基于雙向循環生成對抗網絡的無線傳感網入侵檢測方法
2023-02-03 03:02:04劉擁民楊鈺津羅皓懿謝鐵強
計算機應用 2023年1期
劉擁民,楊鈺津,羅皓懿,黃 浩,謝鐵強
(1.中南林業科技大學 計算機與信息工程學院,長沙 410004;2.中南林業科技大學 智慧林業云研究中心,長沙 410004)
0 引言
無線傳感器網絡(Wireless Sensor Network,WSN)的應用前景非常廣闊,如森林火災檢測、自動駕駛汽車和智能電網等[1-3]。WSN 主要負責從物理環境采集數據,將收集到的數據傳輸到互聯網數據中心或網絡云端進行處理。隨著第五代移動通信技術(5th Generation mobile communication technology,5G)的推廣以及物聯網應用的擴充造成WSN 數據激增,WSN 面臨多方威脅。由于WSN 節點資源受限、部署策略和通信信道開放等特性,WSN 系統在數據的采集和傳輸過程中易受到各種類型的入侵攻擊,其中對數據進行的攻擊常常導致數據損壞;而對網絡結構、路由的攻擊則可能導致網絡功能喪失,甚至停止服務、網絡崩潰。面對上述威脅,入侵檢測是一種能夠保障安全的主動防御技術,它能監測通信網絡中的各種類型的入侵活動,并自動檢測各種入侵企圖[4],預警內部和外部的攻擊。入侵檢測系統分為基于規則的和基于行為的[5]兩種類型,前者基于已知惡意流量既定的屬性,后者側重于與正常樣本特征的偏差。基于規則的入侵檢測系統對識別新攻擊的效果不佳,相比之下,基于行為的入侵檢測能更有效地將各種偏離正常的行為捕獲為異常。
在過去,研究者們提出了許多方法來設計WSN 入侵檢測系統。Selvakumar 等[4]使用Allen 區間代數和模糊粗糙集特征選擇算法實現了一種自適應的入侵檢測機制,通過選擇大量的攻擊數據對WSN 進行有效的攻擊預測。結果表明,與標準模型相比,該方法提高了檢測精度,降低了誤報率,但它需要通過使用基于遺傳的特征才能進一步提高性能。Sun等[6]引入否定選擇算法(Negative Selection Algorithm,NSA)改進V-detector 入侵檢測模型,通過修改檢測器生成規則和優化檢測器來改進V-detector 算法,并使用主成分分析來減少檢測特征。Kalnoor 等[7]使用模式匹配技術檢測入侵者,將提取的特征與現有模式進行比較,如果在模式匹配過程中出現偏差,則認為是異常的,然而,對于大型網絡該過程過于復雜,因此不適用于大型無線傳感網絡。Borkar 等[8]提出了ACSO(Adaptive Chicken Swarm Optimization)模型,以突破聚類方法中的限制,還提出了一種基于自適應支持向量機的入侵檢測分類模型來檢測不同類型的攻擊。雖然該模型融合了聚類技術提高網絡效率,減少了時間消耗,提高了預測精度,但在解決高維優化問題時,容易陷入局部最優。Otoum等[9]提出了通過受限玻爾茲曼機入侵檢測結構來保護WSN,分析了基于深度學習的入侵檢測系統在WSN 中應用的可行性,并與自適應機器學習的入侵檢測方法進行了比較,實驗結果表明,構建的入侵檢測結構檢測率更高,但檢測時間增加了一半。Gavel 等[10]將數據出現概率與全局概率密度函數相結合,判斷網絡中的入侵事件,并引入了皮爾遜散度以提高檢測精度,降低假陽性率,但是,該研究沒有考慮入侵的不平衡性。
