基于CNN的安防數據相似重復記錄檢測模型
2023-03-15 09:56:42洪惠君梁雅靜
計算機應用與軟件 2023年2期
王 巍 劉 陽 洪惠君 梁雅靜
1(河北工程大學信息與電氣工程學院 河北 邯鄲 056038) 2(河北省安防信息感知與處理重點實驗室 河北 邯鄲 056038) 3(江南大學物聯網工程學院 江蘇 無錫 214122)
0 引 言
隨著信息化時代的飛速發展,每個行業每天都會產生大量的數據,安防行業也不例外。在安防行業中,部分結構化的信息還需要以手工錄入、人為修改的方式進行[1]。這種方式不但效率低,而且會產生許多的臟數據,會直接影響到各類事件的后續處理效率。這些臟數據的表現形式主要有相似重復記錄、缺失數據、沖突數據和錯誤數據等幾種類型[2]。其中數據源中存在相似重復記錄是最嚴重的問題之一,嚴重時可能會導致數據失效。因此相似重復記錄的檢測及清除一直都是研究的熱點。
當前常見的相似重復記錄檢測算法主要有編輯距離算法(Levenshtein Distance)、Smith-Waterman算法、N-gram算法和機器學習算法等。陳俊月等[3]提出了基于詞向量的編輯距離算法,改進了傳統的編輯距離算法和Jaccard系數,將編輯距離的刪除和插入兩種編輯操作修改為空字符與目標字符的替換操作,通過詞向量計算每種編輯操作的相似度并累加,得出改進的編輯距離相似度。文獻[4]改進了編輯距離算法,使用同義詞詞典替換了傳統的語法變異的方法,對于存在大量語法錯誤和拼寫錯誤的問題的數據集,可有效提高算法的精度。文獻[5]利用依賴圖的傳遞閉包和循環傾斜提出了一種Smith-Waterman算法并行化的方法,將精確傳遞閉包的方法替代為近似傳遞閉包,在現代多核計算機中加速效果顯著。文獻[6]對比了三種基于統一計算設備架構(Compute Unified Device Architecture,CUDA)的Smith-Waterman算法的并行計算方法,分別是粗粒度加速方法、細粒度加速方法和重新定義遞歸公式的方法。其中:粗粒度加速方法可利用GPU同時處理多個對齊,但是不同線程處理長度不同的序列的時間不同,導致處理短序列的線程等待時間較長;細粒度加速方法可以利用多線程計算DP矩陣,減少了中間計算的時間,但是在計算開始和結束的階段都需要花費大量的時間;重新定義遞歸公式的方法重新定義了Smith-Waterman算法的遞歸公式,將算法時間復雜度從O(mn)降低到了O(mlog2n),其中m和n表示任意兩條記錄的長度,提高了算法的效率,但不能對差距的擴大給出不同的罰分。王常武等[7]提出了一種加權的N-Gram相似重復元數據記錄檢測算法,對于不同的標簽在相似重復記錄檢測的過程中的重要程度賦予不同的權重,依據權重使用加權的N-gram算法進行相似度計算,實驗表明,加權后的N-gram算法優于普通的N-gram算法。陳亮等[8]使用分塊技術根據字段對數據排序并分塊,使用滑動窗口的思想提升檢測效率,然后將各字段得出的分塊一起聚類,對重復率較大的分塊對首先比對,并放棄聚類效果較差的分塊,最終通過降低聚類次數和放棄聚類效果較差的分塊的方式提升了效率和準確率。
