基于CPU-GPU的有序統計類恒虛警檢測優化
2023-04-21 13:10:28火靜斌張曉濱
計算機技術與發展 2023年4期
火靜斌,張曉濱,田 澤
(1.西安工程大學,陜西 西安 710048;2.集成電路與微系統設計航空科技重點實驗室,陜西 西安 710068)
0 引 言
在雷達系統中,恒虛警率檢測技術(CFAR)通過動態調整檢測門限來檢測背景雜波干擾下的目標。為了估計雜波功率,需要對每個雷達回波樣本進行大量的計算。雷達系統需要高吞吐量和低延遲,傳統的CFAR處理通常使用現場可編程門陣列(FPGA)或數字信號處理器(DSP)[1-2],但也存在一定的問題,如開發周期長、調試難度大、耗費資源等。隨著GPU統一渲染架構的出現,基于CPU-GPU的異構計算體系結構開始普及,OpenCL、CUDA等開發平臺簡化了GPU編程難度,基于異構計算平臺的GPU開發環境已廣泛應用于雷達信號處理領域[3-6]。
在雷達應用中,有多種方法可以實現恒虛警檢測,比如經典的單元平均恒虛警檢測技術(Cell Averaging CFAR,CACFAR)、平均選大(Greatest of CFAR,GOCFAR)和平均選小恒虛警檢測技術(Smallest of CFAR,SOCFAR)。但是在需要多目標或高性能的應用環境中,有序統計類恒虛警檢測技術的應用范圍更廣[7]。與其他檢測方法不同的是,OSCFAR的內部實現更為復雜,屬于計算密集型方法,需要高性能計算設備。文獻[8]在Tesla C1060 GPU上研究了PD雷達中CACFAR的GPU實現,通過對算法進行了優化,提高了算法的并行性,達到了一定的加速效果。文獻[9]利用OpenCL在集成顯卡以及中等級別產品AMD GPU實現CACFAR,但由于使用零填充方法,容易造成程序虛警。文獻[10]利用積分圖像算法加速了并行均值濾波算法,但需要兩個內核函數上分別實現計算并行前綴和以及平均值,會產生額外的計算以及對共享內存的不必要訪問。