正,TN表示把負樣本成功預測為負,FP表示把負樣本錯誤地預測為正,FN表示把正樣本錯誤地預測為負。Precision及F1 值越大說明結果越準確。
3.4 結果分析
本文提出的Per-BERT MF 模型及其他對比模型在所有數據集上所得出的預測與真實的均方誤差如表2 所示,在每列中最低的MSE 值使用粗體標明。表2 的實驗結果顯示,Per-BERT MF 模型在所有數據集上表現均優于其他對比模型。

表2 各模型在Amazon 數據集上的MSE 值Table 2 MSE of each model on Amazon datasets
表2 結果表明,考慮用戶評論的預測模型(如ConvMF、NARRE、TARMF、Per-BERT MF 等)在結果上均優于僅將用戶評分作為輸入的預測模型(如PMF、SVD++)。實驗證明使用評論與評分組合作為預測模型的輸入因素相比較單獨使用評分作為預測模型的輸入因素提高了預測質量,獲得了更好的預測結果。評論信息包含了更多潛在的用戶及項目特征。
其次,在使用深度學習技術的推薦模型中,使用attention(自注意力)機制進行特征提取的模型(如TARMF、Per-BERT MF 等)在預測結果上的表現均優于未使用attention 機制的模型(如ConvMF 等)。相比較使用詞袋(bag-of-word)模型進行特征提取的模型,attention 機制所提取的特征對上下文信息進行了良好的概括。從而在提取特征用于評分預測的實驗中取得了更好的結果。
如表2 所示,Per-BERT MF 模型在3 個數據集上的表現均優于其他對比模型。Per-BERT 建立一個用戶的人格模型,提取用戶評論信息中的情感特征,并轉化為人格得分。通過將人格得分引入評分預測模型,提高了預測結果的準確性。
