基于結構特征的地震剖面二維可視化方法
2023-03-27 12:48:08聶小燕陳瀟瀟羅凱陳紅
科學技術與工程 2023年5期
聶小燕,陳瀟瀟,羅凱,陳紅
(1.電子科技大學成都學院,成都 611731; 2.中國測試技術研究院,成都 610066)
地質剖面圖的結構特征被稱為同相軸[1]。在地震勘探資料處理解釋中,準確的同相軸信息能夠為地震資料處理和解釋工作提供更好的約束條件和指導作用,使結果更精細、可靠[2]。同相軸的識別和追蹤的準確度會直接影響到地質結構特征的判斷。
同相軸的構成是在同一個地震勘探數據中,擁有相同的振動相位并且位于相鄰兩列的波峰與波峰(或者波谷與波谷)的連線[3]。能夠相連的波峰、波谷應該是有規律出現的,基本上包含了絕大部分的地質結構特征信息。同相軸數據用來作為地震數據處理的約束條件[4],最終輸出的結構特征可視化圖像會更加可靠,更有利于幫助專業人員完成地質資源的標點定位工作。
針對地震剖面的結構特征問題,趙靜等[5]基于疊前及疊后資料的同相軸提取方法,提出一種適用于地震同相軸拾取的數學形態學方法。算法識別效率高,但在信噪比稍大一點的情況下拾取效果不是很好。謝瑋等[6]針對縫洞型油藏的地震識別,提出了從常規反射波數據中分離出繞射波數據,利用地震波場中的繞射信息對斷裂和裂縫地質體進行識別。余為維等[7]結合同相軸反射特征統計序列分析、灰度共生矩陣紋理屬性、Hu不變矩參數方法,從內部結構與外部特征角度提出一種地震相綜合數字表征方法,以期實現地震相的精確數字化表征。
隨著人工智能與機器學習的發展和進步,越來越多的智能方法被提出來。田高鵬等[8]設計自組織神經網絡,通過聚類分析優選出地震屬性,對優選優化后的屬性進行多波復合運算提取油氣特征信息。該方法具有良好的自組織學習能力、自組織分類等特點,但需要大量計算神經元與樣本的距離以確定最佳匹配單元,且不適用于稀疏數據場景。
余里輝[9]從地震振幅體數據出發,提出了一種全卷積網絡來實現斷層端到端的識別。提取得到斷層二值數據體后,考慮到斷層分布與空間形態的復雜性,采用先提取斷層骨架再對斷層點云直接重建斷層曲面的算法。該方法對山地高陡地質模型識別率低,且小斷層無法識別。
