基于關鍵字的RDF聚合查詢研究
2023-02-17 01:54:02馬曉芳楊衛東
計算機應用與軟件 2023年1期
馬曉芳 楊衛東
(復旦大學計算機科學與技術系 上海 201203)
0 引 言
隨著語義網、知識圖譜等技術的快速發展,結構化語義數據的應用越來越廣泛,這些數據通常使用資源描述框架(RDF)來表示。互聯網上出現了大量RDF形式的數據,如Dbpeida[1]、Yago[2]、Freebase[3]等。利用這些數據可以實現在用戶搜索時由一般文檔檢索轉換為知識檢索,提高返回結果與用戶搜索意圖的相關度,避免無關信息的展示。對于RDF數據中信息的檢索,可以通過W3C組織推薦的標準查詢語言SPARQL來實現。但是SPARQL語法非常復雜,且使用URI表示的數據資源可讀性較差,要準確書寫SPARQL語句還需要用戶對原始數據圖的模式信息有一定的先驗知識,這使得一般用戶從RDF數據中獲取所需信息是非常困難的,所以對于RDF數據的關鍵字查詢或者自然語言問句查詢的研究得到了越來越廣泛的關注,旨在方便普通用戶獲取RDF數據信息,實現語義檢索。相比于自然語言問句,RDF的關鍵字查詢更加接近于用戶的日常檢索習慣也更簡潔易用,并且可以包含更多更廣泛的查詢信息。但是,由于關鍵字輸入中缺少語句中必要的依賴信息,使得對于用戶查詢意圖的理解相較于自然語言更加困難。
對于RDF數據基于關鍵字的信息檢索研究,主要可以分為兩大類[12]。一類是將關鍵字匹配到原始數據圖上的元素后,通過在整個數據圖上做檢索,獲得覆蓋全部匹配元素的最小子結構,從而直接得到查詢結果[7,10-11];第二類則是先將關鍵字查詢轉換為意圖匹配的結構化查詢語句,之后再通過現有的查詢引擎執行語句來獲得最終的結果[6,8-9]。文獻[11]通過劃分子圖對數據圖進行索引,有效降低了搜索空間。文獻[8]通過在擴展模式圖上進行檢索確定查詢結構,文獻[6]的查詢模式與文獻[8]類似,并且在結果排序時考慮了給定查詢中每個關鍵字對于其他關鍵字解釋的影響。
直接查詢和查詢轉換兩類方法都可以實現對于一般關鍵字查詢的支持,但是直接查詢方法只能返回圖中存在的元素作為查詢結果;查詢轉換方法也只能得到只包含查詢模式的查詢語句,無法充分利用SPARQL所支持的豐富查詢操作。上述相關研究的重點在于對圖進行索引,以降低搜索空間,加快檢索效率,而忽略了對于統計信息的查詢。例如,對于查詢Q1={num, student, university0}表示“查詢university0中的學生數”,Q2={Article, max, volume}表示“查詢卷數最多的文章”,num/max所指示的查詢意圖無法被正確解析。同時,對于Q2中的關鍵字“max”可能指示MAX或TOP1類型的聚合操作,也可能匹配到名為“Max Robert”的人,對應查詢意圖為“學者max所發表文章的卷數”,由于關鍵字是否匹配聚合查詢的不確定性,使得查詢意圖的確定更加困難。
