融合特征增強模塊的小樣本農業害蟲識別
2023-04-29 19:46:50王祎李旭偉劉怡光陳立平
四川大學學報(自然科學版) 2023年4期
王祎 李旭偉 劉怡光 陳立平

摘 要 ???:基于深度學習的圖像識別技術在具體應用前必須先經過大量帶標簽樣本的訓練,然而在實際場景中目標域樣本可能非常稀缺,小樣本圖像識別技術應運而生.為了提升小樣本場景下的圖像識別準確率,本文提出一個通用的兩階段訓練模型以融合現行主流方法并增強其表現.首先,針對訓練時不同害蟲種類背景相似度過高的問題提出融合雙注意力機制的特征加強模塊;其次,針對小樣本情況下預測可能產生的過擬合問題提出基于高斯分布的特征生成模塊以提高泛化能力;最后,將三種典型小樣本識別方法統一成兩階段訓練模型以融入提出的方法.將該思路及改進首次應用于傳統害蟲分類數據集IP102,識別準確率可以在基準方法上取得2.11%到6.87%的提升.為了進一步驗證本文方法的有效性,在小樣本領域公開數據集Mini-Imagenet也進行了相應的實驗,提升效果同樣顯著.
關鍵詞 : 圖像識別; 小樣本; 特征增強; 農業害蟲
中圖分類號 :S126 文獻標識碼 :A DOI : ?10.19907/j.0490-6756.2023.042001
Few shot learning of agricultural pests classification ?fusion with enhanced feature model
WANG Yi ?1, LI ?Xu-Wei ?1, LIU Yi-Guang ?1, CHEN Li-Ping ?2
(1. College of Computer Science (College of Software), Sichuan University, Chengdu 610065, China;
2. School of Information Engineering, Tarim University, Tarim 843300, China)
In order to achieve accurate image recognition in scenarios where the target domain samples are limited,such as agricultural pest Image recognition, few shot image classification methods have been developed as an extension of deep learning-based image classification .To further improve the accuracy in the few shot image classification, this paper proposes a general two-stage training model that integrates current mainstream methods and enhances their performance to improve the recognition accuracy in limited sample scenarios Firstly, a feature enhancement module incorporating dual attention mechanism is proposed to solve the problem that the background similarity of different pest species is too high during training. Secondly, a feature generation module based on Gaussian distribution is proposed to solve the problem of overfitting that may occur in prediction in the case of a single sample. to improve the generalization ability. Finally, three typical few-shot recognition methods are unified into a two-stage training model to incorporate the proposed method. This idea and improvement are applied to the traditional pest classification dataset IP102 for the first time, and the recognition accuracy can be improved by 2.11% to 6.87% over the benchmark method. In order to further verify the effectiveness of the method in this paper, corresponding experiments were also carried out on the public dataset Mini-Imagenet in the field of few shot learning, the improvement effect is also significant.
Imagine classification; Few shot learning; Feature enhancement; Agricultural pests
1 引 言
農業問題關乎民生大計,種類繁多的害蟲卻給糧食生產和作物安全帶來了巨大的挑戰 ?[1],因此安全高效地識別農業害蟲尤為重要.同時基于深度學習的圖像識別技術也取得了飛速的進展,各種改進的卷積神經網絡 ?[2-4]和Transformer機制 ?[5-6]在某些特定場景下的表現已經超越人類,面對經濟與效率的取舍,有學者在農業害蟲識別領域使用機器視覺方法進行了各種積極的嘗試.
2016年吳翔使用12層卷積神經網絡對128*128輸入的彩色圖像進行識別 ?[7], 在10類害蟲識別上達到了76.7%的識別準確率;2017年Cheng ?[8] 等通過深度殘差模塊對復雜農田背景下的害蟲進行識別,準確率達到99.67%;2018年周愛明 ?[9]提出了適合移動端部署的輕量化模型,在保證一定效率的條件下識別準確率為93.5%;2019年Thenmozhi ??[10]等使用遷移學習的思路研究農業害蟲識別,并對多種超參數進行調節,最終在引用的三類害蟲識別上達到95%以上的準確率;2020年Nanni ??[11]等在更具挑戰的ip102 ?[12]數據集上,將顯著性方法與卷積神經網絡進行融合,達到了61.93%的識別準確率; 2021年Hridoy ??[13]等使用不同的卷積神經網絡,在早期秋葵害蟲圖像上進行對比實驗,其中MobileNetV2表現效果最佳,取得了98%的識別準確率.