文獻[11]在GPU端采用Blelloch掃描算法來對CA-CFAR求和過程進行優化,避免了重復計算,但存在的問題是數據必須是以二的指數冪格式傳輸。文獻[12]提出的局部最大最小快速濾波是一種充分考慮數據重用的算法,可以用來解決GOCFAR、SOCFAR的數據重用,但存在邊界溢出的問題。
以上都是對均值類恒虛警檢測算法進行了GPU加速實現,而對OSCFAR加速的研究還比較少。文獻[13]在FGPA上設計實現了可以規避排序算法的OSCFAR,但是如果需要排序值計算信噪比時不能滿足系統要求。文獻[14]設計了重復快速排序算法,但快速排序不適合在GPU上進行計算。文獻[15]提出了具有分布式直方圖的OSCFAR的計算方法,但是需要一定的計算量。文獻[16]提出了基于“掃雷算法”的OSCFAR算法,適合并行計算,但是需要利用第三方工具做預處理排序。
該文的研究重點是在OSCFAR中使用GPU進行加速,提出了一種改進的OSCFAR方法,使其適用于GPU并行實現。首先,設計了一個預處理程序,對每個多普勒通道進行數據擴充。在預處理程序中,為了減少GPU處理中的分支操作,對每個多普勒通道數據進行擴充,大小為左右保護單元以及參考單元數量之和,從而優化設備計算效率。其次,設計并實現了CPU-GPU異構架構下OSCFAR的并行加速方法。根據GPU的顯存大小,將原始數據按時間順序劃分為若干個子數據并傳輸到GPU。為了優化計算效率,預處理程序分配給CPU執行,之后OSCFAR由GPU執行。為了證明所提出方法的可行性,在雷達模擬噪聲信號為瑞利噪聲背景條件下,對有序統計類恒虛警檢測方法進行了仿真實驗。在實驗中,所提出的方法消耗時間是僅在CPU上運行的OSCFAR所消耗時間的1/60,且目標信號質量并沒有降低。
1 有序統計類恒虛警處理方法分析
在瑞利背景條件下,假設v(t)是單脈沖檢測中某個分辨單元的一個觀測值,當使用平方律檢波器進行檢波時,可寫成如下形式:
D(v)=I2(v)+Q2(v)
(1)
其中,I(v)表示信號的同相分量,Q(v)表示信號的正交分量。在一般的雜波環境中,可以認為接收到的雜波的包絡服從瑞利分布。在均勻的瑞利雜波背景條件下,單元平均方法就是利用檢測單元周圍的前沿滑窗和后沿滑窗中的一組獨立同分布的參考單元采樣的平均值來估計雜波功率水平的。有序統計類(Order Statistics)OSCFAR是采用統計手段來估計雜波水平功率。該方法和常規均值類CFAR的區別是其在多目標環境下檢測性能較好,但是在雜波邊緣環境和均勻環境下會存在一定的損失,如圖1所示。
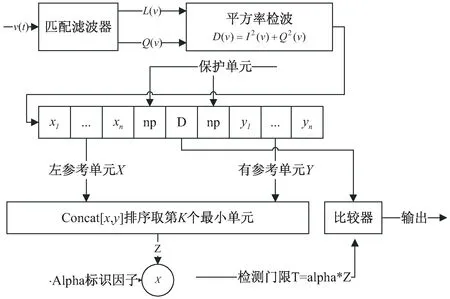
圖1 有序統計類CFAR檢測方法
數據經過平方率檢波得到距離多普勒功率譜,對每個待檢測單元D選取參考單元(xi(i=1,2,…,n),yj(j=1,2,…,n)),為了防止目標的能量泄露到參考單元造成雜波功率估計值較高,一般在檢測單元兩側選取一定的保護單元(np)。OSCFAR算法是將待檢測單元兩側參考單元(ns)拼接后進行排序,得到一個遞增序列。然后取第K個有序值作為雜波水平的估計值,一般條件下K的取值和rate相關,具體計算方式為K=rate*2n。OSCFAR的虛警概率PFA與門限因子α的關系如下:
(2)
一般條件下,虛警概率PFA為固定概率值,由此計算得到門限監測因子α,檢測門限T為門限監測因子與有序值K的乘積。將待檢測目標單元與檢測門限進行比較,如果待檢測單元的功率值大,則判決為目標,否則判為雜波。
從有序統計類恒虛警檢測圖中可看出,均值類恒虛警檢測方法CACFAR是每一個采樣點需要完成一次求和運算,這樣可以通過并行掃描的方式避免大量的重復運算。例如Blelloch算法是在GPU端計算掃描的方法,避免了CPU完成掃描處理時主機段與設備端之間的傳輸時間。而OSCFAR與CACFAR的區別在于中間的排序過程,會耗費系統大量的資源。為此,如何選擇適合GPU并行的排序算法以及對完整流程的并行化設計是OSCFAR加速研究的重點。
