YOLOv4算法在安全帽目標(biāo)檢測(cè)技術(shù)中的應(yīng)用
2023-05-24 20:53:03程瀟劉雪梅郭幸語韓昌
無線互聯(lián)科技 2023年5期
程瀟 劉雪梅 郭幸語 韓昌
摘要:目標(biāo)檢測(cè)技術(shù)廣泛應(yīng)用于各個(gè)領(lǐng)域,其目的是通過對(duì)輸入圖像中的物體和場(chǎng)景進(jìn)行信息的特征提取,從而識(shí)別圖中感興趣的目標(biāo)。為了減少作業(yè)人員在建筑工地作業(yè)時(shí)因未佩戴安全帽造成的人員傷亡事故,文章提出了一種基于深度學(xué)習(xí)的建筑工地安全帽目標(biāo)智能檢測(cè)方法,檢測(cè)建筑工地人員安全帽佩戴情況,提高行業(yè)安全生產(chǎn)效率。本研究通過安全帽數(shù)據(jù)集進(jìn)行先驗(yàn)框設(shè)計(jì),采用k-means算法獲得本數(shù)據(jù)集的先驗(yàn)框維度;將用于訓(xùn)練的圖片進(jìn)行拼接實(shí)現(xiàn)了數(shù)據(jù)集的增強(qiáng);用CIOU代替回歸損失增加預(yù)測(cè)精度,基于YOLOv4的基礎(chǔ)網(wǎng)絡(luò)進(jìn)行特征提取,獲得不同尺度的特征層,將獲得的特征層經(jīng)過深層次特征金字塔進(jìn)行特征融合,再輸入分類回歸層進(jìn)行回歸預(yù)測(cè)。
關(guān)鍵詞:安全帽檢測(cè);數(shù)據(jù)增強(qiáng);特征金字塔
中圖分類號(hào):TP399文獻(xiàn)標(biāo)志碼:A
1 研究背景及意義
在建筑生產(chǎn)環(huán)境中,由于工作人員在進(jìn)行生產(chǎn)操作過程中沒有按照安全規(guī)定佩戴安全帽或者沒有正確佩戴安全帽而造成的安全事故越發(fā)多見,為了響應(yīng)國(guó)家對(duì)施工安全規(guī)范的提倡,越來越多的企業(yè)注重員工的安全行為規(guī)范,因此,需要一種技術(shù)來監(jiān)測(cè)作業(yè)工人在建筑生產(chǎn)環(huán)境中安全帽的佩戴情況,從而督促工人們佩戴好安全帽,減少安全事故的發(fā)生。
隨著卷積神經(jīng)網(wǎng)絡(luò)的提出和發(fā)展,可以用一些數(shù)學(xué)函數(shù)來描述計(jì)算機(jī)難以理解的問題,使得目標(biāo)檢測(cè)有了新的研究方向。通過設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)模型進(jìn)行訓(xùn)練后,自動(dòng)提出特征的方法使目標(biāo)檢測(cè)的研究方向轉(zhuǎn)到了深度學(xué)習(xí)。基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法發(fā)展得很迅速,從Faster RCNN[1]錨框的提出到SDD、YOLOv系列的提出,在不斷地提高目標(biāo)檢測(cè)的精度和計(jì)算速度。
