AI大模型混戰(zhàn),中國云服務準備好了嗎?
2023-05-30 10:48:04Cloud
電腦報 2023年18期
Cloud
成本激增,算力搶灘難度頗高
隨著ChatGPT引爆的人工智能大模型混戰(zhàn)開打,算力之爭也成為了各大頭部企業(yè)爭奪下一個“時代風口”的紅海。所謂的人工智能大模型,也就是“大算力+強算法”結合的產物,通常是在大規(guī)模無標注數據上進行訓練,學習出一種特征和規(guī)則,當需要具體的應用方向時,再將大模型進行微調,比如在特定任務上,進一步采用小規(guī)模有標注數據進行二次訓練,當然,也可以不進行微調就直接參與多個應用場景。
在這個過程中不難發(fā)現,算力是打造大模型生態(tài)的必備基礎,一個優(yōu)秀的算力底座在大模型的訓練和推理上具備效率優(yōu)勢,而平臺是大模型和算力之間的“橋梁”,可針對不同的模型和硬件實現資源的合理分配,達到軟硬件的最優(yōu)組合,從而大幅提升訓練模型的效率。根據IDC的數據顯示,國家計算力指數與GDP/數字經濟的走勢呈現出了顯著的正相關,十五個重點國家的計算力指數平均每提高1點,國家的數字經濟和GDP將分別增長3.5‰和1.8‰,預計該趨勢在2021-2025年將繼續(xù)保持,所以,算力優(yōu)勢對經濟的拉動作用將變得更加顯著。
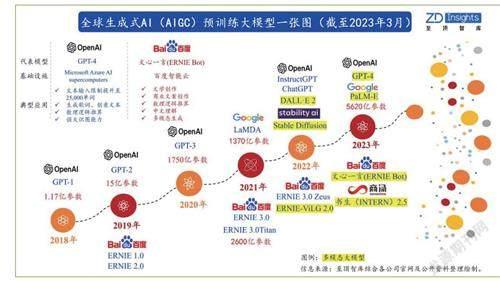
更重要的是,隨著半導體短溝道效應以及量子隧穿效應帶來的漏電、發(fā)熱等問題愈發(fā)嚴重,摩爾定律已日趨放緩接近失效,人工智能訓練算力需求增長與摩爾定律出現了嚴重的不匹配現象,這也將推動對算力基礎設施需求的快速提升,而龐大的數據量以及算力決定了人工智能產業(yè)一定是典型的重資金產業(yè):以GPT-3模型消耗的算力3640pfs-day為例,若按照單個500petaflops算力中心項目總投資約30億元來計算,若想要保證ChatGPT的正常運行,則至少需要投入7~8個數據中心,所產生的總成本超過200億元。為此,著名經濟學家任澤平也提出了2023年云計算行業(yè)將重新洗牌的觀點。
中國“四朵云”,AI時代反應各不相同
在我國云計算市場,就是阿里云、華為云、騰訊云和百度智能云這“四朵云”占據了80%的市場份額,考慮到人工智能對云計算算力的強需求性,它們也順理成章地成為了大家心目中國產人工智能的舉旗者。
但事實上,這四大云服務商在內容方向上并不一致,阿里云主要是物聯網和“云釘一體”;華為云則從政務云和私有云的角度起步;騰訊云則以直播為主打,提供SaaS服務;而百度智能云走的是“云+AI”戰(zhàn)略路線,主要在助力傳統產業(yè)智能化轉型方面發(fā)力。但它們的共同點就是主要的用戶還停留在政商領域,而當ChatGPT顯露了一把身手之后,相當一部分的中小企業(yè)或者是傳統企業(yè),甚至是個人用戶,也將會參與到云計算市場中來。

目前來看,阿里云是當前國內唯一實現盈利的云服務商,但它同樣面對很多的問題,比如目前雖然在國內IaaS領域市場份額第一,但IaaS領域存在產品高度同質化的問題,毛利率也只有10%-15%,遠低于SaaS行業(yè)內50%以上的毛利率,再加上消費市場復蘇不及預期、出口業(yè)下滑等因素,阿里云本身也并不輕松,所以拓展新領域就成了重中之重,這時候ChatGPT的出現就順理成章地為阿里云指出了方向,在AIGC領域先是拿出了通義千問,后又低調地推出了文字生成視頻的大模型,發(fā)展速度和效率都有目共睹。
百度智能云雖然是“四朵云”里份額最小的,但是通過飛槳平臺輸出了文心大模型,在對話型人工智能、文生圖等領域已經開始有所建樹,雖然現在的功能水平還飽受詬病,但百度的前景在現有的人工智能發(fā)展線路下反倒是比較有優(yōu)勢的,以對話型人工智能為例,百度智能云在芯片、框架、模型、應用四層技術的布局上都有和ChatGPT開發(fā)流程十分貼近的規(guī)模。
而華為云則是在4月25日剛剛發(fā)布了全新的盤古大模型,雖然也涉及了自然語言處理,但初衷還是聚焦機器視覺,我們也采訪了華為的相關人士,他表示華為內部的基本判斷是短期內很難推出一個可以對標GPT的產品,國內云服務廠商真正應該做的是商業(yè)化閉環(huán)內有個核心,也就是服務單一場景為主,這樣成功率會比較高。
因為混元大模型可能要在今年9月才會發(fā)布,所以目前騰訊云的思路還是更傾向于上游,在4月中旬發(fā)布了國內性能最強的大模型計算集群,采用最新一代騰訊云星星海自研服務器,國內首發(fā)搭載了英偉達最新的H800GPU,覆蓋人工智能訓練/推理、渲染、科學計算三大方向,換個角度來說也可以理解為騰訊在大模型上是相對滯后的,但這種“兵馬未動糧草先行”的思路確實也有后發(fā)優(yōu)勢,畢竟云計算的“下半場”剛剛開始,鹿死誰手還不得而知……
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
Defence Technology(2020年4期)2020-07-02 03:16:58
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
青年與社會(2018年2期)2018-01-25 15:37:06
小康(2017年16期)2017-06-07 09:00:59
光學精密工程(2016年6期)2016-11-07 09:07:19
南風窗(2016年19期)2016-09-21 16:51:29
