基于DBSCAN聚類的熱能發電大數據異常檢測模型
2023-03-04 03:50:50薛貴元
工業加熱 2023年1期
郭 莉,吳 晨,薛貴元
(國網江蘇省電力有限公司經濟技術研究院,江蘇 南京 210000)
熱能種類繁多、數量龐大,其中包括太陽能、工業余熱等類別,充分利用熱能可以提高能源的利用率,減少石油、煤炭等不可再生資源的消耗。以低溫熱能有機物循環發電系統為例,其為在節約能源的同時,也造成了發電大數據的迅速增長,隨之出現了數據龐大且信息貧乏的情況[1-2]。低溫熱能有機物循環發電系統在受到自身或外界某些因素影響時會導致數據異常,為了保證熱能發電系統的穩定運行,相關的數據異常檢測方法變得至關重要。
孫文慧[3]等以供熱末端住戶供暖數據為研究對象,利用高斯混合聚類算法將數據集映射到高維空間并完成聚類后,搭建工業大數據分析平臺實現異常用熱數據集的解釋與辨識。周嘉琪[4]等為了精準快速地定位光伏發電系統中光伏逆變器的異常,提出了一種基于GAN的異常檢測方法。采用卷積長短期記憶網絡的編碼器,提取每個時間序列數據的時間信息以及各變量之間的相關信息后,求解異常評分函數實現光伏逆變器數據異常檢測。肖勇[5]為了解決智能電表遭受的網絡攻擊的問題,提出了基于深度信念網絡與數據聚合模型的智能電表數據異常檢測方法。將分布式數據模型聚合后的數據輸入至深度信念網絡中,將執行數據經過深度信念網絡提取特征傳送至電表數據計量管理系統,實現智能電表損失檢測。上述方法雖然都實現了異常檢測,但是由于熱能發電大數據種類較多,數量龐大,導致其存在誤報率高、檢測率低和漏報率高的問題。
為了解決上述方法存在的問題,基于密度的噪聲應用空間聚類(density-based spatial clustering of applications with noise,簡稱DBSCAN)方法可以將簇定義為密度相連的點的最大集合,能夠把具有足夠密度的區域劃分為簇,并可以在有噪聲的空間數據集中發現任意形狀的簇,提高數據檢測的準確性,因此將該方法引入熱能發電大數據異常檢測模型設計中,以此提升熱能發電大數據異常檢查命中率,對異常事件精準鎖定,從而提高解決問題的效率并降低經濟損失。
1 數據預處理
低溫熱能有機物循環發電系統主要由膨脹機蒸發器、冷凝器、工質泵和發電機構成,該系統的各個部件均會產生壓力、質量流量、溫度等不同類型且數量眾多的數據,一旦其受到大量的無關數據和噪聲數據影響,將會導致數據異常或丟失,因此在異常檢測前需要對數據進行預處理[6]。
1.1 數據異常值修正
設延遲算子為B,光滑算子為α(B),可逆算子為β(B),α(B)和β(B)的對應參數為α1,α2,…,αq和β1,β2,…,βq,?表示1-B,at為滿足正態分布的噪聲序列點,用ARIMA模型對未檢測到的熱能發電大數據異常的時間序列為{Xt}:
(1)
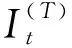
(2)
通過ARIMA模型表示時刻T的時間序列,該序列存在已被檢測到的缺失值和噪聲點[7],具體分為以下兩種情況:
1)持續異常模型
設{Yt}表示在時間t處存在持續異常值的時間序列,此序列可表示以下形式:
(3)
2)獨立異常模型
設{Zt}表示在時間T處存在持續異常值的時間序列,該模型被獨立異常值影響,如下所示:
(4)
由式(2)和式(3)可以看出,Yt和時間t后的時間序列Yt+1,Yt+2…均會受到異常值的影響,由式(4)可以看出,獨立異常值只對時間T處的序列值產生影響。
設模型擬合誤差為et,t+j項的擬合誤差為et+j,殘差影響算子為πj,得到持續異常值和獨立異常值對時間序列的影響ωφ和ωφ如下所示:
(5)

(6)
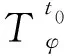
通過以上計算可以修正時間序列中數據被異常值所影響的部分。
1.2 數據歸一化