雖然已有研究取得了較好的成果,但是其識別準確率嚴重依賴數據集,對于新出現的未經訓練的類別則束手無策.小樣本學習專門用于解決目標域樣本不足這一問題,但是目前將其用于農業害蟲識別這一領域的研究寥寥無幾.
因此本文以當前最具挑戰的IP102農田害蟲數據集作為基準數據,首次采用小樣本領域的研究思路進行研究;目的是通過已有類別的訓練,使得模型在遇到新的類別時,只需要一張引導圖片便可以將學習到的特征進行遷移,從而顯著提高模型對新出現類別的識別準確率.
為了進一步提高模型在小樣本情況下的識別準確率,分析三種典型小樣本識別方法:匹配網絡 ?[24],原型網絡 ?[14]和圖神經網絡 ?[15]共性部分,在訓練階段,引入空間注意力機制和通道注意力機制以強化不同類別害蟲類別差異信息;在驗證階段,使用基類信息加強新類支撐集樣本特征以避免過擬合,最終將兩種方法進行結合,使得模型識別準確率在基準方法上得到了大幅提升.
應用該方法可以在新的害蟲種類比如非洲蝗蟲剛入侵時,只需專家進行一次標定,后續便可以對其地區容易混淆的害蟲種類進行識別,從而進行針對性防治預案.因此對于比較稀缺和較難獲得的樣本,這種訓練模式無疑是更具有實際應用價值.
2 任務定義
小樣本學習 ?[16]的目標是給定一組標記好的圖集 S={( x ?1, y ?1),( x ?2, y ?2),…,( x ?i, y ?i)} ,其中 ?x ?i∈ 瘙 綆
d×d 是圖像特征, ?y ?i∈C 是樣本標簽,人為將 S 劃分為基類(base) ?S ?b 和新類(new) ?S ?n ,二者關系為 ??S ?b∩ S ?n=, S ?b∪ S ?n=S .對于基類數據和新類數據分別存在支撐集 ?S ?s (Support set)和查詢集 ??S ?q (Query set),目的是通過 ?S ?b 的引導使得網絡具有在 ?S ?n 中的泛化能力,即:在每一次任務 T 中,通過支撐集 ?S ?s ?n 的引導能將 ?S ?q ?n 劃分到正確的類別中. n 含義為每一次任務的數據來源為新類(new).
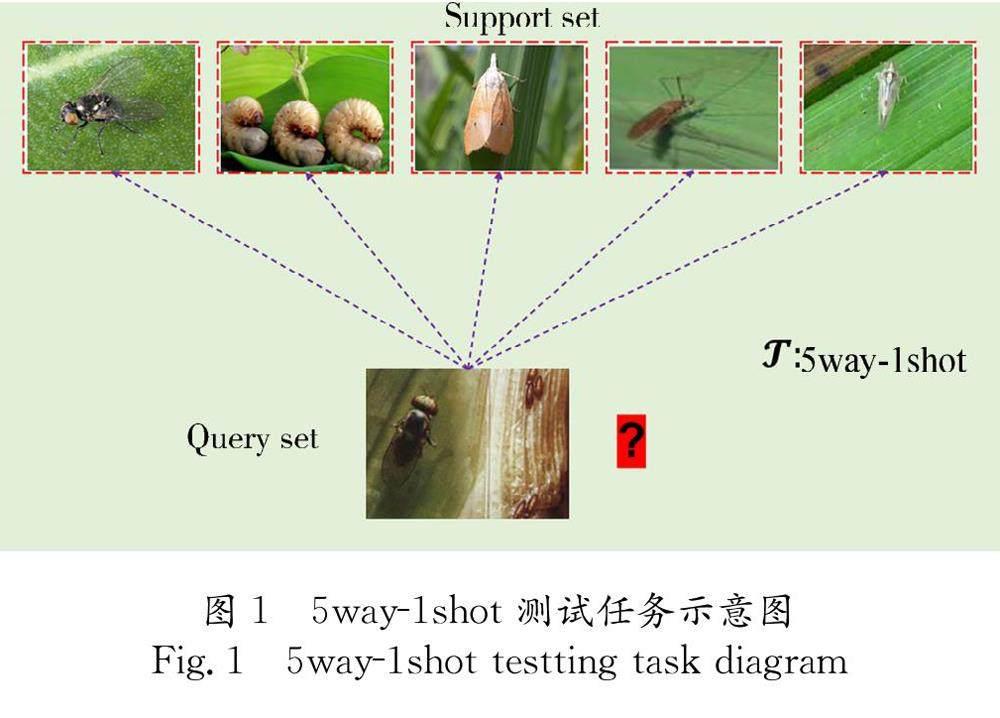
為了衡量模型的泛化能力,通常會定義一個K-way N-shot的問題,即:在新類下,每次任務會隨機抽取 K 個類別,每個類別只提供 N 個帶標簽的樣本作為支持集,然后對新出現的未知標簽樣本進行分類計算準確率.當 N =1時就是單樣本學習,即支持集每一個類別只提供一個帶標簽的樣本用于學習.該任務信息如圖1的5way-1shot 測試任務示意圖.
