基于Jensen模型與SSA-BP模型的寬壟溝灌冬小麥水氮生產函數研究
2023-06-04 23:20:10汪順生楊成宇黃一丹柳騰飛楊金月張昊
江蘇農業科學 2023年9期
汪順生 楊成宇 黃一丹 柳騰飛 楊金月 張昊

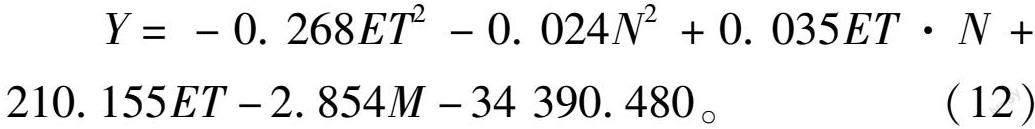



摘要:為了明確寬壟溝灌下不同水氮處理冬小麥的產量、耗水特性和水氮生產函數,本研究設計灌水下限為田間持水率的60%(W1)、70%(W2)和80%(W3)3種灌溉處理,120 kg/hm2(N1)、220 kg/hm2(N2)和320 kg/hm2(N3)3種施氮處理,共9組試驗處理,運用耗水量-施氮量-產量構建水氮生產函數的Jensen模型與SSA-BP模型。結果表明,寬壟溝灌下冬小麥產量在N2W2處理最大,為8 121.75 kg/hm2;耗水量在N3W3處理最大,為444.61 mm;水分利用效率在N2W2處理最大,為2.07 kg/m3;氮肥偏生產力在N1W2處理最大,為64.03 kg/kg;Jensen模型下的水分敏感指數累積曲線表明,在整個生育階段拔節-抽穗期的水分敏感指數最大;針對BP神經網絡收斂速度慢等問題,引入麻雀搜索算法進行優化,構建SSA-BP模型下的水氮生產函數,通過多次訓練對比發現,SSA-BP 模型比原始BP模型迭代次數更少,誤差更小;對水氮生產函數進行產量的模擬值與實測值對比,發現Jensen模型、SSA-BP模型和BP模型均能得到線性擬合接近y=x的實測產量與預測產量,且SSA-BP模型效果更好;綜合考慮冬小麥產量及水氮利用,寬壟溝灌下冬小麥可以選擇70%田間持水率的灌水下限和235.98 kg/hm2的水氮方案,結果可為寬壟溝灌冬小麥水氮施用制度提供參考依據。
關鍵詞:冬小麥;寬壟溝灌;水氮生產函數;Jensen模型;SSA-BP模型
中圖分類號:S275.3;S512.1+10.6;S512.1+10.7??文獻標志碼:A??文章編號:1002-1302(2023)09-0207-08
基金項目號:國家自然科學基金(編號:52079051);河南省高等學校重點科研項目(編號:22A570004)。
作者簡介:汪順生(1978—),男,安徽懷寧人,博士,教授,主要從事農業水土與環境研究。E-mail:wangshunsheng@ncwu.edu.cn。
通信作者:張?昊,博士,講師,主要從事節水灌溉原理及理論研究。E-mail:zhanghao@ncwu.edu.cn。
水是一個國家發展的生命之源,不管是生存還是發展都需要足夠的水資源作為支撐[1]。華北地區平原面積廣闊,土地資源相對較好,灌溉水利用效率在2017年達到0.514,已經屬于全國領先范疇,但與發達國家水平相比仍有很大的差距[2-3]。水資源匱乏和灌溉水利用效率不高仍是阻礙我國農業發展的重要因素[4]。化肥的使用對糧食產量影響顯著[5],然而化肥支出的邊際產值小于1,化肥過量施用程度十分嚴重[6-7]。因此,科學合理地制定灌水施肥制度是避免水氮資源浪費和生態污染的關鍵。
