基于通道和空間注意力的機場道面地下目標自動檢測
2023-03-24 13:25:42李海豐張凡樸敏楠王懷超李南莎桂仲成
計算機應用 2023年3期
李海豐,張凡,樸敏楠*,王懷超,李南莎,桂仲成
(1.中國民航大學 計算機科學與技術學院,天津 300300;2.成都圭目機器人有限公司,成都 610101)
0 引言
機場道面地下目標主要包含兩類[1]:1)地下病害,隨著航空業務量的發展,飛機頻繁起降會對機場道面地下的結構造成損傷,長期超負荷地使用容易破壞內部結構;2)機場道面地下組成部分,如鋼筋和地燈等目標。隱蔽的地下病害可能會造成重大交通事故,帶來巨大的損失;而鋼筋是支撐機場道面的重要部件,會影響機場道面的安全性評估。因此對地下目標的檢測是保障機場安全運行的必要工作。
目前檢測機場道面地下目標的物理方法有鉆芯取樣法[2]、彎沉儀法[3]和超聲探測法[4]。鉆芯取樣雖然能直觀地看到樣塊內部的結構情況,但是該方法對機場道面有損害,采樣塊的數量有限,很難代表整個機場道面地下的內部情況,檢測精度不高。彎沉儀只能檢測出靠近地表層的脫空病害,且一般用于檢驗機場道面的承受能力。超聲波檢測技術可以根據聲波的傳播時間、幅值和頻率等參數確定地下目標的位置,但是該方法特別容易受到外界因素的干擾。而探地雷達(Ground Penetrating Radar,GPR)是一種無損檢測地下目標的技術,具有檢測速度快、分辨率高、覆蓋面積廣等特點,在工程勘探領域應用廣泛[5]。
有學者通過雷達信號對機場道面地下目標進行研究。曹蕓茜等[6]利用波變換和時延估計搜索局部峰值,抑制地下鋼筋的強反射回波,并結合時頻分析及最小距離分類器識別地下目標,通過頻域波數域的波場逆推進行目標成像。何煒琨等[7]利用脫空病害的回波特性,將回波作S 變換,擬合出脫空的波形特征。Zou等[8]使用多基地雷達系統掃描機場瀝青道面,利用橫波特性檢測淺層道面的層間剝離。也有學者通過雷達B-scan 圖進行研究,Pham等[9]采用二維Faster RCNN(Faster Region-based Convolutional Neural Network)提取灰度B-scan 圖像的雙曲線特征,對地下鋼筋進行檢測。李海豐等[10]采用支持向量機(Support Vector Machine,SVM),并設定雙閾值對B-scan 圖進行目標分割。Dinh等[11]結合傳統圖像處理和卷積神經網絡(Convolutional Neural Network,CNN),在B-scan 上通過校正零偏、濾波和閾值分割等預處理操作確定地下目標的范圍,再將提取到的目標區域送入CNN進行特征學習。在其他領域,與雷達C-scan 數據相似的有計算機斷層掃描(Computed Tomography,CT)數據和視頻數據,Cai等[12]設計了Ghost-Light-3DNet 對心臟CT 數據集進行檢測。Xu等[13]設計了三維Faster R-CNN 在CT 數據集上生成三維建議框,并對多類別目標進行三維可視化。Al-Hammadi等[14]將一段視頻拆分為32 幀連續圖像,使用三維CNN 從連續的圖像中學習手勢特征。
基于雷達信號的研究需要經過大量的預處理操作,計算量大且容易增加誤差。而僅基于B-scan 圖的研究雖然能避開冗雜的電磁波特性,但是忽略了相鄰B-scan 間存在一定的特征關聯關系,導致特征信息丟失。機場道面地下結構復雜多樣,生成的B-scan 和C-scan 往往包含大量噪聲,給地下目標檢測帶來了挑戰。針對以上問題,本文提出一種三維通道和空間注意力的UNet(Three-Dimensional Channel and Spatial Attention UNet,3D-CSA-UNet)模型,并應用于機場道面地下目標檢測。
