
基于差分進化算法的正態分布均值變點檢測
2023-02-01 07:44:24朱偉業成金良瓊
科技創新與應用 2023年2期
關鍵詞:檢測
朱偉業成,金良瓊,沈 婷
(貴州民族大學 數據科學與信息工程學院,貴陽 550025)
變點檢測問題自20世紀50年代被提出以來,一直是統計領域當中的一個熱點問題。變點指的是從某個時刻開始,樣本的分布或者數字特征發生了變化。變點檢測就是要檢測數據中是否存在變點及對變點的個數和位置進行估計。隨著社會的發展,變點檢測理論已廣泛運用在經濟、醫學、氣象和圖像處理等領域。
在變點檢測問題中,均值變點是一類重要的變點類型,數據的均值發生變化往往引起人們的重視。針對正態分布序列的均值變點問題,中外許多學者都對此進行過研究。Hawkins[1]應用極大似然法研究正態序列均值變點問題。Sen等[2]利用貝葉斯方法給出了均值變點的精確和漸進的分布函數。Kim等[3]采用一種退火隨機逼近蒙特卡洛法(ASAMC)對韓國傳染病數據進行均值變點研究。趙江南等[4]基于ASAMC方法對正態分布序列均值變點問題進行研究并將結果應用于烏魯木齊市的溫度變點檢測問題。胡丹青等[5]在貝葉斯后驗分布的基礎上應用遺傳算法,研究了線性回歸模型中的多結構變點問題。王曉原等[6]運用加速遺傳算法結合均值變點模型對交通流變點問題進行分析研究。郭衛娟[7]采用二分法對方差已知且相等的正態分布均值多變點問題進行研究,給出了變點位置的后驗分布。繆柏其等[8]基于信息論準則,研究了異方差情況下的多元正態分布均值變點問題。何朝兵等[9]采用馬爾科夫蒙特卡洛方法研究了左截斷右刪失情況下的對數正態分布序列的變點檢測問題。楊豐凱等[10]采用一種非迭代抽樣方法(IBF)與迭代Gibbs抽樣算法做對比,研究了在無信息先驗條件下的正態分布均值單變點問題。對于方差已知且相等的正態分布序列均值變點模型,貝葉斯法是一種常用的研究方法,但貝葉斯法存在的不足之處就是后驗分布的計算量較大。基于此,本文將差分進化算法與貝葉斯法結合,對正態分布序列均值變點問題進行研究,模擬結果表明該方法能快速有效地計算后驗分布的最大值,并且檢測出均值變點的位置。
1 正態分布均值多變點模型

式中:μ1≠μ2,μ2≠μ3…μk≠μk+1,σ2為已知常數,則稱該模型為正態分布序列均值變點模型,k為變點個數,r1,r2,r3...rk為變點位置。當k=1時,該模型為單變點模型,k>1時,為多變點模型。本文考慮的問題是在k已知的情況下,如何估計變點位置,即r1,r2,r3...rk的值。
針對變點問題的研究方法主要有(加權)最小二乘法、極大似然法、非參數方法和貝葉斯法等。貝葉斯法利用貝葉斯理論,對包括變點位置在內的未知參數選取合適的先驗分布,利用似然函數推導變點位置的后驗分布,結合樣本數據計算分布的最大值,對變點的位置進行估計。運用貝葉斯法,如何選取參數的先驗分布是關鍵,本文選擇的是無信息先驗分布。
2 貝葉斯估計
2.1 變點位置的無信息先驗分布
正態分布序列均值變點模型中的未知參數為變點位置r1,r2,r3…rk和分布的均值μ1,μ2…μk+1。無信息先驗分布可以理解為對參數的任何可能值既無偏愛,又同等無知[11]。在1,2…n-1上每個變點序列出現的概率都是相等的,因此本文選取r1,r2,r3…rk的聯合先驗分布為
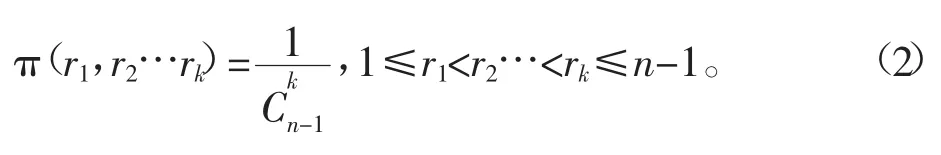
2.2 正態均值的無信息先驗分布[11]
正態分布中的均值μ為位置參數,總體X的密度函數具有形式p(x-μ)。為求均值μ的無信息先驗分布,對X做平移變換,得到Y=X+c,對參數μ也做同樣的變換,得到η=μ+c。設分布Y有密度函數p(y-η),此時,μ和η應有相同的先驗分布。即

