手繪草圖到服裝圖像的跨域生成
2023-02-16 06:35:36楊聰聰劉軍平何儒漢梁金星
紡織學報 2023年1期
陳 佳,楊聰聰,劉軍平,何儒漢,梁金星
(1.武漢紡織大學 計算機與人工智能學院,湖北 武漢 430200;2.湖北省服裝信息化工程技術研究中心,湖北 武漢 430200)
服裝設計是將設計美學和自然美應用于服裝及其配飾的技藝,它追求實用美,是一種以人體為對象,以材料為基礎,與各種機能性相結合的創造性行為。服裝設計師不僅要對大眾的生活方式和客戶的需求有很好的了解,還要能夠清晰地表達自己的想法。最重要的是,他們必須非常具有原創性,并有創新的想法。其中服裝草圖是設計師創作意圖的集中體現,設計師首先通過構思畫出服裝草圖,然后在服裝草圖基礎上設計出服裝效果圖;但這需要消耗設計師大量的時間和精力,因此,本文將研究通過深度學習技術來實現將缺少顏色和細節的服裝草圖自動生成服裝效果圖。
傳統的由草圖到圖像的生成主要采用圖像檢索方法, 如Chen等[1]提出的Sketch2Photo系統以及Eitz等[2]提出的PhotoSketcher系統等。首先從大量的圖像數據庫中搜索相關的圖像,然后從相關圖像中提取出對應的圖像塊,最后將這些圖像塊重新融合成新的圖像。此類方法很難設計特征表示,且后處理過程非常繁雜[3]。
近幾年,隨著深度學習的不斷發展,生成對抗網絡(generative adversarial networks,GANs)在服裝圖像生成領域展現出巨大的潛力,其通過使用一個判別器來區分生成器生成的圖像和真實圖像,從而迫使生成器生成更加真實的圖像[4]。這種基于深度學習的方法在訓練過程中需要標記大量的數據集,而現實世界中成對的服裝草圖-圖像數據集比較稀缺且制作起來耗時耗力。Zhu等[5]提出的循環一致生成式對抗網絡(cycle-consistent generative adversarial networks,CycleGAN)越來越多被應用在草圖到圖像的生成過程中,這種方法主要側重于學習圖像域之間的映射,而忽略了其它關鍵語義信息,難以相應規范訓練過程。如果不考慮高級語義信息,會誤導模型建立不相關的翻譯模式,生成的圖像可能會出現嚴重的偽影甚至是不正確的圖像屬性。
本文提出一種基于循環生成對抗網絡的屬性引導服裝圖像生成方法,即AGGAN(CycleGAN-based method for attribute-guided garment synthesis),其將服裝屬性融入到生成器中以生成忠實于該屬性的服裝圖像。同時,考慮到服裝設計草圖的稀疏性,本文引入注意力機制來引導生成器更多地關注筆畫密集的區域,并提出將像素值這種低層圖像數據和服裝屬性這種高層語義信息結合到生成模型中,以減少圖像映射的模糊性。
1 服裝圖像生成模型
1.1 AGGAN框架
本文所提出的服裝圖像生成模型如圖1所示。從草圖域X={x1,x2,…,xn}開始,在屬性向量集合C={c1,c2,…,cn}的指導下完成目標服裝圖像域Y={y1,y2,…,yn}的轉換。為保證服裝屬性的一致性,本文將輸入的服裝屬性作為條件信息融入到具有深度敏感注意力機制的生成器G和鑒別器Dy中。通過將服裝草圖X輸入到生成器G中,同時將服裝屬性通過One-hot編碼之后輸入到多層感知機中得到AdaIN[6]參數,然后將其融入到生成對抗網絡網絡生成器的殘差層中,以此生成具有相應屬性的卷積特征圖,最后通過生成器解碼得到目標服裝圖像。鑒別器則用于區分生成服裝圖像與真實服裝圖像。

