
基于YOLOv5的遙感圖像小目標(biāo)檢測
2023-03-11 06:29:42李文博趙正旭
科技創(chuàng)新與應(yīng)用 2023年6期
李文博,趙正旭
(青島理工大學(xué) 機械與汽車工程學(xué)院,山東 青島 266520)
計算機視覺(Computer Vision,CV)中,目標(biāo)檢測(Object Detection)技術(shù)的研究一直都是該領(lǐng)域熱點研究方向。目標(biāo)檢測技術(shù)是指從復(fù)雜的背景中,基于目標(biāo)幾何和統(tǒng)計特征進行表達與分類,實現(xiàn)對檢測目標(biāo)的識別和位置確認,為后續(xù)的分析處理提供信息。其中,小目標(biāo)檢測精度和速度是該領(lǐng)域的熱門研究方向[1]。
遙感圖像的目標(biāo)檢測技術(shù)目前在農(nóng)業(yè)、醫(yī)學(xué)和軍事等領(lǐng)域都有研究應(yīng)用。隨著深度學(xué)習(xí)技術(shù)的不斷發(fā)展,相較手工提取特征的傳統(tǒng)算法,因深度神經(jīng)網(wǎng)絡(luò)識別準確率高、速度快和特征自提取等優(yōu)勢被廣泛應(yīng)用到目標(biāo)檢測領(lǐng)域中來[2]。近些年,許多基于卷積神經(jīng)網(wǎng)絡(luò)的速度快、精度高的目標(biāo)檢測算法被提出,卷積神經(jīng)網(wǎng)絡(luò)可以對圖像數(shù)據(jù)自主訓(xùn)練學(xué)習(xí),更新參數(shù),得到一個比較準確的模型[3],并在很多開源檢測數(shù)據(jù)集的檢測結(jié)果和性能表現(xiàn)都很出色[4-9]。目前流行的深度學(xué)習(xí)目標(biāo)檢測算法主要為two-stage和one-stage。Two-stage是先生成候選區(qū)域,再通過卷積神經(jīng)網(wǎng)絡(luò)對預(yù)測目標(biāo)進行分類和定位,如Mask R-CNN[4]、FasterR-CNN[10]等。One-stage是直接利用卷積神經(jīng)網(wǎng)絡(luò)提取目標(biāo)特征值,預(yù)測目標(biāo)的分類與定位,較為代表性的為YOLO算法。第一類目標(biāo)檢測方法其優(yōu)點是目標(biāo)定位和檢出率精度高,但是訓(xùn)練時間長、速度慢,達不到實時性要求。第二類目標(biāo)檢測方法其優(yōu)點是速度快,能夠?qū)崟r對目標(biāo)對象進行識別定位,但精度不高,特別是對小目標(biāo)識別不準確。綜合考慮,本文選用YOLO算法中最流行的YOLOv5作為基礎(chǔ),對DOTA數(shù)據(jù)集中的遙感圖像中的艦船、車輛進行檢測,采用GIOU_loss作為損失函數(shù),能夠準確檢測出艦船、車輛等遙感圖像中的小目標(biāo)。
