
基于Raft算法改進的實用拜占庭容錯共識算法
2023-02-03 03:01:46王謹東
計算機應用 2023年1期
關鍵詞:監督
王謹東,李 強
(四川大學 計算機學院,成都 610065)
0 引言
區塊鏈作為以比特幣[1]為代表的眾多數字貨幣的底層技術支撐,近年來受到廣泛關注并逐漸應用到眾多領域。區塊鏈的本質是網絡中的各個節點在分布式的環境下,借助密碼學、共識算法、利用智能合約操作數據的一種鏈式數據結構。作為一種全新的分布式計算范式,區塊鏈提供了去中心化、不可篡改、透明、可溯源的分布式數據庫解決方案[2]。
根據節點準入機制的不同,可將區塊鏈分為公有鏈(Public blockchain)、聯盟鏈(Consortium blockchain)、私有鏈(Private blockchain)三類[3]。其中,聯盟鏈具有一定的準入門檻,節點需要授權才能加入區塊鏈網絡,是多中心化的區塊鏈,也是未來區塊鏈發展的重要方向[4]。聯盟鏈目前在數據存儲[5]、版權管理[6]、隱私保護[7]、數據溯源[8]等方面已有眾多的應用。在大多數情況下,聯盟鏈不需要設計激勵層來推動“挖礦”和智能合約的執行,降低了系統部署和維護的成本;同時,以Hyperledger Fabric[9]為代表的眾多企業級區塊鏈平臺支持可插拔的共識算法、多種語言編寫智能合約,進一步推動了大量基于聯盟鏈的應用落地。然而,聯盟鏈仍然面臨可擴展性差的問題。目前在聯盟鏈應用廣泛的實用拜占庭容錯(Practical Byzantine Fault Tolerance,PBFT)[10]共識算法雖然不需要消耗大量算力,但隨著節點數量的增長,其通信開銷會呈平方級增長,導致共識效率較低。在金融、智慧城市、供應鏈管理等領域對區塊鏈的性能與可擴展性要求較高,通常要求單鏈到達萬級吞吐量、千級節點組網能力、秒級交易確認時延,PBFT 算法難以滿足這些領域的需求[11]。同時,PBFT 算法的網絡結構相對靜態,動態添加節點時必須重啟整個系統[12],嚴重影響系統的可用性。不難發現,PBFT 算法目前已不能滿足部分應用場景的需求,一定程度限制了聯盟鏈的進一步發展。共識算法作為區塊鏈的核心技術,對區塊鏈的交易確認時延、吞吐量、可擴展性有著決定性的影響,對PBFT 算法進行改進能夠有效解決上述問題。
針對PBFT 共識算法存在的問題,文獻[13]提出了一種基于協調器的共識算法,通過協調器將交易分類處理,并只對異常交易執行完整的共識,將該算法應用于PBFT 后,獲得了使共識時延縮短為原來的21%;但可能會面臨協調器單點故障導致系統失效的問題。文獻[14]將區塊鏈分片,在分片內部與分片之間分別執行PBFT 算法,使共識效率提升了20%,提升了系統的可擴展性;但是這種算法可能導致整個區塊鏈網絡中的數據不一致。文獻[15]提出了一種基于特定硬件的PBFT 共識算法,所有節點使用硬件芯片(如Intel SGX)構建可信執行環境(Trusted Execution Environment,TEE),并利用消息聚合技術使算法的通信開銷大幅降低;雖然這種算法提升了PBFT 算法的可擴展性,但需要所有節點都具備相同的硬件環境,在實際應用中具有一定的局限性。文獻[16]提出了一種基于EigenTrust 信任模型的PBFT 算法,通過各節點的行為來評估節點的信任度,選擇高質量的節點構建共識組以降低視圖切換概率;但這種算法在共識中的通信復雜度與PBFT 算法相同,難以顯著地提升PBFT 算法的可擴展性。文獻[17]提出了一種基于分片型區塊鏈的共識算法RapidChain,其Decentralized Bootstrapping 階段將參與共識的節點劃分為多個共識委員會。RapidChain 改進了PBFT 算法,將PBFT 算法與ErasureCode、IDA-Gossip 消息傳遞協議結合,原消息被分割為若干個片段在網絡中傳播,各節點收到消息后通過ErasureCode 恢復原消息以減少通信量。
僅對PBFT 算法進行改進并不能從根本上解決PBFT 算法存在的問題,當節點數量增加時,三階段提交過程會使其性能大幅降低。因此,本文提出了一種基于Raft 算法改進的實用拜占庭容錯共識算法K-RPBFT(K-medoids Raft based Practical Byzantine Fault Tolerance)。首先,以節點之間的通信時延作為歐氏距離,利用K-medoids 聚類算法將區塊鏈分片;其次,每個分片的主節點之間使用PBFT 算法進行共識,在分片內部使用基于監督節點改進的Raft 算法進行共識。該算法大幅降低了PBFT 算法的通信開銷與共識時延,提升了吞吐量,并且使系統擁有動態的網絡結構。本文的主要工作如下:
1)提出了一種帶監督節點的拜占庭容錯共識算法K-RPBFT,闡述了K-RPBFT 算法的分片策略、監督機制、共識流程。
2)對K-RPBFT 算法的安全性、一致性、活性進行了分析,以證明K-RPBFT 算法的有效性。
3)通過實驗對K-RPBFT 算法進行了評估,與PBFT 算法、Raft 算法在單次共識通信次數、共識時延、吞吐量等方面進行了對比。
1 相關背景
1.1 PBFT算法
PBFT 算法由Castro 等[10]于1999 年提出,最初被用于構建支持拜占庭容錯的分布式系統,能夠在系統內拜占庭節點數量(n為節點總量)的情況下保證系統的可用性。隨著區塊鏈技術的不斷發展,PBFT 算法常被用于聯盟鏈中節點的共識過程。
PBFT 算法的共識過程包含請求(request)、預準備(preprepare)、準備(prepare)、提交(commit)、回復(reply)等階段。主節點(Leader)在收到客戶端的請求消息后,將會生成預準備消息并廣播給所有從節點(replica)。從節點在收到預準備消息并且通過驗證后,將向所有節點發送準備消息。當從節點收到2f個不同節點(不包括自己)的有效準備消息時,將會向其他節點廣播確認消息。此時節點將會收集所有的確認消息,當收到2f+1 個來自不同節點的有效確認消息時,此請求消息將會被提交,同時向客戶端發送回復消息。當客戶端收到f+1 個不同節點的有效回復消息后,會認為一次共識成功。PBFT 算法的共識流程如圖1 所示。