為了確定作物最優灌溉制度和進行灌溉經濟分析,國內外專家對于水分生產函數進行了大量研究[8-10],結果表明,將試驗實測數據與數值模型相結合是當前主要研究方向,且不同地區不同作物不同灌溉方式下的水分生產函數差異較大。Mukherjee使水分生產函數與有效土水相互作用相結合,發現比單獨使用產量響應函數的單方程模型更促進虧缺灌溉的優勢[11]。王仰仁等在水分敏感指數累積函數中加入與時段數有關的優化參數,以此降低了時段劃分過少對作物產量模擬精度的不利影響[12]。Pushpalatha等利用CROPWAT軟件對灌溉制度和需水量進行了模擬,發現不論農業氣象條件如何,CROPWAT軟件在計算木薯需水量和制定灌溉時間表方面具有廣泛的適用性[13]。然而除農業氣象外,還有生理、生態和管理措施等難以衡量的因素影響作物生長模擬模型的建立[14],因而機制模型仍是水分生產函數的根本出路[10]。并且水、氮作為我國農業的主要投入,在生產函數中不能僅考慮水的作用而忽視氮的作用。Singh等進行田間試驗,運用水肥生產力評價灌溉制度對芥菜產量的影響,結果準確卻不利于結論移植[15]。周智偉等引入肥料因子構造了Jensen模型和BP模型下的水肥生產函數,卻忽視了灌溉方式對其的影響[16]。王龍強等運用經過粒子群算法優化(PSO)的支持向量機(SVM)建立產量與灌水和施肥的關系,表明PSO-SVM模型有更好的精度,但缺點是無法得到具體的函數參數[17]。
寬壟溝灌具有增加土壤透氣性、減少灌溉用水量等優點,前人對寬壟溝灌下的土壤水分運動和氮素運移的研究較為全面,但關于該種灌溉方式下的水氮生產函數構建鮮有研究。本試驗在研究不同水氮處理下寬壟溝灌冬小麥產量變化的基礎上,運用Jensen模型和SSA-BP模型對冬小麥水氮生產函數進行模擬,確定寬壟溝灌下的水分敏感指數累積曲線,為華北地區寬壟溝灌下冬小麥的田間水氮優化管理提供科學依據。
1?試驗與方法
1.1?試驗區概況及試驗材料
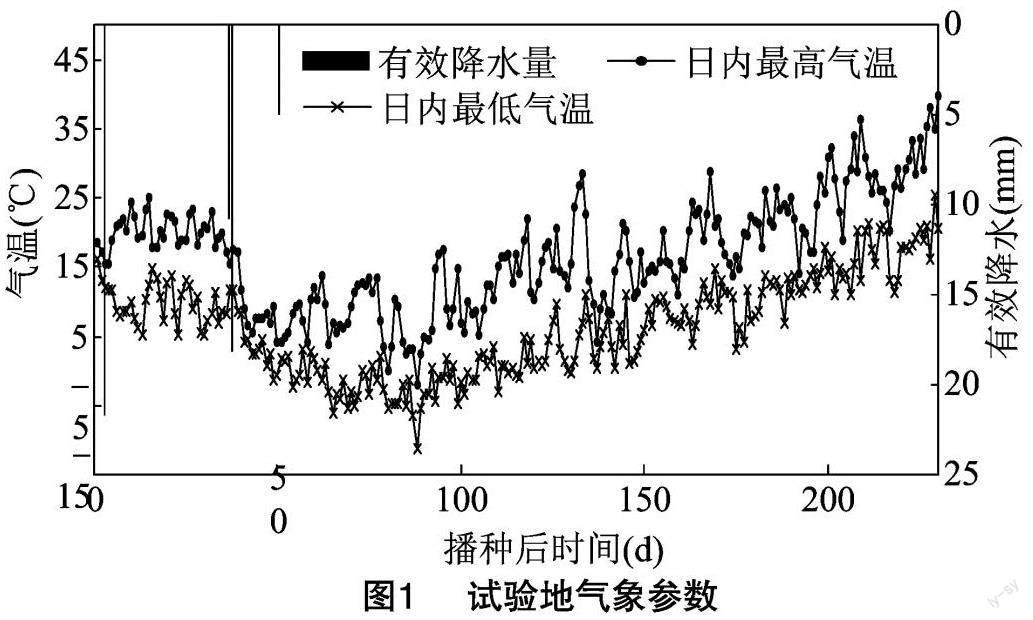
試驗于2020年在鄭州市華北水利水電大學河南省節水農業重點實驗室展開,地理位置為113°48′E,34°50′N,試驗地為粉沙質壤土,土壤0~100 cm土層內平均容重為1.35 g/cm3,田間持水率為34%,土壤有機質質量分數為870 mg/kg,全氮質量分數為 539 mg/kg,堿解氮質量分數為55 mg/kg。試驗地氣象參數見圖1(以下所有含水率均為體積含水率,田間持水率簡記為FC,有效降水量不計單次 5 mm 以下的降水)。
1.2?試驗設計
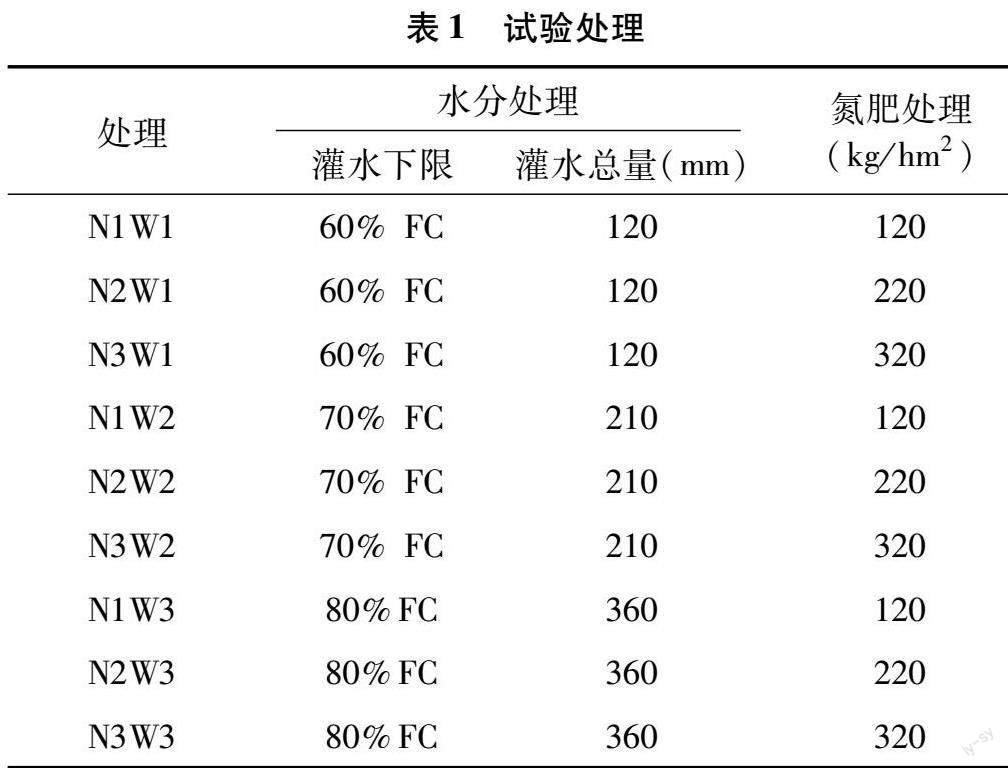
