基于LightGBM多階段醫(yī)療服務(wù)等待時(shí)間的預(yù)測研究
2023-01-31 09:42:44黃益槐韓樂奇吳成宇
計(jì)算機(jī)應(yīng)用與軟件 2022年12期
彭 俊 項(xiàng) 薇,2* 謝 勇,3 黃益槐 韓樂奇 吳成宇
1(寧波大學(xué)機(jī)械工程與力學(xué)學(xué)院 浙江 寧波 315211) 2(寧波大學(xué)先進(jìn)儲能技術(shù)與裝備研究院 浙江 寧波 315211) 3(撫州幼兒師范高等專科學(xué)校 江西 撫州 344099)
0 引 言
我國三甲醫(yī)院門診就診中普遍存在“三長一短”的問題,即“掛號排隊(duì)時(shí)間長、看病等候時(shí)間長、取藥排隊(duì)時(shí)間長、醫(yī)生問診時(shí)間短”。有學(xué)者統(tǒng)計(jì)研究表明門診患者的醫(yī)療診治時(shí)間僅占有門診總時(shí)間的10%~15%[1]。這其中的“三長”極大影響患者對醫(yī)院醫(yī)療服務(wù)滿意度,也直接造成患者就診過程排隊(duì)擁堵現(xiàn)象,影響醫(yī)療機(jī)構(gòu)的正常運(yùn)作管理。
基于不斷增長的醫(yī)療需求的影響,就診排隊(duì)等待現(xiàn)象似乎不可避免。目前,患者和醫(yī)院依然存在信息不對稱的情況,特別是當(dāng)患者需要進(jìn)行多項(xiàng)檢查及診治服務(wù)時(shí),患者無法獲得各科室實(shí)時(shí)就診信息,僅依靠經(jīng)驗(yàn)選擇就診項(xiàng)目進(jìn)行排隊(duì)等待。應(yīng)用預(yù)測分析技術(shù)可以為醫(yī)院過度擁擠提供一個(gè)解決方案[2-3],把預(yù)測出的等待時(shí)間等信息通過電子屏幕等移動設(shè)備發(fā)布給患者,增強(qiáng)患者就診體驗(yàn),緩解患者因?yàn)榻辜碑a(chǎn)生等待的焦慮,從而提高其滿意度。
針對醫(yī)療服務(wù)等待時(shí)間預(yù)測問題,依據(jù)其復(fù)雜性,可提煉成單一服務(wù)階段等待時(shí)間預(yù)測與多階段服務(wù)等待時(shí)間預(yù)測這兩類問題。單階段等待時(shí)間預(yù)測是指這類患者需要知道當(dāng)前所在科室的實(shí)時(shí)等待信息,該患者已經(jīng)在該科室的隊(duì)列中,我們需要預(yù)測該患者所在科室隊(duì)列的實(shí)時(shí)等待時(shí)間;多階段服務(wù)等待時(shí)間預(yù)測是指這類患者需要接受系列的就診服務(wù),過程中有多重排隊(duì)隊(duì)列選擇,不僅需要知道當(dāng)前所在科室的實(shí)時(shí)等待信息,還需要獲取下一流程所在科室的等待信息乃至在醫(yī)院的總逗留時(shí)長。通過文獻(xiàn)綜述發(fā)現(xiàn),現(xiàn)有的服務(wù)等待時(shí)間預(yù)測研究主要為單階段等待時(shí)間預(yù)測,少有針對多階段服務(wù)等待時(shí)間預(yù)測的相關(guān)文獻(xiàn)。
