高錯誤率長序列基因組數據敏感序列識別并行算法
2023-03-16 00:58:38鐘誠孫輝
通信學報 2023年2期
關鍵詞:實驗
鐘誠,孫輝
(1.廣西大學計算機與電子信息學院,廣西 南寧 530004;2.廣西高校并行分布與智能計算重點實驗室,廣西 南寧 530004)
0 引言
基因組數據是一類重要的醫療大數據,被廣泛應用于生物醫學、定制化醫療服務、法醫學鑒定和全基因組關聯研究等領域[1-2]。基因組數據敏感序列是指可用于發起推斷攻擊、成員身份攻擊、身份追蹤攻擊和完全攻擊等基因組數據隱私攻擊的核苷酸序列,包括短串聯重復(STR,short tandem repeat)序列和疾病相關序列(DRS,disease-related sequence)[3]。不同于網絡隱私數據的可重塑性,基因組數據敏感序列信息的泄露會對隱私泄露者的醫療保險、社會就業和公共福利等產生不利影響[4]。通過識別過濾基因組數據中的敏感信息,可以實現基因組數據敏感信息脫敏,有助于降低基因組數據隱私敏感信息受攻擊的風險。
基因組數據中的敏感序列包括STR 和DRS 這2 類。敏感序列識別串行算法的設計主要基于Hash映射思想,即通過產生序列Hash 指印來實現敏感序列的精確識別。此類代表算法有SRF(short read filter)[3]、LRF(long read filter)[4]和PriLive[5]等。這些基于序列Hash 指印思想的串行算法對高錯誤率的長序列基因組數據敏感序列識別準確率較低,且難以滿足對大規模長序列實時識別過濾的要求。為此,一些學者基于多核CPU 集群系統,通過設計多核CPU 并行算法,在準確識別含有錯誤信息的敏感序列的同時,加速求解大規模基因組數據敏感序列識別問題。
關于基因組數據敏感序列識別并行算法的研究,文獻[6]基于STR 挖掘工具FLASH(fast length adjustment of short read)和PERF(Python exhaustive repeat finder),在Hadoop 平臺上開發了CPU 并行加速的基因組數據短串聯重復序列識別算法BigFiRSt。文獻[7]采用劃分后綴分組方法,提出基于CPU 集群系統的最大串聯重復序列識別并行算法。在串行算法FindTRs 的基礎上,文獻[8]設計了在多核CPU 集群系統上運行的大規模短串聯重復序列識別并行算法MPI-dot2dot。根據STR 的周期重復性質,文獻[9]在多核CPU 集群系統上設計實現了生物序列模式精確匹配的并行算法。文獻[10]通過枚舉所有具有統計顯著性的局部最優出現頻率的子串,提出了一種面向多核CPU 系統的頻繁子串模式挖掘并行算法。上述多核CPU 并行算法僅針對基因組數據中的STR 進行識別,并沒有處理基因組數據中DRS 的識別,因此這些并行算法僅能識別出基因組數據中的部分敏感序列。對于低錯誤率的基因組數據,文獻[11]提出一種多核CPU 并行算法,以識別基因組數據中的短串聯重復序列和疾病相關序列。