試驗設計3種水分處理和3種施氮處理,每個重復3次。溝深和溝底寬均為0.2 m、溝面寬 0.4 m、壟面寬0.7 m、溝長10 m。壟上種植5行小麥,行間距為0.15 m,與溝的間距為0.05 m;水分控制下限為60%FC、70%FC、80%FC;施氮處理為120、220、320 kg/hm2。各處理見表1。
1.3?測定項目與方法
1.3.1?產量測定?作物成熟后,寬壟溝灌每個試驗組收獲1.0 m×0.7 m面積的植株樣品測定產量。
1.3.2?土壤水分測定?在作物生育期內,用Trime-PICO-IPH每7 d測定1次土壤含水率。在作物種植前、收獲后以及關鍵生育期內通過烘干法測定 0~100 cm深度內土壤含水率,每20 cm為1層,對Trime-PICO-IPH測量的土壤含水率進行率定。
1.3.3?作物階段耗水量?由于試驗所在地地下水埋深遠大于2.5 m,且采用節水灌溉,故地下水補給量和深層滲漏可忽略不計,作物階段耗水量可簡化為下式:
式中:ET1~2為階段1至階段2作物的耗水量,mm,試驗階段為1~7,對應生育期為播種—越冬—返青—拔節—抽穗—灌漿—成熟,即6個生育期;i為土層編號,試驗共5個土層;r為平均土壤容重,r=1.35 g/cm3;Hi為第i層土層厚度,試驗均為20 cm/層,共100 cm;M為時段內灌溉水量,mm;P為時段內有效降水量,試驗期間有效降水量共為139.9 mm。
1.3.4?冬小麥水氮利用效率?利用水分利用效率(WUE,kg/m3)和氮肥偏生產力(PFPN,kg/kg)綜合評價冬小麥的水氮處理:
式中:Y為產量,kg/hm2;ET為全生育期內作物耗水量,mm;N為全生育期內氮肥施用量,kg/hm2。
1.4?模型構建
1.4.1?水氮生產函數Jensen模型?根據周智偉等對水肥生產函數的研究,將氮素效益函數與Jensen模型相結合,構造不同灌溉方式下冬小麥的水氮生產函數[16]。其表達式如下:
式中:λi為第i階段作物缺水敏感指數;ETi為第i階段作物耗水量,mm;ETim為充分供水條件下第i階段最大耗水量,mm;Ya為作物實際產量,kg/hm2;Ym為作物潛在產量,kg/hm2;Ym(F)為產量與氮肥的函數。
對式(4)兩邊取對數,則
運用水分敏感指數累積曲線消除離散的水分敏感指數帶來的誤差:
式中:t為播種后的時間。
1.4.2?水氮生產函數SSA-BP模型?函數逼近是BP神經網絡的一個重要功能,已被廣泛應用于電力工業、電信技術、公路與水路運輸等多個領域,周智偉等第1次將其運用到產量估計上[16],但隨著BP神經網絡模型的廣為應用,其數據搜索能力差、收斂速度慢、易陷入局部極小值等問題日益突出[18-19]。本試驗采用搜索能力強、收斂速度快、能避免最優解出現極值的麻雀搜索法(sparrow search algorithm,簡稱SSA)[20]對神經網絡進行優化,模型建立步驟如下:
第1步:建立優化前的神經網絡。設置輸入節點、中間節點和輸出節點,對樣本進行歸一化處理。
式中:x為原始樣本數據,y為歸一化后的樣本數據,xmax、xmin分別為樣本中的最大值、最小值。