國內(nèi)學(xué)者朱啟東[4]基于科室、掛號時(shí)間、是否為工作日、月份、醫(yī)生、同科室候診人數(shù)、當(dāng)天本科室掛號總?cè)藬?shù)和是否為節(jié)假日8個(gè)變量建立BP神經(jīng)網(wǎng)絡(luò)患者候診時(shí)間預(yù)測模型。張會會[5]基于醫(yī)療信息系統(tǒng)數(shù)據(jù)將星期、是否周末、科室、卡號類型、卡號類型、預(yù)約時(shí)段等變量提取出來,分別利用線性回歸、Lasso回歸、隨機(jī)森林回歸、K最近鄰回歸四種方法建立患者等待時(shí)間預(yù)測模型,隨機(jī)森林和K最近鄰回歸精度最高,平均絕對誤差低至13分鐘左右。何躍等[6]將患者掛號月份、時(shí)間段、科室隊(duì)列人數(shù)和科室隊(duì)列流速作為預(yù)測模型的自變量,建立基于BP神經(jīng)網(wǎng)絡(luò)急診科室患者等待時(shí)間預(yù)測模型,其研究顯示隊(duì)列流速對患者等待時(shí)間影響較小。
國外研究主要側(cè)重于急診科室患者等待時(shí)間的預(yù)測,與之相關(guān)的文獻(xiàn)采用了大量的統(tǒng)計(jì)方法。Austin等[7]基于患者年齡、性別、患者緊急情況、病情程度、是否為工作日等15個(gè)變量使用分位數(shù)回歸模型預(yù)測患者在請求急診服務(wù)科多久到達(dá)醫(yī)院。Poole等[8]使用正則化模型(Ridge and Lasso)和隨機(jī)森林回歸預(yù)測患者急診候診時(shí)間。Champion等[9]通過使用簡單的移動平均、滾動平均方法計(jì)算出等待時(shí)間的算術(shù)平均值來構(gòu)建預(yù)測模型。Pianykh等[10]將科室隊(duì)列人數(shù)、最近的3位病人平均等待時(shí)間、隊(duì)列流速等作為輸入變量,建立線性回歸模型預(yù)測患者等待時(shí)間。Ang等[11]使用正則化回歸模型預(yù)測病情較輕患者等待時(shí)間。Arha[12]基于時(shí)間類變量(如這一天是星期幾、患者幾點(diǎn)到達(dá)等)、急診科室快速通道的狀態(tài)、患者類型、患者地點(diǎn)位置等變量,構(gòu)建基于正則化回歸方法(Lasso、Ridge、Elastic Net、SCAD和MCP)和隨機(jī)森林的患者等待時(shí)間預(yù)測模型。
綜上所述,總結(jié)對患者等待時(shí)間統(tǒng)計(jì)建模輸入的變量:主要可分為時(shí)間類、患者類型、科室類型、掛號方式、地點(diǎn)位置5類變量,具體如表1所示。現(xiàn)有的研究主要采用移動平均、回歸分析和神經(jīng)網(wǎng)絡(luò)三類算法,具體如圖1所示。移動平均模型僅利用本身的歷史數(shù)據(jù)進(jìn)行預(yù)測,數(shù)據(jù)需求簡單,但也因此忽略了其他因素的影響;神經(jīng)網(wǎng)絡(luò)算法可解釋性較差同時(shí)需要大量的歷史數(shù)據(jù);而經(jīng)典的回歸分析方法如正則化方法、分位數(shù)回歸、K最近鄰、決策樹等預(yù)測技術(shù)由于欠擬合導(dǎo)致預(yù)測性能欠佳,同時(shí)也不適用在大數(shù)據(jù)樣本的預(yù)測。本文將選取醫(yī)療服務(wù)等待時(shí)間的預(yù)測問題為研究對象,引入基于LightGBM算法實(shí)現(xiàn)多階段服務(wù)等待時(shí)間的預(yù)測。

表1 統(tǒng)計(jì)預(yù)測建模輸入變量
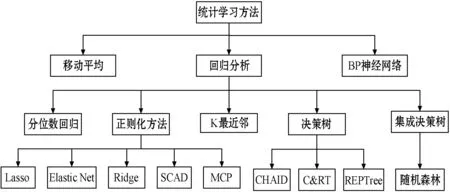
圖1 統(tǒng)計(jì)學(xué)習(xí)預(yù)測方法