工質泵是低溫熱能有機物循環發電系統的動力部分,其中包含了循環效率、工質吸熱量、凈輸出功率三個指標,上述三個指標的單位和量綱特征量不一致,會對熱能發電大數據分析的結果和數據指標的可比性產生影響,因此在修正時間序列中數據異常部分后,還需要對數據進行歸一化處理,從而使數據不受到量綱的影響。將熱能發電大數據歸一化處理后,數據的各項指標數量級統一,能夠對其進行更加準確的對比研究。基于DBSCAN聚類的熱能發電大數據異常檢測模型中,數據歸一化處理采用的是離差標準化算法[8]。
設原始數據為x,發電數據集中最大值為xmax,最小值為xmin,將x進行線性轉換,其結果x*映射到[0,1]中,歸一化計算方式如下:
x*=x-xmin/xmax-xmin
(7)
2 構建熱能發電大數據異常檢測模型
2.1 流式DBSCAN
在收集熱能發電大數據用于研究時,發電數據是以數據流的形式存在的[9],對頻率動態聚類進行計算時需要實時更新,從而檢測異常數據。基于DBSCAN聚類的熱能發電大數據異常檢測模型通過Streaming DBSCAN實現該檢測步驟。設x為一個新出現的數據點,對其建立新的密度聯系,有如下四種可能的狀態:
1)x為異常值
若新數據點x的鄰域內不存在核心點,則x為異常值。
2)創建新的聚類
若新數據點x本身為核心點,x不存在于其他現有聚類中,且在x密度可到達的點中沒有出現聚類核心點,則生成新聚類。
3)加入現有聚類
若新數據點x與任意一個聚類的核心點呈現密度可達的狀態,則將x加入該聚類。
4)合并多個聚類
若插入新數據點x后呈現不同聚類核心點密度可達的狀態,則將x與相鄰聚類合并生成新聚類。
由于歷史數據會對新數據產生影響,因此引入延遲因子α判斷其影響,當α的值為1時,歷史數據和新數據影響相同,當α的值為0時,歷史數據的影響可以忽略不計。設用xt表示新到達的數據,ct表示上一時刻或歷史時刻聚類情況,ct+1表示新的聚類,nt+1表示新聚類中數據點個數,nt+1=nt+m,其中nt為歷史數據數量,mt為新到達數據數量,對新聚類進行計算得到:
ct+1=ctntα+xtmt/ntα+mt
(8)
2.2 Spark Streaming
處理大量的數據流對系統的性能有很高的要求,為此基于DBSCAN聚類的熱能發電大數據異常檢測模型采用Spark Streaming進行流處理,Spark Streaming可以接入多種數據源,是Spark對于數據流處理的一種延伸[10],Spark的優點是在數據挖掘和機器學習需要多次迭代的情況下依然適用,Spark最基本的數據結構是RDD[11],其作用是通過本地集合完成分布式數據集的操作,Spark中對數據流的抽象為DSsteams,DSsteams用來描述連續序列RDDs,其中全部RDD都存在特定時間間隔的一段數據。
2.3 Streaming DBSCAN算法
通過Spark Streaming設計熱能發電大數據Strea-ming DBSCAN算法,該算法對數據流計算分為以下步驟:
1)歷史數據選取利用
選擇具有代表性的歷史數據建立訓練數據集[12],用以獲取不同類型的熱能發電數據特征,將數據通過DBSCAN算法聚類處理并進行數據點標注,設標注后的數據點為p,數據點的屬性、所在聚類和類型分別為xi、y和z,得到
p=(y,[x1,x2,…],z)
(9)
在低溫熱能有機物循環發電系統運行過程中,選取的歷史數據會更新為涵蓋多時間間隔的真實數據,對于Spark Streaming,這些數據會成為廣播變量并下發到全部節點。
2)單位時間內的數據向量計算
依據系統實時性需求計算單位時間內的有效電壓、電流和發電量,將其作為熱能發電數據的特征量。結合其他相關信息,得到數據點向量。
利用電流值描述發電特征[13],設有效電流值為Ie,采樣周期和采樣時刻分別為T和i(T),得到
(10)
