基于特征融合的無人駕駛多任務感知算法
2023-04-29 10:02:57孫傳龍趙紅崔翔宇牟亮徐福良路來偉
復雜系統與復雜性科學 2023年3期
孫傳龍 趙紅 崔翔宇 牟亮 徐福良 路來偉

摘要: 為提高無人駕駛汽車感知系統硬件資源利用率,構建了一種基于特征融合的無人駕駛多任務感知算法。采用改進的CSPDarknet53作為模型的主干網絡,通過構建特征融合網絡與特征融合模塊對多尺度特征進行提取與融合,并以7種常見道路物體的檢測與可行駛區域的像素級分割兩任務為例,設計多任務模型DaSNet(Detection and Segmentation Net)進行訓練與測試。使用BDD100K數據集對YOLOv5s、Faster R-CNN以及U-Net模型進行訓練,并對mAP、Dice系數以及檢測速度等性能指標做出對比分析。研究結果表明:DaSNet多任務模型在道路物體檢測任務上,mAP值分別比YOLOv5s和Faster RCNN高出0.5%和4.2%,在RTX2080Ti GPU上達到121FPS的檢測速度;在占優先權與不占優先權的可行駛區域上分割的Dice值相較于U-Net網絡分別高出了4.4%與6.8%,有較明顯的提升。
關鍵詞: 無人駕駛;多任務;特征融合;道路物體檢測;可行駛區域分割
中圖分類號: TP391文獻標識碼: A
Multi-task Sensing Algorithm for Driverless Vehicle Based on Feature Fusion
SUN Chuanlong1,ZHAO Hong1,CUI Xiangyu2,MU Liang1,XU Fuliang1,LU Laiwei1
Abstract:In order to improve the utilization of hardware resources of driverless vehicle perception system, a multi-task driverless vehicle perception algorithm based on feature fusion is constructed. The improved CSPDarknet53 is used as the backbone network of the model, and multi-scale features are extracted and fused by constructing feature fusion network and feature fusion module. The detection of 7 common road objects and pixel-level segmentation of the driving area are taken as examples. Multi-task DaSNet (Detection and Segmentation Net) is designed for training and testing. In order to compare model performance, BDD100K data set is used to train YOLOv5s, Faster R-CNN and U-NET models, and comparative analysis is made on mAP, Dice coefficient and detection speed and other performance indicators. The results showed that DaSNet multi-task model′s mAP value is 0.5% and 4.2% higher than YOLOv5s and Faster RCNN, respectively, and the detection speed of 121FPS can be achieved on RTX2080Ti GPU. Compared with U-NET network, Dice value of segmentation in priority and non-priority drivable are 4.4% and 6.8% higher, showing an obvious improvement.
