基于Transformer模型的手勢(shì)腦電信號(hào)分類識(shí)別
2023-03-27 12:04:02李趙春周永照馮衛(wèi)奔王玉成
科學(xué)技術(shù)與工程 2023年5期
李趙春,周永照,馮衛(wèi)奔,王玉成
(1.南京林業(yè)大學(xué)機(jī)械電子工程學(xué)院,南京 210037; 2.中國(guó)科學(xué)院合肥物質(zhì)科學(xué)研究院智能機(jī)械研究所,常州 213000)
調(diào)查顯示,腦卒中已成為導(dǎo)致中國(guó)居民的第一位死亡原因,也是中國(guó)成年人殘疾的首要原因。腦卒中后的患者大多會(huì)發(fā)生手功能障礙,手功能的恢復(fù)既是治療重點(diǎn)也是難點(diǎn)[1]。因此,及時(shí)有效的康復(fù)訓(xùn)練對(duì)重塑患者大腦功能進(jìn)而改善運(yùn)動(dòng)能力至關(guān)重要。基于頭皮腦電信號(hào)的精細(xì)手勢(shì)動(dòng)作識(shí)別是腦卒中患者運(yùn)動(dòng)功能康復(fù)的重要技術(shù)手段。
腦電信號(hào)(electroencephalogram,EEG)作為一種電生理信號(hào),反映了最簡(jiǎn)單、直接的大腦活動(dòng)狀態(tài)。它可以以非常高的時(shí)間分辨率、非侵入式方式和較低的成本在頭皮表面獲取,采集方法簡(jiǎn)單安全。腦機(jī)接口(brain-computer Interface,BCI)是大腦與外界的通信通道,通過(guò)EEG可以清楚看到大腦中各種各樣的思維活動(dòng)[2]。BCI的關(guān)鍵是從大腦活動(dòng)中解釋運(yùn)動(dòng)意圖。高效的神經(jīng)解碼算法可以提高解碼的精度,但是EEG信號(hào)低信噪比導(dǎo)致EEG信號(hào)分類精度較低。因此,如何設(shè)計(jì)更好的實(shí)驗(yàn)范式并設(shè)計(jì)更符合EEG信號(hào)數(shù)據(jù)結(jié)構(gòu)特征的分類識(shí)別方法至關(guān)重要。
對(duì)于精細(xì)的手勢(shì)動(dòng)作來(lái)說(shuō),單靠運(yùn)動(dòng)想象獲取的腦電信號(hào)無(wú)法獲得較高的分類準(zhǔn)確率。為了得到更好的腦電信號(hào),通常是采用實(shí)際手勢(shì)動(dòng)作,而不是運(yùn)動(dòng)想象,因?yàn)樗庇^,從而提高了BCI的性能。
EEG信號(hào)相對(duì)于其他生理信號(hào)更為微弱,一般在微伏數(shù)量級(jí),并且由于導(dǎo)聯(lián)方式,更容易受到干擾。常見(jiàn)的偽跡干擾來(lái)自外部電子設(shè)備或受試者本身的出汗、肌肉活動(dòng)、眼動(dòng)、心電等。在對(duì)EEG信號(hào)分析前,通常需要對(duì)EEG信號(hào)進(jìn)行預(yù)處理,最小化偽跡干擾,可以提高EEG信號(hào)的信噪比和分類精度。常見(jiàn)的去偽跡方法包括盲源分離(blind source separation,BSS)[3],小波變換(wavelet transform,WT)[4]和經(jīng)驗(yàn)?zāi)B(tài)分解(empirical mode decomposition,EMD)[5]。