統計查詢是常用的,但在當前RDF關鍵字查詢研究中無法支持對其意圖的正確解析。在關系數據庫上已有算法對支持聚合關鍵字的查詢進行了研究[4-5]。SQAK[4]通過限制num、max等特殊詞語一定匹配聚合操作,并使用保留關鍵字WITH確定查詢解釋,最終轉換為SQL的子集rSQL。PowerQ[5]則需要用戶交互信息進行支持,得到注釋圖模式并轉換為SQL查詢。同時,RDF數據上的自然語言問句查詢也有研究對聚合查詢進行處理,文獻[13]通過句子中的依存關系,確定用戶查詢意圖。TBSL[14]則通過問句的語義表征,確定所對應的SPARQL模板,再將命名實體等加入插槽中。
由于數據結構的不同以及語句依存關系的缺失,RDF上的聚合關鍵字查詢無法直接利用上述方法實現。此外,已有聚合關鍵詞的研究忽視了聚合操作關鍵字可能匹配到一般字面量的情況,而是將聚合關鍵字作為特殊的保留詞[4-5],這會限制查詢的表達能力,錯過可能的查詢解釋。為了使用戶可以利用簡單的關鍵字進行查詢,本文不對輸入內容做限制,不強制用戶輸入指定的聚合關鍵字。對于可能指示聚合意圖的關鍵字,我們會在匹配階段計算其為聚合關鍵字的概率,從而確定可能的查詢解釋,再通過在模式圖上根據查詢解釋中的元素進行擴展,得到查詢意圖。
相比于關系數據,RDF數據還需要考慮聚合查詢對于查詢結構圖連接方式的影響,例如對于查詢Q3= {AssistantProfessor, interest, sames as, fullprofessor1},其對應的查詢結構圖如圖1所示,操作符“=”連接了兩個不同的節點,轉換后的SPARQL查詢語句如圖2所示,通過filter子句對查詢意圖進行了準確的描述。
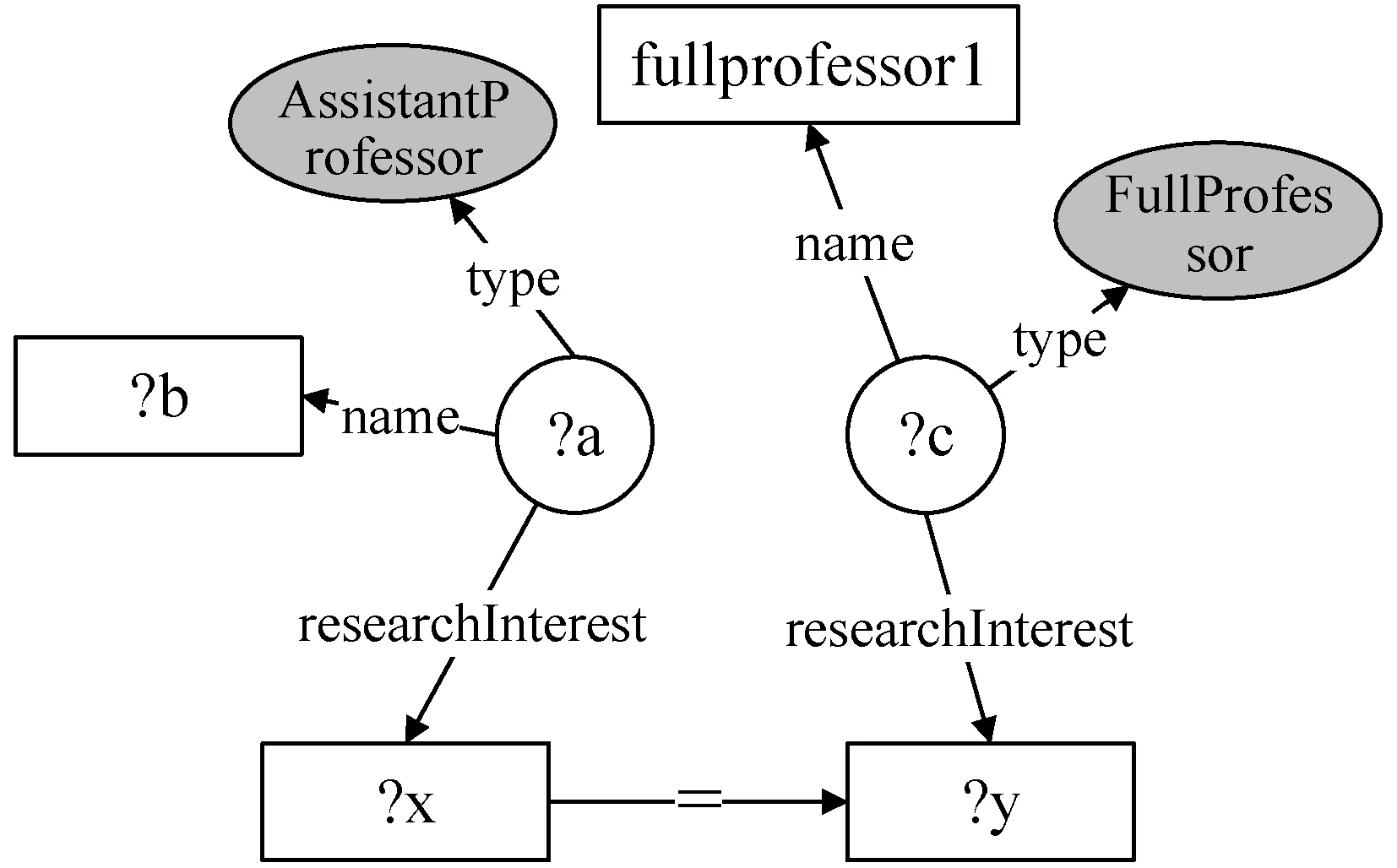
圖1 查詢Q1對應的查詢結構圖

圖2 Q3對應的SPARQL查詢
通過上述分析本文提出了包含聚合信息的關鍵字查詢轉換算法,將查詢統計信息的關鍵字轉換為帶聚合函數的SPARQL語句,實現對于MAX、AVG、MIN、COUNT、SUM及GROUP BY等操作的支持。本文主要貢獻如下:(1) 定義帶有聚合信息及查詢結構圖的查詢意圖,給出具體的描述及含義;(2) 對聚合操作進行分類,并構造關鍵字與其匹配的字典,在關鍵字映射階段,同時獲得關鍵字元素及聚合信息;(3) 提出查詢意圖對應分數的計算方法,結合查詢結構圖與聚合信息,獲得查詢意圖的匹配分數;(4) 針對所提出的查詢意圖,設計模式圖上的查詢算法及SPARQL語句生成算法。
1 概述和定義
1.1 RDF數據
RDF數據的基本組成單元為三元組
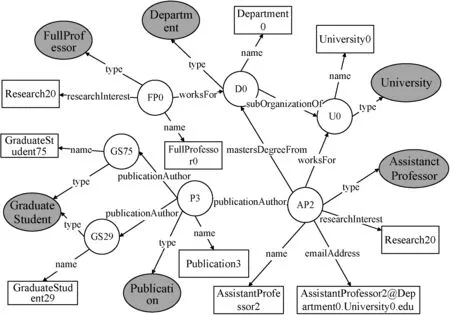
圖3 RDF數據圖示例
1.2 相關定義
為了支持將關鍵字查詢轉換為帶有聚合函數的標準查詢語句,實現查詢語義的擴充,本文提出了特定的查詢意圖概念,并對相關定義描述如下。
定義1查詢意圖。關鍵字查詢可能對應的查詢意圖定義為I=(G,A),其中:G為查詢結構圖,用于描述查詢內容之間的語義關系;A則為聚合信息,當查詢不含聚合意圖時,A為null。查詢圖與聚合信息的具體定義分別在定義2和定義3中給出。