已有的基因組數據敏感序列識別并行算法的設計主要是針對敏感序列2 種類型(STR 和DRS)中的一種進行處理的;有的并行算法雖然同時處理STR 和DRS 的識別,但它面向的是低錯誤率序列構成的基因組數據,而不是高錯誤率序列構成的基因組數據。此外,已有的基因組數據敏感序列識別并行算法是多核CPU 并行算法,隨著單分子實時測序和牛津納米孔測序等第三代測序技術的發展,測序平臺產生的序列具有長度長和錯誤率高的特點[12]。已有的并行算法難以高效、準確地識別出高錯誤率長序列構成的基因組數據中的2 類敏感序列STR 和DRS。為解決此問題,本文研究改進序列相似度計算模型,進而提出一種CPU 和GPU 協同計算加速識別高錯誤率長序列基因組數據中STR 和DRS 的并行算法CGPU-F3SR。該并行算法的特色和創新介紹如下。
1) 采用滑動窗口策略和k-mer 編碼方法,分割并提取高錯誤率長序列基因組數據中的核苷酸序列堿基錯誤信息。引入布隆過濾器,對高錯誤率長序列基因組數據進行高效過濾,避免算法對重復數據的多次計算。
2) 根據短串聯重復序列和疾病相關序列的結構特點,提出一種改進的序列相似度計算模型,實現準確識別出高錯誤率長序列基因組數據中的2 類敏感序列(STR 和DRS)。
3) 對基因組數據測序序列進行周期劃分,設計實現CPU 和GPU 協同計算的敏感序列識別并行算法,大大提升算法的運行效率。
1 方法
設待識別基因組數據共有l條長序列,Ns[0:ns-1]表示長度為ns的第s條長序列,s=0,1,2,…,l-1。本文提出的CPU 和GPU 協同計算的高錯誤率長序列基因組數據敏感序列識別并行算法包括序列分割過濾、短串聯重復序列并行識別、疾病相關序列并行識別和生成掩碼核苷酸序列4 個階段。
1.1 并行算法4 個階段
1.1.1 序列分割過濾
為并行識別高錯誤率長序列基因組數據中的敏感序列,首先將長序列Ns[0:ns-1]分割為ns-r+1條、每條長度為r的短序列Rs,j=Ns[j:j+r-1],其中,短序列Rs,j和Rs,j+1共享r-1 個重疊堿基,j=0,1,2,…,ns-r,s=0,1,2,…,l-1,ns>r。因為人類DNA序列中約99.5%的序列具有高度一致性,所以將長序列分割為短序列會產生許多相同的短序列[3]。
布隆過濾器由一個二進制位數組(位向量)和若干Hash 函數組成,多用于數據去重以及數據檢索[13]。為避免對重復短序列的多次計算,本文引入雙布隆過濾機制對短序列Rs,j并行過濾去重,j=0,1,2,…,ns-r,s=0,1,2,…,l-1。
設布隆過濾器BF1用于敏感序列去重,其位數組和使用的Hash 函數數目分別為B1[0:b1-1]和h1。布隆過濾器BF2用于非敏感序列去重,其位數組和使用的Hash 函數數目分別為B2[0:b2-1]和h2。為了初始化雙布隆過濾器,需根據式(1)計算B1和B2的位數組規模b1和b2[13]。
其中,pi表示布隆過濾器誤報率,ti表示BFi可容納序列數目的上限。通過預設參數pi和ti,可以根據式(1)計算得到位數組規模bi,i=1,2。此時,可以計算BFi使用的Hash 函數數目hi[13]為
依據式(1)和式(2)計算出雙布隆過濾器的參數b1和b2以及h1和h2之后,初始化布隆過濾器位數組B1,i=0 和B2,k=0,i=0,1,2,…,b1-1,k=0,1,2,…,b2-1。
當初始化雙布隆過濾器完成后,將短序列Rs,j進行周期劃分,然后使用Pr 個CPU 核心通過雙布隆過濾器BF1和BF2并行地對短序列Rs,j進行過濾去重,s=0,1,2,…,l-1,j=0,1,2,…,ns-r。
為方便理解短序列周期劃分思想,圖1 給出了塊劃分和周期劃分短序列的示例。