EEG信號(hào)模式識(shí)別一直是個(gè)具有挑戰(zhàn)性的問(wèn)題,早期的機(jī)器方法依賴于過(guò)多的預(yù)處理和已經(jīng)確定的信號(hào)特征,最佳特征子集和算法沒(méi)有明確規(guī)定。但在近幾年里,用于EEG信號(hào)分類的深度學(xué)習(xí)模型已被成功地提出,卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)和循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)廣泛應(yīng)用于EEG分類中,但它們各有弊病。CNN可以捕捉到局部的接收域信息,但忽略了全局信息。RNN網(wǎng)絡(luò)無(wú)法捕捉空間信息,并行計(jì)算效率較低。
近年來(lái),受Transformer在自然語(yǔ)言處理和機(jī)器視覺(jué)等領(lǐng)域的成功啟發(fā),許多研究人員開(kāi)始探索其在EEG信號(hào)分類中的應(yīng)用。Sun等[6]設(shè)計(jì)了5種新的基于變壓器的腦電信號(hào)分類模型,取得了良好的性能。 Liu等[7]提出了一種新的基于自我注意的腦電情緒識(shí)別框架。該方法考慮了腦電樣本中不同腦區(qū)和時(shí)間段的不同貢獻(xiàn),以及腦電信號(hào)固有的時(shí)空特征。 Lee等[8]提出了一種基于變壓器結(jié)構(gòu)的注意模塊來(lái)解碼腦電信號(hào)中的想象語(yǔ)音,證明了用注意力模塊解碼想象語(yǔ)音的技術(shù)有潛力作為真實(shí)世界的通信系統(tǒng)。 Tao等[9]為了捕獲長(zhǎng) EEG 序列中編碼的時(shí)間信息,在 EEG 信號(hào)上使用 Transformer 的增強(qiáng)版本,即門(mén)控Transformer,沿著EEG序列學(xué)習(xí)特征表示,實(shí)現(xiàn)了新的最先進(jìn)的性能。Transformer模型在EEG信號(hào)分類取得了良好的效果,與CNN和RNN相比,Transformer在處理長(zhǎng)距離依賴關(guān)系方面表現(xiàn)更為出色,是一個(gè)很好的長(zhǎng)序列數(shù)據(jù)識(shí)別模型。在長(zhǎng)時(shí)間序列中,注意力機(jī)制可以確定最相關(guān)的信息,了解哪些數(shù)據(jù)部分與最終輸出有關(guān)。
為增強(qiáng)大腦感覺(jué)運(yùn)動(dòng)功能皮層EEG信號(hào)強(qiáng)度、降低腦機(jī)交互過(guò)程中的大腦負(fù)荷,現(xiàn)設(shè)計(jì)4種實(shí)際手勢(shì)動(dòng)作并同步采集EEG信號(hào)作為數(shù)據(jù)處理對(duì)象,有效提高EEG信號(hào)與手勢(shì)動(dòng)作的信號(hào)關(guān)聯(lián)度;同時(shí)設(shè)計(jì)一種基于MEMD-CCA的混合去偽影方法,在消除肌電偽影和眼電偽影方面效果良好。