
基于One-Shot聚合自編碼器的圖表示學習
2023-02-03 03:01:14袁立寧
計算機應用 2023年1期
袁立寧,劉 釗
(1.中國人民公安大學 信息網絡安全學院,北京 100038;2.中國人民公安大學 研究生院,北京 100038)
0 引言
圖表示學習將原始圖的結構和特征信息嵌入到低維向量空間,從而能夠直接應用常見機器學習算法來挖掘網絡的潛在特征。圖表示學習旨在生成保留拓撲和屬性信息的低維表示,用于節點分類[1]、鏈接預測[2]、聚類[3]等機器學習任務。為了保證圖數據挖掘任務的質量,節點向量在盡可能保留編碼屬性和邊緣信息的同時,還要兼顧較小的嵌入維數。由于圖數據的復雜性,基于人工設計特征[4]的傳統圖嵌入方法成本極高,而直接在圖上學習節點表示深度學習的方法[5]因其強大的表示能力,受到了越來越多的關注。在最近的文獻中,已經有許多研究嘗試將深度學習方法用于圖表示學習。其中,基于深度學習的無監督模型能夠在缺乏先驗知識或標記信息有限的情況下,從數據中選出具有代表性的特征,因此常用于生成原始數據低維節點向量表示。
基于深度學習的無監督圖嵌入模型主要分為基于隨機游 走[6]和基于自編碼器(AutoEncoder,AE)[7]的算法。DeepWalk[8]和node2vec[9]模型使用隨機游走獲取節點序列,然后訓練Skip-Gram[10]生成節點向量表示。這類方法通常以整個網絡結構為輸入,能夠有效捕捉鄰域相似性,但是未能充分利用提供重要信息的節點特征。基于AE 的圖嵌入模型將圖的拓撲結構和節點特征信息作為編碼器輸入生成低維向量表示,再利用解碼器重構圖結構;但是大部分AE 模型的編碼器部分使用圖神經網絡(Graph Neural Network,GNN)[11]將節點編碼到低維向量空間中,導致模型性能會隨著編碼器深度的增加而降低[12]。
針對上述問題,本文使用One-Shot 聚合(One-Shot Aggregation,OSA)和指數線性單元(Exponential Linear Unit,ELU)函數改進基于圖自編碼器(Graph AutoEncoder,GAE)和圖變分自編碼器(Variational Graph AutoEncoder,VGAE)的深層模型,并在3個基準引文數據集上的鏈路預測實驗中驗證模型性能。本文主要工作如下:1)提出新的GAE 模型OSA-GAE和新的VGAE模型OSA-VGAE,使用OSA[13]和ELU函數[14]編碼圖的拓撲結構和節點特征,改善深層模型的表示能力;2)在損失函數中引入正則化項,防止模型在訓練過程中參數過擬合;3)在鏈路預測實驗中,OSA-GAE 和OSA-VGAE 的性能始終優于相同深度的基線方法,而且它們的性能不會隨著隱藏層數量的增加而降低,并且在部分數據集上呈現出上升趨勢。
1 相關工作
1.1 圖表示學習
根據不同的策略,常見的無監督圖表示學習模型可以分為兩類:基于隨機游走和基于AE 的模型。
基于隨機游走的模型通過隨機游走獲得訓練語料庫,然后將語料庫集成到Skip-Gram 獲得節點的低維嵌入表示。DeepWalk 使用隨機游走采樣節點序列,再通過Skip-Gram 最大化窗口范圍內節點之間的共現概率將節點映射為嵌入向量,由于優化過程中未使用明確的目標函數,使模型保持網絡結構的能力有限。node2vec 在DeepWalk 的基礎上引入有偏的隨機游走,增加鄰域搜索的靈活性,但是仍然缺乏一個明確的目標函數來保持全局網絡結構。Walklets[15]修改DeepWalk 的采樣過程,捕獲節點與社區之間不同尺度信息,顯式建模多尺度關系,使生成的嵌入能夠保留更豐富的節點從屬關系信息。
基于AE 的模型使用AE 對圖的非線性結構建模,生成圖的低維嵌入表示。SDNE(Structural Deep Network Embedding)[16]利用深度自編碼器以及一階和二階相似度,明確優化目標,使生成的嵌入有效保留全局和局部結構信息,增強了模型在稀疏圖上的魯棒性。DNGR(Deep Neural networks for Graph Representations)[17]使用正點互信息矩陣構建圖的高階相似度,捕獲鏈路預測和節點分類等任務所需的底層結構,同時引入堆疊去噪自編碼器增強模型在含噪聲圖上的魯棒性。VGAE[18]使用變分自編碼器(Variational AutoEncoder,VAE)[19]學習可解釋的無向圖嵌入表示,與非概率自編碼器相比,使用VAE 提升了模型性能。Res-VGAE(Variational Graph AutoEncoders with Residual connections)[20]在VGAE 的基礎上引入殘差連接[21],改善深層VAE 性能,但是模型性能隨著深度的增加仍表現出顯著性降低。ANE[22]使用對抗性自編碼器[23]生成捕獲高度非線性結構信息的低維嵌入,在生成過程中施加對抗性正則化避免流形斷裂問題,同時利用一階和二階相似度捕捉局部和全局結構。
1.2 深層模型策略
理論上,隨著深度增加,神經網絡模型能夠提取更復雜的特征,獲得更好的結果。實際上,模型性能會因深度增加而退化,導致準確度達到飽和甚至下降,并且在訓練中出現梯度消失。
為解決上述問題,ResNet[21]引入殘差單元,將各層的輸入和輸出相加,實現跨層連接,改善深層模型的梯度更新。DenseNet[24]使用稠密連接,即每一層的輸入來自前面所有層的輸出,改善梯度消失問題。與ResNet 相比,DenseNet 能夠保留多個感受野的特征圖,更加充分地利用特征信息,但是稠密連接使輸入通道增加,導致模型計算效率嚴重降低。VoVnet[13]使用OSA 將全部特征圖聚合到最后一層,使模型在繼承DenseNet 優點的情況下,解決了稠密連接效率低的問題。OSA 方式如圖1 所示。以上方法改善了卷積神經網絡(Convolutional Neural Network,CNN)[25]隨深度增加加深出現梯度消失的問題,本文借鑒上述建模思路改進深層GNN 編碼器模型架構。