本文研究的問題是機場道面地下目標檢測,主要的工作如下:1)設計三維通道和空間注意力并行模塊(Three-Dimensional Channel and Spatial parallel attention Block,3DCS-Block)以充分提取相鄰B-scan 間的聯合特征,在保證地下目標信息完整性的同時,對背景和目標進行區分;2)根據3D-CS-Block 設計多尺度的三維分割模型,將模塊加入多個編碼器和解碼器中組合成模型,加強模型對雷達C-scan 中地下目標特征提取的能力。
1 本文模型設計
1.1 探地雷達數據
探地雷達在機場道面水平移動,通過天線向地下發射電磁波,當遇到不同電磁特性的物體時會發生反射,天線接收回波信號。A-scan、B-scan 和C-scan 是探地雷達從一維到三維的數據保存形式。如圖1 所示:A-scan 記錄單組發射波和回波的信號強度和行進時間;探地雷達在不同位置會產生一系列A-scan,多個A-scan 形成二維B-scan 數據,如果將信號表示為灰度值,就能得到二維圖像[15];將B-scan 按照雷達通道順序進行組合,可形成三維C-scan 數據。

圖1 探地雷達數據Fig.1 Ground penetrating radar data
機場道面地下情況復雜多樣,探地雷達在探測地下目標時受到測量噪聲以及未知異物的干擾,導致生成B-scan 時目標區域不明顯且背景紊亂,給地下目標檢測帶來了挑戰。本文要檢測的地下目標為脫空、鋼筋和鋼筋平行,它們的特征形態在B-scan 上如圖2 所示。圖2(a)為脫空病害,一般位于地下結構的分層處,多呈現為黑白條紋疊加的形狀,黑白分明且橫向長度較長;圖2(b)為鋼筋,具有明顯的雙曲線特征,黑白雙曲線疊加,當多條鋼筋在地下并排時,會出現一排連續的雙曲線;圖2(c)為鋼筋平行,它由于探地雷達在道面的運行方向與鋼筋放置方向互相平行造成,特征一般為小塊狀且黑白相間,橫向長度較短。
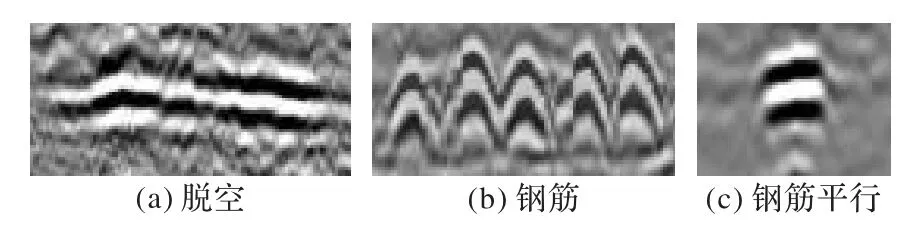
圖2 地下目標的形態特征Fig.2 Morphological characteristics of underground targets
1.2 三維通道和空間注意力并行模塊
經過預處理后的探地雷達數據往往包含了大量噪聲且背景十分復雜。為了抑制C-scan 中噪聲的干擾,引導模型更好地從三維C-scan 中提取出目標特征,本文設計了三維通道和空間注意力并行模塊(3D-CS-Block),主要由三維通道注意力和三維空間注意力組成,模塊結構如圖3 所示。兩種注意力對同一個三維特征矩陣集合進行特征提取,各自生成新的特征矩陣集合,再將兩個新的特征矩陣集合相加得到最終的特征矩陣集合。三維通道注意力給不同通道的三維特征矩陣賦予不同的權重值,讓模型在訓練過程中更加關注有用通道的特征信息;三維空間注意力對每個三維特征矩陣中的像素位置賦予不同的權重值,目的是區分地下目標和背景,讓模型著重關注目標的特征信息。為了從多維度引導模型學習地下目標的特征,將兩種注意力的結果進行求和,從而提高模型的目標檢測能力。

圖3 3D-CS-Block結構Fig.3 Structure of 3D-CS-Block
1.2.1 三維通道注意力模塊