圖1 正向的AGGAN框架
1.2 屬性融入模塊
服裝圖像具有豐富的語義屬性以及視覺細節,其中,顏色、袖長和紋理是最主要的視覺特征,因此本文提取服裝屬性(顏色、袖長和紋理)進行探索。當AGGAN接收到任意服裝屬性標簽時,所有屬性都可同時學習,服裝屬性由一個One-hot向量表示,該向量用于區分目標屬性和其它屬性,One-hot向量一般可用來表示沒有大小關系的類別特征,在One-hot向量中,屬性向量表示為Ci=(0,1)N。其中:N為所添加的屬性個數;Ci表示將N個(0,1)連接起來的第i個屬性向量。只有對應于標簽的元素被設置為1,而其它元素被設置為0。分別將顏色、袖長和紋理3種屬性集合進行編碼得到的One-hot向量矩陣輸入到多層感知機中,并展開到高維空間作為AdaIN樣式參數。AdaIN操作能夠對齊內容特征與樣式特征的二階統計數據,將AdaIN參數插入到生成器G中的殘差層中并與卷積特征圖融合,可產生相關屬性樣式的內容特征。假設經過生成器G的殘差層產生t∈RHt×Wt×Ct的特征圖,其中:R為實數集;Ht為特征圖t的高;Wt為特征圖t的寬;Ct為特征圖t的通道數。AdaIN操作為
式中:tc∈RHt×Wt,為輸入的特征圖;C為屬性特征參數;μ(tc)和σ(tc)分別表示特征圖tc的均值和標準差;μ(C)和σ(C)分別表示服裝屬性特征的均值和標準差。
1.3 生成器和鑒別器
生成器G的網絡結構如圖1所示。首先使用多個下采樣卷積層學習高層特征映射,然后通過多個上采樣卷積層生成輸出圖像。與一般的GAN不同之處在于,本文在上采樣層前學習仿射變換,以便通過AdaIN操作將服裝屬性融入到生成器中。該服裝屬性通過One-hot編碼到二進制向量C(C∈R1×1×N)中,且每個分量是屬性的狀態。將其融入生成器的殘差層后經過注意力模塊,使模型能夠選擇信息最豐富的屬性來分類和區分相似的類,對于第i個屬性,將其聚焦于圖像不同區域的關注度定義為
式中:sij為圖像隱含特征和潛在屬性特征的內積;βj,i表示對應用softmax函數計算出的關注度;CTi為屬性向量集中的第i個屬性向量;g(xj)為圖像第j個子區域的隱含特征;oj為注意力層的最終輸出。
生成器G包含下采樣層、殘差層、注意力模塊和上采樣層。下采樣層分別是步長為1的7×7卷積層,2個步長為2的3×3卷積層,每個Convolution卷積層后是BatchNorm歸一化層,激活函數為ReLU。為了讓生成器網絡能夠接收服裝屬性信息,本文將殘差塊的BatchNorm歸一化層更改為AdaIN自適應歸一化層。服裝草圖輸入用作AdaIN的內容輸入,服裝屬性的AdaIN參數則作為樣式輸入,以確保網絡學習正確的屬性信息。上采樣層分別為2個步長為1的3×3反卷積層,每個卷積層后是BatchNorm歸一化層,激活函數為ReLU,最后一個輸出層則是步長為1的7×7卷積層使用tanh激活函數來確保歸一化生成的圖像位于范圍[-1,1]內。