近年來機器學習成了研究的熱點,幾乎在各行業都有應用案例,也有研究人員運用機器學習算法來檢測相似重復記錄。相似重復記錄的檢測在機器學習中可以看作分類問題中的二分類問題。呂國俊等[9]提出了一種基于多目標蟻群優化的支持向量機的相似重復記錄檢測方法,該方法將相似重復記錄描述為一個二分類問題,同時考慮到相似重復記錄中重復樣本很少的問題,只用不相似重復記錄樣本進行訓練。文中的實驗結果驗證單類支持向量機算法的有效性。張攀[10]將BP神經網絡運用到相似重復記錄的檢測當中,用兩條記錄相同字段間的編輯距離組成的向量作為BP網絡的輸入數據,并為其添加上標簽訓練出BP網絡,然后使用訓練出的BP神經網絡檢測兩條記錄是否為相似重復記錄,實驗結果表明,在數據生成器“febrl”生成的數據中,基于BP神經網絡的相似重復記錄檢測方法的準確率可達97%以上。孟祥逢等[11]首先融合Jaro算法與TF-IDF算法計算字段相似度,然后使用經過遺傳算法優化的神經網絡計算兩條記錄的相似度,可以有效提高檢測的準確率和精度,但在中文數據中的效果還有待商榷。
盡管上述相似重復記錄檢測算法的精確率(Precision)和召回率(Recall)等指標都已經達到了較高的水平,但是上述數據大部分是開源的數據集,實際應用中的數據集存在更復雜的情況。在安防數據庫中,由于不同信息錄入員的不同習慣,存在大量空值、錯誤值、串字段錯誤和各種符號等干擾信息,對相似重復記錄的檢測產生了一定的影響,同時安防數據中部分相似重復記錄肉眼辨別都需要較長時間。例如表1中前兩條記錄表述不同,但實際含義相同,是相似重復記錄,而后兩條記錄雖然僅存在個別字不同,但其是兩個不同的加油站,不是相似重復記錄。因此,安防數據相似重復記錄的檢測難度比網絡上開源的數據集要高,需要開發一種適用于安防數據的相似重復記錄檢測模型,檢測出盡可能多的相似重復記錄對,同時還需要較強的泛化能力。卷積神經網絡(Convolutional Neural Networks,CNN)是深度學習的代表算法之一,在深度學習中的研究最為廣泛[12]。近年來,CNN開始應用于文本分類等自然語言處理領域,并且取得了一定的成果。例如,文獻[13-14]將CNN應用于文本情感分類;宋巖等[15]使用CNN對文本進行分類;肖琳等[16]使用CNN對文本進行多標簽分類;張璞等[17]結合CNN與微博文本特征對用戶性別進行分類等。
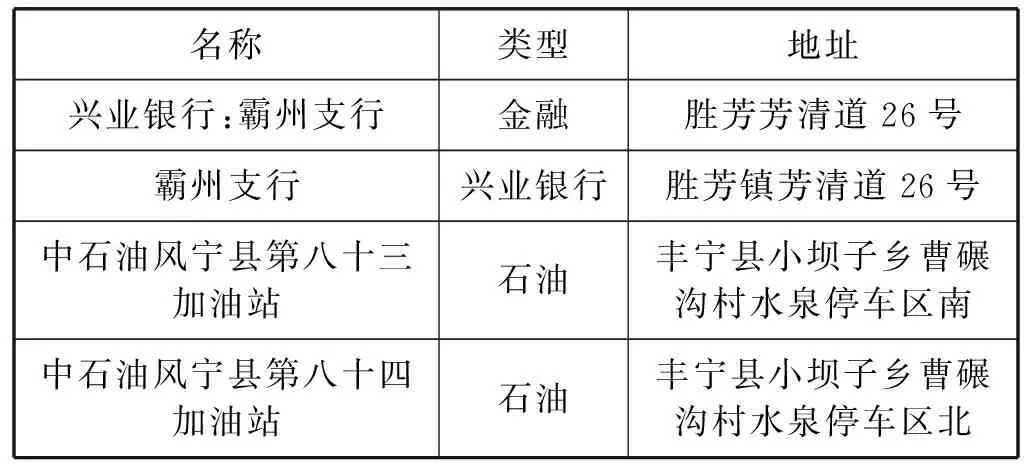
表1 安防數據相似重復記錄示例
因此,本文設計一種基于CNN的安防數據相似重復記錄檢測模型。通過對在手寫數字識別上擁有不錯效果的LeNet- 5進行改進,得出了兩種適用于安防數據的相似重復記錄模型,一種是以詞向量矩陣為輸入的CNN模型(Word Embedding Matrix CNN,WE-CNN),另一種是以相似度矩陣為輸入的CNN模型(Similarity Matrix CNN,SIM-CNN)。然后分別對這兩種模型進行了介紹,并通過了K折驗證,使用精確率、召回率和F1值(F1 Score)等評價指標對模型進行了評價。
1 數據預處理