張子良等[10]提出基于改進DNA算法的地震層位拾取技術,提出復式五點采樣的方法建立基因庫,減少人為干預。地震DNA算法是一種較新的辦法,在地震數據特征選取上有一定的優勢,但是針對山地高陡復雜地質構造,結構特征交疊、不連續的情況較為明顯。
由于地質構造是極其復雜的,地質結構的多樣性導致了地震數據解釋的不確定性[11]。上述方法的結果好壞與所選取的地震資料屬性以及屬性計算方法有關。
現針對山地高陡復雜地質構造,為了更大程度地提高地震數據可視化效率以及更充分地挖掘山地高陡地震數據的結構信息,提出一種基于結構特征的地震剖面二維可視化方法。主要是從數據預處理方法、結構特征提取方法和二維可視化方法這三部分進行研究。提出領域加權平均濾波算法、特征選擇的正切值過濾算法和方差過濾算法、結構特征提取的相關算法、可視化的雙線性插值算法和顏色映射算法。將文獻[10]和所提出的方法應用到地質模型數據中,對兩者的實驗結果進行比較分析。
1 地震信號結構特征提取
1.1 數據預處理方法
地震勘探數據中會有斷層、裂縫等地層邊緣成分,而這些邊緣成分數據化時會包含較多的高頻分量,也就是噪聲[12]。在鄰域平均濾波法的基礎上,加入了鄰域內各數據的權重,能夠有效降低噪聲,提高數據的信噪比。
首先,根據圖像數據的特點來確定一個鄰域S的窗口大小為M×N,即鄰域S中有M列N行個圖像像素點,通常鄰域S呈正方形,大小取為3×3或者5×5鄰域;M與N的值一般為奇數,這樣方便確定鄰域中心像素點的位置。

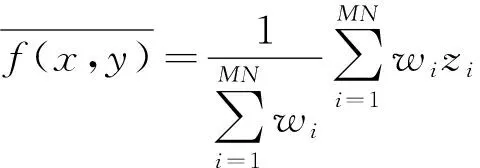
(1)
式(1)中:zi為以(x,y)為中心的領域像素值;wi為每個像素值對應的權重。
