
邊坡穩定性自動機器學習預測方法研究*
2023-02-24 05:17:02張化進吳順川張中信孫俊龍韓龍強
中國安全生產科學技術 2023年1期
張化進,吳順川,2,張中信,孫俊龍,韓龍強
(1.昆明理工大學國土資源工程學院,云南 昆明 650093;2.自然資源部高原山地地質災害預報預警與生態保護修復重點實驗室,云南 昆明 650093)
0 引言
邊坡災害作為全球3 大地質災害(地震、洪水、滑坡泥石流)之一,嚴重威脅人類生命財產安全。快速、準確、可靠的邊坡穩定性評價是邊坡工程設計與處治的先決條件,一直是邊坡工程關注的焦點問題。目前評價邊坡穩定性的主要方法有極限平衡法、數值分析法、穩定性圖表法以及監測預警法等[1],但各類方法均存在一定局限性。譬如極限平衡法難以確定臨界滑移面;數值分析法的可靠性極度依托于巖土體強度參數與本構模型的確定;圖表法的主觀性較強;監測預警法數據量龐大易導致分析結果缺乏時效性等。
隨著大數據中心、人工智能等新型基礎設施建設的提出與倡導,智能決策系統為解決多變量、非線性復雜問題提供方法,并獲得廣泛認可。人工智能方法如K-近鄰(KNN)、支持向量機(SVM)、人工神經網絡(ANN)、決策樹(DT)等已在邊坡穩定性研究領域廣泛應用,結合遺傳算法、粒子群算法等優化方法,形成一系列以數據為基礎、算法為主導的邊坡穩定性智能分析體系。張豪等[2]基于KNN模型,構建自適應人工免疫算法提高模型預測準確性;Rukhaiyar等[3]結合粒子群算法與ANN,構建出的優化模型較常規模型取得更好的預測效果;Hoang等[4]運用螢火蟲算法對最小二乘支持向量分類算法進行超參數優化,構建的機器學習(ML)模型較元模型精度提高4%。截至目前,大多數學者致力于改進某類ML算法提升模型性能,但不同ML算法適用于不同的問題與數據集。針對某一具體任務,要構建高質量的ML模型,必須進行模型選擇和超參數調優,這些工作耗費大量時間與精力,且其效果極度依托于豐富的數字科學經驗,而這是多數巖土工作人員不具備的技能,因此目前需要1 種更簡單有效的手段預測邊坡穩定性。
