基于深度自編碼器的室內指紋插值與定位方法
2023-05-11 08:58:24范貴明樂燕芬厲天宸
軟件導刊 2023年4期
范貴明,樂燕芬,厲天宸
(上海理工大學 光電信息與計算機工程學院,上海 200093)
0 引言
隨著無線網絡技術和智能設備的普及,各類基于位置服務的應用逐漸成為人們日常生活不可或缺的部分[1]。在室外區域,全球定位系統和北斗衛星導航系統能滿足大多數應用的定位需求。然而,由于無線信號的傳播受建筑構造、物體阻隔和人員走動等影響,無法利用衛星導航系統在室內區域實現有效定位。因此,其他信號,如Wi-Fi、RFID、ZigBee、紅外線、藍牙、慣性導航等被用于室內定位。隨著無線局域網(WLAN)作為室內接入系統的廣泛使用和無線通信設備的普及,基于Wi-Fi 信號的室內目標搜索、定位、導航和跟蹤等服務得到了極大發展。
其中,接收信號強度(Received Signal Strength,RSS)指紋的室內定位方法由于其部署成本較低且應用靈活的優點,成為國內外學者研究的熱點[2-5]。這些方法利用各接入點(Access Point,AP)或錨節點在各參考位置的RSS 信號確定定位區域的無線信號分布特性,并由此利用目標接收的RSS 信號完成位置估計。因此,基于無線信號的室內定位系統越來越獲得人們的認可。
無線定位基本分為兩類:一類基于測量方式,另一類基于指紋方式。基于測量方式的無線定位系統主要通過測量到達時間(Time of Arrival,TOA)、到達角度(Angle of Arrival,AOA)或到達時間差(Time Difference of Arrival,TDOA)進行位置估計[6]。然而,這些物理量不能直接被普通的無線信號接收器所測量,因此基于指紋方式的無線定位系統更具普適性[7-9]。基于指紋方式的定位系統一般采用機器學習的方法。文獻[7]采用K 近鄰(K Nearest Neighbors,KNN)方法,提出了基于指紋方式的無線定位系統。支持向量機(Support Vector Machine,SVM)也在文獻[10]中被用來確定設備的位置。文獻[11-12]分別提出利用壓縮感知(Compressive Sensing,CS)分析定位信號與指紋數據庫對應關系的方法。然而這些分類方法因其結果的離散性,使得系統的定位精度受到一定程度的限制。
文獻[13-14]用徑向基函數(Radial Basis Function,RBF)和多層感知(Multilayer Perceptron,MLP)解決無線定位問題。通過將無線信號強度輸入到訓練好的淺層神經網絡,直接得到連續的位置坐標。此外,基于人工神經網絡的定位系統可以得到比傳統方法更好的結果[15]。然而針對波動的無線信號,由于淺層網絡的擬合能力有限,上述文獻所提出的系統均難以實現精確定位。
在諸如視覺分類[16-17]和語音識別[18]等領域,深度神經網絡(Deep Neural Network,DNN)已獲得了成功應用。為此,本文提出基于深度神經網絡的無線定位方法:首先在離線階段利用少量的指紋數據,通過神經網絡對其他位置進行RSS 估值,實現對指紋庫更高密度的重構,減小離線階段對原指紋數據的依賴;然后,采用四層深度神經網絡結構,通過特征學習的方式,從大量波動的無線信號數據中提取特征,解決定位問題。利用堆疊自編碼器(Stacked Autoencoder,SAE)對網絡結構進行預訓練[19],并通過反向傳播進行全局微調,從而使網絡能夠避免手工方式,自動地從指紋數據中學習到高層特征,并通過這些特征進行位置估計,得到更魯棒的定位結果。
1 深度自編碼器指紋插值與定位方法
1.1 基于深度神經網絡的指紋庫重構
深度神經網絡內部分為輸入層、隱藏層和輸出層,層與層之間是全連接的,即前一層的任意一個神經元與后一層的任意一個神經元相連。基于深度神經網絡的插值結構如圖1 所示。在本文指紋庫重構過程中,利用離線采集的指紋數據對其他位置點的RSS 信號進行估值,從而生成位置密度更高的指紋庫。設整個區域內共有m個AP,布置 有n個參考 點,其位置 表示為pi=(xi,yi),i∈{1,2,…,n};在參考點pi接收的RSS 信號向量表示為Ri=(ri1,ri2,…,rim),其中rij,j∈{1,2,…,m}是參考點pi接收的來自第j個AP 的RSS 信號,其中RSS 類別數m已知。
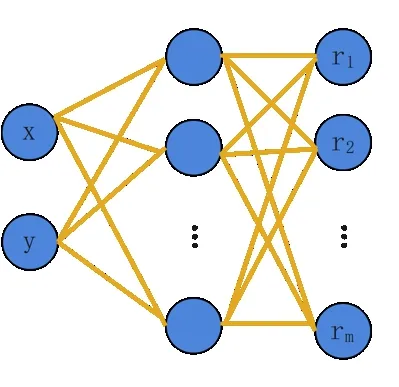
Fig.1 Structure of deep neural network圖1 深度神經網絡結構
在插值過程中,其位置坐標p=(x,y)作為輸入,相對應的信號強度值r=[r1,r2,…,rm]作為隱藏層的輸出。
模型訓練好后,系統通過計算得到插值點的信號強度,即:
其中,r=[r1,r2,…,rm]為插值點的信號強度,w為深度神經網絡的輸出層權重,b為輸出層偏置。
1.2 基于深度編碼器的位置定位
自編碼器是一種盡可能復現輸入信號的神經網絡。對接收的輸入樣本,經過編碼將其轉換成高效的抽象表示,而后經解碼過程再輸出原始樣本的重構。算法通過調整網絡參數使樣本的重構誤差達到最小值,從而獲得輸入樣本的最優抽象表示。從神經網絡的角度而言,編碼提取的抽象表示也即網絡的中間層或稱隱藏層。
SAE 是將多個自編碼器堆疊在一起組成的深度學習架構。輸入層的數據通過第一層的自編碼器后映射到第一個隱藏層;而后該隱藏層作為第二層自編碼器的輸入層繼續進行訓練獲得第二個隱藏層。訓練逐層進行,將前隱藏層的特征表達傳遞到后序的自動編碼器中。調整網絡中每層的參數,輸出每一個隱含層的權重和偏置,從而得到輸入和輸出數據的模型結構[20]。隱藏層的層數在SAE中起著重要作用,它對提取特征的不變性和抽象性起著關鍵作用。根據文獻[21],SAE 設置為5層。
如圖2 所示,在本文所提算法中,輸入的RSS 信號向量,通過SAE 提取的特征建立與位置坐標之間的映射模型。SAE 用梯度下降將輸入輸出的誤差最小化,然后將SAE 訓練結束的網絡作為初始狀態,為了有效地訓練定位系統參數,本文采用Dropout 方法,并設置隨機置零的概率為0.1。