為了得到更好的腦電分類結(jié)果,結(jié)合腦電信號(hào)的時(shí)間特征和空間特征,考慮多通道腦電采集時(shí)體積傳導(dǎo)和受試者反應(yīng)速度的不同,改進(jìn)一種基于自注意力的Transformer模型:在經(jīng)典Transformer模型中添加top-k選擇,構(gòu)建top-k稀疏Transformer模型并選擇信號(hào)特征明顯的k個(gè)數(shù)據(jù)段以期提高分類準(zhǔn)確率。最后,通過(guò)重構(gòu)腦電信號(hào)數(shù)據(jù)結(jié)構(gòu),對(duì)比分析時(shí)間、空間、top-k時(shí)間和top-k空間4個(gè)變體Transformer模型的分類識(shí)別性能效果。
1 腦電信號(hào)采集
1.1 腦電信號(hào)通道選擇
研究表明,人腦對(duì)手勢(shì)動(dòng)作的控制神經(jīng)均位于大腦中央前回區(qū)域[10]。因此所選16導(dǎo)電極均圍繞此區(qū)域分布,根據(jù)10-20國(guó)際標(biāo)準(zhǔn)電極放置法,選擇如下16導(dǎo)電極位置:Fz、FC3、FC1、FCz、FC2、FC4、C5、C3、C1、Cz、C2、C4、C6、CP3、CPz、CP4,如圖1所示。
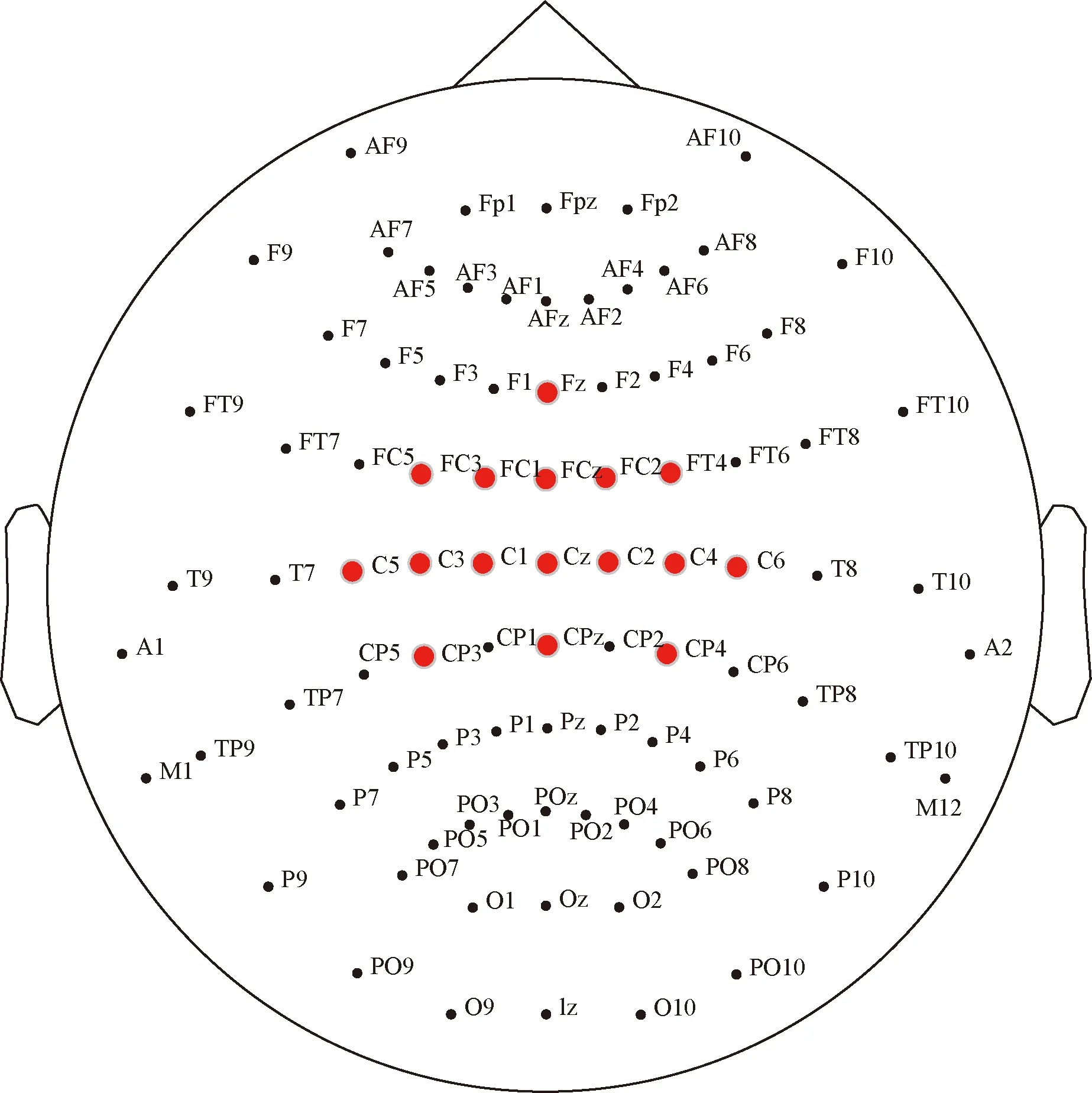
圖1 10-20國(guó)際電極放置標(biāo)準(zhǔn)16通道電極位置分布圖Fig.1 Distribution of 16-channel electrode position 10-20 international standard electrode placement method
1.2 腦電信號(hào)采集
設(shè)計(jì)手勢(shì)動(dòng)作共4種,如圖2所示,依次為握拳、伸掌、數(shù)字2和數(shù)字3。實(shí)驗(yàn)范式如圖3所示,單次試驗(yàn)時(shí)長(zhǎng)共7 s,腦電設(shè)備采樣頻率設(shè)為1 000 Hz,分為4個(gè)階段。
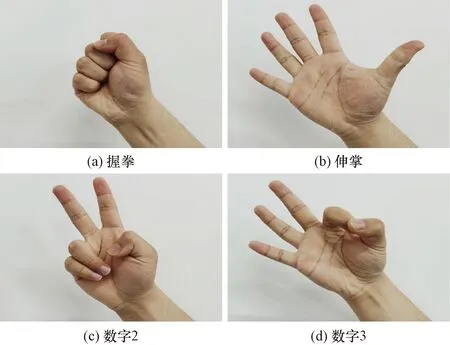
圖2 手勢(shì)動(dòng)作Fig.2 Gesture action
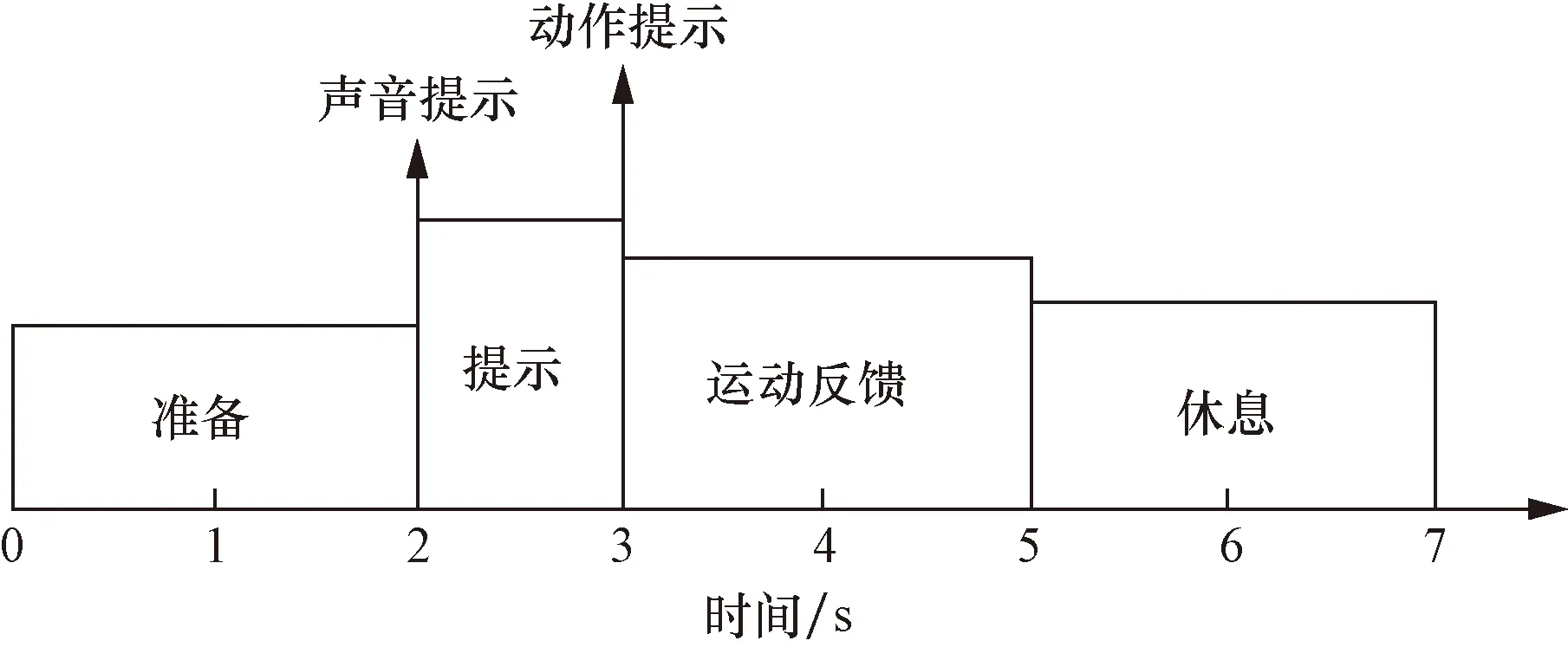
圖3 實(shí)驗(yàn)范式Fig.3 Experimental paradigm
(1)準(zhǔn)備階段。0~2 s,該階段內(nèi)受試者保持放松狀態(tài)。
(2)提示階段。2~3 s,第二秒開(kāi)始時(shí),揚(yáng)聲器會(huì)發(fā)出“嘀”的一聲提示音,持續(xù)大約0.5 s,提醒受試者做好準(zhǔn)備。
(3)反饋階段。3~5 s,第3秒開(kāi)始時(shí),顯示器上會(huì)出現(xiàn)動(dòng)作提示,受試者根據(jù)出現(xiàn)的圖片做出相應(yīng)的動(dòng)作。
(4)休息階段。5~7 s,受試者重新回到放松狀態(tài),等待下一次提示。
實(shí)驗(yàn)對(duì)象共3名,均為健康的男性青年,年齡在23~35歲,均為右利手。實(shí)驗(yàn)前受試者均已熟悉實(shí)驗(yàn)步驟和流程,且都為自愿參加。
2 腦電信號(hào)預(yù)處理