圖1 PBFT算法的共識流程Fig.1 Consensus flow of PBFT algorithm
當從節點檢測到主節點失效或為拜占庭節點時,將觸發視圖切換(view-change)協議重新選舉主節點。在PBFT 算法中,主節點按照編號輪流當選。視圖切換協議保證了即使主節點為拜占庭節點,系統仍能正常工作。
PBFT 是一個三階段提交算法,從節點之間的相互驗證導致PBFT 的通信復雜度為O(N2),使得算法的可擴展性不強,在具有大規模節點的區塊鏈系統下,可能會導致網絡風暴。
1.2 Raft算法
Raft 算法由Ongaro 等[18]于2014 年提出,是一種相較于Paxos[19]更易理解與實現的共識算法。Raft 的核心由日志復制與領導者選舉兩部分構成,節點的狀態將會根據不同的條件在領導者(Leader)、跟隨者(Follower)、候選者(Candidate)之間變遷。系統在任意時刻只擁有1 個領導者,并與所有跟隨者之間維持周期性的心跳消息。當跟隨者超時仍未收到領導者的心跳消息時,將會轉變為候選者狀態。候選者將會向其他節點發送投票請求消息,申請成為新的領導者,如果此候選者在超時前收到超過半數節點的確認消息,則轉換為領導者。節點狀態的詳細變遷過程如圖2 所示。
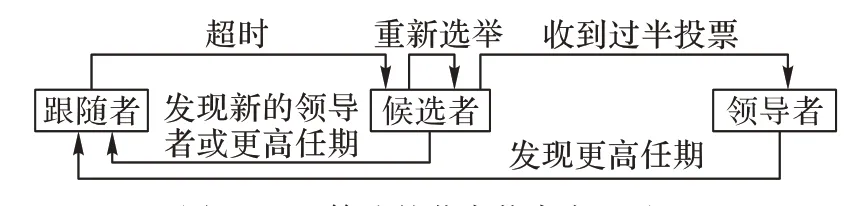
圖2 Raft算法的節點狀態變遷過程Fig.2 Node state transition process of Raft algorithm
在日志復制階段,所有的交易均由領導者打包生成區塊并向所有的跟隨者廣播,在收到超過一半的跟隨者回復后,領導者將會向所有節點發送確認信息,此時該區塊將會被提交上鏈。
Raft 算法的通信復雜度為O(N),共識效率較高,具有良好的擴展性。Raft 算法在系統內不超過一半的節點宕機時仍能正常工作,但是不支持拜占庭容錯,因此通常應用于節點完全可信的私有鏈中。
2 K-RPBFT算法模型
本文結合PBFT 算法的拜占庭容錯特性與Raft 算法的高效性,提出一種帶監督節點的分片區塊鏈共識算法K-RPBFT。在區塊鏈中引入若干監督節點,基于K-medoids聚類算法將區塊鏈分片,令分片數量K等于監督節點數量,并為每個分片分配一個監督節點。在分片內部使用改進的Raft 算法進行共識,在每個分片的Raft 領導者之間使用PBFT算法進行共識。
2.1 K-RPBFT分片策略
K-medoids 算法是一種常見的無監督聚類算法,初始的聚類中心點限定在樣本點中,且K-medoids 對于樣本中噪聲的魯棒性相較于K-means 等算法更好[20],因此基于K-medoids 算法對區塊鏈網絡進行分片,具體過程如下。
1)節點探測。
定義區塊鏈網絡中的節點集合V={v1,v2,…,vn},對于?vi∈V,在初始分片時向節點集合V中的所有節點發送探測消息PING,vi,timestampi,signi,其中PING 為探測消息標識,vi為節點編號,timestampi為探測消息發送時的時間戳,signi為消息簽名。?vj∈V(i≠j),收到此探測消息后將會記錄時間戳timestampji,并驗證消息的合法性,通過驗證后則由式(1)計算出節點vi到vj的單向距離。

