基于用戶異常行為數據的個性化推薦模型研究
2023-04-04 00:30:58章群英房書豪章嘉愉王申奧
科海故事博覽 2023年9期
章群英,房書豪,章嘉愉,曾 瑩,王申奧
(嘉興學院,浙江 嘉興 314001)
數字經濟時代,信息的冗余和過載現象日益凸顯,精準定位用戶喜好并進行個性化推薦的運營方式成為大多數C 端企業的商業共識,可以有效地對信息進行過濾和篩選,幫助用戶以個性化的方式來檢索符合其需求的信息資源,緩解信息過載的個性化推薦系統[1],也成為當前的研究熱點。
個性化推薦系統是根據用戶對信息的反饋互動行為來判斷用戶和信息之間的匹配程度,從而向用戶進行信息推薦的一類數據分析系統,它通過獲取用戶的歷史行為數據,如網頁的瀏覽數據、購買記錄、社交網絡信息、用戶地理位置等,來推斷用戶偏好,并據此進行推薦[2]。由此可知,個性化推薦系統往往與用戶本身的興趣強相關,且興趣可以通過特定的行為來表現。這意味著用戶網絡行為產生的數據是推薦系統的重要數據源,換言之,推薦系統的推薦不精確問題,常常是因為無意義、偶發性且不能代表用戶偏好的數據所導致。
基于上述原因,本文通過分析偶發性用戶數據的產生原理,認為此類數據的產生原因是用戶在體驗系統服務的過程中發生的自身興趣的動態變化。并利用此結論,以用戶的異常行為數據為基礎,架構了一個可以精確篩選異常數據、輔助系統優化的理論模型。該模型可以在一定程度上提高傳統個性化推薦系統的推薦準確程度,提升用戶在使用相關服務時的體驗感。
1 模型原理概述
偶發性用戶數據也稱之為異常行為數據,是系統所捕捉到的用戶在使用系統時發生的用戶異常行為。這種行為往往不符合用戶在使用系統時的通常習慣,可以作為用戶興趣動態變化的標識,并由此進一步優化系統對用戶的精確推薦。本節將主要闡述興趣動態變化與用戶異常行為之間的內在聯系,討論哪些行為的捕捉對于系統分析用戶興趣更具有價值,并嘗試總結其行為規律。
1.1 用戶異常行為
個性化推薦系統的實質是通過理解用戶的興趣和偏好幫助用戶過濾大量無效信息并獲取感興趣的信息或者物品的信息過濾系統[3],但由于影響興趣變化的因素眾多,且興趣動態變化規律相對復雜,導致用戶異常行為也相應地出現難預知性、突發性和無周期性等特征。合理分析用戶異常行為的特征,是模型篩選有價值信息的基礎。
1.1.1 定義與特征
用戶異常行為是用戶個體做出的不符合自身網絡社交活動習慣的特殊行為,此類行為往往不符合用戶原有的喜好偏向,并表現為與原有喜好有較大差異甚至對立。譬如用戶點贊以往不喜歡的視頻類型,這一現象就會被視為異常現象。