隨著5G 的應用和物聯網的感知數據流量的增加,大規模、多維度的數據源源不斷地產生,攻擊場景變得更加復雜。現有WSN 入侵檢測方法在取得一定成果的同時,也存在著處理高維、多樣、不平衡數據時效果不佳,泛化能力不強的問題。針對以上問題,機器學習技術被應用于WSN 的入侵檢測系統中。基于傳統機器學習的WSN 入侵檢測方法如K 近鄰[11]、支持向量機[12]、決策樹[13]以及隨機森林[14]等存在許多局限性,如決策樹的運行需要足夠的內存,因此不適用于太大的數據集;而支持向量機在處理高維數據時很耗時。正常和異常樣本數量之間的不平衡性會給這些基于統計學習模型的判斷帶來偏差;在數據的預處理和標記方面需要做大量的工作;它們的訓練都必須是基于已知攻擊類型的,對于未知攻擊的檢測能力非常弱。
WSN 數據具有高維、不平衡的特點。在以往的研究中,較大的數據集和高維特征數據可能會降低入侵檢測系統的性能[4],隨著深度學習的發展,基于深度學習的異常檢測方法以其良好的性能得到了廣泛的應用[15]。例如,深度自動編碼高斯混合模型[16]、長短期記憶(Long Short-Term Memory network,LSTM)編碼器-解碼器[17]、深度自編碼器與生成對抗網絡(Generative Adversarial Network,GAN)的混合模型[18]顯示出多元異常檢測的良好性能。然而,入侵檢測系統在對抗性例子下逐漸暴露其脆弱性,攻擊者試圖通過使用對抗的惡意流量,欺騙模型進行錯誤分類。GAN 是抗衡、甚至是反制這種對抗攻擊的潛在方法,通過GAN 可以增加入侵檢測系統的魯棒性[19]。GAN 是由Goodfellow 等[20]最早提出生成模型中的一種,目前,主要應用于計算機視覺、時間序列和文本生成等領域[21-23]。在圖像數據中,特定特征周圍的特征通常相互關聯。然而,網絡數據流的特征大多是獨立的特征,這些特征之間相關性不強。在這種情況下,經典的卷積核對特征提取的影響很小,因此本文采用了帶有Dropout 操作的全連接層來構建網絡。將GAN 應用于異常檢測任務是通過學習正常狀態的分布,然后通過測試樣本和學習到的分布之間的差異,來判斷測試樣本是否為異常狀態。盡管GAN 適用于模擬現實世界數據的高維復雜分布[24],但GAN 在異常檢測中的應用還相對較少。Schlegl 等[25]最早提出的AnoGAN(Anomaly detection with GAN)方法基于深度卷積對抗網絡(Deep Convolution GAN,DCGAN),通過建立真實空間和潛在空間之間的映射來更好地提取正常樣本的特征,但當數據維數增加時,基于反向傳播算法的映射時間成本很高。Donahue 等[26]提出BiGAN(Bidirectional GAN),當生成器學習潛在空間到真實空間的映射時,編碼器同時學習從真實空間到潛在空間的映射,該方法通過加入編碼器顯著降低了時間成本,但檢測效率不高。Zenati 等[27]提出了對抗學習異常檢測(Adversarially Learned Anomaly Detection,ALAD),在加入編碼器的基礎上,改進了判別器,因此能更快、更有效地進行推理,異常檢測性能也顯著提高,并且擅長處理高維特征數據。