關(guān)于如何保障作業(yè)人員在建筑生產(chǎn)環(huán)境中的安全問題,目前已經(jīng)有一些有關(guān)安全帽佩戴檢測(cè)的相關(guān)研究。在計(jì)算機(jī)視覺研究方面,馮國(guó)臣等[2]提出了應(yīng)用機(jī)器視覺的相關(guān)方法來實(shí)現(xiàn)安全帽的自動(dòng)識(shí)別任務(wù),通過在圖像預(yù)處理的基礎(chǔ)上利用混合高斯模型來做前景檢測(cè),然后運(yùn)用連通域的判斷來進(jìn)行人體頭部區(qū)域的定位[2]。楊莉瓊等[3]在機(jī)器學(xué)習(xí)的基礎(chǔ)上對(duì)安全帽佩戴檢測(cè)做了相關(guān)研究,利用深度學(xué)習(xí)算法檢測(cè)出現(xiàn)場(chǎng)視頻中的施工人員臉部位置,根據(jù)安全帽與人臉的關(guān)系估算出安全帽潛在區(qū)域再對(duì)區(qū)域圖像進(jìn)行增強(qiáng)處理,使用 H方向梯度直方圖提取樣本的特征向量,用支持向量機(jī)分類器對(duì)臉部上方是否有安全帽進(jìn)行判斷,實(shí)現(xiàn)對(duì)施工人員安全帽佩戴行為的實(shí)時(shí)檢測(cè)與預(yù)警。在建筑施工場(chǎng)地方面,劉云波等[4]提出一種基于計(jì)算機(jī)視覺的施工現(xiàn)場(chǎng)的安全帽監(jiān)控技術(shù),通過利用背景差法從圖像中提取出前景,運(yùn)用二值化的方法分割出檢測(cè)目標(biāo)進(jìn)行尺度濾波提高檢測(cè)的準(zhǔn)確性。
在YOLOv系列算法的改進(jìn)方面,王兵等[5]在YOLOv3的基礎(chǔ)上使用GIoU代替交并比IOU,在包含IOU對(duì)目標(biāo)物體的尺度不敏感的特點(diǎn)下,GIoU可優(yōu)化預(yù)測(cè)框與真實(shí)框的重疊區(qū)域,從而改進(jìn)了回歸的損失函數(shù),提高了判斷是否佩戴安全帽的檢測(cè)效果。林俊等[6]利用YOLO v3提出了安全帽檢測(cè)的方法,通過修改分類器使輸出的張量為18維度,再對(duì)基于YOLOv3的預(yù)訓(xùn)練模型進(jìn)行訓(xùn)練,根據(jù)損失函數(shù)和交并比的曲線對(duì)模型的參數(shù)進(jìn)行優(yōu)化得到最適合的安全帽檢測(cè)模型。施輝等[7]提出了基于改進(jìn)YOLO v3算法的安全帽佩戴檢測(cè)方法,通過采用圖像金字塔結(jié)構(gòu)獲取不同尺度的特征圖用于多尺度的位置和類別預(yù)測(cè),使用施工場(chǎng)地的監(jiān)控視頻作為數(shù)據(jù)集進(jìn)行目標(biāo)框維度聚類,在訓(xùn)練迭代過程中改變輸入圖像的尺寸從而增加模型對(duì)尺度的適應(yīng)性。
王明芬等[8]基于視頻圖像做了安全帽檢測(cè)、識(shí)別和跟蹤的相關(guān)研究,通過提取視頻里的幀序列進(jìn)行前景處理,然后在處理后的結(jié)果中檢測(cè)目標(biāo)、預(yù)測(cè)和跟蹤軌跡的新位置,再匹配檢測(cè)目標(biāo)并顯示目標(biāo)的跟蹤結(jié)果。鄧開發(fā)等[9]提出一種基于深度學(xué)習(xí)的安全帽佩戴檢測(cè)方法,使用Keras深度學(xué)習(xí)框架搭建Faster RCNN模型,通過卷積層和池化層提取圖像的信息形成特征圖,提高了檢測(cè)速度。劉曉慧等[10-12]對(duì)安全帽的識(shí)別算法進(jìn)行了研究,在定位識(shí)別人臉時(shí)創(chuàng)新性地引入了檢測(cè)膚色的方法來獲得臉部以上的區(qū)域圖像,將不變矩作為圖像的特征向量,再通過支持向量機(jī)(SVM)分類模型[13]判斷是否佩戴安全帽。
