少樣本知識圖譜補全技術研究
2023-06-07 08:30:02彭晏飛張睿思王瑞華郭家隆
計算機與生活 2023年6期
彭晏飛,張睿思,王瑞華,郭家隆
遼寧工程技術大學 電子與信息工程學院,遼寧 葫蘆島125100
知識圖譜(knowledge graph,KG)用結構化的形式描述客觀世界中概念、實體及其關系,它將互聯網的信息表達成更接近人類認知世界的形式,提供了一種更好地組織、管理和理解互聯網海量信息的能力[1]。知識圖譜以三元組的形式(頭實體,關系,尾實體)存儲知識和事件,以網絡的形式作為展示,在網絡中每個節點代表實體,節點之間相互連接的邊代表關系。目前一些大規模知識圖譜NELL(never-ending language learner)[2]、Wikidate[3]、YAGO(yet another great ontology)[4]等被廣泛應用于各種自然語言處理任務中,例如語義搜索[5]、智能問答[6-7]、推薦系統[8-9]等。
盡管知識圖譜中有著大量的實體、關系、三元組,但是現有的大部分知識圖譜都是不完整的,具體體現在一些實體之間缺少對應的關系,一些頭實體和關系間缺少對應的尾實體。知識圖譜補全任務(knowledge graph completion,KGC)旨在學習知識圖譜中現有的實體關系三元組,進而推斷出知識圖譜缺失的實體或關系。
知識圖譜嵌入(knowledge graph embedding,KGE)旨在將實體和關系嵌入到潛在的低維數字表示中[10]。在過去幾年,KGE 方法被證明在KGC 任務上是有效的[11-12],并且許多KGE方法已經應用于KGC任務,其中包括TransE(translating embedding)[13]、ComplEx(complex embeddings)[14]和ConvE(convolutional 2D knowledge graph embeddings)[12]等方法。但是目前的這些方法都假設KG包含足夠的實體和關系數據,然而在KG 中少樣本關系數據是廣泛存在的,例如Wikidate 中大約有10%的關系只有不超過10 個三元組實例[3]。此外,在實際應用的過程中,社交媒體或推薦系統產生的KG,會隨著時間的流動進行動態更新,更新后的新關系通常只有少量的三元組實例。這種情況會導致大部分KGC 方法的效果下降,因為這些方法都要求擁有足夠的訓練實例[15],所以在只擁有少數三元組實例的情況下,如何完成知識圖譜補全任務是重要且具有挑戰性的。
鑒于上述問題,Xiong等人[16]在2018年第一次定義少樣本知識圖譜補全概念,并提出Gmatching 模型用來解決FKGC(few-shot knowledge graph completion)任務。這也是少樣本學習[17]在知識圖譜補全上的第一項研究,之前少樣本學習的研究主要集中在計算機視覺[18]、情感分析[19]和文本分類[20]等領域上。近年來,學者們也提出了很多解決FKGC 任務的方法[21],然而FKGC模型仍然面臨著FKGC補全程度不高、無法很好利用KG中的結構信息、太過依賴于實體的鄰域信息[22]等問題。本文將現有的FKGC 方法作為研究對象,整理并歸納FKGC經典方法以及最新研究成果,總結目前研究面臨的挑戰,并對未來的研究趨勢進行展望。本文的主要貢獻如下:
(1)對目前FKGC 方法進行全面分類,以解決問題的方法作為分類依據,分為基于度量學習的方法、基于元學習的方法以及基于其他模型的方法。
(2)詳細闡述了每種FKGC 模型的思想,歸納并分析每種模型的核心、模型思路、特點和局限性;最后從方法分類、發表年份、數據集、評價指標、模型優缺點和模型思路上對FKGC方法進行橫縱比較。
(3)列出常用的FKGC 數據集;對FKGC 中常用的評價指標進行說明;以NELL-One 和Wiki-One 數據集為例,在不同數據集上比較各個模型間的性能差異并進行分析。
(4)討論了目前FKGC 任務的難點問題,展望了FKGC方法未來值得關注的發展方向。
1 少樣本知識圖譜補全概述和相關內容
知識圖譜G表示為三元組{(h,r,t)}?E×R×E的集合,其中E和R是實體集合和關系集合。每個三元組都由一個關系r∈R和兩個實體h,t∈E組成,它們之間可以表示為頭實體h到尾實體t有一條有向邊r連接。
在知識圖譜中,知識圖譜補全任務分為兩種:一種是在已知兩個實體(h,?,t)的情況下,預測其中的關系r;另一種是在已知頭部實體和關系(h,r,?)的情況下,預測尾部實體t。目前研究者更專注于后一種研究。
少樣本知識圖譜補全任務考慮了實際場景,與知識圖譜補全中假設每個關系都有足夠的實體對不同。該任務只擁有少數與關系r相關的三元組作為參考集,需要預測查詢集中潛在的尾實體t。
對于該任務而言,少樣本知識圖譜補全方法的目標是在給定參考集S的情況下,查詢集Q正確尾實體ttrue的排名要高于其他錯誤尾實體。
對于FKGC任務而言,一些當前領域的相關內容如下:
背景知識圖譜G′:是當前知識圖譜G的一個子集,其中包含和任務關系r相關的三元組。
實體的一跳鄰居集合Ne:一般在FKGC任務中Ne也被稱為實體e的鄰域,它是由背景知識圖譜G′產生,其中包含所有與實體e相連接的關系r和尾實體t。
少樣本關系的鄰域:針對少樣本關系r而言,它自身的鄰域可以被定義為{h,t,Nh,Nt},其中h、t是頭實體和尾實體,它們和關系r可以構成一個三元組(h,r,t);Nh、Nt是頭實體和尾實體的一跳鄰居集合。
2 少樣本知識圖譜補全方法
2018 年Xiong 等人[16]提出了少樣本知識圖譜補全的任務,并利用基于匹配網絡的模型Gmatching試圖對少樣本三元組進行少樣本關系學習來解決這一問題。由此少樣本知識圖譜補全任務受到學者們的廣泛關注,目前現有的FKGC方法按照解決問題的方法分類可以分為基于度量學習的方法[16,23-34]、基于元學習的方法[35-45]以及基于其他模型的方法[46-63]。
2.1 基于度量學習的方法
度量學習的方法一般是從一組待訓練的任務中學習到可概括的距離公式和相應的匹配函數,進而推廣到新出現的任務中[20],此類方法大多采用深度孿生網絡中所提出的通用匹配框架Matching Nets[64]。在KGC中,很多KGC模型在訓練過程中都需要大量的數據作為支撐,如果在FKGC任務中使用,就會面對性能受限制或者沒有足夠數據支持的問題。針對這種情況,學者們結合度量學習的思想,提出了若干模型。