節點vj將d(vi,vj) 記錄到本地并構造回復消息REPLY,vj,d(vi,vj),signj發送給vi,其中REPLY 為回復消息標識,vj為節點編號,d(vi,vj)為單向距離,signj為消息簽名。
當探測結束后,所有節點將會計算出一個全局一致的距離矩陣:

其中dij(1 ≤i≤n,1 ≤j≤n)由式(3)計算:

2)初始分片。
使用K-medoids 算法將節點聚類為K個簇,并使K等于區塊鏈網絡中監督節點的數量。用Ci表示每個簇,在每一輪迭代過程中,Ci都有一個當前聚類的簇中心節點ni,定義所有的簇中心節點集合N={n1,n2,…,nK}。根據距離矩陣D,構建節點vi的隸屬函數:
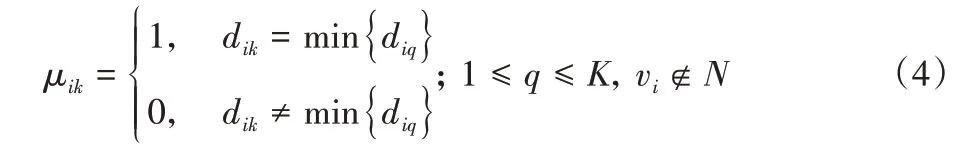
根據隸屬函數可以得到迭代的目標函數:

根據K-medoids 算法流程,在節點集合V中隨機選取K個節點作為初始聚類中心節點。根據式(4)將剩余節點分配到相應的簇中心。在每個簇中,計算每個節點對應的準則函數,選擇準則函數最小時的節點作為新的簇中心。重復迭代上述過程直至所有的簇中心不再發生變化。
當K-medoids 算法迭代收斂后,此時的目標函數值最小。按照迭代生成的聚類結果將區塊鏈劃分為K個分片,簇中心節點作為分片的領導者,其余的節點作為跟隨者,并為每個分片分配監督節點。在所有的簇中心節點之間執行“片間共識”,在每個簇內部執行“片內共識”。此時分片區塊鏈的模型結構如圖3 所示。

