面向下一代移動通信的高效率超寬帶線性化技術(shù)的研究
2023-03-20 03:22:53黃健安郭新郝建豹胡光雄
電子產(chǎn)品世界 2023年12期
黃健安 郭新 郝建豹 胡光雄


關(guān)鍵詞:下一代移動通信;數(shù)字預(yù)失真;非線性濾波模型;現(xiàn)場可編程門陣列
0引言
當(dāng)前移動通信網(wǎng)絡(luò)中,數(shù)據(jù)量呈指數(shù)式增長。為適應(yīng)這個趨勢,移動通信網(wǎng)絡(luò)迫切需要進(jìn)一步優(yōu)化和升級,向多載波及多輸入多輸出(multiple-input multiple-output,MIMO)技術(shù)演進(jìn)。在網(wǎng)絡(luò)建設(shè)中,射頻功率放大器(簡稱“功放”)作為一個核心部件,對上述目標(biāo)達(dá)成起著至關(guān)重要的作用。
下一代移動通信信號的寬頻帶和高峰均比給射頻功率放大器提出了更高的要求。為了達(dá)到更高的效率,通常讓功放在飽和區(qū)工作,但是在超寬帶信號下,功放會有記憶效應(yīng)且信號易失真,對通信質(zhì)量產(chǎn)生影響。由于功放的效率和線性度是矛盾的,既要保證功放的效率,又要使其具有盡可能高的線性度,是研究人員要實現(xiàn)的復(fù)雜平衡。
目前,改善功放線性度較理想的方法是數(shù)字預(yù)失真(digital pre-distortion,DPD)技術(shù),其具有性能良好、實現(xiàn)靈活、一致性好的特點。但是,數(shù)字預(yù)失真系統(tǒng)能夠處理的信號帶寬也受到反饋回路中模數(shù)轉(zhuǎn)換器(analog to digital converter,ADC)的速率和位數(shù)限制,同時為了實時更新功放模型參數(shù),需要消耗大量高速運算和存儲資源,從而增大系統(tǒng)功耗。
針對目前超寬帶高線性通信技術(shù)存在的問題,本研究提供一種帶限函數(shù)自適應(yīng)數(shù)字預(yù)失真算法,可克服ADC的速率和位數(shù)限制,并不需要增強(qiáng)數(shù)字信號處理器件的性能。
1系統(tǒng)硬件設(shè)計
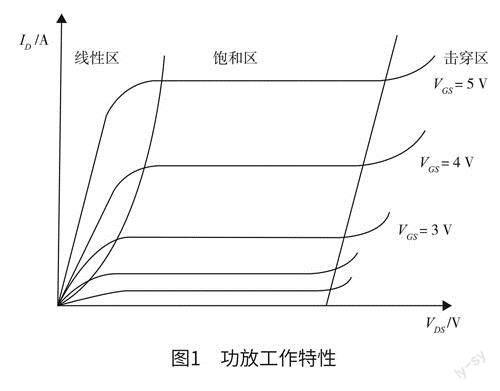
根據(jù)功放原理,目前主流的橫向雙擴(kuò)散金屬一氧化物一半導(dǎo)體場效應(yīng)管(lateral double-diffusedMOSFET,LDMOS)功放的典型工作特性如圖1所示。
當(dāng)功放在線性區(qū)時,表現(xiàn)為很好的線性度,不過由于效率太低,會對無線通信基站造成巨大的能量浪費和設(shè)備發(fā)熱問題。因此,功率回退的方法無法廣泛應(yīng)用于射頻功放線性化場合。
預(yù)失真技術(shù),即預(yù)先在射頻功放模塊前插入一個與射頻功放工作特性相反的預(yù)失真單元,把理想的原信號經(jīng)過預(yù)先處理變成設(shè)定的預(yù)失真信號,這時射頻功放的輸入就換成了新的預(yù)失真信號,從而提高了功放線性度。具體的實現(xiàn)原理圖如圖2所示。模擬預(yù)失真因為電路簡單得到了廣泛使用,然而模擬預(yù)失真通常只適用于雙音信號或較窄帶的信號,不適用于寬帶的信號。
數(shù)字預(yù)失真是一種把射頻功率放大器輸出信號通過下變頻混頻電路變至基帶后,與射頻功放的輸入信號產(chǎn)生射頻功率放大器的逆模型。功放的逆模型參數(shù)存儲在現(xiàn)場可編程門陣列(field-programmable gate array,F(xiàn)PGA)等芯片中。基于查找表(LUT)技術(shù)的數(shù)字預(yù)失真方法是數(shù)字信號處理(digital signal processrng,DSP)芯片依據(jù)輸入信號的特性調(diào)用相應(yīng)的表項參數(shù)進(jìn)行數(shù)字預(yù)失真。數(shù)字預(yù)失真結(jié)構(gòu)原理框圖如圖3所示,D/A為數(shù)字信號轉(zhuǎn)換成模擬信號;A/D是模擬信號轉(zhuǎn)換成數(shù)字信號。
本文設(shè)計一種基于數(shù)字預(yù)失真硬件平臺的算法,其硬件原理框圖如圖4所示。
2系統(tǒng)軟件設(shè)計
本文提出一種軟件設(shè)計方法,在數(shù)字預(yù)失真硬件平臺中運行,解決了大功率射頻功放應(yīng)用中遇到的效率和線性度矛盾問題。