人類基因組數據測序序列中存在連續的串聯重復區域。若將分割得到的短序列采用圖1(a)所示塊劃分方式并行處理,則會造成部分線程處于“計算等待”狀態。為均衡數據計算,使每個線程達到負載均衡,本文采用圖1(b)所示的周期劃分對短序列進行并行處理,并采用雙布隆過濾器過濾去重。
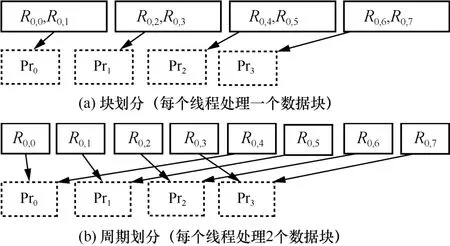
圖1 基于塊劃分和基于周期劃分短序列的示例
本文并行短序列過濾去重方法介紹如下。
Pr 個CPU 核心并行對Rs,v+dPr執行h1次Hash計算,以獲得h1個Hash 值H1,i(Rs,v+dPr),且對BF1中的位數組B1進行查詢。
若B1[H1,i(Rs,v+dPr)]的值均為1,i=0,1,2,…,h1-1,則表明Rs,v+dPr是重復短序列且為敏感短序列;若B1[H1,i(Rs,v+dPr)]的值不全為1,則需對Rs,v+dPr執行h2次Hash 計算,以獲得h2個Hash 值H2,i(Rs,v+dPr),并對BF2中的位數組B2進行查詢。
若B2[H2,i(Rs,v+dPr)]的值均為1,i=0,1,2,…,h2-1,則表明Rs,v+dPr為重復短序列且為非敏感短序列;若B2[H2,i(Rs,v+dPr)]的值不全為1,則表明Rs,v+dPr不存在于BF1或BF2中,Rs,v+dPr不是一條重復序列,此時需對Rs,v+dPr進行短串聯重復和疾病相關序列識別處理,d=0,1,2,…,,v+dPr≤ns-r,v=0,1,2,…,Pr-1,s=0,1,2,…,l-1。
通過并行地對短序列過濾去重,可避免對短序列的重復計算。若短序列不存在于布隆過濾器BF1或BF2,則需對短序列進行短串聯重復序列識別的處理。
1.1.2 短串聯重復序列并行識別
STR 也被稱作微衛星DNA,由1~6 個堿基的重復基序組成,約占人類基因組數據的3%[3]。短串聯重復序列的重復結構性質表明,通過合理分割短串聯重復序列,可以得到記錄短串聯重復序列基本重復單元的相同子段[14]。在借鑒文獻[14]思想的基礎上,本文使用Pr 個CPU 核心并行地識別高錯誤率長序列基因組數據中的短串聯重復序列。
并行識別短串聯重復序列的方法介紹如下。
首先,Pr 個CPU 核心并行分割短序列Rs,v+dPr為4 個長度均為w的短片段集合i=0,1,2,3,v=0,1,2,…,Pr-1,v+dPr≤ns-r,s=0,1,…,l-1。
為降低將非敏感序列誤識別為短串聯重復序列的概率,根據短串聯重復序列的結構特點,文獻[15]引入控制參數c_str 和皮爾遜相關系數(PCC,Pearson correlation coefficient)改進序列局部片段相似度的計算為
1.1.3 疾病相關序列并行識別
DRS 是指攜帶疾病易感基因的核苷酸序列[11]。不同于短串聯重復序列,疾病相關序列更多體現在位點上的變異,而非結構上的重復。為此,本文通過改進序列相似度計算模型,將待識別序列和第三方數據庫中疾病相關序列進行計算比對,以并行識別出高錯誤率長序列基因組數據中的疾病相關序列。
1) 并行構建敏感序列詞典
構建敏感序列詞典是為了降低大量短序列與第三方數據庫中疾病相關序列相似度計算的代價。本文使用二維數組 hostDict[0:m-1][0:4k+2]表示CPU 端構建包含m條序列的敏感序列詞典。
并行構建敏感序列詞典的方法介紹如下。
首先,Pr 個CPU 核心并行地從第三方數據庫提取每個疾病易感基因的染色體編號CHR_ID 和染色體位置CHR_POS,并使用pysam 工具[16]從人類參考基因組HG38 中提取m條長度為r的疾病相關序列Dv,i,i=0,1,2,…,m-1,v=0,1,2,…,Pr-1。