2 安全帽檢測(cè)算法
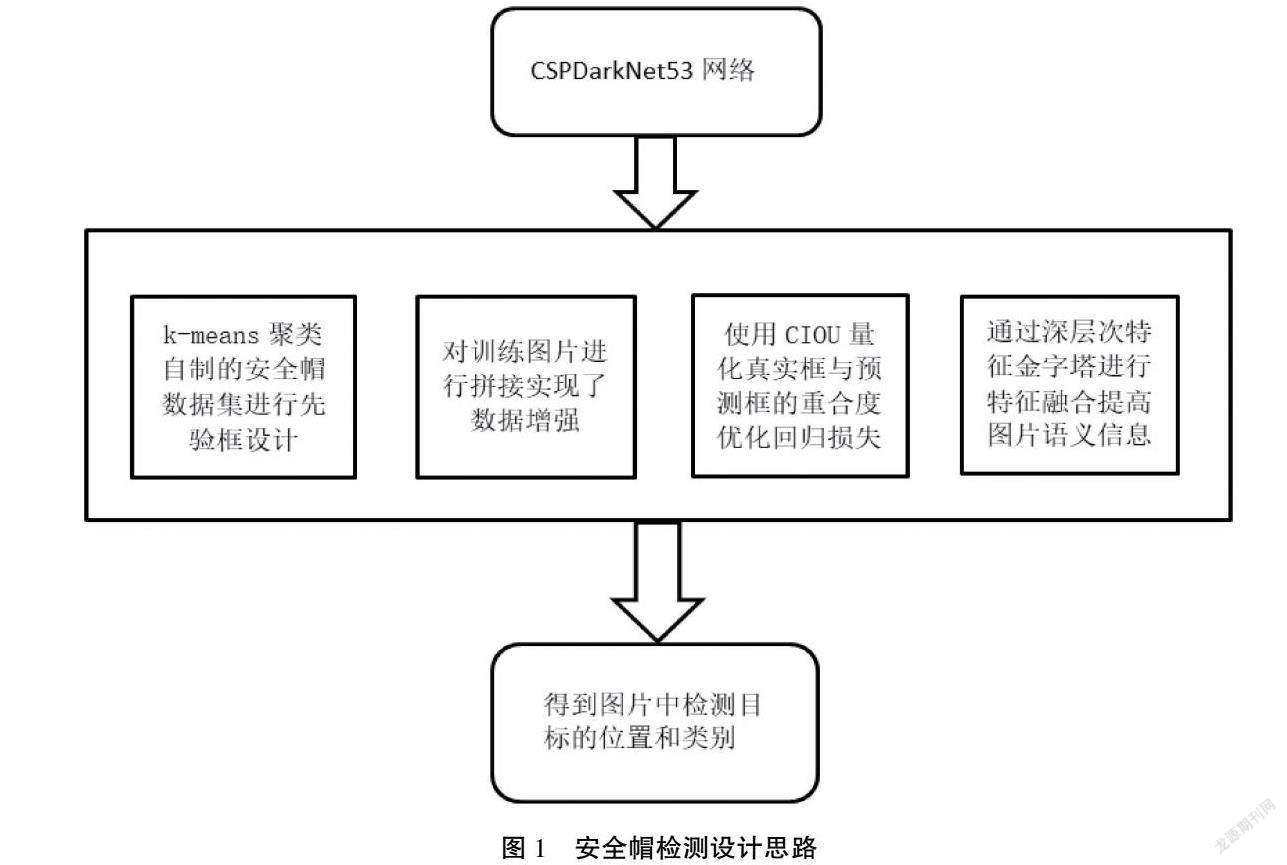
以提高建筑行業(yè)安全生產(chǎn)效率為目的,本文提出了一種基于機(jī)器人視覺的建筑工地安全帽目標(biāo)檢測(cè)算法用于檢測(cè)建筑工地人員安全帽佩戴情況,算法的設(shè)計(jì)思路如圖1所示。本文的目標(biāo)檢測(cè)算法采用k-means算法通過自制的安全帽數(shù)據(jù)集進(jìn)行先驗(yàn)框設(shè)計(jì)獲得新的先驗(yàn)框維度,將用于訓(xùn)練的圖片進(jìn)行拼接實(shí)現(xiàn)了數(shù)據(jù)集的增強(qiáng),使用CIOU量化真實(shí)框與預(yù)測(cè)框的重合度優(yōu)化回歸損失,從而增加預(yù)測(cè)精度,基于YOLOv4的基礎(chǔ)網(wǎng)絡(luò)進(jìn)行特征提取,獲得不同尺度的特征層,將獲得的特征層經(jīng)過深層次特征金字塔進(jìn)行特征融合,再輸入分類回歸層進(jìn)行回歸預(yù)測(cè)。
2.1 特征提取網(wǎng)絡(luò)
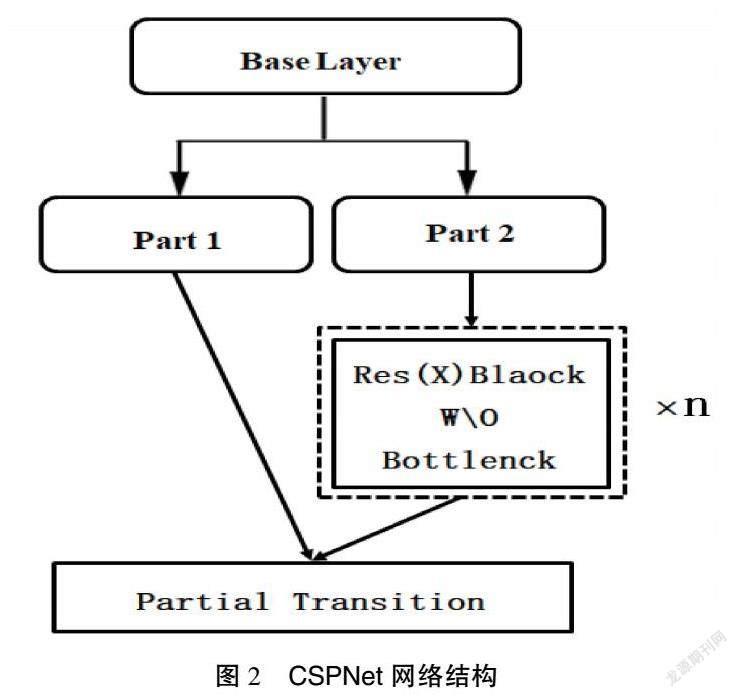
CSPDarkNet53作為YOLOv4的主干特征提取網(wǎng)絡(luò),是在DarkNet53的基礎(chǔ)上結(jié)合了CSPNet。CSPNet網(wǎng)絡(luò)主要用來增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力,其結(jié)構(gòu)如圖2所示。CSPNet將原來由殘差單元疊加的卷積網(wǎng)絡(luò)進(jìn)行了左右的拆分,第一部分會(huì)有一個(gè)大的殘差邊不經(jīng)過堆疊的殘差結(jié)構(gòu)直接連接到后面的輸出層,第二部分作為主干部分繼續(xù)進(jìn)行原來殘差塊的堆疊。
從圖2 CSPDarkNet53特征提取網(wǎng)絡(luò)結(jié)構(gòu)中可以看到,YOLOv4的輸入是一個(gè)416×416×3的圖片,當(dāng)然也可以對(duì)輸入圖片的大小進(jìn)行改變,例如改為608×608×3的圖片,但考慮到常用電腦顯存的問題,本論文選擇了輸入大小為416×416×3的圖片。
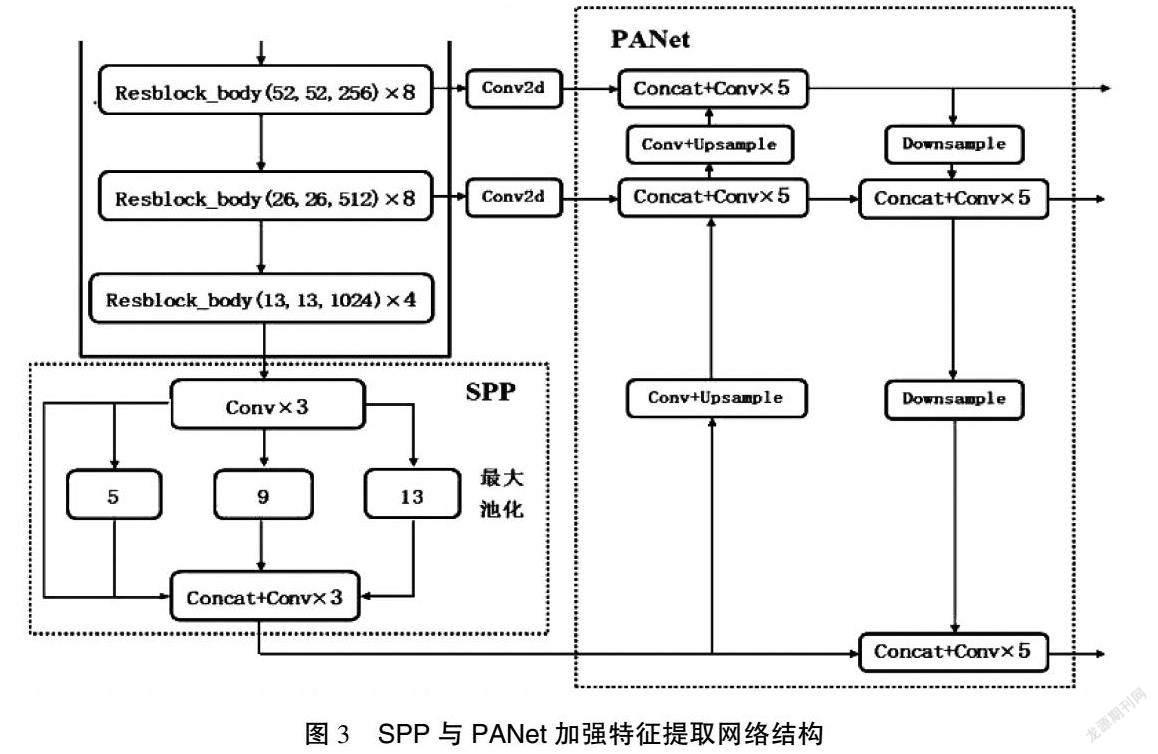
在主干特征提取網(wǎng)絡(luò)中,只使用了最后面3個(gè)的特征層進(jìn)行下一步的操作,因?yàn)檫@3個(gè)特征層的語義信息更為豐富一些。在獲得了最后3個(gè)特征層后,本研究將第五層的特征層,即13×13×1 024的有效特征層進(jìn)行3次卷積操作,再將卷積后的結(jié)果輸入SPP網(wǎng)絡(luò)結(jié)構(gòu)中。
SPP網(wǎng)絡(luò)結(jié)構(gòu)具有4個(gè)分支,事實(shí)上就是運(yùn)用不同池化核大小的最大池化對(duì)輸入進(jìn)來的特征層進(jìn)行池化處理從而增加網(wǎng)絡(luò)的感受野,然后將池化后的結(jié)果經(jīng)過堆疊和3次卷積操作輸入下一個(gè)環(huán)節(jié)即PANet網(wǎng)絡(luò)中。SPP與PANet加強(qiáng)特征提取網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。