基于CEEMDAN-VMD-LSTM的超高頻金融時間序列預測
2023-05-14 19:29:04閆勇志沐年國
計算機時代 2023年5期
閆勇志 沐年國
摘? 要: 對超高頻金融數據的預測,模態分解降低了數據的噪聲,提高了數據預測精度。據此提出了自適應噪聲的完整集合經驗模態分解(CEEMDAN)與變分模態分解(VMD)相結合的二次分解模型。先將期貨日度行情數據通過CEEMDAN一次分解,并通過樣本熵將分解后的序列整合成高頻、低頻和趨勢序列;再將高頻和低頻序列分別進行VMD分解,然后將各個IMF分量通過LSTM網絡預測,最終整合各個預測結果。模型各項指標均好于一次分解。
關鍵詞: 超高頻金融數據; CEEMDAN; VMD; 二次分解
中圖分類號:TP391? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2023)05-102-07
UHF financial time series predicting based on CEEMDAN-VMD-LSTM
Yan Yongzhi, Mu Nianguo
(Business School, University of Shanghai for Science & Technology, Shanghai 200093, China)
Abstract: For the prediction of UHF financial data, modal decomposition reduces the noise of data and improves the accuracy of data prediction. Accordingly, a quadratic decomposition model combining the complete ensemble empirical mode decomposition for adaptive noise (CEEMDAN) and variational mode decomposition (VMD) is proposed. Firstly, the daily market data of futures are decomposed by CEEMDAN, and the decomposed series are integrated into high-frequency, low-frequency and trend series by sample entropy. Then, the high-frequency and low-frequency series are decomposed by VMD respectively, and each IMF component is predicted by LSTM network. Finally, the prediction results are integrated. Compared with CEEMDAN decomposition and VMD decomposition, each index of the proposed model is better.
Key words: UHF financial data; CEEMDAN; VMD; quadratic decomposition
0 引言
超高頻金融數據是根據市場上的每一筆交易來進行采集,時間間隔不固定,具有非平穩、非線性以及高度復雜的特征[1]。如何準確掌握日內超高頻數據是量化投資領域的重大課題之一。
金融高頻數據的預測主要方法是通過神經網絡進行預測,Hajiabotorabi等[2]采用基于B樣條小波多分辨率改進DWT-RNN模型,結果表明,BS3-RNN預測模型比使用其他小波或神經網絡模型具有更好的預測能力,但是RNN模型有梯度消失問題,因此Bukhari等[3]提出了ARFIMA-LSTM模型,不僅最小化了波動性問題,而且克服了神經網絡的過擬合問題。