選擇不適合數據集的模型與超參數容易導致模型出現過擬合或欠擬合現象,但現有算法種類甚多,每種算法在泛化能力和復雜度等方面各有優缺點[5]。因此,如何選擇合適的模型及其超參數一直是算法工程師迫切希望解決的關鍵科學與技術問題。為解決這一難題,自動機器學習[6](automatic machine learning,AutoML)方法應運而生,AutoML通過一些技術和方法使盡可能多的工作(如模型選擇與超參數優化等)被自動化完成,不需要人工干預和過多的ML領域專業技能與知識,也能構建出比傳統機器學習更優越的預測模型,有效提高ML的通用性和高效性。AutoML已成為人工智能領域最熱門的研究課題之一,在醫療保健與目標檢測等領域已做出一定貢獻,但在邊坡穩定性評價等巖土工程行業鮮有報道[7]。
截至目前,AutoML中仍沒有1 種框架始終優于其它自動化框架,要么適用于某些結構,要么適用于某類任務或數據[8]。因此,針對邊坡穩定性AutoML預測問題,亟需分析與評價各種AutoML框架在穩定性預測任務上的有效性及適用性。本文在探討AutoML現狀和特性的基礎上,以收集的422 組邊坡穩定性狀態數據為例,采用5 種主流AutoML框架和6 種傳統ML方法構建邊坡穩定性預測模型,通過對比分析各模型的預測性能與速度等性質,檢驗基于AutoML的邊坡穩定性預測模型的泛化能力和可行性,以期為邊坡穩定性預測提供1種更為便捷有效的預測方法。
1 AutoML框架
AutoML[9]不像傳統ML在數據集中擬合1 個模型那樣簡單,其利用數據集自身性質自動化實現特征工程、算法選擇、超參數優化、模型評估及迭代建模等步驟,從而實現所有步驟的端到端過程。本文選擇對MLBox、TPOT、H2O、Auto_ml及AutoKeras 5 種主流的開源AutoML框架進行分析,選擇上述框架的原因包括以下2點:一是可提供Python API,可在Windows系統下免費使用;二是不需要先驗數字科學知識和指定模型及超參數搜索空間,輸入數據集可自動完成模型訓練。AutoML里包含許多高級算法,不需要深入探索或編譯,可自動搜索性能最好的預測模型及其超參數。一般工作流程為:根據訓練數據特征,系統自動配置模型結構與超參數,并評估預測性能不斷迭代優化,以選出預測效果最好的模型[8]。通用AutoML框架流程如圖1所示。
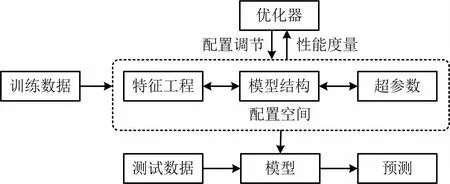