圖3 分片區塊鏈模型Fig.3 Model of sharding-based blockchain
3)重分片。
區塊鏈網絡的運行過程中,可能會存在節點動態加入或退出的情況。K-RPBFT 分片模型所使用的節點探測與K-medoids 算法的迭代過程均需要消耗資源。為了更好地控制分片過程的資源消耗,引入重分片上限閾值與重分片下限閾值參數。節點動態加入區塊鏈時,將直接加入節點數量最少的分片中,當有節點加入或退出區塊鏈網絡時,都會對每個分片的節點數量進行檢查,若某一分片的節點數量大于重分片上限閾值或者小于重分片下限閾值時,將會按照分片模型重新進行區塊鏈分片。定義穩定系數S為重分片上限閾值與重分片下限閾值之差:當S較大時,區塊鏈的各節點結構較為穩定,不會頻繁發生重分片,但隨著節點地不斷加入或退出,可能會導致區塊鏈的分片方式與理論最優分片方式出現一定偏差;當S較小時,區塊鏈的結構更容易反映真實的聚類情況,但資源消耗較高。在實際應用中,可設置不同的穩定系數以滿足算法在不同場景下的需求;同時,傳統的PBFT 算法并不支持節點動態加入,新的節點加入時系統必須重啟,而每個分片內部使用的Raft 算法賦予了系統動態添加或刪除節點的能力,提高了系統的靈活性,使系統具有動態的網絡結構。
2.2 片內共識與監督機制
在分片內部,如果進行Raft 共識的領導者為拜占庭節點,向分片中的跟隨者發送錯誤的數據,將會導致此分片與系統中其他分片的數據不一致。為了預防“單片接管攻擊(Single-shard takeover attack)”,監督節點將會參與片內共識,并在適當的時機觸發Raft 算法的Leader election 協議,賦予了Raft 算法一定的拜占庭容錯的能力。片內共識的詳細過程如下:
1)領導者廣播區塊。
領導者將區塊、領導者編號、消息簽名等信息寫入AppendEntries RPC 的entries 域中,向分片內所有節點廣播。
2)監督節點收集區塊。
與傳統的Raft算法不同的是,分片內的跟隨者收到領導者的同步請求后不會立即響應,而是將收到的消息發送給監督節點,等待監督節點的確認消息。監督節點收到領導者的數據后將會檢查區塊中的交易集是否一致,當在超時時間內收到超過3n/4(n為分片內節點數量)個交易集一致的區塊并且與領導者發送的區塊中的交易集一致,則進入監督節點驗證環節,否則觸發執行Leader election協議,并重新執行片內共識。
3)監督節點驗證。
監督節點通過安全散列算法(Secure Hash Algorithm,SHA)[21]計算區塊中交易集的信息摘要,向所有分片的監督節點廣播驗證消息,其 中CHECK 為驗證消息標識,ci為監督節點編號,digi為當前區塊的交易集信息摘要,timestampi為時間戳,termi為當前分片的領導者節點任期。
當前監督節點也會相應地收到來自其他監督節點的驗證消息。監督節點將檢查收到的驗證消息的合法性,并判斷其中的信息摘要與當前分片領導者廣播的區塊交易集的信息摘要是否相等。若相等,則說明這兩個監督節點所管理分片的領導者下發了一致的數據,當前監督節點維護的有效驗證消息數量加1;若監督節點在超時時間內收到超過K/2 個有效的驗證消息,則向當前分片的所有跟隨者發送確認消息,否則發送領導者重選消息;若監督節點發現此分片的領導者下發的數據與其他大多數分片的領導者不一致時,將向分片內的所有節點發送領導者重選消息。
4)區塊提交。
若分片內的節點收到了監督節點的確認消息,則繼續執行Raft 算法的余下流程,收到領導者的commit 消息時提交日志并將區塊上鏈,否則將會執行Leader election 協議,并重新執行片內共識。片內共識流程如圖4 所示。