這種方法可以幫助降低噪聲,但同時也會降低圖像的分辨率,并且鄰域窗口越大,圖像就會越模糊,窗口越小,圖像的去噪效果就越差。因此鄰域平均濾波法既具有使用簡便、運行時間短等優點,但同時也存在以破壞圖像細節和圖像模糊為代價的缺點。鄰域平均濾波法的所有像素點的權重都一樣,但鄰域加權平均濾波法是在鄰域S內,像素點的權重會發生改變,中心點的權重值最大,離中心點越遠的坐標點與中心點的相關性越低,所以權重值越小。
傳統的平均過濾的方式會讓邊緣斷點信號受到統計平均效應的影響,從而導致嚴重的畸變,通過加權平均的方式,可以同時兼顧數據的去噪效果和圖像分辨率問題。
1.2 特征優化選擇
為了能夠提取數據中的同相軸,首先需要提取每列數據中的波峰、波谷。為了縮小由于數據的坐標值和數據值量級差距過大的影響,選擇線性歸一化的方法,按比例放縮,保證數據點之間的關系。
線性歸一化公式為
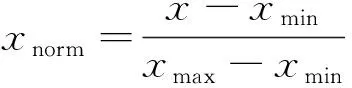
(2)
式(2)中:xmax為序列中的最大值;xmin為序列中的最小值,屬于原數據等比例放縮。
地質結構特征是由振幅較強的波峰、波谷表現出來的,所以可以用找到的波峰波谷序列通過方差或正切值過濾法進行序列優化,得到最優化的波峰、波谷序列。
1.2.1 方差過濾
通過數據點的方差判斷與樣本之間的特征關系。
定義總體標準偏差公式為
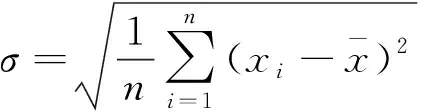
(3)
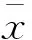
在上述步驟中所提取出來的波峰、波谷序列里,對每一個極值點相對于樣本的方差進行過濾。
方差過濾中閾值的確定會影響特征組合的有效性,如果閾值很小,大部分具有結構特征的數據點將不會被過濾;如果閾值比較大,將會有很多數據點被過濾掉,而被過濾掉的數據點可能很多都是有效特征數據點,所以閾值的大小對過濾效果至關重要。
1.2.2 正切值過濾
因為振幅強的極值一般會出現在與上下地層差別較大的地方,而含有油氣的地層與其相鄰地層會反射較大的傾斜角。所以也可以使用正切值過濾的方法,這種方法可以直接按每個極值點與兩邊鄰接極值的斜率來判斷振幅的強弱,正切值的絕對值越大,說明這個極值對于左右兩邊的振幅越強,那么這個極值點的特征性更強。