表3 及表4 的實驗結果表明,本文提出的模型在Amazon-Video Games 及Amazon-Movie&TV 數據集上推薦表現均優于其他對比模型。說明本文提出的模型除預測用戶評分準確率之外,向用戶推薦未評價項目的有用性方面也有良好的表現。表5 顯示Per-BERT MF 模型在Amazon-Tools Improvement 上的推薦表現略遜于ANR 模型,優于除ANR 之外的其他模型。主要原因是Amazon-Tools Improvement 數據集內用戶評論數量及評論平均字數遠少于其他數據集,本文提出的模型更依賴用戶評論信息。
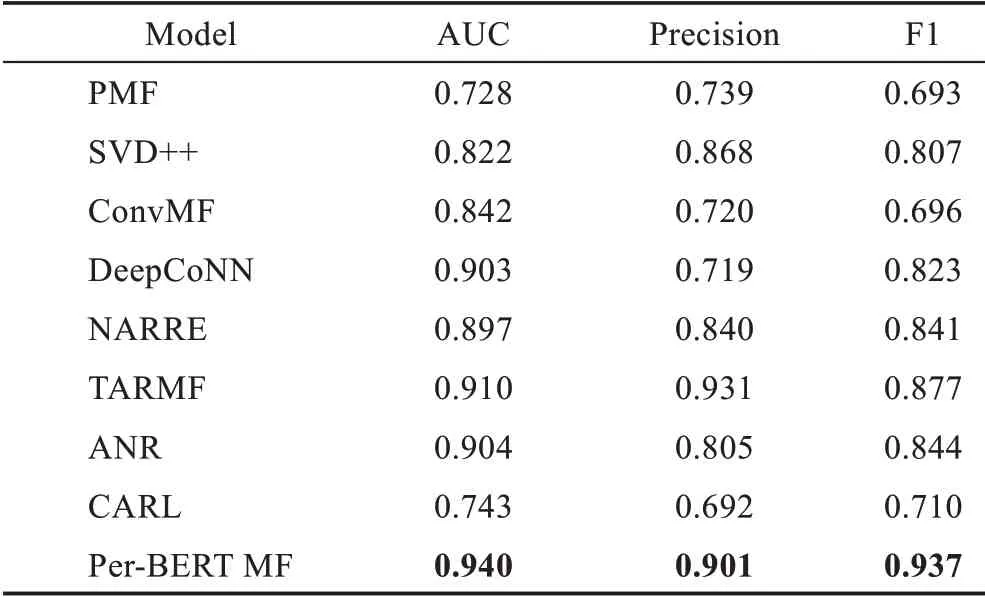
表3 Amazon-Video Games數據集上的指標對比Table 3 Index comparison on Amazon-Video Games dataset
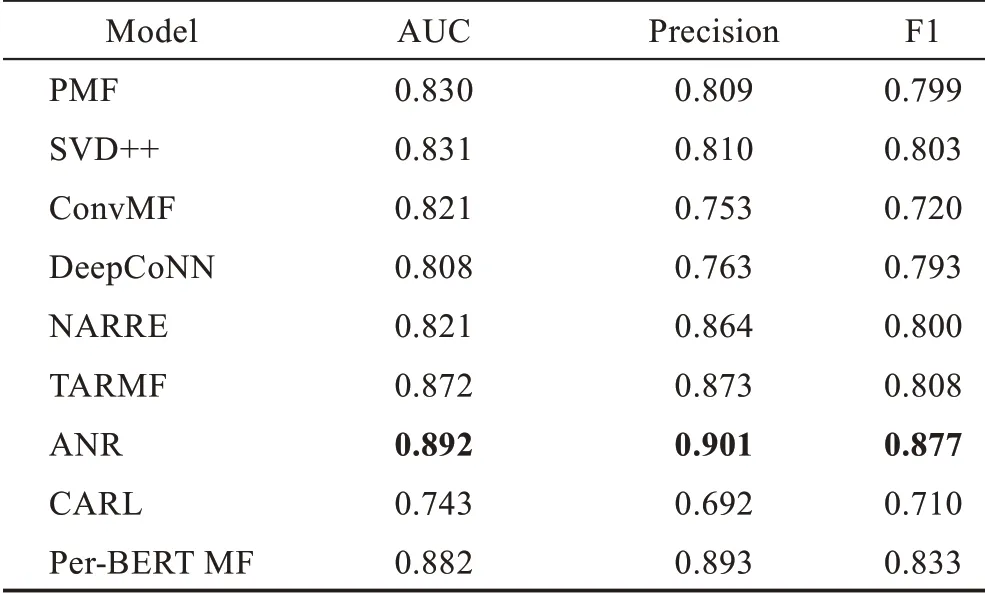
表4 Amazon-Movie&TV 數據集上的指標對比Table 4 Index comparison on Amazon-Movie&TV dataset
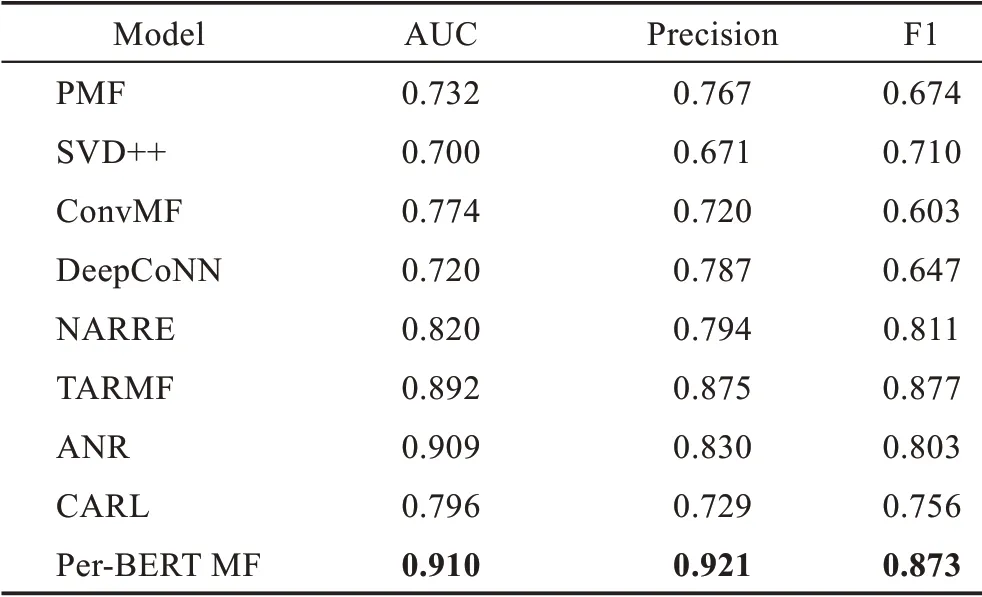
表5 Amazon-Tools Improvement 數據集上的指標對比Table 5 Index comparison on Amazon-Tools Improvement
4 結論與展望
本文提出了一種新的推薦模型Per-BERT MF,該模型解決了用戶的特征表示及項目的上下文信息表示問題。同時設計了一個新的Per-NN 神經網絡用于從用戶評論中提取用戶的人格特征得分,并將人格特征得分作為用戶的特征表示集成到概率分解模型PMF 中,同時使用BERT 提取用戶對項目評論文本的上下文信息。最終集成用戶特征和項目特征進行評分預測。實驗結果表明Per-BERT MF 模型性能優于其他流行的推薦模型。下一步的研究工作主要圍繞優化用戶和項目特征的提取方式。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