3 相關工作及改進分析
3.1 相關工作
目前少樣本研究以Meta-learning ??[17]為主要思路,最具代表的有匹配網絡MatchingNet ?[24],原型網絡ProtoNet ?[14],圖神經GnnNet ?[15]等基于度量學習的方法.
3.1.1 匹配網絡 ?匹配網絡的思想就是在給定支持集樣本的情況下,假設有一個新的測試樣本 ?x ?^ ?,需要分別求出 ?x ?^ ?屬于 ?y ?i 的概率,并將最大類別標簽概率作為最終預測結果.模型一般表示如式(1).
P(y ?^ ∣x ?^ ,S)= ∑ ?k ?i=1a x ?^ ,x ?i y ?i ?(1)
其中, k 為類別數,對于支持集的每一個類別都需要求出概率 ;a 是網絡訓練的目標,其一般表達式為式(2).
a x ?^ ,x ?i =e ??d(f(x ?^ ),g(x ?i)) / ?∑ ?k ?j=1e ??d(f(x ?^ ),g(x ?j)) ?(2)
其中, d 是查詢集與支持集的距離度量,原文采用余弦相似度作為度量; f 和 g 為網絡嵌入模型,目的是將查詢集和支持集映射到不同的特征空間.
3.1.2 原型網絡 ?原型網絡則假定對于每一類樣本在特征空間都存在一個原型位置prototype,同類別樣本則分布于這個原型附近.因此在訓練時先通過一個embedding函數 ?f ?φ 將數據映射到特征空間,然后將向量化均值作為每一類的原型空間.形式化表示為式(3).
c ?k= 1 ∣S ?k∣ ?∑ ??(x ?i,y ?i)∈S ?kf ?φ(x ?i) ?(3)
其中, ?c ?k 為每一類別的原型; ?f ?φ 是一個嵌入模型,目的是將圖像轉化到特征空間,增強計算效率.
在測試時將查詢 集數據與每個類別原型的距離經softmax處理便可以得到所屬類別,即式(4)所述.
p ?φ(y=k∣x)= ?exp ?-d f ?φ(x), c ?k ???∑ ??k′ exp ?-d f φ(x), c ?k′ ????(4)
其中, d 是一個距離度量函數,用于衡量查詢集與類別原型之間的距離.
3.1.3 圖神經網絡 ?圖神經網絡的方法則通過將標簽信息從有標簽的樣本傳播到無標簽的樣本上進行圖像分類.首先按照式(5)構造圖神經網絡初始節點.
x ?(0) i= f φ x i ,h l i ???(5)
其中, ?f ?φ( x ?i) 是樣本在特征空間中的向量表示; ?h( l ?) 是標簽的One-Hot向量,二者拼接作為圖的初始結點.接下來,獲得圖的臨接矩陣如式(6).
A ~ ??(k) ?i,j= ?MLP ?θ ~ ??abs ??x ?(k) i- x ?(k) j ???(6)
將結點 i 和 j ?的絕對值之差疊加一個多層感知器作為圖的臨界矩陣,MLP即是一個多層感知機, ?θ ?是可以學習的參數.最后,獲得整體圖模型并通過式(7)進行消息傳播.
x ??(k+1) l=ρ ?∑ ?B x ??(k)θ ??(k) ?B,l ??(7)
其中, B 為鄰接矩陣的集合; ??θ ?(k) ?B,l 是可以訓練的參數,它可以獲得當前層結點和其鄰接矩陣的頂點并更新為下一層的頂點; ρ(·) 是為了提高泛化能力引進的激活函數.通過以上方法經過多次迭代可以將標簽信息傳播至無標簽樣本.