用戶異常行為具有一些重要的特征:在內容上,表現為較強的難預知性。由于用戶異常行為的定義是用戶對“反常規偏好”做出的“反常規反饋”的反饋,因此在內容上會出現與原有偏好的較大差異,內容跳躍性強且無法被系統為用戶已建立的規律所感知。在時間上,表現為突發性、短時性、低頻性和無周期性。用戶異常行為的發生通常不會持續太長時間,既不會持續發生,也不會定期發生。
1.1.2 價值判斷推論
用戶異常行為可以具體細分為有價值和無價值兩種,異常行為的價值判斷取決于該行為數據對用戶自身的喜好分析是否具有實際意義。舉例而言,某用戶在短期內重復性瀏覽具有相同內容標簽但并不屬于該用戶傳統興趣偏好內容的信息,這有可能是因為該用戶的興趣偏好的確出現變化,也有可能是因為用戶錯誤操作(如忘記關閉APP、系統卡頓造成誤觸等)所導致。前者對于系統分析用戶興趣有優化作用,故可稱為有價值的用戶異常行為,后者則稱為無價值的用戶異常行為。
推薦系統為用戶所推薦的內容之所以時常出現某種偏差,核心就是因為對異常行為的錯誤的價值衡量,從而導致在篩選數據時忽略了部分有價值行為數據或提取了無價值行為數據。
1.2 用戶異常行為的價值判斷法
有價值的用戶異常行為有助于系統對用戶的內容偏好做出更精確的判斷,因而在系統篩選行為數據時,應當具有一個可靠穩定的篩選機制來獲取這些有價值的用戶異常行為數據并加以處理。對于價值判斷而言,其實質是判斷用戶的用戶異常行為是否滿足興趣動態變化規律。興趣動態變化規律分為興趣演化與興趣漂移兩種,相應的,用戶異常行為的價值判斷同樣具有兩種:用戶精力變化判斷和用戶經驗累積判斷。
1.2.1 用戶精力變化判斷
用戶精力變化判斷是基于興趣漂移規律的異常行為價值判斷,其目的在于篩選出關于興趣漂移的異常行為。興趣漂移規律被定義為用戶隨時間的改變而不斷發生興趣的動態變化,其主要方式是通過計算用戶隨時間的推移在其本身已有的不同偏好中分配的精力來推測用戶的主要興趣。基于此,用戶精力變化判斷的基本假設是:若用戶在其發生用戶異常行為前存在精力分配的變化趨勢,比如逐漸增加了導致用戶發生異常行為的偏好內容的關注,則可以判定用戶的異常行為是基于興趣動態變化現象所導致,故而可以判定其異常行為對于系統優化有利。
根據興趣漂移規律,這類行為的判定一般基于時間的長短。用戶分配在新偏好上的時間越多,則用戶的主要偏好朝著新偏好發展的可能性就越大。因此,對于精力判斷而言,時間序列分析方法將是必要的,并需要考慮到用戶對新內容的遺忘 程度。