通過Spark Streaming對時間間隔內采集到的數據點進行計算并輸出向量,計算分為兩個部分,分別為Map和Reduce[14],其中Map部分用來解析數據,獲取需求數據;Reduce用來進行數據規約,對數據進行合并分類,輸出向量。
3)Streaming DBSCAN
實時檢測輸出的發電數據向量聚類特征,以便識別其中存在的異常數據,將其用于低溫熱能有機物循環發電系統的問題判斷。發電數據的聚類特征表現在橫向與縱向上[15],橫向為相似發電廠,縱向為歷史數據。聚類特征分為個體與群體特征,個體聚類特征為某發電廠一天的發電信息和歷史發電信息之間會呈現相似特性[16];群體聚類特征為對于相似的發電廠,發電特征會呈現相似性。在樣本集中數據數量滿足條件時[17],若某一發電廠發電信息與其歷史信息或與相似發電廠的信息不相符,則該發電信息可能有問題出現,需要對其重點觀察。對異常數據的判斷主要通過橫向與縱向上是否表現出聚類特征,若表現出聚類特征,則正常,反之,異常。
4)獲取異常數據
采用根據歷史數據獲取的延遲因子將最近的時間間隔內的數據建立為訓練集,重復以上步驟,完成異常數據的檢測。
3 實驗與結果
為了驗證基于DBSCAN聚類的熱能發電大數據異常檢測模型的有效性,需要對其檢測能力進行測試。
3.1 對比測試
分別以誤報率、檢測率和漏報率為指標對所提方法、文獻[3]方法和文獻[4]方法進行如下測試,每項指標進行5次不同實驗,實驗結果如下:
1)誤報率測試
對所提方法、文獻[3]方法和文獻[4]方法進行誤報率測試,測試結果如圖1所示。
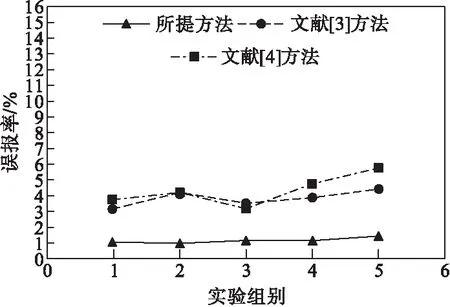
圖1 誤報率檢測結果
由圖1可以看出,采用所提方法、文獻[3]方法和文獻[4]方法建立的模型對發電大數據異常值進行檢測時,所提方法的整體誤報率均低于文獻[3]方法和文獻[4]方法,在第5組實驗中,所提方法、文獻[3]方法和文獻[4]方法的誤差率均有升高,但所提方法依舊低于文獻[3]方法和文獻[4]方法,因為所提方法在對異常值檢測前通過時間序列模型對原始發電大數據進行了數據序列異常值的分析與修復,使數據更為精確,更具有代表性。從而降低了所提方法的誤報率。
2)檢測率測試
對所提方法、文獻[3]方法和文獻[4]方法進行檢測率測試,測試結果如圖2所示。

圖2 檢測率檢測結果
由圖2可以看出,所提方法在5次實驗中的檢測率均高于文獻[3]方法和文獻[4]方法,說明所提方法對熱能發電大數據檢測的覆蓋面更廣,對數據的利用性更高,更有助于獲取到準確的發電異常值。
3)漏報率測試
對所提方法、文獻[3]方法和文獻[4]方法進行漏報率測試,測試結果如圖3所示。
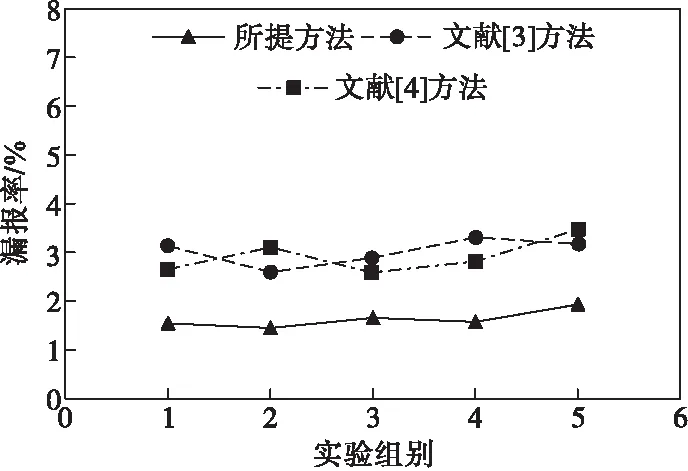
圖3 漏報率檢測結果
由圖3可以看出,所提方法的漏報率較為穩定且始終低于文獻[3]方法和文獻[4]方法,說明所提方法在熱能發電大數據檢測中的有效性更強。
3.2 異常值測試
利用所提方法對熱能發電大數據異常值進行檢測,檢測結果如圖4所示。
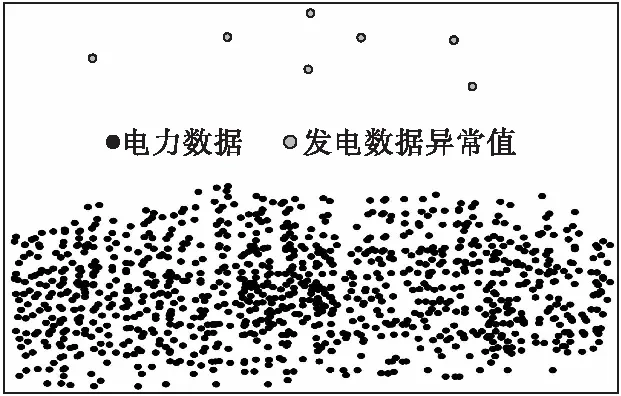
圖4 異常值檢測結果
由圖4可以看出,采用所提方法共獲取到7個發電異常值,與發電廠發電的實際情況相吻合,說明所提方法對發電大數據異常情況的檢測具有較高的可靠性。
4 結 語
低溫熱能有機物循環發電系統的不斷優化促使電力數據量的不斷增加,對熱能發電大數據進行挖掘研究并建立異常檢測模型變得至關重要。為了解決熱能發電大數據異常檢測存在誤報率高、檢測率低和漏報率高的問題,提出了基于DBSCAN聚類的熱能發電大數據異常檢測模型,將預處理后的原始發電大數據通過Streaming DBSCAN算法完成異常值的獲取,解決了誤報率和漏報率高的問題,提高了異常數據檢測率,對保障低溫熱能有機物循環發電系統穩定運行具有重要的意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