針對WSN 入侵檢測任務,ALAD 方法仍然存在局限性,離散特征的數據會導致GAN 訓練過程中出現不穩定,模式崩潰的問題[28],只能簡單地提取一些局部特征,因而只能學習到一個不完全分布,在處理多樣性的WSN 入侵流量數據問題上比較困難[29]。為擺脫這種困境,本文提出一種基于雙向循環生成對抗網絡的無線傳感網入侵檢測方法——BiCirGAN(Bidirectional Circulation Generative Adversarial Network),利用雙向異常檢測結構[27],結合譜歸一化方法[30]和Wasserstein 距離[28]改進GAN 的目標函數,并對異常評分進行優化。在KDD99、UNSW_NB15 和WSN_DS 數據集上的實驗結果表明,本文方法在具有離散高維特征的不平衡數據集上的精確度高于其他經典方法,具備更加優異的性能。
1 WSN結構及入侵檢測模型
WSN 為多跳分布式網絡,由多個簇群組成,每一個簇由簇頭節點和傳感器節點組成,簇頭為每個簇中的匯聚節點,且由資源豐富的節點擔任。簇內感知節點將采集的數據傳輸到簇頭節點,簇頭節點對本簇內的感知數據進行處理后轉發至基站,如圖1。采用分層結構的WSN 可對網絡流量進行分布式檢測,能分散能量開銷減輕通信負擔,實現節能[31]。
基于互聯網的信息處理系統面臨著各種各樣的威脅,這些威脅會導致系統被破壞,進而導致WSN 中的信息嚴重丟失;此外,通過WSN 進行數據通信的流量也在不斷增加,如此大量的數據自然成為了攻擊者的目標,因此確保通過互聯網進行安全有效的信息交流至關重要。如圖1 所示,WSN 受到的攻擊可能來自互聯網、鄰近的WSN 或是本身的WSN 內部,對于資源受限的傳感器節點而言,檢測WSN 中的入侵行為是一個挑戰。由于基站(Base Station,BS)具有充足的能量和強大的運算能力,因此本文在基站上設置入侵檢測系統,監控流量并訓練入侵檢測模型,對攻擊進行檢測,無需傳感器節點(Sensor Node,SN)花費額外的能量參與入侵檢測。
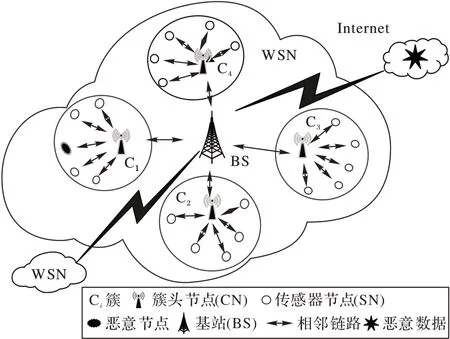
圖1 與互聯網連接的WSN的分布式分層系統Fig.1 Distributed hierarchical system of WSN connected with Internet
針對這種WSN 的結構,傳統的檢測方法在檢測數據的海量性、高緯度與多樣性上非常受限,無法有效地平衡檢測模型在時間尺度與檢測準確率上的一致性,引言中介紹了基于GAN 的方法能有效擺脫這種困境。如圖2 所示,本文提出的BicirGAN 模型分為以下幾個階段:1)數據預處理階段,WSN 中的簇頭節點(Cluster Node,CN)每隔一段時間將收集的傳感數據發送給無線網絡中的基站,基站調整初始流量數據的格式并對調整后的數據進行數值化和歸一化處理;2)訓練與檢測階段,使用預處理好的訓練數據集訓練入侵檢測模型,通過BiCirGAN 從大量流量數據中區分異常數據,對可疑數據作進一步檢測,整個訓練過程通過多次調整方法參數提高檢測率;3)評估階段,通過檢測的結果評估訓練后的入侵檢測模型,如果檢測率能滿足實際應用需求,則停止訓練,否則重復階段2)對BiCirGAN 進行訓練。