定義2查詢圖。查詢結構圖G=(V,E)是模式圖的一幅子圖,或者是由比較操作符連接的多個子圖,對于查詢中的每一個關鍵字,查詢圖中都包含與之對應的關鍵元素。
定義3聚合信息。聚合信息的形式為A=(operation,ST,AT),其中operation為查詢所屬聚合操作類型,ST為檢索對象,AT為聚合對象,限定ST與AT為查詢圖G所包含的元素,或為null。
定義4查詢解釋。在關鍵字匹配階段獲得查詢解釋,根據查詢解釋進行圖檢索可以得到查詢意圖。查詢解釋定義為E=(c,A),其中c為一組關鍵元素,A則為對應的聚合信息。
1.3 問題描述與算法結構
包含聚合信息的關鍵字查詢轉換算法是將RDF數據上關鍵字查詢轉換為SPARQL查詢語句的研究,旨在理解用戶輸入關鍵字的查詢意圖,并支持轉換為復雜的聚合操作。對于給定的RDF數據圖G=(E,V,L),我們定義用戶輸入的關鍵字查詢為一組關鍵字的集合,即Q={k1,k2,…,kn}。每一個關鍵字ki,可能為指示聚合意圖的關鍵字或為一般關鍵字,對于一般關鍵字則獲得RDF圖中與其匹配的元素集合Mi。確定查詢解釋后,在模式圖上根據所包含的關鍵元素進行擴展,并考慮聚合操作對于圖連接性的影響,獲得查詢結構圖,再結合聚合信息得到對應的查詢意圖。根據所提出的意圖分數計算方法,選擇前k查詢意圖,將其轉換為對應的SPARQL查詢語句。
所以,本文算法將關鍵字轉換為SPARQL查詢的主要步驟為:(1) 檢索關鍵字索引,與聚合操作詞典,獲得查詢解釋;(2) 提取RDF模式圖,并根據查詢解釋在圖上進行檢索得到排序的候選查詢意圖;(3) 將查詢意圖一對一地轉換為SPARQL查詢語句。算法具體結構如圖4所示,輸入為數據圖與關鍵字查詢,輸出則為符合查詢意圖的SPARQL語句。
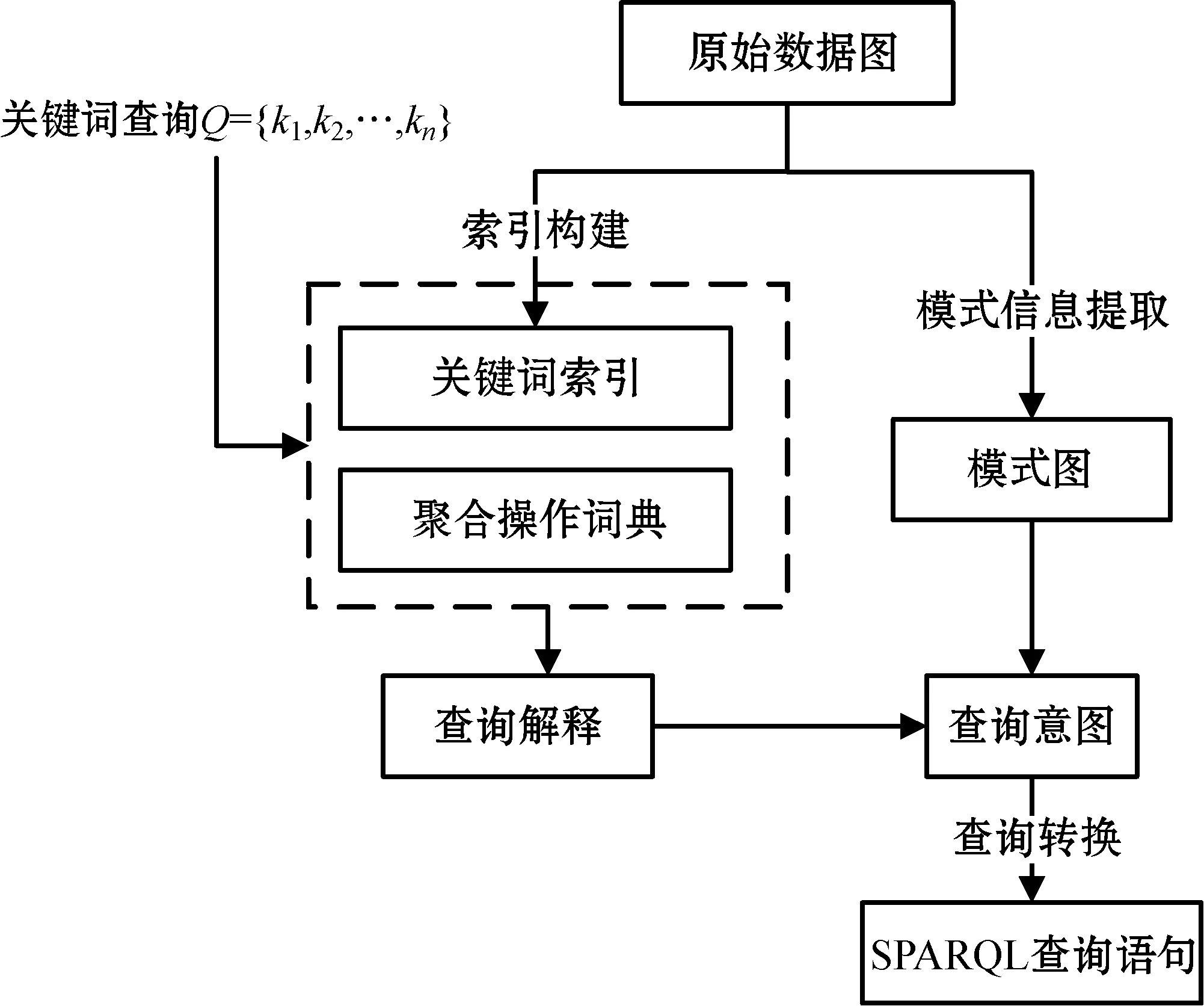
圖4 RDF關鍵字查詢結構圖
2 關鍵字查詢解釋
2.1 關鍵字映射
為了根據關鍵字獲得可能匹配的圖元素,我們設計了特定的圖元素存儲結構,并構建關鍵字-圖元素的映射表。我們認為用戶查詢時會通過name、title等屬性所對應的值來描述實體,所以我們考慮關鍵字匹配到屬性值節點,類別節點和關系標簽三種情況,即?m∈Mi,m∈VL∪VC∪L。對于圖中的每一個元素,我們將其存儲在定義的數據結構(class,property,value)中,其中,class為元素對應的類別信息,property為邊標簽,value則為屬性值。為了實現關鍵字的快速匹配,并且支持關鍵字與元素信息部分匹配的情況,我們構建了關鍵字的倒排索引。
2.2 聚合操作與聚合信息
根據定義3可知,聚合信息的結構為A=(operation,ST,AT),ST所對應變量出現在SELECT子句中,并可能被MAX、MIN等操作限制,同時也可能出現在group by子句中。當AT不為空時,所對應對象出現在order by、having或filter操作中。operation則為所屬的操作類型,聚合操作的分類及描述如表1所示。