EEG信號(hào)頻率主要集中在0.1~40 Hz,在上位機(jī)先對(duì)EEG信號(hào)進(jìn)行50 Hz陷波和0.1~40 Hz帶通濾波。偽影一般僅使用傳統(tǒng)BSS技術(shù)是難以去除的,因?yàn)樗鼈円罂捎猛ǖ赖臄?shù)量應(yīng)等于或大于未知源的數(shù)量。因此,在通道數(shù)量有限的情況下,僅使用獨(dú)立成分分析(independent component analysis,ICA)或典型相關(guān)分析(canonical correlation analysis,CCA)都無(wú)法完全恢復(fù)腦源和非腦源。在最近的調(diào)查中,研究人員反復(fù)建議,抑制EEG偽影的最佳方法可能包括通過(guò)組合多個(gè)算法的多個(gè)處理過(guò)程,而不是單獨(dú)使用[11]。CCA使用了比ICA算法尋求的統(tǒng)計(jì)獨(dú)立性更弱的條件,且具有自動(dòng)化和計(jì)算效率更高的優(yōu)點(diǎn)。MEMD算法是一種經(jīng)驗(yàn)和數(shù)據(jù)驅(qū)動(dòng)的方法,本質(zhì)上是自適應(yīng)的,不需要任何先驗(yàn)知識(shí),特別適合處理非線性和非平穩(wěn)神經(jīng)信號(hào),充分利用通道之間的信息。
設(shè)計(jì)了基于多變量經(jīng)驗(yàn)?zāi)J椒纸?multivariate empirical mode decomposition,MEMD)和CCA的混合去除偽影方法(MEMD-CCA)。基于MEMD和CCA的混合去除偽影方法具體步驟如下。
步驟1輸入數(shù)據(jù)是16通道腦電采集數(shù)據(jù),依圖3實(shí)驗(yàn)范式截取0.5~6.5 s數(shù)據(jù),單個(gè)腦電數(shù)據(jù)的大小為16×6 000。
步驟2使用MEMD算法分解16通道腦電數(shù)據(jù)。IMF分量根據(jù)原始通道順序被重組為一個(gè)IMF矩陣X(t)。
步驟3識(shí)別并去除與肌電偽影偽影相關(guān)的IMF,組成新的IMF數(shù)據(jù)集,定義為F(t)。肌電偽影一般雜亂無(wú)章,具有相對(duì)較低的自相關(guān)值,而眼電偽影則具有相對(duì)高的自相關(guān)值,計(jì)算IMF的自相關(guān)值并設(shè)置高低閾值來(lái)識(shí)別與偽影相關(guān)的IMF,并使用相對(duì)較高或較低的閾值來(lái)避免錯(cuò)漏EEG成分,那些從不同的腦電通道識(shí)別出的IMF實(shí)際上由于體積傳導(dǎo)具有內(nèi)在相似的振蕩模式。這些跨信道信息可以在很大程度上促進(jìn)后續(xù)BSS步驟。
步驟4基于二階統(tǒng)計(jì)量(second order statistics,SOS)的CCA算法用于將分散在數(shù)據(jù)集F(t)的IMF分量中偽影信號(hào)集中到幾個(gè)CCA組件(CCs)中。CCA使用重組的IMFs矩陣X(t)及其延時(shí)版本Y(t)=X(t-1)通過(guò)解決等式中的最大化問(wèn)題,通過(guò)分解矩陣wx和wy得到源矩陣Sx和Sy。
步驟5計(jì)算源信號(hào)矩陣Sx的每個(gè)源信號(hào)的自相關(guān)系數(shù)r,若r小于所設(shè)閾值e時(shí),將Sx中與偽影對(duì)應(yīng)源信號(hào)設(shè)置為零,并定義新的數(shù)據(jù)集Snew。