為了提高模型的效率和可靠性,在訓練模型之前,需要對數據進行預處理,并且需要將每條記錄中的每個詞都轉換為模型可以識別的詞向量(Word Embedding)。根據安防數據存在的問題以及安防數據的特點,本文將數據預處理主要步驟分為分詞和詞向量生成兩部分,具體流程如下:
(1) 字段選擇。手動選擇數據庫中對于任意兩條記錄是否為相似重復記錄影響較大的字段,并且刪除數據庫中的空記錄等無效的記錄。
(2) 分詞。對記錄中的每一個字段進行中文分詞,并刪除停用詞、標點、特殊字符等內容。本文采用“jieba”分詞工具進行分詞。將每條記錄分詞后的內容按照字段順序組成一個列表,也就是一個列表對應一條記錄,則第i個列表的長度L(i)表示為:
(1)
式中:n為字段數;lif為第i個列表的第f個字段分詞后的詞語的個數。
(3) 訓練詞向量。對分詞后的所有列表進行詞向量的訓練,得出每一個詞的詞向量c。本文采用Google的“Word2vec”工具訓練詞向量,主要參數如表2所示。其語料庫為本文的實驗數據某安防報警網絡公司用戶數據。
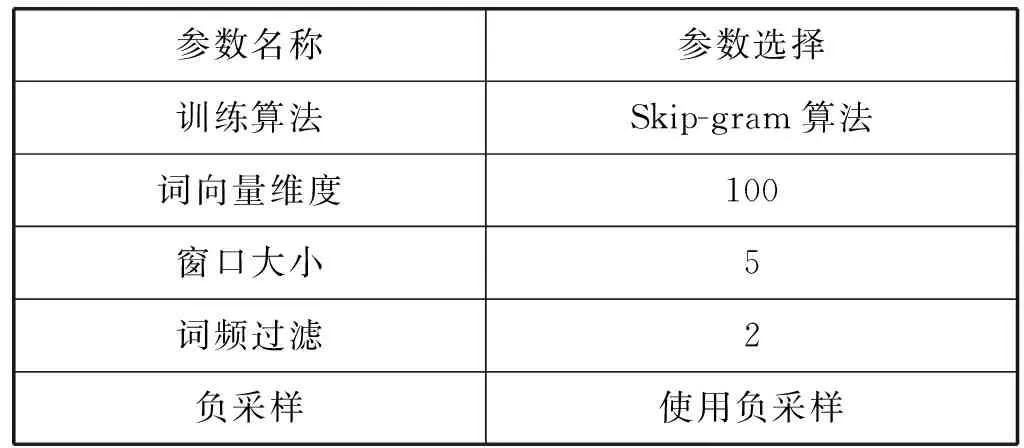
表2 “Word2vec”詞向量訓練工具主要參數
表2中的Skip-gram算法使用中心詞預測周圍詞語,根據預測結果修正中心詞詞向量。通過對安防領域數據的驗證,大部分字段為中文短句或者長詞組,每個詞與前后詞的關聯較大,并且這些短句或者長詞組對兩條記錄是否為相似重復記錄影響較大,因此對于安防領域數據,可使用“Word2vec”的Skip-gram算法訓練詞向量。
(4) 合成矩陣。將每一個記錄中的所有詞語對應的詞向量組成一個向量組,該向量組就是詞向量矩陣。假設第i條記錄的詞向量矩陣是Vi,則該矩陣表示為:
Vi=[c1,c2,…,cL(i)]
(2)
使用Word2vec中的相似度計算算法,計算出兩條記錄m和n中所有詞之間的相似度,組成相似度矩陣S,表示為:
(3)
(5) 統一矩陣大小。統一各詞向量矩陣的矩陣大小和各相似度矩陣的矩陣大小,根據分詞后的每一個列表的長度L(i)(i∈N且i∈[0,n),n是數據庫中刪除無效記錄后的記錄數),選擇合適的矩陣大小,不足的部分補充0,超出的部分刪除。如果選擇的矩陣大小太小,無法包含記錄的有效信息,相反,過大會降低計算的效率。圖1為本文選用的安防數據記錄對應的記錄長度比例分布圖,橫坐標表示記錄長度,縱坐標表示小于等于某長度的記錄與全部記錄的數量比。可以看出95%左右的記錄長度都在60以下,因此本文的詞向量矩陣大小為60×100,相似度矩陣大小為60×60。
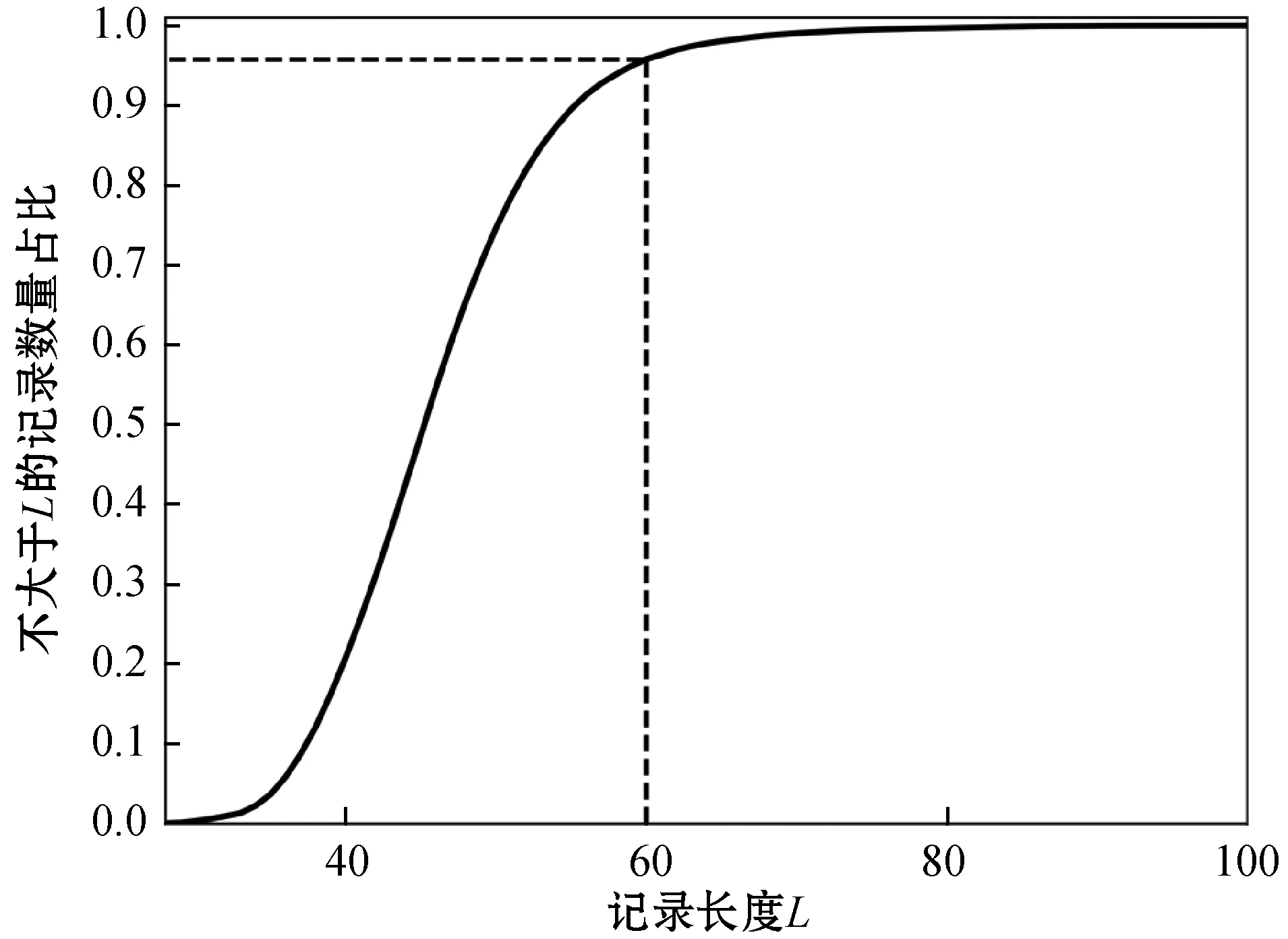
圖1 安防數據記錄長度比例分布
(6) 標記數據。標記兩條記錄m和n是否為相似重復記錄,并將m和n詞向量矩陣與標簽組成帶標簽的詞向量矩陣數據。將兩條記錄m和n組成的相似度矩陣與標簽組成帶標簽的相似度矩陣數據。
上述流程如圖2所示。
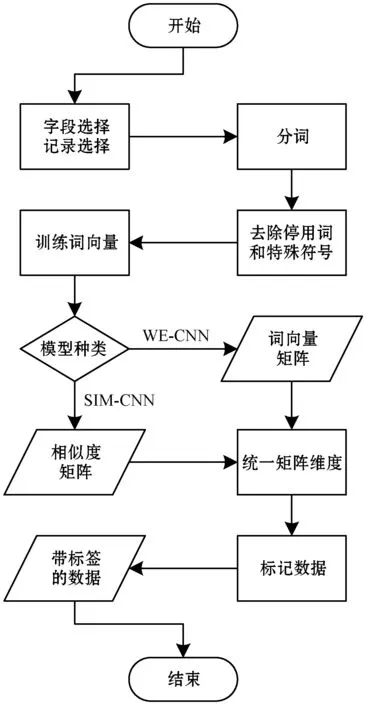
圖2 數據預處理流程
2 模型設計
2.1 LeNet- 5模型
Fukushima[18]最早提出了卷積神經網絡,除去輸入層和輸出層,卷積神經網絡通常還包含若干個卷積層、池化層和全連接層。LeNet- 5[19]是出現時間最早的卷積神經網絡之一,由Yann LeCun提出,最早應用于手寫體識別。LeNet- 5的結構如圖3所示。