金融高頻數據含有大量噪聲,諸多學者采用小波降噪法對金融數據進行處理。Huang[4]提出了經驗模態分解方法,引入復雜數據集的瞬時頻率,消除了表示非線性和非平穩信號的雜散諧波的需要。Afolabi et al[5]利用EMD方法結合LSTM神經網絡對蘋果公司股價進行預測;但是EMD會造成模態混疊的問題,Huang and Wu[6]提出了一種基于集成經驗模式分解(EEMD)的算法,有效遏制EMD模態混合問題,Yeh等[7]提出互補集合經驗模式分解(CEEMD)克服了EEMD重構誤差大、分解完備性差的問題。Torres[8]提出自適應噪聲的完整集合經驗模態分解(CEEMDAN)固有模態分量中殘留噪聲更少,有效減少重構誤差,分解效率最高。馮曉天[9]年提出CEEMDAN-SSA-LSTM方法,基于1分鐘收盤價高頻數據的CEEMDAN-SSA-LSTM模型是預測效果最好的模型。
Konstantin Dragomiretskiy[10]提出一種變分模態分解(VMD)方法,一種自適應、非完全遞歸的非線性分解方法,可以實現分解模態的同時提取,有效地將時間序列中混入的高斯白噪聲分離,實現信號的降噪處理。史心怡[11]改進類經驗模態分解-LSTM-Adaboost組合模型對股市波動率預測研究,結果表明VMD的分解精度優于EEMD。
近年很多學者考慮二次分解技術,以求提高模型的預測精度,程文輝等[12]提出二次分解與LSTM的金融時間序列預測算法,將VMD和EEMD相結合,將VMD分解后的殘余分量二次處理,結果表明,二次分解算法有效提升模型的預測能力。何榮輝[13]年提出多元預測模型對短期風電功率進行預測研究,通過CEEMDAN一次分解后,將波動大的IMF分量進行VMD分解,二次分解后的預測結果好于對比模型。唐莉[14]提出混合分解集成模型對碳排放權價格進行研究,首先通過CEEMDAN對序列進行一次分解,然后通過計算IMF模糊熵值,將模糊熵值大的分量進行VMD分解,結果表明二次分解好于其他模型。Feite Zhou等[15]總結了兩個基本的CEEMDAN-LSTM框架,并提出了一種與VMD相結合的混合框架對碳價格進行預測研究,結果表明,二次分解技術能夠提高一次分解的預測精度。
綜上所述,對非平穩、非線性的時間序列數據,基于CEEMDAN和VMD的二次分解方法具有較好的預測效果。因此本文提出CEEMDAN-VMD-LSTM對超高頻金融數據進行研究,主要貢獻有:
⑴ 通過樣本熵重構高頻序列和低頻序列,對兩個序列分別進行VMD分解,充分利用CEEMDAN和VMD分解,并且對比單變量回歸和多變量回歸結果,結果表明對高頻和低頻序列都進行二次分解后,單變量回歸模型略好;
⑵ 期貨行情數據,即超高頻數據的研究較少,本文提出的預測方法,為期貨量化交易,提出了新的方向。
1 研究方法
1.1 CEEMDAN
具有自適應噪聲的完全集成經驗模態分解(CEEMDAN)是由EMD、EEMD和CEEMD發展而來的。定義[EMDn·]為應用 EMD 算法產生的第[n]個階段的模態分量,CEEMDAN算法產生的第[n]個模態分量記為[IMFn]該算法的實現過程如下:
(a) 將待分解的信號[ft]添加[ n]次均值為0的高斯白噪聲序列,構造共[n]次實驗的待分解序列[fit]。
[fit=f(t)+ε0ωi(t),i=(1,2,...,n)]? ⑴
其中,[ε0]為信噪比,[ωi(t)]為第i次添加的白噪聲序列
(b) 對每一個[fit]應用EMD算法進行分解,得到第一個模態分量(IMF)及第一個唯一殘余分量[r1(t)]:
[IMF1(t)=1ni=1nIMFi1(t)=1nEMD1(fi(t))]
[r1(t)=f(t)-IMF1(t)]? ⑵
(c) 將分解后得到的殘余分量添加噪聲繼續應用 EMD進行分解。
[IMFk(t)=1ni=1nEMD1(rk-1(t)+εk-1EMDk-1(ωi(t))),k=2,3...,n]
[rk(t)=rk-1(t)-IMFk(t)]? ⑶
(d) 最后,當殘差不超過兩個極值點且不能繼續分解時,終止CEEMDAN算法。此時,殘差趨勢明顯而直接,原始信號序列被分解為n個模態分量和殘差項[R(t)]:
[ft=k=1nIMFkt+Rt] ⑷
1.2 樣本熵
樣本熵可以評價時間序列數據的系統復雜度,是對近似熵的改進。以和的對數計算,以減少近似熵誤差。與近似熵相比,樣本熵的計算不依賴于數據長度,具有更好的一致性。一般來說,序列的樣本熵越大,表示序列越復雜。
(a) 設[n]為數據點總數,[m]為待比較序列的長度,則向量[xmi]可表示為:
[xmi=xi,x(i+1),..,x(i+m-1),i=1..,n-m+1] ⑸
(b) 定義(a)中兩個向量之間的距離為
[dmxm(i),xm(j)=max[xm(i+k)-xm(j+k)],0≤k≤m-1] ⑹
(c) 給定閾值r,統計[dmxm(i),xm(j)≤r]的個數記為[νm],增加維度至[m+1],統計[dm+1xm+1(i),xm+1(j)≤r]的個數記為[ωm+1]。
(d) 確定匹配點的概率,[Bmr]為[m]維概率,[Amr]為m+1維概率:
[Bmr=1n-mi=1n-mvmin-m+1Amr=1n-mi=1n-mwm+1in-m+1] ? ⑺
(e) 樣本熵定義為[S(m,r)]:
[Sm,r=limn→∞(-lnAmrBmr)] ⑻
當n為有限值時,樣本熵可用以下公式估計:
[Sm,r,n=-lnAmrBmr] ⑼
1.3 VMD
VMD是一種信號分解方法,在得到分解分量的過程中,通過迭代搜索變分模型的最優解,確定各分量的中心頻率和有限帶寬,從而自適應地實現信號的頻域劃分和各分量的有效分離。VMD將每個分量的估計帶寬之和最小化,并使用交替方向乘子法提取相應的中心頻率。
VMD的核心思想是構建和求解變分問題。需求解的約束變分優化問題如式:
[minuk,wkk∥?t(δt+jπt)*ukte-jwkt∥22] ? ⑽
[s.t.k=1Kuk(t)=f(t)] ⑾
其中,[uk]輸入信號分解后第k個模態函數,[wk]為中心頻率,[K]為需分解的模態數量[δt]為單位脈沖函數,[f(t)]為原始信號。
(a) 為了解決優化問題,引入拉格朗日乘數和二階懲罰因子[α],然后將約束變分問題轉化為無約束變分問題,得到增廣拉格朗日表達式:
[Luk,wk,λ=αk∥?t(δt+jπt)*ukte-jwkt∥22]
[+∥f(t)-kuk(t)∥22+λt,f(t)-kuk(t)] ⑿
(b) 利用交替方向乘子法計算鞍點即原問題最優解,求解[uk]、[wk]和[λ]
[un+1kw=f(w)-i≠kui(w)+λw/21+2αw-wk2]? ⒀
其中,[un+1kw]、[uiw]、[fw]、[λw]是[un+1kw]、[uiw]、[fw]、[λw]的傅里葉變換。
(c) 更新[wk]
[wn+1k=0∞w|un+1k(w)|2dw0∞|un+1k(w)|2dw] ⒁
(d) 更新[λ]
[λn+1(w)=λn(w)+τf(w)-kun+1k(w)] ⒂
其中,[τ]為噪聲的容忍度。
重復上述步驟直到滿足迭代條件。
1.4 LSTM
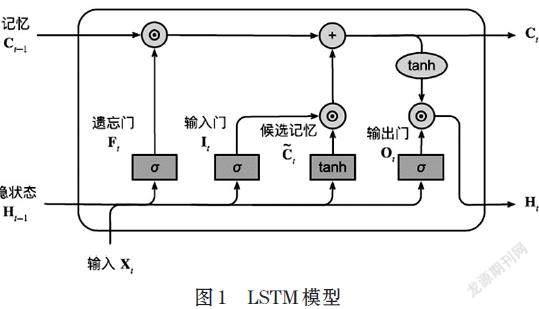
LSTM模型在圖像數據處理中,其主要可以緩解梯度消失和梯度爆炸,模型由三部分組成,如圖1所示,分別為輸入門、遺忘門和輸出門。
LSTM模型的數學表達如公式⒃:
[It=σ(XtWit+Ht-1Whi+bi)Ft=σ(XtWxf+Ht-1Whf+bf)Ot=σ(XtWxo+Ht-1Who+bo)Ct=tanh(XtWxc+Ht-1Whc+bc)Ct=Ft⊙Ct-1+It⊙CtHt=Ot⊙tanh(Ct)] ⒃
其中,[Ht-1]為前一步時間隱狀態,[Wxi]等為權重,[bi]等為偏置項,[Ct]為輸出
2 數據處理
2.1 數據采集
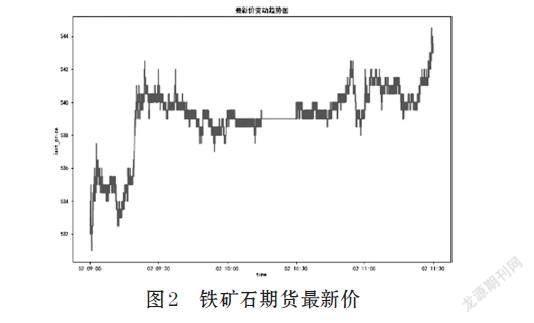
文章選取大連商品交易所,鐵礦石主力期貨,2018年1月2日9:00-11:30的最新價作為研究對象。9:00-11:30共有15684個數據。最新價變動趨勢如圖2所示。
2.2 數據分析