斜率計算公式為
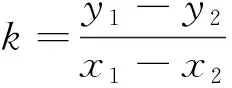
(4)
式(4)中:y1和y2為采樣點數據值;x1和x2為采樣點的時間序號。
1.3 結構特征提取
地質勘探人員會使用科學方法收集用來描述地質信息的離散數據,但由于單個離散數據值中所蘊含的地質特征信息太少[13],所以需要通過分析所有的離散數據之間的聯系,從中找出能夠代表地質結構特征的數據序列。
相關算法是以數據中相鄰兩列的極值點作為計算對象。相關算法最重要的目的就是要找到每一個極大值點或者極小值點對應右邊列中極大值點(或者極小值點)的相關系數,然后再根據相關系數來判斷兩個極大值點(或兩個極小值點)之間相關性的強弱。在分析經過特征選取后的極值序列時,極大值點和極小值點不會一起求解相關系數,而是需要將每一列的極大值點序列和極小值點序列分開計算,極值點之間的相似性就通過相關值的大小來衡量。而相關系數是根據兩個極值點得出兩組相關系數求解序列,滑動窗口的大小決定求解序列的大小,然后這兩組數據按相關公式計算得出。相關系數有正負之分,取值為-1~1,若相關系數的值等于最大時,就說明這兩個極值點在滑動窗口大小內的相位相同;若相關系數的值等于最小時,就說明這兩個極值點在滑動窗口大小內的相位完全相反。相關系數的絕對值越大,則這兩組數據呈線性關系,此時這兩個極大值點(或者波谷)相關性越強,可以作為結構特征序列;若相關系數的絕對值越小,則這兩個極大值點(或者波谷)相關性越弱,當相關系數絕對值沒有達到閾值,就不會加入到結構特征序列。
相關系數計算公式為
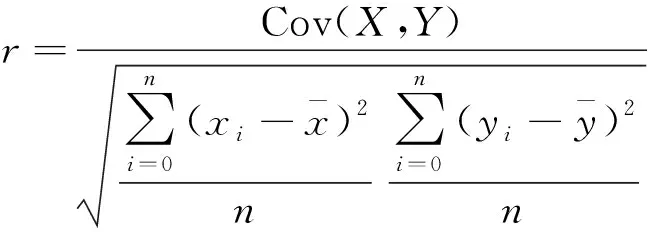
(5)
式(5)中:Cov(X,Y)為協方差,計算公式為
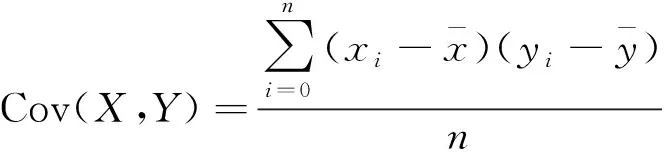
(6)
2 結構特征約束的可視化方法