Key words: driverless vehicle; multi-task; fature fusion; road object dection;driveable area segmentation
0 引言
目前,無人駕駛已經成為眾多國家的發展戰略之一,其中,感知系統[1-3]作為無人駕駛汽車中不可或缺的部分之一,對環境的感知適應性、實時性直接影響了無人駕駛汽車的安全性和可靠性,而目標檢測、語義分割作為感知系統中的兩大任務,其效果將直接影響無人駕駛汽車決策系統的決策質量。
近年來,深度學習[4]在目標檢測、語義分割領域的應用取得了重大的突破,這很大程度上歸功于大型數據集、計算機強大的計算能力、復雜的網絡架構和優化算法的進展。在目標檢測領域,兩階段算法與單階段算法是目前兩大類基于深度學習的目標檢測算法,其中兩階段算法主要有R-CNN[5],其改進后的Fast R-CNN[6]以及Faster R-CNN[7],這類算法需要先從圖像中選取候選框,再對候選框進行分類與回歸,雖準確率較高,但繁瑣的檢測步驟容易導致出現檢測速度較低,實時性較差等問題。以YOLO[8]為代表的單階段算法具有端到端的網絡結構,具有較高的檢測速度,同時,由于巧妙的網絡設計方式使其具備令人滿意的檢測準確率。在圖像語義分割領域,基于區域分類的圖像語義分割和基于像素分類的圖像語義分割是目前主流的基于深度學習的語義分割方法,前者先將圖像劃分為一系列目標候選區域,通過深度學習算法對目標區域進行分類,避免了超像素的生成,有效提高了圖像分割效率,其代表有MPA[9]、DeepMask[10]等;后者則是以像素分類的方式直接利用端到端結構的深層神經網絡進行分割,避免了生成候選區域算法缺陷帶來的問題,其代表有DeepLab[11]、ICNet[12]、U-Net[13]等。
以上算法雖然都在對應的感知系統各項任務中取得了較好的效果,但“一項任務對應一種算法模型”的方式,忽略了感知系統各項任務特征之間的聯系,這不僅加劇了感知系統的計算負擔,而且降低了無人駕駛汽車中有限硬件資源的利用率。本文針對這一問題,通過整合感知系統各項任務特征之間的聯系與各項任務的算法結構特點,提出了一種基于特征融合[14]的端到端的多任務算法模型DaSNet(Detection and Segmentation Net),挖掘多任務之間的信息,通過算法自學習來優化各項任務損失的權重,得到最佳權重配比,且構建了可行駛區域分割與道路目標檢測的多任務輕量化網絡,在提高了無人駕駛道路環境感知系統中硬件資源的利用率的同時提升了檢測與分割任務的精度。
1 DaSNet算法結構
DaSNet整體算法結構如圖1所示,該模型由主干網絡、特征融合網絡、道路物體檢測層以及可行駛區域分割網絡四部分組成。
輸入數字圖像經過特定的預處理操作后輸入到主干網絡,提取不同抽象等級的特征,并將得到的不同的尺度特征圖輸入到特征融合網絡中,在特征融合網絡中經過多次上采樣與卷積操作,與其它特征圖融合以增強特征表達能力,最終輸出融合后3種尺度的特征圖;道路物體檢測層分別在3個特征圖上進行檢測并輸出車輛、行人以及路標等道路物體的預測信息。同時,可行駛區域分割網絡將來自主干網絡的可行駛區域的通用語義特征,即待預測圖像中的淺層語義信息和圖像內容信息,與來自特征融合網絡的特征包含車輛行人等可能阻礙汽車前進的物體的類別與位置信息通過Fusion融合模塊進行自底向上的特征融合,恢復圖像細節與分辨率,實現對圖像中可行駛區域的像素級預測,進而達到在一個模型上同時完成兩類任務的效果,其網絡的構建為本文的重點。
1.1 主干網絡
主干網絡作為整個模型的前置部分,負責提取圖像中的信息,生成特征圖,供后置功能網絡使用。本文改進了CSPDarknet53作為模型的主干網絡,主要由改進的Focus層,卷積塊CBL(Conv+Batchnorm+Leaky ReLU),殘差單元(ResUnit),跨階段局部單元CSP(Cross Stage Partial)和空間金字塔池化層SPP(Spatial Pyramid Pooling)組成,其結構如圖2所示。為更好地保留輸入圖像原始信息,在DaSNet模型中對YOLOv5s中的Focus層做了結構上的改進,即在原來的結構基礎上增加一條通路,直接將輸入圖像進行卷積,再將兩條通路進行拼接后,經過一次卷積,即可得到改進的Focus層的輸出。這種結構能在YOLOv5s中Focus層優勢的基礎上,更多地保留原始圖像信息,并且將兩條通路結合,豐富輸入圖像信息,使后續卷積層可以獲得更好的特征提取效果。