表1 聚合操作分類
通過對SPARQL所支持聚合查詢的分析,我們對聚合操作進行了分類,具體定義如表1所示。對于TOP1_G與TOPN_G類型的聚合操作,需要group by來實現查詢意圖,而其他聚合操作則不需要,這通過聚合信息是否為描述數值型字面量的關系標簽來確定。例如“students with most classes”屬于TOP1_GF,而對于“students with highest score”則屬于TOP1_F,因為score匹配為關系標簽,且其賓語為數值型對象。TOP1_G使用group by、order by、count與limit 1獲取排名最前的對象。>/<和EQU使用filter子句實現對于結果的過濾,并且該類型的聚合操作會影響查詢結構圖的連接性,需要考慮操作函數連接子圖以獲得查詢結構的情況。
TOPN使用group by、having、count對查詢對象分組,對聚合對象進行計數。MAX、MIN、AVG、COUNT及SUM則為簡單聚合查詢,查詢模塊中的AT為null,直接將聚合函數作用于ST。MAX與TOP1的區別在于MAX是直接對屬性值最查詢,而TOP1則查詢具有最值屬性的對象,注意:不是包含“max”就對應MAX類別,也有可能是TOP1類型。
如果ki與聚合詞典中的key值相匹配,則為候選聚合關鍵字,如果不存在圖元素與ki相匹配,則ki為聚合關鍵字的概率P(op|ki)為1。當存在圖元素與其匹配時,則計算ki匹配圖元素的距離倒數S:
(1)
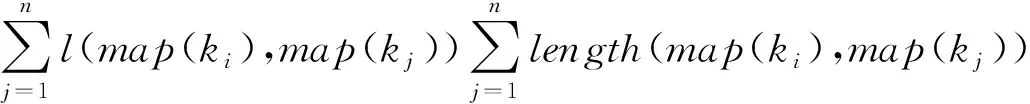
(2)
綜上所述,不存在圖元素與ki匹配時P為1,否則ki與所匹配字面量編輯距離越小,P越小;ki對應圖元素與其他圖元素的距離越小,P越小。當P大于閾值時,認為ki與聚合操作匹配。
2.3 查詢解釋確定
在查詢解釋確定階段,對于每一個ki,查看聚合詞典,如果ki是候選的聚合關鍵字則確定是否存在圖元素與其匹配,如果不存在,則確定ki為聚合關鍵字;如果存在,則得到匹配的元素Mi。然后計算Mi所有組合情況,得到元素集合C,對于每一個c屬于C,計算ci為聚合關鍵字的概率。
同時,由聚合操作的分類可知存在聚合操作由詞語的比較級或最高級指示,這些特殊的關鍵字除了指示聚合操作外,其原型形式還會與圖元素匹配提供信息。所以對于比較級/最高級形式的關鍵字,獲得對應聚合類型后,將原型詞語加入到一般關鍵字集合中,用于圖元素匹配,查詢解釋獲取算法如算法1所示。
算法1查詢意圖解釋生成算法
輸入: 關鍵詞查詢Q={k1,k2,…,kn}。
輸出:一組查詢解釋。
1.forki in Qdo
2. Mi=map.get(ki)
//關鍵元素集合
3.ifkiin Operation map.keys()
//候選聚合關鍵字
4.ifMi==null