π(·)和π*(·)分別為μ和η的無信息先驗分布。此外,由變換η=μ+c可得到η的無信息先驗分布為

比較式(3)和式(4)可得π(η)=π(η-c),由于η與c的任意性,可得均值μ的無信息先驗分布為

這是正態均值μ的一個廣義先驗分布。
2.3 變點位置的后驗分布
設參數θ=(r1,r2,…rk,μ1,μ2…μk+1),假設變點位置與均值參數互相獨立,即

利用貝葉斯公式

可得θ的后驗分布為
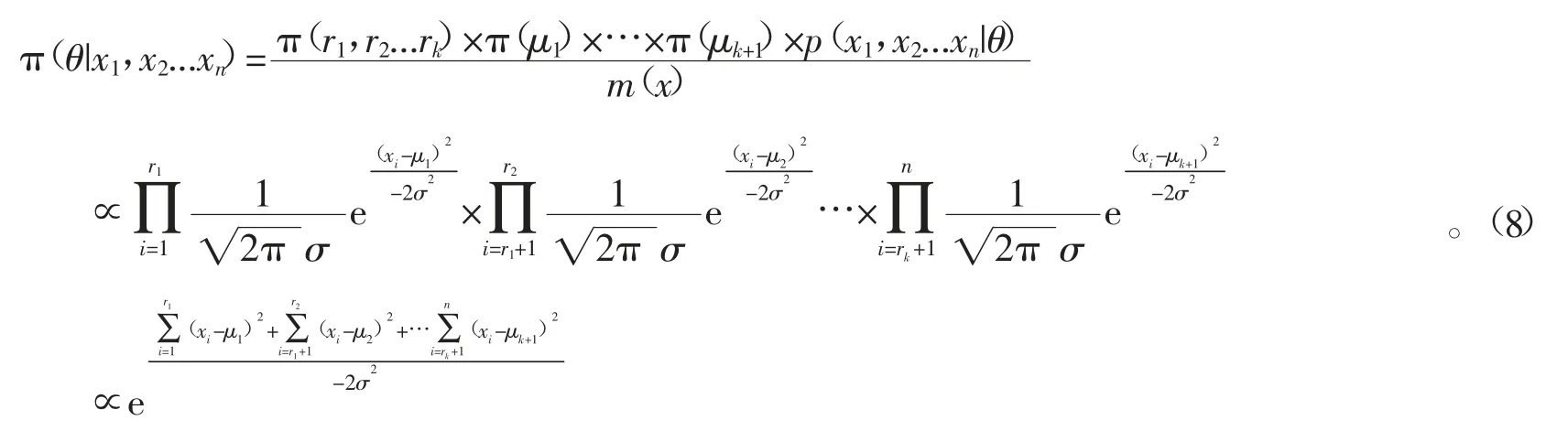
對式(8)中的μ1,μ2…μk+1積分,可得r1,r2,…rk的后 驗分布為