Fig. 2 Structure of deep encoder圖2 深度編碼器結構
輸入層是由m個單元組成的,中間一層是n個單元組成的隱藏層。其中,輸入層r數據集表示每個AP 的RSS 數據,即:
其中,wi是權重矩陣,bi是偏置向量,fi是激活函數,例如有Sigmoid 函數,雙曲正切函數和修正線性單元函數等。該算法中采用的是Sigmoid 函數。
在線定位階段,定位系統用已訓練的深度神經網絡模型,從目標的RSS 信號向量中提取特征,然后通過深度神經網絡模型計算待測點的位置坐標,即p=(x,y)。
1.3 DNN-SAE算法步驟
如圖3 所示,DNN-SAE 算法由指紋數據庫、深度學習網絡、在線采集信號和定位位置預測等部分組成。大致分為離線階段和在線階段兩個部分。具體算法步驟如下:
Step1:在室內環境中采集的RSS 信號組成深度學習的原始訓練集。
Step2:利用深度神經網絡對其他位置的RSS 信號進行估值,最終完成指紋數據庫重構。
Step3:將重構的指紋數據庫輸入到SAE 中進行預訓練,逐層對RSS樣本編碼,提取特征數據。
Step4:通過SAE 提取的特征建立與位置坐標之間的映射模型。
Step5:逐層訓練并調整網絡參數,用梯度下降將輸入輸出的誤差最小化,訓練結束后得到關于RSS 信號與位置坐標的室內定位模型。
Step6:在線階段,利用訓練好的模型,從采集的RSS 信號提取有效特征,計算出所對應的位置坐標。