通過堆疊和3次卷積后的特征層在PANet網(wǎng)絡(luò)中通過上采樣,將輸入的特征層的高和寬變?yōu)樵瓉淼?倍,當(dāng)輸入的特征層尺寸為13×13,則經(jīng)過上采樣處理后的特征層尺寸為26×26,這樣就可以把上采樣得到的特征層與在主干特征提取網(wǎng)絡(luò)中獲取到的shape同樣為26×26×512的特征層進(jìn)行堆疊從而實(shí)現(xiàn)特征融合,完成堆疊后再進(jìn)行5次卷積,5次卷積的操作為1×1的卷積和3×3的卷積交替進(jìn)行來完成,這樣的結(jié)構(gòu)有助于提取圖片的特征并減少了參數(shù)量。同理再一次上采樣、堆疊、卷積,這樣就完成了一個(gè)特征金字塔的結(jié)構(gòu)并將主干特征提取網(wǎng)絡(luò)中的3個(gè)有效特征層都進(jìn)行了特征融合。
PANet網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)一步加深了特征提取,將特征融合后的結(jié)果進(jìn)行下采樣,使特征層的高和寬再一次被壓縮,從而與第一次上采樣得到的特征層進(jìn)行堆疊,堆疊后進(jìn)行5次卷積,卷積后的輸出一方面用于YOLO Head進(jìn)行結(jié)果預(yù)測(cè),另一方面繼續(xù)進(jìn)行下采樣再與池化后的特征層進(jìn)行特征融合。在PANet結(jié)構(gòu)中,進(jìn)行多次的特征融合得到了更加有效的特征。
2.2 YOLO Head網(wǎng)絡(luò)結(jié)構(gòu)
YOLO Head將提取到的特征進(jìn)行結(jié)果預(yù)測(cè),YOLO Head的結(jié)構(gòu)與YOLOv3的分類回歸層是一致的,在YOLOv4網(wǎng)絡(luò)結(jié)構(gòu)中一共存在3個(gè)YOLO Head,可以分為上層、中層和下層。每個(gè)YOLO Head的內(nèi)部是1個(gè)3×3的卷積和1個(gè)1×1的卷積,3×3的卷積是對(duì)前一層輸出結(jié)果的特征整合,1×1的卷積是利用3×3卷積后的特征獲得最終的輸出結(jié)果。YOLO head的網(wǎng)絡(luò)結(jié)構(gòu)如圖4所示。
本文使用的數(shù)據(jù)集是基于VOC數(shù)據(jù)集的格式。因此,YOLO Head的預(yù)測(cè)結(jié)果為(52×52×75)(26×26×75)(13×13×75),分別對(duì)應(yīng)著上層、中層和下層。以下層為例,下層的預(yù)測(cè)結(jié)果(13×13×75)基于下采樣與池化后的特征層進(jìn)行特征融合獲得特征圖預(yù)測(cè)。75可以分解成3×25,其中3表示網(wǎng)格點(diǎn)上的3個(gè)先驗(yàn)框,下層利用的特征層shape為13×13,即將輸入的圖片劃分為169個(gè)網(wǎng)格,每個(gè)網(wǎng)格會(huì)負(fù)責(zé)該區(qū)域物體的檢測(cè)。當(dāng)某個(gè)物體的中心落到該區(qū)域時(shí)就需要利用網(wǎng)格對(duì)物體進(jìn)行檢測(cè)。因此,YOLO Head輸出的預(yù)測(cè)結(jié)果是將先驗(yàn)框進(jìn)行調(diào)整后的最終預(yù)測(cè)框結(jié)果。