1 YOLOv5算法介紹
YOLO算法作為目標(biāo)檢測領(lǐng)域的一個經(jīng)典算法,其中YOLOv1奠定了整個YOLO系列的基礎(chǔ),后面的YOLO算法是對其的不斷改進創(chuàng)新。YOLOv1發(fā)布于2015年,是one-stage detection的開山之作,在此之前的目標(biāo)檢測都是采用two-stage的方法,雖然準確率較高,但是運行速度慢。由于YOLOv1存在定位不準確及與two-stage方法相比召回率低的缺點,作者于2017年提出了YOLOv2算法,從更準確、更快和更多識別3個角度對YOLOv1算法進行了改進,擴展到能夠檢測9 000種不同對象的檢測識別,被稱為YOLO9000。YOLOv3于2018年提出,總結(jié)了在YOLOv2的基礎(chǔ)上做的一些嘗試性改進。其中有2個值得一提的亮點,一個是使用了殘差模型,另一個是使用了FPN架構(gòu)實現(xiàn)多尺度檢測[5,9]。YOLOv3在之前的基礎(chǔ)上引入了殘差塊,并進一步加深了網(wǎng)絡(luò),改進之后的網(wǎng)絡(luò)有53個卷積層,取名為Darknet-53。
YOLOv4是在YOLOv3的主干網(wǎng)絡(luò)(Darknet-53)的基礎(chǔ)上增加了Backbone結(jié)構(gòu),其中包含了5個CSP模塊,可以有效增強網(wǎng)絡(luò)的學(xué)習(xí)能力,降低成本。同時增加了Droblock模塊,緩解過擬合現(xiàn)象。此外YOLOv4使用Mish激活函數(shù),由于其函數(shù)曲線相對更平滑,相對Relu激活函數(shù)能更好地保證準確率,如圖1所示。
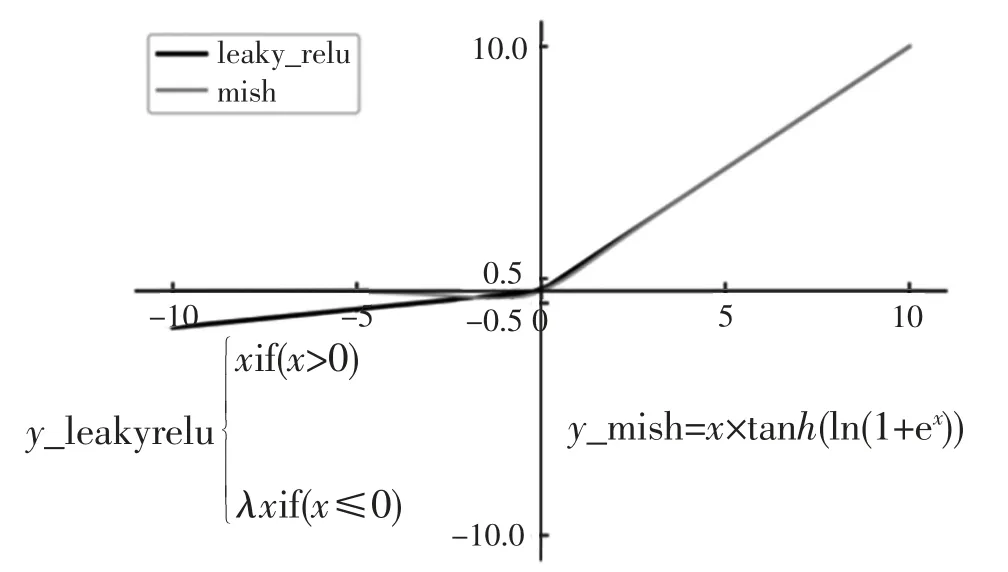
圖1 Mish激活函數(shù)
YOLOv5是在YOLOv4的基礎(chǔ)上進行的一定程度上的優(yōu)化。YOLOv5中新加入了Focus模塊,主要用于切片操作,另外在YOLOv4中使用的CSP模塊在YOLOv5的Backbone和Neck中都有應(yīng)用。輸入部分依然采用了YOLOv4中采用的Mosaic數(shù)據(jù)增強技術(shù),另外對于錨框的設(shè)置采用了每次訓(xùn)練時自適應(yīng)生成的方式,以及為了保持正常的長寬比,在填充增強環(huán)節(jié)自適應(yīng)增添最少的黑邊。預(yù)測部分采用GIOU_Loss損失函數(shù)和NMS非極大抑制。
YOLOv5共有4種模型,分別是YOLOv5-s、YOLOv5-m、YOLOv5-l和YOLOv5-x。4種模型網(wǎng)絡(luò)的深度和寬度有所不同。經(jīng)過同一數(shù)據(jù)集訓(xùn)練模型并推理預(yù)測結(jié)果比較,YOLOv5-s模型速度和性能最好,而YOLOv5-x模型的平均精度均值最佳[1,11]。
