中文專利數(shù)據(jù)可視化分析系統(tǒng)研究與設(shè)計(jì)
2023-02-17 01:54:02徐勝捷張麗麗
計(jì)算機(jī)應(yīng)用與軟件 2023年1期
陳 挺 徐勝捷 陳 龍 陸 間 張麗麗
1(河海大學(xué)商學(xué)院 江蘇 南京 211100) 2(河海大學(xué)計(jì)算機(jī)與信息學(xué)院 江蘇 南京 211100)
0 引 言
專利作為技術(shù)信息最有效的載體,囊括了全球絕大多數(shù)最新的技術(shù)資料,對專利進(jìn)行分析能夠從海量的專利數(shù)據(jù)中挖掘出有效的信息。然而,現(xiàn)有的專利分析系統(tǒng)在可視化方面存在一些不足之處,針對中文專利的可視化分析工具仍然較少。因此,本文結(jié)合文本挖掘方法,設(shè)計(jì)并實(shí)現(xiàn)一個(gè)“中文專利數(shù)據(jù)可視化分析系統(tǒng)”,拓展專利分析功能并進(jìn)行可視化呈現(xiàn)。
1 研究背景及意義
1.1 專利數(shù)據(jù)可視化分析國外研究現(xiàn)狀
隨著現(xiàn)代信息社會(huì)的到來,大數(shù)據(jù)時(shí)代下專利數(shù)據(jù)可視化分析工具與日益增長的專利數(shù)據(jù)之間存在著不平衡關(guān)系。專利數(shù)據(jù)被許多發(fā)達(dá)國家視為國家核心競爭力,是知識庫和數(shù)據(jù)源的重要體現(xiàn),國際上很早就有了對于專利信息分析相關(guān)領(lǐng)域的理論和研究,國際市場上對專利的競爭尤為激烈。一些大型軟件公司將數(shù)據(jù)挖掘技術(shù)與專利數(shù)據(jù)可視化展示完美結(jié)合,成功開發(fā)出一批專利信息數(shù)據(jù)庫和專利信息分析系統(tǒng)。利用數(shù)據(jù)挖掘技術(shù)和專利數(shù)據(jù)可視化展示,實(shí)現(xiàn)對專利信息的自動(dòng)分析與管理,如德溫特?cái)?shù)據(jù)公司基于德溫特世界專利索引內(nèi)容的智能檢索功能可以查找全球?qū)@墨I(xiàn)庫的專利記錄;IBM公司開發(fā)了“Intelligent Miner for Text”(IMT)軟件,實(shí)現(xiàn)了對專利信息特征的檢索、聚類、引文分析等功能;Aureka提供廣泛的專利信息源,Aureka引證樹和Aureka地形圖能夠形象化地顯示出專利布局的重要信息,是一種深層次的專利信息分析工具;Delphion、Wisdomain Analysis Module、MCAM、Vivisimo、Invention Machine Knowledgist的功能比較簡單,僅提供同義詞表進(jìn)行概念分組[1]。VantagePoint可以產(chǎn)生列表使用戶得以快速瀏覽,同時(shí)它也提供多維度分析功能,應(yīng)用模糊匹配技術(shù)來識別和整理數(shù)據(jù)。
自20世紀(jì)90年代中后期以來,專利情報(bào)相關(guān)研究一直受到國外學(xué)者的關(guān)注,研究領(lǐng)域不斷擴(kuò)展,并且日益成熟;近年來研究趨于縱深化,正面臨著傳統(tǒng)領(lǐng)域的逐漸分化和新興領(lǐng)域的不斷產(chǎn)生[2]。