Gmatching 模型[16]是由Xiong 等人在2018 年提出,該模型的核心是利用實體嵌入信息和局部圖結構來構建匹配度量函數。模型思想是針對當前任務的關系r,計算查詢實體對與參考實體對的相似度,排序得到正確尾實體ttrue的排名。
如圖1 所示,Gmatching 模型由鄰居編碼器和匹配處理器構成,在鄰居編碼器部分,為了得到實體e的鄰域表示f(Ne),首先將實體e相連接的每一個關系和尾實體拼接,得到關系實體對的嵌入信息將每個關系實體對的嵌入信息合并:
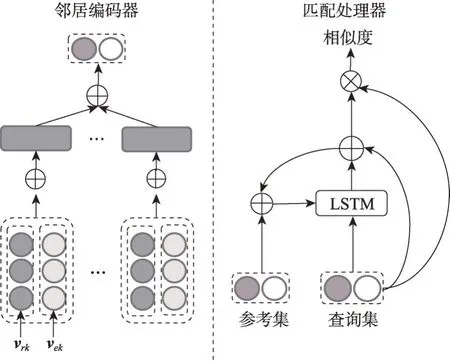
圖1 Gmatching模型結構Fig. 1 Gmatching model structure
其中,vrk、vek分別是關系實體對(rk,ek)中關系和實體的嵌入信息,⊕表示拼接操作,σ為激活函數tanh,Wc是權重參數。在匹配處理器中,為了得到ttrue排名,分別將參考集實體對(h0,t0) 和查詢集實體對(hi,tij)的鄰域表示拼接后得到對應的參考集關系向量s和查詢集關系向量q;最后利用式(2)求出所有查詢集與參考集的關系相似度得分。
其中,hk、ck是LSTM(long short-term memory)網絡的隱藏狀態和單元狀態,k是超參數。
作為少樣本知識圖譜補全任務的開山之作,Gmatching模型提出了一種基于關系學習的框架,與傳統的知識圖譜補全方法相比,該模型可以對任何關系進行預測,處理新添加的關系時也無需重新訓練模型,而之前的方法通常需要微調模型以適應新關系。
雖然Gmatching模型的整體結構簡單,但是每個部分都有各自的作用,其中鄰居編碼器利用局部的圖結構更好地表示了實體信息,匹配處理器利用多步循環對兩個集合的信息進行打分。在基于Wiki-One 數據集的實驗中,該模型性能比TransE 在MRR(mean reciprocal rank)指標上提高12.8%,具有較好的實驗效果。然而,此模型也存在一定缺點,由于鄰居編碼器在獲取實體的鄰域表示時,平等地集合鄰域中的不同信息,忽略了無效實體對模型產生的影響,導致模型效果降低。
為彌補Gmatching 模型的缺點,Zhang 等人[23]在2020 年提出FSRL(few-shot relation learning)模型。該模型的核心是利用異構鄰居解碼器分配給鄰域信息不同的權重,并在參考三元組集合中集成了來自多個三元組的信息,而在Gmatching中僅將單個三元組用于FKGC。如圖2 所示,FSRL 模型提出了異構鄰居解碼器模塊和聚合模塊,在異構鄰居編碼器中,實體e的鄰域表示f(Ne)不再采用集合所有嵌入信息的計算方式,而是為每個嵌入信息賦予一個權重αi,具體公式如下:
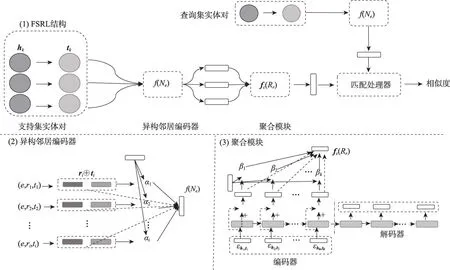
圖2 FSRL模型結構Fig. 2 FSRL model structure