現有的地震數據剖面可視化通常被當作一個單純的計算機問題。如圖1所示,信號的強弱反映了地層結構的變化。由于地層存在起伏和傾角,在等時或等深界面上不同道上的信號相位不同。可視化的目的是最大程度保持原有信號反映的結構特征。現有的可視化渲染方法忽略了信號特征的約束,導致地震剖面可視化圖像的分辨率和連續性較差。所提出的結構特征約束的可視化渲染方法可以提高可視化效果的保真度。

圖1 地震剖面信號Fig.1 Seismic profile signal
地震勘探數據屬于時空數據[14]。時空數據用圖像表示的時候,可以利用數據的各個屬性來簡化可視化設計,根據數據中各數據點的坐標位置,劃分成不同維度的目標圖像。
2.1 不規則雙線性插值
雙線性插值是以二維坐標為基礎的,相當于在兩個方向使用三次單線性插值。常用的有兩種計算方式:第一種是先在y軸方向求兩次,然后在x軸方向求一次;第二種方式是先在x軸方向求兩次,然后在y軸方向求一次,如圖2所示。兩種方式計算結果相同。由于不規則四邊形有兩條邊是平行于y軸的,所以采用第二種方式更適合。
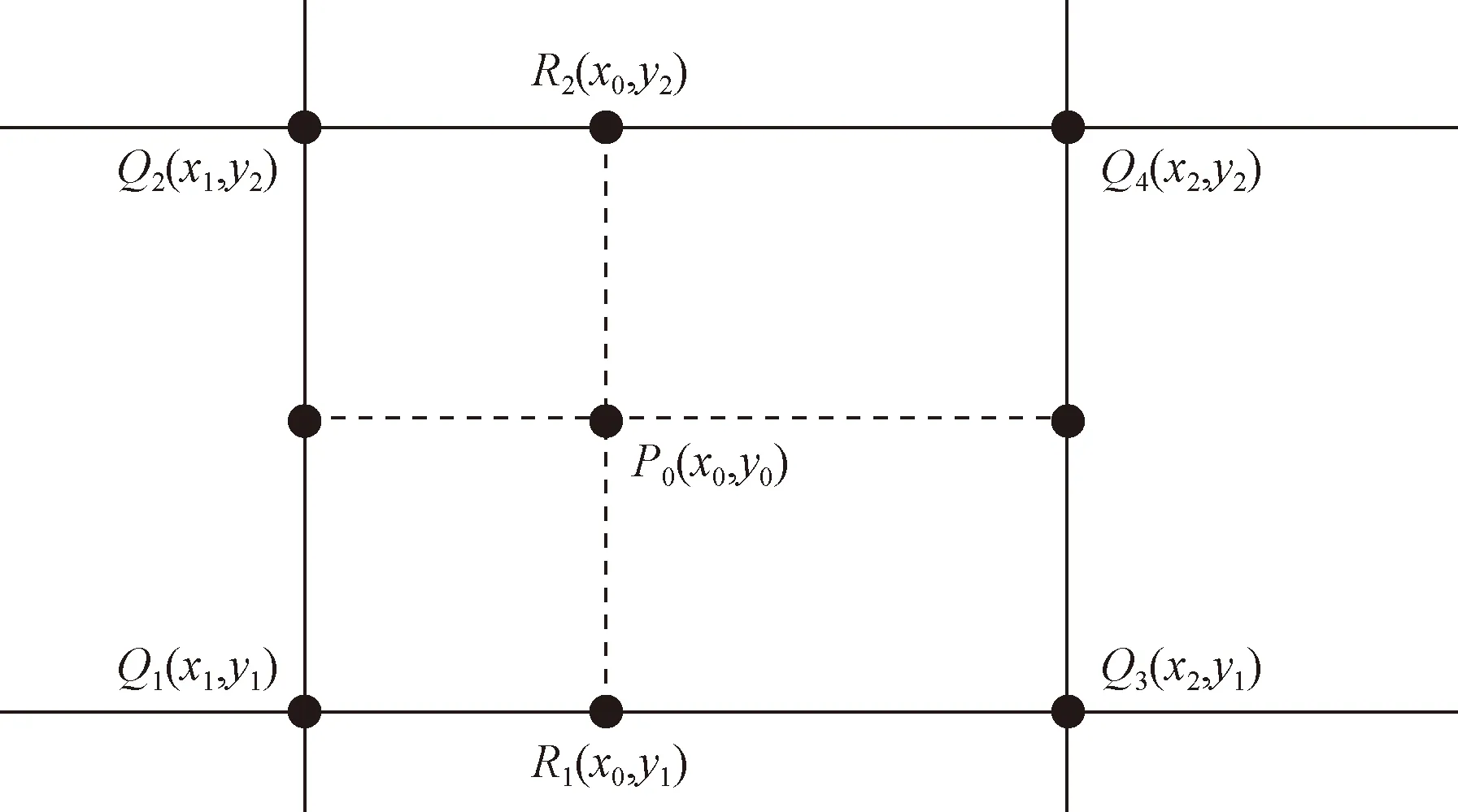
圖2 規則的雙線性插值示意圖Fig.2 Schematic diagram of regular bilinear interpolation
兩次x軸方向單線性插值計算公式如下。
(1)點R1的函數值。
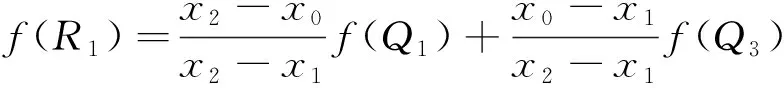
(7)
(2)點R2的函數值。
(8)
一次y軸方向單線性插值計算公式如下。
點P0的函數值公式為
(9)
根據處理的輸入數據特點,采用不規則雙線性插值方法。
四邊形的4個頂點取原數組中相鄰的4個數據點,兩個在第i列,另外兩個在第i+1列,由于4個點只涉及兩列數據的范圍,則由這4個點組成的四邊形中兩條邊是與y軸平行的,但是其他兩條邊不一定與x軸平行,所以這里的四邊形是不規則的(如圖3所示)。點P0的函數值計算公式為
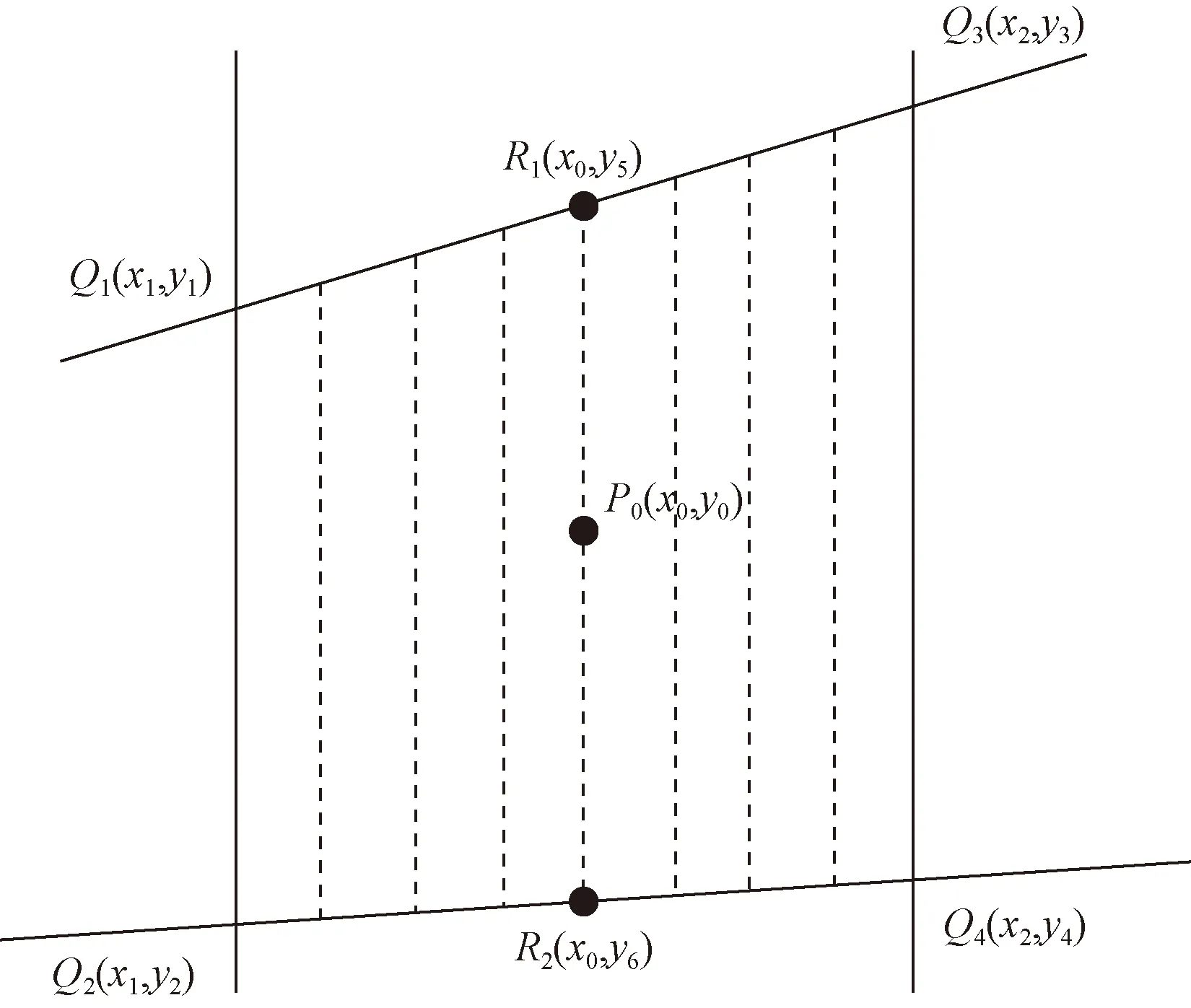