//確定為聚合關鍵字
5. aggType=Operation map.get(ki); aggPos=i
6.ifkiin CompSup_Map.Keys0then
7. archetype=CompSup_map.get(ki)
8. Mi=map.get(archetype)
9.elseMi.add(Operation map.get(ki))
10.elseMi=map.get(ki); aggPos=i
11.C=cartesianProduct(Mi)
12.ifaggType==null && aggPos!=null
//存在候選聚合
13.forc in C:
14.ifP(op|ci>threshold
15. ci=aggType=Operation_map.get(ki); aggPos=i
16. aggType: Operation_map.get(ki)
17. Element.add(getAgg(c, aggType, aggPos))
18.elseElement.add(
19.elseifaggType=nullthenreturn
20.elseElement=getAgg(C, aggType, aggPos)
21.returnElement
22.endif
其中,getAgg函數用于聚合信息的獲取,輸入關鍵元素組合,以及聚合操作出現的位置。對于每一組c屬于C,如果aggType為MAX/MIN,檢查聚合位置前是否為類別,如果存在類別,則將aggType對應修改為TOP1類型;對于TOP1類型的,則根據聚合關鍵字之后的對象是否為數值型屬性,具體分為TOP1_G與TOP1。確定所屬聚合類別后,獲取查詢對象和聚合對象的信息:
(1) 聚合類型屬于{AVG, MAX, MIN, SUM},聚合位置之后最接近的屬性標簽為查詢對象,聚合對象為null。
(2) 當聚合類型為COUNT,關鍵字元素中全部類別元素可能為查詢對象,分別對應不同的聚合信息結果,聚合對象則為null。
(3) 聚合類型屬于{>, <, EQU},查詢對象為聚合操作前的類別元素,聚合對象則描述為A-B的形式,其中A為對應的聚合屬性元素或類別信息,B則為聚合操作后的字面量。例如,查詢Q1對應的聚合信息為(EQU, AssistantProfessor, interest-fullprofessor1)。
(4) 當聚合類型為TOP1時,如果聚合位置前不存在類別信息,則查詢對象ST為聚合位置后的類別節點,AT則為聚合位置對應的屬性標簽;否則查詢對象為聚合位置之前的類別元素,聚合對象為聚合位置之后的類別或屬性標簽。
(5) 當聚合類型為TOPN_G時,查詢對象ST為聚合位置之前的類別元素,聚合對象AT則為聚合位置后類別-聚合位置后字面量。
3 查詢意圖確定與轉換
3.1 模式圖提取