關(guān)于國外專利數(shù)據(jù)可視化分析的研究現(xiàn)狀可以總結(jié)出一些規(guī)律和特點(diǎn):(1) 理論研究與方法技術(shù)研究齊驅(qū)并駕,特別是基于專利文本挖掘的可視化分析研究最為顯著;(2) 針對不同技術(shù)領(lǐng)域的專利實(shí)證研究,多數(shù)專利分析軟件切實(shí)結(jié)合可視化研究調(diào)查,使專利數(shù)據(jù)可視化分析的結(jié)果具有極高的研究價(jià)值;(3) 能夠廣泛借鑒其他學(xué)科領(lǐng)域的科學(xué)技術(shù)方法,不斷研究和總結(jié)出可視化分析工具的發(fā)展態(tài)勢,向著更加前沿的方法技術(shù)深入推進(jìn),發(fā)展軌跡十分清晰。
1.2 專利數(shù)據(jù)可視化分析國內(nèi)研究現(xiàn)狀
國內(nèi)在專利研究方面的首次發(fā)文時(shí)間為2007年,與排名靠前的其他國家和地區(qū)相比起步較晚[3],但是發(fā)展十分迅速,專利申請量也在不斷增加。國家知識產(chǎn)權(quán)戰(zhàn)略的推出,在很大程度上推動(dòng)了我國專利數(shù)據(jù)可視化分析的進(jìn)程。國內(nèi)的研究人員著重于專利的基礎(chǔ)理論分析,對于專利分析結(jié)果可視化研究方面較為欠缺。劉曉英等[4]對專利信息可視化分析系統(tǒng)的現(xiàn)狀與技術(shù)基礎(chǔ)做出了研究,馬芳等[5]作出了基于數(shù)據(jù)挖掘技術(shù)的專利信息分析,馬建霞等[6]針對專利情報(bào)分析軟件的現(xiàn)狀和趨勢提出了自己的看法,劉玉琴等[7]對國內(nèi)外專利分析工具做出了比較研究,方建國[8]探索了文本挖掘在專利分析中的應(yīng)用。相比于國外的專利數(shù)據(jù)可視化分析研究,國內(nèi)專利研究仍有很大的提升空間。
因此,針對專利數(shù)據(jù)可視化分析方面的研究,尤其是對中文專利的可視化分析研究方面存在的諸多問題及不足,本文結(jié)合數(shù)據(jù)挖掘技術(shù),設(shè)計(jì)并初步實(shí)現(xiàn)了基于Django框架的中文專利分析系統(tǒng),目的是在深度挖掘?qū)@麛?shù)據(jù)價(jià)值的同時(shí),將其蘊(yùn)含的信息內(nèi)容可視化展現(xiàn)出來,為研究者或決策者提供新的思路和借鑒。
2 中文專利分析系統(tǒng)設(shè)計(jì)
2.1 中文專利分析系統(tǒng)需求分析
在專利分析中,可視化的目的是“給專利以形象”,幫助人們用視覺化的方式洞察海量專利數(shù)據(jù)背后的關(guān)系特征和規(guī)律,并能及時(shí)反饋市場趨勢以及知識產(chǎn)權(quán)戰(zhàn)略等領(lǐng)域相關(guān)的問題,讓使用者在短時(shí)間內(nèi)理解所獲得的信息并做出相應(yīng)決策。近年來,中國的科技創(chuàng)新能力和科學(xué)技術(shù)水平在全球化進(jìn)程中受到越來越多的國家的競爭,對專利信息進(jìn)行分析顯得頗為重要。但是現(xiàn)有的大多數(shù)專利分析系統(tǒng)主要面對對象的英文專利的分析,中文專利分析系統(tǒng)少之又少,且現(xiàn)存的專利數(shù)據(jù)可視化分析工具仍存在較大不足,需要在今后中文專利數(shù)據(jù)可視化分析系統(tǒng)的發(fā)展過程中予以考慮和改進(jìn)。(1) 與英文專利數(shù)據(jù)不同,中文沒有使用空格對詞語進(jìn)行分割,同時(shí)中文一詞多義、同義詞等現(xiàn)象普遍存在,中文專利數(shù)據(jù)中對“詞”的處理相比英文更加復(fù)雜。