YOLOv5網(wǎng)絡(luò)模型如圖2所示,該模型包括Input(輸入端)、Backbone(主干網(wǎng)絡(luò))、Neck(網(wǎng)絡(luò))和Prediction(預(yù)測端)4部分。
2 訓(xùn)練數(shù)據(jù)集
2.1 DOTA數(shù)據(jù)集介紹
DOTA圖像是從中國資源衛(wèi)星應(yīng)用中心提供的谷歌地球,GF-2和JL-1衛(wèi)星收集的,CycloMedia B.V.DOTA機構(gòu)提供的航空圖像,由RGB圖像和灰度圖像組成。RGB圖像來自Google Earth和CycloMedia,而灰度圖像來自GF-2和JL-1衛(wèi)星圖像的全色帶。所有圖像都以“jpg”格式存儲。
2.2 數(shù)據(jù)集的來源
從DOTA數(shù)據(jù)集中選擇2 000張圖片,組合訓(xùn)練集和測試集。樣本集中包含15個類別:飛機、船舶、港口、橋梁、大型車輛、小型車輛、直升機、環(huán)形交叉路口、足球場、游泳池、儲罐、棒球場、網(wǎng)球場、籃球場和地面田徑場。
部分樣本集如圖3所示。

圖3 部分樣本集
3 實驗流程
3.1 實驗環(huán)境與配置
3.1.1 基于YOLOv5算法的小目標(biāo)檢測的硬件配置
處理器:Intel Xeon Silver 4210 CPU@2.20 GHz。
內(nèi)存:12 GB。
顯卡:GeForce RTX 2080 Ti。
3.1.2 基于YOLOv5算法的小目標(biāo)檢測的軟件環(huán)境
操作系統(tǒng):Centos7。
實驗平臺:python 3.7,pytorch1.7.1。
3.2 超參數(shù)設(shè)置
本文基于YOLOv5算法,采用小批量隨機梯度下降法(SGD)來訓(xùn)練小目標(biāo)檢測模型。在開始訓(xùn)練前,首先將YOLOv5模型的初始學(xué)習(xí)率設(shè)為0.01,動量參數(shù)設(shè)為0.937,權(quán)重衰減系數(shù)設(shè)為0.000 5,最大訓(xùn)練次數(shù)設(shè)為300,輸入圖片尺寸設(shè)為1 024 px×1024 px,batch_size設(shè)為16。
3.3 YOLOv5模型訓(xùn)練