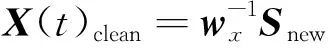
步驟7MEMD信號(hào)重構(gòu)。X(t)clean中的干凈的IMFs對(duì)應(yīng)代替數(shù)據(jù)集F中具有偽影成分的IMFs,得到無(wú)偽影的IMF數(shù)據(jù)集,將IMFs相加得到干凈的腦電信號(hào)。
步驟8依實(shí)驗(yàn)范式,截取動(dòng)作反饋的2~4 s的重構(gòu)腦電數(shù)據(jù),保存數(shù)據(jù)集。
3 模型構(gòu)建
3.1 Tranformer模型
在研究中,多通道EEG數(shù)據(jù)具有空間信息和時(shí)間信息,每個(gè)采樣通道下所有時(shí)間點(diǎn)的信息都是該通道的特征,每個(gè)采樣時(shí)間點(diǎn)下所有通道的信息都是該時(shí)間點(diǎn)的特征。另外,根據(jù)對(duì)EEG信號(hào)的觀察,一個(gè)時(shí)間片段比單個(gè)采樣點(diǎn)更能反映信號(hào)趨勢(shì)和特征。受vision transformer(ViT)模型啟發(fā)[12],構(gòu)建了時(shí)間Tranformer模型和空間Transformer模型,兩模型分別計(jì)算了采樣時(shí)間段間的相關(guān)性和采樣通道間的相關(guān)性。
時(shí)間Tranformer模型和通道Transformer模型的區(qū)別在于輸入,如圖4所示。在時(shí)間Transformer模型中,模型輸入按時(shí)間維度切割成k份不重疊的時(shí)間切片并展平成一維向量(k=通道數(shù),確保注意力模塊輸入相同),通過(guò)線性映射到模型維數(shù)。在空間Transformer模型中,模型輸入按電極通道分割數(shù)據(jù),通過(guò)線性映射到模型維數(shù)。
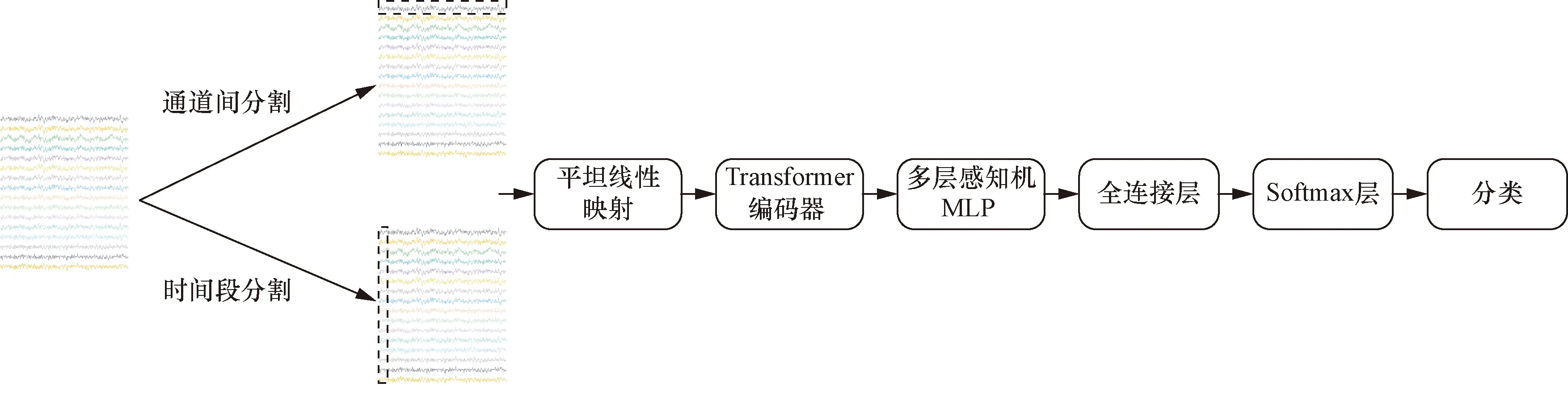
圖4 時(shí)間Tranformer模型和通道Transformer模型Fig.4 Time Transformer model and spatial Transformer model
Transformer模型架構(gòu)中自注意力模塊采用查詢-鍵-值(query-key-value,QKV)模式,其計(jì)算過(guò)程如圖5所示。注意力模塊用于映射一組查詢和鍵值對(duì),其中輸出計(jì)算為值的加權(quán)和。自注意力模型使用縮放點(diǎn)積來(lái)作為注意力打分函數(shù),輸出向量序列可以簡(jiǎn)寫(xiě)為
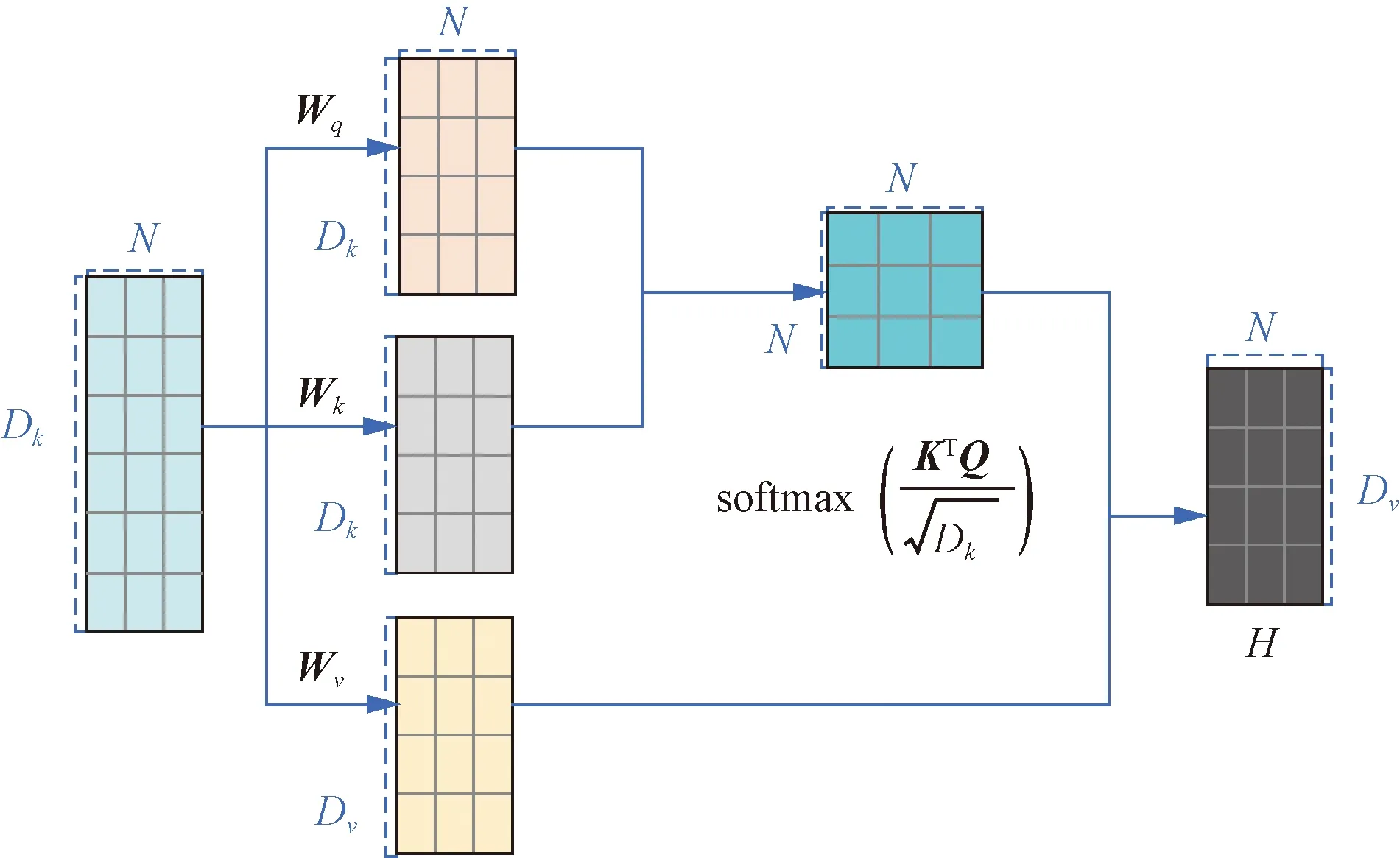
Dk、Dv為矩陣的行數(shù);N為矩陣的列數(shù);Wq、Wk、Wv為輸入數(shù)據(jù)線性變化的矩陣圖5 自注意力模型的計(jì)算過(guò)程Fig.5 The calculation process of the self-attention model
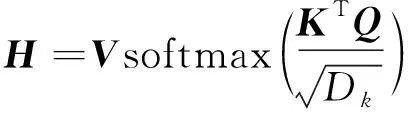
(1)
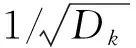
3.2 top-k稀疏Transformer模型