模型訓練過程中,通過卷積操作產生多個通道的特征矩陣,這些特征矩陣包含了豐富的特征信息。但是由于C-scan本身含有大量噪聲,導致生成的矩陣也含有很多噪聲信息,而且不同通道的特征矩陣對地下目標的表現程度有差異,并不是所有的特征矩陣都能很好地表達目標特征[16]。如果考慮所有通道的特征矩陣,反而會增大背景和噪聲的影響,不利于模型的訓練。因此,本文加入三維通道注意力,賦予每個通道不同的權重值,讓模型有側重地學習目標信息明顯的通道特征以提高訓練效率。
如圖3 所示,三維通道注意力由一個全局池化、兩個全連接層、一個線性修正單元(Rectified Linear Unit,ReLU)激活函數和一個Sigmoid 激活函數組成。全局池化采用平均池化,它的作用是將每個特征矩陣在空間上進行壓縮,而全連接層和激活函數則給不同通道的特征矩陣賦予不同權重值。對于輸入特征 集合U={U1,U2,…,Up,…,Uc},Up∈RD×H×W代表某個維度為(D,H,W)的特征矩陣。特征集合U首先經過全局池化層變為Zc×1×1×1,即壓縮每個通道的空間特征:
輸入特征集合U被壓縮空間后變為Zc×1×1×1,再經過兩個全連接層和激活函數變為Z*,如式(2)所示:
1.2.2 三維空間注意力模塊
機場道面地下環境復雜,探地雷達在生成B-scan 時,往往包含了大量噪聲,且背景也比較紊亂。而C-scan 由B-scan組成,雖然C-scan 能有效還原地下目標的三維特征,但是也增加了噪聲的干擾,模型很難從C-scan 中提取出有效的目標特征。雷達C-scan 數據具有三維空間特性,一個C-scan 中可能包含一個或多個地下目標,相鄰的B-scan 具有一定的特征關聯,而一般的空間注意力并不能滿足對C-scan 的檢測要求。因此,本文加入特殊的三維空間注意力,給C-scan 中不同像素位置賦予不同的權重值。對于地下目標區域,權重值較大,而對于背景和噪聲,權重值則較小。這是為了讓模型自動區分出地下目標,從而抑制噪聲的影響。
如圖3 所示,三維空間注意力由一個三維卷積核和Sigmoid 激活函數組成。三維卷積核的輸出通道和步長都為1,它的作用是將輸入特征集合在通道上進行壓縮,而Sigmoid 激活函數則給空間中的每個位置賦予不同的權重值。輸入特 征矩陣U=[U1,1,1,U1,1,2,…,Ui,j,k,…,UD,H,W],Ui,j,k∈R1×1×1×c,(i,j,k)為該像 素在三 維矩陣 空間的位置。特征矩陣U經過一次三維卷積得到Q∈RD×H×W,如式(4)所示,其中:WConv3d∈R1×1×1×c×1為三維卷積核的權重。特征矩陣Q經過一個Sigmoid 激活函數將權重值歸一化到[0,1],歸一化后的特征矩陣再和原始的特征矩陣U相乘,得到新的特征矩陣UsSE,如式(5)所示。
1.3 基于通道和空間注意力的分割模型
1.3.1 3D-CSA-UNet
一個尺度下的特征集合包含的特征信息較少,且具有局限性。為了提升3D-CS-Block 對復雜三維C-scan 目標特征的提取能力,本文參考UNet 模型[17]和SSD(Single Shot Multibox Detector)模型[18],設計了多尺度的三維分割模型3D-CSAUNet。3D-CSA-UNet 可以提取出多個尺度下的C-scan 特征信息,控制不同大小的感受野,學習地下目標的全局信息和局部信息,以增強提取目標特征的能力,從而實現地下目標精確檢測。
如圖4 所示,3D-CSA-UNet 由4 個編碼器(Encoder)、4 個解碼器(Decoder)和1 個三維卷積核組成。每個編碼器由三維卷積核(Conv3d)、注意力并行模塊(3D-CS-Block)和下采樣(Maxpool+ReLU)組成;每個解碼器由反卷積(Deconv3d)、注意力并行模塊和上采樣(Upsample+ReLU)組成。

圖4 3D-CSA-UNet結構Fig.4 Structure of 3D-CSA-UNet
