基于車輛信息的大數據分析系統設計與實現
2023-02-17 01:54:00張積存宋雪萍費繼友
計算機應用與軟件 2023年1期
張積存 宋雪萍 費繼友 王 凱
1(大連交通大學機械工程學院 遼寧 大連 116028) 2(東軟集團(大連)有限公司 遼寧 大連 116085)
0 引 言
近年來,我國在公共安全信息化建設方面的投入飛速增長,其中視頻監控系統是一個主要的發展方向。對視頻的監控、追蹤已經成為各級公安部門主要的破案手段。隨著城市部署的車輛卡口點位越來越多,卡口數量增加,各地公安機關已經擁有大量的車輛卡口數據和視頻圖像資源[1-2]。以北京市為例,全市每日通過交通卡口采集的過車數據都達到千萬級別的數據量。但是越來越多的視頻資源帶來幫助的同時,也給存儲和分析造成巨大困難。
如何充分利用這些資源,結合現代化信息技術,為情報、刑偵、治安等不同警種服務,已經成為公安機關信息化建設的主要需求。然而目前已有的基于車輛的大數據分析系統[3-5]大同小異,多是基于對數據的查詢,存在著分析數據種類單一、分析時間滯后、系統使用率低等問題。這類系統僅解決了“有”的問題,而不能滿足“精”的需求。
為使車輛數據得到更充分的應用,分析更全面、更準確、更及時,以滿足公安機關日益精進的信息化建設需求,本文在已經完成的視頻結構化平臺的基礎上,設計并實現車輛大數據分析系統。本系統以平臺提供的結構化數據為數據源,結合公安網中大量車輛信息、業務數據和圖像數據,使用Kafka消息隊列、Elasticsearch分布式引擎、Redis內存數據庫和大量的模型算法,實現了海量數據的實時傳輸、存儲、檢索和分析,提供豐富的業務實戰應用。
1 系統設計
1.1 系統架構設計
車輛大數據分析系統基于視頻結構化平臺,共包括采集層、存儲層、服務層和應用層,并考慮安全保障體系和標準規范體系。系統軟件架構設計如圖1所示。