因?yàn)槭褂玫氖荲OC數(shù)據(jù)集的格式,所以分為20個(gè)種類。25則包含著VOC數(shù)據(jù)集分的20個(gè)種類;4個(gè)用于調(diào)整先驗(yàn)框的參數(shù),通過4個(gè)調(diào)整參數(shù)對(duì)已經(jīng)設(shè)定好的先驗(yàn)框的中心和寬高進(jìn)行調(diào)整,調(diào)整后的結(jié)果即為預(yù)測(cè)框;最后剩下的1個(gè)1,用來判斷先驗(yàn)框內(nèi)部是否包含需要檢測(cè)的物體。當(dāng)數(shù)值越趨近于1,則表示先驗(yàn)框內(nèi)包含檢測(cè)物體;同理,當(dāng)數(shù)值越趨近于0,則表示先驗(yàn)框內(nèi)不包含檢測(cè)物體。
3 實(shí)驗(yàn)過程及即結(jié)果分析
3.1 實(shí)驗(yàn)數(shù)據(jù)集制作
實(shí)驗(yàn)數(shù)據(jù)集是目標(biāo)檢測(cè)任務(wù)的關(guān)鍵性部分,數(shù)據(jù)集的好壞直接影響著訓(xùn)練模型的預(yù)測(cè)效果,本文使用的數(shù)據(jù)集是基于VOC格式的自制數(shù)據(jù)集,利用企業(yè)提供的安全帽數(shù)據(jù)進(jìn)行數(shù)據(jù)集的制作,通過對(duì)圖片數(shù)據(jù)的篩選濾除了重復(fù)的或不符合檢測(cè)任務(wù)的圖片,用于本文的安全帽數(shù)據(jù)集總共包含8 270張,其中,用于模型訓(xùn)練的圖片為7 581張、用于模型測(cè)試的圖片為689張。用于模型訓(xùn)練的圖片需要對(duì)圖片進(jìn)行數(shù)據(jù)標(biāo)注,本文使用了專門的圖像標(biāo)記工具labellmg對(duì)安全帽數(shù)據(jù)集中的訓(xùn)練圖片進(jìn)行標(biāo)記,制作用于模型訓(xùn)練的訓(xùn)練數(shù)據(jù)集。
3.2 實(shí)驗(yàn)平臺(tái)
本實(shí)驗(yàn)所使用的軟硬件工具包括Python,CUDA,OpenCV,Keras,numpy以及服務(wù)器等工具,基于YOLOv4的安全帽檢測(cè)算法采用Pytorch框架。為了方便環(huán)境的搭建和管理,本文還使用了anaconda軟件工具包。本文實(shí)驗(yàn)環(huán)境的配置如表1所示。
3.3 實(shí)驗(yàn)方案
本文的實(shí)驗(yàn)把安全帽數(shù)據(jù)集分為兩類:一類是用于對(duì)改進(jìn)后的新網(wǎng)絡(luò)進(jìn)行訓(xùn)練的訓(xùn)練集。在訓(xùn)練的時(shí)候,網(wǎng)絡(luò)算法會(huì)在訓(xùn)練集的圖片中隨機(jī)選取圖片進(jìn)行訓(xùn)練,直至遍歷完所有的圖片;另一類是用于已經(jīng)訓(xùn)練成功的網(wǎng)絡(luò)模型進(jìn)行測(cè)試的測(cè)試集。