3.2 改進分析
由于目前不同小樣本學習方法在具有不同特征的數據上表現各有優勢,本文擬提出通用的特征增強模塊以提高各種方法對農業害蟲識別的準確率和適應能力.分析3.1節三種典型網絡,其共性為:在特征空間上度量各類別之間的距離以完成分類,不同之處在于度量模式的不同.匹配網絡 ?[24]計算待分類圖片與每一張支撐集圖片的余弦距離進行度量;原型網絡 ?[14]計算待分類圖片與類別原型之間的高斯距離進行度量;而圖神經網絡 ?[15]直接將類別關系通過節點與邊進行傳遞,在傳遞過程中度量待分類樣本與各類別之間的關系.
然而,這三種典型網絡都只關注度量方法合適與否而忽略了兩個關鍵信息:(1) 在將圖像信息映射到特征空間的過程中是否損失了每個害蟲類別的關鍵性特征信息,如果每類害蟲缺乏獨有的特征標識,那么分類效果勢必受到影響;(2) 即使映射后的特征向量足以保留每張害蟲圖像的類別信息,在測試階段每一類害蟲僅有一張圖片進行分類引導,如果這一張圖片特征不明確或者某些非關鍵性信息過于強烈則會對分類結果有錯誤的引導.
4 提出的方法
不同于以往的小樣本圖像分類方法,本文采用兩階段訓練的模式進行訓練.第一階段引入雙注意力機制對特征提取階段每類害蟲的關鍵性特征信息進行數據增強;第二階段采用基于高斯分布的特征生成模塊,借助基類豐富的樣本信息生成相關樣本以糾正測試樣本稀缺帶來得偏分布,整體網絡架構如圖2所示.
具體的,第一階段:首先基于傳統的小樣本學習方法訓練出一個良好的可以準確提取不同害蟲類別關鍵性信息的特征提取器,如resnet,并在這一階段引入空間注意力和通道注意力 ?[18]機制,使得特征提取網絡能夠識別到不同種類在各種背景下的細微差異,從而重點關注每一個害蟲類別獨有特征信息.第二階段:由于新類中的數據只有有限的帶標記樣本,如果采用傳統方法直接分類很可能會產生過擬合的情況.因此假定特征是基于高斯分布的,則每個類的類別信息與其均值和方差直接相關,均值表示了每個類別的原型,方差表示類內差異性,這樣便可以借助基類的分布更加準確地估計新類的分布 ?[19].因此第二階段會借助第一階段的特征提取網絡,計算出基類類別在特征空間上的均值和方差,并基于最近鄰算法的思想利用與新類最相似類別特征生成大量帶標記的樣本,最后結合生成的樣本和新類支持集訓練出一個更加優秀的分類器以實現分類.
4.1 融合雙注意力機制的特征提取網絡
注意力機制使得網絡學會關注重點區域,比如螽斯和蝗蟲的重點差異為觸角與身體長度的比例,一般有空間注意力機制和通道注意力機制兩種模式,空間注意力機制關注圖像維度的差異信息,通道注意力機制關注通道維度的差異信息.
對于農業害蟲而言,圖像維度體現了不同害蟲的大小,角度和位置等信息,通道維度體現了顏色,紋理等信息,二者對于不同的害蟲辨識都非常重要,因此本文結合空間注意力和通道注意力機制對每一階段生成的特征圖進行加強處理.無論以ConvNet還是ResNet作為特征提取網絡,都在跳躍連接階段引入雙注意力機制以達到準確率和效率的平衡,具體實現流程如圖3所示.
4.1.1 通道注意力機制 ?將圖像映射到特征空間過程中,圖像信息經過多層卷積不斷進行信息壓縮,每個卷積層的不同通道會關注不同的信息,通道注意力機制解決網絡應該重點關注通道信息的問題,一個通道注意力機制由式(8)和式(9)組成.
ω 1=σ f ?(W 0,W 1) α F ?+f ?(W 0,W 1) δ F ????(8)
其中, F∈ 瘙 綆
C×H×W 為選取的中間層的特征圖, C,H,W 分別表示特征圖的深度,高度和寬度; α,δ 分別表示平均池化下采樣和最大池化下采樣,經過其作用后特征圖尺寸為 C×1×1 ,整個過程見式(9).