DaSNet模型中全部采用Leaky ReLU作為激活函數對卷積層得到的運算結果進行非線性激活,如圖3所示,傳統的ReLU激活函數雖然具有較快的計算速度與收斂速度,但當輸入為負值時,會因為其0輸出導致神經元無法更新參數;而Leaky ReLU函數相較于傳統的ReLU函數在輸入的負半區間引入了Leaky值,避免了輸入為負值時0導數的出現導致神經元無法更新參數的問題。
1.2 特征融合網絡
原始圖像中一些小尺寸目標本身具有的像素較少,最后一層特征圖在經過多次卷積與下采樣操作后,很可能將小尺寸目標對應的像素和信息丟失,因此,若僅使用主干網絡最后一層輸出特征來進行目標的預測,則會導致漏檢;且在主干網絡中,靠前的淺層卷積層更容易提取到抽象級別較低的圖像內容信息,而較深卷積層更容易提取到抽象等級較高的特征信息,若只對主干網絡最后一層的特征圖進行檢測,容易漏掉許多原始圖像的內容信息,從而導致檢測結果不理想。因此在主干網絡后,加入特征融合網絡,從主干網絡中提取多個尺度的特征并進行融合,進而使用融合后含有豐富信息的特征進行檢測,使檢測性能得到大幅提升。
類比PAN[15](Path Aggregation Network)特征融合網絡,采用CSP2-1模塊作為基本單元構成如圖4所示的特征融合網絡結構。這種使用CPS2-1模塊改進的PAN結構多了一輪自低而上的融合步驟,提高了模型的特征表達能力,使融合后的特征含有更豐富的語義信息,從而進一步提升檢測效果。
1.3 道路物體檢測網絡
道路物體檢測網絡來自特征融合網絡輸出的3個特征,分別對其進行卷積操作,將3個輸出張量作為預測結果,網絡結構如圖5所示。
DaSNet模型中先驗框初始值設置為橫向矩形,方形與縱向矩形3種,在道路感知場景中,這3種先驗框的配置可以很好地適應車輛,路標以及行人等目標的預測。隨著網絡的訓練,模型會根據數據集標簽框的數值分布,自適應地對先驗框大小做出調整。
1.4 可行駛區域分割網絡
可行駛區域分割網絡作為DaSNet模型的第22分支,負責對道路前方可以行駛的區域進行像素級分割,其網絡結構如圖6所示。
目前大多算法使用單獨的分割網絡對區域進行預測,不但會消耗大量的算力,且由于路面區域語義特征不明顯,導致分割準確率較差。而DaSNet中的可行使區域分割網絡的輸入分別來主干網絡以及特征融合網絡。來自主干網絡的特征包含待預測圖像中的淺層語義信息以及圖像內容信息,能提供可行駛區域的通用語義特征;來自特征融合網絡的特征包含車輛行人等可能阻礙汽車前進的物體的類別與位置信息;輸入特征在經過上采樣后,經過融合模塊Fusion與尺寸大一倍的輸入特征進行融合。并在每兩次Fusion操作后使用CSP模塊進行特征增強,最后使用一個卷積層得到分割結果,其兩通道分別表示對應像素為占優先權的可行駛區域與不占優先權的不可行駛區域的概率,若預測值小于閾值則認為該像素點為不可行駛區域,其中閾值的選取與檢測分支的閾值選取同理。
可行使區域分割網絡融合模塊Fusion將兩個輸入特征按通道方向拼接后進行兩次CBL模塊運算,并使用上采樣層恢復特征圖像細節與分辨率,作為下一個Fusion模塊的輸入特征。
將區域分割的任務融合到道路物體檢測網絡中,作為一個附加的分支,達到在一個模型上同時完成兩類任務的效果,由于共用主干網絡以及特征融合網絡的特征,分割網絡可以獲取到模型已提取到的道路物體語義信息,由于道路前方的汽車與行人等障礙物會使可行駛區域發生改變,因此利用這些道路物體語義特征對可行駛區域進行預測,在減少算力的同時,也可以使分割效果明顯提升。
2 損失函數與數據集
2.1 損失函數設計
IoU(Intersection over Union)為交并比,是目前檢測中比較常用的指標,可以反映出預測檢測框與真實檢測框的檢測效果,計算公式為
式(4)中,confLoss為單個預測框的置信度損失,yconfi為該預測框的置信度預測值,當檢測目標預測框的網格處有標記物體時tconfi為1,否則為0;式(5)中clsLoss為分類概率損失,當標記物體的類別為i時,tclsi為1,否則為0,yclsi為模型輸出預測框類別為i的概率。
在訓練分割網絡時,選擇合適的損失函數,也能使網絡得到更準確光滑的分割效果。本文選用一種由度量集合相似度的度量函數演化而來的DiceLoss,其計算公式為