圖1 系統軟件架構設計視圖
(1) 應用層。基于Vue.js框架開發的Web平臺,針對不同警種的需求提供相關的應用功能。平臺的應用功能包含智能檢索、異常排查、一車一檔、布控告警、統計分析和17種技戰法(包括異常停留、快速離城、區域徘徊、遮擋面部、晝伏夜出、頻繁夜出、頻繁過車、首次入城、首次出現、重點車輛分析、無牌車、套牌車、隱匿車輛挖掘、時空碰撞、同行車[6]、落腳點、相似車牌串并)。
(2) 服務層。服務層包括模型算法服務、應用服務、Elasticsearch實時全文檢索服務。基于存儲層的數據,為上層應用提供算法分析、模型訓練、智能檢索等服務。包括:算法集、模型庫、分布式計算中心和分布式數據檢索引擎。
(3) 數據資源層。基于ES(Elasticsearch)分布式搜索引擎平臺,對海量過車數據進行存儲,為數據分析提供支撐。Redis內存數據庫保證算法集群獲取數據的實時性。業務庫采用MySQL數據庫,存儲各業務功能相關數據。
(4) 采集層。使用視頻結構化平臺提供的標準化數據對接接口,從各類平臺采集海量的卡口數據,并使用Kafka作為消息總線進行數據的實時傳輸。
1.2 系統邏輯處理設計
車輛大數據分析系統在實際工作中,依托于視頻結構化平臺采集接口提供的結構化數據,數據進入卡口監視消息總線后,一方面供給ES(Elasticsearch)檢索引擎,滿足前端的實時檢索;另一方面存入Redis內存數據庫,并與人員專題庫數據、車駕管數據一起提供給模型算法模塊,由算法模塊實現自動化標簽、一車一檔、布控告警等功能供前端調用。系統邏輯結構圖如圖2所示。
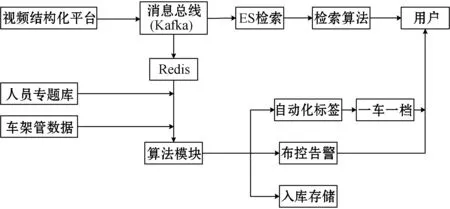
圖2 系統邏輯處理結構視圖
1.3 系統部署運行
(1) 系統部署:各模塊均采用集群部署,隨著業務規模擴展,數據接入增多,各服務節點也可以平滑橫向擴展,保證服務的高可用性。在測試環境下,可處理日均400萬的過車數據。系統部署運行如圖3所示。系統部署配置情況如表1所示。
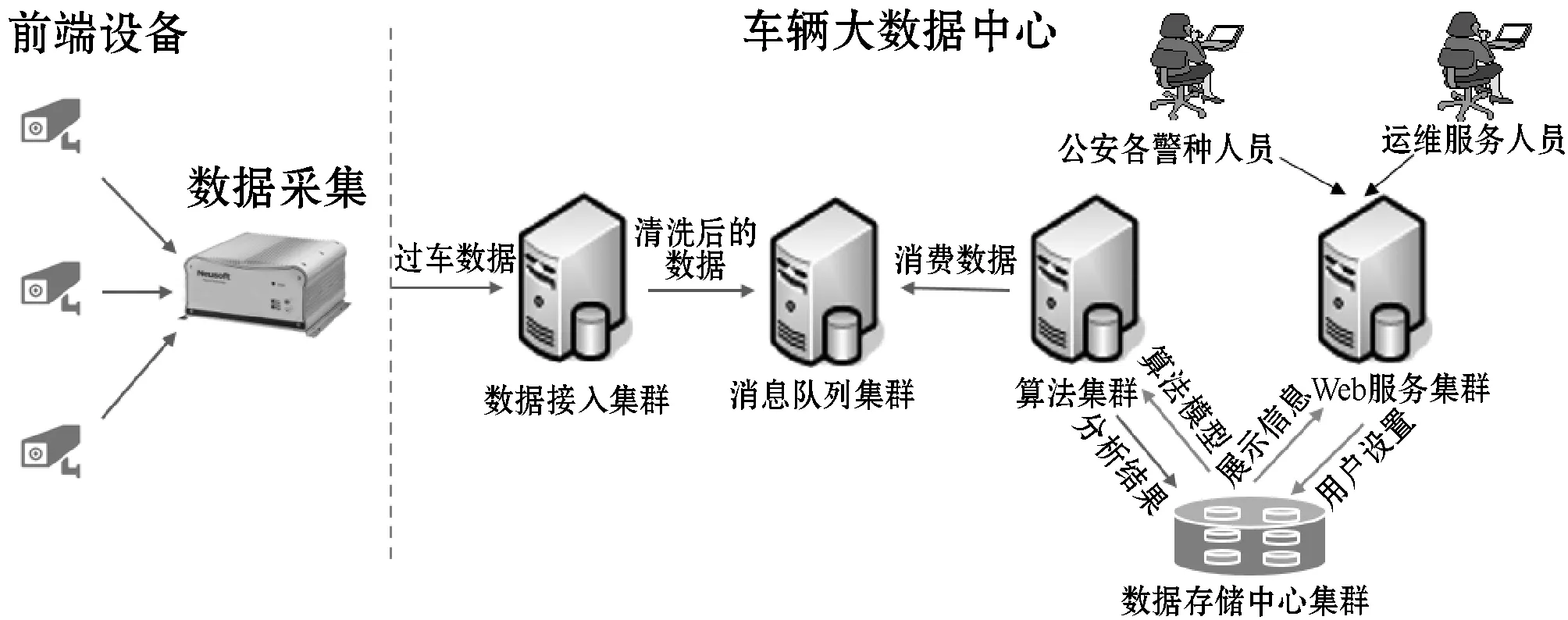
圖3 系統部署運行圖