δ(F)= ?max ???H,W(F),
α(F)= 1 W×H ?∑ ?H ?i=1 ∑ ?W ?j=1F ??i,j ?(9)
其中, ?W ?0, W ?1 是共享卷積層,目的是改變特征圖的通道數.一個完整的通道注意力機制如式(10).
ω 1=σ( W 1 ReLU ( W 0α(F))+
W 1 ReLU ( W 0δ(F))) ?(10)
其中,ReLU()和 σ() 分別表示Relu激活函數和sigmoid激活函數.
4.1.2 空間注意力機制 ?空間注意力機制解決網絡應該關注哪些重點區域的問題,與通道注意力機制類似,其實現方式是將平均池化下采樣和最大池化下采樣的結果進行特征融合后疊加一個卷積層,以獲取空間權重特征,可形式化表示為式(11).
ω 2=σ W ?7*7 α(F);δ(F) ???(11)
4.1.3 骨干網絡信息融合 ?對于每一個stage的輸出都會經過這樣一個雙注意力機制,通道注意力機制會把原圖轉化成一個 C×1×1 的一維向量,并與特征圖進行相乘以學習通道的權重信息;空間注意力機制會將原圖轉化成一個 1×H×W 特征圖,以學習到特征圖的每一個空間信息的權重值.雙注意力機制可表示為式(12)所示.
F′=ω 1(F)?F,
F″=ω 2(F′)?F′ ?(12)
其中, ?ω ?1, ω ?2 分別代表第3.1節提到的通道注意力機制和空間注意力機制; ? 表示逐元素相乘.一個完整的并行雙注意力機制則會將通道注意力機制的輸出作為空間注意力機制輸入,最終疊加得到注意力增強結果.
4.2 基于高斯分布的特征生成器
在測試階段每一類害蟲只有一張引導圖片,已訓練出的模型很容易因為樣本不足形成的偏分布而導致過擬合,為防止過擬合,需要合理利用基類數據中的大量樣本.對于農業害蟲而言,雖然新類是沒有見過的類別,但均屬于昆蟲種類,圖像特征與基類圖像具有極大的相似性,因此可以借助訓練集中相似樣本的均值和方差來校準偏分布以防止過擬合.
4.2.1 計算基類特征信息 ?利用第一階段生成的特征提取網絡將原圖映射到特征空間,可以有效地減少數據維度,從而進行特征的快速提取.由于基類中數據樣本充足,可以方便地獲取每一個類別在特征空間內的統計信息,其中第 i 類的均值 ?μ ?i 和方差 ??Σ ??i 分別為式(13)和式(14)所示.
μ ?i= ?∑ ??n ?i ?j=1x j n ?i ??(13)
Σ ?i= 1 n ?i-1 ?∑ ??n ?i ?j=1 x ??j-μ ?i ??x ?j-μ ?i ??T ?(14)
其中, i ?代表支持集內樣本種類數; j 代表對應種類內具體的樣本數量; ?n ?i 則表示基類 i 中樣本的總數; ?x ?j 是基類 i 中第 j 個樣本的特征向量.
4.2.2 生成相關種類特征 ?特征遷移與校準的前提是樣本相似度較高,因而在特征空間內的均值和方差相差不大,而基類數據類別豐富,不可能全部用于樣本生成,因此需要找出與新類關系最為密切的種類信息.本文采用歐式距離進行密切性度量找出關系最為密切的 t 個類別,通過這 t 個類別的均值和方差來生成最相關類別的特征信息.
(15)
其中, ?x ?是新類中帶標簽樣本在特征空間中的向量表示; ??瘙 綃
b 是基類中所有樣本與新類帶標簽樣本(新類支持集)的歐式距離的集合; b 含義為基類數據(base).按照式(16)選取距離最近的前TOP( t )個元素作為補充類集合 ?瘙 綃
t ,這里 t 本質上為超參數,可以根據不同的數據集靈活選取.
(16)
使用補充類集合內的元素可以按照式(17)生成與新類關系最為密切的均值和方差:
(17)
4.2.3 根據生成特征采樣樣本訓練線性分類器 ?對于每一次測試任務都應該基于以上方法計算均值和方差生成樣本來校正支持集樣本分布,將生成的特征集合稱作
y={( μ′ ?1, ?Σ ′ ?1),…,( μ′ ?k, ?Σ ′ ?k)} ,其中 ?μ′ ?i, ?Σ ′ ?i 是根據支持集中第 i 類圖像的特征向量生成的校準分布均值和方差.