圖1 One-Shot聚合Fig.1 One-Shot aggregation
此外,選擇合適的激活函數,同樣能夠解決深層神經網絡的梯度消失問題。例如,線性整流函數(Rectified Linear Unit,ReLU)[26]:

ReLU 解決了梯度消失問題,能大幅提升模型的計算速度,但是在x<0 時負的梯度被置零,導致神經元壞死,不再對任何數據產生響應。ELU 在ReLU 基礎上引入指數函數,使其在負輸入值的情況下也能返回信息:

相較于ReLU,在輸入為負值的情況下,ELU 有一定的輸出,從而消除ReLU 神經元壞死的問題。此外,ELU 的輸出均值接近0,減少了偏移效應,使正常梯度接近于自然梯度;在輸入較小時負值能夠快速飽和,對噪聲有一定的魯棒性。
2 模型與算法
本章提出基于One-Shot 聚合自編碼器的圖表示學習模型OSA-GAE 和OSA-VGAE 并討論算法原理,介紹了模型框架及編碼器和解碼器結構,并討論了模型的損失函數。
2.1 模型框架
基于One-Shot 聚合自編碼器的圖表示學習模型框架如圖2 所示。OSA-GAE 和OSA-VGAE 以節點特征矩陣和鄰接矩陣為輸入,重構鄰接矩陣為輸出,它們的結構分為編碼器(Encoder)和解碼器(Decoder)兩部分。編碼器使用基于OSA的多層圖卷積網絡(Graph Convolutional Network,GCN)[27]進行構建,用于特征提取和數據降維,生成每個節點的低維向量表示。解碼器利用編碼器生成向量的內積重構鄰接矩陣。

圖2 OSA-GAE和OSA-VGAE模型結構Fig.2 Model structures of OSA-GAE and OSA-VGAE
2.2 編碼器網絡結構
GCN 利用卷積運算從圖中提取特征,生成包含拓撲結構和節點屬性信息的特征向量。具體而言,GCN 使用節點特征矩陣X與鄰接矩陣A作為原始輸入,其層間傳播公式為:

OSA-GAE 編碼器使用引入One-Shot 聚合的多層GCN 提取特征,其表達式為:

其中:L為GCN 層數;W(Final)為權重矩陣。
OSA-VGAE 編碼器使用引入One-Shot 聚合的多層GCN生成均值向量μ和方差向量σ:

采樣層使用μ和σ從高斯先驗分布生成樣本,構建低維嵌入。最終,將嵌入重新參數化為潛在空間上概率的分布[18]:

其中:X為節點特征矩陣;A為引入自環的鄰接矩陣;yi是節點i的低維嵌入,N為節點數。
2.3 解碼器網絡結構
對于OSA-GAE 模型,解碼器是利用兩個節點表示內積重構鄰接矩陣的非概率模型:

其中:A′表示重構矩陣;φ表示sigmoid 函數。
對于OSA-VGAE 模型,解碼器是利用兩個節點表示內積重構鄰接矩陣的概率模型:

其中:Aij為鄰接矩陣A的元素。
2.4 損失函數
OSA-GAE 通過最小化A和A′的重構損失進行訓練,表達式為:

OSA-VGAE 通過最大化變分下界以及最小化重構損失進行訓練,表達式為:

為了避免參數過擬合,在OSA-GAE 和OSA-VGAE 損失函數中引入L2-norm 正則化項Lreg,使用超參數α控制比重:

在訓練過程中,GCN 層的輸入和輸出維度必須相同,才能使用OSA。此外,OSA-GAE 和OSA-VGAE 均執行全批次梯度下降,并利用重參數化技巧[19]進行訓練。
3 實驗與結果分析
3.1 數據集
本文使用Cora、CiteSeer、PubMed 這3 個基準引文網絡數據集[30]評估OSA-VGAE 和OSA-GAE 生成的低維嵌入表示在鏈接預測任務中的性能。在數據集中:節點表示論文,邊表示一篇論文對另一篇論文的引用,節點特征是論文的詞袋表示,節點標簽是人工設定的論文的學術主題。表1 為3 個數據集的統計信息。

表1 數據集統計信息Tab.1 Statistics of datasets
3.2 基線模型
本文使用以下模型作為基線:
VGAE:該模型將VAE 遷移到圖表示學習,其基本思路是利用GCN 獲得節點表示的概率分布,然后在分布中采樣生成節點表示,最后使用內積解碼重構圖的鄰接矩陣。
GAE[18]:該模型直接使用GCN 編碼器生成節點表示,然后使用內積解碼器重構鄰接矩陣。
Linear-VGAE[31]:該模型使用歸一化鄰接矩陣的簡單線性模型替換VGAE 中的GCN 編碼器,解碼器與VGAE 相同。
Linear-GAE[31]:該模型使用歸一化鄰接矩陣的簡單線性模型替換GAE 中的GCN 編碼器,解碼器與GAE 相同。
Res-VGAE:該模型在VGAE 的基礎上引入殘差連接,改善深層VAE 模型的性能。
Res-GAE[20]:該模型在GAE 的基礎上引入殘差連接,改善深層AE 模型的性能。
3.3 實驗設置
為了驗證模型在鏈接預測任務中的性能,需要對基準引文網絡數據集進行預處理[19]:1)保留所有節點的特征信息,將圖中部分邊移除;2)隨機采樣無邊的節點對,其數量與先前移除的邊數相同;3)利用移除的邊和無邊節點對構建驗證集和測試集,其比例分別為總邊的5%和10%。
根據模型正確分類邊和非邊的能力比較模型性能,使用平均精度(Average Precision,AP)和ROC 曲線下的面積(Area Under ROC Curve,AUC)作為評價指標。模型的隱藏層維度均設置為32,生成嵌入的維度設置為16,學習率設置為0.01,迭代次數設置為200。各模型使用相同的驗證集和測試集劃分,運行10 次獲得平均值。
3.4 實驗結果
鏈接預測任務即預測兩個節點之間是否存在邊,用于評估生成嵌入在保持拓撲結構方面的性能。表2~4 為各模型不同深度的AP(%)和AUC(%)結果。
表2 比較了不同模型使用1 層GCN 的實驗結果。在3 個數據集上,OSA-VGAE 和OSA-GAE 的AUC 和AP 最高,其他基線模型的AUC 和AP 十分接近。對于淺層模型,增加OSA和ELU 激活函數能提升模型的準確度。

表2 1層GCN時各模型的AUC和AP 單位:%Tab.2 AUC and AP of each model with 1-layer GCN unit:%
表3 比較了不同模型使用3 層GCN 的實驗結果。在3 個數據集上,引入殘差連接的Res-VGAE 和Res-GAE 表現略優于直接疊加GCN 層的模型,而OSA-VGAE 和OSA-GAE 的表現明顯優于其他模型,特別是在CiteSeer 數據集上,AUC 和AP 相較單層模型有小幅度提升。