本文采用Jieba分詞模塊對專利數(shù)據(jù)進(jìn)行分詞,并依據(jù)詞性篩去沒有實(shí)際含義的助詞、連詞等,然后再進(jìn)行進(jìn)一步處理。(2) 傳統(tǒng)的統(tǒng)計(jì)圖表往往不具備交互性,可視化效果一般。本文采用PyEcharts和Pygal模塊進(jìn)行動(dòng)態(tài)可視化展示,兼具交互性和優(yōu)秀的可視化效果,能夠給用戶帶來良好的操作體驗(yàn)。(3) 專利數(shù)據(jù)可視化分析工具與分析指標(biāo)匹配度不高。專利數(shù)據(jù)可視化分析的準(zhǔn)確性依賴于專利指標(biāo)的選取,因此本文通過專利特征文本聚類技術(shù)以及專利引證技術(shù)實(shí)現(xiàn)了專利技術(shù)指標(biāo)的選取及可視化分析。(4) 聚類分析功能有待挖掘。在現(xiàn)有基礎(chǔ)上提供文本聚類分析的工具很少,聚類效果不理想。因此本文采用了LDA以及K-Means文本聚類技術(shù)互補(bǔ)形成了有效的聚類技術(shù)支持,對專利進(jìn)行聚類分析。(5) 分析數(shù)據(jù)功能待完善。大多數(shù)專利分析系統(tǒng)只能從搜索到的數(shù)據(jù)進(jìn)行表層分析,過于簡單,不能深度挖掘使用者需要的信息,無法獲得直觀的效果。因此本文從多角度對專利數(shù)據(jù)進(jìn)行了多維度的可視化分析,從描述性統(tǒng)計(jì)分析到聚類分析、引證分析,旨在從專利數(shù)據(jù)中獲取更多具有研究性指導(dǎo)意義的信息。
專利數(shù)據(jù)可視化分析工具的使用效果將更加靈活多變,功能逐漸完善,適應(yīng)性漸強(qiáng),從專利數(shù)據(jù)分析到拓展型可視化分析的分析范圍也會(huì)越來越廣。因此本文研發(fā)并構(gòu)建了中文專利分析系統(tǒng),旨在通過可視化分析平臺的建立可以讓使用者從更高維度的直觀視角,深入專利分析的前沿領(lǐng)域,解決中文專利分析系統(tǒng)中的上述相關(guān)問題。
2.2 專利分析結(jié)果可視化
傳統(tǒng)的統(tǒng)計(jì)圖表一般是靜態(tài)的,用戶只能通過給出的圖表進(jìn)行分析判斷,而采用PyEcharts或Pygal模塊繪制的一些圖表可以在瀏覽器中方便地進(jìn)行點(diǎn)選、拖動(dòng)、縮放等操作,用戶可以方便地對不同年份、不同地區(qū)的專利數(shù)據(jù)進(jìn)行對比分析。
Echarts是一個(gè)基于JavaScript的開源項(xiàng)目,依賴ZRender矢量圖形庫,提供交互性強(qiáng)、自由度高的可視化圖表,包括柱形圖、折線圖、餅圖等統(tǒng)計(jì)圖表,還有結(jié)合地理位置的地圖、結(jié)合時(shí)間變化的Timeline組件等,也可以自定義鏈接跳轉(zhuǎn),給使用者提供了豐富的接口。
PyEcharts是用于生成Echarts的Python庫,將Python與Echarts結(jié)合,可以更方便地使用Python程序操作Echarts圖表的生成,從而使Python強(qiáng)大的數(shù)據(jù)處理與分析能力可以與Echarts美觀的圖表相結(jié)合,提供良好的可視化分析基礎(chǔ)。
Pygal同樣也是一個(gè)繪制圖表的第三方庫,提供了多種圖表形式,同樣具備交互性,并可以方便地生成頁面并單獨(dú)保存成SVG等格式的文件。
2.3 系統(tǒng)架構(gòu)