表1 系統部署配置
(2) 通信傳輸:前后端基于HTTP協議進行消息通信,后端的數據傳輸基于Kafka消息隊列。
(3) 存儲:原始過車數據索引到Elasticsearch中,分析結果存儲到MySQL中,過車數據經預處理后,緩存到Redis中,以備算法可以快速讀取。
(4) 災備:數據存儲采用主從模式,集群部署,即使部分服務宕機,也可保證數據正常存儲。Elasticsearch中的數據會自動創建副本,即使部分節點宕機,也可保證數據的完整性。系統定期將數據備份到數據中心,使用RAID5硬盤存儲,保證數據可恢復。
(5) 系統運行:系統算法由數據采集事件驅動,使用實時消息隊列進行數據傳輸,高性能內存數據庫Redis進行數據緩存,算法基于緩存的數據進行分布式運算,從而保證計算結果的準實時性。
2 關鍵技術及系統實現
2.1 關鍵技術
2.1.1Kafka消息隊列
Kafka是一種高吞吐量的分布式發布/訂閱消息系統。即使非常普通的硬件Kafka也可以支持每秒數百萬的消息吞吐量。
本文利用Kafka分布式消息隊列技術[7-10]處理海量請求,支持高吞吐量的消息發布和訂閱。利用Kafka集群作為系統的消息總線,當采集接口、其他平臺訂閱等多種生產者產生數據時,Kafka集群將消息發布給ES引擎和算法等多個消費者模塊,從而實現海量數據的實時傳輸,圖4為Kafka消息總線的結構圖。