圖1 AutoML框架流程Fig.1 AutoML framework flow
1.1 MLBox
MLBox是1 個基于Python 的分布式自動機器學習框架,主要包括數據預處理、模型優化與預測3 個子包[10]。MLBox框架運行速度快,代碼量小,穩定性高,但仍處于開發階段,隨時可能發展變動,只能進行基本的特征工程,漂移識別存在移除有用變量的風險[11]。
1.2 TPOT
TPOT全稱為樹形傳遞優化技術,是Olson 等[12]開發的基于樹的管道優化工具,其采用遺傳算法構建特征預處理和建模管道比網格搜索方法更具優勢,可最大程度提高ML模型的最終預測性能。TPOP是基于基因編程的框架,因此需要耗費較長計算時間分析數據集[13]。
1.3 H2O
H2O是1 個分布式、快速和線性可擴展的機器學習平臺[14]。除實現傳統機器學習的算法外,H2O可實現分布式隨機森林、梯度提升與深度學習模型,并結合網格搜索與集成算法將性能最好的模型進行聚合。H2O的核心代碼是基于Java開發的,使整個機器學習框架能夠實現多線程。
1.4 Auto_ml
Auto_ml設計用于產業輸出,包括自動化特征響應、數據分析、數據清理、獨熱編碼、深度學習、分類集成等功能[15],并基于樹模型從非線性模型中得到線性模型解釋,Auto_ml可以處理稀疏數據,適合AutoML初學者進行研究與探索,易于分析和獲取生產中的實時預測。
1.5 AutoKeras
AutoKeras是由DATALab 開發的用于創建具有有限數字科學或機器學習背景知識學者可輕易訪問的神經結構搜索系統(NAS)[7]。與上述側重于淺層模型的AutoML框架不同,AutoKeras側重于深度學習任務,對神經網絡支持較好,擅長解決圖像與文本分類問題[8],因此對特征工程要求較低。
2 數據與實驗
為研究AutoML在邊坡穩定性預測領域的可行性與適用性,本文使用上述5 種AutoML框架進行純自動化訓練,在安裝AutoML程序庫后,輸入訓練數據,采用默認配置參數,系統自動實現數據預處理、模型選擇與超參數優化等過程,直至訓練出最優預測模型。結合模型性能度量指標,與6 種傳統ML進行比較,評估AutoML的預測性能,以下實驗過程均在Win10 CPU 3.2GHz系統的Python 3.7 軟件中運行。