編碼器Encoder 1、2 可以提取C-scan 的淺層特征,而編碼器Encoder 3、4,則能夠提取C-scan 的深層特征,解碼器Decoder 1~4 負責對不同尺度的特征進行特征還原。Encoder 1、2 和Decoder 2、3 的特征矩陣進行相加融合,能夠提供地下目標類別信息。Encoder 3 和Decoder 1 的特征矩陣進行相加融合,能夠提供地下目標位置信息。線性融合編碼器和解碼器中相同尺寸的特征信息,可以抑制噪聲,增強模型對目標的關注。最后通過一個三維卷積生成通道與類別數目相同的特征集合,便于后續分類識別。
1.3.2 多尺度特征損失計算
在多次卷積和下采樣后,一些小目標區域的信息會丟失,如果只關注模型最終的輸出特征,而忽略模型中間層輸出特征的影響,會降低模型檢測的準確率。針對該問題,本文計算4 種尺度下的特征矩陣損失值,并且對不同尺度的損失賦予不同權重,再將所有損失求和得到最終損失。如圖4所示,Encoder 1 和Decoder 3 的輸出特征大小為32× 24×224× 224,Encoder 2 和Decoder 2 的輸出 特征大小為64×12× 112× 112,Encoder 3 和Decoder 1 的輸出 特征大小為128× 6× 56× 56,模型的 最終輸 出特征 大小為4× 48×448× 448,將以上4 種大小的特征矩陣分別標記為a、b、c和d。式(6)~(7)為計算模型損失的公式:
式(6)為交叉熵損失函數,其中:N為特征通道數;M為類別數;yic取0 或者1,當樣本i的真實類別為c取1,否則取0;pic為樣本i屬于類別c的預測概率。式(7)是總的損失值,最后輸出的特征權重為1,其他尺度的特征權重為0.1。
2 實驗與結果分析
2.1 實驗設置
2.1.1 對比方法
將3D-CSA-UNet 與3D-SegNe[t19]、三維全卷積網絡(3DFully Convolutional Network,3D-FCN)[20]和3D-UNet[21]進行對比實驗。3D-SegNet 與SegNet 結構一 致,3D-FCN 與FCN(Fully Convolutional Network)結構一致,3D-UNet 與UNet 結構一致,它們的區別在于前者使用了三維卷積核且輸入數據的維度更高。3D-SegNet 的每個編碼器都對應一個解碼器,最終編碼器的輸出會被送入Softmax 分類器進行像素級分類。3D-FCN 是典型的全卷積模型,且目標分割能力較強。3DUNet 也是經典的語義分割網絡,結合多尺度特征實現目標精確分割。
2.1.2 數據集
本文使用的數據集為AUD(Airport Underground Data),包含的地下目標有脫空、鋼筋和鋼筋平行。數據集由成都圭目機器人有限公司提供,采集于國內多個機場道面。該公司自主研發的道路病害檢測機器人,搭載2D、3D 視覺融合系統以及不同頻段的三維探地雷達,采集道面內部結構信息。機器人以20~30 km/h 的速度水平運行,探地雷達不斷收發電磁波,成功收發一次電磁波稱為一個A-scan,多個A-scan 經過編碼得到B-scan,相鄰B-scan 按照雷達通道順序組合形成C-scan。表1 為AUD 數據集的具體信息。

表1 AUD數據集詳細信息Tab.1 Details for AUD dataset
2.1.3 評價指標