圖4 Kafka消息總線示意圖
2.1.2Elasticsearch分布式搜索引擎
本文通過搭建ES(Elasticsearch)分布式搜索引
擎來實現海量數據的實時存儲及檢索。ES是一個分布式、高擴展、高實時的搜索與數據分析引擎。它能很方便地使大量數據具有搜索、分析和探索的能力。它可以近乎實時地存儲、檢索數據,而且具有良好的擴展性,可以擴展到上百臺服務器,處理PB級別的數據[11-15]。
ES的實現原理主要分為以下幾個步驟:
(1) 首先用戶將數據提交到Elasticsearch數據庫中。
(2) 通過分詞控制器將對應的語句分詞,將其權重和分詞結果一并存入數據。
(3) 當用戶搜索數據時候,根據權重將結果排名、打分,再將返回結果呈現給用戶。
2.1.3數據實時分析
Redis是一個開源的,內存中的數據結構存儲系統。它可以用作數據庫、緩存和消息中間件,支持多種類型的數據結構(如字符串、散列、列表、集合、有序集合)與范圍查詢。為了保證效率,Redis的數據保存在內存中,并且支持一定的持久化功能,可以將內存中的數據保存在磁盤中,重啟的時候可以再次加載進行使用,這保證了高并發場景下數據的安全性和一致性。其性能極高,讀的速度可以達到110 000次/s,寫的速度可達81 000次/s。并且支持集群、分布式、主從同步等配置,原則上可以無限擴展,讓更多的數據存儲在內存中。
本文使用Kafka消息隊列作為消息總線保證數據實時傳輸,利用Redis的超高性能保證數據實時讀寫。
當新增數據產生時,一方面發布到ES引擎進行存儲,另一方面發布到Redis內存數據庫,供給模型算法模塊進行實時分析。系統的算法模塊包含十余種業務相關的算法模型:異常停留、套牌車、同行車、落腳點、區域徘徊、時空碰撞等。這些算法模型服務分布式運行在兩臺配置為CPU:E5-2630 V4×2;內存:16 GB DDR4×2的機器上。Redis的高性能讀寫能力允許各算法模型同時讀取數據,通過運行各類算法實時地為車輛數據標記各類異常行為標簽,同時將標簽化的數據存儲在MySQL數據庫中作為模型中間庫以供查詢檢索使用。實時分析流程如圖5所示,系統7×24小時不間斷地對產生的每條過車記錄進行實時算法分析,生成實時的車輛異常行為數據標簽,對每一輛通過交通卡口的車輛都動態建立檔案,用于大數據分析碰撞。系統根據車輛異常行為標簽以及異常行為出現的頻率,會自動進行預警,并將預警信息推薦給Web平臺。平臺使用者能在第一時間發現有異常行為的車輛,從而提前采取布控等措施,極大地提高事前預判、預防、預警能力。
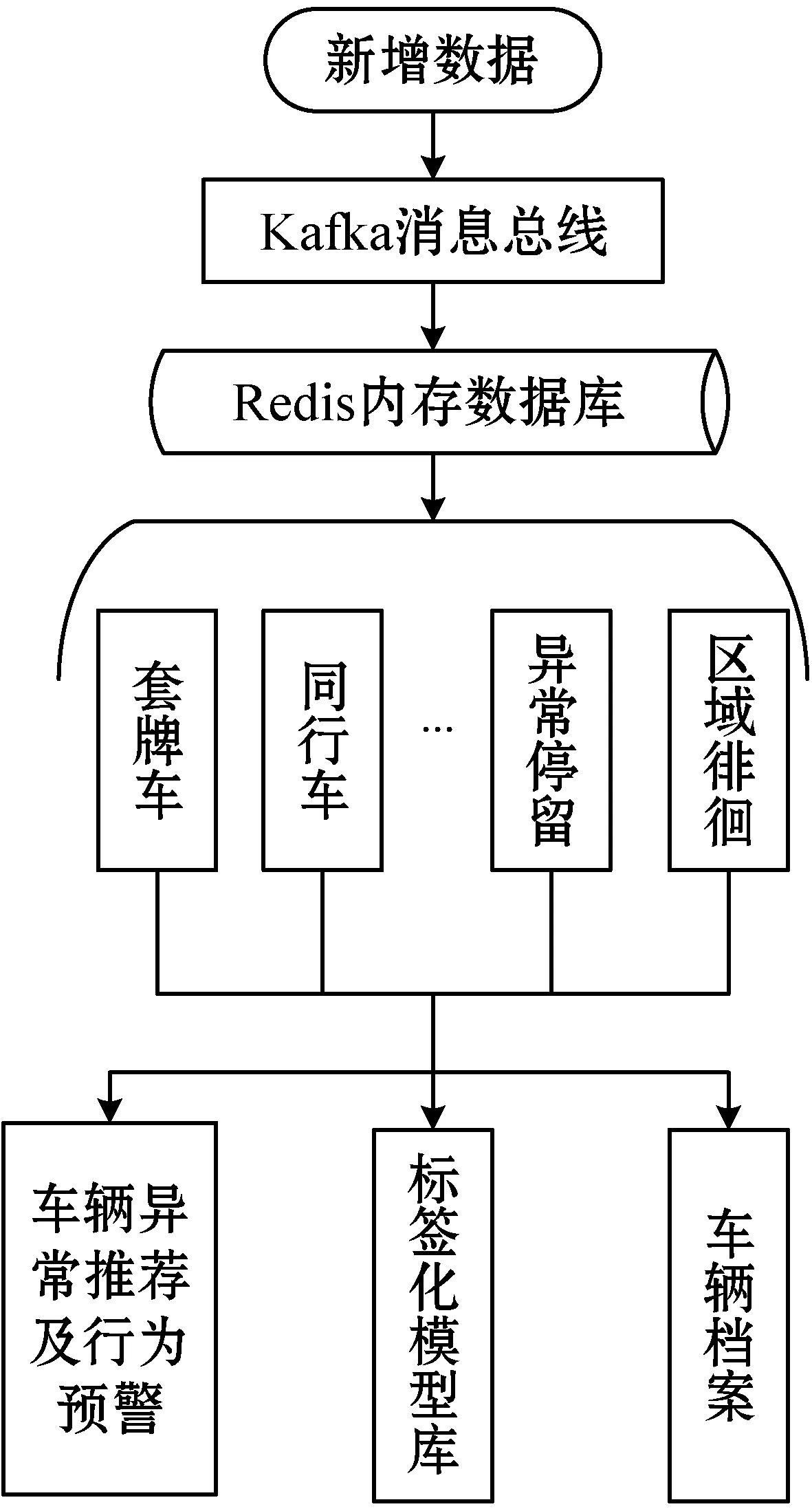
圖5 實時分析流程
2.1.4數據融合分析
系統提供接口對接、人工錄入、批量導入等多種形式,將其他與車輛關聯的數據(車駕管、人員專題庫數據、盜搶車輛等)融入到車輛研判算法中,為車輛研判提供更多的有價值的線索,提升數據價值,提高辦案效率。圖6是車輛布控告警流程,系統通過融合車架管數據,獲取到車輛車牌號碼信息,從而達到以人找車,進行布控告警的目的。圖7是完整軌跡的數據融合分析流程圖。通過融合人臉識別數據、酒店住宿數據、出行數據等,再結合交通卡口的車輛信息,就能夠刻畫出布控目標完整的人車軌跡,用于案件的深度大數據研判分析,提高偵破率。