為計算方便取對數,得
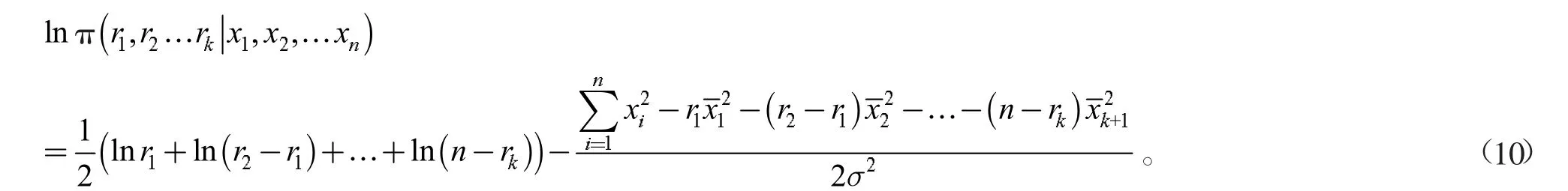
在多變點問題中,變點個數越多,變點位置的參數空間越復雜,計算后驗分布最大值的計算量也變得越大。為快速找到該后驗分布的最大值,本文引用差分進化算法進行分析。接下來介紹差分進化算法的原理和具體步驟。
3 差分進化算法介紹
差分進化算法(DE)是一種高效的全局優化算法。該算法模擬生物進化的過程,首先隨機生成初代種群,然后通過變異、交叉操作生成子代種群,根據“優勝劣汰”原則,淘汰適應度低的種群,保留適應度高的種群。經過不斷迭代進化,最終收斂到最優結果。差分進化算法具備結構簡單、收斂快和自適應能力強等優點,被廣泛運用在各個領域。具體算法流程如下[12-13]。
3.1 初始化種群
首先確定各個參數,包括迭代次數G、種群大小NP、種群維數D、變異算子F、交叉算子CR,以及搜索空間的上下限xmax和xmin。然后隨機生成NP個長度為D的解向量xi,j,i=1,2…NP,j=1,2…D,xmin≤xi,j≤xmax。種群大小NP一般選取[50,200]。
3.2 變異操作
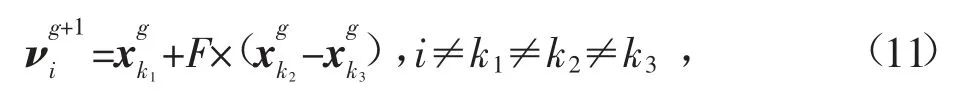
式中:i,k1,k2,k3為兩兩互不相等的隨機整數表示第k個種群的第g代。在變異操作中,變異算子F取值范圍為[0,2],F過小可能陷入局部最優,F過大則不容易收斂,一般取[0.4,1]居多。另外,如果變異以后的值νi,j超出了邊界,可以隨機在范圍內再選擇1個數,或者直接取邊界值。
3.3 交叉操作

式中:rand(0,1)是1個0到1的隨機數,變異算子CR用來控制子代向量值是變異向量值還是原向量值,jrand是1個0到D的隨機整數,其保證了子代向量至少有1個元素與原向量不同。
3.4 選擇操作
選擇操作的原理是計算子代向量和原向量各自的適應度,如果子代向量的適應度更高,則將子代向量保留,替代原向量進入下一代循環,否則保留原向量。具體表達式如下

式中:f(·)為向量對應的適應度函數。
3.5 退出循環
當最后的解向量滿足所需要的精度,或循環次數達到預設值G后,退出循環,否則重復步驟3.2到步驟3.4。
4 數值模擬
在變點個數已知的情況下,對正態分布序列均值變點的位置進行檢測。考慮變點個數為2的情況,模型如下

根據上述模型,分別生成樣本量為300、400、500、600的數據作為檢測的樣本。對應的變點位置分別為100和200、150和300、200和350、200和400。采用2種差分進化算法進行估計:差分進化算法和自適應差分進化算法。兩者的不同之處在于自適應差分進化算法將變異算子F設為1個隨迭代次數變化的值,在迭代初期,F較大,能保證種群多樣性;迭代后期,F較小,能提高搜索效率。算法的參數選擇:種群數NP=50,最大迭代次數Gm=20,變異算子F0=0.5,交叉算子CR=0.4,自適應變異算子由式(15)產生

式中:G表示當前迭代的次數。使用Matlab軟件進行數值模擬1 000次,結果見表1、表2。

表1 不同樣本量下差分進化算法的r1、r2識別結果

表2 不同樣本量下自適應差分進化算法的r1、r2識別結果
從表1和表2可以看出,在樣本量分別為300、400、500、600的情況下,迭代20次,得到的變點位置r1、r2的估計值與真實值的相對誤差均小于0.05%,標準差均小于1.3。說明2種方法均能夠較好地識別出變點位置r1、r2。對比2種方法估計結果的相對誤差與標準差,除了在樣本量為400的情況下,差分進化算法對于r1的估計相對誤差為0.007%,大于自適應差分進化算法對應的相對誤差0.005%以外,其余情況差分進化算法的估計結果的相對誤差與標準差都小于自適應差分進化算法,整體估計效果更好。
在樣本量為300、400、500、600的情況下,統計2種方法正確識別變點位置r1、r2及正負1個或2個單位偏差的次數,對比評估2種方法的識別率,結果見表3、表4。