Fig.3 Block diagram of positioning algorithm of deep autoencoder圖3 深度自編碼器定位算法框圖結構
2 實驗結果與分析訓練
為驗證本文所提出的基于深度自編碼器的室內指紋插值和定位方法性能,在兩個不同的場景進行實驗,分別基于米什科爾茨大學提供的公共數據集[22]的房間區域類定位和基于自主采集的辦公環境數據集的精確定位類,以驗證本文所提方法的可行性和有效性。
2.1 實驗環境
數據集1 是米什科爾茨大學提供的公共數據集。該數據集采用ILONA 系統對一個三層辦公大樓進行了數據采集和記錄。測量位置遵循建筑上的網格布局,采樣點的間隔為1m。數據集1 采用了該公共數據集在1 樓采集的Wi-Fi 信號,實驗環境如圖4 所示,圖中的顏色和線條用于分隔區域。這個數據集共分為6 個房間,當對目標進行區域類定位時,則需正確判定目標所在的房間號。

Fig.4 Experimental layout of dataset 1圖4 數據集1的實驗布局
數據集2是在光電學院大樓面積約為70m×14m 的8樓環境中進行采集。實驗環境具體布局如圖5 所示,其中黑點為參考位置點,紅塊表示在線測試點(彩圖掃OSID 碼可見)。實驗中,利用移動智能終端搭載自主開發的微信小程序在多個工作日掃描采集參考點和測試點的Wi-Fi 信號強度和在線RSS 信號,將目標未能接收到信號的AP 的RSS值設為0。兩個實驗場景的參數如表1所示。
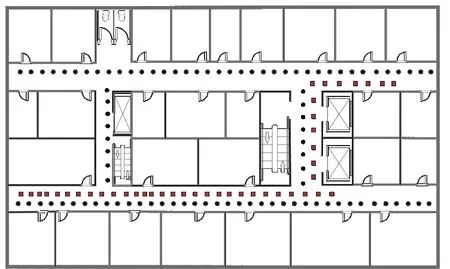
Fig.5 Indoor office map of dataset 2圖5 數據集2的室內辦公地圖

Table 1 Experimental parameter settings表1 實驗參數設置
2.2 定位空間內RSS估值結果分析
首先,對深度神經網絡定位空間內的RSS 估值結果進行實驗分析。從數據集1 中隨機抽取1stFloorLobby 中的101 個采樣點作為原指紋數據,分別采用深度神經網絡(DNN),距離加權反比例插值法(Inverse Distance Weight,IDW)和普通克里金算法(Kriging)對其余50 個待測點作RSS 估值;同樣從數據集2 中隨機選取區域內92 個采樣點的RSS 作為原指紋數據,用上述3 種算法對其余42 個待測點作RSS 估值,并對算法獲得的估計值與實測值進行對比。圖6(a)和(b)分別給出了在兩個數據集上的實驗結果。估值誤差是每個采樣點用算法估計的各AP 的RSS 值與實測值絕對誤差的平均值。
從圖6(a)和(b)可以看出,在數據集1 中DNN 的RSS估值誤差(估值點的估計值與實際值取絕對值作差,再取平均)整體低于IDW 和Kriging,其中有2 個位置點的誤差達到25dB 左右,最低在3dB 左右;而在數據集2 中,DNN 的誤差最高在16dB 左右,最低在3dB 左右,從兩個數據集中都能得出DNN 優于IDW 和Kriging。
2.3 區域類定位性能分析
區域定位,也即實現目標房間級精度的定位。實驗中采用數據集1 進行了多次實驗以評估本文所提指紋重構算法和定位算法的性能。
實驗中,首先分析不同數量的指紋數據訓練SAE 對定位精度的影響。在每個房間隨機選擇10%的指紋作為訓練數據,隨后逐步增加訓練數據量,另從指紋庫中隨機選擇了44個測試點進行位置估計。實驗結果如圖7所示。
圖中定位成功率指對目標估計的所在房間號與其實際房間號一致。從圖7 中可觀察到,隨著訓練數據的增加,不管是SAE 還是WKNN 算法,定位成功率都逐步提高。SAE 從81%提高到92%,WKNN 從80.5%提高到86%。