2.1 數據集
影響邊坡穩定性的因素眾多,一般只選擇具有代表性的因素評價邊坡穩定性。參考文獻[16]的預測指標選擇方案與結果,選取反映巖體強度、幾何因素和地下水狀況的巖土體重度γ、黏聚力c、內摩擦角φ、坡角α、坡高H及孔隙壓力比γw6 個代表性特征對邊坡穩定性進行評價。數據集的規模與質量直接影響構建模型的可靠性,通過文獻查詢與數據匯編[17],收集422 組邊坡穩定性樣本,其中處于穩定狀態的有226 組樣本,處于破壞狀態的有196 組。受篇幅限制,本文僅列出其中10組樣本,如表1所示。
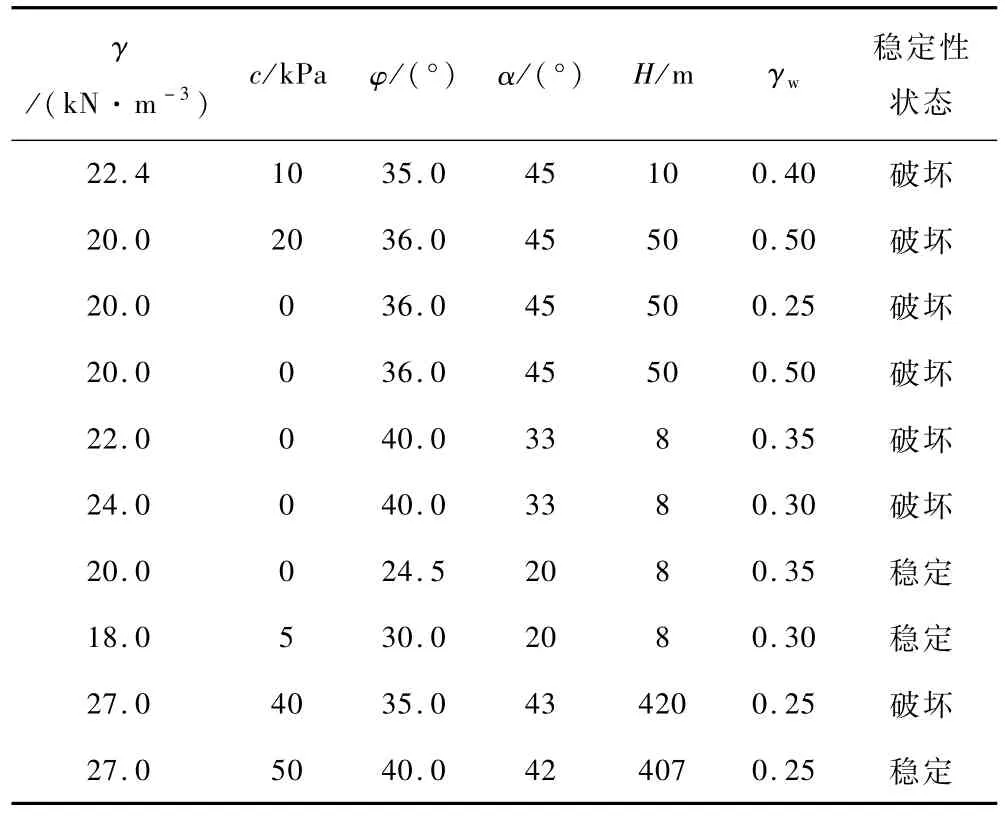
表1 邊坡穩定性預測數據集(部分)Table 1 Prediction data sets of slope stability (part)
考慮到數據集采集受地質條件和穩定性狀態評價指標差異的影響,在劃分數據集之前,先將樣本順序打亂,再按照4 :1 將數據集劃分為訓練數據與測試數據。
2.2 性能度量指標
將測試結果根據實際情況和預測結果的組合分為真穩定(TS)、假破壞(FF)、假穩定(FS)和真破壞(TF)4 種,總測試樣本數N=TS +FF+FS +TF,分類結果的混淆矩陣如表2所示。為評價各種邊坡穩定性預測模型的性能差異,采用準確率Acc、F1分數和受試者工作特征(ROC)曲線下的面積AUC作為客觀評價模型綜合性能的量化指標,3 個指標的取值范圍均為[0,1],值越大表示模型性能越優越。其中Acc與F1的計算分別如式(1)和式(2)所示:
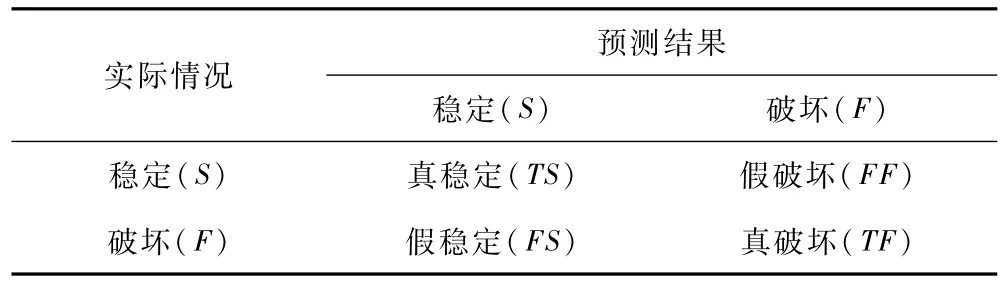
表2 分類結果的混淆矩陣Table 2 Confusion matrix of classification results
ROC曲線根據預測結果對樣本進行排序,隨后逐個將樣本當作穩定狀態進行預測,以假穩定率FSR(FSR=FS/(FS +TF))為橫坐標、真穩定率TSR(TSR=TS/(TS+FF))為縱坐標作圖,得到ROC曲線如圖2所示,陰影表示ROC曲線下面積AUC,虛線表示45°對角線。曲線越靠攏(0,1)點,越偏離45°對角線,模型預測效果越好。