表3 3層GCN時各模型的AUC和AP 單位:%Tab.3 AUC and AP of each model with 3-layer GCN unit:%
表4 比較了不同模型使用6 層GCN 的實驗結果。在3 個數據集上,不引入殘差連接、OSA 和ELU 函數的VGAE、GAE、Linear-VGAE 和Linear-GAE 的AUC 和AP 明顯降低,并且采用線性編碼的Linear-VGAE 和Linear-GAE 表現最差。在Cora 數據集上,Res-VGAE 和Res-GAE 與VGAE 和GAE 性能相近;在CiteSeer 和PubMed 數據集上,Res-VGAE 和Res-GAE 表現優于VGAE 和GAE。在3 個數據集上,OSA-VGAE和OSA-GAE 表現最好,深層模型與淺層模型的性能差異不大,尤其是在CiteSeer 上,AUC 和AP 仍有提升。

表4 6層GCN時各模型的AUC和AP 單位:%Tab.4 AUC and AP of each model with 6-layer GCN unit:%
圖3~5 為不同模型在引文數據集上1~6 層的AUC 和AP。與原始的VGAE 和GAE 相比,隨著深度增加,Linear-VGAE 和Linear-GAE 的精度下降最快,表現最差;引入殘差連接的Res-VGAE 和Res-GAE 雖然在一定程度上緩解了深層模型精度下降的問題,但是其表現與原始模型相接近。本文提出的OSA-VGAE 和OSA-GAE 明顯好于其他模型,隨著深度的增加,模型的性能基本保持穩定,在Cora 和CiteSeer 數據集上其性能呈現隨層數的增加而上升的趨勢。上述實驗結果說明添加OSA 和ELU 函數能夠改善深層模型的梯度信息傳遞問題,提升模型性能。

圖3 Cora數據集上的AUC和APFig.3 AUC and AP on Cora dateset
3.5 消融實驗
為了驗證OSA-VGAE 和OSA-GAE 模型中使用OSA 和ELU 對于算法性能的影響,在Cora 數據集上進行消融實驗,對比單獨使用OSA 和ELU 函數的模型性能。為了保證實驗的公平性,保持學習率、隱層維度和嵌入維度等參數一致。實驗結果如表5 所示。相較于單獨使用OSA 或ELU 函數,OSA-VGAE 和OSA-GAE 獲得了最佳表現,說明同時使用上述兩個模塊能夠顯著提升性能。

表5 消融實驗結果 單位:%Tab.5 Results of ablation experiments unit:%
3.6 參數分析
為了評估不同嵌入維度和迭代次數對實驗結果的影響,在Cora 數據集上對使用1 層GCN 的OSA-VGAE 和OSA-GAE模型進行參數敏感性實驗,記錄相關數據。圖6 顯示了不同嵌入維度對模型性能的影響。最初,AUC 隨維度的增加而提高,這是因為更多的維度使嵌入中編碼了更多有益信息,提升了實驗表現。但是,隨著維度不斷的增加,AUC 開始下降,這是因為訓練樣本個數有限,對于每一類節點都存在最大化模型性能的最優嵌入維數,當嵌入維數超過最優維數時,模型性能表現出逐漸下降的趨勢。此外,從圖6 曲線變化可以看出,OSA-VGAE 相比OSA-GAE 對維度更敏感。因此,在生成節點嵌入時選擇合適的維度十分重要。