為了對3D-CSA-UNet 模型進行量化評估,采用運行時間、準確率(Precision,P)、召回率(Recall,R)、F1 分值(F1-Score,F1)對實驗結果進行分析。運行時間指平均檢測一個C-scan 所需時間;準確率指目標區域被正確檢測出來的像素個數占被檢測出來的像素總數的比例;召回率指目標區域被正確檢測出來的像素個數占應該被準確檢測出來的目標區域像素個數的比例;F 對準確率和召回率進行綜合評價。指標公式定義如下:
其中:TP(True Positive)為地下目標區域被正確檢測出來的像素個數;FP(False Positive)為背景區域被預測為地下目標的像素個數;FN(False Negative)為地下目標區域被預測為背景的像素的個數;TN(True Negative)為背景區域被正確檢測出來的像素個數。
2.1.4 實現細節
本文所有模型均使用Pytorch 框架進行搭建,編程語言為Python,使用Geforce RTX 2080ti 顯卡進行模型訓練和測試。模型的學習率設置為0.000 1,采用Adam 優化器。
本文用于訓練的B-scan 數量為1 722 個,為了增加訓練樣本量,設定模型輸入的C-scan 大小為48× 448× 448。但是有些地下目標只橫跨8 個或者16 個B-scan,因此需將它們進行堆疊,合成到48 個。合成后用于訓練的C-scan 數量一共150 個(相當于7 200 個B-scan),數據量本身較大,所以模型的batch_size 設置為1 也能保證模型能夠充分訓練。使用交叉熵損失函數,即Cross-Entropy Loss。
2.2 實驗結果與分析
所有模型在相同的實驗環境下進行測試,數據集都采用AUD 數據集。每個模型都訓練至擬合狀態,且都采用測試效果最好的模型權重進行對比,表2 為4 個模型在測試集上的量化結果。實驗結果表明,3D-CSA-UNet 對地下目標檢測的各指標都取得了最優和次優結果。相較于對比算法,3DCSA-UNet 對于脫空、鋼筋和鋼筋平行目標預測的平均F1 至少提高12.33、9.05、11.05 個百分點。

表2 多個模型的量化結果 單位:%Tab.2 Quantified results of multiple models unit:%
圖5 展示了4 種模型檢測的可視化結果,實驗結果表明,其他3 種模型容易受到噪聲和背景的影響,提取的目標特征也不清晰。而3D-CSA-UNet 模型由于加入通道和空間注意力并行模塊,可以有效抑制噪聲的干擾,增強模型對地下目標的關注。從雷達C-scan 中提取的多尺度的特征,也使分割效果更加細膩,輪廓更加明顯,有利于提升檢測精度。

圖5 不同模型的可視化結果對比Fig.5 Comparison of visualization results of different models
在運行時間上,各模型的檢測速度都非常快。表3 展示了各模型平均檢測一個C-scan 所需時間,各模型的檢測速度相差都不大。3D-CSA-UNet 檢測一個C-scan 需要0.24 s,而一個C-scan 由48 個B-scan 組成,因此檢測一個B-scan 平均只需要0.005 s,可以較好地滿足工程實際需求。

表3 各模型平均檢測一個C-scan所需時間 單位:s Tab.3 Average time for each model to detect a C-scan unit:s
2.3 消融實驗
為了分別驗證通道注意力和空間注意力對模型檢測的影響,設置了三組實驗,檢測的目標如圖2 所示。針對3D-CSA-UNet 模型,實驗A 為編碼器和解碼器都不加入兩種注意力;實驗B 為編碼器和解碼器都只加入通道注意力;實驗C 為編碼器和解碼器都只加入空間注意力。