原始數據圖中通常含有大量的實體和關系,在查詢意圖確定時需要搜索的空間很大。對于本文中將關鍵字轉換為SPARQL查詢語句的任務,在圖檢索階段只需確定所匹配的關鍵元素之間的結構關系,而無須遍歷完整的數據圖進行精確的匹配。所以我們在包含結構信息的模式圖上,實現對于查詢結構的確定,進而完成查詢轉換。
我們從數據圖中提取了包含類別實體和類別間關系的模式圖,同時本文在模式圖中考慮關系標簽也為特殊的圖節點,在關鍵字匹配到數據圖中的關系標簽時也能正確地得到對應搜索意圖的關鍵元素查詢結構。對于圖3中的RDF數據圖,對應的模式圖如圖5所示。
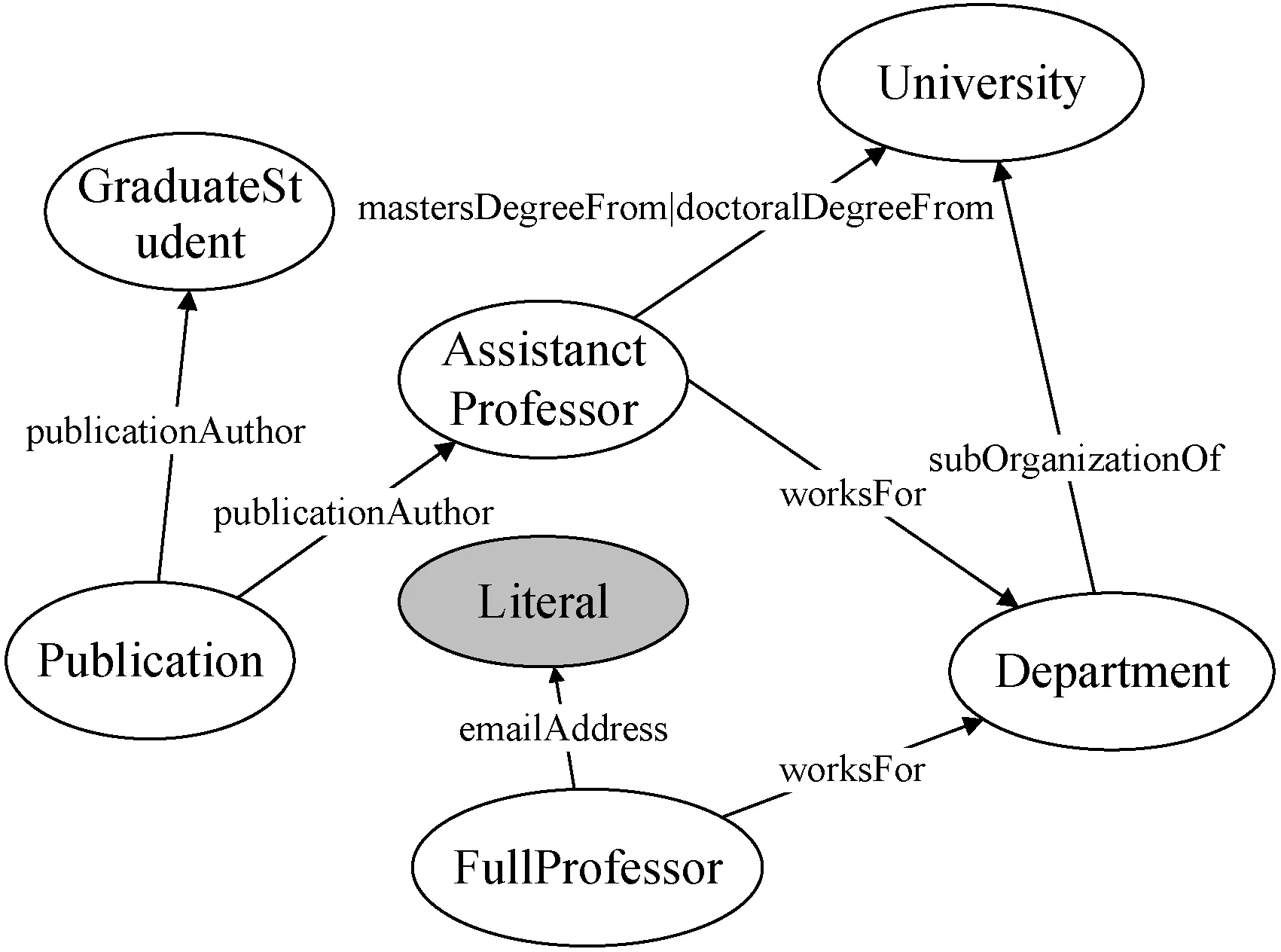
圖5 示例模式圖
3.2 查詢意圖計算
在2.3節獲取查詢解釋后,利用查詢解釋中的元素在模式圖上進行擴展,并慮聚合操作對圖連接的影響,得到候選查詢意圖。查詢意圖獲取如算法2所示。
算法2查詢意圖獲取算法
輸入:意圖組件集合Element={
輸出:查詢意圖集合I={
1.forE in Elementdo
2.ifE.A.operation in {>, <, EQU}then
3. prop=E.A.info.split(-)[0]; value=E.A.Info.split(-)[1]
4.ifvalue not numberthen
5. pos=getpos(prop)
6. C1=cl, c2, …, cpos; C2=prop, cpos, …, cn
7. G1=Expand(C1, max); G2=Expand(C2, max)
8. G.E=G 1.E ∪G2.E
9. G:edge=Gl.edge ∪ G2.edgel∪E.A.operation("Literall","Literal2")
10.else
11. G1=Expand(Evalue, max); G.E=G1.E.add(value)
12. G.edge=G1.Edge.add(A.operation("Literal", value))
13.endif
14.elseG=Expand(E.C,max)endif
15.forg in Gdo
16.fornode in g.Edo
17.ifnode.property!=nullandnode.element!=nullthen
//字面量
18. g.E.add(node.element)
19. g.edge.add(node.property(node.classes,node.element))
20.endifendfor
21. I.G=g; I.A=E.A
22. Result.add(I)
23.endforendfor
24. Result.GetTopk()
25.returnResult
當聚合類型屬于{>,<,EQU},聚合操作會影響查詢結構圖的連接性,將查詢分為兩個部分,分別進行擴展,并進行連接。其中,Expand函數用于進行摘要圖的擴展,根據給定的關鍵元素集合以及最大查詢距離max,獲取包含全部元素的子圖。在圖的擴展的過程中,采用反向搜索策略,由關鍵元素出發,按照模式圖中的結構進行擴展,直到到達連接元素,獲得對應查詢結構圖。