第2步:麻雀參數設置。設置麻雀種群數量、迭代次數,初始化捕食者和加入者比例。
第3步:麻雀位置初始化。麻雀種群為由發現者和追隨者組成,選取適應度較好麻雀作為發現者,位置更新描述如下:
式中:Xij表示第i個麻雀在第j維中的位置信息;t代表當前迭代數;α∈(0,1],為隨機數;itermax為最大迭代次數;Q為服從標準正太分布的隨機數;R2∈[0,1],為隨機數;ST為警戒閾值;L為1×d的全1矩陣。
剩余麻雀為跟隨者,位置描述如下:
式中:Xtworst表示t代全局最差位置;Xt+1p表示t+1代發現者最優位置;A為1×d且元素隨機賦值為1或-1的矩陣,A+=AT(AAT)-1。
意識到危險的麻雀為警戒者,占麻雀種群20%左右,其數學表達式為
式中:Xtbest表示t代全局最優位置;K∈[-1,1]的隨機數;fi為i個個體的適應度值;fg和fw分別是當前全局最佳和最差的適應度值;ε為避免分母為0的小數。
第4步:按照第3步進行迭代計算,按照公式(7)~(9)進行評價并更新麻雀位置,直至適應度滿足要求時停止。
第5步:參數選擇結果賦值。將滿足精度要求的麻雀適應度值作為神經網絡的權值和閾值,運用式(6)將樣本數據再次歸一化后進行神經網絡訓練。
具體SSA-BP模型算法流程見圖2。
1.5?數據處理
采用Microsoft Excel 2016進行數據基本運算與畫圖;采用SPSS 23軟件進行顯著性分析;采用Matlab進行神經網絡計算。
2?結果與分析
2.1?水氮生產函數全生育期模型
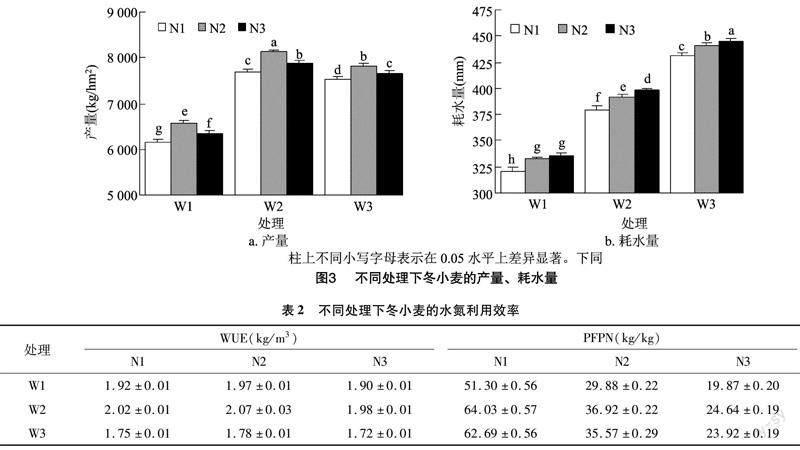
由圖3可知,灌水、施肥可以顯著提高作物產量和耗水量,其增長幅度因用量不同而產生差異。寬壟溝灌下冬小麥產量在N2W2處理最大,為 8 121.75 kg/hm2;耗水量在N3W3處理最大,為444.61 mm。以產量最低組N1W1作為對照組,冬小麥增產達201.64~1 965.70 kg/hm2,其中最高增幅發生在N2W2處理組 為31.93%;不同水分控制下限對產量影響顯著,以W1組平均產量為對照組,寬壟溝灌下冬小麥平均產量增長率在W2時達24.12%,W3時達20.52%,可以看出中水處理比高水處理更有利于作物產量積累;不同氮肥處理對產量影響也比較顯著,以N1組平均產量為對照組,寬壟溝灌下冬小麥平均產量增長率在N2時達5.42%,N3時達2.50%,可以看出中肥處理比高肥處理對產量更有積極影響;從產量的誤差棒可以看出,W1和W2時,N2處理組的標準偏差明顯小于N1和N3,作物產量積累得更加均勻。
由表2可知,各處理組的水分利用效率差異不大,但氮肥偏生產力差異較大。寬壟溝灌下冬小麥平均水分利用效率在W1、W2、W3時分別為1.93、2.03、1.75 kg/m3,在N1、N2、N3時分別為1.90、1.94、1.87 kg/m3,平均氮肥偏生產力在W1、W2、W3時分別為33.68、41.86、40.73 kg/kg,在N1、N2、N3時分別為59.34、34.12、22.81 kg/kg,可見當水分處理為70%FC,繼續增大灌水量不能增大冬小麥的水分利用效率和氮肥偏生產力。