如圖1所示,本系統(tǒng)采用B/S三層架構(gòu),客戶端瀏覽器將請求發(fā)送給功能支持層,功能支持層收到相應(yīng)的請求后再對數(shù)據(jù)庫中的數(shù)據(jù)進(jìn)行操作,保證了數(shù)據(jù)對普通用戶的保密性。在系統(tǒng)的構(gòu)建過程中,充分體現(xiàn)了“高內(nèi)聚低耦合”的建設(shè)思想,為系統(tǒng)標(biāo)準(zhǔn)化和邏輯的復(fù)用打下了良好基礎(chǔ),易于擴(kuò)展和維護(hù)。相較于傳統(tǒng)的Java Web程序,本系統(tǒng)通過Python Django框架實(shí)現(xiàn),建設(shè)更簡單,減少了編程人員的工作量,并充分利用了Python強(qiáng)大的第三方庫資源:使用PyEcharts和Pygal模塊進(jìn)行動(dòng)態(tài)可視化展示,使用Jieba模塊進(jìn)行文本分詞和過濾,使用Sklearn模塊進(jìn)行文本聚類挖掘。用戶使用瀏覽器登錄注冊即可使用本系統(tǒng),登錄后通過點(diǎn)擊選擇數(shù)據(jù)和功能模塊,即可得到多層次、易于理解的動(dòng)態(tài)展示結(jié)果。
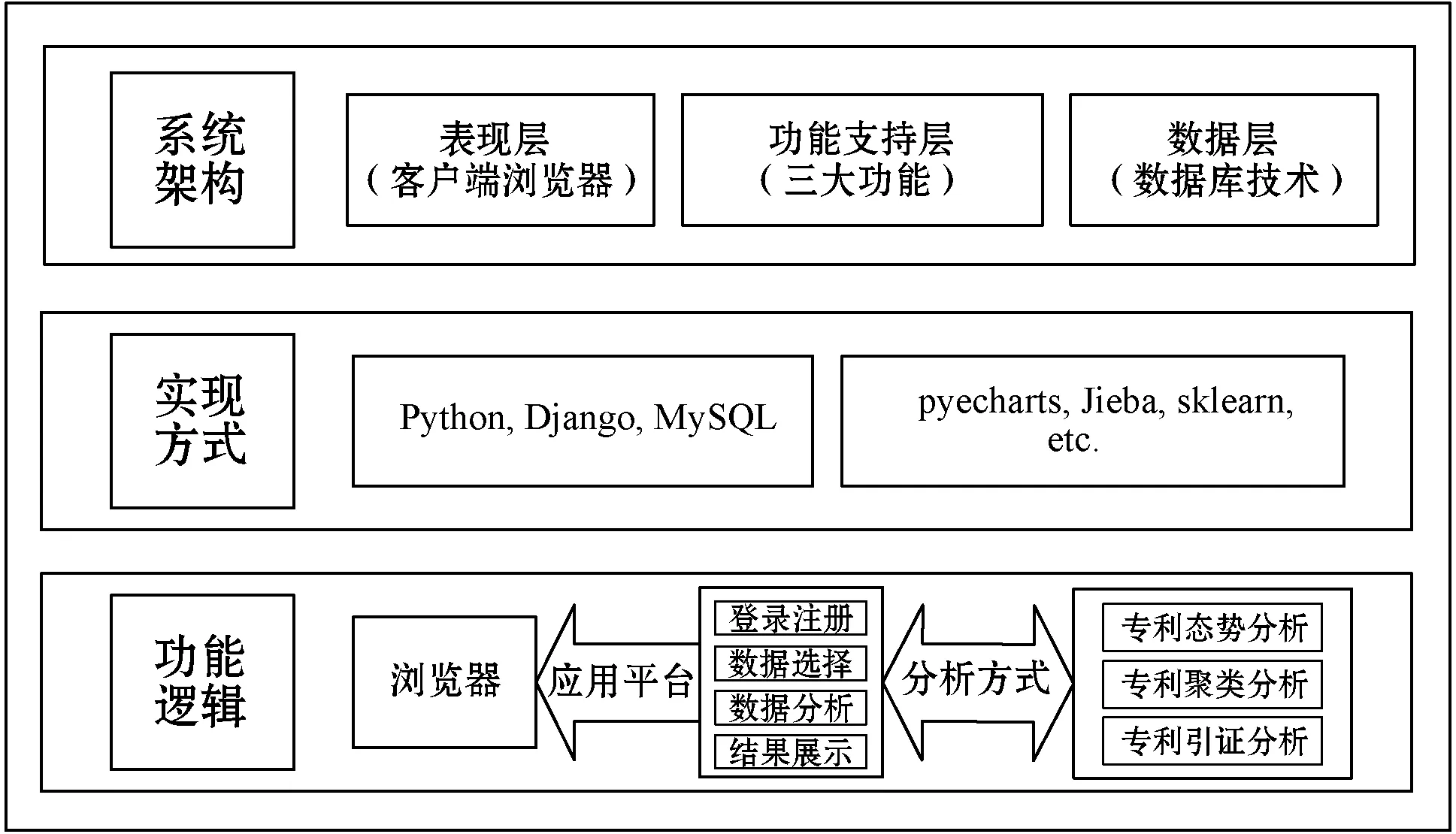
圖1 系統(tǒng)框架
2.4 系統(tǒng)流程設(shè)計(jì)
在中文專利分析系統(tǒng)中,用戶首先輸入用戶名、密碼登錄,校驗(yàn)通過后進(jìn)入系統(tǒng)。用戶可以選擇上傳數(shù)據(jù)源或選擇已有的數(shù)據(jù)源,選擇數(shù)據(jù)源后可以進(jìn)行專利態(tài)勢分析、專利聚類分析和專利引文分析,數(shù)據(jù)流圖如圖2所示。
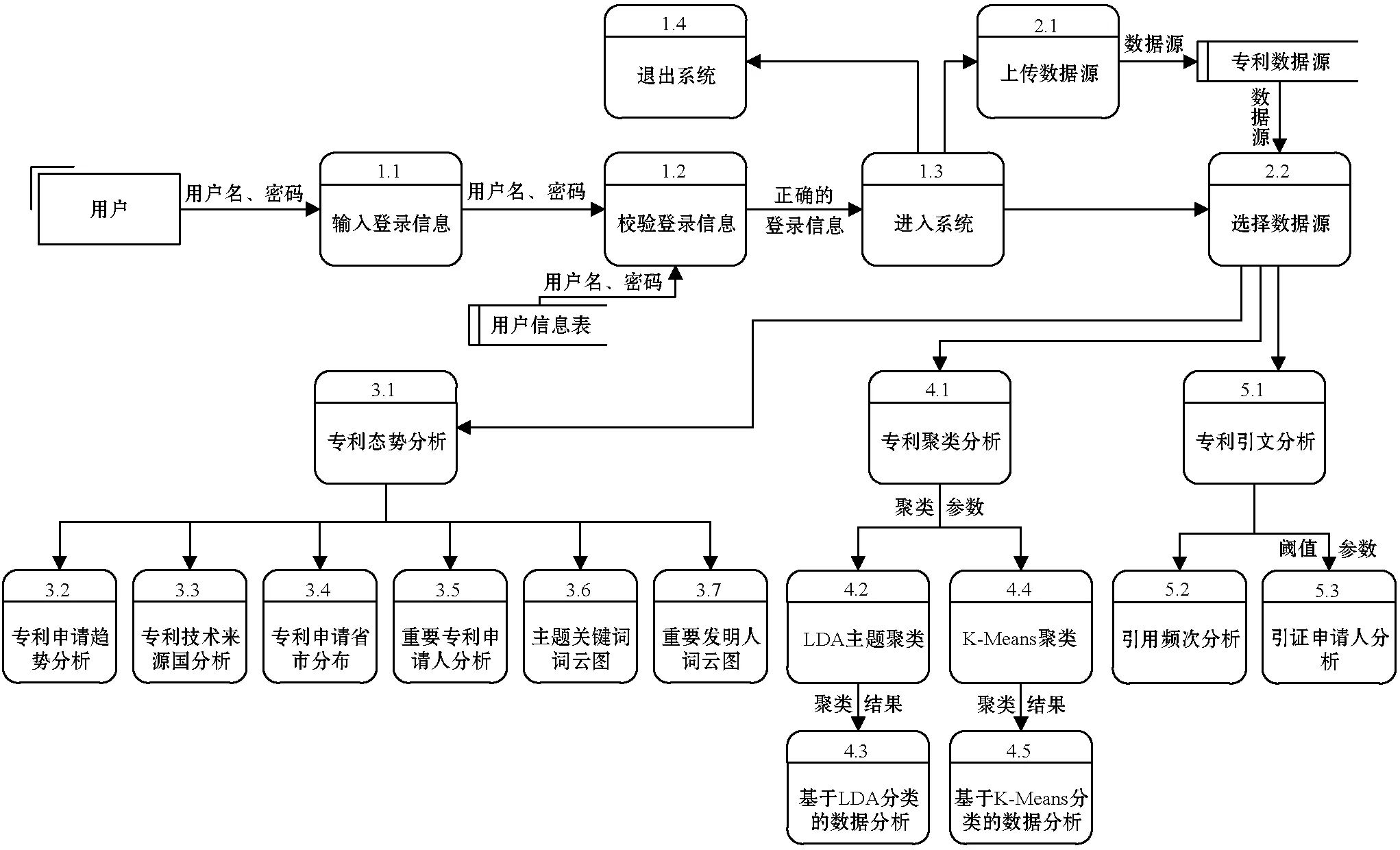
圖2 中文專利分析系統(tǒng)數(shù)據(jù)流圖
其中,專利態(tài)勢分析展示了專利數(shù)據(jù)源中的專利發(fā)展趨勢和分布,包括專利申請趨勢分析、專利技術(shù)來源國分析、國內(nèi)申請人省市分布、重要申請人分析、主題關(guān)鍵詞詞云圖和重要發(fā)明人詞云圖等功能;專利聚類分析包括LDA主題聚類和K-Means聚類兩種聚類算法,在完成聚類后可以基于聚類結(jié)果進(jìn)行進(jìn)一步分析,用于挖掘數(shù)據(jù)中蘊(yùn)含的較深層信息;專利引證分析包括引證次數(shù)分析和引證申請人分析,可以找出行業(yè)內(nèi)的重要專利,也可以分析申請人之間的引證關(guān)系,從而展示出專利申請人之間的聯(lián)系。
2.5 數(shù)據(jù)模型設(shè)計(jì)
如圖3所示,數(shù)據(jù)庫設(shè)計(jì)采用維度模型,即使用星型模式,根據(jù)業(yè)務(wù)流程將專利基礎(chǔ)信息劃分為What、Who、Where、When四個(gè)維度,每個(gè)專利對應(yīng)一個(gè)申請人、地區(qū)和公開日,但是一個(gè)申請人和一個(gè)地區(qū)可以對應(yīng)多個(gè)專利,減少了數(shù)據(jù)的冗余,提高了數(shù)據(jù)的讀寫效率。按照維度進(jìn)行預(yù)先的統(tǒng)計(jì)、分類、排序等操作,通過這些預(yù)處理,能夠極大地提升數(shù)據(jù)倉庫的處理能力。相比于3NF的建模方法,星型模式的性能優(yōu)勢更明顯。
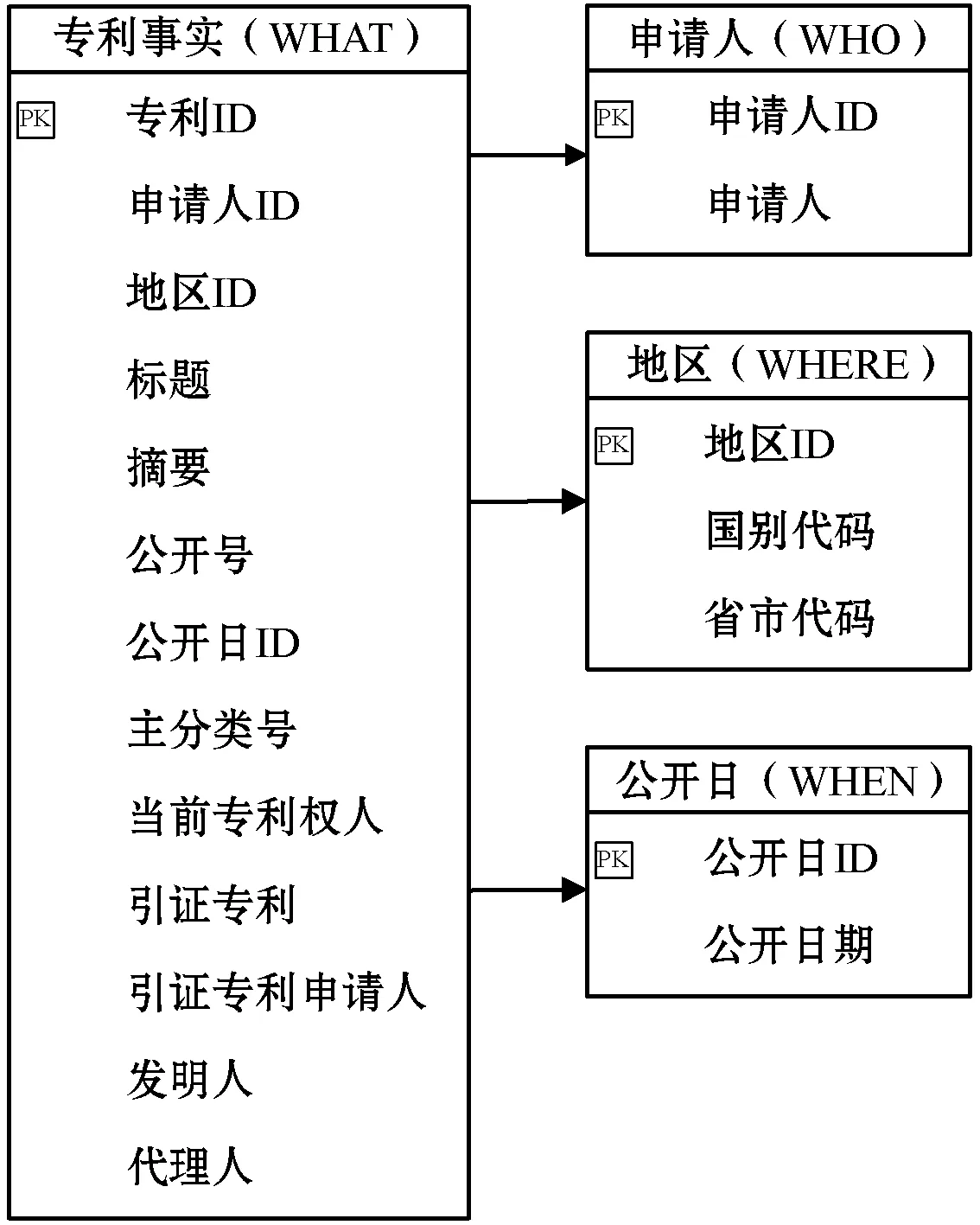