多通道EEG信號(hào)采集時(shí),由于設(shè)備的傳輸速率和人的反應(yīng)速度,腦電信號(hào)的采集有延遲性,另外,由于體積傳導(dǎo)的緣故,EEG不同通道采集的信號(hào)存在共模冗余信號(hào)成分。自注意力能夠?yàn)殚L(zhǎng)距離依賴關(guān)系建模,但它可能會(huì)受到信號(hào)中不相關(guān)或冗余信息的影響。因此,為了提取腦電信號(hào)中特征更加明顯的時(shí)空信息,使用了基于top-k選擇的稀疏Transformer模型[13]。在Transformer Encoder層,通過(guò)top-k選擇將注意退化為稀疏注意,這樣有助于保留引起注意的部分信號(hào),而其他無(wú)關(guān)信號(hào)就被刪除了,這樣能有效地保留重要的信息和去除噪聲,注意力就可以集中在最具信息價(jià)值的數(shù)據(jù)上。
在稀疏Transformer模型注意力模塊中,首先生成注意力分?jǐn)?shù)P,表達(dá)式為
(2)
然后在假設(shè)得分越大、相關(guān)性越大的基礎(chǔ)上,模型對(duì)注意力分?jǐn)?shù)P進(jìn)行評(píng)估,對(duì)P執(zhí)行稀疏注意力掩蔽操作M(·),以選擇top-k貢獻(xiàn)元素。掩蔽函數(shù)M(·)為
(3)
式(3)中:ti為第i行中第k大的值。通過(guò)top-k選擇高注意力分?jǐn)?shù),保證EEG信號(hào)重要成分的保留。輸出向量序列可以簡(jiǎn)寫(xiě)為
H=Vsoftmax[M(P,k)]
(4)
結(jié)果表明,采用自注意力機(jī)制的最具貢獻(xiàn)的數(shù)據(jù)上。top-k選擇應(yīng)用于時(shí)間Transformer模型,可以集中更多的注意力在更有價(jià)值的時(shí)間段;top-k選擇應(yīng)用于空間Transformer模型,可以集中更多的注意力在更有價(jià)值的通道上。
3.3 實(shí)驗(yàn)配置及參數(shù)設(shè)置
使用的實(shí)驗(yàn)環(huán)境為Windows10系統(tǒng),處理器為AMD Ryzen 7 3700x 8-Core Processor,編程語(yǔ)言為python 3.8,改進(jìn)的Transformer模型的構(gòu)建使用pytorch1.10.1。在實(shí)驗(yàn)中,模型的自注意力模型均設(shè)置為3層,每層自注意頭的個(gè)數(shù)為8,dropout為0.5,Mmodel為512,連接前饋層的參數(shù)設(shè)置為2 048,學(xué)習(xí)率為5×10-5。模型均使用的是交叉熵?fù)p失函數(shù)和Adam優(yōu)化器。top-k稀疏Transformer模型中超參數(shù)k為8。為了保證模型的穩(wěn)定性,使用了10折交叉驗(yàn)證的方法進(jìn)行訓(xùn)練。將樣本按個(gè)體的順序隨機(jī)打亂并平均分成10份,每次取不同的1份作為測(cè)試集對(duì)模型進(jìn)行測(cè)試得到分類準(zhǔn)確率,剩下的9份作為訓(xùn)練集進(jìn)行訓(xùn)練,最后將得到的10個(gè)準(zhǔn)確率取平均作為模型的分類結(jié)果。
4 結(jié)果與討論