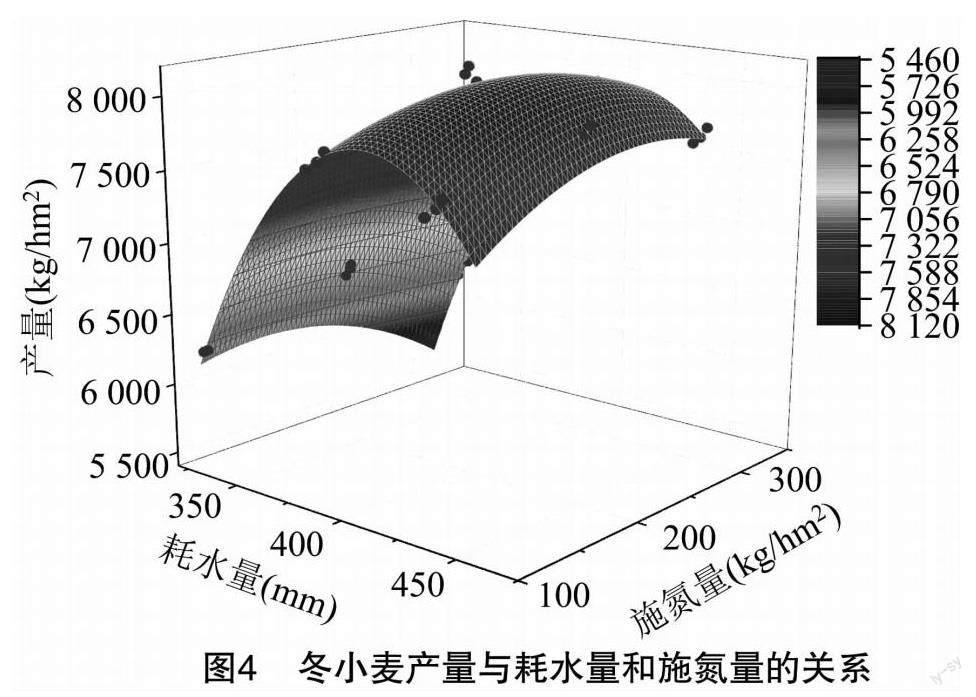
通過分析耗水量、施氮量與產量的關系,發現其符合非線性曲面模型,擬合情況見圖4,設Y為產量,kg/hm2;ET為全生育階段內的耗水量,mm;N為施氮量,kg/hm2;則:
Y=-0.268ET2-0.024N2+0.035ET·N+210.155ET-2.854M-34 390.480。(12)
對擬合參數進行t檢驗,發現其所有參數的相關性均在0.99以上,整體決定系數R2為0.983,且產量隨耗水量和施氮量的增大而先增大后減小。定義dY/dET=0和dY/dN=0時對應耗水量和施氮
量為最優值,則冬小麥在寬壟溝灌下,最佳需水量為407.73 mm,最佳施氮量為235.98 kg/hm2。
2.2?Jensen模型下的冬小麥水氮生產函數及敏感指數累積曲線
將施氮量作為自變量分析其與產量的關系,發現氮素效益函數與二次曲線擬合良好,決定系數R2在0.92之上,氮肥效應函數如下所示:
通過式(6)將各處理數據采用SPSS軟件進行擬合,得到Jensen模型下的冬小麥水氮生產函數,如下所示:
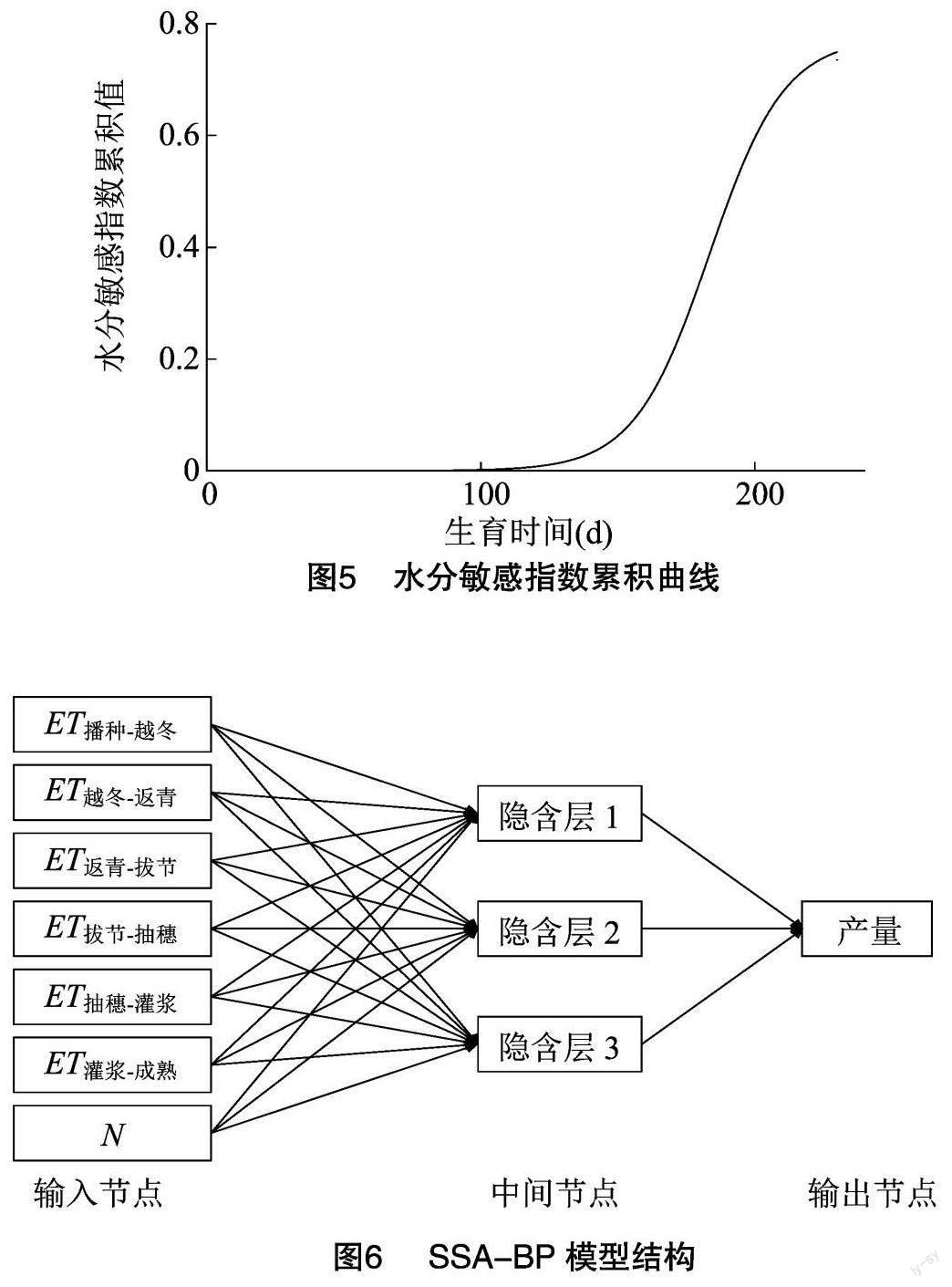
由式(14)可知,寬壟溝灌下冬小麥水分敏感指數表現為拔節—抽穗(λ4=0.282)>抽穗—灌漿(λ5=0.272)>灌漿—成熟(λ6=0.09)>返青—拔節(λ3=0.038)>播種—越冬(λ1=0.031)>越冬—返青(λ2=0.022)。為了減小因生育期劃分帶來的誤差,本試驗通過式(7)進行了水分敏感指數累積曲線的擬合,如圖5所示,對擬合參數進行t檢驗,發現其所有參數的相關性均在0.6以上,整體決定系數R2為0.99,水分敏感指數累積函數如下所示:
2.3?SSA-BP模型下的冬小麥水氮生產函數
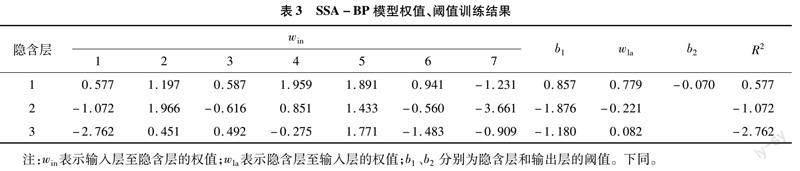
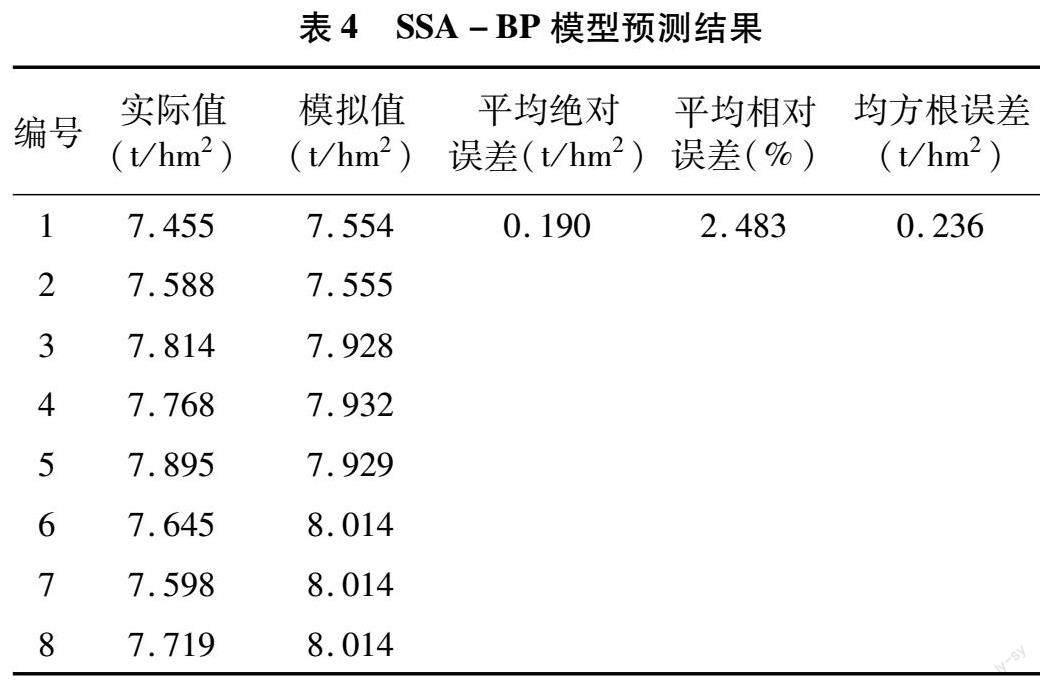
試驗獲得27組數據,以其中隨機70%數據(19組)作為訓練集,其他(8組)作為測試集,模型結構見圖6,設置7個輸入,其中6個表示各生育階段的耗水量,剩余1個表示施氮量,3個隱含層節點,1個輸出,形成1個7-3-1的神經網絡結構。設置SSA參數為麻雀數量NP=20,最大迭代次數 itermax=50,警戒閾值ST=0.6,發現者比例PD=0.6。SSA-BP模型權值、閾值訓練結果見表3,由表3參數對8組測試樣本進行計算,其結果見表4。
2.4?水氮生產函數模型比較
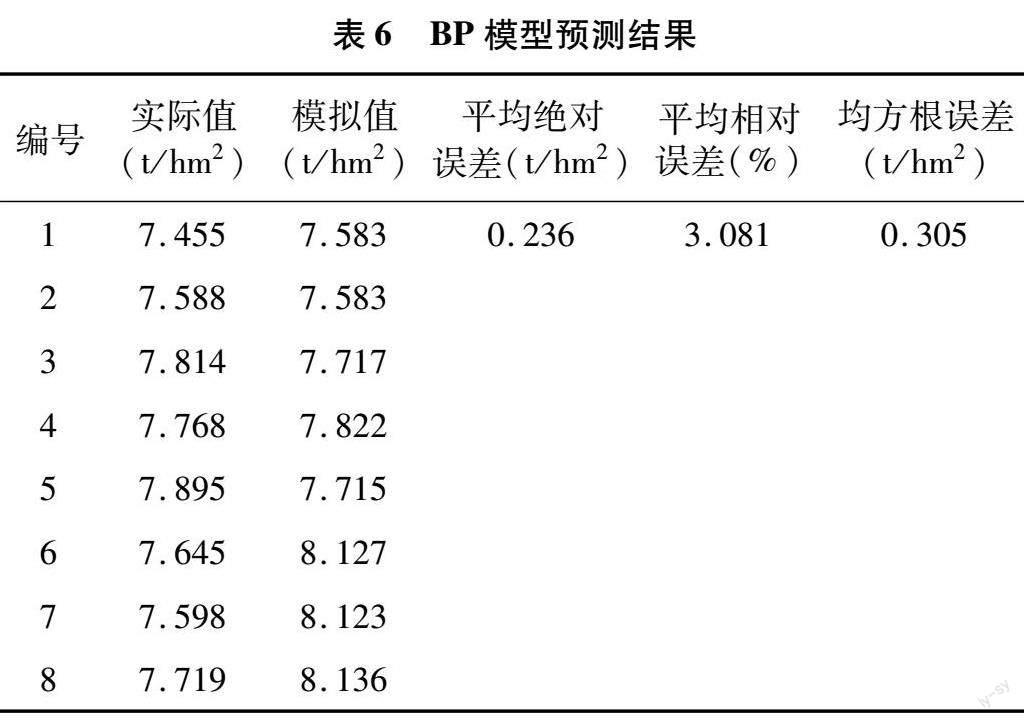
