基于步態與聲紋特征融合的人物身份識別
2023-05-11 08:58:32熊經文岳文靜
軟件導刊 2023年4期
熊經文,陳 志,倪 康,岳文靜
(南京郵電大學 計算機學院,江蘇 南京 210023)
0 引言
步態與聲紋作為典型的生物特征,具有非配合性等特點,廣泛應用于門禁控制、法醫鑒定和安保系統等領域,但其單一模態的生物特征仍存在不足,如步態識別會受到復雜背景下難以提取步態輪廓圖、人物衣著覆蓋人體輪廓等因素影響,造成識別率不佳;聲紋識別中的環境噪聲可能對說話人聲紋特征造成干擾,導致系統無法準確學習說話人特征,從而產生誤判。多模態的生物特征識別使用不同的生物特征,將不同層面的互補身份信息相結合,能從多層面表征人物的身份信息,相比于單一模態的識別系統能夠更好地增強生物識別系統的魯棒性與準確性。因此,采用多種模態聯合進行生物身份識別是未來的研究趨勢,并且在科研和實際應用領域都受到廣泛關注。
國內外學者在該領域已開展了許多研究工作。文獻[1]提出將說話人聲紋與唇部相結合進行身份識別的方法,在特征層將兩種特征進行拼接,證明了聲紋與嘴唇特征的互補性,取得了不錯的效果;文獻[2]將視頻中的人臉與語音模態融合以進行維度情感識別,該方法使用注意力機制融合人臉與語音特征,為解決數據集中語音干擾較大的問題,將人臉特征與融合后的特征相加,增加人臉的權重,針對特定場景提升了模型的魯棒性;文獻[3]提出一種將虹膜與眼周特征融合的方法,通過共同注意力機制進行特征融合,取得了較好效果。目前的研究主要集中于人臉與語音、模態等方面,而基于步態與聲紋融合的研究較少。
針對上述情況,本文提出一種融合步態與聲紋的身份識別方法,使用GaitSet 網絡提取步態特征,通過提取聲音的MFCC 頻譜圖,將MFCC 特征輸入ResNet 網絡,使用CBAM 注意力機制關注頻譜圖的有用信息,提取聲音的高級語義特征,并將提取的特征通過門控注意力機制進行融合,設計與實現一個身份識別系統。
1 基于多模態融合的身份識別網絡
本文所提出的步態—聲紋多模態融合身份識別網絡模型框架如圖1 所示。該網絡使用預處理的提取的步態輪廓序列和音頻的MFCC 特征作為步態輸入及聲音輸入,分別通過步態、聲音模型提取各自的高級特征,之后進行特征融合。
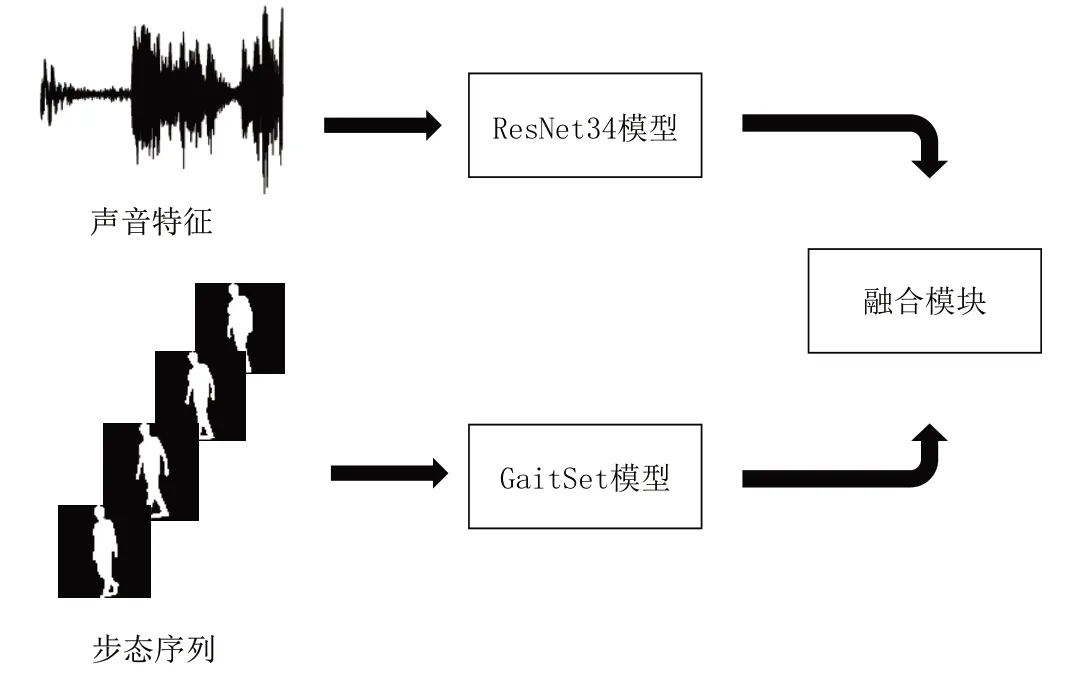
Fig.1 Gait-voiceprint joint recognition network architecture圖1 步態聲紋聯合識別網絡架構
1.1 步態特征提取
本文使用步態識別中的經典網絡GaitSet 提取步態特征,該網絡模型在步態識別任務中取得了良好效果,能夠有效提取步態輪廓序列的高級特征[4]。模型中以二值化的步態輪廓序列作為輸入,使用多個共享權重的CNN 卷積提取初步特征,通過集合池化的思想將幀級特征聚合成獨立序列級特征,很好地保留了空間和時間信息。經過驗證,當Gaitset 網絡輸入30 張步態序列圖片時,模型的準確率達到相對穩定,繼續增加步態序列數量,準確率提升不多,但計算量相對增加。因此,本文從一段視頻中抽取30幀作為模型的輸入,進而提取步態特征。