1 相關(guān)方法
1.1 LightGBM原理
LightGBM算法屬于Boosting集成算法中的一種,Boosting是機(jī)器學(xué)習(xí)中集成學(xué)習(xí)算法的一個(gè)分支,是目前經(jīng)典的用于預(yù)測的機(jī)器學(xué)習(xí)算法,由Schapire[13]提出,其主要思想是將多個(gè)弱監(jiān)督學(xué)習(xí)模型進(jìn)行有機(jī)組合得到一個(gè)性能更好更全面強(qiáng)監(jiān)督學(xué)習(xí)模型,即便是某一個(gè)弱學(xué)習(xí)器得到了錯誤的預(yù)測,其他的弱學(xué)習(xí)器也可以將錯誤糾正。常見的機(jī)器學(xué)習(xí)Boosting集成算法有Adaboost、GBDT、XGBoost和LightGBM。Adaboost和GBDT都是經(jīng)典的Boosting決策樹算法,XGBoost在GBDT基礎(chǔ)上進(jìn)行了一定改進(jìn),使其性能得到提升。XGBoost算法雖然強(qiáng)大,但是由于XGBoost算法迭代次數(shù)和特征維度有很大關(guān)系,當(dāng)樣本數(shù)據(jù)維度增加,每次迭代需要遍歷全部的數(shù)據(jù)樣本,在這種情況下XGBoost算法效率顯著降低。為了應(yīng)對大數(shù)據(jù)樣本的挑戰(zhàn),還需要對XGBoost進(jìn)行優(yōu)化。LightGBM是微軟2017年提出的新的Boosting框架模型[14],LightGBM算法在XGBoost基礎(chǔ)上進(jìn)一步進(jìn)行了以下改進(jìn):
(1) 梯度單邊采樣技術(shù):梯度單邊采樣技術(shù)(Gradient-based One-Side Sampling,GOSS)可以剔除很大一部分梯度很小的數(shù)據(jù),只使用剩余的數(shù)據(jù)來估計(jì)信息增益,從而避免低梯度長尾部分的影響。由于梯度大的數(shù)據(jù)對信息增益更加重要,所以GOSS技術(shù)在較之傳統(tǒng)GBDT少很多的數(shù)據(jù)前提下仍然可以取得相當(dāng)高的預(yù)測精度[15]。
(2) 獨(dú)立特征合并技術(shù)和直方圖算法:獨(dú)立特征合并技術(shù)(Exclusive Feature Bundling,EFB)實(shí)現(xiàn)互斥特征的捆綁,以減少特征的數(shù)量,因?yàn)樵诟呔S特征的數(shù)據(jù)樣本中,很多樣本的特征存在互斥的情況,EFB技術(shù)識別并對這些特征進(jìn)行捆綁。另外,在GBDT和XGBoost算法中,最耗時(shí)的步驟是利用預(yù)排序(Pre-Sorted)的方式在排好序的特征值上枚舉所有可能的特征點(diǎn),然后找到最優(yōu)劃分點(diǎn),而LightGBM中使用直方圖算法替換了傳統(tǒng)的Pre-Sorted以減少對內(nèi)存的消耗,直方圖算法的思路是將連續(xù)的特征值進(jìn)行裝箱處理,裝箱處理其實(shí)就是離散化連續(xù)的特征值,而對于類別特征,一種取值就是一個(gè)箱,這樣處理的好處是在節(jié)點(diǎn)分裂時(shí),XGBoost和GBDT中需要遍歷所有離散化的值,而在LightGBM中只要遍歷箱。因此LightGBM更加高效,占用內(nèi)存更低。