從表4 中的實驗A~C 的量化結果可以看出,在實驗A 的模型中加入通道注意力或者空間注意力,各項指標都有明顯提升。相較于實驗A 的模型,當只加入通道注意力時,實驗B 的模型對鋼筋平行檢測的召回率提高了6.84 個百分點,有效減少了鋼筋平行的漏檢情況;當只加入空間注意力時,實驗C 的模型對脫空檢測的準確率提高了8.17 個百分點,有效提高了脫空檢測的準確率。從圖6 中展示的實驗A~C 的可視化效果可以看出:通道注意力和空間注意力均能抑制背景和噪聲對目標的干擾,能提高模型對鋼筋平行的檢出率。實驗B 和實驗C 的可視化效果表明,通道注意力的去噪能力比空間注意力強,而空間注意力對目標特征的學習能力更強,甚至能夠提取出目標的邊緣輪廓特征。因此,本文設計了三維通道和空間注意力并行模塊(3D-CS-Block),充分利用兩種注意力各自的優勢,幫助模型更好地檢測地下目標。
為了進一步驗證3D-CS-Block 的有效性,設置實驗D 只在編碼器部分加入3D-CS-Block;實驗E 只在解碼器部分加入3D-CS-Block;實驗F 中編碼器和解碼器都加入3D-CSBlock,即本文模型。
從表4 中實驗A 和實驗D、E、F 的量化結果可以看出:如果只在編碼器后加入3D-CS-Block,對3 類地下目標檢測的各項指標都有明顯提升。如果只在解碼器后加入3D-CSBlock,雖然F1 提升較小,但是對于脫空病害檢測的召回率下降很多,說明脫空的漏檢數量增加了。實驗D 的模型的F1優于實驗E,說明在編碼器后加入3D-CS-Block 比在解碼器后加入效果更佳。如果編碼器和解碼器后都加入3D-CSBlock,對鋼筋和鋼筋平行兩類目標的檢測指標都有明顯提高,而且檢測脫空病害的召回率也是最高,有效減少了脫空病害漏檢的數目。從圖6 中的實驗A、D、E、F 的部分可視化效果可以看出:實驗A 的模型沒有加入3D-CS-Block,容易受到噪聲的影響,將一些背景區域也會識別為地下目標,且對于鋼筋平行的檢測效果不好。實驗D 和E 的可視化效果表明,在編碼器后加入3D-CS-Block 比在解碼器后加入3D-CSBlock,能更好地學習目標的輪廓特征,有助于提升模型檢測精度。由實驗D~F 的可視化結果可知,在實驗A 的模型中每個編碼器和解碼器后都加入3D-CS-Block,模型的去噪能力變強了,對地下目標的關注也增多了,且分割的效果也變得更加細膩。

表4 消融實驗的量化結果 單位:%Tab.4 Quantified results of ablation experiments unit:%

圖6 消融實驗可視化結果Fig.6 Visualization results of ablation experiments
綜上所述,通過加入3D-CS-Block,模型在訓練過程中會自動賦予目標和背景不同的權重值,讓模型有側重地學習地下目標特征,減少復雜背景和噪聲的影響。同時,模型能夠提取出地下目標不同尺度的特征,從不同大小的感受野學習目標的細節特征,使分割效果更加清晰。
3 結語
為了從復雜的雷達C-scan 中檢測出地下目標,本文設計了三維通道和空間注意力并行模塊,從兩個角度提取出地下目標的三維特征,抑制復雜背景和噪聲帶來的干擾。同時基于該注意力并行模塊設計了多尺度的三維分割模型(3D-CSA-UNet),加強對目標特征的提取,從淺層的語義特征中得到目標的類別信息,從深層的語義特征中得到目標的位置信息,從而實現對地下目標的精確檢測。實驗結果表明,3D-CSA-UNet 模型在機場道面地下目標檢測任務中有較好的效果。同時,模型存在參數量較大、訓練速度較慢等問題,這值得在后續研究中進行改善。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