圖3 數(shù)據(jù)維度模型
3 中文專利數(shù)據(jù)的可視化分析
本文基于Django框架搭建平臺,簡單實(shí)現(xiàn)了專利態(tài)勢分析、專利聚類分析和專利引證分析,并利用可視化模塊展示出來,達(dá)到更為直觀簡潔的效果。本文主要使用了PyEcharts和Pygal模塊,兩者均能實(shí)現(xiàn)圖表的動(dòng)態(tài)可視化效果,并具有較好的交互性,能夠給用戶帶來良好的使用體驗(yàn)。系統(tǒng)實(shí)驗(yàn)環(huán)境及主要軟件模塊版本為:Windows Server 2012 R2系統(tǒng),IIS 8服務(wù)器,Python 3.7,Django 3.0.5,PyEcharts 1.7.1,Pygal 2.4.0。采用光纖領(lǐng)域中國發(fā)明專利數(shù)據(jù)進(jìn)行測試,數(shù)據(jù)截至2017年12月1日。
3.1 專利態(tài)勢分析
(1) 專利申請量的趨勢分析。技術(shù)領(lǐng)域?qū)@暾埩康淖兓厔菀子诮y(tǒng)計(jì),且能直接反映該技術(shù)所處的發(fā)展階段,可用于判斷該技術(shù)是否還有價(jià)值,為企業(yè)決定是否投資以及投資力度的管控提供重要參考依據(jù)。一般將技術(shù)的生命周期劃分為四個(gè)階段:導(dǎo)入期、成長期、成熟期和衰退期。根據(jù)對技術(shù)當(dāng)前所處生命周期階段的正確判斷,企業(yè)可以制定不同的技術(shù)策略,當(dāng)技術(shù)將進(jìn)入衰退期時(shí),企業(yè)就該去尋求新技術(shù)。
如圖4示例,在2003年前,該領(lǐng)域?qū)@暾埩可伲袠I(yè)處于導(dǎo)入期,2003年-2016年,該領(lǐng)域?qū)@暾埩考ぴ觯袠I(yè)處于成長期。通過專利態(tài)勢分析可視化,可以進(jìn)一步了解某領(lǐng)域?qū)@l(fā)展情況趨勢,能夠使學(xué)界業(yè)界的研究者更加直觀感受到某領(lǐng)域中某項(xiàng)技術(shù)的潛力價(jià)值。
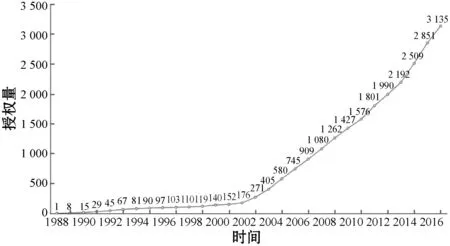
圖4 專利授權(quán)量累計(jì)圖示例
(2) 專利地域分析。專利的質(zhì)量與數(shù)量是企業(yè)創(chuàng)新能力和核心競爭能力的體現(xiàn),是企業(yè)在該行業(yè)身份及地位的象征,是國家創(chuàng)新力的集中體現(xiàn),是國家綜合國力的重要指標(biāo)。在經(jīng)濟(jì)全球化的時(shí)代背景下,企業(yè)了解國內(nèi)競爭者、了解國際形勢,是生存與發(fā)展的需要。而通過對專利的地域分析,企業(yè)可以快速明確國內(nèi)主要競爭者以及外國的潛在競爭者。
本文組合使用時(shí)間軸和地圖組件,將地域分布和時(shí)間維度結(jié)合起來,并使用動(dòng)畫展示,能夠讓使用者一目了然地看到專利申請地域分布隨時(shí)間的變化,快速定位集聚效應(yīng)。
(3) 關(guān)鍵人物和信息分析。少數(shù)的專利申請人通常掌握了大量的專利,少數(shù)的發(fā)明人是該領(lǐng)域的“關(guān)鍵人”,是技術(shù)發(fā)展的“帶頭人”,對一個(gè)行業(yè)的發(fā)展而言舉足輕重,行業(yè)帶頭人也是企業(yè)人才爭奪的重要對象。發(fā)揮“關(guān)鍵人”的關(guān)鍵作用,其首要前提是需要明確關(guān)鍵人。專利數(shù)據(jù)中的一些關(guān)鍵詞是技術(shù)發(fā)展的方向指標(biāo),對行業(yè)發(fā)展的未來有指導(dǎo)作用。通過對文本進(jìn)行分詞、去停用詞和詞頻統(tǒng)計(jì)等操作,可以得出行業(yè)關(guān)鍵詞,如圖5所示。