圖4 片內共識流程Fig.4 Flow of intra-shard consensus
2.3 K-RPBFT共識流程
客戶端發送至主節點的若干交易被打包成一個區塊,等待完成共識后上鏈。
定義分片數量為K=3f+1,PBFT 主節點編號為p,PBFT 從節點編號為i,當前視圖編號為vId,請求編號為rId,客戶端請求消息為msg,dig(msg)為請求消息msg的摘要,為節點p對msg進行數字簽名,timestamp為時間戳,client為客戶端編號,res為請求的執行結果。
K-RPBFT 算法的共識流程如下:
1)區塊鏈分片。按照2.1 節中的分片策略將區塊鏈分為K個片,開始等待共識。
2)客戶端請求階段。客戶端發送msg到聚類中心節點的主節點(即PBFT 共識集群的主節點),開始進行片間共識。
3)PBFT 預準備階段。PBFT 共識集群的主節點向PBFT從節點廣播預準備消息
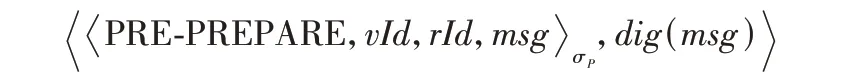
4)PBFT 準備階段。PBFT 從節點會對收到的預準備消息進行檢查,若預準備消息不合法則丟棄。通過檢查后,從節點向其他 PBFT 共識節點廣播準備消息,當節點收到至少2f個不同的PBFT 共識節點的準備消息,且通過合法性檢查后,執行PBFT 確認階段。
5)PBFT 確認階段。當前節點向所有PBFT 共識節點廣播確認消息,同時此節點將會收到其他節點的確認消息,檢查消息簽名、視圖編號、消息序號合法并收到至少2f+1 個不同節點的有效確認消息時,片間共識完成,開始進行片內共識。
6)片內共識階段。此時PBFT 共識節點將作為分片的領導者,執行基于Raft 算法改進的片內共識算法,片內的共識流程見2.2 節。跟隨者完成共識后,向領導者反饋消息,當領導者收到超過一半的跟隨者節點反饋后,確認片內達成共識,此領導者進入PBFT 提交階段。
7)PBFT 提交階段。當PBFT 節點所屬的分片內部共識完成后,此節點向客戶端發送回復消息
K-RPBFT 算法共識的完整流程如圖5 所示。
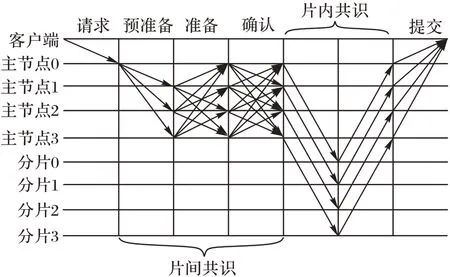
圖5 K-RPBFT算法的共識流程Fig.5 Consensus flow of K-RPBFT algorithm
3 算法分析
K-RPBFT 算法作為一種面向聯盟鏈的共識算法,需要在系統具有少量拜占庭節點的情況下工作。本章對算法的安全性、一致性、活性進行了分析,并對K-RPBFT 算法、PBFT 算法、Raft 算法的通信次數進行了分析與對比。K-RPBFT 算法一定程度上繼承了PBFT 算法與Raft 算法的安全性、一致性與活性;同時,監督節點的引入進一步增強了K-RPBFT 算法的安全性與活性。
3.1 安全性
在片間共識中,PBFT 算法自身的三階段提交過程保證了在拜占庭節點數量小于2/3 時的安全性。如果PBFT 從節點在共識過程中檢測到主節點異常(不響應客戶端請求、故意發送錯誤的請求)時,將會執行視圖切換協議重新選擇主節點。
在片內共識中,監督節點保證了Raft 算法在系統中含有拜占庭節點時的安全性。由于監督節點將會與其他分片的監督節點進行相互驗證,如果分片的領導者向整個分片廣播了錯誤的消息,監督節點將不會向分片中的跟隨者發送確認消息,同時罷免當前領導者并觸發Leader election 協議以確保鏈上信息的正確性;如果領導者向分片發起了一個并不存在的區塊同步請求,監督節點在發出驗證消息后,經過超時時間仍未收到足夠的由其他監督節點發出的驗證消息時,將重置超時時間并觸發Leader election 協議重選領導者;如果Raft 主節點故意攔截區塊同步請求,監督節點在陸續收到其他監督節點的驗證消息時,會感知到主節點異常,進而觸發Leader election 協議重新選舉領導者。
這里對片內共識的拜占庭容錯性進行討論。設分片內的節點數量為n,拜占庭節點數量為f。拜占庭節點在收到領導者的消息m后,可能對其作出錯誤的共識(不處理m或將m替換為偽造消息m′),并且向監督節點發送含有正確消息m的區塊以欺騙監督節點。因此監督節點收到的x個交易集一致的區塊中可能含有f個拜占庭節點發送的區塊,為了確保超過一半的誠實節點收到正確消息m,則x應滿足:

由前文可知,x=3n/4,即:

因此,監督節點的存在能保證分片內拜占庭節點數量小于n/4 時共識的正常進行。
對于監督節點自身而言,由于不能動態加入區塊鏈,且由上層監督者進行指定,因而只存在監督宕機的情況。分片內的從節點將與監督節點之間保持定期的心跳消息以確認監督節點存活,當超時無響應時會觸發重分片,縮減分片數量以保證每個分片至少有一個可用的監督節點。同時,監督節點之間的通信以及監督節點與片內節點之間的通信均采用數字簽名技術[22]以防止消息偽造。
3.2 一致性
根據CAP 定理[23],在一個分布式系統中,一致性(Consistency)、可用性(Availability)、分區容忍性(Partition tolerance)最多只能同時滿足其中兩項。而為了保證系統的高可用,通常根據BASE(Basically Available,Soft state,Eventually consistent)即(基本可用、軟狀態、最終一致性)理論[24]來構建分布式系統。這里的一致性即指最終一致性而并非強一致性。
在片間共識中,PBFT 算法保證了在拜占庭節點數量小于節點總量1/3 時的一致性。在分片內部,Raft 算法的Log Replication 過程保證了片內共識的最終一致性,領導者將通過AppendEntries RPC 將日志同步到跟隨者,并在收到大多數跟隨者的反饋后提交日志。即使有部分節點宕機,在恢復后通過日志復制也能保證所有節點數據的最終一致性。
3.3 活性
PBFT 算法的view-change 協議提供了保證了K-RPBFT 片間共識的活性。當PBFT 主節點無法響應客戶端請求時,會通過p=vIdmodK確定新的主節點編號以推動共識的繼續進行,其中vId為當前視圖編號,K為PBFT 共識節點數量。此外,進行PBFT共識的節點將同時作為片間Raft共識的領導者,而Raft跟隨者會與領導者之間通過心跳消息保持聯系,若超時未響應將觸發Leader election 協議進行領導者重選,新的領導者將替換失效的領導者參加PBFT 共識,加快了PBFT 算法對失效節點的檢測與替換,增強了PBFT 算法的活性。
Raft 算法的Leader election 協議保證了片內共識算法的活性,當跟隨者超時仍未收到領導者的心跳消息時,將轉變為候選者狀態以進行新的領導者選舉,新的領導者將替換原有已失效的領導者,保證共識的繼續進行。
3.4 通信開銷分析
本節對K-RPBFT 算法單次共識所需的通信次數與傳統的PBFT 算法和Raft 算法進行對比。為便于分析,假設區塊鏈的分片數量為K(K≥4),每個分片的節點數量為n(n≥3),可得系統中的總節點數:

1)PBFT 單次共識的通信次數。
若系統中的節點使用PBFT 算法進行一次共識,在預準備階段主節點將向所有從節點發送預準備消息,此過程的通信次數為(N-1)。在準備階段,每一個從節點將向其余節點發送準備消息,此過程的通信次數為(N-1)*(N-1);在確認階段,所有節點將向其他節點發送確認消息,此過程的通信次數為N*(N-1);在回復階段,參與共識的節點將向客戶端發送回復消息,此過程的通信次數為N。因此可以得到PBFT 單次共識的通信次數:

2)Raft 單次共識的通信次數。
若系統中的節點使用Raft 算法進行一次共識,在Log Replication 階段,領導者向所有跟隨者發送包含一個區塊的日志記錄,此過程的通信次數為N-1。跟隨者在收到領導者的日志記錄后,向領導者發送回復消息,此過程的通信次數為N-1;領導者在收到超過一半的跟隨者的回復消息后,向發送客戶端回復消息,并向所有跟隨者發送確認消息以將此區塊提交上鏈,此過程的通信次數為N。因此可以得到Raft 單次共識的通信次數:

3)K-RPBFT 單次共識的通信次數。
若系統中的節點使用K-RPBFT 算法進行一次共識,在片間進行PBFT 共識的通信次數為2K2-K。對于單個分片內部,領導者首先向所有跟隨者以及監督節點廣播區塊,此過程的通信次數為n;然后監督節點將收集所有跟隨者的區塊,此過程的通信次數為(n-1)。在監督節點驗證階段,監督節點將向其余分片的監督節點廣播驗證消息,此過程的通信次數為(K-1);在提交階段,監督節點將向所有跟隨者發送確認消息,然后跟隨者向領導者發送消息,此過程的通信次數為2(n-1)。因此可以得到K-RPBFT 單次共識的通信次數:
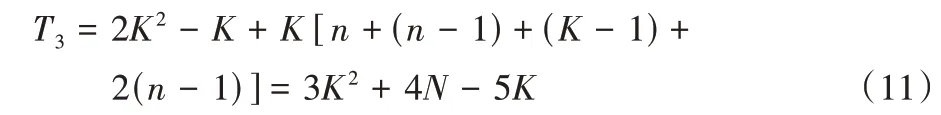
由分析可知,相較于PBFT 單次共識O(N2)的通信復雜度,K-RPBFT 的通信復雜度僅為O(N+K2)。圖6 為不同節點數量下算法的單次共識通信次數對比。可以看出,隨著節點數量的增加,PBFT 算法的單次共識通信次數將大幅增加,當節點數量為40 時,需要進行超過3 000 次通信才能達成共識。K-RPBFT 的單次共識通信次數與Raft 算法非常相近,遠小于PBFT 算法且增長十分緩慢。