2 基于GPU的有序統計類恒虛警檢測并行化技術
脈沖多普勒雷達信號處理系統常用的算法模塊包括脈沖壓縮、動目標信號顯示、動目標檢測、恒虛警檢測。雷達信號在經過前三個步驟之后可以得到大小為Np*Ns的二維矩陣,針對該矩陣進行距離維CFAR檢測時,各個脈沖之間不存在聯系,可以同時進行Np個脈沖的CFAR檢測,因此存在數據集的并行。針對有序統計類的檢測算法而言,處理主要有平方率檢波、每個單元的雜波功率估計(包括窗口排序)、檢測門限計算以及待檢測單元的比較,都可以由GPU的多個線程完成。因此,OSCFAR具有較好的數據以及線程級別的可并行性。
2.1 有序統計類恒虛警檢測的GPU實現
基于OpenCL的OSCFAR處理流程如圖2所示,采用以單個脈沖為單位進行OSCFAR,單個脈沖內的平方率檢波,兩側參考單元的排序,以及待檢測單元的分支可以由多個線程并行實現。
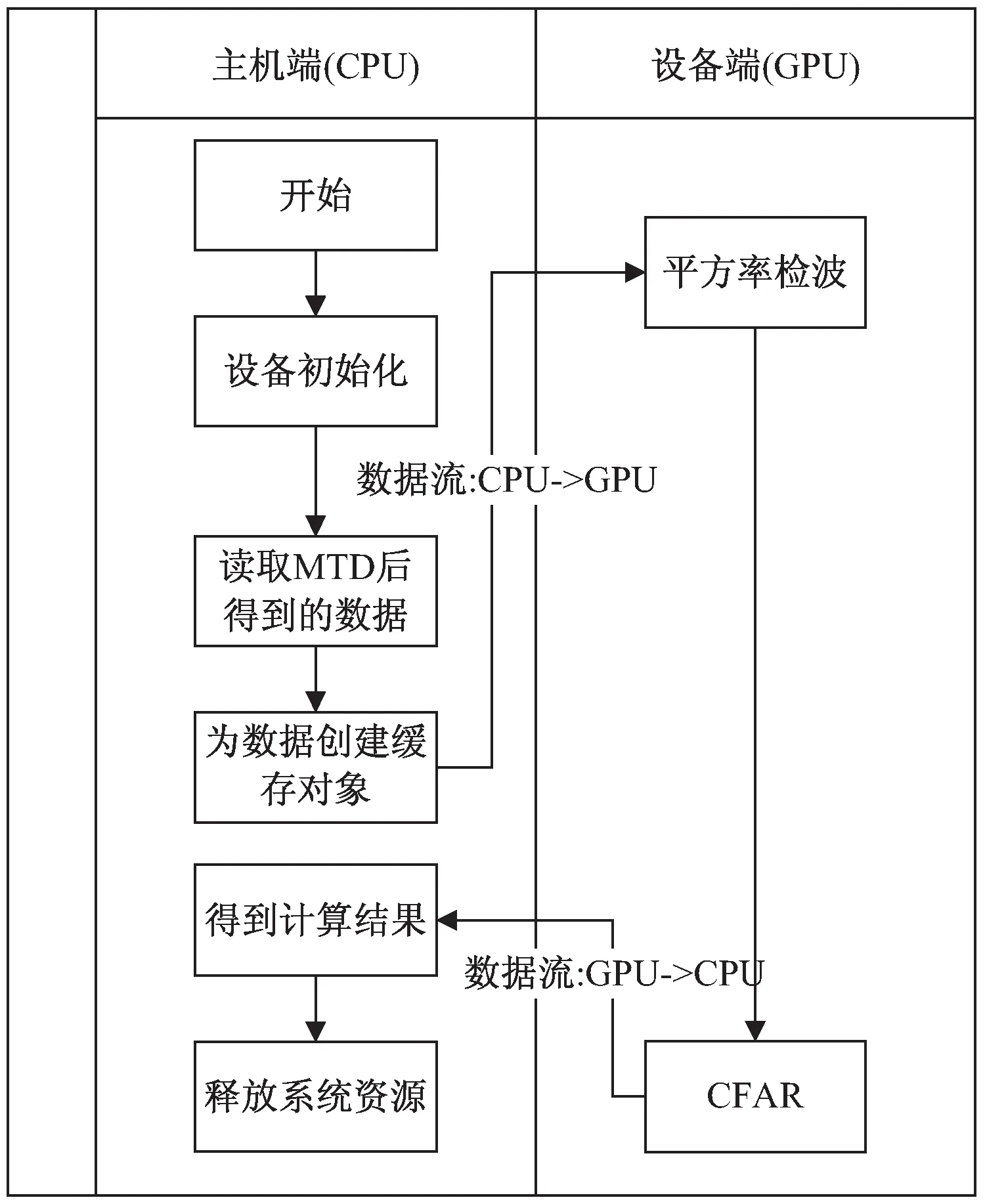
圖2 基于OpenCL的OSCFAR處理流程
大小為Np*Ns的數據從主機端傳到設備端后,按照流程可以將算法分解為兩個模塊依次對應兩個內核函數,第一個內核函數平方率檢波主要將復數信號轉化為實數信號,數據格式為實部虛部交替存儲,即連續兩個數據分別是信號的實部和虛部,一般采用OpenCL內建矢量數據類型表示。若采用一維尋址的方式,設置合適的workgroup大小p,則需要的workgroup數量為Np*Ns/p記為q,每個線程完成一個平方律檢波計算,總的計算組織架構如圖3所示。

圖3 平方率檢波處理流程