圖5 關(guān)鍵詞詞云圖示例
本文通過詞云圖將統(tǒng)計(jì)結(jié)果呈現(xiàn)出來,從圖6中可以清晰地看出關(guān)鍵的發(fā)明人和發(fā)明內(nèi)容。通過高頻關(guān)鍵詞繪制的詞云,可以直接了解到某領(lǐng)域的技術(shù)“帶頭人”以及主流的專利技術(shù)分布情況。
3.2 專利聚類分析
聚類是將一個(gè)數(shù)據(jù)集按照某一特定標(biāo)準(zhǔn)分割成多個(gè)不同的類或簇,同一簇中的數(shù)據(jù)對象相似度盡可能高,同時(shí)不同簇之間的數(shù)據(jù)對象差異度也盡可能高。而文本聚類則是利用聚類不需訓(xùn)練過程及其較為優(yōu)秀的自動(dòng)化處理能力,將文檔原本的自然語言文字信息轉(zhuǎn)化為數(shù)學(xué)信息,對文本信息進(jìn)行分簇。
文本聚類的過程如下:首先,基于中文專利數(shù)據(jù)的特點(diǎn),使用Jieba分詞模塊對文本進(jìn)行分詞處理,然后進(jìn)行詞頻統(tǒng)計(jì),對一些高頻率但無意義的停用詞進(jìn)行過濾;然后,利用詞袋模型和文本向量方法將數(shù)據(jù)轉(zhuǎn)換為詞向量并構(gòu)建詞權(quán)重,以此評估一個(gè)詞語在文本中重要性。最后,選擇聚類算法進(jìn)行文本聚類,再根據(jù)結(jié)果進(jìn)行評估與參數(shù)調(diào)整,得出最終結(jié)果。本文主要使用LDA主題模型和K-Means進(jìn)行專利文本聚類分析。
1) LDA主題模型聚類分析。LDA(Latent Dirichlet Allocation)是一種包含了詞、主題、文檔三層結(jié)構(gòu)的文檔主題生成模型,因此也被稱為三層貝葉斯概率模型。主題分布與詞分布均是多項(xiàng)式分布。同時(shí),LDA作為一種無監(jiān)督的機(jī)器學(xué)習(xí)技術(shù),能夠從大規(guī)模的文檔集和語料庫中提取出來潛在的主題信息。
用d表示文檔集合D中的每篇文檔,w為文檔d中的單詞,t為主題,則文檔d中出現(xiàn)單詞w的概率如式(1)所示。
P(w|d)=P(w|t)·P(t|d)
(1)
我們將專利標(biāo)題輸入LDA模型,根據(jù)專利的主題將專利分進(jìn)不同的類別當(dāng)中,然后輸出每個(gè)類別的前n個(gè)主題詞。
以下為在專利分析中使用LDA主題模型進(jìn)行文本聚類的主要步驟:
(1) 使用Jieba對每個(gè)專利的標(biāo)題字段進(jìn)行分詞,過濾固定停用詞、量詞和標(biāo)點(diǎn)符號,構(gòu)建詞袋。
(2) 統(tǒng)計(jì)詞頻,使用Sklearn中的CountVectorizer函數(shù)得到所有專利標(biāo)題中各個(gè)詞的詞頻向量和主題詞袋構(gòu)成的列表。
(3) 使用Sklearn中的LatentDirichletAllocation函數(shù)進(jìn)行LDA聚類,設(shè)置主題個(gè)數(shù)和最大迭代次數(shù)等參數(shù),可以得到每篇專利文獻(xiàn)屬于每個(gè)主題的概率矩陣和每個(gè)主題中主題詞的分布概率矩陣。