(6)
其中,X和Y分別為標簽像素與預測像素,反映了區域與標簽像素區域的重合關系。Dice損失更注重于優化預測區域與標簽區域的重合關系,更適合于DaSNet模型的可行駛區域分割任務,因此在訓練可行駛區域分割網絡時選擇DiceLoss作為損失函數。
2.2 BDD100K網絡數據集
本文采用2018年5月伯克利大學AI實驗室發布的BDD100K數據集,其中包含10萬個高清視頻序列,總時長超過1 100 h,涵蓋不同時間、不同天氣條件和駕駛場景。每個視頻對第10秒進行關鍵幀采樣,得到10萬張尺寸為1 280*720的圖片,并對道路物體、可行駛區域、車道線和全幀實例分割進行標注,這些標記能使模型更好地理解不同場景中數據和對象的多樣性。
如圖7所示,在BDD100K數據集中,8用于目標檢測的有公共汽車、交通燈、交通標志、人、自行車、卡車、摩托車、汽車、火車和乘車人等共上百萬個目標物體的標注數據;且有超過10萬張相關圖像含有用于語義分割與實例分割的像素級注釋和豐富實例級注釋;也有超過10萬張圖片的多種車道線標注可用于車道線的檢測。
3 實驗驗證及結果分析
本文使用的模型訓練環境均為高性能的桌面臺式機,選用微星Z390主板、搭載Intel i9 9900KF處理器以及32GB運行內存,采用11G顯存的Nvidia Geforce RTX2080Ti GPU進行模型的訓練與測試;軟件方面,系統選用Ubuntu20.04版本,集成開發工具選用PyCharm 2020版本并結合Anaconda包管理器創建conda虛擬環境,使用Python3.7環境下的Pytorch10.1版本進行算法模型的開發與測試。
3.1 檢測主分支訓練
在道路物體檢測分支網絡訓練過程中,對主干網絡、特征融合網絡以及檢測層做前向傳播,根據標簽數據求出分類損失、置信度損失以及檢測框損失,在反向傳播后,使用隨機梯度下降算法更新主干網絡、特征融合網絡以及檢測層的網絡權重參數。在整個訓練過程中,采用大小為16的batch size,并設置初始學習率為0.1,設置如圖8所示的學習率調整策略,在7萬張圖像的訓練集上進行300次迭代,由于Mosaic數據增強方法每次融合4張圖片,且網絡使用了較高性能的預訓練權重,因此300次迭代足夠使模型達到收斂后較平穩的區域。在網絡剛開始訓練的階段,由于部分權重參數是隨機初始化生成的,如果使用較高的學習率會使訓練過程非常不穩定,所以采用warm up的方式在訓練前4次迭代中將學習率逐漸增加到初始學習率0.01;在網絡訓練后期,權重在最優值附近,一直使用較高學習率會使權重每次都有較大變換,導致損失值在最小值左右來回震蕩,使用余弦退火的學習率衰減策略,使學習率在訓練過程中不斷下降,從而使損失值收斂于最優點。
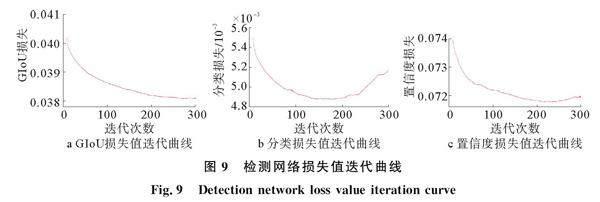
模型訓練過程中在驗證集上的損失值迭代曲線如圖9所示,最上方為分類損失,中間為GIoU損失,下方為置信度損失。可以看出,在訓練開始階段,3種損失值較大,隨著學習率增加為初始值,損失值開始較快下降,隨著訓練迭代次數的增加,由于調整策略的調整學習率緩慢下降,損失值的下降逐漸趨于平穩,在240次迭代中損失值到達最優值,將此時的網絡權重保存作為最終訓練結果,并對其性能做出評價。
3.2 分割分支訓練
由于可行駛區域分割網絡以道路物體檢測網絡的特征層作為輸入,因此分割網絡的訓練必須在道路物體檢測網絡訓練之后進行,訓練時對主干網絡,特征融合網絡以及分割網絡做前向傳播,網絡輸出與輸入圖像尺寸相同的掩膜,掩膜與標記掩膜求Dice損失,并反向傳播,在更新網絡權重時,將主干網絡與特征融合網絡的參數固定,只對可行駛區域分割網絡進行權重參數的更新。
分割網絡分支無預訓練的權重,因此將訓練的迭代次數增加到600次,與檢測網絡采用相同學習率衰減策略與0.1的初始學習率,batch size同樣設置為16。網絡訓練過程的損失值迭代曲線如圖10所示。可以看出,由于主干網絡在檢測分支的訓練過程中預先學習到了圖像的通用特征,因此分割網絡損失值有著較低的初始值,且在訓練過程中隨著學習率的調整不斷波動,在最后100次迭代中收斂于最優值。
3.3 模型預測效果展示
在預測過程中,圖片經過自適應填充縮放后,輸入到加載了訓練過的權重的模型中進行前向傳播并得到預測結果,將其解碼后經過非極大值抑制算法過濾掉多余檢測框,并將檢測結果恢復到原始圖像的尺度,使用openCV庫在原始圖像上進行結果繪制,即可得到如圖11所示的預測效果圖。