2) 疾病相關序列相似度并行計算
在判斷短序列Rs,j是否為疾病相關序列之前,本文已經對Rs,j進行過濾去重和短串聯重復序列識別。因此,僅需要對經上述步驟處理后剩余的g條序列進行疾病相關序列識別。將剩余的g條序列和敏感序列詞典hostDict[0:m-1][0:4k+2]中的m條序列進行相似度計算比對十分耗時。為此,本文采用多核CPU 和GPU 協同并行計算以加速疾病相關序列的識別,j=0,1,2,…,ns-r,s=0,1,2,…,l-1。
CUDA(computer unified device architecture)并行編程模型將GPU 線程層次結構抽象成線程塊網格Grid 和線程塊Block 兩層[17]。在CUDA 線程層次結構中,Block 和Grid 由uint3 類型定義的三維向量 blockIdx.x、blockIdx.y、blockIdx.z 和threadIdx.x、threadIdx.y、threadIdx.z 表示[17]。為準確定位識別疾病相關序列,本文采用一維線程塊網格和線程塊進行CUDA 線程索引。
其中,e=0,1,2,i=0,1,…,m-1,tID=0,1,…,g-1,s=0,1,…,l-1,dis_sim 為疾病相關序列相似度閾值。若sim(Di,Rs,tID)≥dis_sim,則序列Rs,tID是一條疾病相關序列,且它和敏感序列詞典中第i條序列Di具有很高的序列相似度。
1.1.4 生成掩碼核苷酸序列
1.2 并行算法描述與分析
設GWAS Catlog 數據庫中疾病相關序列數據集為disData(包含m組數據),HG 表示疾病相關序列并行識別步驟構建敏感序列詞典時所使用的參考基因組,并行算法使用的CPU 核心數為Pr,使用的GPU 線程數為Cu。
圖2 給出了CPU/GPU 并行算法CGPU-F3SR的處理流程。
圖2 中,res[0:ns-1]表示記錄每條短序列的敏感序列識別結果的輔助數組,且res[j]∈{0,1,2,3,4}分別表示原始短序列結果標記、BF1過濾標記、BF2過濾標記、短串聯重復序列標記和疾病相關序列標記,j=0,1,2,…,ns-1,s=0,1,2,…,l-1。hostRes[0:g-1]表示保存疾病相關序列的識別結果的輔助數組,其中,,I(res[j])=0 表示指示函數(條件成立則取值為1,否則取值為0)。strIndex[0:g-1]表示保存疾病相關序列識別的短序列索引的輔助數組。式(4)中,的求解需要做許多分支判斷。若使用GPU 計算,則將使部分GPU 線程處于長時間“計算等待”狀態,為均衡 GPU 端數據運算,本文引入輔助數組hostData[0:g-1][0:4k+2],并使用多核CPU 預編碼核苷酸序列和堿基含量統計,以簡化GPU 端數據運算,提升GPU 端的運行效率。
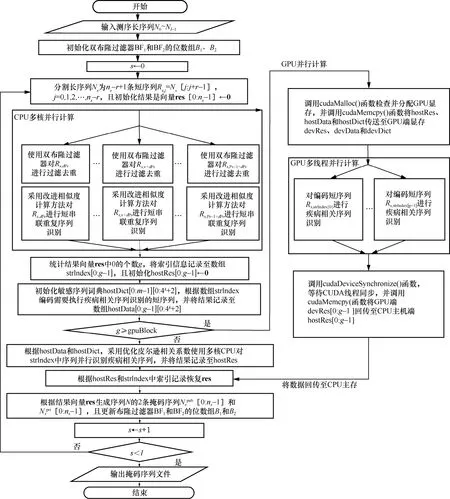
圖2 CPU/GPU 并行算法CGPU-F3SR 的處理流程
算法1 給出了CGPU-F3SR 的流程。
算法1 CGPU-F3SR




當CPU/GPU 并行算法CGPU-F3SR 中參數的gpuBlock 取值為0 時,它就變為僅采用多核CPU并行計算的版本(簡記為算法CPU-F3SR)。
2 實驗