(3) 不同于XGBoost和GBDT采用基于按層生長的決策樹成長方式,又叫做level-wise策略。LightGBM算法中單個(gè)決策樹的節(jié)點(diǎn)分離方法是基于葉子分裂的,又叫l(wèi)eaf-wise策略,這樣的好處是不會對許多分裂增益過低的節(jié)點(diǎn)進(jìn)行遍歷搜索,降低了對計(jì)算資源的消耗。
1.2 預(yù)測分析過程
本文預(yù)測分析過程如圖2所示,首先基于SIMIO獲取相關(guān)數(shù)據(jù),對數(shù)據(jù)進(jìn)行獨(dú)熱編碼及標(biāo)準(zhǔn)化預(yù)處理后使用Lasso、Ridge、GBDT、XGBoost和LightGBM算法建立預(yù)測模型,使用隨機(jī)搜索選擇參數(shù),最后通過對比選出最佳模型。
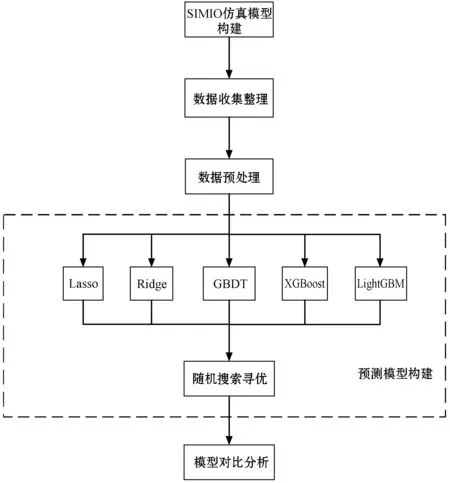
圖2 預(yù)測分析過程
2 構(gòu)建多階段患者服務(wù)等待時(shí)間預(yù)測模型
2.1 預(yù)測問題描述
將患者服務(wù)等待時(shí)間定義為患者在醫(yī)院接受服務(wù)時(shí)間以及等待時(shí)間之和。醫(yī)院各科室隊(duì)列人數(shù)的實(shí)時(shí)狀態(tài)S、患者診療流程中的科室構(gòu)成O是影響患者服務(wù)等待時(shí)間的主要因素。
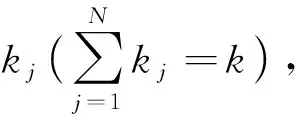
(1)
所以,多階段患者服務(wù)等待時(shí)間可用式(2)表示,因?yàn)闊o法知道公式的具體形式,因此采用LightGBM算法建立回歸模型預(yù)測患者服務(wù)等待時(shí)間。
F=f(k1,k2,…,kn,p11,p12,…,p1n,…,pMnM)
(2)
2.2 基于SIMIO訓(xùn)練樣本的收集
對寧波某婦幼保健院以及寧波多家醫(yī)院的調(diào)研發(fā)現(xiàn),目前醫(yī)院的HIS系統(tǒng)與排隊(duì)系統(tǒng)獨(dú)立運(yùn)作,無法直接獲取多階段的原始數(shù)據(jù),本文采用SIMIO軟件進(jìn)行仿真,獲取模型訓(xùn)練集和驗(yàn)證集數(shù)據(jù)。
仿真首先需要仿真目標(biāo),本文基于文獻(xiàn)[16]建立仿真模型獲取相關(guān)實(shí)驗(yàn)數(shù)據(jù)。論文中以大連某體檢中心實(shí)際工作流程為基礎(chǔ),對于患者的就診流程、患者到達(dá)分布、人員設(shè)備配置、各科室服務(wù)時(shí)間、排隊(duì)過程均有詳細(xì)說明。
對于建模輸入變量,本文主要考慮患者和醫(yī)務(wù)人員兩方面的影響,主要包括時(shí)間類(患者到達(dá)時(shí)間)、科室類(各科室隊(duì)列人數(shù)類、患者檢查項(xiàng)目)這2大類變量對患者等待時(shí)間的影響,具體變量和變量類型如表2所示,通過SIMIO中添加觸發(fā)器并加入write step模塊將實(shí)驗(yàn)相關(guān)數(shù)據(jù)輸出成.csv文件格式。對于上述共17類數(shù)據(jù),服務(wù)等待時(shí)間是我們的預(yù)測目標(biāo),進(jìn)入隊(duì)列時(shí)間既可獲取進(jìn)入隊(duì)列時(shí)刻,也可與完成時(shí)間計(jì)算得到患者的服務(wù)等待時(shí)間,其他14個(gè)變量為輸入模型中的因變量,將仿真模型運(yùn)行60天后匯總得到樣本共計(jì)8 110條。