圖2 WSN入侵檢測模型訓練流程Fig.2 Training flow of WSN intrusion detection model
2 基于改進GAN的無監督入侵檢測方法
2.1 雙向異常檢測方法
GAN 由生成器Ge和判別器Di組成。Ge將從潛在空間(通常是高斯分布或均勻分布)中采樣的隨機變量z映射到真實空間,生成類似真實數據的正常樣本,Di嘗試區分真實數據樣本x與Ge生成的樣本Ge(z)。二者對抗博弈完成訓練。博弈采用的是最大最小博弈,目標函數為:

其中min maxV(Di,Ge)表示:對于判別器Di,訓練目標是使函數V取到最大值;而對于生成器Ge,訓練目標是最小化V的值。E 表示數學期望,pX是數據x在真實空間X的分布,pZ為潛在生成器變量z在潛在空間Z的分布。固定的Ge,最優判別器為:

當且僅當pGe(x)=pX(x)時,Ge和Di同時達到全局最優。
在異常檢測中,為了提高計算效率采用對抗性學習異常檢測,提高GAN 的學習速度以及方法的整體異常檢測性能,結構如圖3,ALAD 方法包含一個生成器Ge、一個編碼器En和三個判別器Dixz,Dixx,Dizz。ALAD 方法的目標函數為:
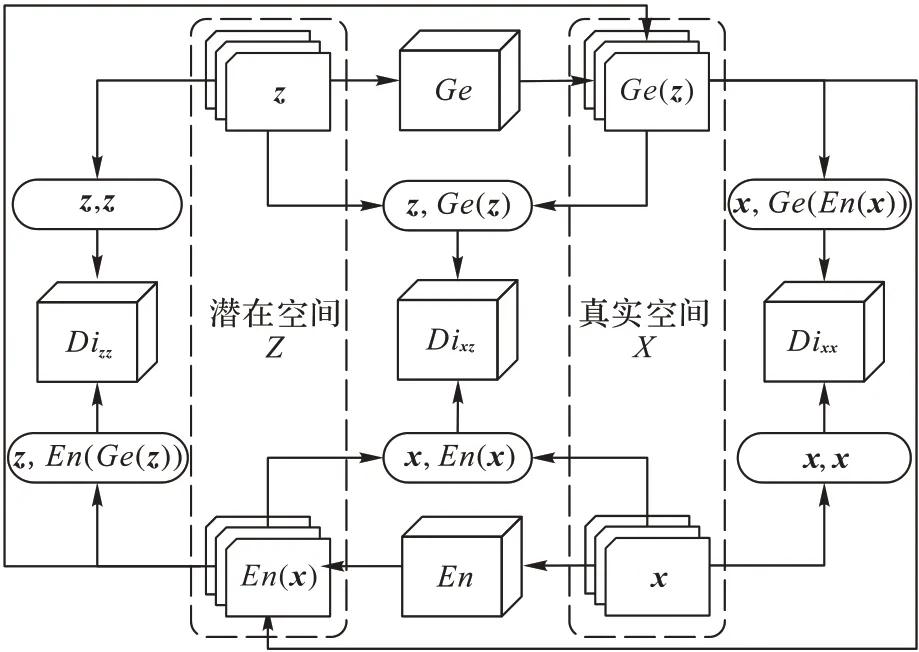
圖3 ALAD方法結構Fig.3 Structure of ALAD method

在ALAD 方法基礎上,引入自適應矩估計梯度下降法不斷降低三個判別器的損失,組合網絡流量數據間各種有效的特征來進行對抗學習,以縮小潛在空間分布與真實空間分布的差距。BiCirGAN 具體結構信息如下:
1)編碼器En。編碼器En將輸入的x∈X映射到潛在空間得到編碼樣本En(x),解碼器Ge將En(x)映射回真實空間,從而重構特征Ge(En(x))。En是一個非線性函數映射的多層感知機(Multi-Layer Perceptron,MLP),由兩層神經網絡組成,每層都是全連接層,神經元個數逐層遞減。

其中:WEn表示En的權重矩陣;bEn表示En的偏移矢量矩陣;σEn表示En的激活函數。
2)生成器Ge(解碼器)。生成器Ge將隨機采樣的z∈Z映射到真實空間生成特征Ge(z),編碼器En將Ge(z)映射回潛在空間得到En(Ge(z))。Ge由全連接的三層神經網絡組成,第一層神經元個數為潛在特征空間維度,第三層的神經元個數為真實空間中原始數據的特征維度。

其中:WGe表示Ge的權重矩陣;bGe表示Ge的偏移矢量矩陣;σGe表示Ge的激活函數。
3)判別器Dixz為核心判別器,采用帶有Dropout 操作的全連接層來構建網絡。concat(x,En(x))和concat(Ge(z),z)作為輸入進行對抗學習,得到帶有判別信息的潛在表示。生成特征與潛在表示的聯合概率分布分別為:

4)判別器Dixx。聯合輸入concat(x,Ge(En(x))) 和concat(x,x)到判別器Dixx進行對抗學習,能有效降低重新構建特征信息的損失。本文借鑒Li 等[32]提出的Hπ(x|z)=(其中π(x,z)代表x和z上的聯合分布),使Dixx近似Ge和En的條件熵,從而促進循環達到一致性,目標函數為:

5)判別器Dizz。concat(z,z)和concat(z,En(Ge(z)))作為輸入進行對抗學習,使生成的樣本更具多樣性,從而提高GAN 的學習能力以及穩定性,目標函數為:

2.2 目標函數優化
對于網絡入侵檢測中的離散特征數據,JS 散度(Jensen-Shannon divergence)有其局限性。對于用0-1 表示的邏輯特征與用One-Hot 編碼或Dummy 編碼的非數值特征,維度擴展可能非常嚴重,造成真實樣本和生成樣本之間幾乎沒有重疊。當兩個分布幾乎沒有重疊時,JS 散度將不可避免地收斂到一個常數,導致梯度消失的發生。
針對上述問題,WGAN(Wasserstein Generative Adversarial Network)方法利用Wasserstein 距離代替了JS 散度來衡量兩個分布的差異,該方法在離散分布上也表現良好,有助于改善區分過程,也有助于改善生成過程,從而生成更穩定、更優質的結果。即使兩個沒有重疊的分布,Wasserstein 距離仍然能夠反映其遠近。該模型的目標函數為:

其中f表示滿足1-Lipschitz 約束的任意函數,也稱Critic,1-Lipschitz 約束定義為:

這一約束的作用在于對相鄰的兩點x1和x2,函數值f對數據不會過度敏感。
WGAN 使訓練過程更加穩定,避免了模式坍塌的發生。WGAN 的目標函數中的函數f可以通過神經網絡模型來估計,要使每一層的神經網絡都滿足1-Lipschitz 約束,通過證明與推導只需要約束參數w:

WGAN 模型提出了參數裁剪(weight clipping)來約束參數的范圍,使f的w保持在[-c,c]范圍,但用這種方法訓練出來的模型過于簡單,生成能力較差,還很容易造成梯度消失或梯度爆炸。
本文采取譜歸一化來約束參數范圍。譜歸一化約束是通過約束Critic的每一層網絡的權重矩陣的譜范數來約束Critic的1-Lipschitz,這樣增強了GAN 在訓練過程中的穩定性。譜范數(Spectral Normalization)的定義為:

其中‖W‖s為權重矩陣W的最大特征值(maximum singular value)。對式(14)進行調整得到:

結合式(11),譜范數能更準確地反映1-Lipschitz 約束,使權重矩陣W與譜范數‖W‖s的比值等于1,得到譜歸一化:

結合WGAN 的目標函數,將ALAD 模型的目標函數修改為:
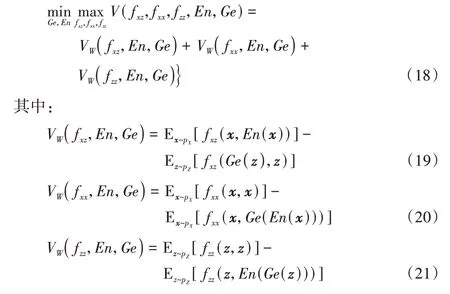
通過式(18)~(21)生成的潛在空間特征的Wasserstein 距離,可以使生成的潛在空間特征更接近真實空間特征,從而生成更高質量的網絡流量數據。此外添加譜歸一化穩定GAN 的訓練,能使模型更快地收斂。
2.3 異常評估
測試樣本和正常樣本的學習分布之間的差異越大,測試樣本越可能異常,因此可以通過差異來評估樣本,而不需要直接評估生成器生成的結果。結合Li 等[22]與Zenati 等[27]提出的計算異常分數方法,本文提出的異常率為:

其中:A表示異常率,A值越大樣本異常的概率越高;n代表樣本個數,λi為一個常數;LRi為重建損失,用來衡量測試樣本和生成樣本之間的差異;xi是輸入樣本,Ge(En(xi)是通過生成器重建的樣本;LDi是從真實的數據分布中得到的判別損失。在判別損失中,fxxj(·,·)表示給定輸入樣本對的判別器Dixx網絡中的特征層,k代表中間層層數,中間層產生的損失也稱為特征匹配損失[26],如圖4 所示。

圖4 訓練損失Fig.4 Training loss
異常的評估取決于生成樣本與原始樣本分布的距離,即生成器從潛在空間學習特征分布的能力,本文綜合考慮了判別與重構損失,增強了模型識別正常樣本與異常樣本的能力,提高了異常檢測精度。
關于異常率,一種方法是在檢測中確定一個閾值來判斷樣本是否異常入侵。這種方法適用于在線檢測,因為不需要了解正常樣本和異常樣本的比例,只需要從經驗中獲得的閾值。第二種方法將高于污染率c(異常/(正常+異常))的相關樣本標記為異常入侵,通常應用于數據集上的測試。由于本文的實驗是在數據集的基礎上進行仿真測試的,因此采用第二種方法來評估模型的異常檢測率。
3 實驗與結果分析
本章從對比實驗、消融實驗和可視化實驗來分析BiCirGAN 的檢測性能。此外,通過計算方法的執行時間來評估方法的實時檢測效率。
3.1 實驗環境、數據集與預處理
實驗環境基于Windows 操作系統,使用Python 語言,在Pytorch 框架上搭建方法,主要硬件環境為CPU Intel Core i7-4710HQ,內存8 GB,GPU NVIDIA GeForce GTX 860M。
實際上,目前的WSN 仍處于建設的初級階段,難以進行大規模的物理測試。為了充分評估和驗證所提出的方法,實驗使用公開權威數據集:KDD99 數據集[27]、UNSW-NB15 數據集[33]、WSN_DS 數據集[34]。
首先對數據集進行預處理。KDD99 數據集中每條記錄包含41 個固定的特征屬性和1 個類標識,在41 個固定的特征屬性中,9 個特征屬性為離散型,對其進行One-hot 編碼后,總共獲得121 個特征。UNSW-NB15 數據集每條記錄包含49個特征,對其中3 個離散特征使用One-Hot 進行編碼,總共得到196 個特征。WSN_DS 數據集為無線傳感器網絡入侵檢測系統專用數據集,該數據集的數據特征是基于WSN 中的LEACH(Low Energy Adaptive Clustering Hierarchy)路由協議,選擇其中的18 個無標簽特征屬性作為實例特征。對數據集選取的樣本的統計詳見表1。

表1 數據集描述Tab.1 Data set description
流量數據歸一化可以消除不同維度數據之間的差異,保證訓練結果的可靠性。本文采用最小-最大值歸一化方法處理數據:

其中Qi,j代表數據集的第i行和第j列中的特征值。
3.2 評價指標
采用經典網絡異常檢測系統研究相同的評估方法。為測量基于GAN 的WSN 入侵檢測模型的性能,使用精確度Prec(Precision)、假陽性率(False Positive Rate,FPR)、召回率Rec(Recall)和F1 分數F1(F1 score),計算如式(24)~(27)所示。異常檢測的分類混淆矩陣,如表2 所示。


表2 異常檢測分類混淆矩陣Tab.2 Anomaly detection classification confusion matrix
3.3 實驗參數設置
不同數據集下相關參數設置如表3 所示。其中:learning_rate表示學習率;batch_size代表每一批次的大小;latent_dim為潛在空間的維度;nb_epochs表示迭代的次數。

表3 數據集參數Tab.3 Parameters of datasets
模型的網絡參數依據數據集維度進行設置,如表4 所示,其中:units表示神經元個數;σ表示激活函數;Dropout表示丟失率,連接方式為全連接。