鑒別器Dy根據輸入的Y域圖像和1組屬性向量C={c1,c2,…,cn}來計算概率D(Y,C)。該鑒別器包含了5個下采樣層組成的卷積神經網絡,這些卷積神經網絡的結構是由Convolution-BatchNorm-LeakyReLU層構建的,在最后一層之后,應用全連接層,然后是Sigmoid函數,第1層不采用BatchNorm歸一化層。
1.4 損失函數
生成器和鑒別器之間的對抗性過程促使生成圖像更具真實性,此外還需要在對抗過程中融入屬性條件信息來保證生成圖像屬性上的一致性。鑒別器Dy的輸入為Y域服裝圖像以及相對應的屬性。研究目標是使得鑒別器Dy能夠區分生成的服裝效果圖和真實的服裝圖像,并判斷輸入的服裝圖像是否包含所需的屬性。在訓練鑒別器網絡的過程中,將真實服裝圖像數據對(Y,C)作為正樣本,而生成的服裝圖像(G(X,C),C)及其屬性C的數據對則被定義為負樣本,其中X為輸入生成器的服裝草圖。訓練鑒別器網絡的目標函數分別為用于檢驗屬性一致性的Latt和用于判別圖像真實性的Lauth,因此鑒別器Dy的對抗性損失為
LDy=λ1Latt+Lauth
λ1初始化為0,在后面的訓練過程中逐漸增大,使得鑒別器Dy能夠首先注重于鑒別真假圖像,然后逐漸注重于屬性一致性檢查,Latt與Lauth計算公式分別為:
Latt=-E(Y,C)~Pdata(Y,C)lnDy(Y,C)+
Lauth=-E(Y,C)~Pdata(Y,C)lnDy(Y,C)+
E(X,C)~Pdata(X,C)lnDy(G(X,C),C)

AGGAN的生成器G與鑒別器Dy對抗損失為
式中,ln(1-Dy(G(X,C)))表示判別器的優化目標。該值越大,Dy(G(X,C))的值越小。
與生成器G的網絡結構不同,重建過程的生成器F沒有服裝屬性條件的引導,將生成圖像恢復至服裝草圖F(G(X)),在沒有屬性回歸約束的情況下,則生成器F與鑒別器Dx的對抗損失為
式中:Pdata(X)和Pdata(Y)分別表示服裝草圖和服裝圖像的數據分布;EX~Pdata(X)和EY~Pdata(Y)分別表示從服裝草圖數據分布獲取的期望以及從服裝圖像數據分布獲取的期望;F(Y)表示輸入為服裝圖像Y時,生成器F生成的草圖。
重建草圖的內容與原始輸入草圖通過L1損失在像素級對齊,則循環一致性損失公式為
式中:F(G(X,C))表示重建服裝草圖;G(F(Y))表示輸入為服裝草圖時生成的服裝圖像。
綜上所述,最終的目標函數為
L=LGAN(G,Dy,X,Y,C)+LGAN(F,Dx,Y,X)+Lcycle
式中:LGAN(G,Dy,X,Y,C)為生成過程生成器G與鑒別器Dy的對抗損失;LGAN(F,Dx,Y,X)為重建過程生成器F與判別器Dx的對抗損失;Lcycle為循環一致性損失。
2 實驗部分
2.1 數據集與實驗設置
本文對所提出的網絡模型進行了驗證,并在帶有屬性向量的VITON數據集[7]上對其性能進行了評估。該數據集包括14 221個圖像和22個相關屬性,數據集中的每個條目都由1個來自VITON的圖像和1個屬性向量組成。由于服裝圖像中上衣圖像相較于其它品類的服裝圖像其視覺特征更為豐富,更具有代表性,因此本文選擇上衣圖像作為研究對象。訓練過程中先將其轉換為服裝草圖,再進行基于服裝草圖的圖像生成任務。本文設置所有數據被訓練的總輪數為200,初始學習率是0.000 2,并且使用Adam優化器,批次大小為8,輸入圖像的大小為256像素×256像素。