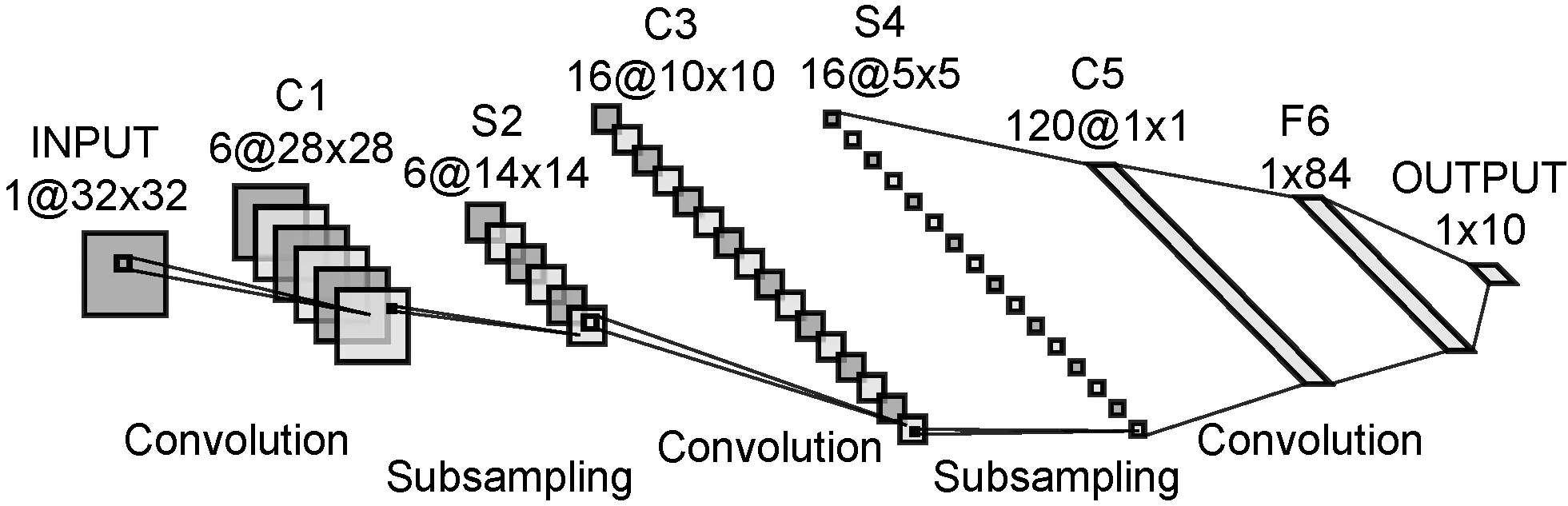
圖3 LeNet- 5結構
LeNet- 5一共有8層,包括:3個卷積層C1、C3和C5;兩個池化層S2和S4;一個全連接層F6;一個輸入層INPUT和一個輸出層OUTPUT。其中INPUT層的輸入是1幅維度為32的圖片;C1層通過6個5×5大小的卷積核得出6幅維度為28的特征圖;S2層將上一層特征圖中2×2范圍內的數值相加并乘一個系數加一個偏置,得出6幅維度為14的特征圖,這個過程稱為二次采樣(Subsampling),其中的系數和偏置可訓練;C3層采用部分映射的方式將S2層的6幅特征圖通過5×5大小的卷積核轉換為16幅10×10的特征圖,表3展示了具體對應的方案,其中的數字為特征圖(通道)號;S4層通過二次采樣,得出16幅5×5的特征圖;C5層用5×5的卷積核對5×5的特征圖進行卷積操作,將S4層的16幅特征圖轉換為120幅1×1的特征圖;F6層包括84個單元,并且完全連接到C5層。OUTPUT層有10個歐氏徑向基函數單元,表示十個手寫數字,可得到圖片是哪個手寫數字。
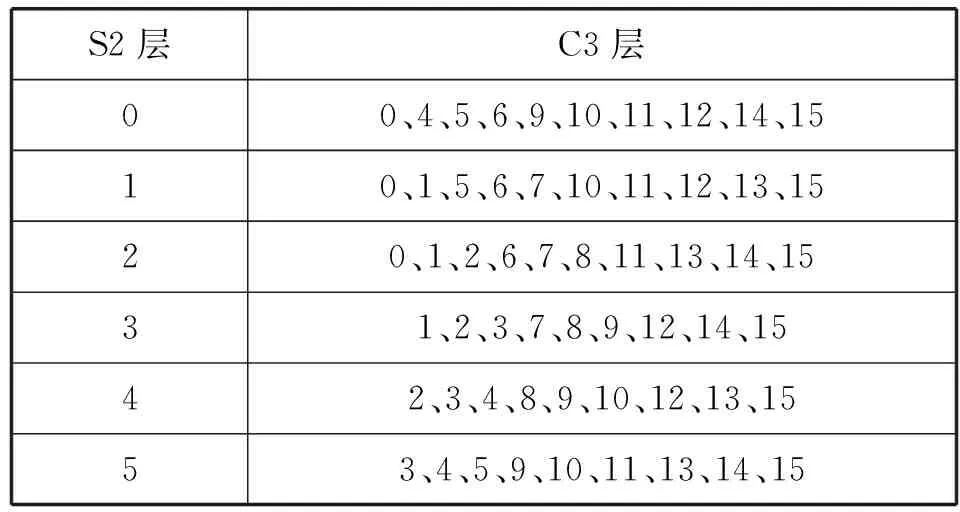
表3 S2與C3的連接方案
2.2 改進的LeNet- 5模型
(1) WE-CNN模型。與復雜的圖像識別相比,文本識別的復雜度要低一些。而LeNet- 5可以識別較為簡單的手寫體圖片,所以將LeNet- 5應用于相似重復記錄的識別具有一定的可行性。為了讓LeNet- 5模型適用于文本識別,并且可以有效解決安防數據相似重復記錄檢測存在的無法填補的空值、串字段等難點,本文設計以記錄的詞向量矩陣為輸入的CNN模型WE-CNN,模型在LeNet- 5的基礎上進行改進,改進后的模型如圖4所示,具體做了以下幾個部分的改進。
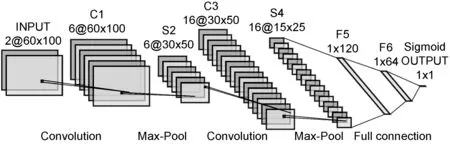
圖4 WE-CNN模型結構
在LeNet- 5中,輸入維度為32×32,為了保證得到更全的細節特征,提高模型的識別率,將輸入的維度修改為與數據預處理中描述的60×100,同時因為要判斷兩條記錄的相似度,所以輸入的通道數為2。
為了簡化算法,將S2層與C3層之間的連接方案改為全映射;把C5層改為全連接層并改名為F5,這樣可以更好地將特征矩陣中的信息傳遞下去,這里涉及的特征矩陣對應LeNet- 5中的特征圖;C1層和C3層均采用3×3的卷積核,并且將卷積操作的填補(padding)設置為1,在進行卷積操作時可以不改變特征矩陣的維度,在簡化各層之間的維度計算的同時可以保留更全的信息;將S2層和S4層中的二次采樣修改為最大池化(Max-Pool),可以保留記錄中更多的邊緣特征。
由于相似重復記錄檢測問題屬于二分類問題,故將模型的輸出從十個改為一個,并使用Sigmoid函數,將輸出值轉化為一個介于0到1之間的概率值,概率值越接近1,表示輸入的兩條記錄為相似重復記錄的可能性越大,反之不是相似重復記錄的可能性越大,區分是否是相似重復記錄的閾值通常取0.5。