圖6 布控告警流程

圖7 完整軌跡流程
2.2 系統實現
根據數據性質的不同,分別采用MySQL、Redis、Elasticsearch三種不同的數據庫來進行數據存儲和管理。數據庫實現如圖8所示,三種數據庫特性比較如表2所示。

圖8 數據庫實現框圖

表2 數據庫特性對比表
(1) 應用層的用戶、角色、權限管理、字典表管理以及算法結果使用Mysql進行存儲。
(2) 過車數據的預處理結果,用于算法的實時計算,采用內存數據庫Redis進行緩存。
(3) 離線算法需要實現對機動車過車記錄的高性能搜索,可支持查詢、統計、聚合,所以選擇當前主流的Elasticsearch存儲機動車過車記錄。
服務層采用java語言開發,系統為Windows系統。應用層為基于Vue.js框架的Web平臺。圖9為系統主界面,共包含各統計分析,智能檢索、車輛追蹤、異常排查等的功能入口按鈕。圖10為技戰法分類界面,共包含17中技戰法。圖11-圖13為部分功能界面運行效果。
圖9 系統首頁
圖10 技戰法界面

圖11 車輛檔案

圖12 技戰法—區域徘徊

圖13 車輛追蹤
3 系統測試
本文使用北京某區域交通卡口三個月過車數據進行系統功能測試及性能測試。測試數據量大于一億條。
3.1 系統功能測試
系統功能測試主要是利用Cypress E2E(end to end) Web 測試框架通過對應用層Web平臺進行UI自動化測試并保存每次服務端的返回結果生成txt文件進行業務驗證,以檢測系統各功能是否實現以及運行效果。表3為Web模塊各項功能列表。