表3 不同樣本量下基本差分進化算法的r1、r2識別率

表4 不同樣本量下自適應差分進化算法的r1、r2識別率
由表3和表4可以看出,除了在樣本量n=300的情況下,差分進化算法對第二個變點正負1個單位偏差的識別率為96.7%,低于自適應差分進化算法的97%。其余情況下,差分進化算法的識別率均大于等于自適應差分進化算法,進一步說明前者的識別效果更好。從表中還看出r2的識別率大于r1的識別率,這是因為r2前后的均值跳躍度要大于r2前后的均值跳躍度,2組數據的差異更明顯,因此更容易識別出來,符合常理。
為更加直觀地觀察估計效果,以樣本量為600的實驗結果為例,繪制r1、r2的散點圖如圖1—圖4所示。

圖1 差分進化中r1的散點圖

圖2 自適應差分進化中r1的散點圖
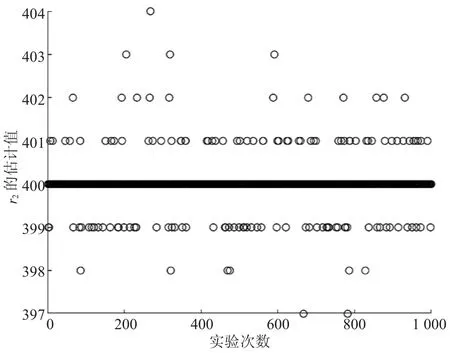
圖3 差分進化中r2的散點圖
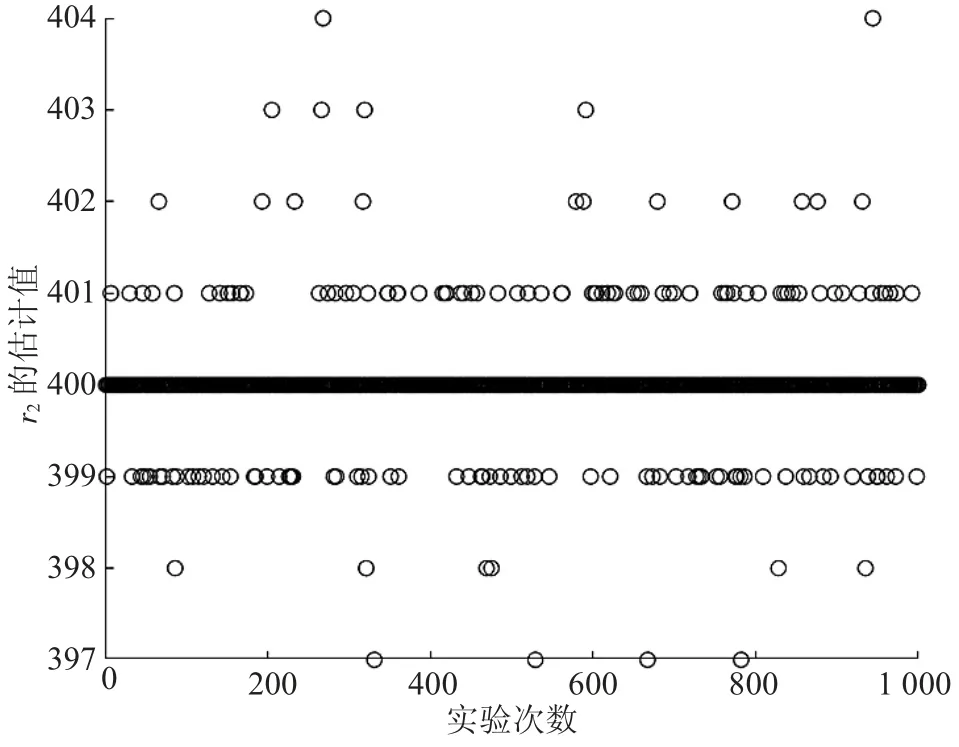
圖4 自適應差分進化中r2的散點圖
由圖1—圖4可以明顯看出,2種方法對r1、r2的識別結果集中在各自對應的真值附近。其中,對r2的識別結果比r1更為集中,效果更好。
為了進一步對比2種方法的優劣,繪制迭代圖如圖5、圖6所示。