本實(shí)驗(yàn)的網(wǎng)絡(luò)訓(xùn)練初始參數(shù)參考了YOLOv4官網(wǎng)上提供的部分參數(shù),然后在預(yù)訓(xùn)練權(quán)重的基礎(chǔ)上進(jìn)行訓(xùn)練。將首次訓(xùn)練得到的權(quán)重參數(shù)作為下一次訓(xùn)練的權(quán)重,根據(jù)訓(xùn)練效果對(duì)網(wǎng)絡(luò)參數(shù)進(jìn)行調(diào)節(jié)再多次進(jìn)行訓(xùn)練,從而得到最優(yōu)網(wǎng)絡(luò)效果的權(quán)重參數(shù)。本文的特征提取網(wǎng)絡(luò)會(huì)有3種不同尺度的特征層。因此,本實(shí)驗(yàn)在安全帽圖片尺寸的選擇上并沒有采取相同尺寸的訓(xùn)練圖片,而是在網(wǎng)絡(luò)訓(xùn)練時(shí)隨機(jī)輸入不同尺寸的圖片。
3.4 實(shí)驗(yàn)結(jié)果分析
本實(shí)驗(yàn)通過使用最佳的權(quán)重參數(shù)進(jìn)行圖片預(yù)測(cè),從而檢測(cè)模型的訓(xùn)練效果。實(shí)驗(yàn)?zāi)P退惴ǖ臋z測(cè)效果如圖5所示。
從該圖片的檢測(cè)結(jié)果中可以看出,本研究把圖片中佩戴安全帽的作業(yè)人員的安全帽用描框框選出來并標(biāo)記為hat;同時(shí),把未佩戴安全帽的作業(yè)人員也框選出來并用紅色標(biāo)記為person。模型檢測(cè)精度的計(jì)算采用的是mAP,mAP常用于衡量目標(biāo)檢測(cè)的精確度。
在使用mAP計(jì)算精度前,需要了解TP,TN,F(xiàn)P和FN的概念。mAP的計(jì)算過程會(huì)涉及檢測(cè)樣本是否有被正確地分類以及被分成了正樣本還是負(fù)樣本,因此采用TP,TN,F(xiàn)P和FN來代替4種分類,即正確的被分為了正樣本;正確的被分為了負(fù)樣本;錯(cuò)誤的被分為了正樣本,實(shí)際上為負(fù)樣本;錯(cuò)誤的被分為了負(fù)樣本,實(shí)際上為正樣本。
在計(jì)算mAP中,需要使用精確度和召回率這兩個(gè)指標(biāo),精確度的概念表示的是分類器正確分類正樣本的部分占所有被分類器認(rèn)為是正樣本的比例(包含被錯(cuò)誤分為了正樣本的部分),用來衡量分類器預(yù)測(cè)結(jié)果的準(zhǔn)確度,其表達(dá)見公式(1):
召回率的概念表示的是分類器正確分類正樣本的部分占所有實(shí)際上是正樣本的比例(包含被錯(cuò)誤分為了負(fù)樣本的部分),用來衡量分類器是否把比較多的正樣本檢測(cè)了出來,其表達(dá)見公式(2):
在計(jì)算mAP中,要使用兩個(gè)指標(biāo),是因?yàn)樵谀繕?biāo)檢測(cè)算法中,會(huì)人為地對(duì)置信度的值進(jìn)行設(shè)定。只有當(dāng)預(yù)測(cè)結(jié)果的置信度大于所設(shè)定的值時(shí),檢測(cè)網(wǎng)絡(luò)才會(huì)認(rèn)為圖片中包含檢測(cè)的目標(biāo)。如果置信度的值設(shè)置得比較合適,分類器預(yù)測(cè)的結(jié)果就會(huì)越符合實(shí)際情況,即更多的正樣本被正確地檢測(cè)了出來。如果設(shè)置得太高就會(huì)使一部分實(shí)際的正樣本被分為負(fù)樣本,此時(shí)在計(jì)算精確度時(shí)其值為等于1,召回率的值就會(huì)很低。