為進一步進行比較,用相同試驗樣本建立未經優化過的BP模型來描述寬壟溝灌下冬小麥水氮生產函數,模型設置與SSA-BP模型相同。BP模型權值、閾值訓練結果見表5,由表5參數對8組測試樣本進行計算,結果見表6。通過對比表4、表6,可以看出相同網絡結構下SSA-BP模型的平均絕對誤差、平均相對誤差和均方根誤差均小于BP模型。
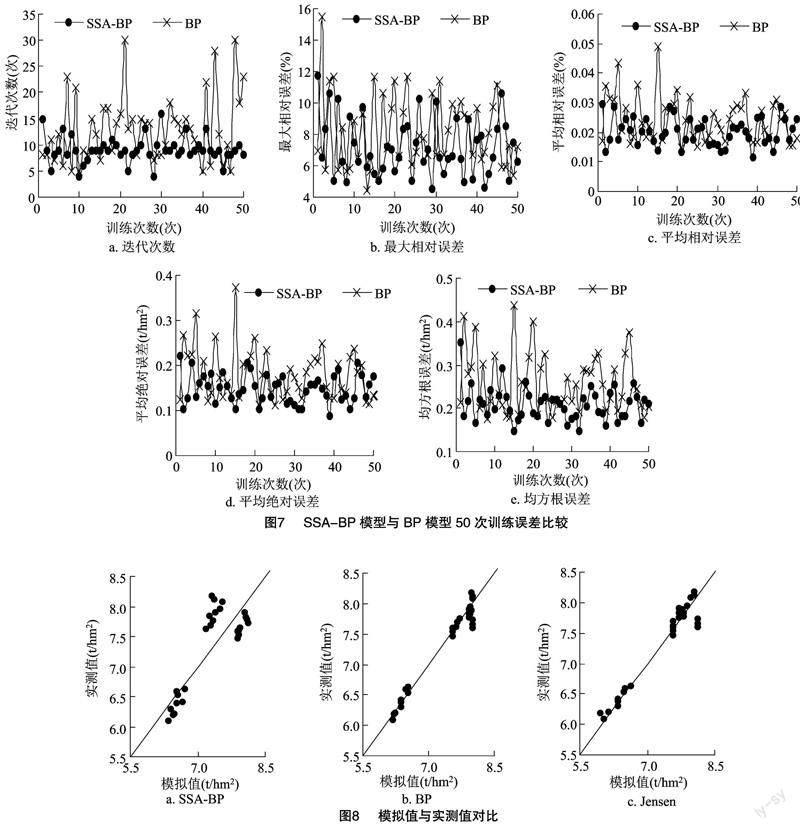
為消除訓練帶來的隨機誤差,經50次模型訓練后,結果見圖7,取迭代次數、最大相對誤差、平均相對誤差等指標判斷其優劣性。由此可知,在50次模擬中BP模型的平均迭代次數為12.88次,比SSA-BP模型多3.82次,最大相對誤差為7.141%,比SSA-BP模型大13.29%,平均相對誤差為0.020%,比SSA-BP模型大17.12%,平均絕對誤差為0.181 t/hm2,比SSA-BP模型大17.82%,均方根誤差為0.258 t/hm2,比SSA-BP模型大19.33%,由此可見,SSA-BP模型收斂速度更快,效果更好。
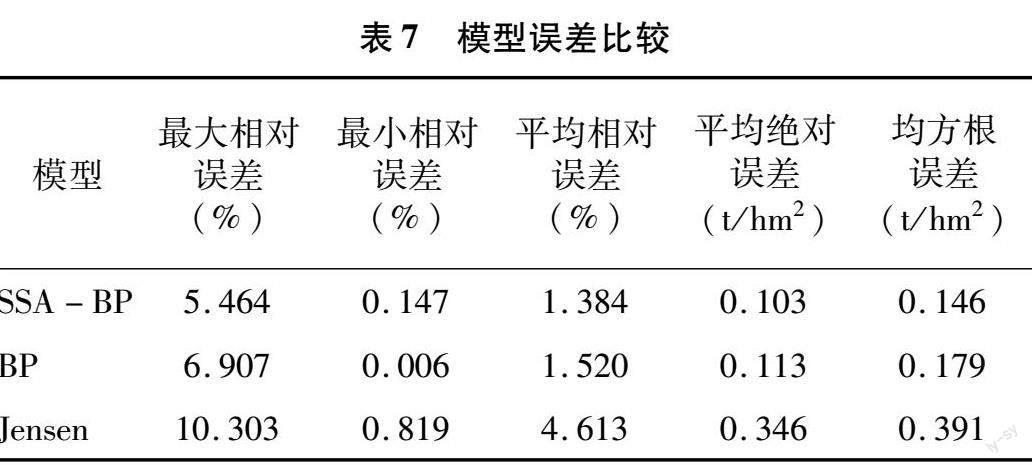
利用表3、表5的SSA-BP模型和BP模型與Jensen模型得到的水氮生產函數進行產量的實測值與模擬值對比,結果見圖8,具體誤差見表7。
3?討論與結論
水、肥作為影響作物產量的主要因素,選擇適宜的上下限對提高產量具有重要意義[21-22]。本試驗表明,不同水、氮處理均能顯著影響冬小麥的產量和水氮利用效率,作物產量與耗水量和施氮量均呈非線性關系,表現為W2>W3>W1,N2>N3>N1。從耗水特性來看,全生育期內寬壟溝灌冬小麥最佳需水量為407.73 mm,比劉俊明等采用常規灌溉節水23.68%[23],比王松林等發現壟植溝灌節水比例略小,這是因為肥液中氮素含量增加造成基質勢增加,肥液更易向土壤深層滲流,表現出增加施氮量促進作物耗水量增加的特性[24]。增加灌水量在一定范圍內能夠提高氮肥偏生產力,過量施氮反而對水分利用效率造成消極影響。本試驗中水分利用效率表現為W2>W1>W3,N2>N1>N3;氮肥偏生產力表現為W2>W3>W1,N1>N2>N3。綜合考慮產量及水氮利用效率,在施氮量為235.98 kg/hm2、水分處理為70%FC時,既能得到較高效益,又避免了過度灌溉和施肥造成的環境污染和資源浪費,對建設節約型農業有積極意義。
本研究寬壟溝灌下冬小麥水分敏感指數表現為拔節—抽穗(λ4=0.282)>抽穗—灌漿(λ5=0.272)>灌漿—成熟(λ6=0.09)>返青—拔節(λ3=0.038)>播種—越冬(λ1=0.031)>越冬—返青(λ2=0.022),說明寬壟溝灌下在拔節—抽穗期冬小麥產量對水分最為敏感,此時冬小麥的根、莖、葉快速生長,根系加速對土壤水分的吸收,作物在該時期需保證正常供水,否則將會造成減產,這與已有研究結果[25-26]基本一致。此外,播種—越冬—拔節期的敏感指數較朱嘉偉等的研究結果小[27],可能是因為結合了苗期與越冬期,且該時段的有效降水量占全生育期的78%,降低了該時段的水分脅迫。