Fig.6 Comparison of the estimation results圖6 估值結果比較

Fig.7 Positioning success rate for every additional 50 training data圖7 每增加50個訓練數據的定位成功率
接著分析在少量指紋數據的情況下,如何通過插值提升定位性能。實驗中,在每個房間中隨機選取10%的指紋數據,并傳給深度神經網絡對其他位置點進行RSS 信號估值以重構高密度的指紋庫。從圖8 可以看出,僅使用44 個指紋數據時,本文所提算法的定位成功率約為83%,而WKNN 在80.5%左右。隨著新生成指紋數據的加入,算法的定位性能得到提高。在增加了200 個新生成得到的數據時,SAE 定位性能約為89%,WKNN 在85%左右。
2.4 精確定位結果分析
在數據集2 中,利用所提算法對42 個在線測試點進行實時定位,并與其真實位置進行比較,獲得定位誤差作為算法性能指標。考慮到監測區域內AP 點的數量較大,且樓層內狹長走廊的布局,使得某些AP 的信號較微弱,或者覆蓋范圍較小,因此實驗中根據每個AP 被檢測到的RSS信號強度之和以及每個AP 被檢測到的次數分別篩選AP,篩選結構如表2所示。

Fig.8 Positioning success rate for every 50 additional newly generated data圖8 每增加50個新生成數據的定位成功率

Table 2 AP screening results in data set 2表2 數據集2中AP篩選結果
采用兩種準則篩選AP 后的定位結果如圖9、圖10 所示。圖9 中篩選AP 強度之和大于300(108 個AP)的精度最好,SAE 算法的平均定位誤差為1.61m,WKNN 在2.26m,定位精度提高29%。而圖10 中篩選AP 被收到次數大于3個(144 個AP)的精度最好,SAE 的定位精度在1.6m,WKNN 在2.31m。從圖中也可觀察到,當AP 數量足夠多時,繼續增加AP,算法性能并不會有大的提升。

Fig.9 Positioning error obtained by filtering the number of APs based on the sum of AP intensity圖9 基于AP強度之和篩選AP得到的定位誤差
為了進一步驗證算法的定位性能,圖11 給出了數據集2 中本文所提算法、WKNN 算法的定位誤差累計分布函數。在本實驗中,在原有的92 個離線指紋庫中,加入15 個由深度神經網絡生成的新指紋。由誤差累計分布曲線可觀察到,整體曲線表明本算法在抑制大誤差和提高平均定位誤差的性能上均優于其他3 種方法。具體而言,上述4種算法在數據集2 中的平均定位誤差分別是1.49m、2.18m、1.75m 和2.33m,與WKNN 算法相比,該算法定位精度提高約36.1%。

Fig.10 Error obtained by screening the number of APs based on the detection time of AP圖10 基于AP被檢測的次數篩選AP個數得到的誤差

Fig.11 Comparison of positioning performance of different methods圖11 不同算法的定位性能比較
3 結語
本文提出了一種基于深度自動編碼器的離線指紋重構和室內定位方法。通過公共數據集和實際辦公環境收集數據實驗,對所提算法在區域類定位和精度定位中的性能進行了驗證和分析。實驗結果表明,更多的指紋訓練數據可以提高算法定位精度。而使用更多新生成的指紋數據,有利于節省構建指紋庫的時間和成本。通過與現有一些定位算法比較,在采用同樣數量的指紋數據時,通過深度神經網絡重構的高密度指紋庫和堆疊式自編碼器的定位模型,該算法在區域類定位中有利于定位成功率提升,在精確定位中則能有效降低定位誤差。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