第二個內核函數主要用于計算雜波功率水平估計以及與實際值進行判斷,若采用一維尋址的方式,設置workgroup大小,每個線程進行一個信號的雜波水平估計與判斷。假設單側參考單元大小為nr,單側保護單元大小為np,由此可以將距離維度的數據劃分為三個部分:對于前nr+np個元素來說,如果要填充左右數據的話可以從右側取2*(nr+np)個元素對其排序后將第K個有序值作為待檢測單元的估計值,對于最后nr+np個元素取其左側2*(nr+np)個元素,中間部分的話直接從左右兩側各取nr+np個元素。將兩側數據排序取K值作為雜波功率的估計值,最后將估計值與實際值作對比確定是否為目標對象。
2.2 算法優化
優化1:數據填充。
在估計雜波功率水平時,需要將距離維度的數據劃分為三個部分,即需要三個分支操作來進行各自的計算。由于GPU的設計不善于處理分支判斷,因此需要將每個線程進行統一操作。采取的辦法是數據擴充,擴充的方法如圖4所示。如果填充數據零的話,對于均值類CFAR和有序統計類OSCFAR來說,將導致雜波功率估計值變小,從而導致檢測門限變小容易造成虛警[9]。因此,可以采取的方法是將原數據做復制,不論是鏡像復制還是按序復制都會對這兩類數據結果產生影響較小,在實驗中采用按序復制一側的方法。

圖4 數據填充方式
優化2:排序分析。
得到數據后將兩側數據合并,利用合適的排序算法得到雜波功率的估計值。采取的排序算法可以是傳統的冒泡排序算法以及快速排序,由于只需要遞增排序前K個元素,對于冒泡排序來說,時間復雜度可以降為O(K×N)。當數據量過大時,排序過程可能成為程序瓶頸,快速排序具有良好的執行效率可以提高性能,但由于OpenCL平臺限制,GPU執行的機器代碼僅包含分支和循環,一般情況下,對于函數調用來說編譯器會將函數轉換為內聯函數,但是對于遞歸調用來說無法做到。因此,對于高效的快速排序無法應用到本項目場景中。
為此,解決的辦法是采用雙調排序。雙調排序是基于Batcher定理的一種適用于數據并行的排序算法,首先需要生成一個雙調序列(有一個非嚴格遞增序列和一個非嚴格遞減數列),然后將該序列劃分為兩個子序列(左邊的雙調序列小于右邊的序列),繼續對每個子序列進行劃分直到序列長度為1,就可以得到單調遞增的序列。