表3 Web模塊各項功能
系統進行了6次全功能測試及10余次隨機UI測試。整個測試過程未發現崩潰性和嚴重性錯誤,并且生成的結果文件通過業務驗證滿足業務需求,可以證明系統在功能上滿足用戶需求。
3.2 系統性能測試
(1) 典型業務場景測試。使用三輛已知號牌的車輛作為測試的目標車輛,按照規劃的測試路線行駛,形成伴隨關系,并按計劃進行停留,通過不同的卡口位置,共歷時7天。結合3個月時間采集到的約1億2千萬條卡口實際過車數據進行共30余項業務場景測試。以智能檢索、同行車、落腳點、布控告警為例說明測試結果。
① 智能檢索:根據起止時間、車牌號、車牌顏色、車輛類型、車型車款、車身顏色、車內飾品、是否系安全帶等條件進行車輛檢索,達到快速捕捉目標車輛的目的。測試以三輛已知號牌車輛為目標車輛,自由組合各項檢索條件進行多次測試。
測試結果表明:從開始分析到結果顯示平均耗時約為55 ms,并準確找到測試目標車輛。
② 同行車:融合FP-groupth算法以及車輛軌跡對比分析算法進行同行車、伴隨車挖掘與分析。測試分別以其中一輛已知號牌車輛為目標車輛,分析并找出其同行車。
測試結果表明:從開始分析到結果顯示平均耗時約為430 ms,并準確找到同行的測試車。
③ 落腳點:以起止時間、車牌號、車牌顏色為條件(不同車牌類型存在有相同車牌號的情況,如綠牌車和藍牌車可以有相同車牌號),使用改進的Optics聚類算法進行目標車輛的落腳點挖掘。以三輛已知號牌車輛為目標車輛進行測試。
測試結果表明:從開始分析到結果顯示平均耗時約為245 ms,并準確找到目標車輛的落腳點。
④ 布控告警:以一輛測試車輛為目標車輛,模擬布控告警實時測試。系統顯示布控車輛已有的過車記錄,刻畫行車軌跡。當布控目標車的過車數據再次被系統檢測到時,進行報警并顯示目標車的位置。
測試結果表明:從過車數據采集入庫到推送給UI響應,數據平均延遲時間約為550 ms,符合布控告警對實時性的要求。
(2) 大數據下的系統性能測試。系統性能測試是在進行UI自動化測試的同時,監控系統各模塊的響應時間;在產生新數據時,監控各算法模型的計算時間來驗證系統各模塊性能。表4為UI測試時系統各模塊的平均響應時間。表5為新增數據時各模塊平均響應時間。

表4 UI測試各模塊平均響應時間 單位:ms

表5 新增數據時各模塊平均響應時間
測試結果表明,本系統在車輛數據達億級時,各功能的響應時間均在秒級。在新增數據達到每秒2 000條,即每天新增1.728億條車輛數據時(目前一般除特大型城市外,一個大中型城市,每天卡口車輛數據在千萬條級別,測試數據已超過一個城市每日實際產生的卡口車輛數據),各模塊的傳輸、存儲和運算時間也都達到秒級響應。性能上近乎可以做到實時分析和實時查詢,能夠滿足當前用戶的需求。將來隨著城市車輛保有量的增加以及車輛卡口采集點位的不斷建設,每日新增的數據量也將持續增加,可以考慮通過硬件擴容的方式,增加Kafka和ES節點,通過集群部署的方式,提升系統的負載能力,從而滿足系統實時性的使用要求。
4 結 語
本文設計開發了基于車輛信息的大數據分析系統。相比于已有的相關大數據系統[16-18],本系統具有時效性高、實用性強、推薦結果精準、分析全面等優點。總結歸納為以下三個方面:
(1) 分析手段:區別于現有的大數據系統主要基于規則查詢的手段,本系統建立了大量業務相關的模型庫,算法庫用以分析、挖掘數據價值。
(2) 時效性:相比于現有的大數據系統多是事后查詢分析,本系統可以進行實時分析,做到事先預警、及時布控。
(3) 實用性:相比單純的過車數據,本文結合人員專題庫數據進行融合分析,人車一體,分析更全面。
目前本系統已經在北京、甘肅等多地正式投入使用。使龐大的過車數據得到充分利用,為公安機關布控預警、異常排查、重點車輛管控等工作提供更全面、更準確、更智能的應用服務。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
北京測繪(2020年12期)2020-12-29 01:33:58
電子制作(2018年18期)2018-11-14 01:48:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
財經(2017年2期)2017-03-10 14:35:35
山東工業技術(2016年15期)2016-12-01 05:31:22
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