實驗環境設置:使用Windows10的64位操作系統,采用Pytorch1.2.0深度學習框架,CPU為3.70 GHz Intel(R)Core(TM)i5-9600KF,GPU為NVIDIA GeForce GTX1080Ti。
2.2 評價指標
本文使用初始分數IS、弗雷切特初始距離FID[8]以及平均意見分數MOS[9]3個指標來評價生成服裝圖像的質量。IS和FID是GAN模型的典型圖像評價指標,分別關注生成圖像的多樣性和生成圖像與真實圖像之間的特征距離,而MOS量化指標則是用來評價圖像的生成效果。
初始分數IS通過將生成器輸出的圖像輸入到訓練好的Inception V3[10]中,從而得到一個概率分布的多維向量,其計算公式為
IS(G)=exp(Ex~pgKL(p(y|x)||p(y)))
式中:pg為生成數據的分布;x為從分布pg中采樣的圖像;Ex~pg表示從分布pg上獲取的數學期望,KL表示KL散度[11];p(y|x)表示輸入到Inception V3網絡中并輸出的分類向量;p(y)為生成圖片在所有類別上的邊緣分布。
弗雷切特初始距離FID是通過Inception V3提取出特征向量,沒有采用原Inception V3的輸出層,而是讓其網絡倒數第2個全連接層成為新的輸出層。FID值越小,它們之間的相似程度越高。FID計算公式如下:
式中:μr和Cr分別為真實樣本在輸出層的均值和協方差矩陣;μg和Cg別為生成樣本輸出層的均值和協方差矩陣;Tr為矩陣的跡。
平均意見分數MOS是一種從主觀角度對生成圖像質量評估的方法,該方法需要受試者給出對所觀察圖像質量的評分,然后將所有受試者給出的評分匯總在一起計算出平均意見分數。MOS值為一個有理數,通常在1~5的范圍內,其中1是最低感知質量,5是最高感知質量。
2.3 對比實驗
為驗證本文所提方法AGGAN的性能,進行了一系列對比實驗。圖2分別示出輸入草圖,真實圖像,CycleGAN[5]、MUNIT[12]、USPS[13]以及AGGAN的生成圖像結果。可以看出,MUNIT在本文服裝圖像生成任務上存在圖像模糊,圖像邊緣難以分辨的問題,在訓練期間,生成器學習生成與特定屬性相對應的有限數量圖像樣本,所生成的圖像不足以欺騙鑒別器,因此生成器和鑒別器網絡沒有得到充分優化。CycleGAN生成的圖像較為模糊且顏色單一,圖像缺乏真實感。最先進的基于草圖生成圖像方法USPS從視覺效果上生成可信的服裝圖像,但生成的服裝圖像顏色單一且質量不高。與其它方法相比,本文所提出的AGGAN不僅可生成多種顏色的服裝圖像,而且在視覺效果上更接近真實情況,同時AGGAN產生的圖像極大地緩解了失真現象,這主要是由于模型融入了服裝屬性,在訓練階段學習更好的條件數據分布,此外,在所提出的AGGAN中使用注意力機制也有助于提升模型的性能。

圖2 AGGAN與其它方法生成服裝圖像結果對比
本文使用IS、FID來進一步定量評估模型,結果如表1所示。可見:本文方法所生成的服裝圖像IS值為1.253,相較于CycleGAN提高了13.8%,且高于其它方法;其FID值為139.634,相較于CycleGAN降低了26.2%,且低于其它方法。除了上述2個評價指標外,本文還采用了MOS量化指標來評價各方法生成的服裝圖像質量,通過在校園線下分發問卷的方式進行調研。實驗中,評分人員被要求在數秒內從上述4種方法所生成的服裝圖像中選擇出他們喜歡的服裝圖像并依次對各方法生成的結果進行評分,設置的評分區間為1~5分,每種方法所生成的服裝圖像取出100張作為評價樣本,最后取各方法得分的平均值作為MOS值,從表1可看到,本文方法的MOS值為4.352分,高于其它圖像生成方法。