冬小麥敏感指數峰值比彭致功等運用Minhas模型測算的大興區冬小麥敏感指數峰值略有提前[28],說明寬壟溝灌能夠使作物提前進入生育期,水氮的充足施用促進作物早熟。該生育階段若進行水分脅迫,將會造成減產。冬小麥水分敏感指數累積值符合“S”曲線特征,與韓松俊等的研究結果[29]一致,在拔節期之前緩慢增加,在拔節到灌漿期增長較快,到成熟期接近?0.8。拔節期后冬小麥進入快速生長期,在抽穗后,生物產量和經濟產量同時增長,植株蒸騰較強,耗水量較大,此時應保證充足灌水量。
灌區產量預測是了解土壤生產潛力和糧食安全保障能力的重要手段之一[30]。水氮生產函數可定量評估田間水分和施氮對作物產量的影響[31]。本研究運用寬壟溝灌下冬小麥的產量-耗水量-施氮量建立水氮生產函數的Jensen模型、SSA-BP模型,并使SSA-BP模型與原始BP模型進行對比,經過50模型訓練后,發現SSA-BP模型的平均迭代次數比BP模型少3.82次,其平均最大相對誤差、平均相對誤差等誤差指標更小。且運用SSA-BP模型建立的水氮生產函數的實測值與模擬值比Jensen模型平均最大相對誤差降低46.97%,平均相對誤差降低70.00%,平均絕對誤差降低70.23%,平均均方根誤差降低62.66%,可見雖然Jensen模型能夠更直觀體現各生育期對水分的敏感性,卻在產量預測上略遜一籌,SSA-BP模型不僅適用于水氮生產函數的表達且誤差更小。
本研究根據寬壟溝灌下冬小麥試驗資料分析了不同水氮處理對寬壟溝灌下冬小麥的產量、耗水量和水氮利用效率的影響,建立了水氮生產函數的Jensen模型、SSA-BP模型。通過實例的計算和分析得到以下結論:冬小麥產量及水氮素利用效率受水氮處理影響顯著,相同含水率控制下限,當施氮水平超過 220 kg/hm2 時,增施氮肥不能顯著增加冬小麥產量和水分利用效率,反而會降低氮肥偏生產力。隨著含水率控制下限的增加,耗水量也增加,產量和水氮利用效率先增大后減小。本試驗條件下最優水氮方案為:70%FC控制下限和235.98 kg/hm2施氮量。Jensen模型下寬壟溝灌冬小麥各生育階段水分敏感指數大小表現為拔節—抽穗(λ4=0.282)>抽穗—灌漿(λ5=0.272)>灌漿—成熟(λ6=0.09)>返青—拔節(λ3=0.038)>播種—越冬(λ1=0.031)>越冬—返青(λ2=0.022),拔節—抽穗期對水分虧缺最為敏感。本研究中SSA-BP模型能夠使水氮生產函數的模擬值與實測值的最大相對誤差、平均相對誤差、平均絕對誤差、均方根誤差更小,且迭代次數較BP模型更少,收斂速度更快。同時發現Jensen模型、SSA-BP模型和BP模型均能描述水氮生產函數,均能得到線性擬合接近y=x的實測產量與預測產量,其誤差評價指標表現為Jensen模型>BP模型>SSA-BP模型。
參考文獻:
[1]馬?濤,劉九夫,彭安幫,等. 中國非常規水資源開發利用進展[J]. 水科學進展,2020,31(6):960-969.