與Gmatching 模型相比,FSRL 模型的異構鄰居編碼器彌補了Gmatching模型平等分配權重的缺點,新增的聚合模塊增加了三元組間的交互。實驗結果表明,在Wiki-One 和NELL-One 數據集上,該模型的性能比Gmatching模型分別提高了0.08、0.04,這足以證明它的改進是有效的。此外,FSRL還通過實驗證明在訓練過程中參考集的大小會影響參考集嵌入的質量,為后續FKGC的研究提供了支撐。
盡管FSRL模型根據不同實體提供不同權重,在一定程度上降低了無效實體對模型的影響,但其賦予權重的方式仍是靜態的,2020年Sheng等人[24]提出FAAN(novel adaptive attentional network)模型,該模型的核心是使用了實體和關系的動態屬性[65]。之前的模型大多關注于實體和關系的靜態信息,而忽略了它們的動態信息,例如實體在不同關系下的含義可能有所不同。為此FAAN模型提出自適應注意力[66]鄰居編碼器和Transformer[67]編碼器來捕捉實體與關系的動態信息。
如圖3 所示,在自適應注意力鄰居編碼器部分,由任務關系嵌入r和鄰接關系嵌入rk求得權重αk,實體對嵌入信息為尾實體嵌入信息的集合,最后利用頭實體嵌入h和實體對嵌入得到鄰域表示f(Ne)。公式如下所示:
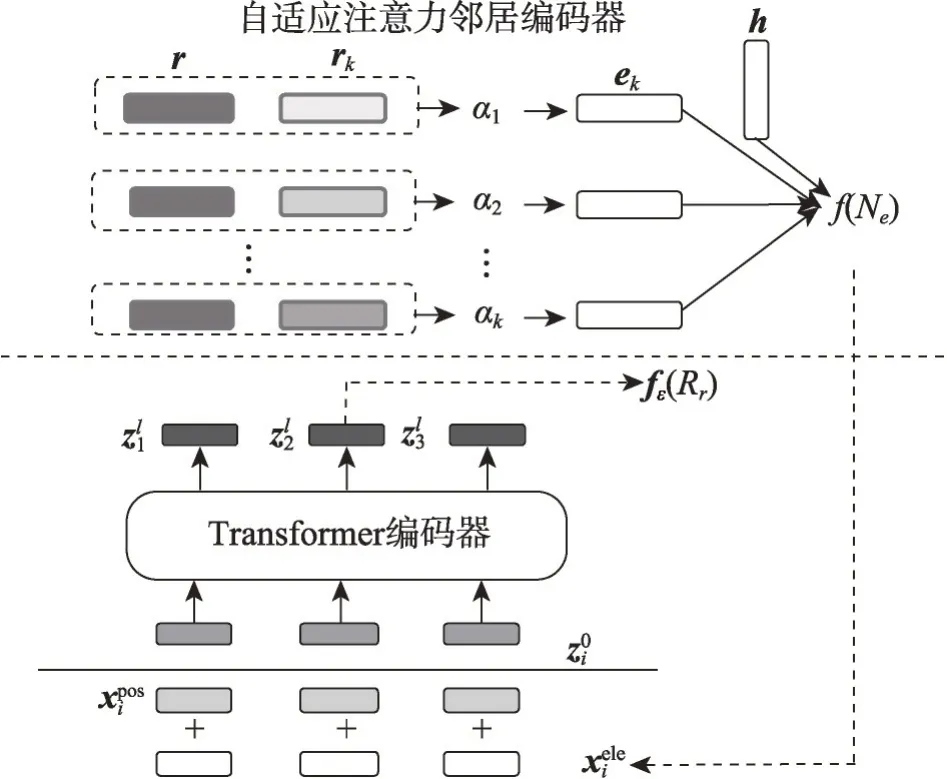
圖3 FAAN模型結構Fig. 3 FAAN model structure
其中,qr為查詢集關系嵌入表示,sk為參考集關系嵌入表示。
與當時其他模型不同,FAAN模型提出了一種新的范式,并且在鄰居編碼器部分將任務關系與鄰接關系結合,這些改進不僅為鄰域表示加入了更多的細粒度信息,也提供了一種計算相似度得分的新方法。在FKGC數據集上,FAAN模型的實驗結果優于當時其他的FKGC方法,其他實驗證明FAAN模型獲取動態屬性的方法提升了模型效果并且針對不同的任務關系具有良好的魯棒性。但是FAAN 模型在鄰居編碼器部分,只是針對實體的動態信息進行改進,并沒有建立參考集三元組間的聯系,忽略了三元組間的交互信息。
現有的大多數基于度量學習的方法,都忽略了三元組內部和三元組間的實體交互,因為這些模型都是針對實體對表示進行相似度匹配。為探索這種交互信息在FKGC 中的作用,Liang 等人[25]在2022 年提出TransAM(transformer appending matcher)模型,他們認為這些實體的交互信息可以提供有價值的顆粒度語義表示。該模型的核心是將參考實體對和查詢實體對作為序列以捕捉三元組內和三元組間實體的交互信息。具體過程為,將參考集和查詢集實體化為一個序列sq,sq=[[CLS],h1,t1,…,hK,tK,hq,tq],其中hK、tK是參考集實體對的頭實體和尾實體,hq、tq是查詢集的頭實體和尾實體;再通過實體編碼器和實體鄰域得到每個實體的最終表示xe,即:
與其他模型相比,TransAM模型利用旋轉操作編碼每個實體對的頭尾實體,這種操作使得模型學習到了更多的結構化信息(即對稱和反對稱信息)。為了使三元組內部交互,TransAM構建了塊注意掩碼矩陣來約束每個實體,使它只關注于自身三元組。此外,Liang 等人為了保留三元組結構的同時分離實體信息和三元組位置信息,設計了一種分離三元組位置信息的編碼方式。上述的這些方法使TransAM模型成為了目前最先進的方法之一,但是TransAM 的局限性在于模型過多地關注實體信息,而三元組內的關系信息只用于貢獻權重,導致模型不能處理復雜的少樣本關系,今后可以在這一方向上進一步研究。