為了防止出現過擬合的現象,在S2層與C3層之間、S4層和F5層之間、F5層和F6層之間、F6層和OUTPUT層之間均加入Dropout方法。Dropout方法可以隨機丟棄p%的神經元,使用剩下的神經元進行訓練,可以防止過擬合和增強模型的泛化能力。為了減輕梯度消失問題對模型的影響,在S2層、S4層、F5層、F6層和F7層均設置一個tanh函數。
使用Adam算法作為模型的優化算法。Adam算法結合了Momentum算法和RMSprop算法中的更新方向方法和計算衰減系數方法,式(4)為Adam算法的算法策略。
(4)
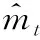
在二分類問題中,可以采用適用于二分類問題的交叉熵損失函數函數(Cross Entropy Error Function)作為模型的損失函數,式(5)為該函數的表達式。
(5)
式中:n是批量大小(batch size);x是模型實際輸出的值;y是標簽上的值,也就是目標值。
(2) SIM-CNN模型。在安防行業中,某些數據會有極高的質量要求,為了進一步提高數據的質量,在WE-CNN模型的基礎上,提出以相似度矩陣為輸入的CNN模型SIM-CNN。從理論上來說,與WE-CNN模型相比,在同樣的數據源下,SIM-CNN模型應該具有更高的識別率,但是SIM-CNN模型所需的相似度矩陣生成的時間較長。
除了輸入層,SIM-CNN與WE-CNN模型的其余部分完全相同。SIM-CNN的輸入為通道數為1的相似度矩陣,根據數據預處理中的描述,將輸入的相似度矩陣維度設置為60,模型的結構如圖5所示。
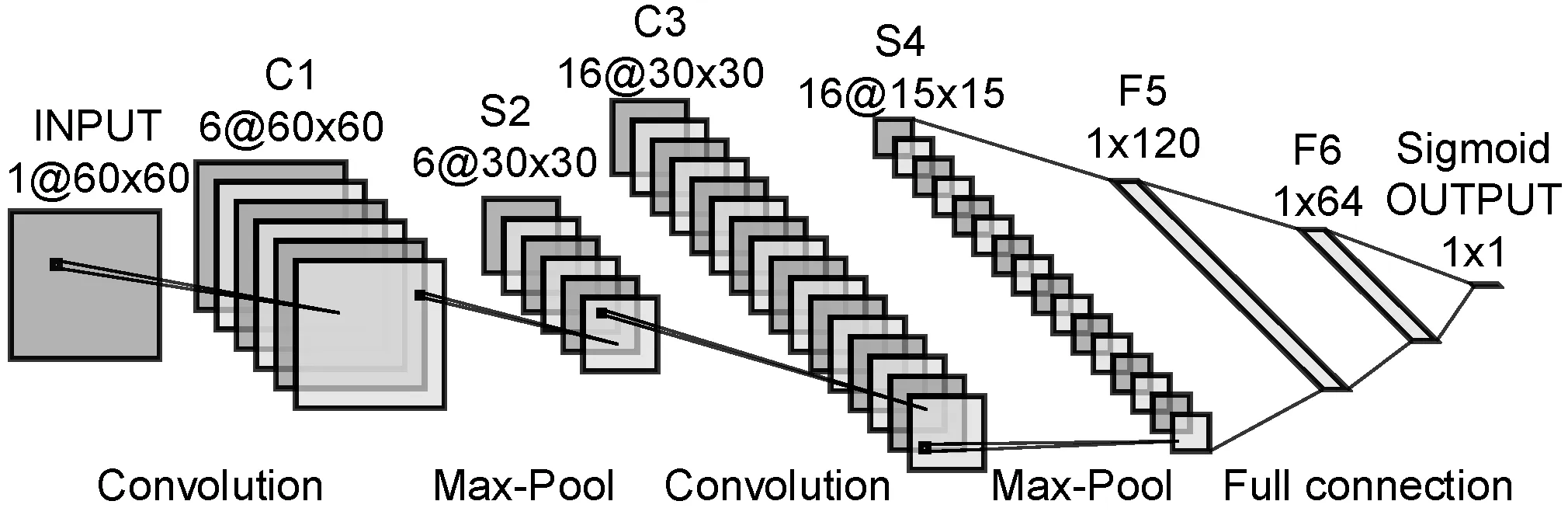
圖5 SIM-CNN模型結構
3 實驗驗證
本次實驗首先對實驗數據、實驗環境和實驗中用到的一些評價方法進行了介紹;然后對模型中的部分參數進行了選擇分析,并對模型的效果、泛化能力進行了驗證;最后與BP神經網絡進行了對比。
3.1 實驗數據說明
實驗采用某安防網絡報警公司的用戶數據作為實驗數據,一共有32 480條記錄,120個字段。經過篩選,得到了30 513條有意義的記錄,26個對相似重復記錄的識別影響較大的字段。經過初步判斷,實驗數據中有6 100對左右的相似重復記錄。
本次實驗選取了11 000對記錄作為訓練數據和測試數據,其中相似重復記錄和不是相似重復記錄的數據各5 500對。
3.2 實驗環境
實驗的硬件環境配置如表4所示。
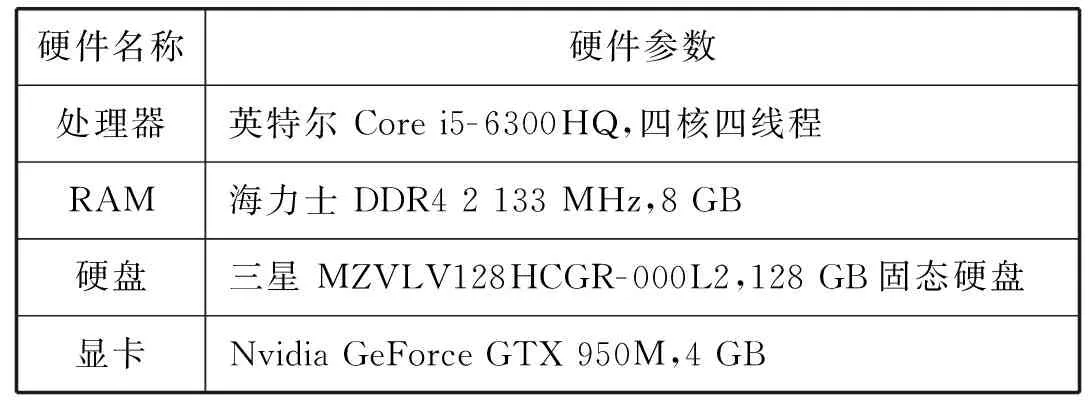
表4 實驗硬件環境
本實驗采用了CUDA并行計算架構,實驗的軟件環境如表5所示。
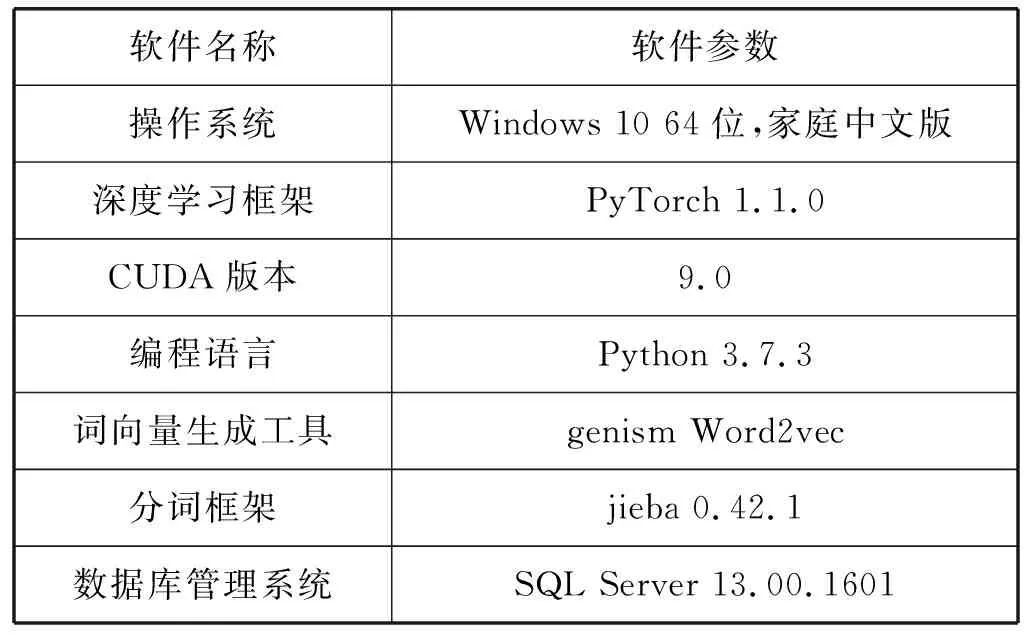
表5 實驗軟件環境
3.3 實驗評價方式
為了評價模型的優劣,引入了精確率、召回率和F1值等評價指標。精確率、召回率和F1值分別可以用式(6)-式(8)表示。
(6)
(7)
(8)
假設將不是相似重復記錄記為正類,是相似重復記錄記為負類,則式(6)-式(8)中:TP表示實際上和預測的都不是相似重復記錄的數據對的個數,記為真正類;FN表示實際上不是相似重復記錄,預測是相似重復記錄的數據對的個數,記為假負類;FP表示實際上是相似重復記錄,預測不是相似重復記錄的數據對的個數,記為假正類;TN表示實際上和預測的都是相似重復記錄的數據對的個數,記為真負類。