使用了準(zhǔn)確率和混淆矩陣評(píng)價(jià)模型。在10折交叉驗(yàn)證中,準(zhǔn)確率指10次訓(xùn)練準(zhǔn)確率的平均值。時(shí)間Transformer模型、空間Transformer模型、top-k時(shí)間Transformer模型、top-k空間Transformer模型訓(xùn)練曲線、10折交叉驗(yàn)證準(zhǔn)確率如圖6和圖7所示。表1為手勢(shì)腦電信號(hào)Transformer模型10折交叉驗(yàn)證準(zhǔn)確率。

表1 手勢(shì)腦電信號(hào)Transformer模型10折交叉驗(yàn)證準(zhǔn)確率平均值Table 1 Average accuracy of gesture EEG Transformer model 10-fold cross-validation

圖6 手勢(shì)腦電信號(hào)的Transformer分類模型訓(xùn)練曲線Fig.6 Transformer classification model training curve of gesture EEG signals
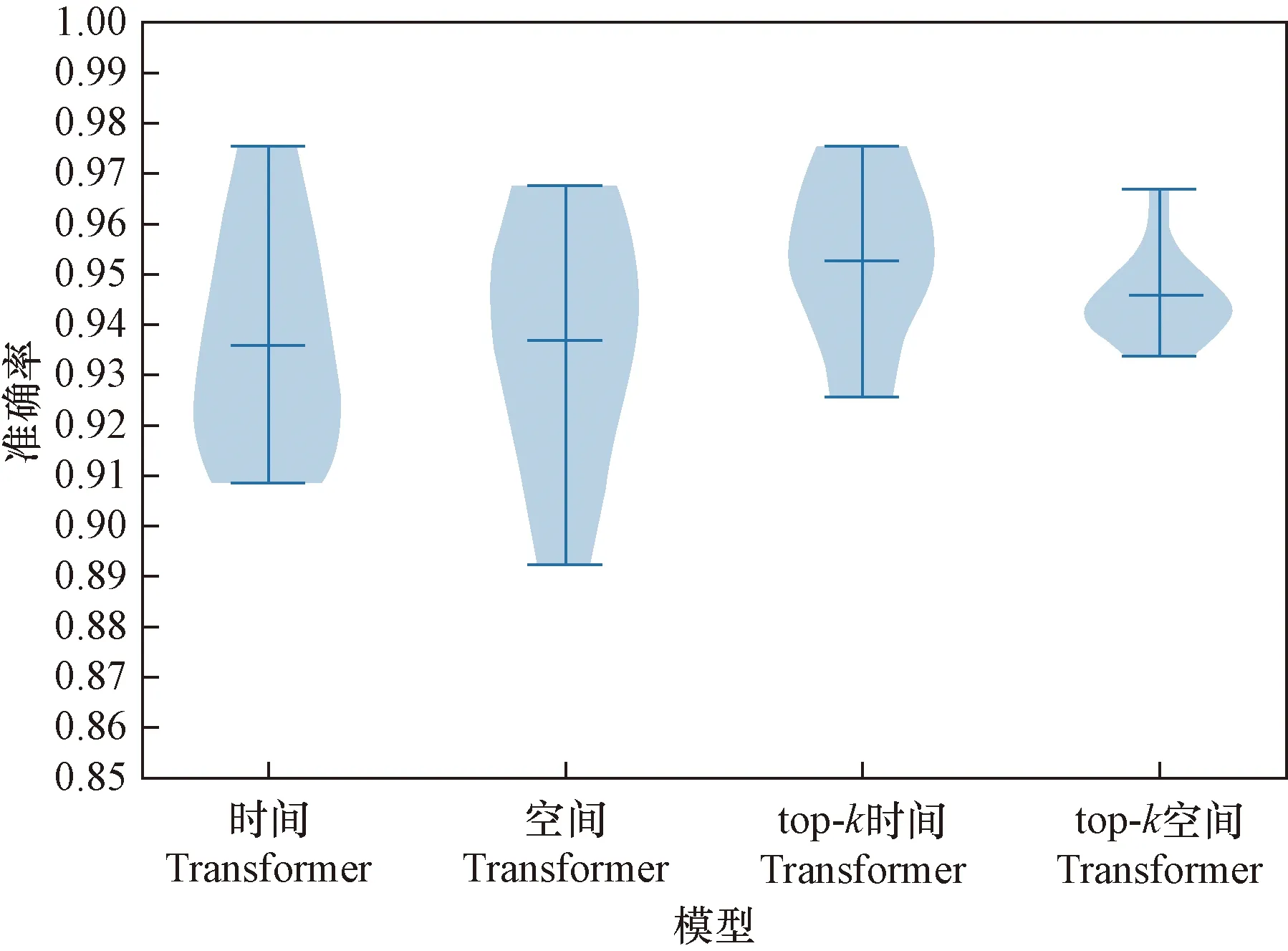
圖7 手勢(shì)腦電信號(hào)Transformer模型10折交叉驗(yàn)證準(zhǔn)確率Fig.7 Gesture EEG Transformer model 10-fold cross-validation accuracy
混淆矩陣表現(xiàn)了每一種分類情況的具體數(shù)量。混淆矩陣用來(lái)觀察每個(gè)類別的分類情況以及各類別錯(cuò)分的情況。混淆矩陣對(duì)角線上的數(shù)目代表了該類分類正確的數(shù)目。時(shí)間Transformer模型、空間Transformer模型、top-k時(shí)間Transformer模型、top-k空間Transformer模型10折交叉驗(yàn)證混淆矩陣如圖8所示。
據(jù)圖6~圖8可知,4個(gè)Transformer模型都取得較好的分類結(jié)果。自注意力的優(yōu)點(diǎn)是參數(shù)少、對(duì)算力要求少、可并行計(jì)算、對(duì)長(zhǎng)期依賴關(guān)系有著更強(qiáng)的捕捉能力。結(jié)果表明,采用自注意力機(jī)制的Transformer模型具有較好的性能。由于數(shù)字2和數(shù)字3手勢(shì)相關(guān)腦電信號(hào)相似性強(qiáng),容易混淆識(shí)別。在添加了top-k選擇后,注意力退化為稀疏注意力,將注意力都轉(zhuǎn)移到最具信息價(jià)值的數(shù)據(jù)上,top-k時(shí)間Transformer模型和top-k空間Transformer模型準(zhǔn)確率分別增加了0.017和0.008,手勢(shì)數(shù)字2和數(shù)字3還存在互相識(shí)別錯(cuò)誤,但是手勢(shì)數(shù)字2和數(shù)字3識(shí)別率上升。從表1可知,增添了top-k選擇的Transformer模型取得了更好的分類結(jié)果,top-k時(shí)間Transformer模型的結(jié)果優(yōu)于top-k空間Transformer模型,因?yàn)閠op-k時(shí)間Transformer模型選取的是最具信息價(jià)值的時(shí)間片段,而top-k空間Transformer模型選取的是最具信息價(jià)值的通道信息,通道信息中含有無(wú)關(guān)信息。另外,繪制了同種手勢(shì)EEG信號(hào)的各個(gè)Transformer模型最后一層的單個(gè)注意力頭的注意力權(quán)重,可以看到,因?yàn)閠op-k選擇,注意力權(quán)重主要集中在一小塊區(qū)域,從而提高了分類的精度。如圖9所示。