圖5 差分進化算法迭代圖
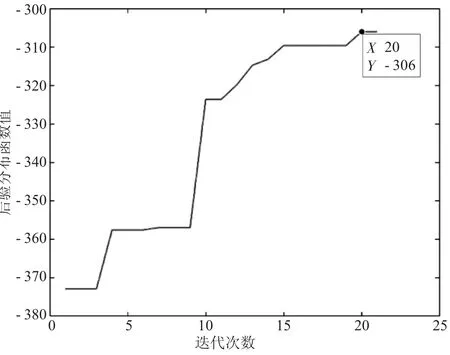
圖6 自適應差分進化算法迭代圖
從圖5和圖6可以看出,差分進化算法在迭代到第16代的時候就已經搜索到了最優解,但自適應差分進化算法到第20代的時候才搜索到最優解,這說明差分進化算法能夠更快地收斂到函數的最大值。為探究迭代次數對2種方法估計效果的影響。下面將最大迭代次數Gm增加到100次,以樣本量為600的變點模型為例,進行數值模擬,結果見表5、圖7、圖8。

表5 最大迭代次數Gm=100下的2種算法的識別結果
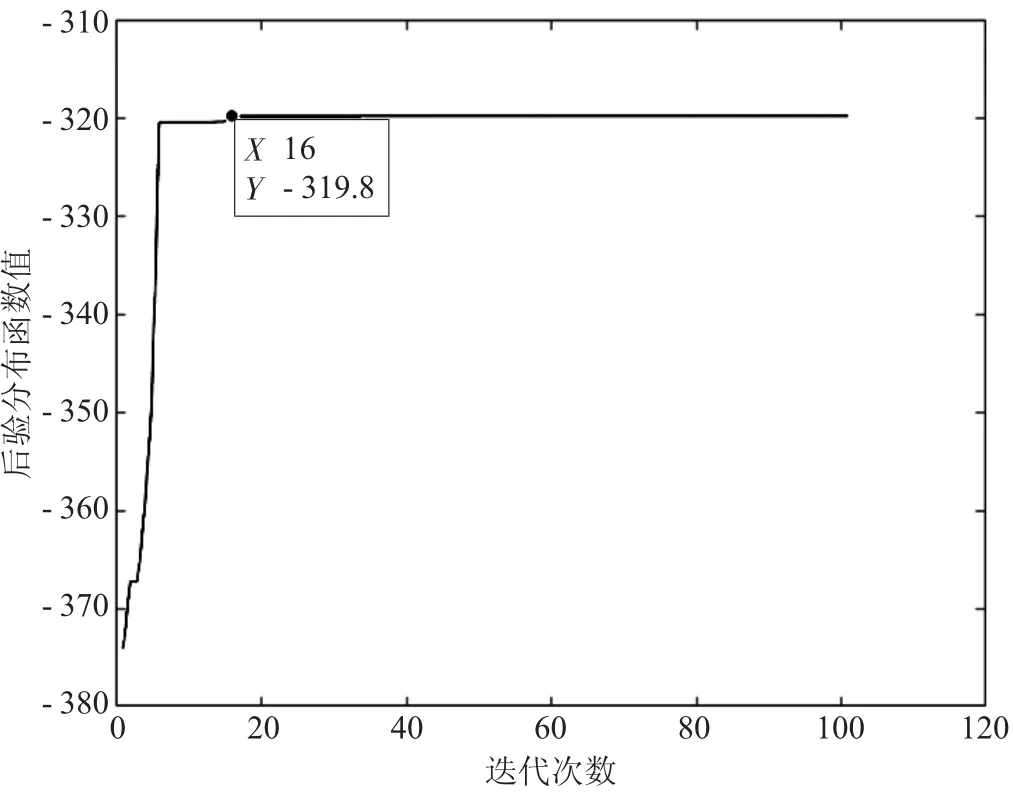
圖7 Gm=100時差分進化算法的收斂圖