圖6 通信次數對比Fig.6 Comparison of communication times
表1 為節點數量N為100 時K-RPBFT 的通信次數,當分片數量為4 時取得最小通信次數428,而此時PBFT 算法完成一次共識需要進行19 900 次通信。隨著分片數量的增多,片間參與PBFT 共識的節點數量將會相應增多,導致K-RPBFT算法單次共識的通信次數上升,但仍遠小于PBFT 算法。
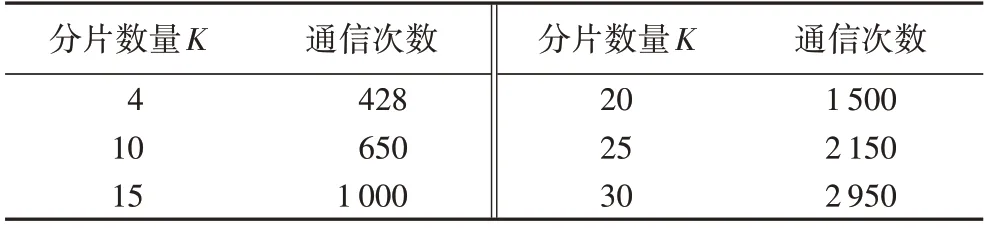
表1 節點數量為100時K-RPBFT算法的通信次數Tab.1 Communication times of K-RPBFT algorithm when the number of nodes is 100
因此,K-RPBFT 顯著降低了單次共識的通信次數,當系統中具有100 個節點時,相較于PBFT 算法,K-RPBFT 能使通信次數降低兩個數量級,且隨著節點總量的增加,這種優勢將更加明顯。
4 仿真實驗
為了驗證K-RPBFT 算法的有效性,本文使用Netty 4.1.42 作為網絡通信組件,Java 作為編程語言實現了本算法,通過在同一設備上監聽多個不同的TCP 端口模擬多節點環境。本章從共識時延、吞吐量等方面與PBFT 算法、Raft 算法進行了比較。此外,由于RapidChain 共識算法在性能和安全性上已經達到了較好的效果,因此本章對K-RPBFT 與Rapidchain 進行了對比。
4.1 共識時延測試
共識時延是衡量算法性能的重要指標,指客戶端發起請求到區塊被確認上鏈所需的時間。在實驗中K-RPBFT 共識時延的計算公式為:
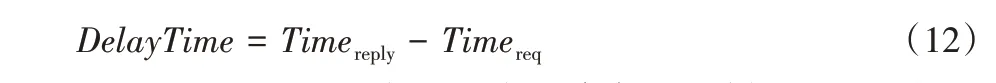
式中:Timereq表示客戶端發起共識請求的時刻,Timereply表示客戶端收到足夠的PBFT 回復消息的時刻。
取多次實驗數據的平均值作為共識時延,并與PBFT 算法、Raft 算法進行對比。算法的共識時延對比測試結果如圖7 所示。由圖7 可知,三種算法的共識時延隨著節點數量的增加均逐漸增大,但K-RPBFT 與Raft 的時延增加較為緩慢,PBFT 的時延增加較為劇烈。K-PBFT 算法的共識時延與Raft相近,當節點數量為12 時,PBFT 的共識時延約為K-RPBFT的2.5 倍,而當節點數量增加到40 時,PBFT 的共識時延超過了K-RPBFT 的4.5 倍。因此K-RPBFT 算法在大規模節點的環境下能顯著降低共識時延。

圖7 共識時延對比Fig.7 Comparison of consensus latency
4.2 吞吐量測試
吞吐量指系統在單位時間內處理的事務數量,在區塊鏈領域中通常用每秒完成的交易數量(Transactions Per Second,TPS)來計算,即:

其中:Δt為出塊時間,TransactionΔt為出塊時間內處理的交易總量。吞吐量不僅與節點數量有關,還與區塊中包含的交易數量有關,因此進行兩組不同的實驗對算法的吞吐量進行驗證。
實驗一 將每個區塊中包含的交易數量固定為1 000,將系統中參加共識的節點設置為12~36,取多次實驗數據的平均值作為吞吐量實驗結果,并與PBFT 算法、Raft 算法進行對比,實驗結果如圖8 所示。由圖8 可以看出,算法的吞吐量均隨著節點數量的增加而呈下降趨勢,但K-RPBFT 算法的吞吐量仍然遠高于PBFT 算法,且與Raft 算法相近。

