基于時間序列神經網絡預測模型的職工出勤記錄數據校正方法
2023-06-02 23:52:01魏葳耿一婷呂倩楊顯軍
計算機應用文摘 2023年10期
魏葳 耿一婷 呂倩 楊顯軍
關鍵詞:神經網絡;出勤記錄;數據校正
1引言
可靠且準確的職工出勤數據可以為企業的決策和調度工作提供重要信息,但由于企業內職工的出勤記錄數量較大,出勤記錄會不可避免地出現誤差,因此需要對職工的出勤記錄進行核對和校正[1]。本文基于時間序列神經網絡預測模型,設計職工出勤記錄數據校正方法,為企業內的出勤數據修正提供理論支持。
2顯著誤差檢測原理約束出勤記錄數據未知變量
在變量不可測的基礎上對誤差變量進行估計,剔除出冗余性變量。在顯著誤差的檢測原理下給定統計函數,計算式為:
3基于時間序列神經網絡預測模型獲取校正最優解
按照時間序列神經網絡預測模型對職工的出勤記錄數據進行誤差誤測,在反向推導中獲取校正最優解。其中最優解的計算精準度與預測誤差有關,因此需要保證預測誤差在最小范圍內,即:
4全覆蓋視域流程下實現職工出勤記錄數據校正
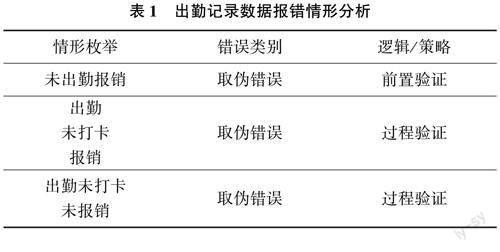
在時間序列神經網絡預測模型的相關性分析下,對出勤數據進行核對和校正。分析校驗報錯形式如表1所列。
根據表1所列,在工作現場需要對出勤進行記錄,按照前置確認和過程驗證2種形式,對工作人員的出勤情況進行分析。基于對現場工作中出現的錯誤類型的分析,將上文中獲取的預測模型最優解代人校正過程中,以全覆蓋的形式設計校正流程,對錯誤情況或是符合條件的內容進行覆蓋。
在進行職工出勤記錄校正時需要對基礎表格進行獲取,并對照職工在不同時段內的出勤記錄和相關文件,將數據導人至模型內。按照邏輯和策略在校驗過程分類出2個路徑,即報錯和通過,當出現報錯后轉入校正環節,沒有出現錯誤的直接歸納到新的文檔中,在校正完畢后進行基礎表格輸出。至此,基于時間序列神經網絡模型實現校正方法設計。
5實驗測試分析
實驗測試中選擇動態數據校正方法和多層次數據校正方法作為對照組,分別與本文方法進行對比,以驗證不同校正方法的有效性。
5.1準備職工出勤記錄數據
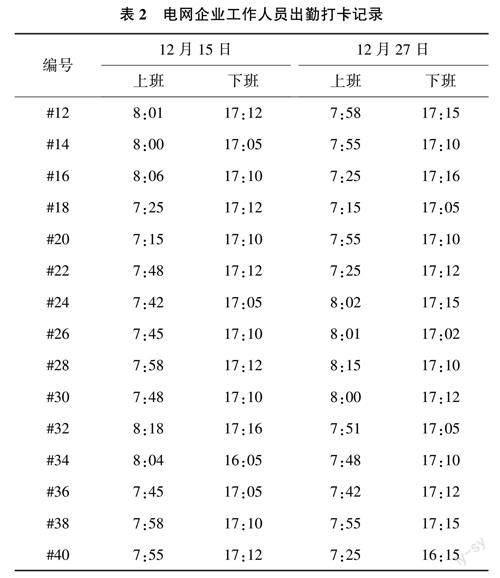
以某電網企業作為測試對象,對其工作人員的現場工作活動進行數據調取,以保證出勤記錄數據的真實性。隨機選擇15名工作人員的打卡時間,并將其作為數據來源。該企業的正常上班時間為8:00,下班時間為17:00,超過5min為遲到,提前打卡為早退。調取2022年12月無遲到和早退人員的數據記錄如表2所列。
根據表2所列,在隨機選擇的工作人員中出現了出勤打卡記錄錯誤的情況,具體情況如下。
(1)12月15日:編號為#16和#32工作人員在上班打卡日寸出現記錄異常,表現為遲到狀態;而編號#34的工作人員在下班打卡時出現異常,表現為早退狀態。
(2)12月27日:編號為#28的工作人員表現為遲到狀態;編號為#40工作人員表現為早退狀態。
基于上述情況,需要對工作人員的打卡記錄進行校正,使其在工資記賬前修正為正確形式,不影響工作人員的全勤保障。
5.2出勤數據校正準確性比較及分析
將上述出現問題的數據上傳至測試平臺中,分別連接3組校正方法,以驗證不同方法校正的準確性。調取視頻監控整理上述人員的實際打卡時間,具體情況如下。
(1)12月15日:編號#32工作人員上班打卡時間分別為7:58;編號#34工作人員下班打卡時間為17:05。
(2)12月27日:編號#28工作人員上班打卡時間分別為7:55;編號#40工作人員下班打卡時間分別為17:15。
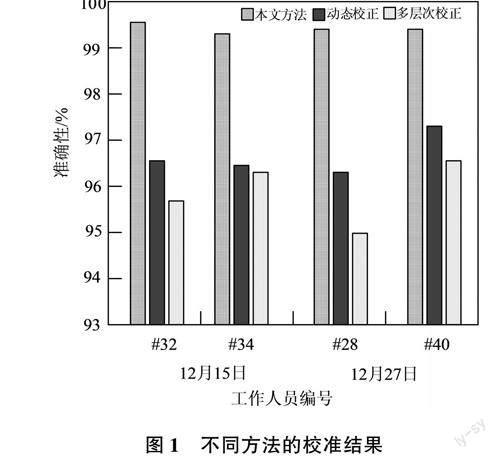
以視頻調取數據作為校正對照,分別驗證不同方法的校正準確性,具體如圖1所示。
根據圖1測試結果可知,本文方法的打卡記錄校正結果準確性高于99%,而2組方法在不同日期內的校準結果與實際數據存在較大誤差,綜合結果可知本文方法更有效。
5.3出勤數據校正效率對比及分析
上文驗證了新方法的校正準確性,為進一步驗證新方法的有效性,對多組職工出勤數據進行校正效率測試。仍將上班打卡和下班打卡的數據記錄作為測試對象,調取該企業2022年內所有錯誤數據,測試結果如表3所列。
根據表3所列,在不同月份中產生的錯誤出勤記錄有所不同,在本文方法應用下能夠在20s內完成校正,而動態數據校正方法和多層次數據校正方法所需的時間明顯比本文方法更多,說明本文方法的數據校正效率更高。
6結束語
本文通過時間序列預測模型的應用并結合實驗驗證了新方法的有效性,其能夠對職工的出勤記錄進行有效校正。但由于時間有限,在研究中只選擇了較少的數據完成測試,具有一定的不足,后續研究中會增加校正的數據類型,為企業員工的出勤記錄數據校正提供理論支持。