表4 不同數據集下網絡參數設置Tab.4 Network parameter settings under different datasets
3.4 實驗結果分析
3.4.1 對比實驗
BiCirGAN 方法與以下4 種方法進行對比:1)AnoGAN[25]是基于生成對抗網絡異常檢測最常見的方法;2)BiGAN[26]首次在生成對抗網絡上引入了編碼器;3)MAD-GAN(Multivariate Anomaly Detection with GAN)[22]是基于GAN 的多變量時間序列異常檢測方法,以LSTM 為基本方法來捕獲時間上的依賴關系,并將其嵌入到GAN 的框架中;4)ALAD[27]是一個基于雙向GAN 的異常檢測方法。
5 個方法在3 個數據集的對比實驗結果如表5 所示,BiCirGAN 的效果最好,檢測精確度提高了3.9%~33.0%。說明在充分考慮潛在空間分布合理性的前提下,BiCirGAN 能夠有效地發揮深度生成學習方法的優勢,在高維、樣本多樣、數據量多的UNSW-NB15 數據集和不平衡數據較多的WSN_DS 數據集上有效提升精確度、召回率、F1 分數,假陽性率(誤報率)也有所下降。

表5 基于GAN模型的異常檢測模型在3個數據集上的評估結果Tab.5 Evaluation results of anomaly detection models based on GAN model on three datasets
3.4.2 消融實驗
為驗證模型各部分的有效性,在KDD99、UNSW-NB15、WSN_DS 數據集上進行了BiCirGAN 的消融實驗,不同模型的組合如下:1)ALAD+JS 模型:應用改進后的ALAD 網絡結構,目標函數使用原始的JS 散度衡量異常與正常兩個分布之間的差距。2)ALAD+WD 模型:應用改進后的ALAD 網絡結構,目標函數采用Wasserstein 距離衡量異常與正常兩個分布之間的差距,通過WGAN 原始的參數裁剪來約束參數。3)BiCirGAN 模型:在模型2)的基礎上,添加譜歸一化對WGAN 進行參數約束。結果如表6 所示。
從表6 中可見,將JS 散度替換成用Wasserstein 距離衡量異常和正常兩個分布之間的距離,性能反而降低,是因為WGAN 的參數裁剪導致訓練的不穩定,沒能充分學習數據的分布。在UNSW-NB15 數據集上,BiCirGAN 方法相較于ALAD+JS 方法,Pre、Rec、F1 指標分別提高了6.74%、5.71%、7.58%;在WSN_DS 數據集上Pre、Rec、F1 分別提高了4.16%、1.85%、3.04%,在KDD99 數據集Pre、Rec、F1 分別提高了3.70%、1.00%、2.34%。從評價指標上來看,在維度更高、數據類型更多的UNSW-NB15 數據集上,效果更好,在不平衡的WSN_DS 數據集上效果次之。實驗結果表明BiCirGAN 方法不僅能學到更好的特征分布,在處理高維、樣本類型多樣以及不平衡數據上效果會更佳。
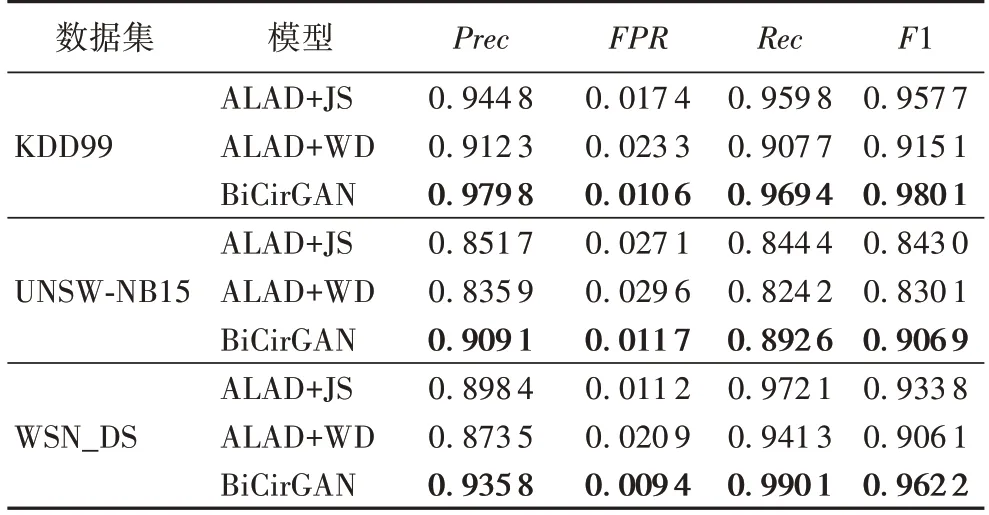
表6 消融實驗評估結果Tab.6 Evaluation results of ablation experiment
3.4.3 訓練效率實驗
繪制出在KDD99 數據集上訓練迭代100 次的判別器損失圖,如圖5 所示,可以看出當生成器最小化時,BiCirGAN 方法相較于ALAD 收斂得更快,在50 代左右損失值已經達到比較低的水平。