3.3 意圖排序方法
由于本文定義的查詢意圖中包含了聚合信息,所以在對于意圖分數進行計算時,需要同時考慮查詢圖和聚合信息兩個部分。對于查詢意圖I=(G,A),本文設計了新的度量策略來計算由關鍵字查詢獲得查詢意圖的對應分數,主要考慮以下三個指標:
(1) 關鍵字匹配度。查詢圖中元素與所對應關鍵字的匹配程度是衡量意圖是否準確的重要指標。同文獻[8]一樣,對于每一個關鍵元素,計算其與對應關鍵字之間的編輯距離;對于非關鍵元素則認為編輯距離為0,匹配度Sim(G)則為全部元素編輯距離之和的倒數。
(2) 查詢圖大小。與其他相關研究一樣,本文同樣認為用戶查詢的是與給定元素鄰近的信息,所以越緊湊的查詢結構圖,越可能符合用戶的查詢意圖。因此本文使用圖中節點數與邊數的總和來表示查詢結構圖的大小SizeG。
(3) 聚合信息的置信度。聚合信息的匹配程度同樣是度量查詢意圖理解準確性的重要指標。對于聚合信息A=(operation,ST,AT),當A為null時,其對應分數為0;當A屬于直接聚合和間接聚合兩類時,置信度的計算方法分別描述如式(3)、式(4)所示。
當A為直接聚合時:
(3)
當A為間接聚合時:
(4)
Path(AT→ST).length表示在查詢結構圖中AT與ST所對應元素之間路徑的長度。根據上述三個方面影響,得到對于查詢意圖構建代價的計算方法:
Score(I)=Score(G)+(1-α)Score(A)
(5)
式中:α為調和參數,一般取0.5;Score(G)為查詢結構圖的分數。
(6)
3.4 SPARQL查詢生成
獲得查詢意圖后,可以根據查詢結構圖轉換得到與其對應的查詢語句。對于每一個三元組
聚合信息同樣利用所包含的信息進行轉化,對于TOP1類型的聚合操作,在WHERE子句之后使用group by修飾ST對應變量,再加入order by desc/asc count(variable(AT))(只有TOP1_G類別需要使用count),最后使用limit 1實現返回結果中排序第一的對象;對于TOPN類型的操作,則使用group by修飾ST對應變量,再加入having(count(variable(AT)))對結果進行篩選;而對于MAX/MIN等直接聚合的查詢,則通過在SELECT子語句中添加operation(ST)限制,類約束待返回的結果,表達對應的查詢語義,例如SELECT MAX(?x),可以返回?x位置所對應的值最大的結果。
4 實 驗
為了驗證算法的正確性及有效性,本文使用Java語言和Jena框架來解析和處理RDF數據,并實現了上述算法(Power Keyword to SPARQL, PowerKTS)。
4.1 實驗環境及數據
實驗所用的環境為Windows 10操作系統,i5 CPU,8 GB內存。實驗數據為Lehigh大學的開放基準數據集LUBM和RDF形式的2005年DBLP數據,對于LUBM通過代碼生成了包含127萬條三元組的RDF數據,兩個數據集的具體信息表2所示。