為了驗證模型的可靠性,引入K折交叉驗證的方法對模型進行分析。K折交叉驗證是將數據分成K組,使用任意一組作為測試集,剩余的K-1組作為訓練集,迭代K次,讓每一組數據都做過一次測試集,每次迭代的測試集中的數據不會出現在當次迭代的訓練數據中。
3.4 實驗結果和分析
(1) 學習速率選擇實驗。在批量大小batch-size都為64,迭代次數epoch都為60,以及其他參數都相同的情況下,從0.01、0.005、0.001、0.000 5和0.000 1五個學習速率當中確定合適的學習速率。從理論上來說,在各參數都相同的條件下,如果學習速率較大,可能會出現發散的情況,如果學習速率越小,收斂速度越慢。本實驗中,在學習速率在0.01時,兩個模型出現了損失發散的情況,在學習速率為0.005時,WE-CNN模型存在低概率的發散,故舍棄這些導致損失發散的學習速率。兩個模型在不同學習速率下的各項指標如圖6和圖7所示。
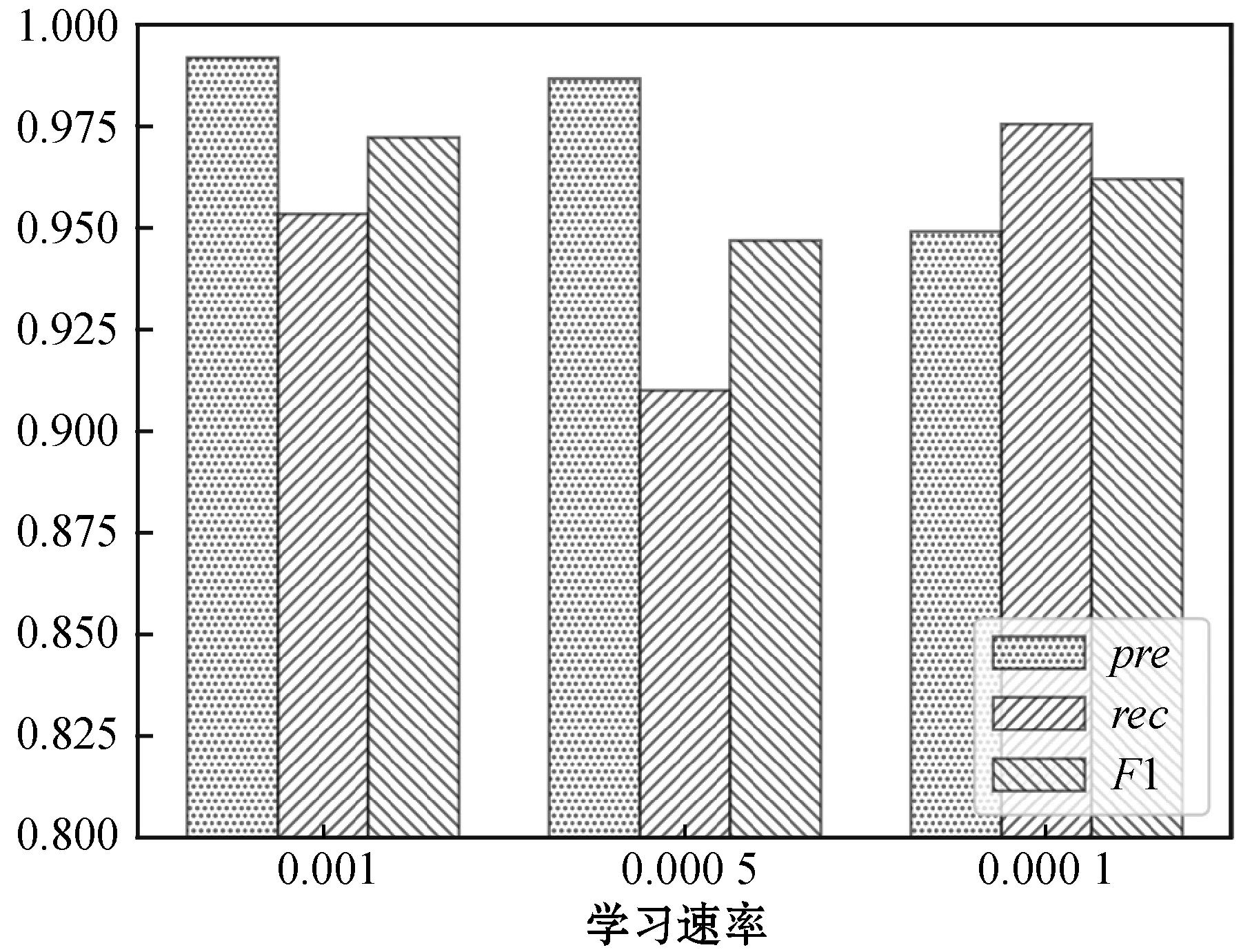
圖6 WE-CNN模型不同學習速率下的表現
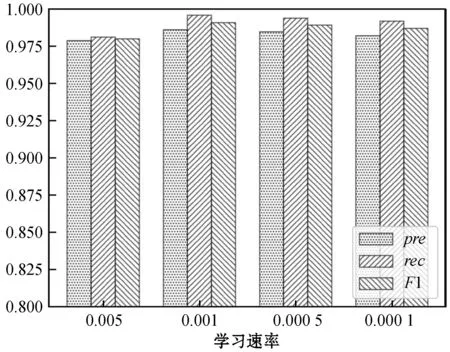
圖7 SIM-CNN模型不同學習速率下的表現
從圖6中可以看出,WE-CNN模型的學習速率為0.001時的整體效果最好,其F1值最大,但是召回率較低;從圖7中可以看出,當SIM-CNN模型在學習速率為0.001、0.000 5和0.000 1時,精確率、召回率和F1值都很接近,并且都在0.975以上,不過學習速率等于0.001時的SIM-CNN模型略優于其他學習速率的模型。這是因為隨著迭代次數的增加,學習速率為0.001的模型可以最先達到最優結果。所以在本實驗的測試數據集中,WE-CNN模型和SIM-CNN模型的學習速率在0.001時模型的表現最優。
(2) Dropout對模型的影響。表6介紹了是否使用Dropout優化方法對模型的影響。可以得出WE-CNN模型在不使用Dropout優化方法時會對模型的識別能力產生較大的影響,因為每次訓練都是使用相同的模型,所以出現了過擬合現象。而使用Dropout可以使神經元隨機失活,每次訓練的模型都不同,因此不容易出現過擬合現象,識別率相對更高。SIM-CNN模型在不使用Dropout優化方法時同樣會對模型的識別能力產生影響,所以使用Dropout優化方法可以有效防止過擬合,增強模型的識別能力。
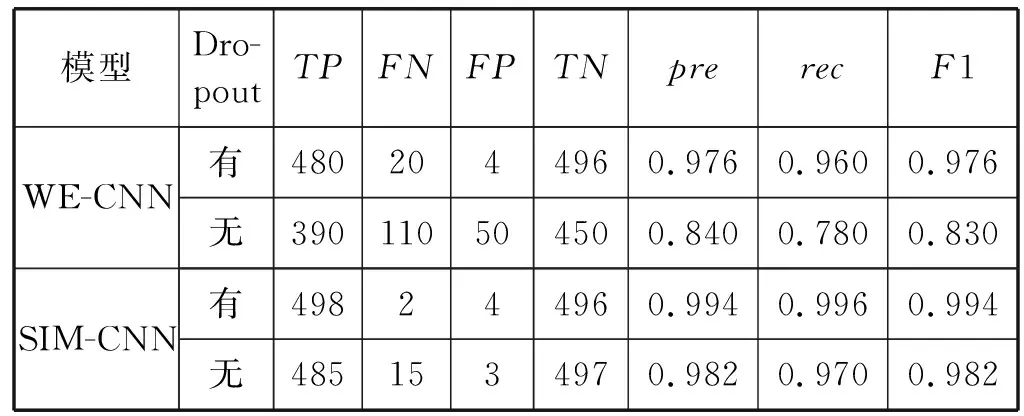
表6 Dropout優化方法對模型的影響
(3) K折交叉驗證。根據K折交叉驗證的規則,將本次實驗的11 000個樣本,分成了11組數據,每組數據中都有500個正類樣本和500個負類樣本。從第1組樣本開始,依次將該組數據作為測試集,并將剩余的數據作為第1組的訓練集。將學習速率設置為0.001,批量值batch-size=64,迭代次數epoch設置為60,閾值設置為0.5,通過WE-CNN模型在所有的訓練集進行訓練,并使用每個訓練集對應的測試集對模型進行測試,使用式(5)所示的交叉熵損失函數計算損失,得出K折驗證中每個測試集的精確率、召回率和F1值。WE-CNN模型的K折交叉驗證的各項指標如表7所示。