圖8 Gm=100時自適應差分進化算法的收斂圖
由表5、圖7、圖8可知,在迭代次數足夠大的情況下,2種算法對變點位置的檢測效果相同。
由此可知:在迭代次數較小時,差分進化算法的檢測效果要優于自適應差分進化算法。當迭代次數達到一定的程度時,2個方法的檢測效果一致。
為了觀察變點檢測前后序列的均值特征,繪制變點檢測前后的均值特征圖如圖9、圖10所示。
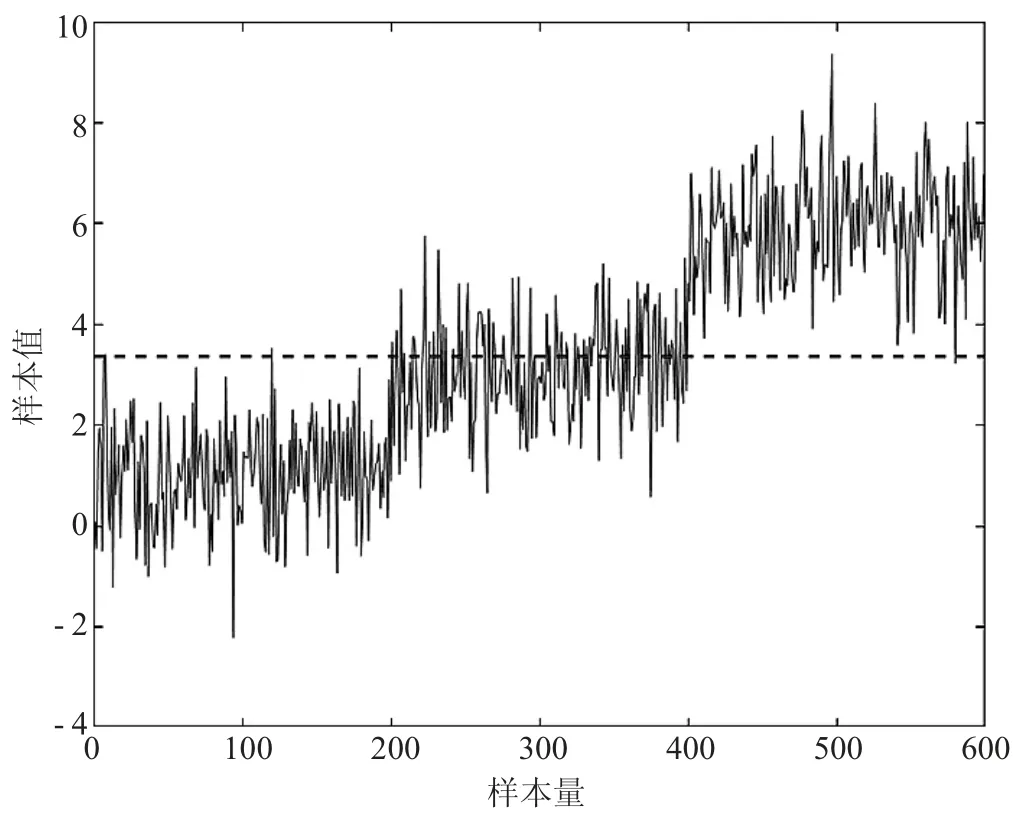
圖9 變點檢測前的均值特征

圖10 變點檢測后的均值特征
圖9的虛線表示無變點模型的數據均值特征,圖10的虛線表示在變點模型下的數據均值特征。可以看出變點模型將數據分成3段,每段分別刻畫數據的均值。更符合數據的真實情況。這說明了本文引用的差分進化算法能夠檢測出變點的位置從而更好地解釋正態分布均值的特征。
5 結束語
本文在貝葉斯理論的基礎上,對已知變點個數條件下的正態分布序列均值變點模型進行研究。首先選擇無信息先驗作為變點位置和正態均值的先驗分布,利用貝葉斯公式得到變點位置的后驗分布。為快速計算后驗分布的最大值,引入2種差分進化算法結合后驗分布進行優化并進行數值模擬。模擬結果表明:2種算法均能夠有效識別出變點的位置。其中,差分進化算法的效果要優于自適應差分進化算法,因此在選擇方法時,應選擇差分進化算法估計變點。綜上,使用差分進化算法結合貝葉斯法能夠更有效地檢測變點個數已知下的正態分布序列均值變點模型中的變點位置。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