表1匯總了本節所提到的基于度量學習的FKGC方法,可以看出度量學習的方法在逐步完善缺點的同時也在尋找更適合的匹配方法,但是復雜的少樣本關系不僅是少樣本知識圖譜補全所遇到的問題,也是目前知識圖譜補全存在的難點。

表1 度量學習方法匯總Table 1 Summary of measurement learning methods
根據對現有的基于度量學習的少樣本知識圖譜補全方法的整理,可以發現:目前的模型一方面在探索如何通過實體的鄰域信息,獲得更加豐富的關系嵌入表示,如FSRL、FAAN 等;另一方面受到當前自然語言處理中預訓練語言模型的影響,探索如何構建一種匹配方法,能夠更好地求出參考集與查詢集的相似度得分,如TransAM等。
2.2 基于元學習的方法
元學習就是學會學習的學習[68],其特點是只使用少量的訓練樣本,也能快速學習新的概念或知識[69]。在FKGC的研究中,基于元學習的方法旨在學習訓練任務中的關聯三元組特征,從而在新的任務上進行泛化,其中比較有代表性的方法有MetaR(meta relational learning)模型[35]、Meta-KGR(meta-based multi-hop reasoning)模型[36]、GANA(gated and attentive neighbor aggregator)模型[37]、Meta-iKG模型[38]。
MetaR 模型[35]是由Chen 等人在2019 年提出的,該模型是第一個將元學習應用于FKGC 上的方法。MetaR 模型的核心是利用關系元信息和梯度元信息來加速模型的更新迭代與完成FKGC任務。
如圖4 所示,首先聚合所有實體對的關系表示R(hi,ti),計算得到關系元信息RTr:
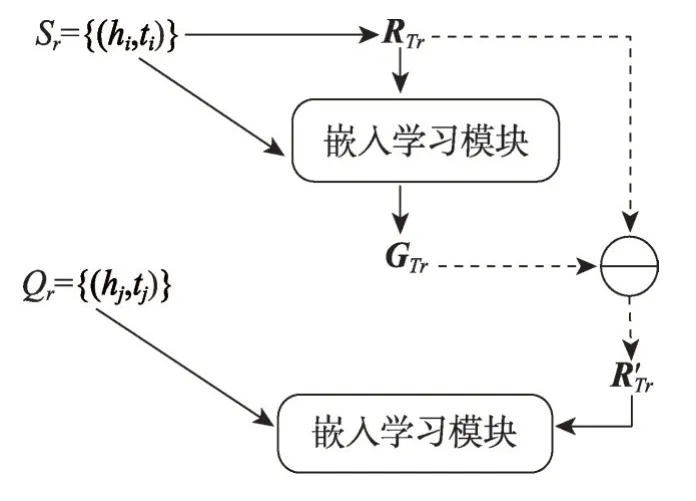
圖4 MetaR模型結構Fig. 4 MetaR model structure
在得到當前任務Tr的關系元信息后,通過損失函數生成梯度元信息GTr:
其中,||x||代表向量x的L2 范數,s(hi,ti)是利用了TransE中的思想得到的評分函數,它假設頭實體嵌入h、關系嵌入r、尾實體嵌入t滿足h+r=t,L(Sr)是模型的損失函數,γ是超參數,L(Sr)代表損失函數的梯度。之后利用GTr對關系元信息的更新進行加速:
作為第一個將元學習應用于FKGC 的方法,MetaR模型不僅融合了TransE模型的思想,還證明了將關系特定的元信息從參考集轉移到查詢集的方法,在FKGC 任務上是有效的。同時,在基于Wiki-One 和NELL-One 數據集的實驗中,無論是1-shot 還是5-shot的結果,都比當時的其他模型效果更好。但是MetaR模型的局限性在于計算關系元信息時,認為所有實體對的貢獻相同,忽略了參考集中三元組對關系表示的不同影響。