表2 變量類別及類型
2.3 數(shù)據(jù)預(yù)處理
(1) 標(biāo)準(zhǔn)化。對數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理可以排除不同變量值域量綱差異過大的影響,有利于算法模型的收斂。通過式(3)進(jìn)行轉(zhuǎn)換,假設(shè)原始變量集合為X={X1,X2,…,Xn},標(biāo)準(zhǔn)化處理后的變量集合為Z={Z1,Z2,…,Zn},使用sklearn.preprocessing中StandardScaler模塊可以快速進(jìn)行數(shù)據(jù)標(biāo)準(zhǔn)化處理。本文對檢查科室總數(shù)、采血科隊(duì)列人數(shù)、一般檢查科隊(duì)列人數(shù)、眼耳口鼻科隊(duì)列人數(shù)、內(nèi)科隊(duì)列人數(shù)、外科隊(duì)列人數(shù)和彩超科隊(duì)列人數(shù)進(jìn)行標(biāo)準(zhǔn)化處理。
(3)
式中:μ是該變量的均值;s為該變量的標(biāo)準(zhǔn)差。
(2) 獨(dú)熱編碼。獨(dú)熱編碼即一位有效編碼,其方法是使用N位狀態(tài)寄存器來對N個(gè)狀態(tài)進(jìn)行編碼,每個(gè)狀態(tài)都有它獨(dú)立的寄存器位,并且在任意時(shí)候,其中只有一位有效。如對0和1進(jìn)行編碼,首先只有兩個(gè)狀態(tài)就是需要兩個(gè)狀態(tài)寄存器,將其編碼為00和01。獨(dú)熱編碼使得特征間的距離度量合理,不過會增加特征維度。本文使用Python的第三方庫pandas中g(shù)et_dummies()方法對進(jìn)入隊(duì)列時(shí)刻、采血科是否檢查、一般檢查科是否檢查、眼耳口鼻科是否檢查、內(nèi)科是否檢查、外科是否檢查和彩超科是否檢查共7個(gè)離散特征進(jìn)行獨(dú)熱編碼。
2.4 數(shù)據(jù)集切分
為評估模型的泛化性能,將實(shí)驗(yàn)源數(shù)據(jù)集,共計(jì)8 110條實(shí)驗(yàn)源數(shù)據(jù),隨機(jī)選取80%的數(shù)據(jù)(6 488個(gè)樣本)作為訓(xùn)練集,20%的數(shù)據(jù)(1 622個(gè)樣本)作為測試集。

表3 數(shù)據(jù)集大小
2.5 模型評價(jià)指標(biāo)
使用兩個(gè)指標(biāo)MAE和MAPE度量Lasso、Ridge、GBDT、XGBoost、LightGBM模型的預(yù)測精度。
(1) 平均絕對誤差(MAE)。平均絕對誤差可以直接衡量預(yù)測值與真實(shí)值的差值大小,具體MAE計(jì)算方式見式(4)。
(4)
式中:n為樣本個(gè)數(shù);yobs,i為第i個(gè)實(shí)驗(yàn)數(shù)據(jù)的真實(shí)值;ymodel,i為第i個(gè)實(shí)驗(yàn)數(shù)據(jù)的預(yù)測值。MAE值越小說明算法預(yù)測精度越高。
(2) 平均絕對百分比誤差(MAPE)。平均絕對百分比誤差不僅僅考慮預(yù)測值與真實(shí)值的誤差,還考慮了誤差與真實(shí)值間的比例。MAPE計(jì)算方式見式(5),MAPE值越小說明算法預(yù)測精度越高,由式(5)可知當(dāng)實(shí)際值為0時(shí)公式將不適用,因此在計(jì)算MAPE時(shí)將實(shí)際值為0的樣本刪除。