(4) 標(biāo)記每篇專利文獻(xiàn)所屬的主題,并輸出各主題中詞頻最高的n個(gè)主題詞。
使用LDA主題聚類模型對專利數(shù)據(jù)的“標(biāo)題”字段進(jìn)行聚類,用戶可以設(shè)置最大迭代次數(shù)m和分類組別數(shù)n。其中m越大,分組的準(zhǔn)確性越高,但相應(yīng)用戶需要等待實(shí)時(shí)運(yùn)算的時(shí)間也會(huì)越長。
通過對比,用戶可以看到各國家、地區(qū)和企業(yè)專利的類別分布,并以此判斷不同國家、地區(qū)和企業(yè)研究方向的差異,同時(shí)也可對比分析各類別的發(fā)展趨勢。用戶還可以使用LDA主題分類對數(shù)據(jù)集進(jìn)行進(jìn)一步拆分研究。LDA主題聚類模型分組結(jié)果示例如圖6所示。

圖6 LDA主題聚類模型分組結(jié)果示例
2) K-Means算法聚類分析。K-Means算法是較為傳統(tǒng)也較為基礎(chǔ)的一種無監(jiān)督的聚類分析算法,因其簡潔高效而被廣泛使用,其中的基本思想是從有N個(gè)元組或記錄的數(shù)據(jù)集劃分為K個(gè)簇,然后根據(jù)給定的初始點(diǎn)進(jìn)行反復(fù)迭代,常用歐氏距離計(jì)算公式計(jì)算簇每個(gè)數(shù)據(jù)與聚類中心點(diǎn)的距離,使得簇內(nèi)的數(shù)據(jù)距離越來越近,簇與簇之間的距離越來越遠(yuǎn),進(jìn)而達(dá)到優(yōu)化簇的目的。
K-Means算法[9]如下:
假設(shè)有一數(shù)據(jù)集{x(1),x(2),…,x(m)},將其分為n個(gè)簇。
(1) 在樣本中隨機(jī)選取n個(gè)聚類質(zhì)心點(diǎn){1,2,…,n},其中i為簇Ci的聚類質(zhì)心點(diǎn),如式(2)所示。
(2)
(2) 計(jì)算所有質(zhì)心點(diǎn)與各個(gè)簇之間的距離,再將該點(diǎn)劃入最近的簇中。
(3) 重新計(jì)算每個(gè)簇的質(zhì)心點(diǎn)。
(4) 重復(fù)步驟(2)和步驟(3)直至收斂。
使用K-Means聚類算法對專利數(shù)據(jù)的“標(biāo)題”字段進(jìn)行聚類,用戶可以設(shè)置分類組別數(shù)n。
與LDA主題聚類的預(yù)處理方式相同,系統(tǒng)過濾停用詞、量詞和標(biāo)點(diǎn)符號后,使用LDA主題模型進(jìn)行聚類運(yùn)算;運(yùn)算結(jié)束后,系統(tǒng)對數(shù)據(jù)集中的數(shù)據(jù)標(biāo)注K-Means分類。同樣,通過對比,用戶可以分析各國家、地區(qū)和企業(yè)專利的類別分布以及各類別的發(fā)展趨勢。用戶也可以選擇將每組單獨(dú)保存為數(shù)據(jù)集進(jìn)行進(jìn)一步拆分研究。
如圖7所示,示例將專利數(shù)據(jù)使用K-Means算法聚為5類,不同類別間國家分布可能差異顯著,可由此分析各國在不同方面專利技術(shù)的優(yōu)勢和劣勢。
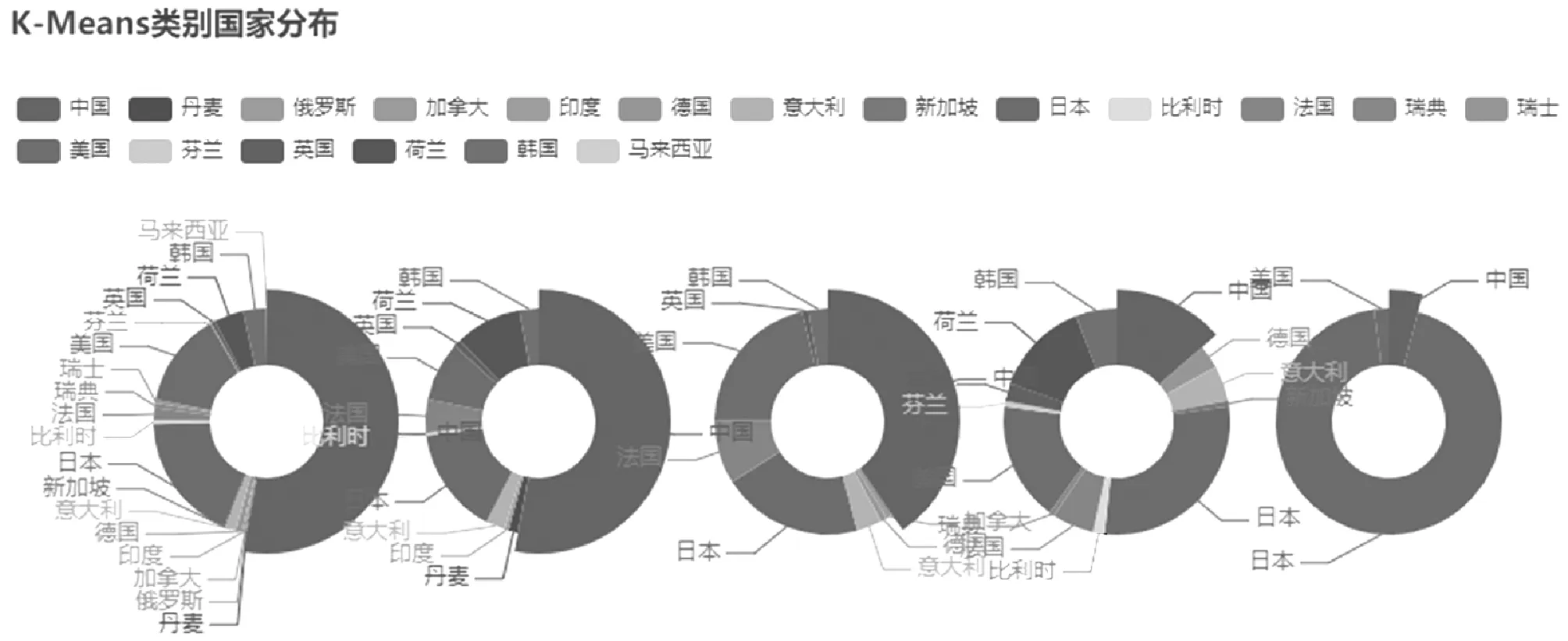
圖7 K-Means類別下的專利技術(shù)來源國分布示例
本文對聚類結(jié)果進(jìn)行了可視化展示,并支持進(jìn)一步迭代研究,能夠幫助使用者直觀、快速地發(fā)現(xiàn)更深層次的信息。
3.3 專利引證分析