Meta-KGR 模型[36]是由Lv 等人在2019 年提出的,該模型的核心是將強化學習(reinforcement learning,RL)[70]與元學習結合。該模型將具有相同關系r的三元組查詢都視為一項任務,對每個任務先利用RL 訓練一個代理,目的是搜索目標尾實體和推理路徑,其中該模型為了使用決策的歷史信息使用LSTM網絡對搜索路徑進行編碼,訓練過程中,此部分的損失函數定義為:
其中,r是查詢關系,D是查詢關系的三元組集合,es、eo代表頭實體和目標尾實體,ai是動作,R(sT|es,r)是RL 中的獎勵機制。在得到參考集合DS的參數θ后,為了使其包含不同任務的共同特征,達到能夠快速適應少樣本任務的效果,該模型利用元學習的思想,通過每個任務的查詢集合DQ對θ進行更新,更新公式如下:
Meta-KGR 模型作為一種基于元學習的多跳推理模型,與之前的多跳推理模型相比,Meta-KGR 模型在FKGC 任務上更有優勢。與其他FKGC 方法相比,Meta-KGR 模型能提供多跳的解釋路徑,而大多數方法都是缺乏可解釋性的。此外,在基于FB15k-237 和NELL-995 數據集的少樣本實驗中,該模型效果均優于當時最先進的多跳推理方法,并且實驗還證明了模型具有魯棒性,即可以推廣到不同類型的知識圖譜。但是由于該模型的推理每一步都要求有對應的路徑進行搜索查找,當出現沒有路徑的答案時,模型效果就大大降低。
在少樣本知識圖譜補全過程中,如果當前鄰域過于稀疏,那么在構建鄰域表示時鄰域中的噪音信息會被放大,從而影響模型效果。為解決該問題,Niu等人[37]在2021年提出了GANA模型,該模型的核心是通過門控網絡和圖注意力機制[71]過濾鄰域中的噪音信息,找到鄰域中最有價值的信息。為了確定實體鄰域的范圍進而減少實體鄰域中噪音信息的影響,GANA 模型首先拼接與實體相連接的每個關系嵌入和尾實體嵌入得到ci,同時賦予每個ci對應的權重αi:
其中,g是門值,它的目的是自動確定實體鄰域的范圍,進而利用圖注意力機制賦予權重,得到噪音信息更少的實體鄰域表示e′,即:
其中,ve是當前實體的嵌入信息,W是權重參數。對于當前三元組(h,r,t)而言,將頭實體鄰域表示h′和尾實體鄰域表示t′拼接就得到了減少噪音信息后的三元組關系鄰域表示s。此外,GANA模型為了對復雜關系進行建模,提出了MTransH 方法,這種方法將TransH[72]作為評分函數與元學習進行結合,與MetaR模型相比,這種結合效果更好,因為TransH模型相對于TransE 模型可以更好地模擬三元組中的復雜關系。GANA 模型在基于Wiki-One 和NELL-One 數據集的實驗中,與MetaR模型相比,MRR指標分別提升8%、5%。在針對復雜關系建模的實驗中,GANA 模型也證明了自身在處理1-N、N-1上的優勢,這說明將元學習與TransH結合的方法在對復雜關系建模時是有效的。但是實驗同時也暴露出GANA在N-N上的效果不佳,這也和N-N 的情況下,FKGC 任務難度增加有關。
Meta-iKG 模型[38]是Zheng 等人在2022 年提出的,該模型的核心是利用局部子圖傳輸特定子圖信息。該模型將FKGC任務轉換為子圖建模問題,將相同關系的三元組查詢視為一個任務。在特定關系學習模塊利用GNN網絡[73]圍繞特定關系的子圖學習到參數θ,再構建元學習器模塊,從θ中提取出不同任務中的相同特征,最終達到快速適應少樣本和多樣本任務的目的。