若已知類別的均值和特征向量,則通過隨機采樣生成補充樣本,設生成的樣本集合為 ?G ?y ,其可通過式(18)生成.
G ?y={ x,y |x~N(μ,Σ), (μ,Σ)∈F ?y} ?(18)
其中,第 i 類樣本對應生成補充樣本為 (x,y) ,將生成的樣本與原樣本混合作為增強樣本,通過式(19)以最小化交叉熵損失為目標訓練一個線性分類器.
l=∑ ?(x,y)~S ~ ∪G ??y,y∈YT - log Pr(y|x;θ) ?(19)
其中, ?y ?T 是對于每一個訓練任務而言的類別數; θ 是一個可訓練的參數,訓練完畢之后用式(19)訓練的線性分類器對新類的查詢集進行預測計算準確率.
5 實驗與結果
5.1 數據集介紹
本實驗基于發布在CVPR 2019上的大型農業害蟲數據集IP102,其共包含102類超過75 000幅從野外真實環境中發現的農業害蟲圖像,貼近害蟲自然狀態,并且數據集中包含了各種害蟲不同生長周期的圖像,其周期差異信息也給識別帶來巨大的挑戰.
對于傳統圖像識別任務,采用典型的原數據集劃分模式,即訓練集∶測試集∶驗證集=6∶2∶2;而對于小樣本圖像識別任務,為了使驗證集與訓練集不產生類別交叉,編寫程序隨機選取60個類別作為訓練集,剩余類別里驗證集和測試集各占21個類別,每次任務都隨機挑選五個類別中的一張圖片進行驗證,經過多次實驗取平均值作為預測準確率結果.
5.2 傳統方法表現
傳統的圖像識別方法主要包括手工提取特征和利用深度學習提取特征的方法,前者主要包括如SIFT ?[20]和HOG ?[21]等方法,這些方法在低級語義特征如邊緣,顏色和紋理上表現較好;而后者在高級語義信息上的表現則更為優異.分別采用SIFT和HOG進行特征提取,并用SVM和KNN作為分類器進行結果評估,實驗結果如表1所示.
由實驗結果可見,深度學習提取特征總體上比傳統手工提取特征效果更為優秀,最佳效果是以ResNet為backbone進行特征提取和KNN進行分類,但其平均準確率也僅為43.7%,從側面反映ip102數據集具有一定的識別難度.
5.3 實驗對比與提升結果
對于3.1節提到的主流且效果較好的三種方法分別以5-way1-shot單樣本農業害蟲識別實驗設定充分進行對比實驗,在使用高斯分布校準新類樣本分布時最近鄰閾值 t 取5,分類器采用邏輯回歸,每次測試都在相同的測試集上循環實驗10 000次,取平均準確率作為最終結果,因為文獻[7,14-15]提出多以Conv4作為特征提取網絡,但最近研究發現Resnet10更能兼顧速度與精度,為了驗證方法有效性,分別以兩種特征提取網絡結合提出的方法均做了對比實驗,實驗結果如表2所示.
由實驗結果可見,本文提出的方法效果顯著,對于三種不同的方法識別準確率最高得到了687%增強,最差也有2.11%的提升.表現最好的是GNN網絡結合提出的特征增強模塊,在ip102數據集上得到了46.06%的分類準確率.
最后,對比兩種不同任務的實驗結果,可以發現小樣本方法利用極小的數據集獲得了超過傳統方法的識別準確率,但是,傳統方法是利用全部數據集在102個類別上進行預測,而小樣本方法是只抽取一張圖片在5個類別上進行預測,其識別準確率在數值其實沒有直接可比性,但對于實際應用而言,顯然小樣本方法更具有價值,因為對于未知類別而言并不需要在所有農業害蟲類別上進行識別,反而只給出個別專家標注樣本進行針對性的識別更有意義.
5.4 在其他數據集上的表現
目前小樣本學習的主要公開數據集為mini-ImageNet數據集,該數據集是從大型圖像分類數據集ImageNet中抽取的60 000張圖像構成的,總共分類100個類別,每個類別有600張尺寸為 84*84的自然圖像,數據集按照主流方法進行劃分,訓練集,驗證集和測試集分別占64個,16個,20個類別.選取Transductive和Inductive方法下效果最好的PrototypicalNet和GnnNet進行實驗,提升結果如表3所示.