圖3 不規則雙線性插值示意圖Fig.3 Schematic diagram of irregular bilinear interpolation
(10)
相對于規則的雙線性插值,不規則四邊形在y方向的插值對應數值應為點R1和點R2的y坐標值。
2.2 坐標映射法和顏色映射法
采用平面型二維數據可視化方法中的坐標映射法和顏色映射法,可以通過數據點在目標圖像中的位置映射,調節不同的顏色以及顏色的亮度、色標等方式傳達圖像的結構特征信息,通過顏色的差別可以更直觀地突顯地質特征。
輸入的數據是一個二維數組,為了映射更方便,若a和b是小數,則向下取整,分別記為[a]和[b],目標圖像的空白邊緣橫向大小為(M/m)余數的一半,再向下取整,記為a1;空白邊緣縱向大小為(N/n)余數的一半,再向下取整,記為b1,剩余空白像素點向后移。此時原圖像的點(x,y)對應目標圖像的點(a1+xa,b1+yb)。坐標映射原理如圖4所示。
圖4 坐標映射方法Fig.4 Coordinate mapping method
2.3 顏色映射法
顏色映射法可以分為兩步,第一步需要確定一個顏色映射表,顏色映射表中的顏色都需要指定對應的顏色值。第二步將標量數據對應到顏色表中的顏色值上。采用漸變色或混合色時,可以自定義顏色值的范圍來適應標量數據值的范圍,也可以直接指定某一標量值對應某一個顏色值。
如圖5所示是混合色顏色表中的其中一種,左邊顏色對應標量最小值,右邊顏色對應標量最大值。顏色表的顏色值范圍是[0,255],所以顏色值為0對應標量的最小值,顏色值為255對應標量的最大值,然后所有標量按比例對應在[0,255]區間。

圖5 顏色映射表Fig.5 Color mapping table
3 測試結果與分析
3.1 測試環境與系統平臺
采用python作為開發語言,使用pycharm作為開發平臺進行軟件設計。測試環境為Intel(R) Core(TM) i5-2450M CPU @ 2.50 GHz,8.00 GB內存,NVIDIA GeForce GTX750,64位 Windows7旗艦版操作系統。