因此,如果只用精確度來衡量預(yù)測(cè)效果的話,雖然精確度很高,但是仍有明顯的目標(biāo)沒有被檢測(cè)出來;同理,如果只用召回率來衡量預(yù)測(cè)效果的話,當(dāng)置信度設(shè)置得越低,計(jì)算召回率的值就會(huì)越高而精確度卻較低,那么就會(huì)存在較多的誤檢測(cè),即被錯(cuò)誤地分類為正樣本的數(shù)量會(huì)增多,檢測(cè)效果不好。不同置信度的值會(huì)影響精確度和召回率的大小,最終在計(jì)算mAP時(shí)要同時(shí)考慮精確度和召回率,只有將兩者進(jìn)行結(jié)合才能正確評(píng)價(jià)目標(biāo)檢測(cè)算法的優(yōu)劣。在取不同的置信度時(shí)會(huì)得到不同的精確度和召回率值,利用不同的精確度[0,1]與召回率[0,1]的點(diǎn)的組合所得到的曲線圍成面積的值為這一類的AP值,而mAP就是這一類AP值的平均值。
在運(yùn)行mAP的計(jì)算程序前需要準(zhǔn)備兩個(gè)文件夾,分別為detection_result,ground_truth。detection_result用于存放檢測(cè)結(jié)果的txt文件,文件里包含物體的種類、物體的置信度以及物體位置的預(yù)測(cè)結(jié)果;ground_truth用于存放真實(shí)框的內(nèi)容。文件里包含物體的種類以及檢測(cè)物體真實(shí)存在的位置。運(yùn)行相應(yīng)的程序即可得到對(duì)應(yīng)文件夾中的內(nèi)容。部分操作及運(yùn)算結(jié)果如圖6、圖7所示。
當(dāng)生成計(jì)算mAP所需要的文件后,便可以運(yùn)行程序得到mAP的計(jì)算結(jié)果,mAP計(jì)算的值如圖8所示。從mAP的計(jì)算結(jié)果圖中可以得到,檢測(cè)安全帽的召回率為93%,檢測(cè)精度為95.61%;檢測(cè)未佩戴安全帽的作業(yè)人員的召回率為81.57%,檢測(cè)精度為84.63%,整體上mAP的計(jì)算結(jié)果為89.08%。以mAP作為本文算法檢測(cè)效果的評(píng)價(jià)指標(biāo),滿足了本設(shè)計(jì)的檢測(cè)要求。
4 結(jié)語
本文基于YOLOv4的深度學(xué)習(xí)算法,首次在建筑工地領(lǐng)域?qū)崿F(xiàn)了安全帽的智能檢測(cè)。實(shí)驗(yàn)采用k-means算法通過安全帽數(shù)據(jù)集進(jìn)行先驗(yàn)框設(shè)計(jì)獲得新的先驗(yàn)框維度,將用于訓(xùn)練的圖片進(jìn)行拼接實(shí)現(xiàn)了數(shù)據(jù)集的增強(qiáng),使用CIOU量化真實(shí)框與預(yù)測(cè)框的重合度優(yōu)化回歸損失從而增加預(yù)測(cè)精度,基于YOLOv4的基礎(chǔ)網(wǎng)絡(luò)進(jìn)行特征提取,獲得不同尺度的特征層,將獲得的特征層經(jīng)過深層次特征金字塔進(jìn)行特征融合,再輸入分類回歸層進(jìn)行回歸預(yù)測(cè)。本文的安全帽算法在檢測(cè)精度和速度上都滿足設(shè)計(jì)的要求。
參考文獻(xiàn)
[1]GIRSHICK R.Fast R-CNN:Proceedings of the IEEE international conference on computer vision[C].Santiago:2015 IEEE International Conference on Computer Vision (ICCV),2015.