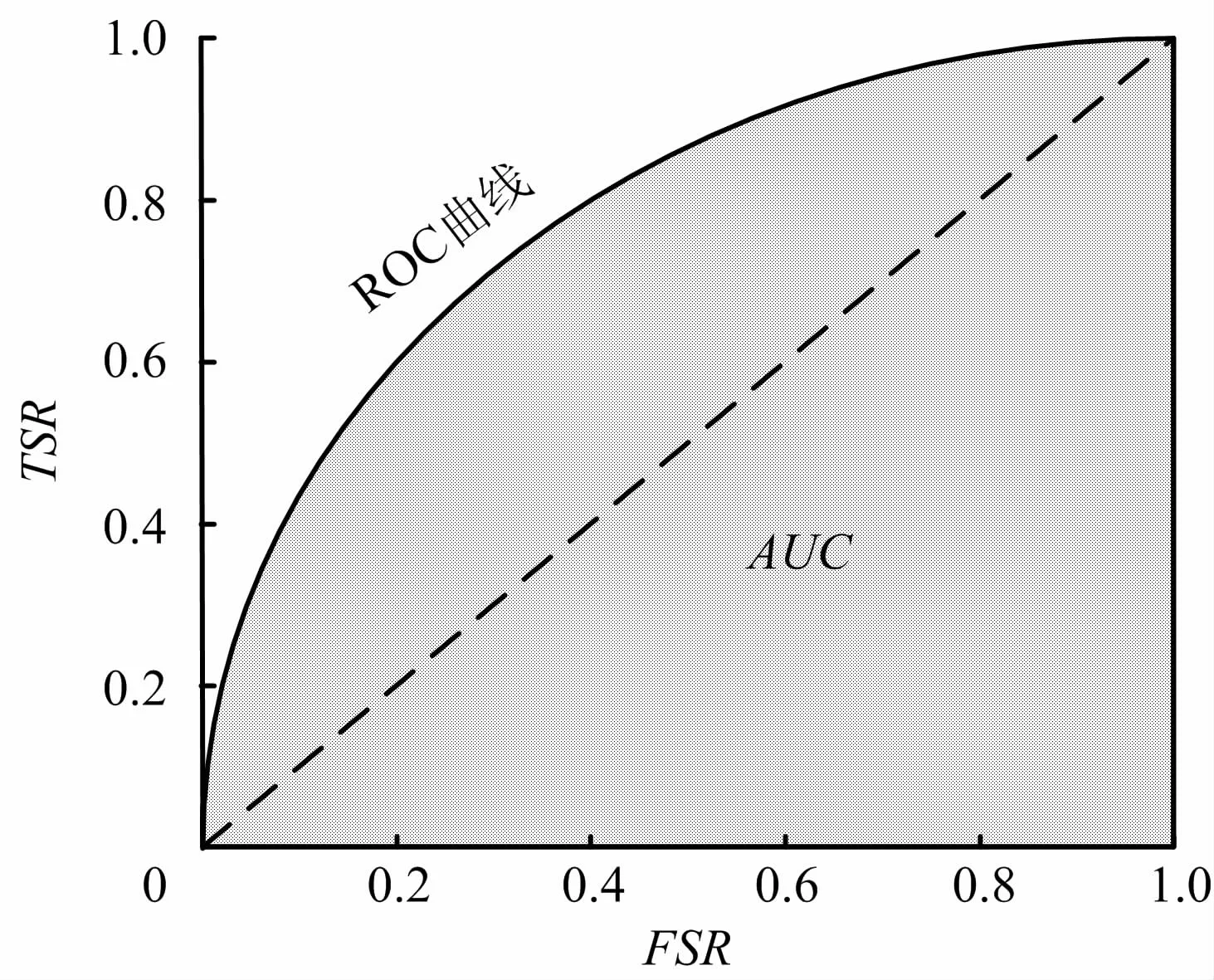
圖2 ROC曲線與AUC示意Fig.2 Schematic diagram of ROC curve and AUC
2.3 傳統機器學習模型
對比的6 種傳統ML為邏輯斯蒂回歸(LR)、樸素貝葉斯(NB)、KNN、DT、SVM 和ANN模型。不同于AutoML,傳統ML目前只支持模型訓練,因此為提升傳統ML模型的預測性能,適當的數據預處理和模型超參數優化必不可少。
2.3.1 數據預處理
1)缺失值處理
由于數據集中孔隙壓力比存在缺失值,因此需對缺失值進行處理。孔隙壓力比屬性的眾數與中位數均為0.25,故以0.25 對缺失值進行填充,使數據完整。
2)標準化處理
由于數據集的數值屬性具有較大的比例差異,如坡高與孔隙壓力比屬性不在同一數量級。因此,在模型訓練之前對數據進行標準化處理,轉化成無量綱的純數值,即計算出數據屬性的均值μ與標準差σ(σ≠0),按照式(3)將屬性轉換成μ為0、σ為1 的標準正態分布N(0,1)形式,統一屬性量綱。
式中:X為轉換后的數值;x為原始值。
2.3.2 超參數優化
6 種傳統ML模型中,每種算法都包含1 個或多個重要的超參數,直接影響模型預測性能。本文采用網格搜索算法[17]進行超參數調優,嵌套5 折交叉驗證法[18]評估模型性能,選出預測性能最佳的1 組超參數組合。5 折交叉驗證法流程如圖3所示,將訓練數據均分為5個子集(D1~D5),依次留出1 個子集作為驗證集,用來性能評估,剩余4 個子集的并集作為訓練集訓練模型,計算5 個訓練模型在驗證集上的平均準確率。將作為模型優化指標,搜索具有最高平均準確率的超參數組合,結果如表3所示。
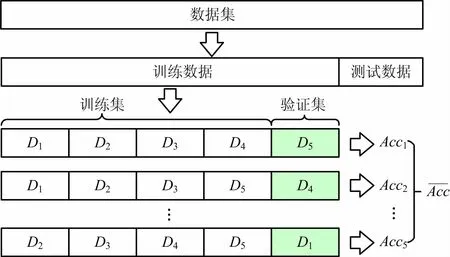
圖3 5 折交叉驗證法Fig.3 5 fold cross-validation method
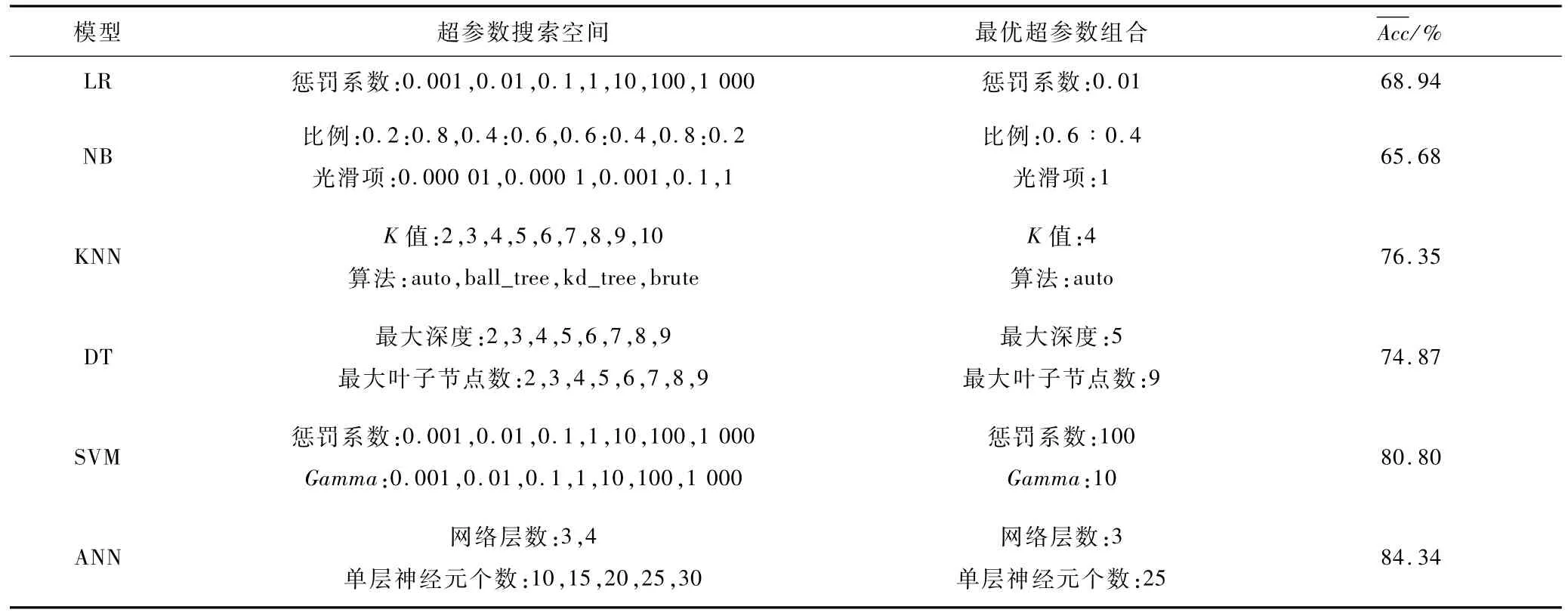
表3 網格搜索超參數優化Table 3 Hyper parameters optimization of grid search
2.4 實驗結果