圖4 CiteSeer數據集上的AUC和APFig.4 AUC and AP on CiteSeer dateset
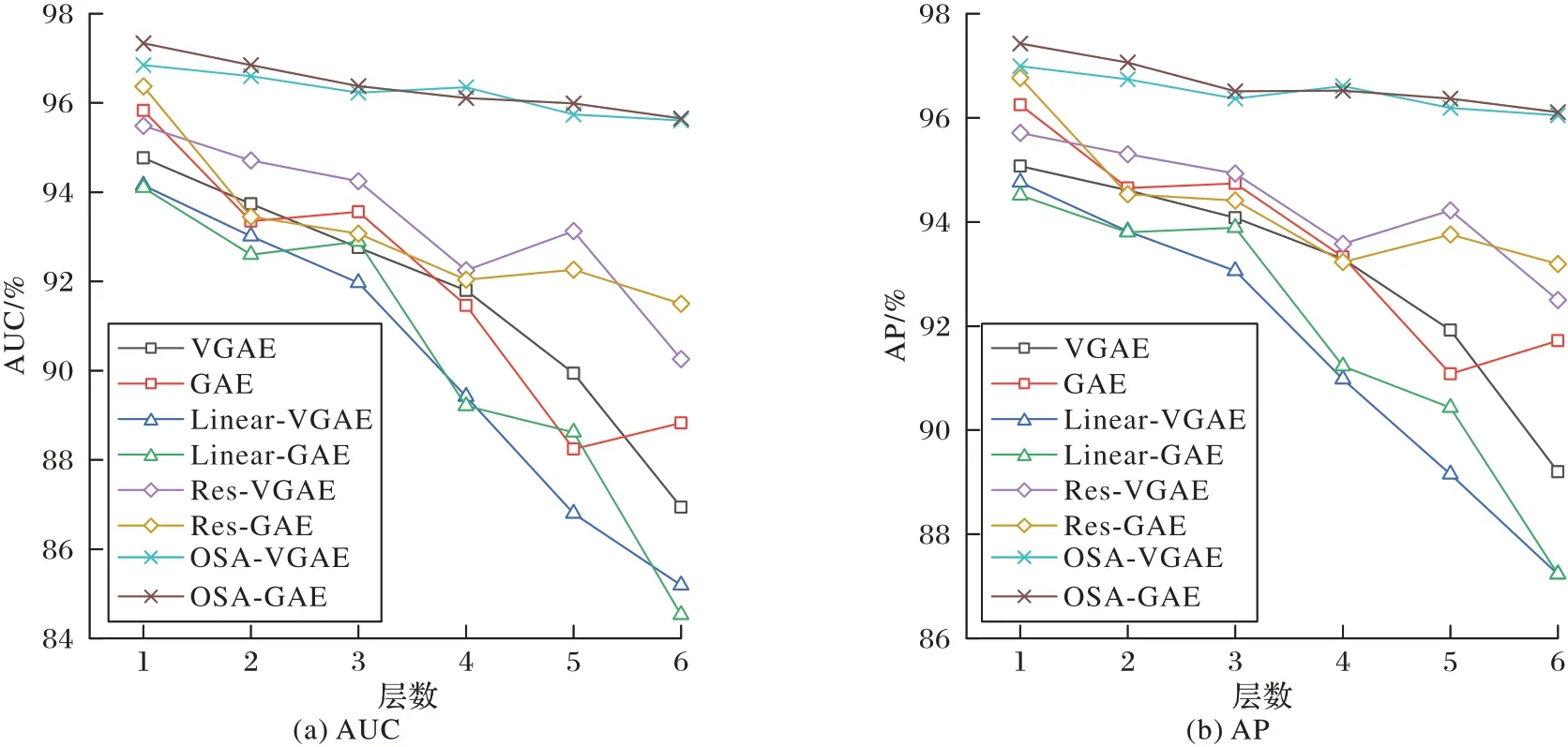
圖5 PubMed數據集上的AUC和APFig.5 AUC and AP on PubMed dateset

圖6 不同嵌入維度的AUCFig.6 AUCs of different embedding dimensions
圖7 記錄了OSA-VGAE 和OSA-GAE 每次迭代的訓練損失和AUC。隨著迭代次數的增加,模型訓練損失整體呈下降趨勢,并且在200~1 000 的迭代過程中,損失值基本處于穩定狀態。在測試集上,初始階段的AUC 隨著迭代次數的增加快速上升,到達一定迭代次數時,模型開始出現過擬合,泛化能力下降,導致AUC 小幅下降并上下震蕩。因此,在訓練模型時選取200 左右的迭代次數即可獲得較為理想的實驗結果。

圖7 OSA-VGAE和OSA-GAE在不同迭代時的訓練損失和AUCFig.7 Training loss and AUC under different iteration for OSA-VGAE and OSA-GAE
4 結語
本文提出了基于One-Shot 聚合和ELU 激活函數的OSAVGAE 和OSA-GAE 模型,改善了模型的梯度信息傳遞,緩解了基于GCN 編碼的自編碼器模型深度問題。實驗結果表明,將計算機視覺中的深層策略引入到圖表示學習中是有益的,能夠提升圖機器學習任務的表現。此外,消融實驗的結果也說明同時使用One-Shot 聚合和ELU 函數對模型性能提升更加顯著。在未來工作中,除了對現有編碼器模型的結構進行改進,將采用更為高效的鄰域聚合和鄰域交互編碼器建模,如基于注意力機制的方法[32];在解碼器部分,將嘗試使用不同的解碼器和概率分布進行實驗。此外,后續工作還將針對模型復雜度、模型泛化能力以及模型避免過擬合能力進行量化和分析。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