實驗在廣西大學的Sugon 7000A 超級并行計算機上進行,使用CPU/GPU 異構計算節點。每個計算節點的內存容量為512 GB、外部存儲容量為8×900 GB、CPU 為2×Intel Xeon Gold 6230(總內核數為40)、GPU 為NVIDIA Tesla-T4(顯存容量為16 GB,含有2 560 個CUDA 核心)。運行操作系統為64 位版本CentOS7.4。采用C++、CUDA 和OpenMP 混合編程實現并行算法CGPU-F3SR。
實驗采用GWAS Catalog 數據庫[18]中全基因組關聯研究數據集gwas_catalog_v1.0.tsv構建敏感序列詞典,該數據集包含Scoliosis、HIV-1 replication 和Opioid sensitivity 等4 680 種疾病,共計216 250 組數據。采用的參考基因組為NCBI 數據庫[19]開放的人類基因組HG38。實驗所用的疾病易感基因來自GWAS Catalog 數據庫[18],短串聯重復序列來自TRDB 數據庫[20]。參考文獻[3]的數據預處理規則,預處理每條序列長度為50 bp 的基準數據序列集All-Together(2 239 340 條序列),每個基準數據集的非敏感序列和敏感序列數量之比為7:1。
為評估算法識別效果,需獲取不同長度且帶有敏感序列標簽的測序長序列。為此,實驗對錯誤率為2%~20%的All-Together 基準數序列集進行隨機抽樣,生成序列長度為100~400 kbp 的總規模約24 GB 的4 組長序列數據集DataSet-100 kbp~Data Set-400 kbp 用于并行算法參數調優測試。
實驗將本文CPU 和GPU 協同計算的并行算法CGPU-F3SR與并行算法PARA-LRF[11]、僅采用CPU并行計算的版本CPU-F3SR(gpuBlock=0)、串行算法F3SR[15]進行測試比較識別效果。實驗評估算法的識別準確率(acc,accuracy)[3]、查準率(pre,precision)[4]和假陽性率(fpr,false positive rate)[4]。準確率和查準率越高,算法識別效果越好;假陽性率越低,算法識別效果越好。在運行效率方面,實驗評估了算法的識別吞吐量(thp,throughput)[4]。吞吐量定義為算法單位時間識別脫氧核糖核苷酸的數量,單位為nt/s[3-4],吞吐量越高,算法運行效率越高。
下面,首先給出本文所提出的CPU/GPU 并行算法CGPU-F3SR 的參數調優實驗結果,然后給出消融實驗結果,最后給出算法CGPU-F3SR 和同類并行算法的實驗結果及分析。
2.1 并行算法參數調優實驗
參考文獻[3,4,15]給出的基因組數據敏感序列識別算法研究的相關實驗,算法CGPU-F3SR 選取pi=0.000 1、ti=108、r=48 bp、k=5、str_sim=0.64、dis_sim=0.80 進行算法部分參數的初始化,i=1,2。
為確定GPU 線程塊大小對并行算法吞吐量的影響,實驗測試了并行算法CGPU-F3SR 采用不同的GPU 線程塊大小在4 組長序列數據集上運行時的吞吐量,結果如圖3 所示。
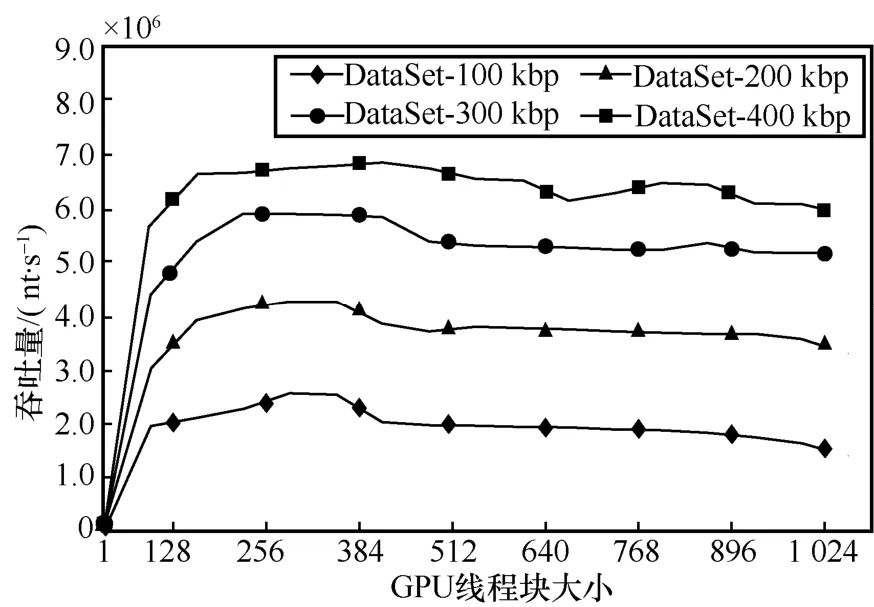
圖3 并行算法CGPU-F3SR 采用不同的GPU 線程塊大小在4 組長序列數據集上運行時的吞吐量