在獲得各種ML模型的最優預測結果后,為評估模型的預測性能和泛化能力,計算各模型在邊坡穩定性狀態測試數據上的性能度量指標與運行耗時T,如表4所示。各模型ROC曲線與AUC如圖4所示。
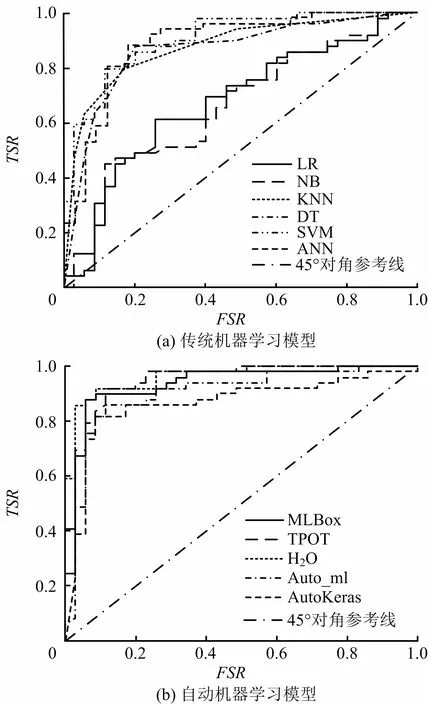
圖4 各模型的ROC曲線與AUCFig.4 ROC curve and AUC of each model
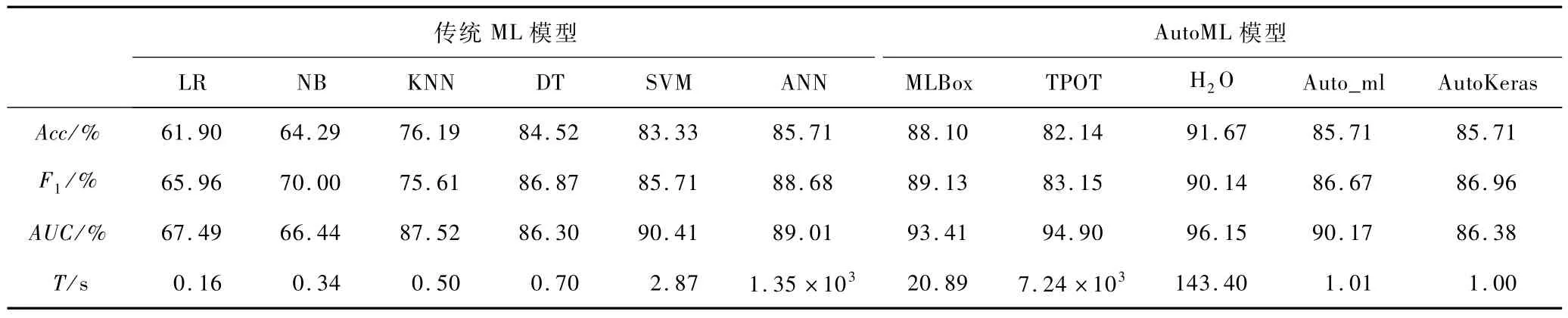
表4 各模型的性能指標與耗時Table 4 Performance indexes and time consumption of each model
在測試數據上,傳統ML模型中的ANN模型預測性能較好(Acc=85.71%,F1分數 =88.68%,AUC=89.01%);DT與SVM 模型性能次之;LR和NB模型表現較差,性能度量指標均未超過70%。AutoML模型預測性能總體上優于傳統ML模型,H2O、MLBox框架在邊坡穩定性預測中表現較好,尤其是H2O模型的準確率、F1分數和AUC 3 項指標均大于90%,預測性能顯著優于傳統ML模型,TPOT和AutoKeras訓練的模型性能相對較差,但也能獲得與ANN模型相匹配的效果。上述結果表明AutoML能夠有效地應用于邊坡穩定性預測任務,提高預測準確率與魯棒性。
相對傳統機器學習,由于AutoML框架需要訓練大量模型,因此運行時間相對更長。本文邊坡穩定性預測任務中,除TPOT模型運行約2 h 外,其余AutoML模型收斂較快,均未超過3 min,運行耗時較短。另外,由于AutoML框架能夠實現全過程自動化數據預處理、模型選擇、超參數優化等一系列工作,僅需導入相應程序庫及訓練數據即可輕易運行程序,基本不需要數字科學經驗和人為干預,便可獲得高性能的預測模型,充分驗證AutoML更易于被巖土工程領域的技術人員掌握,極大程度上減輕巖土工程師的工作量,具有廣泛適用性。
3 討論
盡管大多數AutoML在許多數據集上能夠取得較理想的預測結果,但針對不同的任務類型,目前仍沒有1個AutoML框架可以明顯超越其它框架[8]。因此根據目前AutoML的研究成果,從特征工程、算法支持、超參數優化、特性和運行速度等方面對上述5 種AutoML框架進行綜合比較,結果如表5所示,可為解決類似巖土工程問題提供一定參考。