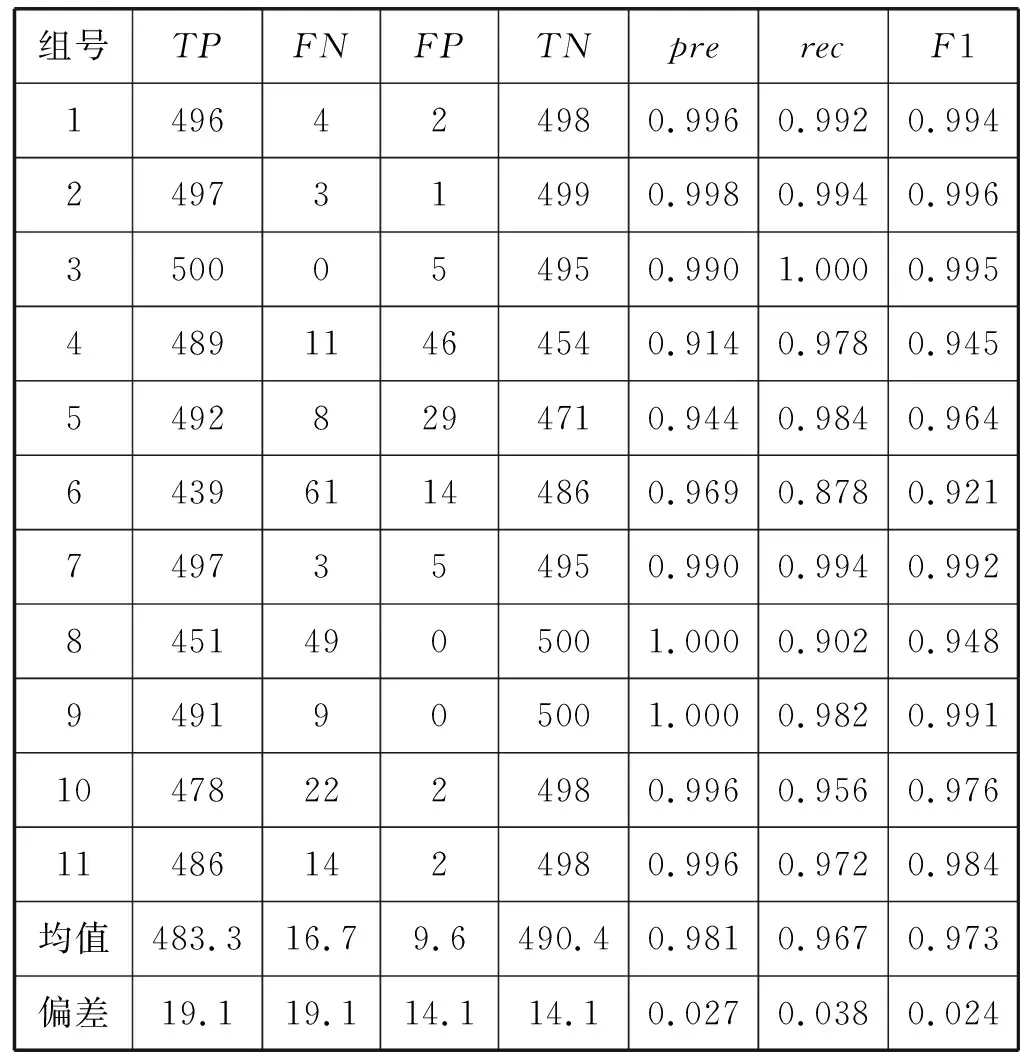
表7 WE-CNN模型K折交叉驗證各項指標
可以看出,雖然第6組數據對應的模型的召回率只有0.878,精確率和F1值也只有0.969和0.921,出現這種情況可能是因為該組數據的測試集中存在個別的標記錯誤。但是從整體上看,大部分組的精確率、召回率和F1值都在0.95到0.99左右,處于一個范圍較小的區間內,平均指標中最低的召回率也高達0.967,偏差也僅有0.038,F1值為0.973,偏差僅為0.024。但是在實際情況中,相似重復記錄的占比較少,而召回率可以表示數據中沒有相似重復記錄的極端情況,所以WE-CNN模型在極端情況下的平均識別率也能高達0.967。因此,WE-CNN模型具有較高的識別率和較強的泛化能力。
基于WE-CNN模型改進的SIM-CNN模型的K折交叉驗證的各項指標如表8所示。
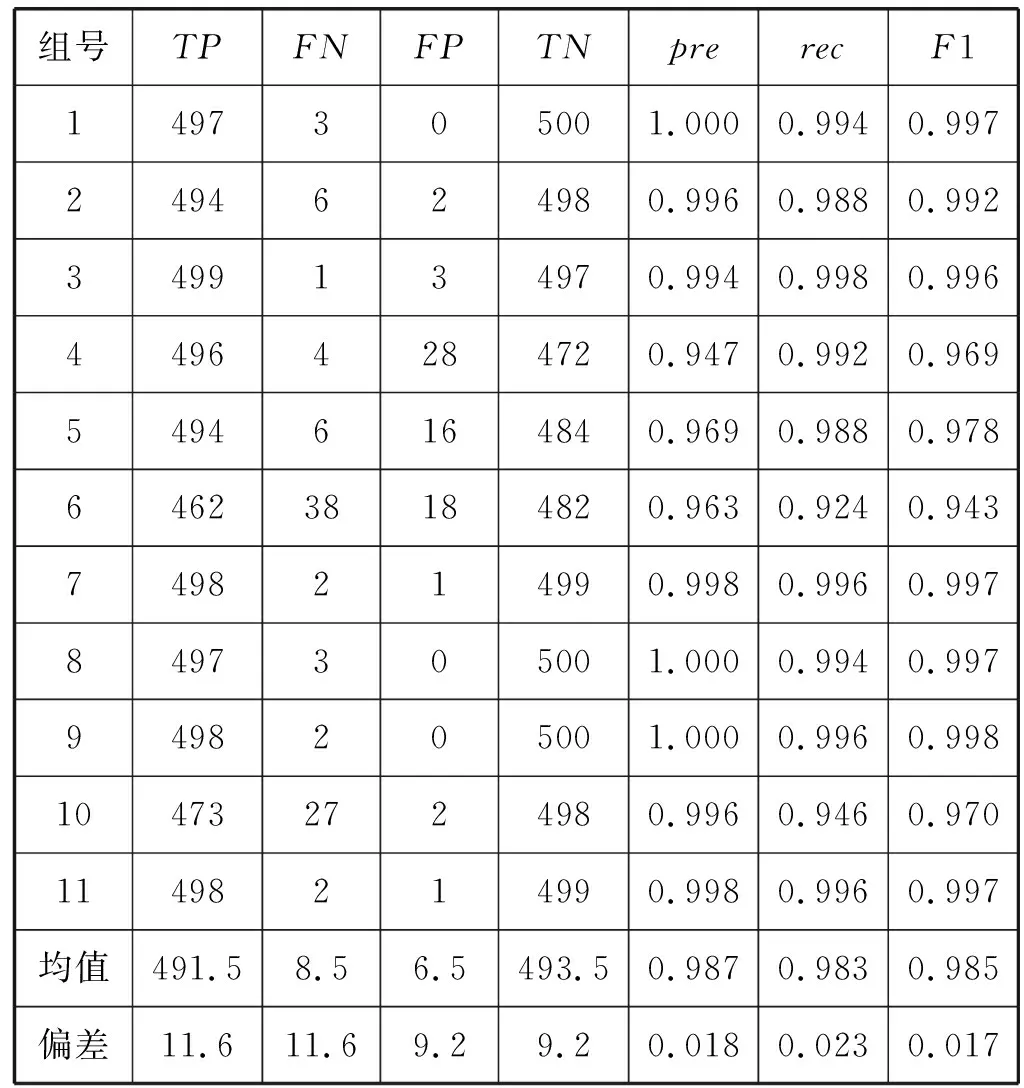
表8 SIM-CNN模型K折交叉驗證各項指標
其中SIM-CNN模型的K折交叉驗證實驗的每一組的訓練數據和測試數據都與WE-CNN模型K折交叉驗證實驗中對應的組中的數據相同。各類超參數也與WE-CNN模型的K折交叉驗證實驗相同。從表9中可以看出,SIM-CNN模型的各項指標要明顯優于WE-CNN,整體上都有了一定的提升。同樣是最低的第6組數據對應的模型的召回率已經達到了0.924,比SIM-CNN模型提升了0.046。從整體上來看,大部分的精確率、召回率、F1值都在0.97到1之間,處于一個很小的區間內,從平均上來看,精確率、召回率和F1值都達到了0.98以上,而偏差最大的召回率也僅有0.023,F1值也高達0.985,偏差僅有0.017。因此,與WE-CNN模型相比,SIM-CNN模型具有更高的識別率和更強的泛化能力。
(4) 運行時間。數據量為本次實驗所用的11 000對記錄,batch-size均設置為64,迭代次數epoch均設置為60,WE-CNN模型和SIM-CNN模型的訓練數據和測試數據都相同。兩模型的整體運行時間如表9所示。
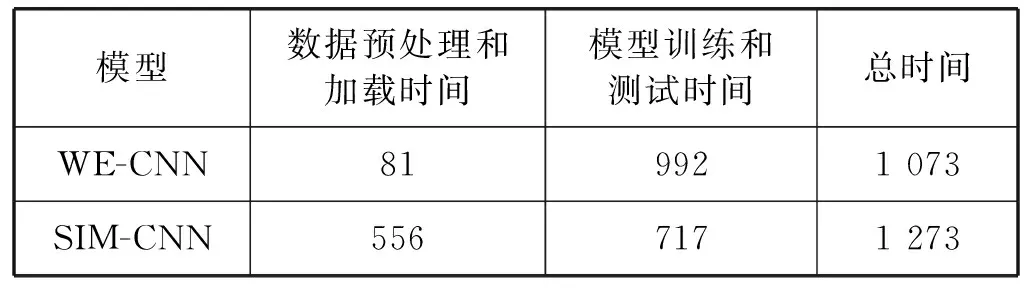
表9 模型運行時間 單位:s
從模型訓練和測試時間上來看,SIM-CNN模型的訓練速度要比WE-CNN模型快,但是由于SIM-CNN模型的輸入是兩條記錄對應的相似度矩陣,生成實驗所需的所有相似度矩陣需要556 s,而生成WE-CNN模型所需的所有詞向量矩陣僅需81 s。因此從整體上看,在本次實驗的數據集中,WE-CNN模型的整體運行時間為1 073 s,比SIM-CNN模型的整體運行時間少200 s。
(5) 模型對比。圖8為相同的實驗數據在WE-CNN、SIM-CNN和文獻[10]所述的BP神經網絡3種模型下的各項指標柱狀圖。
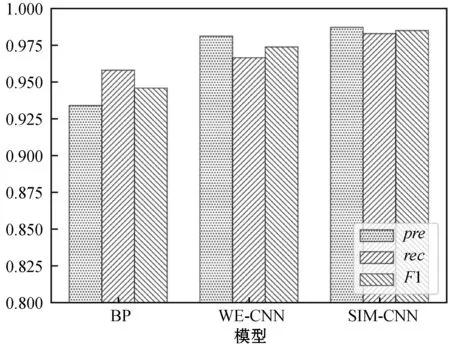