本文使用DOTA數(shù)據(jù)集通過Input(輸入端)進行輸入,由于遙感圖像數(shù)據(jù)集中要檢測的目標(biāo)尺寸較小,為了提升網(wǎng)絡(luò)的訓(xùn)練效果,Input端對輸入的圖片進行預(yù)處理操作,并將其輸入到Y(jié)OLOv5網(wǎng)絡(luò)中進行訓(xùn)練,分別經(jīng)過Backbone(特征提取網(wǎng)絡(luò))、Neck(特征融合網(wǎng)絡(luò)),得到訓(xùn)練好的模型,然后利用訓(xùn)練好的模型通過檢測網(wǎng)絡(luò)(Prediction預(yù)測端)進行預(yù)測,最后輸出預(yù)測結(jié)果。小目標(biāo)檢測過程如圖4所示。
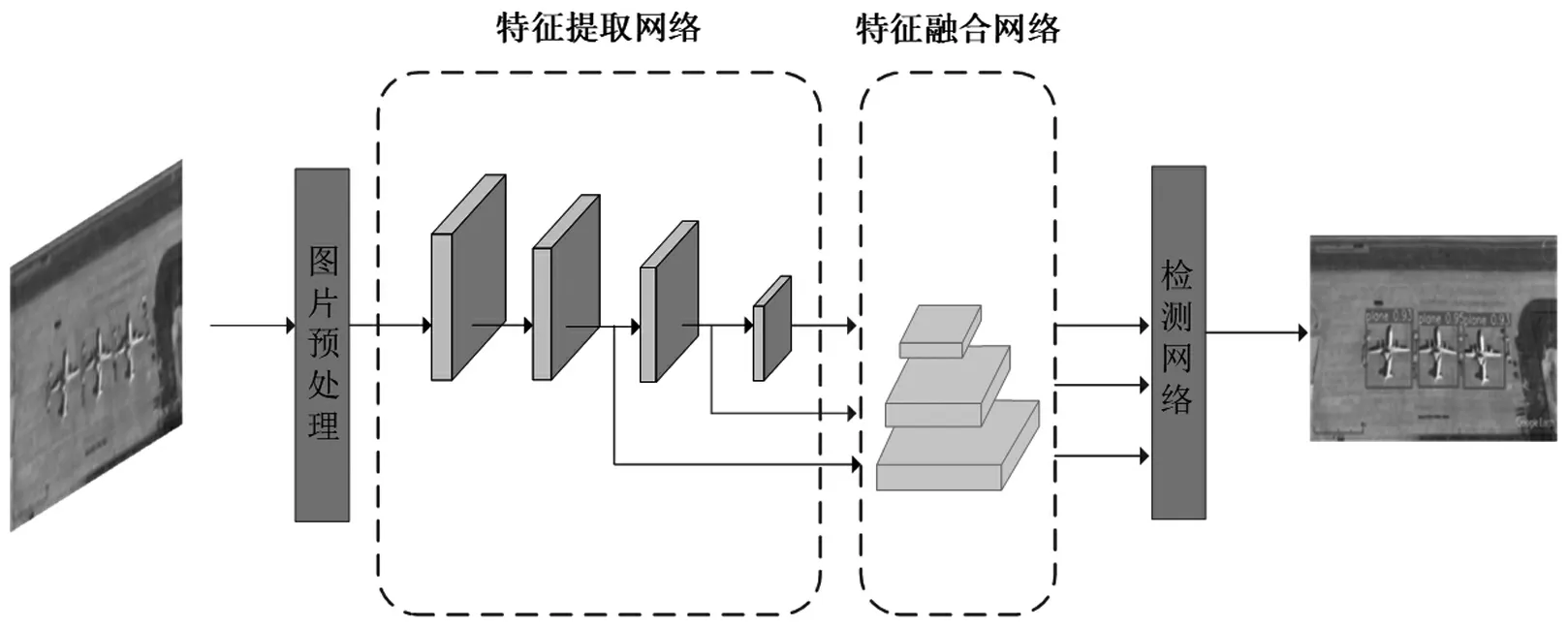
圖4 小目標(biāo)檢測過程
3.3.1 Input(輸入端)
DOTA數(shù)據(jù)集通過Input(輸入端)進行輸入,在Input端會采用Mosaic數(shù)據(jù)增強、自適應(yīng)錨框計算和統(tǒng)一圖片尺寸大小等方法對要訓(xùn)練的數(shù)據(jù)進行預(yù)處理,從而減少黑邊降低冗余信息,以此來提升遙感圖像目標(biāo)檢測精度。
3.3.2 Backbone(特征提取網(wǎng)絡(luò))
Backbone包括Focus模塊、CSP模塊和SPP模塊。YOLOv4中的Backbone中只有CSP模塊,而YOLOv5中新增了Focus模塊[5]。新增的Focus模塊的作用主要是對圖片進行切片操作,類似于下采樣,其過程是逐步變化的。比如在Focus模塊中輸入圖像為1 024 px×1 024 px×3 px,通過切片操作將圖像變?yōu)?12 px×512 px×12 px的特征圖,再經(jīng)過3×3的卷積操作,最終輸出512 px×512 px×32 px的特征圖。SPP是空間金字塔池化的簡稱,由卷積層、不同大小的池化層和卷積層構(gòu)成,其先通過一個標(biāo)準卷積模塊將輸入通道數(shù)減半,然后分別采用kernel-size為5、9、13的最大池化Maxpool(對于不同的核大小,padding是自適應(yīng)的),再將3次最大池化的結(jié)果與未進行池化操作的數(shù)據(jù)進行Concat,提高感受野。
3.3.3 Neck(特征融合網(wǎng)絡(luò))
Neck的結(jié)構(gòu)由FPN(自上而下)+PAN(自底向上結(jié)構(gòu)的特征金字塔)結(jié)構(gòu)組成,F(xiàn)PN結(jié)構(gòu)采用上采樣方法傳遞信息和融合信息,獲取預(yù)測的特征圖。YOLOv5網(wǎng)絡(luò)結(jié)構(gòu)中在FPN層后面,還添加了一個特征金字塔,自下向上,其中有2個PAN(路徑聚合網(wǎng)絡(luò))結(jié)構(gòu),通過下采樣操作,將低層與高層的特征信息進行融合,輸出預(yù)測的特征圖。
3.3.4 Prediction(預(yù)測端)