2.2.1 平穩性檢驗
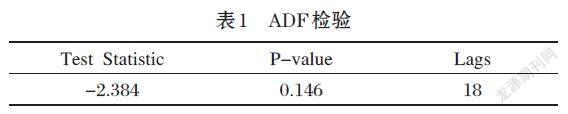
通過Python 中Statsmodels模塊中的函數,使用增強的Dickey-Fuller(ADF)測試來測試數據的平穩性,如表1所示p值為0.146大于0.05,因此接受原假設,認為數據是非平穩序列。
2.2.2 自相關檢驗
LB(Ljung-Box)統計量檢驗序列自相關性,p值為0小于0.05,拒絕原假設,表明數據具有很強的自相關性。
使用Statsmodels模塊計算自相關函數(ACF)和偏自相關函數,如圖3所示, PACF顯著拖尾性,顯示了最新價的自相關關系。
2.2.3 正態性檢驗
JB(Jarque-Bera)統計量檢驗序列正態性,偏度為-1.25,峰度為1.229,p值為0小于0.05,拒絕原假設,序列不服從正態分布。
3 模型建立
3.1 模型評價指標
本文采用均方根誤差RMSE、R Squared、平均絕對誤差MAE、平均絕對百分比誤差MAPE以及準確率作為評價指標。RMSE、MSE、和MAPE反應了預測值和真實值得偏差,數值越小模型擬合越優;R Squared和準確率反應了模型的擬合優度,數值越接近1,擬合效果越好。計算公式如下
[RMSE=1Ni=1Nyi-yi2] ⒄
[R2=1-i=0myi-yi2i=0myi-yi2] ? ⒅
[MAE=1Ni=1N|yi-yi|] ? ⒆
[MAPE=1Ni=1N|yi-yiyi|*100%] ⒇
對于準確率(ACC)的計算,鐵礦石主力期貨數據最小變動單位為0.5,且數據僅有一位小數;將預測的數據與真實數據做差,如果兩者之差的絕對值小于等于0.25,則認為預測值與真實值相等。
3.2 CEEMDAN分解與樣本熵
基于第1章的數學理論,本文使用PyEMD信號模塊中的CEEMDAN函數對鐵礦石主力期貨1月2日上午最新價數據進行分解。圖4(a)顯示了13個IMF從上到下的分解結果。橫軸表示最新價的時間序列號,縱軸表示單位為元的每個部分的價值。序列的頻率和復雜性逐漸降低,變化模式比原始序列更直觀,整體價格趨勢也更明顯。
Python中sampen模塊使用樣本熵來度量每個IMF的復雜性。基于Wang等[16]人的研究,整合具有相似樣本熵值的IMF可以適當減少計算量,增加建模速度,減少過擬合。在圖4(b)中無論m和r的取值如何,第二個和第三個IMF分量的樣本熵值均高于其他分量所對應的值,這代表了一種復雜的、易變的模式;同時第6-13個IMF分量,復雜性波動性很小。因此,這13個IMF可以集成為三個新的合作固有模式函數(Co-IMF):高頻序列Co-IMF0(IMF1-2)、低頻序列Co-IMF1(IMF0、IMF3-4)和趨勢序列Co-IMF2(IMF5-12)。這三個Co-IMF的變化模式相對規則且直接,這便于進一步提取每個IMF的波動特征并訓練預測模型。在實際的建模過程中選取m=1,r=0.1參數進行建模,聚類過程如圖4(c)所示。
3.3 VMD分解
為了準確預測高頻序列,本文利用二次分解方法對高頻序列進行進一步分解。參考Li等[17]人的文獻,使用一種稱為變分模態分解(VMD)的信號分解方法。
避免數據分解出現欠分解和過分解,需要確定序列分解的[K]值,令[K=2,3,...,13]分別進行分解,計算中心頻率,每個[K]值對應的最后頻率隨K值增加,中心頻率逐漸平穩,因此選取[K=10]作為VMD模型分解的參數,其他參數使用默認參數。
由于EMD、EEMD和CEEMDAN都來自EMD,使用它們來重新分解高頻序列不能獲得良好的結果。如表2所示,對于高頻序列數據(Co-IMF0)VMD分解后進行預測的結果RMSE、MAE和MAPE指標均好于CEEMDAN分解和不分解。表明二次分解采用VMD分解能夠將復雜數據分解,模型能夠取得較好的效果。
3.4 CEEMDAN-VMD-LSTM
根據3.2節和3.3節的分析,設計一個CEEMDAN-VMD-LSTM模型對期貨日度高頻最新價進行預測。具體步驟如下:
⑴ 數據處理后進行CEEMDAN分解,得到若干IMF分量。