[2]劉馨井雨,韓旭東,張曉春,等. 基于SEBAL模型和環境衛星的區域蒸散發量及灌溉水利用系數估算研究[J]. 灌溉排水學報,2021,40(8):136-144.
[3]朱?偉,劉春成,馮保清,等. “十一五”期間我國灌溉水利用率變化分析[J]. 灌溉排水學報,2013,32(2):26-29.
[4]佟金萍,馬劍鋒,王慧敏,等. 農業用水效率與技術進步:基于中國農業面板數據的實證研究[J]. 資源科學,2014,36(9):1765-1772.
[5]李書田,劉曉永,何?萍. 當前我國農業生產中的養分需求分析[J]. 植物營養與肥料學報,2017,23(6):1416-1432.
[6]史常亮,朱俊峰. 我國糧食生產中化肥投入的經濟評價和分析[J]. 干旱區資源與環境,2016,30(9):57-63.
[7]劉文倩,費喜敏,王成軍. 化肥經濟過量施用行為的影響因素研究[J]. 生態與農村環境學報,2018,34(8):726-732.
[8]Wang D B,Li F S,Nong M L. Response of yield and water use efficiency to different irrigation levels at different growth stages of Kenaf and crop water production function[J]. Agricultural Water Management,2017,179:177-183.
[9]Greaves G E,Wang Y M. Yield response,water productivity,and seasonal water production functions for maize under deficit irrigation water management in southern Taiwan[J]. Plant Production Science,2017,20(4):353-365.
[10]李中愷,劉?鵠,趙文智. 作物水分生產函數研究進展[J]. 中國生態農業學報,2018,26(12):1781-1794.
[11]Mukherjee D. Optimizing water production function and deficit irrigation scheduling during extreme dry periods[J]. Journal of Irrigation and Drainage Engineering,2021,147(12):1-14.
[12]王仰仁,解愛國,王文龍,等. 作物水模型參數與時段數關系的研究[J]. 中國農村水利水電,2010(8):16-20,25.
[13]Pushpalatha R,Amma S S,George J,et al. Development of optimal irrigation schedules and crop water production function for cassava:study over three major growing areas in India[J]. Irrigation Science,2020,38(3):251-261.
[14]Soltani A,Stoorvogel J J,Veldkamp A. Model suitability to assess regional potato yield patterns in northern Ecuador[J]. European Journal of Agronomy,2013,48:101-108.
[15]Singh S P,Mahapatra B S,Pramanick B,et al. Effect of irrigation levels,planting methods and mulching on nutrient uptake,yield,quality,water and fertilizer productivity of field mustard (Brassica rapa L.) under sandy loam soil[J]. Agricultural Water Management,2021,244:106539.
[16]周智偉,尚松浩,雷志棟. 冬小麥水肥生產函數的Jensen模型和人工神經網絡模型及其應用[J]. 水科學進展,2003,14(3):280-284.
[17]王龍強,郄志紅,吳鑫淼. 冬小麥水肥生產函數的PSO-SVM模型[J]. 節水灌溉,2013(12):1-4,11.
[18]孟志軍,劉淮玉,安曉飛,等. 基于SPA-SSA-BP的小麥秸稈含水率檢測模型[J]. 農業機械學報,2022,53(2):231-238,245.
[19]何茂林,解明聰,徐振洋. 基于SSA-BP神經網絡爆破參數優選試驗研究[J]. 礦業研究與開發,2022,42(1):36-41.
[20]唐興旺,石?玉,于振文,等. 開花期土壤水分含量對不同穗型小麥品種光合特性及產量的影響[J]. 麥類作物學報,2020,40(5):609-614.
[21]張?睿,李鳳艷,文?娟,等. 施肥模式對渭北旱地小麥產量及效益的影響[J]. 麥類作物學報,2018,38(2):191-195.
[22]叢?鑫,張立志,徐征和,等. 水氮互作對冬小麥水肥利用效率與經濟效益的影響[J]. 農業機械學報,2021,52(3):315-324.
[23]劉俊明,高?陽,司轉運,等. 栽培方式對冬小麥耗水量、產量及水分利用效率的影響[J]. 水土保持學報,2020,34(1):210-216.
[24]王松林,史?尚,王?興,等. 不同種植模式冬小麥耗水特性及產量試驗研究[J]. 中國農村水利水電,2014(5):49-52.
[25]袁漢民,王小亮,孫建昌,等. 寧夏引黃灌區小麥壟作節水高產栽培研究[J]. 節水灌溉,2005(6):5-7.
[26]賀?鵬,王鵬新,解?毅,等. 基于動態模擬的冬小麥水分脅迫敏感性研究[J]. 干旱地區農業研究,2016,34(1):213-219,271.
[27]朱嘉偉,趙聰佳,郭蕊蕊,等. 水資源約束條件下的縣域冬小麥節水灌溉制度[J]. 農業工程學報,2021,37(1):92-100.
[28]彭致功,劉?鈺,許?迪,等. 基于RS數據和GIS方法的冬小麥水分生產函數估算[J]. 農業機械學報,2014,45(8):167-171.
[29]韓松俊,劉群昌,王少麗,等. 作物水分敏感指數累積函數的改進及其驗證[J]. 農業工程學報,2010,26(6):83-88.
[30]孫揚越,申雙和. 作物生長模型的應用研究進展[J]. 中國農業氣象,2019,40(7):444-459.
[31]李文玲,孫西歡,張建華,等. 水氮耦合對膜下滴灌設施番茄水氮生產函數影響研究[J]. 灌溉排水學報,2021,40(1):47-54.