圖3 實驗結果表明,當GPU 線程塊大小固定時,序列數據集規模越大,并行算法CGPU-F3SR 的吞吐量越高。原因如下:1) 測序長序列數據集規模越大,CGPU-F3SR 分割長序列得到的短序列中的重復短序列越多,由于雙布隆過濾避免了重復短序列的多次運算,因此過濾效果明顯;2) CGPU-F3SR 將編碼后的短序列提交給GPU 進行疾病相關序列并行識別,測序數據集越大,GPU 線程平均計算處理的數據越多,算法的并行度越高。按照CUDA 并行模型,網格Grid中的各線程塊Block 會被分配到GPU 的各流式處理器中執行。圖3 的實驗結果還表明,當參數gpuBlock取值為128~384 時,算法整體上具有較高的吞吐量。
圖4 進一步給出了GPU 線程塊大小gpuBlock=256、使用不同 CPU 核心數運行并行算法CGPU-F3SR 時得到的吞吐量結果。
圖4 實驗結果表明,并行算法CGPU-F3SR 的識別吞吐量與使用的CPU 核心數呈正相關。數據集規模越大,序列越長,算法吞吐量受CPU 核心數增益效果越明顯。
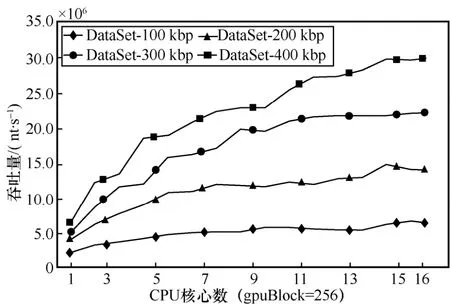
圖4 并行算法CGPU-F3SR 使用不同CPU 核心數在4 組長序列數據集上運行時的吞吐量
為使本文并行算法CGPU-F3SR 充分發揮CPU和GPU 協同并行計算的能力,根據圖3 和圖4 的實驗結果,本文選取gpuBlock=256 和Pr=4 的組合進行后續的實驗。
2.2 并行算法消融實驗
并行算法CGPU-F3SR 引入布隆過濾器對序列數據進行過濾,以免對分割短序列的重復計算。為了確定過濾機制對并行算法CGPU-F3SR 的性能影響,本文實驗評估了并行算法CGPU-F3SR 進行序列過濾With Filter(參數Pr=4,gpuBlock=256)和不進行序列過濾 Without Filter(參數 Pr=30,gpuBlock=256)2 種情形在4 組長序列數據集運行得到的識別準確率、查準率、假陽性率和吞吐量,實驗結果如表1 所示。
表1 的消融實驗結果表明,在識別性能方面,并行算法CGPU-F3SR 在With Filter 和Without Filter 這2 種情形下均獲得相同的識別準確率、查準率和假陽性率。這是因為:1) 布隆過濾器的多哈希映射機制可以對相同序列產生多個相同的哈希映射,這可以在避免對重復序列的多次計算的同時不影響其識別性能;2) 改進序列相似度計算模型能對含有錯誤信息的相似序列產生近似度量值,并行算法CGPU-F3SR 的識別準確率、查準率和假陽性率均取決于改進的序列相似度計算模型,而不是取決于布隆過濾器。在運行效率方面,算法使用4 個CPU核心的With Filter 模式的識別吞吐量比使用30 個CPU 核心的Without Filter 模式高了2 個數量級。這是因為長序列基因組數據中分割短序列具有大量相同的重復短序列,布隆過濾效果明顯。
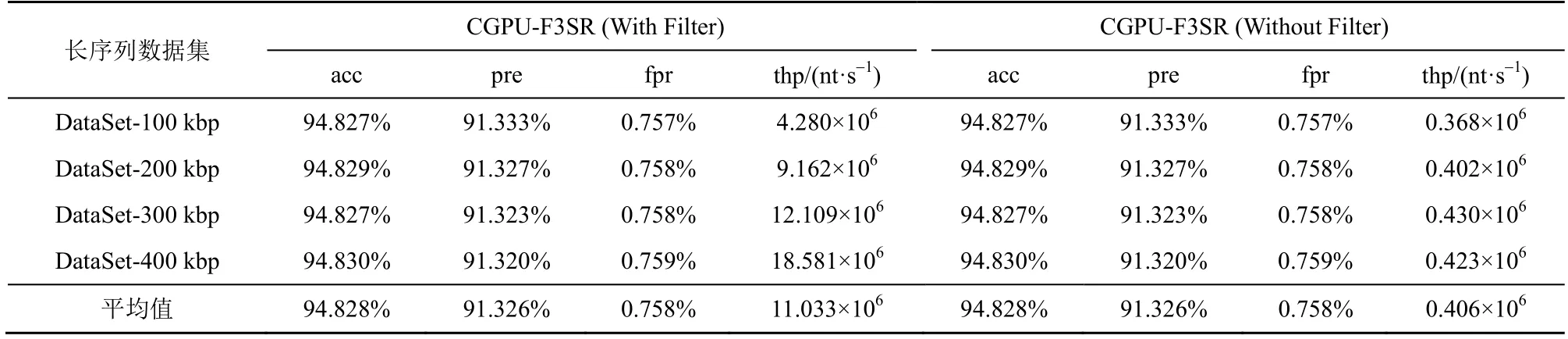
表1 并行算法CGPU-F3SR 的識別準確率、查準率、假陽性率和吞吐量
2.3 并行算法識別性能實驗