從圖11可以看出,DaSNet模型對距離較近的行人、汽車以及路標等有著非常精確的檢測效果,且置信度較高;對遠處較小的汽車與行人目標也有著較高的檢測率。分割網絡也能夠較準確地識別出前方可行駛的道路區域,并且能明顯地區分出前方占優先權的車道與不占有優先權的車道。
3.4 道路物體檢測網絡對比分析
召回率與準確率是目標檢測領域常見的兩個指標,召回率代表模型在所有待預測目標中的已檢測數量,而準確率則代表模型預測正確數量。兩個指標通常呈負相關的關系,因此經常通過綜合評價召回率與準確率的方法來評價模型性能,計算公式為
對某一分類,從0.5到0.95中每隔0.05取一個值作為預測框的IoU閾值,并在所有取到的閾值下計算其召回率與準確率,并作為橫坐標與縱坐標繪制P-R曲線,曲線下的面積即為當前分類的AP值。mAP值即為所有分類AP值的平均值。其計算公式為
其中,c為當前分類的編號,n為總類別數,precision(recall)為當前召回率下準確率的值。mAP值為模型檢測的精度,而檢測速度是除mAP之外另一個重要的評價指標,通常使用FPS(Frames per second)為單位,表示模型在一秒鐘內能完成檢測的圖像數量。根據上述評價指標,使用BDD100K數據集中1萬張驗證集進行推理測試,繪制其在驗證集上的P-R曲線,并計算mAP、mAP50以及推理速度,結果如圖12所示。
可以看到,模型對于不同類別有著不同的P-R曲線,其中深黑色曲線為根據驗證集中所有類別的所有目標求得的P-R曲線,利用該曲線可以求出模型的mAP值為33.7%;記錄模型對整個驗證集的推理時間,利用驗證集數量求得模型的推理速度為121FPS。
為更好地評估DaSNet檢測分支的性能,分別選用目標檢測領域單階段與兩階段兩類算法中性能最優的算法進行對比實驗,分別使用搭載了CSPDarknet53主干網絡與FPN特征融合網絡的YOLOv5s(YOLOv5s與DaSNet模型量級相近)模型與搭載了VGG16的Faster R-CNN模型在BDD100K訓練集上進行300次迭代,并計算相關指標,分別記錄其mAP值、mAP50值以及檢測速度,結果如表1所示。可見,DaSNet模型的道路物體檢測網絡比YOLOv5s模型速度稍慢,但提升了0.5%的mAP與1.1%的mAP50;且在檢測速度遠高于Faster R-CNN模型的同時,比其高了4.2%的mAP與7.4%的mAP50。因此DaSNet模型相較于當前主流的目標檢測算法有了一定的提升。
3.5 可行駛區域分割網絡對比分析
與損失函數保持一致,使用Dice系數對可行駛區域分割網絡性能做出評估,其計算公式為
其中,X為數據集的標記掩膜,Y為模型預測掩膜,該系數很好地反映了標簽掩膜與預測掩膜的重合關系,從而評估模型性能。
使用BDD100K訓練集在U-Net網絡上進行600次迭代,并在驗證集上對訓練后的U-Net模型進行測試,計算其對占優先權與不占優先權兩種可行駛區域的Dice系數,并與DaSNet模型的道路物體檢測網絡對比,兩種模型預測效果如圖13所示。
由圖13可以看出,相較于U-Net,本文設計的DaSNet模型在可行駛區域邊緣部分的分割效果更加平滑,且對于車輛與行人周圍的區域,能更加精細地將可行駛區域分割出來,這說明加入的來自道路物體檢測網絡的輸入特征層確實能影響可行駛區域的分割效果。
由表2可以看出,DaSNet模型在BDD100K數據集的可行駛區域分割效果上,相較于U-Net有著較大的提升,說明融合道路物體語義信息的可行駛區域分割方法在無人駕駛場景感知中有更好的效果;也說明了基于多任務間特征融合的模型設計方法的有效性。
4 結論
經驗證,DaSNet對常見的7種道路物體有較高的檢測精度,在夜晚等復雜環境中幾乎沒有誤檢漏檢,具有較好的魯棒性,且能有效地對前方道路的可行駛區域進行像素級分割,其輕量級的網絡結構模型也帶來了可靠的實時性。通過對比實驗可知,DaSNet相較于當前主流的單一任務的預測模型有著更好的表現效果。這說明本文提出的利用多任務特征共享的模型設計方法確實能有效改善模型的性能,在提高了無人駕駛道路環境感知系統中硬件資源利用率的同時提升了檢測與分割任務的精度,為提高感知系統的運行效率起到積極作用。
參考文獻:
[1]王俊. 無人駕駛車輛環境感知系統關鍵技術研究[D]. 合肥:中國科學技術大學, 2016.