以反映地質信息的數據集作為本文的輸入數據源,選擇所提出的數據預處理方法對采集的數據做預處理,流程如圖6所示。
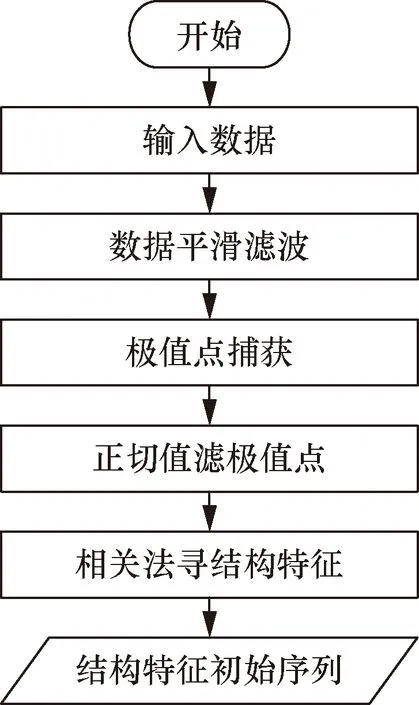
圖6 數據預處理流程圖Fig.6 Data preprocessing flow chart
然后根據結構特征提取方法來尋找數據中隱含的結構特征。地質結構特征提取的過程是根據描述地質信息的數據,尋找隱含結構特征的數據點作為地層的分界面[15],提取流程如圖7所示,最后輸出能夠表現地質特征的數據序列。
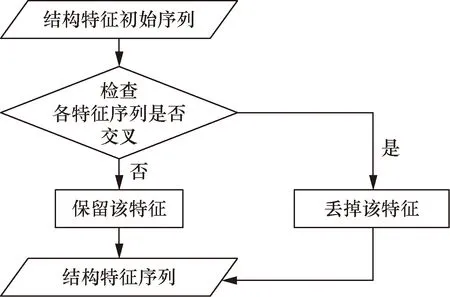
圖7 結構特征提取流程圖Fig.7 Flow chart of structural feature extraction
如圖8所示是實驗中部分數據點形成的波形圖,把數組中每列數據抽象成一個波形線(藍色波線),紅色點是每列數據點中的極大值點,黃色點是每列數據點中的極小值點。相關性較強的極大值點(或極小值點)之間的連線,就是本文方法拾取的結構特征序列。

圖8 結構特征序列波形圖Fig.8 Structural feature sequence waveform
3.2 方法驗證
為了進一步驗證本文方法的有效性,下面分別采用所提出的方法和文獻[10]的方法進行結構特征拾取測試實驗。
如圖9所示,用文獻[10]的方法得到的結構特征提取的同相軸很多不光滑,折點處較多,連續性較差。因為地震DNA算法雖然是一種新的同相軸自動提取算法,但是因其匹配出符合條件的地震特征較多,且層位劃分不夠明顯,很難區分所找到的地震波是否屬于同一個地震層位,所以拾取到的地震層位連續性較差。
圖10是用本文方法得到的結果。與圖9比較可以看出結構特征連續性更強,比較有規律,也不會出現過度曲折和兩條同相軸交疊的現象,更加符合地質結構的實際情況。通過兩種方法結果的比較,本文方法效果更好。
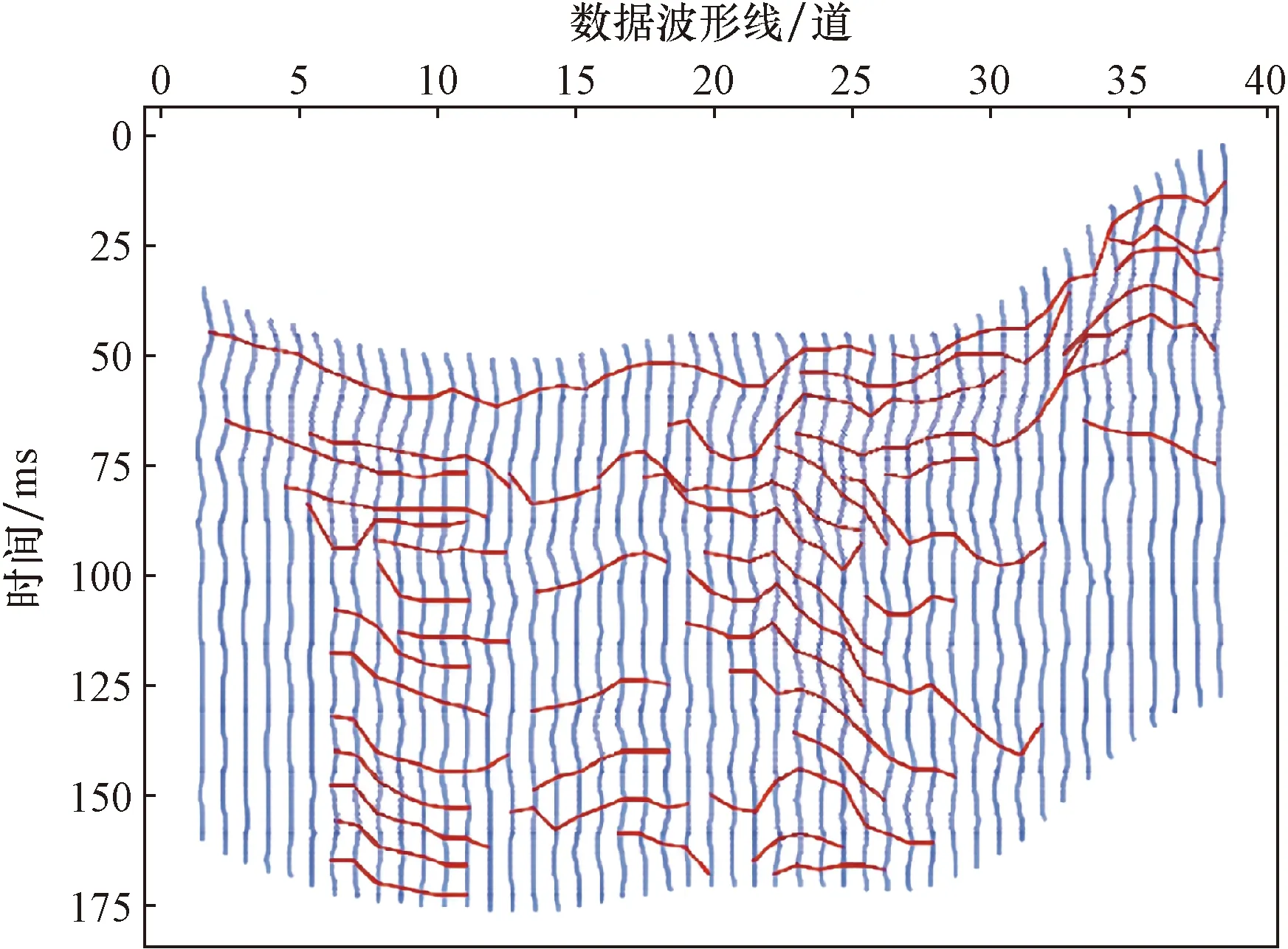