1.2 聲紋特征提取
在聲紋識別領域已進行了許多研究,如基于傳統方法的GMM-UBM[5],該方法采用高階高斯模型對說話人進行建模,適合于文本無關說話人識別;i-vector 方法描述說話人信息時,將語音映射到一個固定的低維向量,該方法有效降低了參數量,在與文本無關的聲紋識別中有較好表現[6];x-vector 利用時延神經網絡提取幀級特征,使用統計池化將幀級特征聚合為段級特征,在短語音情形下有著更強的魯棒性[7]。
本文采用基于ResNet34 的網絡進行聲音特征提取[8],ResNet 網絡在各種任務中都取得了較好效果,模型中使用殘差連接增強模型訓練的魯棒性,可有效解決梯度爆炸問題。本文網絡中使用自注意池化層[9]將幀級特征聚合為語句級特征,并在每個網絡塊的末端加入CBAM[10]注意力機制。通過結合通道注意力與空間注意力機制,CBAM 能增強聲音頻譜圖像的特征表達,關注其中的重要特征并抑制非重要特征。網絡模型具體參數如表1所示。

Table 1 Voiceprint model parameters表1 聲紋模型參數
1.3 融合模塊
生物特征具有多樣性,不同的生物特征相對于其他生物特征都具有獨特優勢,同時也有其不足,沒有一種生物特征能同時滿足所有需求,因此多特征識別則顯得尤為重要。在眾多生物特征中,人物的步態信息和聲紋信息相較于其他生物特征信息更易于獲取,且具有一定的非配合性,適用于非配合場景下的身份識別。但在實際的室內場景中,目標人物的步態視角可能會發生變化,或者受到遮擋等因素影響,一定程度上影響了步態識別的識別率。對于聲紋識別,在目標距離較遠的遠場景下,其聲音信息易受到噪聲干擾,而其步態受干擾較小;在近場景下且有遮擋的環境中,步態信息容易缺失,卻可以較好地采集聲音信息,兩者之間具有一定互補性。同時,人物的步態與聲音信息都包含了目標對象的性別[11]、年齡[12]等信息,具有一定的相關性,所以選擇將兩者進行融合。
在多模態融合中,不同模態的特征所分布的語義空間相差較大,要進行特征融合,必須使不同的模態特征映射到相同的語義空間中,才能對特征進行有效融合。由于步態與聲紋是兩種不同的生物模態,兩者差異較大,為了更有效地融合多源信息,分別將聲紋特征fs通過全連接層映射到256 維空間中,將步態特征fg映射到256 維空間中[13]。具體操作如下式所示:
在語音識別等時序任務中,GRU 和LSTM 將門控機制應用于模態融合[14],該結構可根據來自不同模態的數據組合找到中間表示,每個模態的輸入通過tanh 激活函數編碼,得到一個模態內部的表示特征。對于每個輸入的模態,通過門神經元σ 計算特征對單元整體的輸出貢獻度。本文使用門控注意力機制的方法[15]將輸入的特征進行拼接,通過注意力層關注兩個模態之間的交互。通過門神經元σ 得到不同模態的貢獻度,分別將每個模態的貢獻度與對應的模態特征相乘,計算出加權特征,將加權后的步態特征與聲紋特征相加作為最后的融合特征。公式如下:
式中,σ 為sigmod 激活函數,用來計算融合后的注意力分數,最終的融合特征為。經過tanh 激活函數,增加非線性變化,分別乘以注意力權重z與1-z,計算得到不同模態加權和ep,即融合特征。
2 身份識別系統設計
基于多模態的步態與聲紋身份識別網絡設計身份識別系統,主要框架如圖2 所示,分為行人檢測、數據預處理、融合身份識別幾個模塊。
2.1 行人檢測
身份識別系統使用YOLO 算法[16]檢測并提取行人圖像框。YOLO 算法是目標檢測的經典算法,研究者們已經提出了多個版本,比較經典的有YOLOv3、YOLOv4、YOLOv4-tiny、YOLOv5 等。經過比較,綜合層面YOLOv4 算法的性能最優,YOLOv5 算法模型較小,速度最快,但識別精度較低。綜合考慮計算力和實時性的要求,選擇使用YOLOv5 算法進行行人檢測,當檢測到行人時再進行聲音檢測。

Fig.2 Main framework of the system圖2 系統主要框架
2.2 數據預處理
在實際場景中,圖像幀可能出現復雜背景,受到地面反光或者光照產生倒影等因素影響,使用傳統的背景減除法、幀差法雖然效率高、運行速度快,但會產生噪點。在極端情況下,步態輪廓信息會被破壞。本文選擇使Mask RCNN 算法[17]進行分割,并對圖像進行二值化處理,得到步態輪廓圖。
對采集的聲音信號進行靜音檢測,保留聲紋音量大于閾值的聲音信息。本系統僅針對單人情況下進行身份識別,即每次只識別一名人員,同時目標人員需要正常走動與說話,以確保獲取步態與聲紋信息。
對采集的所有音頻進行預加重處理,避免聲音在低頻的強度大于高頻,采樣率為16KHz。以25ms 每幀進行分幀,為避免兩幀間變化過大,在幀與幀之間加入10ms 幀移,并采用漢明窗進行加窗,然后進行傅里葉變換,得到語譜圖,對每幀語譜圖進行均值和歸一化處理。
2.3 身份識別
身份識別模型使用上述提出的步態—聲紋聯合識別網絡。由于實驗采集的數據量有限,為防止小數據的過擬合,步態、聲紋特征提取模型分別使用CASIA-B 和VoxCeleb1[18]公開數據集上的預訓練模型。
3 實驗與結果分析
實驗代碼采用的語言為Python3.8,使用深度學習框架Pytorch1.7 實現。實驗環境如下:操作系統為Ubuntu20.04,硬件設備為英特爾i9-10090K 處理器,顯卡為英偉達3090。實驗使用反向傳播與交叉熵損失函數訓練模型,并采用五折交叉驗證法對數據集分開進行訓練測試。
3.1 實驗數據集
本文使用在實際場景中自采的步態—聲紋數據集,數據集中包括10 人的步態與聲紋數據。其中,步態使用英特爾D435i攝像頭,分為與攝像頭夾角成90°與270°的兩個行走方向進行采集。主要考慮人員衣著正常的情況,每位人員一共采集20 段行走視頻,每段視頻約120 幀,然后提取出人物輪廓圖,并手動剔除人員進入與走出畫面的無效幀,最后每段視頻得到約90 幀。聲音數據使用NX 開發板外接的麥克風采集,聲音數據與步態數據在相同角度下采集,每位人員一共采集20 段音頻,手動去除開始與結束的靜音片段。