(5)
式中:n為樣本個(gè)數(shù);yobs,i為第i個(gè)觀測樣本的實(shí)際值;ymodel,i為第i個(gè)樣本的預(yù)測值。
2.6 計(jì)算結(jié)果分析
模型驗(yàn)證實(shí)驗(yàn)電腦配置為64位Window 10操作系統(tǒng),8 GB運(yùn)行內(nèi)存,Intel Core i5- 8250U處理器。使用Python3.5編程語言進(jìn)行分析建模,建模過程主要使用到的包和機(jī)器學(xué)習(xí)庫有pandas、numpy、matplotlib、seaborn、sklearn。
使用機(jī)器學(xué)習(xí)算法構(gòu)建預(yù)測模型時(shí),參數(shù)對模型的預(yù)測結(jié)果影響較大。對于Lasso模型,選取alpha和max_iter進(jìn)行尋優(yōu);對于Ridge模型,選取alpha進(jìn)行尋優(yōu);對于GBDT模型,選取learning_rate、n_estimators、max_depth和subsample這4個(gè)主要參數(shù)進(jìn)行調(diào)優(yōu);對于XGBoost模型,選取learning_rate、n_estimators和max_depth這3個(gè)參數(shù)進(jìn)行尋優(yōu);對于LightGBM模型,選取learning_rate、n_estimators、max_depth、num_leaves、min_data_in_leaf、feature_fraction和bagging_fraction共7個(gè)主要參數(shù)進(jìn)行調(diào)優(yōu)。使用隨機(jī)搜索自動選取參數(shù)。具體步驟如下:(1) 確定參數(shù)的尋優(yōu)區(qū)間;(2) 為每個(gè)超參數(shù)定義成均勻分布;(3) 根據(jù)給定的分布進(jìn)行隨機(jī)采樣,然后根據(jù)得到的采樣結(jié)果進(jìn)行遍歷。使用sklearn中RandomizedSearchCV模塊可快速進(jìn)行隨機(jī)搜索。使用5折交叉驗(yàn)證選擇參數(shù),超參數(shù)尋優(yōu)時(shí)采用MAE為評分函數(shù)。確定參數(shù)后分別評估各模型在測試集上的預(yù)測性能,并整理實(shí)驗(yàn)結(jié)果如表4所示。
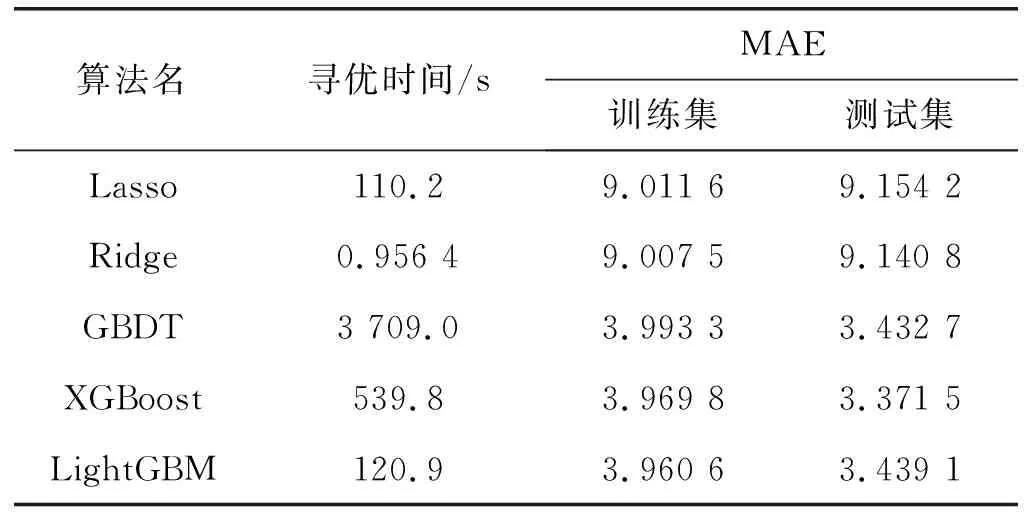
表4 不同模型尋優(yōu)耗時(shí)與MAE值對比
可以發(fā)現(xiàn)Ridge尋優(yōu)時(shí)間最短,預(yù)測性能較差,在測試集上MAE僅為9.140 8。GBDT、XGBoost、LightGBM都可以取得較好的預(yù)測精度,MAE約為3分鐘左右,但是LightGBM模型可大幅降低尋優(yōu)時(shí)間,其尋優(yōu)時(shí)長僅為GBDT模型的3.3%,XGBoost模型的22.4%。因此,綜合尋優(yōu)時(shí)間和預(yù)測精度來看,確定LightGBM為最佳模型。