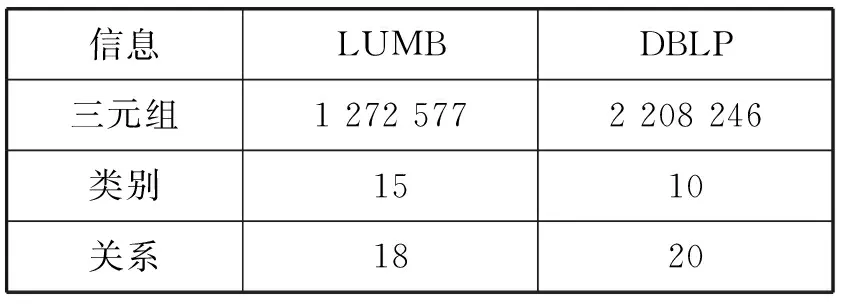
表2 實驗數據集信息
本文給定10組關鍵字查詢進行實驗,所用具體查詢及對應意圖如表3所示,L表示LUBM數據集上的查詢,而D則表示DBLP上的查詢,給定查詢關鍵字中包含一般查詢及聚合相關查詢。

表3 實驗關鍵字查詢數據
4.2 查詢準確性評估
對于查詢結果準確性的評價,我們采用信息檢索領域常用的評價指標MRR(Mean Reciprocal Rank)。
式中:n為正確答案在所返回結果中的排名。即當排序中第一位為正確結果時MRR值最高,此時值為1;而當結果中不包含正確意圖時,MRR值為0。
對于上述10組查詢,算法1中的閾值設置為1/3,則查詢結果對應的MRR值如圖6所示,由實驗結果可知PowerKTS可以正確實現對于查詢統計信息的關鍵字的處理,返回對應的查詢意圖,而KAT則只是將聚合關鍵字與圖元素進行匹配,無法正確解析查詢意圖。而對于一般查詢,PowerKTS也可以取得與KAT一樣的查詢準確度。
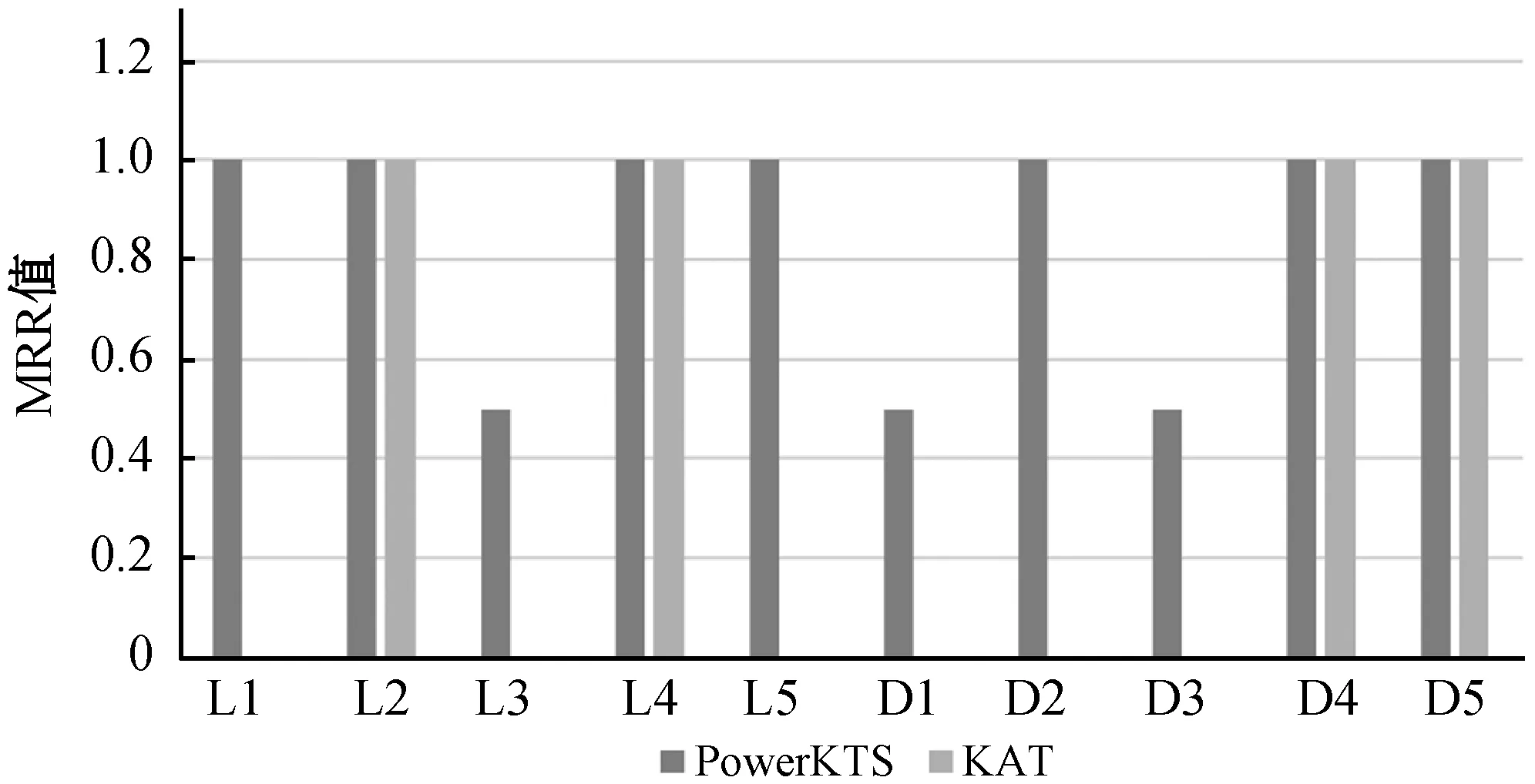
圖6 查詢準確性結果
4.3 索引空間分析
在倒排索引構建時,將每一個圖元素看成是一個文檔,分別考慮關鍵字出現在類別節點、字面量節點以及邊標簽中的情況,實現索引構建。對于不同的數據集,獲得關鍵字索引文件的大小以及構建時間如表4所示。
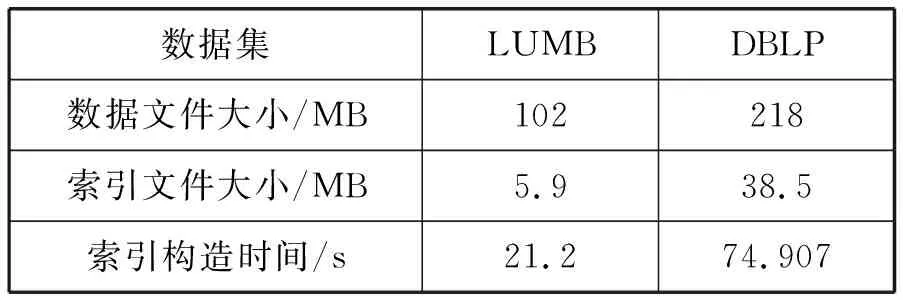
表4 關鍵字索引構建效率
4.4 查詢效率
為了驗證本文算法的查詢效率,對于給定的關鍵字查詢,實驗記錄從輸入查詢到返回SPARQL查詢語句所需要的時間,并與KAT算法進行比較。執行時間結果如圖7所示。
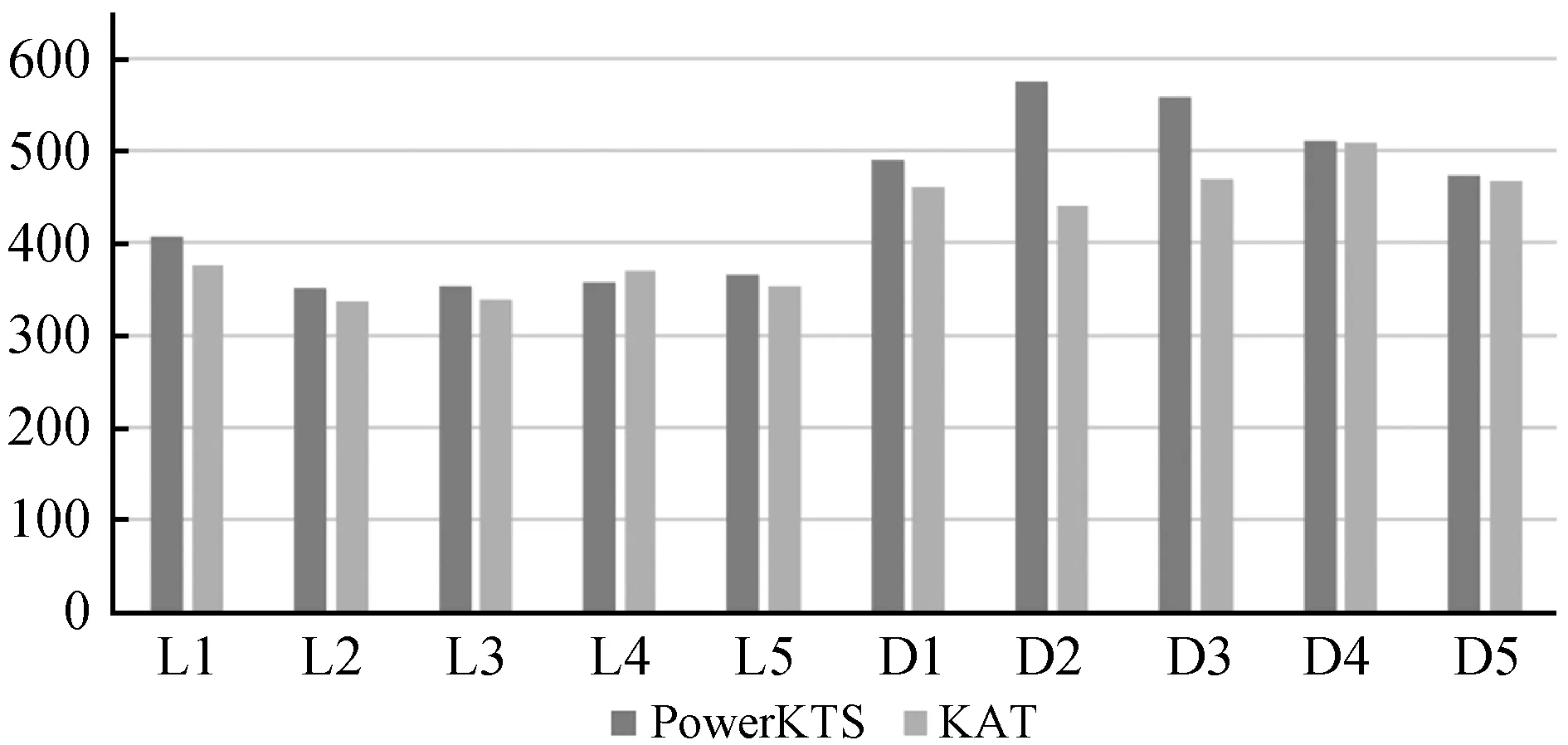
圖7 查詢轉換時間結果
由于在轉換過程中需要對給定關鍵字查詢是否為聚合查詢進行判斷,并獲取聚合信息,且模式圖的規模很少,兩種算法圖檢索所需時間都非常短,所以PowerKTS的執行時間平均略高于KAT,但是兩者差距非常小,驗證了算法的查詢效率。
5 結 語
本文針對RDF數據上的關鍵字檢索問題,在已有研究的基礎上,提出了一種將關鍵字轉換為SPARQL查詢的方法,并且支持聚合查詢的轉換。提出了包含聚合信息的查詢意圖,對聚合操作進行分類,通過構建聚合詞典以及關鍵字索引,實現對于查詢解釋的高效獲取,并且考慮候選聚合關鍵字可能對應圖元素的情況,對查詢解釋包含聚合意圖的概率進行計算。然后在模式圖上進行圖擴展,考慮聚合操作對于查詢結構圖連接性的影響,獲取候選查詢意圖。本文還根據查詢意圖的組成信息,提出了對應的評分策略,對候選意圖進行排序。最后,利用查詢轉換算法,將查詢結構轉換為結構化查詢。實驗驗證本文算法可以將關鍵字轉換為符合查詢意圖的查詢語句,支持對于統計信息的查詢,并且具有較高的轉換效率。