表5 不同AutoML框架的綜合對比Table 5 Comprehensive comparison of differ ent AutoML frameworks
結合表4~5 可知,針對邊坡穩定性狀態等二分類問題,AutoML是1 種很好的選擇,具有較好的魯棒性和廣泛的適用性。對于預測時間要求不高的領域,推薦使用H2O框架,該框架訓練模型的預測性能優于其它方法,并提供Web GUI交互式界面,對用戶十分友好。如果對預測時間要求較高,則優選MLBox或Auto_ml框架,這2 種方法可快速收斂并獲得較準確的結果。AutoKeras不支持特征工程,適用于圖像處理與文本分類等深度學習任務。TPOT相較其它框架運行時間花費更多,盡管提供模板選項功能可加快收斂速度,但需要具有一定知識儲備的人為干預,不太適用于快速初步的邊坡穩定性評價。目前,AutoML正處于早期研發階段,相信隨著工具的發展與完善,在不久的將來預測質量與速度等方面將取得更好的成績。
4 結論
1)AutoML方法可避免模型選擇與超參數優化等挑戰性問題,不需要先驗數字科學知識,能直接基于邊坡穩定性數據集快速自動構建預測模型,為準確、可靠的邊坡穩定性狀態評價提供1 種簡便方法,適合巖土工程領域工作人員研究與應用。
2)基于422 組邊坡穩定性數據集訓練結果發現,AutoML模型預測性能總體上優于傳統ML模型,能夠顯著提高預測準確率和穩健性,證實AutoML在邊坡穩定性預測任務上的適用性和可靠性,對正確評價邊坡穩定性具有重要意義。
3)通過綜合比較與分析典型AutoML框架的預測性能、速度等方面性質,結果表明H2O和MLBox框架可以快速收斂并獲得泛化能力較強的預測模型,更適合于解決邊坡穩定性預測等類似的非線性二分類問題。
4)本文僅針對二分類(穩定與破壞)任務,而不同類型(建筑、土木、露天礦等邊坡)、不同安全等級的邊坡穩定性評判標準不同。因此,下一步應開展AutoML回歸分析研究,精確確定邊坡安全系數,對穩定性狀態進行更精細地量化表達。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