3.2 實驗結果與分析
為了驗證所提出的多模態步態和聲紋身份識別網絡的有效性,首先對融合特征與聲紋特征以及步態特征進行比較。由于聲音數據是在實際場景中進行采集的,包含風扇、空調等環境噪音,所以對音頻進行降噪處理,降低噪聲對識別結果的影響。處理后的單模態與融合模態在測試集上的性能如表2 所示。根據表2 的實驗結果可見,聲音數據經過降噪處理后,在5 個子集上都取得了較高的準確率,平均準確率可達到81.95%,高于步態識別方法。使用步態加聲紋融合特征的方法,在數據集上的平均識別率可達到83.64%,并且在所有子集上都取得了比聲紋、步態識別更好的實驗結果。由此可見,步態與聲紋融合識別方法相比兩個單模態識別方法具有更好的性能。
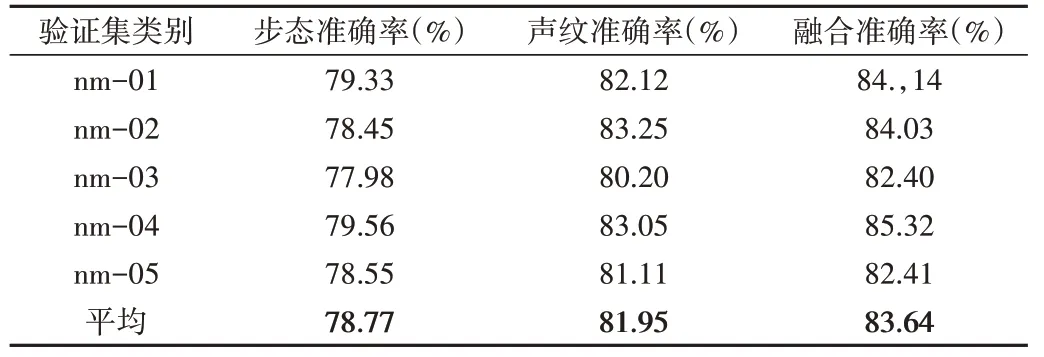
Table 2 Experimental results after data set noise reduction表2 數據集降噪后實驗結果
為進一步驗證融合模態系統的魯棒性,使用步態與聲音未進行降噪的原始數據進行實驗,同時采用拼接的方法,將1*256 維步態特征與1*256 維聲紋特征拼接成1*512維融合特征,并與本文方法進行了對比,實驗結果如表3所示。

Table 3 Original dataset experimental results表3 原始數據集實驗結果
從表3 的實驗結果可以看出,當聲音信息源被噪音干擾時,聲紋識別的準確率受到了較大影響,平均識別準確率為78.89%,相比降噪后的識別率有所下降。而將兩種特征直接拼接的方法取得了81.95%的準確率,高于聲紋識別方法,說明該方法受到干擾較小,具有一定的魯棒性。本文方法的識別率均高于前兩種方法,獲得了最好的識別效果,因為該方法會根據單模態對系統所作的貢獻進行權值分配,對于信息干擾較大的模態分配較小的權值,減弱其對系統的影響。因此,進一步驗證了多模態聯合模型對單模態噪音干擾具有一定的魯棒性,效果優于單模態方法。
4 結語
本文在實際場景下采集了注冊人員的步態—聲紋數據集,設計了聯合步態聲紋多模態身份識別系統,并在自采數據集上對所提出的步態—聲紋聯合模型進行驗證。使用經過降噪處理的音頻數據,模型取得了83.64%的準確率,證明了所提出模型的有效性,并進一步在具有噪音干擾的原始音頻數據集上進行驗證,模型取得了80.27%的準確率,兩種情況都優于單模態系統與簡單拼接的多模態系統,進一步證明了模型的抗干擾性與魯棒性。
在未來的研究中,以下方面需要作進一步改進:步態聲紋數據集數據量仍需進行擴充,后續研究將采集更多的行走視角以及行走狀態的數據,進一步驗證模型的魯棒性;在監控視頻中,人臉信息也可能會被捕捉到,將來可考慮使用決策層融合的方式實現步態、人臉和聲音三模態聯合系統,進一步提高系統的準確率與魯棒性;此外,本文只針對視頻中單人出現的場景進行識別,對于多人場景下的身份識別,還需要作進一步探索。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