為評估算法的并行化對高錯誤率長序列基因數據中敏感序列(包括STR 和DRS)識別效果的影響,首先,實驗測試CPU 和GPU 協同并行算法CGPU-F3SR、僅CPU 并行的算法CPU-F3SR 和串行算法F3SR(參數取值pi=0.000 1,ti=104,r=48,k=5,dis_sim=0.80,str_sim=0.64,i=1,2)[15]在4 組長序列數據集上運行得到的識別準確率、查準率和假陽性率,實驗結果如表2 所示。
表2 的實驗結果表明,CPU 與GPU 協同并行算法CGPU-F3SR 和CPU 并行化算法CPU-F3SR 均獲得了與串行算法F3SR 相同的識別結果。這是因為長序列分割得到的相鄰短序列之間共享r-1 個高度重疊的堿基,通過CPU/GPU 并行計算不會影響算法的最終識別質量。在上述實驗的基礎上,進一步測試比較本文并行算法CGPU-F3SR 和同類并行算法PARA-LRF(參數p=0.02,m=68 915 861)[11]在DataSet-100 kbp~DataSet-400 kbp 數據集上運行時,對高錯誤率長序列基因組數據中敏感序列(包括STR 和DRS)進行識別獲得的識別準確率、查準率和假陽性率,實驗結果如表3 所示。
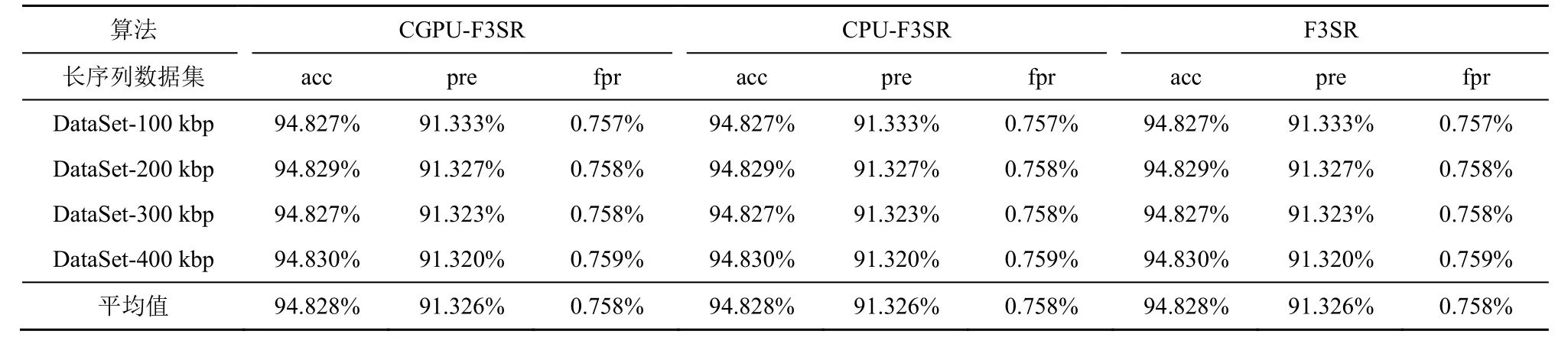
表2 并行算法CGPU-F3SR、CPU-F3SR 和F3SR 的識別準確率、查準率和假陽性率
表3 的實驗結果表明,相較于并行算法PARA-LRF,本文CPU/GPU 并行算法CGPU-F3SR整體上具有更高的識別準確率和查準率以及更低的識別假陽性率。這是因為并行算法CGPU-F3SR采用k-mer 編碼策略有效地提取了高錯誤率長序列中的堿基錯誤信息,且根據STR 和DRS 的結構特點,通過引入控制參數改進了STR 和DRS 相似度的計算方法,使本文并行算法CGPU-F3SR 在準確識別出高錯誤率長序列基因組數據中敏感序列的同時,降低了將非敏感序列誤判為敏感序列的情形的發生,從而整體上獲得更好的識別效果。
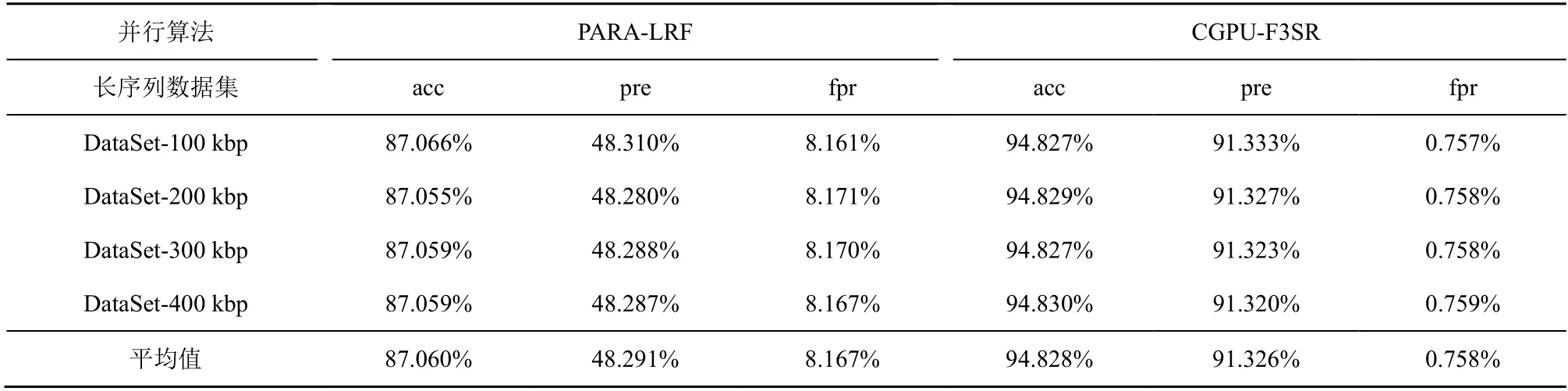
表3 并行算法CGPU-F3SR 和PARA-LRF 的識別準確率、查準率和假陽性率
2.4 并行算法運行效率實驗
在基因組數據敏感序列識別研究中,算法吞吐量和運行時間相關,多用于運行效率評估。基因組數據敏感序列識別并行算法相關研究較少,目前缺乏CPU 和 GPU 協同計算的并行算法。并行算法PARA-LRF[11]是基于多核CPU 設計的并行算法。為公平起見,實驗首先測試了本文僅多核CPU 并行算法CPU-F3SR和多核CPU并行算法PARA-LRF[11]使用不同CPU核心數在4組長序列數據集上運行得到的識別吞吐量,結果如圖5 所示。
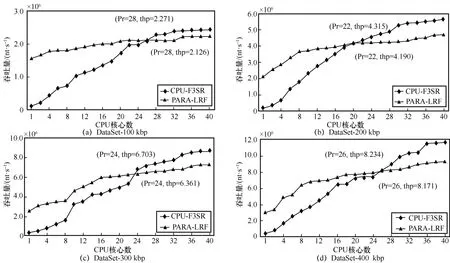
圖5 多核CPU 并行算法CPU-F3SR 和PARA-LRF 使用的CPU 核心數對吞吐量的影響
從圖5(a)可以看出,在DataSet-100 kbp 數據集上,當使用的CPU 核心數為1~28 時,CPU 并行算法PARA-LRF 的識別吞吐量高于本文CPU 并行算法CPU-F3SR;當使用的CPU 核心數為28~40時,并行算法CPU-F3SR 比PARA-LRF 獲得了整體上更高的識別吞吐量。