優化3:內存優化。
對于平方率檢波內核函數來說,AMD系列GPU支持的最大workgroup大小為256,為此可以將交替存儲的實虛數拷貝到本地內存中,減少函數對全局內存的訪問,提高設備計算能力。除此之外,可以在程序中使用頁鎖定(Page-Locked)內存分配方式,操作系統不需要對其分頁也不需要將其交換到磁盤上,可以將其一直置于物理內存中,GPU根據其物理地址直接與主機進行數據的復制與傳遞,可以獲得更好的加速性能。
對齊訪問全局內存對于AMD系列以及Nvida系列GPU來說都會提高GPU性能。本實驗中,在主機端對數組數據進行手工填充比較復雜,該文采用了OpenCL引入的clEnqueueWriteBufferRect命令將主機端數據拷貝到設備端。在創建緩存時,用來確定的列數是滿足對齊后所需的數據。對于一維的大小為256的workgroup來說,列數應該四舍五入到最近的256的倍數。
3 實驗評估
實驗中用到的GPU硬件平臺分別為Intel(R) HD Graphics520和AMD Radeon R7 M370。CPU為Core(TM)i5-6200U CPU@2.30 GHz。所使用的數據是由Matlab仿真的線性調頻信號,其主要參數如表1所示。

表1 模擬信號參數
3.1 優化實驗結果對比
由之前的模擬數據可知,采樣頻率(fs)為2.0×106,雷達發射脈沖重復周期(PRT)為4.096×10-3,則單個脈沖周期的采樣點數fs*PRT為8 192。脈沖數量為16,則總的采樣點數為16*8 192。雷達信號在經過脈沖壓縮、MTI、MTD之后可以得到大小為16*8 192的二維復數矩陣。由于存儲的數據格式為實虛部交替存儲,交由主機端存儲時數據16*8 192*2。