圖5 判別器模型損失值變化Fig.5 Discriminator model loss value change
即使一個方法在檢測中可以達到非常好的效果,檢測延遲依舊是一個重要的考慮因素,如果檢測過程花費了過多的時間,攻擊方仍然有足夠的時間來損壞系統。由于BiCirGAN 是在ALAD 方法網絡結構上進行優化的,因此選擇其作為基準對推斷時間進行比較。在不同數據集上兩個方法的平均推斷時間比較如表7 所示,實驗結果表明,與ALAD方法相比,BiCirGAN 對數據的平均推斷時間更短,在UNSWNB15、WSN_DS 數據集上分別為ALAD 的1/4.57 和1/4.67,因此新方法在高維離散不平衡的網絡數據的異常檢測上較ALAD 方法的效率更高。

表7 平均推斷時間Tab.7 Average inference time
3.4.4 可視化實驗
為了探索BiCirGAN 對異常數據的檢測能力,實驗對BiCirGAN 與ALAD 方法在UNSW-NB15 測試數據集上分別進行了異常率的計算,如圖6 所示。

圖6 測試樣本異常率分布Fig.6 Test sample anomaly rate distribution
在BiCirGAN 的異常率分布結果中,正常與異常分布邊界(c)清晰明顯,重合分布較少,正常樣本和異常樣本在異常率下進行了有效的聚集。對比ALAD 方法的異常率分布與本文方法在可視化上有著明顯的差距,重合分布較多,如圖6(a)。這說明BiCirGAN 較ALAD 方法在網絡異常數據上能學習到更高質量的特征分布,從而給出更加準確的異常率的值。
上述實驗表明,BiCirGAN 在各項評價指標中均有提升,且針對網絡高維數據異常檢測的改進有效、訓練更加穩定、收斂更快、檢測效率更高且能更好地完成正常樣本與異常樣本的分離,在高維、離散、不平衡的WSN 網絡流量數據的異常檢測上表現出更加優異的檢測性能。
4 結語
本文提出了一種雙向循環生成對抗網絡的入侵檢測方法BiCirGAN,能對復雜網絡環境下的WSN 中的異常數據進行有效的檢測。該方法考慮到潛在空間表示分布的約束條件,引入了改進的ALAD 方法,通過雙向內循環訓練機制將高維性、多樣性以及不平衡性的數據集通過潛在空間合理地表示出來,進而提高了異常檢測的有效性;考慮了離散數據特征的重疊分布,結合Wassertein 距離和譜歸一化改進目標函數,解決了GAN 訓練的模式崩壞與不穩定等問題。實驗結果表明該方法各項檢測性能均高于對比方法,在訓練中更加穩定,并且大大減少了測試過程中的時間成本,降低了計算資源的消耗。
但在數據少量的情況下,本方法效果較為一般。在下一步的工作中,本研究將對WSN 特定類型的攻擊進行分類,此外盡管已經驗證了該方法在KDD99、UNSW-NB15、WSN_DS數據集下的實驗結果,但仍有必要進一步改進方法以應對訓練數據集不足以及更復雜的無線傳感網絡傳輸環境。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