圖9 文獻[10]方法的結構特征圖Fig.9 Structural characteristic diagram of reference[10] method
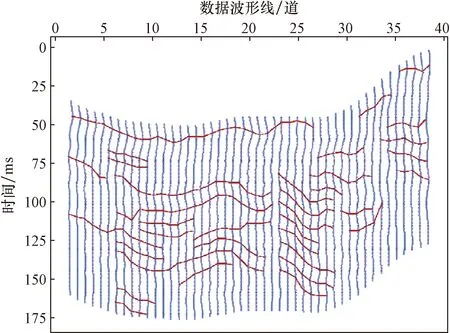
圖10 本文方法結構特征圖Fig.10 The structural characteristic diagram of this method
最后,以上述得到的結構特征序列為約束條件,在渤海灣某工區數據集上進行二維渲染,最終輸出一個結構特征較為明顯的可視化圖像如圖11所示。
圖12是圖11結構特征的局部放大,線條就是本文提取的結構特征序列,疊加在原數據的可視化圖像上。可以很明顯地看出結構特征序列與大部分地質信息是相符合的,連續性更好,與文獻[10]方法相比實現了更準確的地質結構可視化效果。
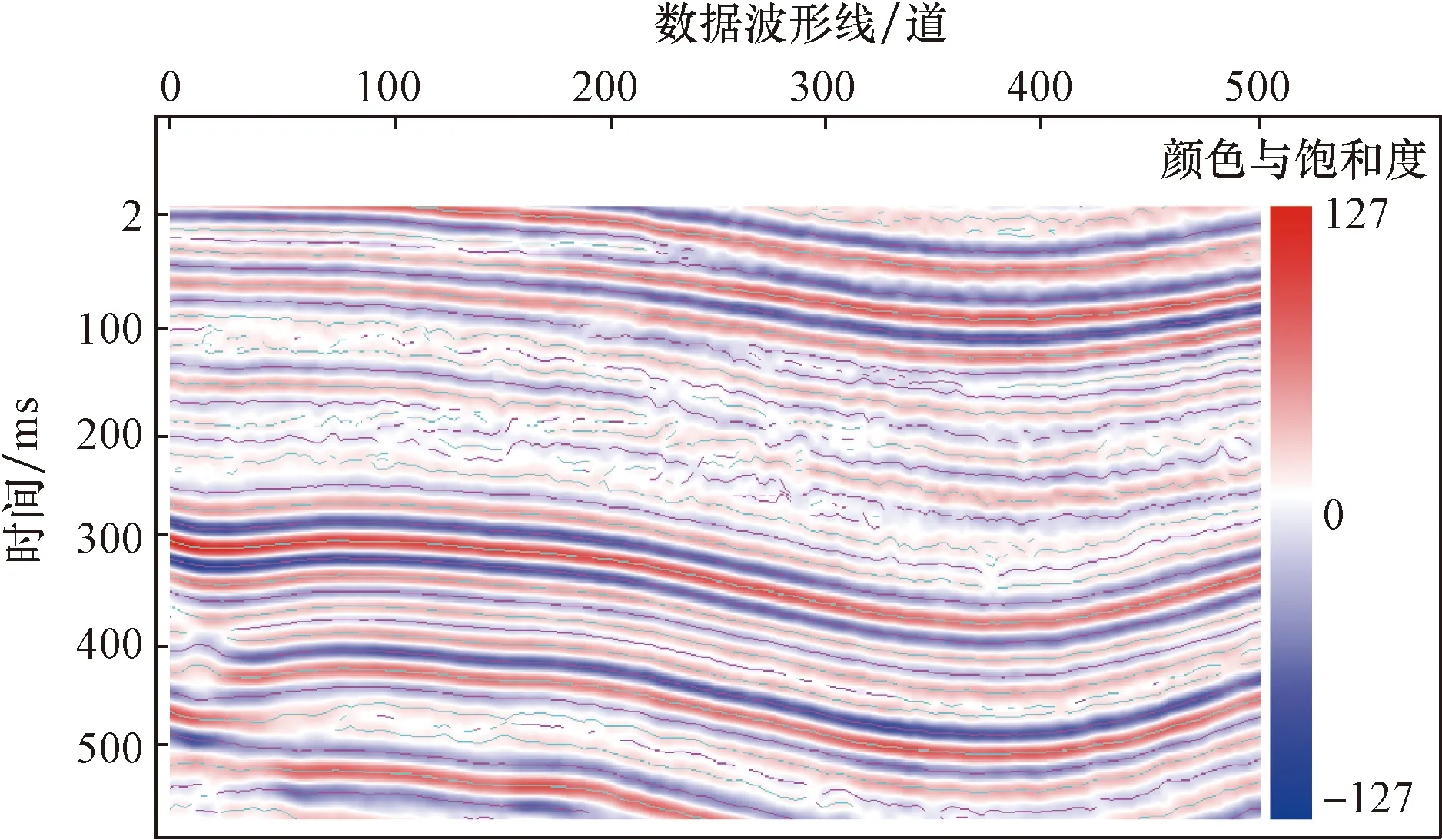
圖11 渤海灣某工區二維可視化圖像Fig.11 Two dimensional visualization image based on structural features

圖12 結構特征局部放大Fig.12 Amplification of structural characteristics
4 結論
地震勘探數據中每個數據點只含有很少的地質結構信息,專業人員需要快速、準確地從大量數據中找出數據反映的結構特征信息,為專業人員提供更能真實反映地質結構特征的圖像來幫助判斷油氣在地下儲藏的位置。
針對山地高陡復雜地質構造,實現了對數據中隱含的結構特征的可視化顯示。與傳統的方法對比,實驗測試結果驗證了獲取的結構特征序列的準確性更高,連續性更好。以結構特征序列為約束條件而輸出的可視化圖像效果也符合預期目標。但在結構特征拾取的過程中,未具體討論閾值確定問題,這是今后需要進一步研究和探討的問題。
猜你喜歡
北京測繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