由實驗結果可見,雖然對比其他方法PrototypicalNet和GnnNet表現已經很優秀,但是融合本文提出特征增強模塊依然得到了較大的提升,同樣說明本文方法在不同的數據集和不同的方法上均具有一定的普適性效果.可以作為小樣本學習的通用增強策略.
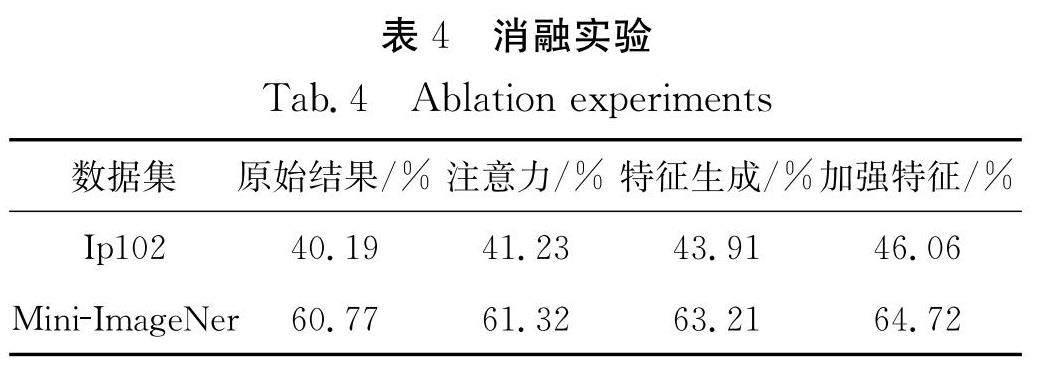
5.5 消融實驗
為了驗證提出的兩個模塊:雙注意力機制模塊和特征生成模塊的作用,采用兩個數據集上表現最好的GNN模型作為基礎架構,分別在兩個數據集上以Resnet10為backbone做了消融實驗,實驗結果如表4所示.
由實驗結果可見,在兩個數據集上只有注意力機制提升效果并不明顯,分別只有1.04%和055%,加上特征生成模塊后提升效果較為明顯,但是同時加上注意力機制和特征生成模塊效果相當顯著,分別達到了5.87%和3.95%的準確率提升,這同時也佐證了提出方法的理論有效性,分析原因,可能是因為利用原始網絡進行預測時注意力機制雖然有效,但是因為網絡學習已經比較徹底,在驗證時作用有限,而我們的方法第二階段進行驗證時需要非常依賴第一階段backbone生成的特征向量進行特征分布的度量,注意力機制使得網絡能夠更加關注每個類別之間不同的特征,配合第二階段的數據生成彌補測試集上樣本不足的情況,這樣兩種方法互相促進,所以會達到不錯的效果.
6 結 論
本文在針對目前基于深度學習的圖像分類在標記樣本不足的情況下表現較差的問題,首次將小樣本領域研究思路應用于大型公開農業害蟲數據集IP102上進行實驗并改進,對比傳統圖像分類方法在出現新的類別時如果沒有大量的訓練樣本便無法進行識別的問題,提出的方法在面對同樣的問題時只需要一個“引導樣本”便能很好的進行識別,該方法研究思路顯然更具實際應用價值.
但在實際應用過程中又發現目前主流小樣本研究方法均由于樣本數量不足存在識別精度過低的問題,本課題擬提出一個通用的模型以提高各種小樣本方法的識別準確率,于是將傳統小樣本方法統一成一個兩階段的訓練模式,在第一階段引入空間注意力機制和通道注意力機制以使網絡更好地提取特征;在第二階段為了防止網絡過擬合又基于高斯采樣的方法借助基類數據集糾正新類分布,綜合兩種方法識別精度能夠得到極大的提升,證明本實驗研究思路和方法確實是具有價值且正確的.
最后為了提高應用價值,在極具挑戰的IP102數據集上做了廣泛的基準實驗,驗證效果的同時,拋磚引玉以求引起更多的實際應用.且目前仍存在一定可以研究的空間,比如沒有解決數據長尾分布,沒有解決農業害蟲在不同生長時期的特征變化等一系列問題,因此后續依然會繼續跟進研究.