在非線性系統(tǒng)分析中,冪級數(shù)是一種最基本的分析方法,適用于無記憶的弱非線性系統(tǒng);諧波平衡法適用于大信號激勵的強(qiáng)非線性系統(tǒng)。沃爾泰拉(Volterra)級數(shù)是一種更高級的分析方法,是泰勒(Taylor)級數(shù)的推廣。它在系統(tǒng)識別領(lǐng)域有廣泛的應(yīng)用。
帶寬的增加不僅會導(dǎo)致很強(qiáng)的記憶效應(yīng),而且對ADC的要求也會更高。如果輸入信號帶寬為80 MHz,5階模型對應(yīng)的帶寬就是400 MHz,根據(jù)奈奎斯特(Nyquist)采樣定理,則ADC采樣速率需要達(dá)到800 MSa/s,這無疑對ADC提出了極高的要求。而帶限函數(shù)自適應(yīng)數(shù)字預(yù)失真(簡稱“帶限數(shù)字預(yù)失真”)技術(shù)只需關(guān)注載帶和鄰帶信號,即專注優(yōu)化鄰道的功率泄漏,而無須對整體頻譜進(jìn)行優(yōu)化。這就大大降低了對ADC性能的需求。帶限數(shù)字預(yù)失真結(jié)構(gòu)如圖5所示,DAC為數(shù)字模擬轉(zhuǎn)換器;IQ信號又稱同向正交信號,是連續(xù)信號在二維直角坐標(biāo)系中的映射,通常用于基帶信號的轉(zhuǎn)換和重建,其中,I為同相(in-phase),Q為正交(quadrature),與I的相位相差90°; RF為射頻信號(radio frequency)。
由于功放的輸出信號在數(shù)學(xué)上可表達(dá)為由低到高的非線性分量相加,本文根據(jù)不同帶寬的信號非線性分量設(shè)計階數(shù)不同的非線性多項式。實驗表明,模型的非線性階數(shù)越接近對應(yīng)頻譜擴(kuò)展的帶寬,建模的精度就越接近理想值。Volterra級數(shù)帶限函數(shù)模型如圖6所示,x(n)為輸入信號,y(n)為輸出信號,y(n)為經(jīng)過低通濾波器(FIR LPF)后的輸出信號,n為Volterra級數(shù)的階數(shù),D1、D3、D5分別為Volterra級數(shù)模型中的一階、三階、五階分量,h1、h3、h5分別為對應(yīng)的一階、三階、五階Volterra核系數(shù)。
本文通過將帶限函數(shù)加入模型,既能使建模的精度滿足數(shù)字預(yù)失真的需要,又能減少模型誤差;不但使模型帶寬得以控制,而且又能維持Volterra級數(shù)的階數(shù)。
(1)在同等的性能條件下,與傳統(tǒng)的帶限記憶多項式模型相比,浮點運算數(shù)目和模型系數(shù)數(shù)目分別下降了約48%和28%。
(2)采用自適應(yīng)的算法求解小數(shù)時延,可解決帶限數(shù)字預(yù)失真系統(tǒng)中的環(huán)路延時問題,提高算法估計的精度,并且采用自適應(yīng)的估算算法,具有一定的工程實現(xiàn)參考價值。
(3)實驗結(jié)果表明,輸出信號的相鄰信道功率比(adjacent channel power ratio,ACPR)改善了27dBc,誤差向量幅度(error vector magnitude.EVM)改善了3%,并且對超出模擬濾波器帶寬外的頻譜也有一定的線性化能力。
本文基于時域信號,設(shè)計模型控制濾波器的帶寬來改變帶限表達(dá)式的帶寬。設(shè)計的模型較好地擬合了輸入信號與輸出信號間的工作特性,并具有很高的建模精度,而無須考慮功放輸出帶限信號的帶寬。如式(1)所示,NMSE為歸一化后的平均絕對誤差,通過控制階數(shù)不變,調(diào)整濾波器帶寬,可將誤差控制在0.682以內(nèi)。
3結(jié)語與展望
本文提出的方案通過設(shè)置預(yù)失真模塊,并優(yōu)化時序分析處理算法,可避免設(shè)備過熱的問題,并解決功放在超寬帶范圍內(nèi)線性差的問題,提高了功放效率。
隨著SG時代的到來,SG基站、智能移動終端及物聯(lián)網(wǎng)(IoT)終端射頻功率放大器應(yīng)用已十分普遍,并且迎來高速發(fā)展。據(jù)統(tǒng)計,智能移動終端射頻功放市場規(guī)模從2017年的50億美元增長到2023年的70億美元,高端長期演進(jìn)技術(shù)(LTE)功率放大器市場的增長,使其在高頻和超高頻領(lǐng)域有更廣闊的發(fā)展空間。本文提出的方案可直接應(yīng)用在射頻功率放大器的生產(chǎn)當(dāng)中,將帶來較大的經(jīng)濟(jì)效益。