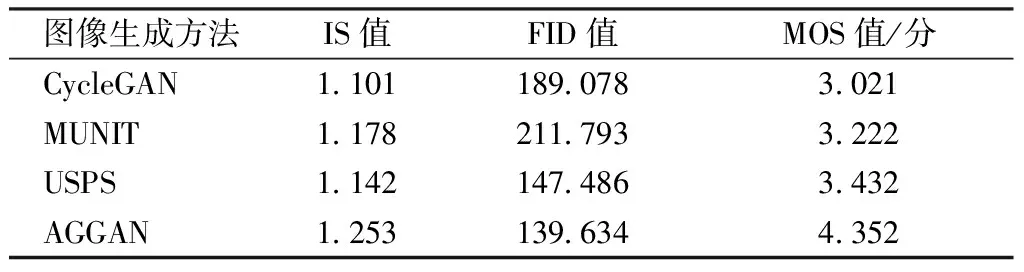
表1 AGGAN與其它方法比較結果
2.4 不同屬性控制生成的實驗結果
服裝圖像具有非常豐富的高級語義特征,而上述對比實驗中的現有方法都不能很好地控制服裝屬性的生成,沒有引入服裝屬性的生成結果往往不能滿足需求,因此本文探究了屬性控制的服裝圖像生成。
2.4.1 袖長屬性控制的實驗結果
袖長屬性是服裝的重要視覺特征,袖長屬性控制的實驗結果如圖3所示。其中生成圖像從左至右分別為無袖、短袖、蓋肩袖、中袖、七分袖和長袖的生成結果。與真實圖像相比,生成的服裝圖像袖長部分變化非常明顯,而且似乎沒有違和感;同時生成圖像與輸入圖像之間的差異明顯,且圖像分辨率相對較高,注重對目標袖長屬性的處理,生成的結果符合直覺邏輯;但“中袖”與“七分袖”生成效果比較接近,區別不明顯,主要是因為現有模型還不足以支撐如此精確的屬性操作。

圖3 袖長屬性控制的生成結果
2.4.2 顏色屬性控制的實驗結果
除了袖長屬性外,本文還探討了顏色屬性對生成服裝圖像的影響,如圖4所示,生成圖像從左至右分別為紅色、粉色、黃色、綠色、藍色和黑色的生成結果。可看到AGGAN在顏色屬性的控制下幾乎能夠生成任何相應顏色的服裝圖像,這是由于在生成器網絡輸入服裝草圖的同時融入了顏色屬性作為顏色提示輸入,在顏色細節生成方面能生成多樣化且高保真度的結果。

圖4 顏色屬性控制的生成結果
2.4.3 紋理屬性控制的實驗結果
除以上2種屬性外,紋理也是服裝圖像最直觀和最主要的視覺特征,紋理屬性控制的實驗結果如圖5所示,生成圖像從左至右分別為橫紋、粗紋、豎紋、波浪紋、柵格紋和印花的生成結果。
從圖5可以看出,橫紋、波浪紋、柵格紋與印花這4列的生成結果較為明顯,基本上可以生成所需要的紋理,但其在真實感上還需改進。粗紋、豎紋這2列的生成結果則不明顯,主要是由于擁有該屬性的服裝數據集較為稀少,在這種情況下,生成器在學習從草圖域生成圖像域時,生成的服裝圖像傾向于在某種程度上忽略融入屬性的影響。

圖5 紋理屬性控制的生成結果
3 結 論
本文研究利用One-hot向量編碼服裝屬性以及多層感知機構建了屬性融入模塊,通過屬性融入模塊、注意力機制和循環生成對抗網絡建立了基于手繪草圖的服裝圖像生成模型,并以此提出了手繪草圖到服裝圖像的跨域生成方法。該方法結合了生成對抗網絡與條件圖像生成方法的優勢,服裝屬性被用作條件以增加服裝圖像生成過程的可控性。實驗結果表明,所提方法相較于圖像生成方法CycleGAN的初始分數IS值提高了13.8%,弗雷切特初始距離FID值降低了26.2%,本文研究方法具有可行性與有效性。
本文研究仍有不足,例如:生成的服裝圖像存在輪廓模糊;紋理屬性生成效果不明顯;研究的服裝屬性較少等。后期將深入探索如何提升生成圖像輪廓的清晰度以及生成屬性的效果,同時還將研究更多種類的服裝屬性生成。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