圖8 不同節點數量下的吞吐量對比Fig.8 Comparison of throughput under different node numbers
實驗二 將系統中參加共識的節點固定為12 個,將每個區塊中包含的交易數量設置為1 000~4 000,取多次實驗數據的平均值作為吞吐量實驗結果,并與PBFT 算法、Raft 算法進行對比,實驗結果如圖9 所示。由圖9 可以看出,K-RPBFT算法的吞吐量與Raft 算法較為接近。當區塊中的交易數量沒有超過節點的處理能力時,各算法的吞吐量均隨著交易量的增加而提升。交易數量為1 000,K-RPBFT 算法相較于PBFT 算法能夠提升700 左右的吞吐量,且隨著交易數量的增加,吞吐量的提升更加明顯。吞吐量的最大值在交易量為3 000 左右時取得,此時K-RPBFT 的吞吐量約為PBFT 的3.5倍。受限于實驗設備的處理能力,當區塊中的交易數量超過3 000 時,此時繼續向區塊中增加交易將會使算法的吞吐量均有所下降,但K-RPBFT 算法的吞吐量仍然高于PBFT算法。
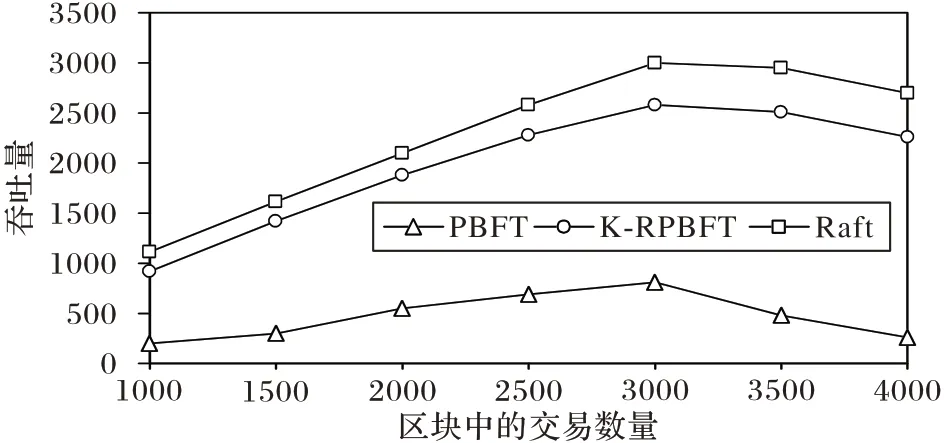
圖9 不同交易數量下的吞吐量對比Fig.9 Comparison of throughput under different transaction numbers
因此,K-RPBFT 算法擁有比PBFT 更大的吞吐量,能夠在單位時間內處理更多的事務,適用于對吞吐量要求較高的聯盟鏈環境。
4.3 K-RPBFT與RapidChain的對比
RapidChain 是 由Zamani 等[17]于2018 年提出的共識算法,對比的數據來自于文獻[17]中所給出的實驗數據。
兩種算法的吞吐量與共識時延對比結果如圖10 所示。在吞吐量方面,K-RPBFT 的吞吐量整體上大于RapidChain 的吞吐量,兩者吞吐量差值的最大值在區塊大小為512 KB 時取得,此時RapidChain 的吞吐量僅為K-RPBFT 的70%,隨著區塊的增大,兩者的差距有所減小,但K-RPBFT 的吞吐量仍大于RapidChain 的吞吐量;在共識時延方面,K-RPBFT 的共識時延整體上小于RapidChain 的共識時延,RapidChain 的共識時延是K-RPBFT 的1.4~1.7 倍。

圖10 兩種算法的吞吐量與共識時延對比Fig.10 Comparison of throughput and consensus latency between two algorithms
在容錯性方面,由于RapidChain 的委員會內部共識本質上還是基于PBFT 算法,因此RapidChain 的容錯率為N/3(N為參與共識的節點數量),與PBFT 算法的容錯率一致。由于K-RPBFT 算法在片內共識引入了Raft 算法,盡管對Raft 算法的共識過程進行了改進,但K-RPBFT 算法的容錯性仍然小于PBFT 算法。通過第3 章的算法分析可知,K-RPBFT 的片內容錯率為n/4(n為片內節點數量)。因此,K-RPBFT 算法的容錯性弱于RapidChain 算法。
通過以上分析可以發現,K-RPBFT 算法首先通過K-medoids 算法將區塊鏈分片,并且在片內共識中引入基于監督節點改進的Raft 算法,使K-RPBFT 算法在性能方面優于RapidChain 算法,但是安全性低于RapidChain 算法。
5 結語
本文提出了一種基于PBFT 與Raft 算法改進的共識算法模型K-RPBFT,該算法較好地結合了PBFT 算法支持拜占庭容錯與Raft 算法共識效率較高的特性,并使用K-medoids 算法將全局共識改進為多中心化的兩層共識。實驗結果表明,K-RPBFT 算法的單次共識通信次數與共識時延均小于PBFT算法,且具有更高的吞吐量,更適用于擁有大規模網絡節點的區塊鏈環境,能夠有效解決現有聯盟鏈共識算法可擴展性不足的問題。
目前K-RPBFT 算法仍處于實驗階段,未來將進一步完善算法細節與性能,并將該算法應用到某一具體的區塊鏈系統中,同時也會考慮將多中心兩層次的K-RPBFT 算法衍進為多中心多層次化的結構,進一步提升在大規模節點下區塊鏈的共識效率,以推動區塊鏈技術的不斷發展。
猜你喜歡
新作文·小學低年級版(2022年3期)2022-08-30 07:40:58
公民與法治(2020年15期)2020-09-25 02:57:42
人大建設(2020年4期)2020-09-21 03:39:12
公民與法治(2020年3期)2020-05-30 12:29:40
當代陜西(2019年12期)2019-07-12 09:12:22
消費導刊(2018年10期)2018-08-20 02:57:12
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
公民與法治(2016年13期)2016-05-17 04:14:35
浙江人大(2014年5期)2014-03-20 16:20:28