與其他元學習模型相比,Meta-iKG 模型在傳統元學習的基礎上,引入了多樣本關系的更新過程,使其能夠很好地對少樣本關系進行泛化,基于FB15k-237 數據集的實驗也證明了這一觀點。同時因為模型只能提取子圖的結構語義,而子圖是一個有向圖結構,這就導致模型不能很好地解決反對稱關系的三元組類型。
表2 匯總了本節所提到的基于元學習的FKGC方法,MetaR模型[35]、Meta-KGR模型[36]、GANA模型[37]、Meta-iKG 模型[38]都在元學習的方法中具有代表性,同時它們都能夠較好地適用于FKGC任務,只是每個模型的側重點不同。MetaR 模型側重于利用元學習來解決少樣本問題,Meta-KGR 模型側重于將RL 和元學習結合,GANA 模型側重于使用門控網絡和圖注意力來消除噪音,Meta-iKG 側重于利用局部子圖來傳輸特定的子圖信息。
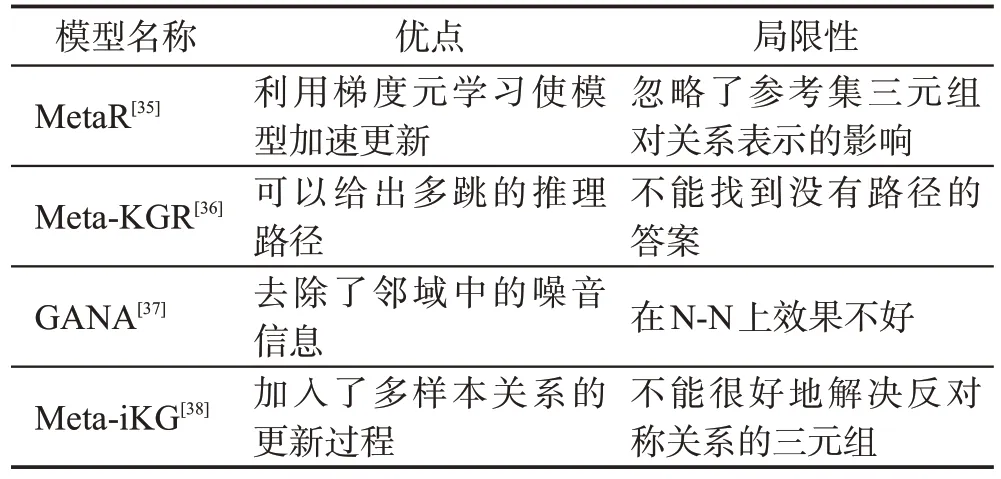
表2 元學習方法匯總Table 2 Summary of meta learning methods
整體而言,基于元學習的方法更關注于關系信息的獲取,模型整體結構一般分成兩部分:第一部分負責融合信息,獲取到任務關系的表示;第二部分負責利用元學習加速更新過程,達到快速適應新關系的目的。在這個過程中,研究者為了達到更好的效果,一般將元學習的方法與其他方法進行結合,例如Meta-KGR 模型中結合RL,GANA 模型中結合圖注意力網絡,Meta-iKG模型中結合GNN網絡等。
2.3 基于其他模型的方法
除了上述兩種主流方法外,還有少數研究者正在拓展其他方法的研究,但是由于這些方法之間理論不同,又無法匯總出一個新的類別,只能暫時將它們歸為基于其他模型的方法。雖然這些研究并不一定有突破的進展,但是為后續的研究者提供了一條新的思路。本節將介紹一些其中典型的方法,例如基于雙重過程理論的模型CogKR(cognitive knowledge graph reasoning)[46]、基于知識協同微調方法的模型(knowledge coordination fine-tuning,KnowCo-Tuning)[47]、基于對抗遷移學習的模型wRAN(weighted relation adversarial network)[48]和基于注意力機制的模型[49]。
雙重過程理論[74]認為人類的推理系統由兩種不同形式的系統組成:一個系統是無意識且隱藏的,它負責檢索大腦中的信息;另一個系統是有意識且可控的,它負責將收集到的信息進行推理。基于此理論,Du 等人[46]在2019 年提出了CogKR 模型,該模型的思路是首先在摘要模塊中通過實體對(h,t)得到潛在關系表示ωh,t:
其中,Ne是實體e的鄰域,ve、vr是實體和關系的嵌入表示,W是權重參數,ωe是實體的信息表示。之后給定一個頭實體h^,與人類的推理過程類似,模型通過對認知圖譜的迭代更新,最終預測出正確的尾實體t^,這個過程結合了隱式搜索和可控推理。