1.2.2 用戶經驗累積判斷
經驗判斷則是與興趣演化相關。對于興趣演化規律,目前學界的基本假設是:用戶的興趣演化是伴隨一個可累積的因素的變化而產生的[4]。我們將這個可累積的因素總結為“經驗”。舉例而言,就是攝影愛好者隨著攝影經驗的增長而減少對非專業相機的偏好,轉而追求專業或專家級相機的情況。由此可以看出,精力變化判斷與經驗累積判斷的不同在于,前者考慮不同偏好的轉移,而后者考慮單個偏好內的深化。
這一判斷的核心在于用戶是否在發生異常行為前存在單一領域內經驗的增長進而達到某種興趣的質變,比如由于用戶接觸的知識水平的提高,用戶發生了對其偏好中更高層次的事物的喜好。同精力判斷一致,若確有此行為,則判定對系統優化有利。依從興趣演化理論的假設來看,這類行為的判定可以基于某種可累積因素的變化而產生。從興趣演化的現象來看,其本質應該是由用戶的學習能力所影響。
2 基于用戶異常行為數據的個性化推薦模型
2.1 模型結構
模型分為數據篩選模塊和個性化推薦模塊兩部分。其中,模型將異常行為檢測機制與興趣動態變化量化結合,從而提高數據篩選的準確度。模型既考慮到了興趣的動態變化也考慮到了時間效應對于用戶興趣的影響,提高了模型的預測精度。
在推薦系統中考慮一系列因子,包括項目信息、用戶信息和用戶行為信息。項目信息包括項目的說明、標簽等表征項目特征的信息;用戶信息包括用戶性別、語言偏好等;用戶行為信息包括用戶點贊、收藏、分享、評論等行為信息。
2.2 數據篩選模塊架構
數據篩選細分為用戶異常行為檢測和興趣動態變化的判斷。異常行為檢測模塊,利用項目信息、用戶信息和用戶行為信息的集成數據即預數據作為該模塊的輸入,最后輸出模型數據作為個性化推薦系統的輸入數據。
本文在模型訓練階段通過引入目標項目來訓練異常行為檢測模塊以做出自主判斷的能力。通過將用戶的瞬時興趣ki與目標項目ti串聯輸入到一個多層感知器MLP 中,多層感知器MLP 據此建模并輸出預測向量pi,若向量pi趨向于0,則用戶的瞬時興趣受到污染,即為異常行為數據,反之為正常行為數據。然后將異常行為數據作為興趣動態變化判斷模塊的輸入數據。

表1 模型模塊功能簡述
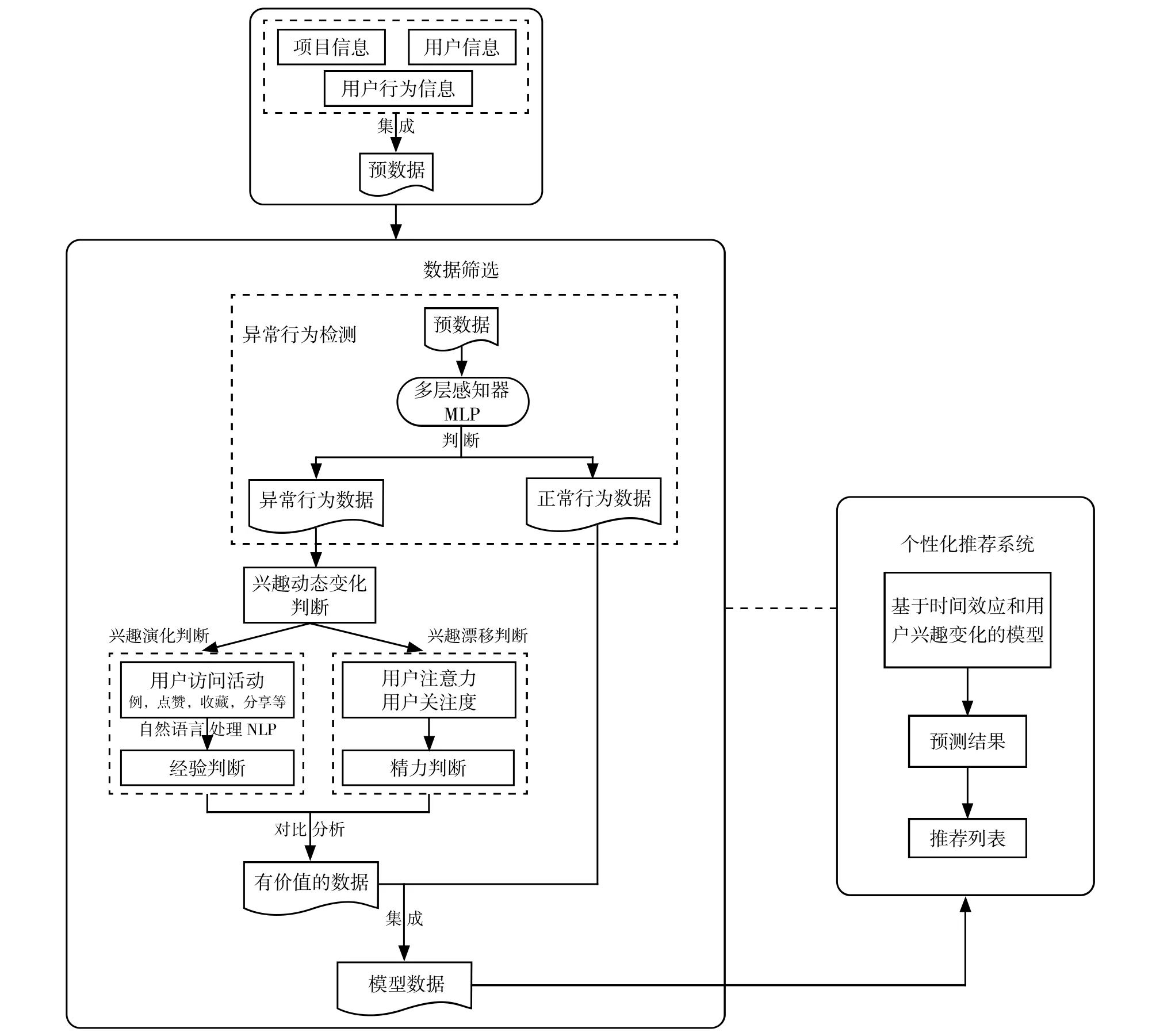
圖1 基于用戶異常行為的個性化推薦模型
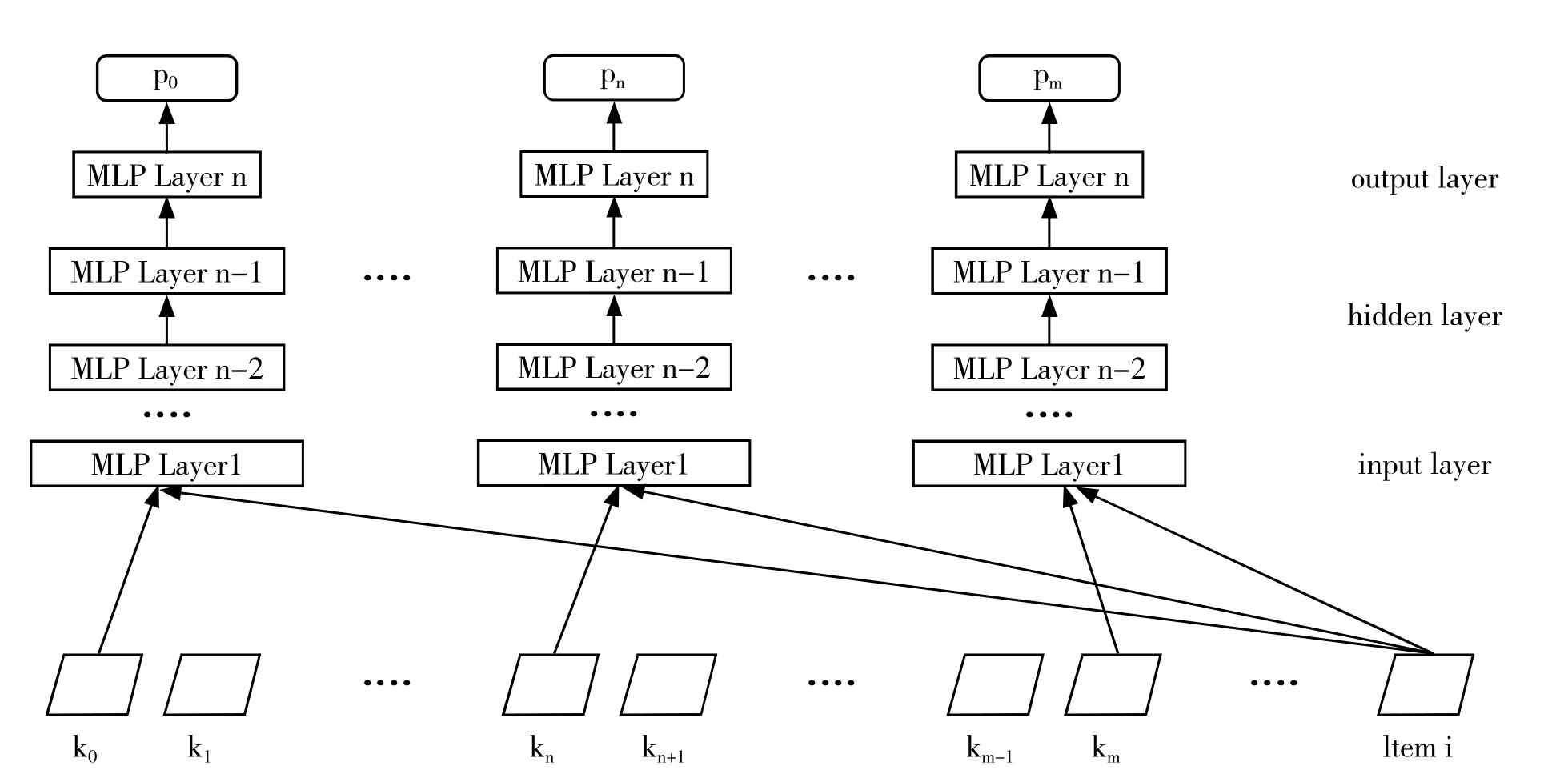
圖2 用戶異常行為監測示意圖