[2]馮國(guó)臣,陳艷艷,陳寧,等.基于機(jī)器視覺的安全帽自動(dòng)識(shí)別技術(shù)研究[J].機(jī)械設(shè)計(jì)與制造工程,2015(10):39-42.
[3]楊莉瓊,蔡利強(qiáng),古松.基于機(jī)器學(xué)習(xí)方法的安全帽佩戴行為檢測(cè)[J].中國(guó)安全生產(chǎn)科學(xué)技術(shù),2019(10):152-157.
[4]劉云波,黃華.施工現(xiàn)場(chǎng)安全帽佩戴情況監(jiān)控技術(shù)研究[J].電子科技,2015(4):69-72.
[5]王兵,李文璟,唐歡.改進(jìn)YOLOv3算法及其在安全帽檢測(cè)中的應(yīng)用[J].計(jì)算機(jī)工程與應(yīng)用,2020(9):33-40.
[6]林俊,黨偉超,潘理虎,等.基于YOLO的安全帽檢測(cè)方法[J].計(jì)算機(jī)系統(tǒng)應(yīng)用,2019(9):174-179.
[7]施輝,陳先橋,楊英.改進(jìn)YOLOv3的安全帽佩戴檢測(cè)方法[J].計(jì)算機(jī)工程與應(yīng)用,2019(11):213-220.
[8]王明芬.基于視頻的安全帽檢測(cè)和跟蹤算法研究[J].信息通信,2020(1):40-42.
[9]鄧開發(fā),鄒振宇.基于深度學(xué)習(xí)的安全帽佩戴檢測(cè)實(shí)現(xiàn)與分析[J].計(jì)算機(jī)時(shí)代,2020(7):12-15.
[10]劉曉慧,葉西寧.膚色檢測(cè)和Hu矩在安全帽識(shí)別中的應(yīng)用[J].華東理工大學(xué)學(xué)報(bào)(自然科學(xué)版),2014(3):365-370.
[11]姬壯偉.基于pytorch的神經(jīng)網(wǎng)絡(luò)優(yōu)化算法研究[J].山西大同大學(xué)學(xué)報(bào)(自然科學(xué)版),2020(6):51-53,58.
[12]BOCHKOVSKIY A,WANG C Y,LIAO H Y M. YOLOv4:Optimal Speed and Accuracy of Object Detection[EB/OL].(2020-04-23)[2023-03-06].https://doi.org/10.48550/arXiv.2004.10934.
[13]WANG C Y,MARK LIAO H Y,WU Y H,et al.CSPNet:A new backbone that can enhance learning capability of cnn[C].Seattle:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops,2020.
(編輯 王永超)

- 無線互聯(lián)科技的其它文章
- 數(shù)據(jù)加密技術(shù)在計(jì)算機(jī)網(wǎng)絡(luò)安全中的應(yīng)用
- 計(jì)算機(jī)網(wǎng)絡(luò)安全技術(shù)在維護(hù)網(wǎng)絡(luò)安全中的應(yīng)用
- 私有云在數(shù)據(jù)中心網(wǎng)絡(luò)安全中的應(yīng)用
- 基于微能源網(wǎng)的物聯(lián)網(wǎng)管理平臺(tái)設(shè)計(jì)
- 基于VMware vSphere 80的云平臺(tái)分析與實(shí)現(xiàn)
- 基于Web技術(shù)的校園體育用品租借App設(shè)計(jì)