⑵ 計算⑴中的IMF分量的樣本熵,聚類整合成高頻序列Co-IMF0、低頻序列Co-IMF1和趨勢序列Co-IMF2。
⑶ 將高頻序列Co-IMF0進行VMD分解,并通過LSTM模型預測
⑷ 將低頻序列Co-IMF1進行VMD分解,并通過LSTM模型預測
⑸ 將趨勢序列Co-IMF2直接通過LSTM模型預測。
⑹ 整合三個預測的序列,并分析相關指標。
4 實驗
4.1 參數設置
鐵礦石主力期貨序列數據包含15684個樣本點,將10:45-11:30數據作為測試集,9:00-10:45數據作為訓練集,即2/3數據用于訓練,1/3數據用于測試。時間步長選取10,即選取10個數據預測下一時刻數據。
4.2 對比模型
為了驗證模型的可行性,選取六種模型對比:
模型1(LSTM):將期貨數據序列直接通過LSTM神經網絡預測。
模型2(EMD-LSTM):將期貨序列進行EMD分解后,每個IMF分量分別通過LSTM網絡預測,最終整合各個分量。
模型3(CEEMDAN-LSTM):將期貨序列進行CEEMDAN分解后,每個IMF分量分別通過LSTM網絡預測,最終整合各個分量。
模型4(VMD-LSTM):將期貨序列進行VMD分解后,每個IMF分量分別通過LSTM網絡預測,最終整合各個分量。
模型5(CEEMDAN-VMD-LSTM多變量):將期貨序列數據,通過CEEMDAN一次分解后,采用樣本熵聚類,整合成高頻、低頻和趨勢序列,然后對高頻和低頻序列進行VMD分解,將分解后的序列通過LSTM網絡,多變量回歸,最后將各個預測值相加。
模型6(CEEMDAN-VMD-LSTM單變量):將期貨序列數據,通過CEEMDAN一次分解后,采用樣本熵聚類,整合成高頻、低頻和趨勢序列,然后對高頻和低頻序列進行VMD分解,將每個IMF分量分別通過LSTM網絡預測,最后將各個預測值相加。
4.3 實驗結果分析
由于深度學習的預測具有一定的隨機性,因此將各個模型預測10次,對指標取均值再對模型進行相應的評價,能夠增加模型的可信度。
6個模型分別預測10次,各個指標取均值的結果如表3所示,圖5將四個指標做了可視化展示。
如表3和圖5所示,模型2通過EMD分解解決了數據不平穩的因素,各項指標均優于模型1,R2值高3.94%,RMSE值低8.28%,MAE值低5.14%,MAPE值低0.96%,ACC值高11.22%。
模型3通過CEEMDAN分解,解決了EMD分解中的模態混疊問題,各項指標均優于模型2,R2值高1.36%,RMSE值低4.42%,MAE值低4.01%,MAPE值低0.75%,ACC值高5.11%。
模型4引入VMD分解,VMD分解能夠更好的分解非平穩、非線性以及復雜的數據,各項指標均好于模型3,R2值高1.47%,RMSE值低5.79%,MAE值低4.88%,MAPE值低0.88%,ACC值高3.01%。
模型6先通過CEEMDAN分解數據,再根據樣本熵重構,重構后的序列再通過VMD分解,最后接LSTM網絡預測,模型充分利用了CEEMDAN和VMD分解的特點,各項指標均好于模型4,其中 R2值高0.32%,RMSE值低2.1%,MAE值低1.58%,MAPE值低0.3%,ACC值高3.1%,進一步說明CEEMDAN-VMD-LSTM模型好于一次分解的EMD、CEEMDAN以及VMD模型。
5 結束語
本文提出一種基于CEEMDAN的二次分解方法,通過樣本熵重構CEEMDAN分解后的序列,復雜序列通過VMD分解后,將各個分量分別通過LSTM模型預測,最終將預測結果整合。通過實驗分析和模型對比,可以得出以下結論。
⑴ CEEMDAN-VMD-LSTM模型處理期貨日度高頻數據,具有更高的準確率,能夠跟蹤期貨tick數據的趨勢以及變化。
⑵ VMD模型處理非線性、非平穩以及復雜的數據,表現得比EMD系列更好,因此將重構的數據通過VMD模型分解,提高了模型的準確度。
未來的工作可以將期貨量化研究、比如期貨做市模型、高頻交易等相聯系。
參考文獻(References):
[1] 田聰.基于改進型EMD-LSTM的高頻金融時間序列預測[D].