WANG J. Research on keytechnologies of environment awareness system for unmanned vehicle [D]. Hefei: University of Science and Technology of China, 2016.
[2]王世峰, 戴祥, 徐寧, 等. 無人駕駛汽車環境感知技術綜述[J]. 長春理工大學學報(自然科學版), 2017,40(1): 1-6.
WANG S F, DAI X, XU N, et al. Overview on environment perception technology for unmanned ground vehicle[J]. Journal of Changchun University of Science and Technology (Natural Science Edition), 2017,40(1): 1-6.
[3]CHEN Q, XIE Y, GUO S, et al. Sensingsystem of environmental perception technologies for driverless vehicle: a review of state of the art and challenges[J]. Sensors and Actuators A Physical, 2021, 319: 112566.
[4]GAYATHRIK D, MAMATA R, NGUYEN T D L. Artificial intelligence trends for data analytics using machine learning and deep learning approaches[M]. USA: Calabasas: CRC Press, 2020.
[5]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587.
[6]GIRSHICK R. Fast r-cnn [C]// IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1440-1448.
[7]REN S, HE K, GIRSHICK R, et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[8]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once:unified, real-time object detection[C]// IEEE conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
[9]LIU S, QI X, SHI J, et al. Multi-scalepatch aggregation (MPA) for simultaneous detection and segmentation[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Seattle :IEEE, 2016: 3141-3149.
[10] PINHEIRO P, COLLOBERT R, DOLLAR P. Learning tosegments objects candidates[C]// Advances in Neural Information Processing Systems. Montreal:NIPS,2015.
[11] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semanticimage segmentation with deep convolutional nets and fully connected CRFs[J]. Computer Science, 2014(4): 357-361.
[12] ZHAO H SH, QI X J, SHEN X Y, et al. ICNet forreal-time semantic segmentation on high-resolution images[J]. Lecture Notes in Computer Science, 2017, 11207: 418-434.
[13] RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[J]. Lecture Notes in Computer Science, 2015, 9351: 234-241.
[14] 李亞. 多任務學習的研究[D].合肥:中國科學技術大學, 2018.
LI Y. Research on multi-task learning [D]. Hefei: University of Science and Technology of China, 2018.
[15] LIU S H, QI L, QIN H F, et al. Path aggregation network for instance segmentation[J/OL]. IEEE.[2021-10-01]. DOI:10.1109/CVPR.2018.00913.
[16] REZATOFIGHI H, TSOI N, J Y GWAK, et al. Generalized intersection over union: a metric and a loss for bounding box regression[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach:IEEE, 2019: 658-666.
(責任編輯 李 進)
收稿日期: 2021-11-07;修回日期:2022-04-07
基金項目: 山東省重點研發計劃(2018GGX105004);青島市民生科技計劃(19-6-1-88-nsh)
第一作者: 孫傳龍(1997-),男,山東淄博人,碩士研究生,主要研究方向為深度學習與計算機視覺在無人駕駛中的應用。
通信作者: 趙紅? (1973-),女,河南南陽人,博士,副教授,主要研究方向為車輛節能減排與新能源技術。