首先,數據在經過平方率檢波內核函數時,相鄰兩個數據之間分別是采樣點的實部與虛部,將二者的平方和存入該線程的寄存器中。其次,針對該矩陣進行距離維CFAR檢測時,采用一維尋址方式,設置全局工作組大小16*8 192,由于workgroup中的work-item不存在數據共享,并未設置本地workgroup大小。處理雜波功率水平估計采用有序統計類方式,測試穩定后取三次實驗結果,表2給出了CFAR在CPU和GPU上運行時間對比。

表2 CPU與GPU運行時間以及加速比
其中,Graphics520執行期間,兩個內核函數(平方率檢波,雜波估計與判別)分別耗費的時間為0.251 ms、99.111 ms。由表2可以看出,并行化后的恒虛警檢測在GPU上有著良好的性能。經過算法優化后的OSCFAR方法實驗結果如表3所示。優化后系統的執行時間較優化前縮小到原來的1/7,實驗證明,該方法加速效果明顯。

表3 優化前后的執行事件對比
3.2 算法優化實驗結果分析
對于OSCFAR來說,優化的方面分別是將條件分支通過數據擴充解決、排序算法的合理使用和內存優化。本實驗采用不同的策略在16個雷達脈沖,在每個脈沖的采樣點數為8 192的條件下進行了分支與數據填充實驗分析,得到的實驗結果如表4所示。
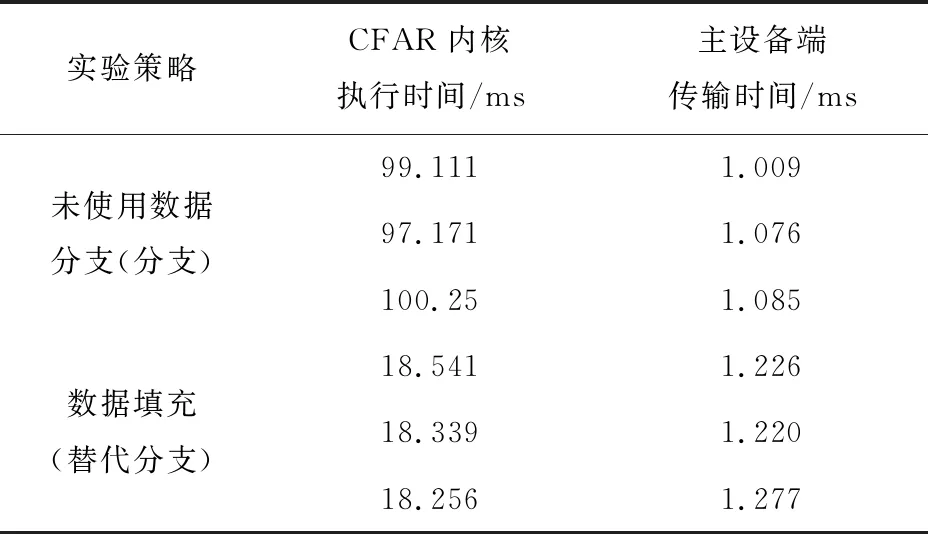
表4 分支與數據填充實驗分析
對于數據擴充來說會影響到兩個方面,首先是在主機端(CPU)擴充了數據,對于每個雷達脈沖的8 192個采樣點來說,只會在其兩側分別添加保護單元和參考單元的總數,導致數據傳輸時間會受到一定的影響。其次就是減少數據流分支,對于工作組中的線程執行同樣的操作會對GPU執行效率產生了近5倍的性能提升,對整體的優化有著顯著的提升。