碩士,江西財經大學,2021
[2] Zeinab Hajiabotorabi,Aliyeh Kazemi,Faramarz Famil
Samavati,Farid Mohammad Maalek Ghaini. Improving DWT-RNN model via B-spline wavelet multiresolution to forecast a high-frequency time series[J]. Expert Systems With Applications,2019,138(C)
[3] Bukhari A H, Raja M A Z, Sulaiman M, et al. Fractional
neuro-sequential ARFIMA-LSTM for financial market forecasting[J].Ieee Access,2020,8: 71326-71338
[4] Norden E. Huang,Zheng Shen,Steven R. Long,Manli C.
Wu,Hsing H. Shih,Quanan Zheng,Nai-Chyuan Yen,Chi Chao Tung,Henry H. Liu. The Empirical Mode Decomposition and the Hilbert Spectrum for Nonlinear and Non-Stationary Time Series Analysis[J]. Proceedings: Mathematical, Physical and Engineering Sciences,1998,454(1971)
[5] Noemi Nava,T. Di Matteo,Tomaso Aste. Anomalous
volatility scaling in high frequency financial data[J]. Physica A: Statistical Mechanics and its Applications,2016,447
[6] Wu Z, Huang N E. Ensemble empirical mode decomposi-
tion: a noise-assisted data analysis method[J].Advances in adaptive data analysis,2009(1):1-41
[7] Yeh J R, Shieh J S, Huang N E. Complementary ensemble
empirical mode decomposition:A novel noise enhanced data analysis method[J]. Advances in adaptive data analysis,2010(2):135-156
[8] Torres M E, Colominas M A, Schlotthauer G, et al. A
complete ensemble empirical mode decomposition with adaptive noise[C]//2011 IEEE international conference on acoustics, speech and signal processing (ICASSP).IEEE,2011:4144-4147
[9] 馮曉天.基于CEEMDAN-SSA-LSTM的高頻股票價格預
測研究[D].碩士,江西財經大學,2022
[10] Konstantin D, Zosso D. Two-dimensional variational
mode decomposition[C]//Energy Minimization Methods in Computer Vision and Pattern Recognition,2015,8932:197-208
[11] 史心怡.基于改進類經驗模態分解-LSTM-Adaboost組
合模型對股市波動率預測研究[D].碩士,上海師范大學,2022
[12] 程文輝,車文剛.基于二次分解與LSTM的金融時間序列
預測算法研究[J].重慶郵電大學學報(自然科學版),2022,34(4):638-645
[13] 何榮輝.基于多元預測模型的短期風電功率預測研究[D].
碩士,廣西大學,2022
[14] 唐莉.基于混合分解集成模型的碳排放權價格的實證研究[D].
碩士,山東大學,2021
[15] Zhou Feite,Huang Zhehao,Zhang Changhong. Carbon
price forecasting based on CEEMDAN and LSTM[J]. Applied Energy,2022,311
[16] Wang Jujie,Sun Xin,Cheng Qian,Cui Quan. An
innovative random forest-based nonlinear ensemble paradigm of improved feature extraction and deep learning for carbon price forecasting[J]. Science of The Total Environment,2020,762(prepublish)
[17] Li Hongtao,Jin Feng,Sun Shaolong,Li Yongwu. A new
secondary decomposition ensemble learning approach for carbon price forecasting[J].Knowledge-Based Systems,2021,214(prepublish)