圖8 3種模型指標對比
可以看出,在整體識別效果上SIM-CNN模型最好,其次是WE-CNN模型,最后是BP神經網絡。這是因為SIM-CNN的輸入為相似度矩陣,與WE-CNN的輸入詞向量矩陣相比,在都保留了原有信息的基礎上輸入更簡潔,需要訓練的參數更少,因此SIM-CNN模型的識別效果最優。而BP網絡的輸入是相同字段間的編輯距離值組成的向量,而安防數據中的部分相似重復記錄的記錄對相同字段間的編輯距離值較大,部分不是相似重復記錄的記錄對相同字段之間的編輯距離值較小,識別效果自然較差。
3.5 實驗評價
綜上所述,SIM-CNN模型在上述實驗數據集中的識別率和在沒有相似重復記錄的極端情況下的識別率(實驗數據集中的召回率)均優于WE-CNN模型,但是SIM-CNN模型的數據生成和加載時間較長,導致整個訓練和測試的時間要長于WE-CNN模型。如果WE-CNN模型可以達到識別率的要求,或者檢測時長受限,可以使用WE-CNN模型進行相似重復記錄的檢測。如果對識別率等指標要求較高,或者檢測時長寬松,可以使用SIM-CNN模型進行相似重復記錄的檢測。
4 結 語
對于任意兩條記錄來說,相似重復記錄檢測只有是相似重復記錄和不是相似重復記錄兩種情況,故本文將相似重復記錄檢測問題視為了二分類問題。同時考慮到安防行業數據的相似重復記錄檢測要比網絡上的開源數據的檢測難度高,并且需要較高的識別率和較強的泛化能力。因此引入了CNN檢測相似重復記錄,提出以詞向量矩陣為輸入的WE-CNN模型和以相似度矩陣為輸入的SIM-CNN模型。
WE-CNN是以LeNet- 5為基礎進行改進的,現將改進內容總結為以下三部分。
1) 輸入和輸出層:將輸入層設置為兩個60×100的詞向量矩陣;輸出層增加Sigmoid函數。
2) 輸入和輸出層以外各層:將S2層與C3層之間設置為全映射;C5層設置為全連層并改名為F5;C1和C3層的采用3×3的卷積核;S2和S4層均設置為最大池化;在各層之間加入Dropout方法。
3) 優化器和損失函數:使用Adam優化器對模型進行優化;使用交叉熵損失函數對模型的損失進行計算。
將改進后的模型(WE-CNN)應用于安防數據相似重復記錄檢測,通過K折交叉驗證,得出了平均精確率、召回率和F1值均在0.96以上的結果。
SIM-CNN改進了WE-CNN的輸入層,將一組詞向量矩陣濃縮為一個相似度矩陣。在安防數據相似重復記錄檢測中,SIM-CNN模型K折交叉驗證的平均精確率、召回率和F1值均在0.98以上。SIM-CNN模型在損失了數據預處理和生成的時間的同時,精確率、召回率和F1值相對于WE-CNN模型分別提高了0.612%、1.656%和1.131%,偏差相對降低了33.333%、39.474%和29.167%。
以上驗證了兩種模型都具有較高的穩定性和泛化能力,可以適用于安防數據相似重復記錄檢測。但是當前模型和模型生成的過程還存在需要進一步完善或者改進的問題,比如安防數據標記方法較難、安防數據中的相似重復記錄的數量可能小于訓練所需的相似重復記錄的數量和安防數據相似重復記錄清除算法的設計等問題還需要解決。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