從圖5(b)~圖5(d)可以看出,對序列長度為200~400 kbp 的3 個長序列數據集,當CPU 核心數分別為22、24 和26 時,并行算法CPU-F3SR 達到吞吐量拐點,此時本文多核 CPU 并行算法CPU-F3SR 比多核CPU 并行算法PARA-LRF 整體上具有更高的識別吞吐量。這是因為并行算法CPU-F3SR 并行過濾去重分割得到的短序列、并行識別短串聯重復序列、并行識別疾病相關序列的部分占比高、算法并行度高,所以在4 組長序列數據集上運行時獲得了更高的識別吞吐量。
從長序列基因組數據中識別疾病相關序列的過程是一個計算密集型工作,為進一步加速求解敏感序列識別問題,本文設計實現了CPU 和GPU 協同計算的敏感序列識別并行算法CGPU-F3SR。為此,實驗也測試了 CPU/GPU 并行算法CGPU-F3SR(參數Pr=4、gpuBlock=256)、多核CPU并行算法PARA-LRF(參數p=0.02、m=68 915 861、Pr=4)[11]、多核CPU 并行算法CPU-F3SR(參數Pr=4)在4 組長序列數據集上運行得到的識別吞吐量,結果如表4 所示。
從表4 可以看出,相較于本文僅采用多核CPU并行加速的CPU-F3SR 算法,本文的CPU 和GPU協同并行求解敏感序列識別問題的CGPU-F3SR 算法平均吞吐量高達11.033×106nt/s,極大提升了識別吞吐量;相較于已有的多核 CPU 并行算法PARA-LRF,本文算法CGPU-F3SR 在吞吐量方面也具有較大幅度的提升。CGPU-F3SR 算法的平均吞吐量分別是CPU-F3SR 和PARA-LRF 算法的11.45 倍和2.44 倍。CGPU-F3SR 算法之所以獲得更高的吞吐量,是因為它采用GPU 并行加速處理屬于計算密集型的疾病相關序列識別過程,加速效果顯著。
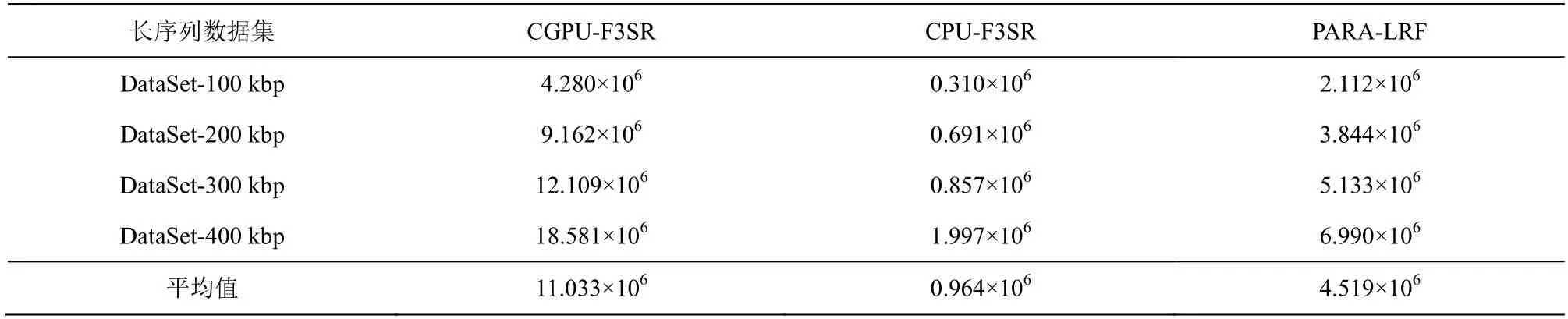
表4 并行算法CGPU-F3SR、CPU-F3SR 和PARA-LRF 的識別吞吐量
綜上所述,CPU 和GPU 協同計算的并行算法CGPU-F3SR 在準確識別出大規模高錯誤率長序列基因組數據中的2 類敏感序列(STR 和DRS)的同時,顯著提升了吞吐量。
3 結束語
第三代測序技術產生的基因組測序數據正以超摩爾定律的速度顯著增長。隨著人們生物信息安全意識的逐漸增強,保護個體基因組數據敏感序列變得越來越重要。本文提出的CPU 和GPU 協同計算識別的并行算法CGPU-F3SR 的特色和優勢是高效準確地識別出第三代測序技術產生的大規模的高錯誤率長序列基因組數據中的2 類敏感序列(短串聯重復序列和疾病相關序列)。在長度為100~400 kbp 的長序列數據集上的實驗結果表明,并行算法CGPU-F3SR 在整體上獲得了較高的識別準確率、查準率和較低假陽性率的同時,顯著提升了識別吞吐量。
近些年來,學者研究發現基因組測序數據中還存在“均聚物”錯誤。考慮到基因組數據錯誤類型復雜、數據規模巨大、數據敏感的特點,在本文研究工作基礎上,下一步的研究方向將包括:1) 研究設計能準確識別出“均聚物”錯誤的敏感序列識別算法;2) 探索設計新的數據索引結構或借鑒其他索引數據結構(如簡潔de Bruign圖結構、FM-index 結構等),研究設計在CPU/GPU 混合體系結構集群上實現的并行算法,以進一步加速求解超大規模超長序列的基因組數據敏感序列識別問題;3)研究如何將本文提出的敏感序列識別并行算法與安全比對算法進行級聯,以實現大規模的高錯誤率長序列基因組數據的安全比對。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