除此之外,有序統計類恒虛警檢測中的排序算法也會對GPU執行效率有一定影響,實驗中采用了改進過的冒泡排序和雙調排序來對參考單元數量進行排序,數據采用填充過的雷達信號數據,實驗結果如表5所示。分析算法中存在的瓶頸,通過設計更加合理、更加具有并行性的排序算法,對估計每個待檢測單元的功率值的GPU執行效率有了近1.5倍的性能提升。
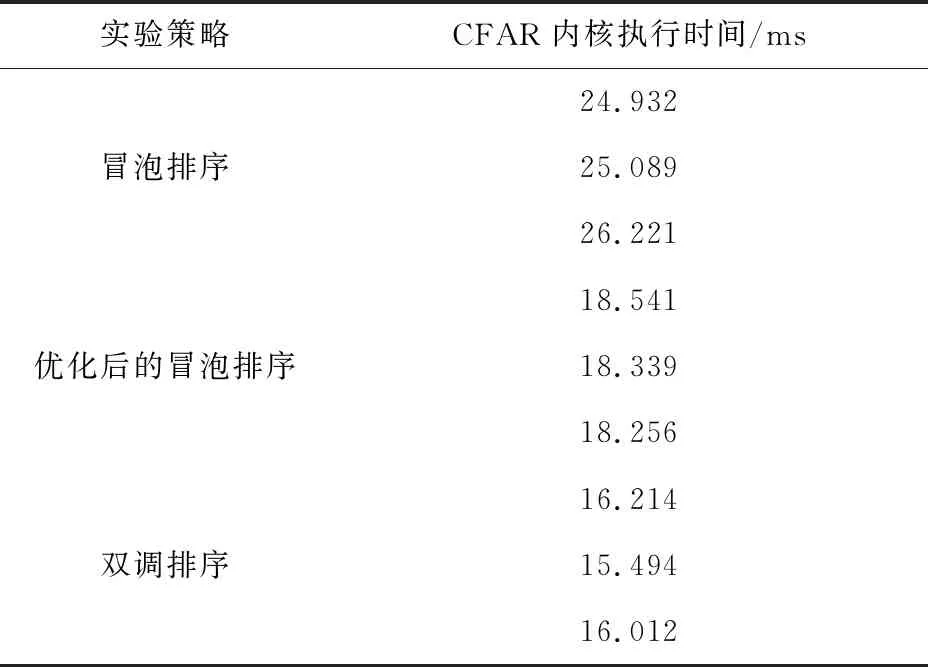
表5 排序算法實驗分析
對于OSCFAR中的兩個內核函數都可以在內存優化方面有一定的空間,采用的方法就是減少對全局內存的訪問,利用本地內存提升效率。利用頁鎖定機制,系統不需要進行分頁也不需要置換內存,可以獲得較好的加速性能。缺點就是如果數據量過大的話,一旦沒有足夠的物理內存供程序使用,系統性能有所下降。通過循環展開將平方率檢波后的二維數據映射到OpenCL二維空間,提升計算部件的利用率。實驗結果如表6所示:算法經過頁鎖定機制以及內存訪問對齊后的性能有所提升。

表6 主存與循環展開實驗分析
3.3 誤差分析
圖5展示了OSCFAR在CPU端和GPU端的目標檢測對比結果,二者處理結果近乎一致。在處理待檢測功率估計值時將CPU與GPU的數據做誤差分析,得到的結果如圖6所示,其絕對誤差小于3×10-3,且GPU具有更好的數據精度。
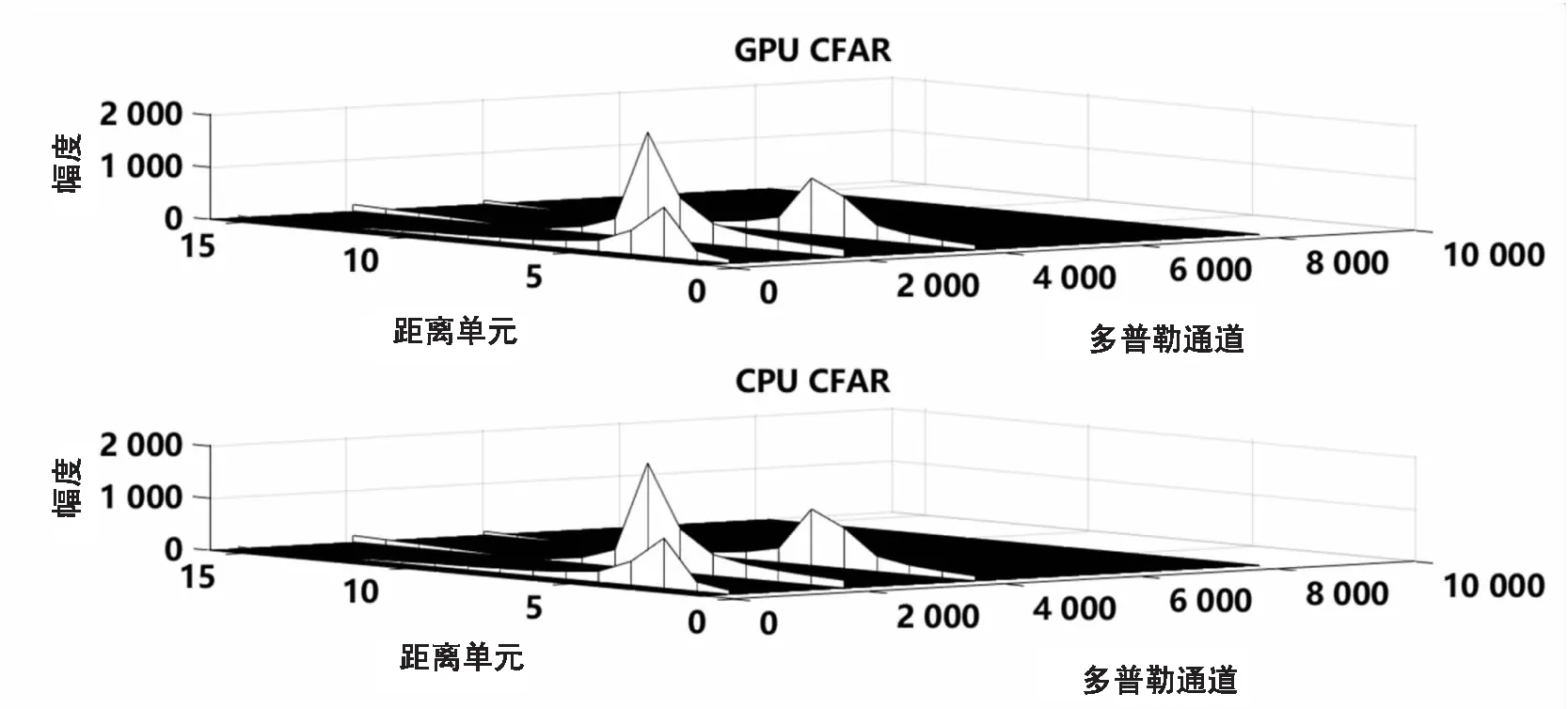
圖5 OSCFAR CPU與GPU處理結果
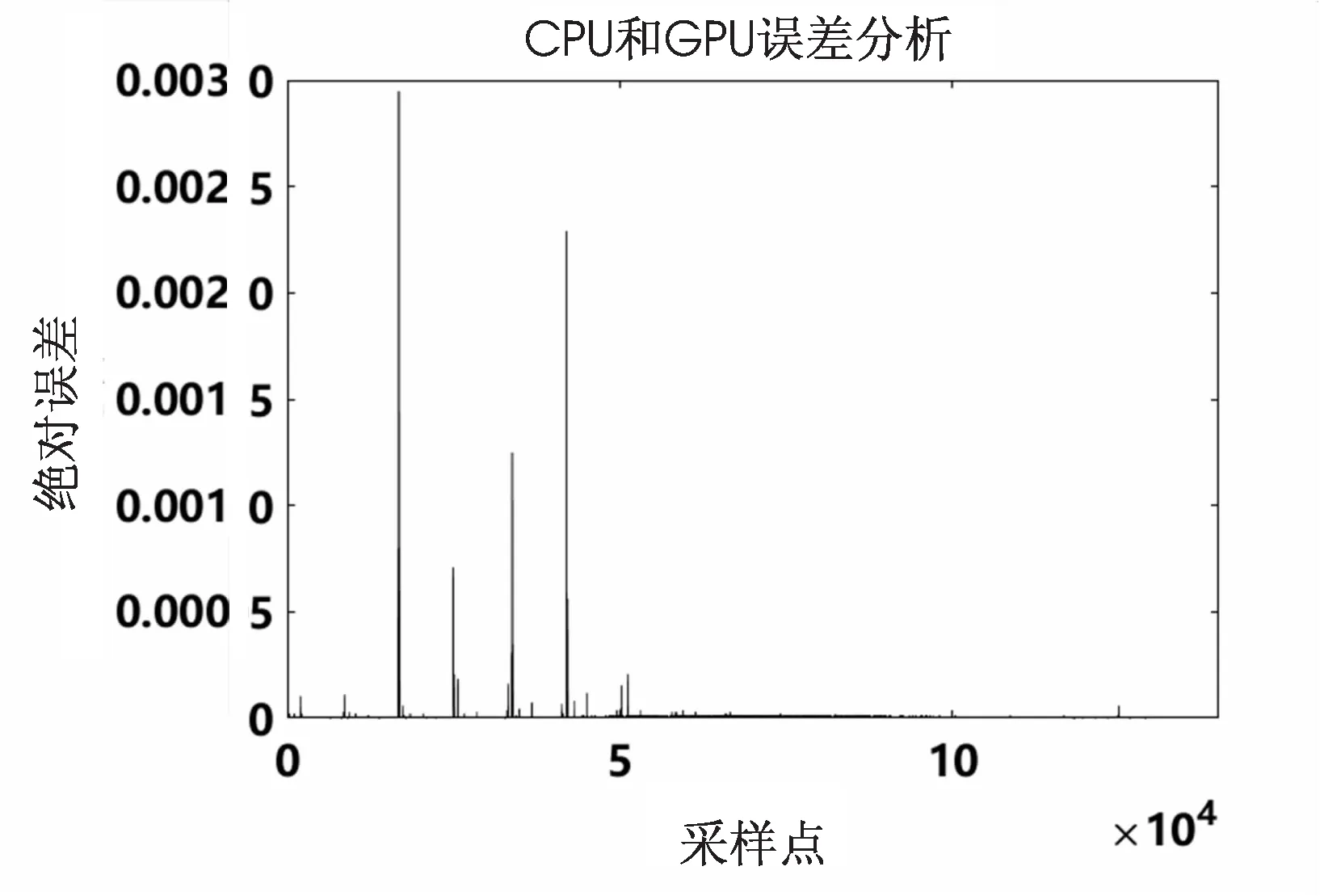
圖6 CPU和GPU誤差分析結果
4 結束語
提出了一種基于GPU的恒虛警檢測并行處理方法,通過對原數據進行填充、采用雙調排序并行化等優化策略來實現GPU加速。基于OpenCL通用異構平臺的GPU加速滿足了雷達信號處理高性能要求,在集成顯卡以及中等級別的AMD顯卡上可以達到60倍左右的加速比,本研究為后續基于國產GPU的加速積累了經驗。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