在興趣動態變化判斷中,分別對用戶具體的學習狀態數據、具體的歷史數據以及訪問頻率進行經驗和精力判斷。因用戶的評論行為可在多場景觸發,若不對用戶評論的內容進行控制,則無法精準地進行經驗判斷。因此,本文采用自然語言處理方法(NLP)的意見挖掘進行情感判斷,利用訓練好的情感分類器對用戶評論的內容進行判斷。通過選取情感詞作為特征詞并統計各特征詞的詞頻,再利用情感分類器對文本進行積極(正向)和消極(負向)的二分分類。例如,“華為手機非常好”表達的是正向情感,“華為手機使用起來很卡頓,不好用!”表達的是負向情感。
通過對比分析用戶的經驗和精力,從而區分有價值數據和無價值數據。若用戶在該領域上既無經驗也無精力,則為無價值數據,反之則為有價值數據且需召回到正常行為的數據中。
2.3 個性化推薦模塊
通過研究用戶的點贊、分享等訪問行為實現用戶興趣點的檢測和推薦,點贊、分享等行為具有序列性,這對預測用戶的行為和興趣具有重要意義。但基于用戶興趣的特征,使得推薦系統要滿足動態和適應性強的特點,且能考慮項目的時效性和用戶興趣的動態變化,從而做出相應的響應。
因此,在個性化推薦模塊采用基于時間效應和用戶興趣變化的模型,該模型分為信息時效性過濾和預測推薦兩部分。在信息時效性過濾部分,將艾賓浩斯遺忘曲線與傳統的協同過濾算法結合,對相似用戶集進行時效性劃分以避免冗余用戶和項目對推薦結果的影響。在預測推薦部分,將通過項目時效性及用戶的動態興趣變化計算得到的概率矩陣和隨機游走算法結合,從而實現對個性化推薦系統的優化。
3 結語
用戶網絡行為作為最能反映用戶興趣偏好的數據,一直是推薦系統進行推薦的主要依據。本文闡述了用戶異常行為帶來的數據偏差是推薦系統推薦不精準的原因,并對興趣動態變化與用戶異常行為進行了概念梳理,提出了異常行為檢測與價值判斷串聯的方法。基于此,本文通過整合興趣的動態變化與時間效應對于用戶興趣的影響,提出了一種基于興趣動態變化的個性化推薦模型。該模型在理論上可以在一定程度上優化個性化推薦系統的數據篩選能力,進而提升系統對于用戶的精準推薦能力。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
文理導航·科普童話(2016年7期)2017-02-04 15:09:20
商用汽車(2016年11期)2016-12-19 01:20:16
小天使·四年級語數英綜合(2016年11期)2016-11-29 22:37:30
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