專利被引用的頻次表現(xiàn)了該專利在某技術(shù)領(lǐng)域內(nèi)的重要程度,如果某專利被大量后續(xù)專利引用,說明該專利具有較高的創(chuàng)新性和先進(jìn)性,可以通過柱形圖展示;如果某申請人有較多專利被引用,則說明該申請人在該領(lǐng)域擁有技術(shù)優(yōu)勢[10]。如圖8所示,用戶可以設(shè)置閾值并通過網(wǎng)絡(luò)圖觀察專利申請人之間的引證關(guān)系并發(fā)現(xiàn)重要申請人。與此同時(shí),運(yùn)用專利引證關(guān)系網(wǎng)絡(luò),可以探究不同專利、不同申請人之間的潛在聯(lián)系,為之后的專利申請乃至企業(yè)之間的科技研究合作提供借鑒之處。
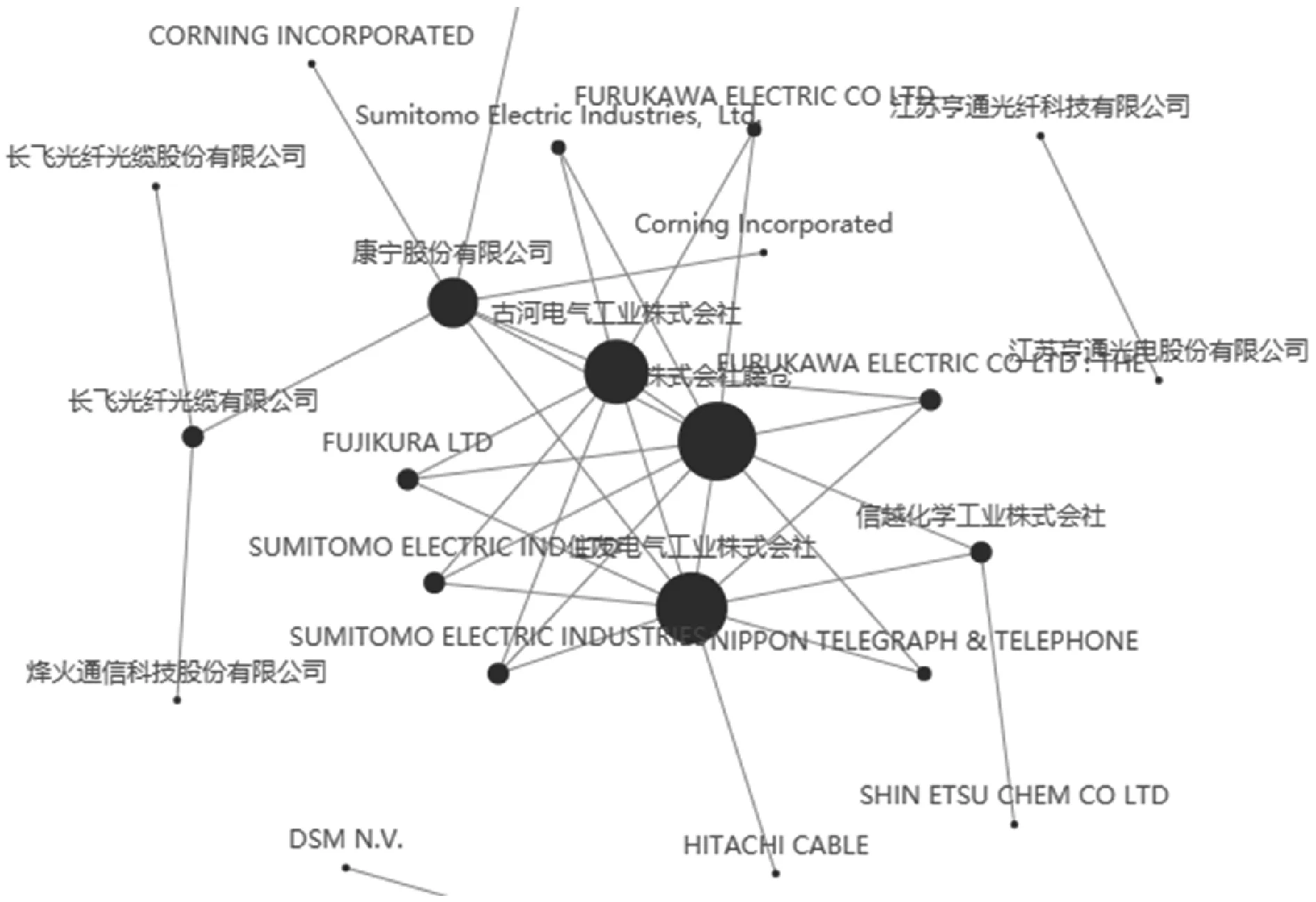
圖8 專利申請人引證關(guān)系網(wǎng)絡(luò)圖示例
4 結(jié) 語
本文基于Django框架和PyEcharts等可視化模塊,結(jié)合文本挖掘、機(jī)器學(xué)習(xí)技術(shù),設(shè)計(jì)并簡單實(shí)現(xiàn)了中文專利數(shù)據(jù)可視化分析系統(tǒng)。從專利態(tài)勢分析、專利聚類分析、專利引證分析三方面,對專利數(shù)據(jù)進(jìn)行多角度分析,從描述性統(tǒng)計(jì)分析到數(shù)據(jù)挖掘深層分析,將分析結(jié)果通過可視化模塊直觀地呈現(xiàn)出來,有利于用戶在檢索專利文獻(xiàn)時(shí)盡快獲得深層次的知識,有利于企業(yè)借鑒新技術(shù),提高運(yùn)營效率,一定程度上彌補(bǔ)了中文專利數(shù)據(jù)可視化分析研究的不足。在此基礎(chǔ)上,本文也為專利分析系統(tǒng)的開發(fā)提供了一定的理論指導(dǎo)。
使用部分發(fā)明專利數(shù)據(jù)進(jìn)行了測試,本文能夠較好地適應(yīng)中文專利數(shù)據(jù),并生成美觀的交互式可視化圖表,聚類算法和進(jìn)一步的統(tǒng)計(jì)分析也能夠在一定程度上發(fā)掘各國、各企業(yè)在不同類別專利上的優(yōu)勢和不足,為企事業(yè)單位的研究和決策提供一定的依據(jù),相較目前的專利分析系統(tǒng)在中文語言支持和可視化方面有一定的改進(jìn)之處,具備較好的研究前景和一定的參考價(jià)值。
同時(shí),本文還存在一些不足,系統(tǒng)現(xiàn)有的功能實(shí)現(xiàn)完好,但仍有待進(jìn)一步擴(kuò)充完善,引入更為先進(jìn)的專利分析技術(shù)。對于專利數(shù)據(jù)的深層次挖掘的研究局限于聚類分析以及引證分析層面,在之后的研究中,可以將更多的機(jī)器學(xué)習(xí)乃至深度學(xué)習(xí)的數(shù)據(jù)分析挖掘技術(shù)應(yīng)用于專利數(shù)據(jù)的研究,旨在最大程度挖掘中文專利數(shù)據(jù)的價(jià)值,并通過多樣的可視化圖表將分析結(jié)果展現(xiàn)出來。
猜你喜歡
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2021-01-21 09:15:02
海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
傳媒評論(2019年4期)2019-07-13 05:49:14
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