Prediction由非極大值抑制(NMS)和Bounding box損失函數(shù)2大部分組成。在Bounding box中,GIOULoss函數(shù)作為損失函數(shù),通過NMS函數(shù)可以在預(yù)測結(jié)果處理階段解決多余預(yù)測框問題或進行篩選,以此選擇最優(yōu)預(yù)測框。計算公式如下
式中:實線框A表示目標(biāo)位置框線,虛線框B表示目標(biāo)的預(yù)測框線,C作為包圍A、B框線的最小包圍框。IOU是輸出框和真實框的交并比。
4 實驗結(jié)果
YOLOv5的初始權(quán)值采用COCO數(shù)據(jù)集上訓(xùn)練好的yolov5s.pt,權(quán)值采用模型從源數(shù)據(jù)學(xué)到的遷移到目標(biāo)數(shù)據(jù)集上,使得YOLOv5模型收斂,得到訓(xùn)練好的模型,其中YOLOv5模型訓(xùn)練耗時為6.609 h,得到的權(quán)值文件大小為14.8 MB,隨著迭代次數(shù)增加,訓(xùn)練參數(shù)變化如圖5所示。
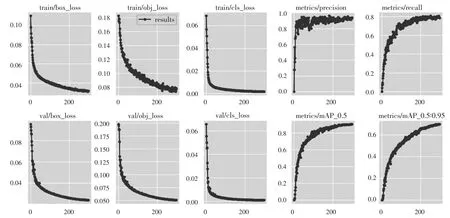
圖5 訓(xùn)練參數(shù)變化圖
box_loss:推測為GIOU損失函數(shù)均值,其值越小方框越準。
obj_loss:推測為目標(biāo)檢測loss均值,其值越小目標(biāo)檢測越準。
cls_loss:推測為分類loss均值,其值越小分類越準。
實驗使用衛(wèi)星拍攝的遙感圖像作為數(shù)據(jù),原始圖片中汽車、輪船是尺寸很小的目標(biāo)物體,本文針對小目標(biāo)檢測任務(wù)訓(xùn)練的YOLOv5模型能夠準確地識別出目標(biāo)的類別。由表1可知,相較于YOLOv3,YOLOv5檢測精度提高了8.93%。
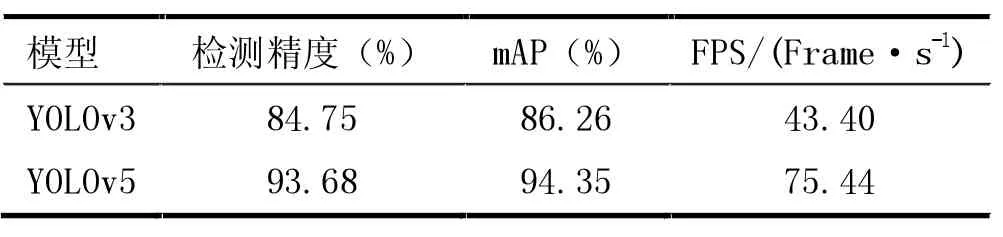
表1 模型對比試驗結(jié)果比較
5 結(jié)束語
目前遙感圖像中存在對物體檢測尺寸較小、檢測不準確等問題,本文提出將YOLOv5算法應(yīng)用到遙感圖像目標(biāo)檢測中,首先對輸入圖片進行預(yù)處理,通過隨機縮放、裁減和排列對圖片進行拼接,增加小目標(biāo)數(shù)量,提高網(wǎng)絡(luò)魯棒性豐富數(shù)據(jù)集。然后將圖像進行卷積得到特征圖,并送入主干網(wǎng)絡(luò)中進行特征融合。GIOU_Loss做為損失函數(shù),對遙感圖像中的小目標(biāo)進行檢測。本文采用衛(wèi)星拍攝的圖片作為目標(biāo)檢測數(shù)據(jù),根據(jù)結(jié)果展示表明,YOLOv5算法能有效檢測識別出遙感圖像中的小目標(biāo)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