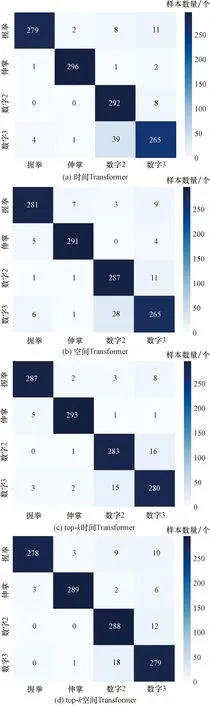
圖8 手勢(shì)腦電信號(hào)Transformer模型10折交叉驗(yàn)證混淆矩陣Fig.8 Gesture EEG Transformer model 10-fold cross-validation confusion matrix
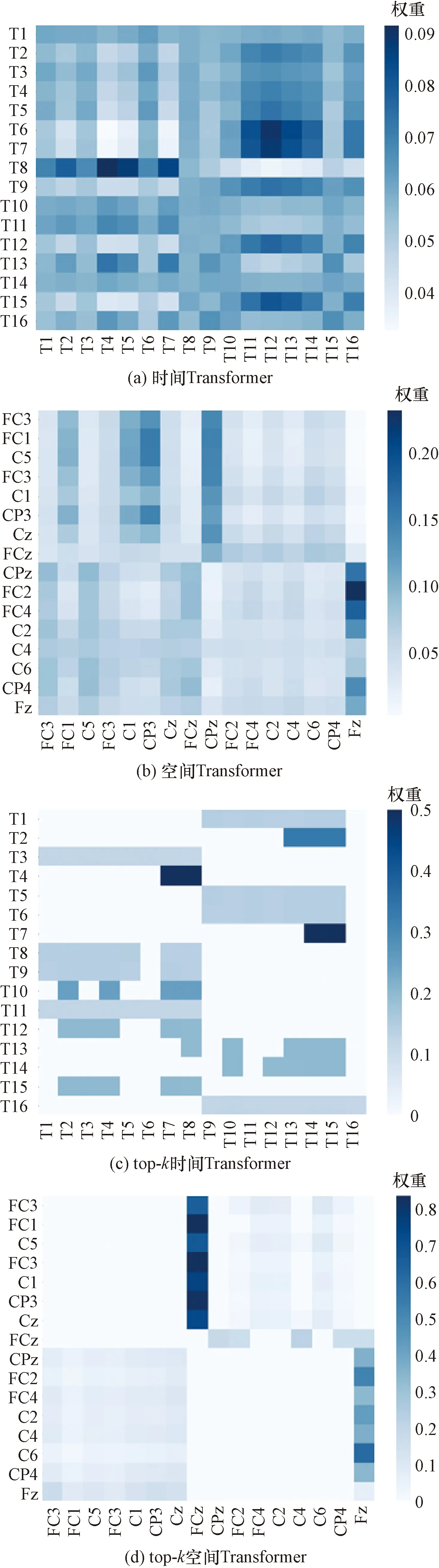
圖9 手勢(shì)腦電信號(hào)Transformer模型單個(gè)注意力頭的注意力權(quán)重Fig.9 The attention weight of a single attention head in the gesture EEG Transformer model
5 結(jié)論
為提高腦電信號(hào)與手勢(shì)動(dòng)作的信號(hào)關(guān)聯(lián)度,設(shè)計(jì)了4種實(shí)際手勢(shì)動(dòng)作,通過(guò)確定手勢(shì)運(yùn)動(dòng)的腦電信號(hào)通道選擇,設(shè)計(jì)腦電信號(hào)實(shí)驗(yàn)范式同步采集手勢(shì)動(dòng)作頭皮腦電信號(hào)。
為了去除眼電和肌電等偽影,設(shè)計(jì)了一種基于MEMD-CCA的混合去偽影方法,對(duì)腦電信號(hào)進(jìn)行二重分解、閾值處理和重構(gòu)。結(jié)合腦電數(shù)據(jù)結(jié)構(gòu)特點(diǎn)改進(jìn)了一種基于自我注意的Transformer模型識(shí)別方法,分別從時(shí)間維度和空間維度構(gòu)建了基于自我注意的Transformer模型及其變體top-k稀疏Transformer模型,改進(jìn)的Transformer模型取得了優(yōu)異的分類識(shí)別結(jié)果。
實(shí)驗(yàn)結(jié)果表明,Transformer模型適用于腦電信號(hào)分類識(shí)別,增添了top-k選擇的Transformer模型取得了更好的分類結(jié)果,top-k時(shí)間Transformer模型識(shí)別率最高,達(dá)到95.2%。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
鴨綠江(2021年35期)2021-04-19 12:24:18
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
考試與評(píng)價(jià)·高一版(2020年6期)2020-11-02 02:45:24
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年11期)2018-08-04 03:25:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