參考文獻:
[1] ??Yang J, Guo X, Li Y, ?et al . A survey of few-shot learning in smart agriculture: developments, applications, and challenges [J]. Plant Methods,2022, 18: 1.
[2] ?He K, Zhang X, Ren S, ?et al . Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway: IEEE, 2016: 770.
[3] ?Howard A, Sandler M, Chu G, ?et al . Searching for mobilenetv3[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE,2019: 1314.
[4] ?Tan M, Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks[C]//International conference on machine learning. Cambridge MA: JMLR, 2019: 6105.
[5] ?Dosovitskiy A, Beyer L, Kolesnikov A, ?et al . An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [EB/OL]. [2023-01-31]. https://www.webofscience.com/wos/alldb/full-record/INSPEC:20255744.
[6] ?Liu Z, Lin Y, Cao Y, ?et al. ?Swin transformer: Hierarchical vision transformer using shifted windows [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE, 2021: 10012.
[7] ?吳翔.基于機器視覺的害蟲識別方法研究[D].杭州: 浙江大學, 2016.
[8] ?Cheng X, Zhang Y, Chen Y, ?et al . Pest identification via deep residual learning in complex background[J]. Comput Electron Agr, 2017, 141: 351.
[9] ?周愛明.基于深度學習的農業燈誘害蟲自動識別與計數技術的研究[D].杭州: 浙江理工大學, 2018.
[10] ?Thenmozhi K, Srinivasulu U. Crop pest classification based on deep convolutional neural network and transfer learning [J]. Comput Electron Agr,2019,164:104906.
[11] Nanni L,Maguolo G,Pancino F. Insect pest image detection and recognition based on bio-inspired methods [J]. Ecol Inform, 2020, 57: 101089.
[12] Wu X, Zhan C, Lai Y K, ?et al . Ip102: A large-scale benchmark dataset for insect pest recognition [EB/OL].[2022-09-28].https://ieeexplore.ieee.org/document/8954351/.
[13] Hridoy R H, Afroz M, Ferdowsy F. An early recognition approach for okra plant diseases and pests classification based on deep convolutional neural networks [C]//Proceedings of the 2021 Innovations in Intelligent Systems and Applications Conference (ASYU). Elazig, Turkey: ASYU, 2021: 1.
[14] Snell J, Swersky K, Zemel R. Prototypical networks for few-shot learning[J]. NIPS, 2017, 30: 1.
[15] Garcia V, Bruna J. Few-shot learning with graph neural networks [C]//Proceedings of the 6th International Conference on Learning Representations, ICLR 2018. Vancouver, BC, Canada: OpenReview.net, 2018: 33.
[16] 趙凱琳, 靳小龍, 王元卓. 小樣本學習研究綜述[J]. 軟件學報, 2020, 32: 349.
[17] Chen W Y, Liu Y C, Kira Z, ?et al . A closer look at few-shot classification[C]//International Conference on Learning Representations. New Orleans, LA, United states: OpenReview.net, 2019.
[18] Hu J, Shen L, Sun G. Squeeze-and-excitation networks [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. NJ: IEEE, 2018: 7132.
[19] Yang S, Liu L, Xu M. Free lunch for few-shot learning: distribution calibration[C]//International Conference on Learning Representations. Vancouver, BC, Canada: OpenReview.net, 2021.
[20] Ng P C, Henikoff S. SIFT: Predicting amino acid changes that affect protein function [J]. Nucleic Acids Res, 2003, 31: 3812.
[21] Dalal N, Triggs B. Histograms of oriented gradients for human detection [C]//Proceedings of the ?2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05). San Diego, CA, USA: IEEE, 2005: 886.
[22] Oh J, Yoo H, Kim C H, ?et al . BOIL: towards representation change for few-shot learning [C]//Proceedings of the 9th International Conference on Learning Representations (ICLR). Stroudsburg,PA: OpenReview.net, 2021: 10112.
[23] Liu Y, Lee J, Park M, ?et al . Learning to propagate labels: Transductive propagation network for few-shot learning [C]//Proceedings of the 7th International Conference on Learning Representations, ICLR 2019. Stroudsburg,PA: OpenReview.net ,2019: 4440.
[24] Vinyals O, Blundell C, Lillicrap T, ?et al . Matching networks for one shot learning [J]. NeurIPS, 2016, 29: 2.