使用MAPE評估各模型的預(yù)測精度在測試集上預(yù)測精度,通常我們認(rèn)為模型MAPE小于10%說明預(yù)測模型精度較高。如表5為各個(gè)模型的MAPE值。可以發(fā)現(xiàn)GBDT、XGBoost、LightGBM算法遠(yuǎn)高于Lasso和Ridge模型預(yù)測精度,預(yù)測精度分別為8.62%和8.23%和8.52%,滿足實(shí)際應(yīng)用需求。

表5 各算法MAPE值對比(%)
2.7 特征重要度
LightGBM建模可使用模型內(nèi)置函數(shù)plot_importance提取特征對于模型的重要度,表6為各特征對模型重要度所占百分比,可以看出各科室隊(duì)列人數(shù)和檢查科室總數(shù)占比最高,計(jì)算可得這些特征占比總計(jì)達(dá)84.77%。這些特征是影響患者等待時(shí)間的關(guān)鍵。

表6 LightGBM模型特征重要度(%)
2.8 預(yù)測應(yīng)用討論
結(jié)合醫(yī)療工作,根據(jù)預(yù)測分析結(jié)果給出如下應(yīng)用討論:
(1) 體檢流程作為典型的多階段服務(wù)流程,患者往往處在焦急的等待之中,在我們的實(shí)際應(yīng)用中,可在預(yù)測出的等待時(shí)間的基礎(chǔ)上加上一段時(shí)間,使得患者實(shí)際感知的等待時(shí)間減少,提高病人滿意度。
(2) 對于多階段服務(wù)等待時(shí)間預(yù)測來說,獲取各科室信息是預(yù)測的基礎(chǔ),因此建立統(tǒng)一的醫(yī)療信息系統(tǒng)尤為關(guān)鍵,結(jié)合文獻(xiàn)調(diào)研分析和本文的研究,采集患者的掛號科室數(shù)、各科室的隊(duì)列人數(shù)等信息對預(yù)測等待時(shí)間尤為關(guān)鍵。
(3) 多階段服務(wù)等待時(shí)間預(yù)測有助于優(yōu)化序列預(yù)約,減少不必要的過號浪費(fèi)現(xiàn)象發(fā)生,因?yàn)槟壳暗那闆r是每個(gè)環(huán)節(jié)都需要排隊(duì)取號,存在大量過號,無法了解排隊(duì)情況,有了患者服務(wù)等待時(shí)間,可用于最優(yōu)化序列預(yù)約。
3 結(jié) 語
本文基于Lasso、Ridge、GBDT、XGBoost、LightGBM建立多階段服務(wù)等待時(shí)間預(yù)測模型,預(yù)測結(jié)果顯示LightGBM取得預(yù)測性能最好,平均絕對誤差分別為3.439 1,平均百分比誤差為8.52%。本文的不足之處在于LightGBM雖然可以提高預(yù)測精度,但與Ridge算法相比,其算法運(yùn)行時(shí)間較長,特別是在醫(yī)療大數(shù)據(jù)的背景下如何在獲得較高預(yù)測精度的同時(shí)降低算法尋優(yōu)時(shí)長是以后研究主要內(nèi)容之一。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
今日農(nóng)業(yè)(2019年14期)2019-09-18 01:21:54
今日農(nóng)業(yè)(2019年12期)2019-08-15 00:56:32
今日農(nóng)業(yè)(2019年10期)2019-01-04 04:28:15
今日農(nóng)業(yè)(2019年15期)2019-01-03 12:11:33
今日農(nóng)業(yè)(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