與其他方法相比,認知圖譜的使用具有兩個優勢:一是圖結構的數據更加靈活;二是搜索效率更高,因為傳統的嵌入方法完成一次查詢需要遍歷整個實體集合,而CogKR 模型依靠局部結構大大降低了時間復雜度,所以CogKR 可以更容易地擴展到大型知識圖譜上。在FKGC 的數據集上,CogKR 模型與Gmatching模型相比,MRR指標提高了5.0%,但是在長路徑的推理上,Gmatching 模型更占優勢,尤其是一些沒有路徑的答案,這與CogKR 模型結構模擬了推理系統的搜索與推理有關,導致路徑越長找到答案的概率就越小,在后續的研究中,可以將更多的信息融入到模型中,進而加強長路徑上的推理能力。
預訓練語言模型已經在自然語言處理的各個領域取得了優異的結果[75],研究者最近的工作是研究如何利用提示對下游任務進行微調,以更好地利用預訓練語言模型。提示包含兩部分:一是模板,它由自然語言組成用來提示模型的輸出;二是提示詞,它表示如何將模型輸出的詞匯轉換為每一個類別的分數。因此,在FKGC 任務中,如何結合知識圖譜的顯示知識和預訓練語言模型的隱式知識成為了一個問題。針對此問題,文獻[47]提出了一種知識協同微調模型(KnowCo-Tuning),該模型的核心是通過協同微調算法來學習最優的模板和標簽。具體過程如下:
首先基于知識圖譜的結構化知識為FKGC 任務生成模板τ:
其中,XS、XO分別是頭實體和尾實體。
其次使用一對多的映射函數M(yj)=={v1,v2,…,vk},v∈V來表示標簽的語義信息特點,其中v表示語言模型字典中的字或詞。
最后KnowCo-Tuning 模型的標簽概率組合為如下形式:
其中,h[MASK]是τ中[MASK]位置對應的特征向量,wM(y)是標簽詞匯對應的特征矩陣,兩者相乘最終得到匹配概率。
與其他FKGC模型相比,KnowCo-Tuning模型不僅是一種新穎的基于預訓練語言模型的微調范式,而且模型訓練過程簡單、有效,同時KnowCo-Tuning模型具有拓展到其他任務的能力。與常規的Fine-Tuning模型相比,KnowCo-Tuning模型能夠更好地利用模型中存儲的外部信息,這是因為其自身沒有引入新的網絡框架和其他參數并且將微調和預訓練統一進行。在FKGC 的實驗中,其性能優于傳統的TransE[13]、TransH[72]等模型。但是在模板τ中,頭尾實體被直接使用,由于實體在不同情況下,它的含義可能是不相同的,而通過實體的鄰域可以得到更多的實體信息,KnowCo-Tuning模型忽略了實體的鄰域信息。
對抗遷移學習指通過對抗性學習提取域的不變特征以完成遷移學習,一般從一個領域的多資源數據中學習特征,用于不同但相關的領域中,通常應用于少樣本領域[76]。受到對抗遷移學習的啟發,Zhang等人[48]在2020 年提出了wRAN 模型,模型核心是在特征遷移的過程中,通過選取無關樣本減少負遷移的影響。首先利用卷積神經網絡將三元組編碼成向量,其次利用對抗遷移學習框架區分不同關系的分布,最后為了識別不相關的樣本并降低它們的權重,該模型提出了一種關系門控機制成功解決負遷移問題。作為第一個將對抗遷移學習應用于FKGC 任務的wRAN 模型,不僅可以將FKGC 任務和關系提取任務相結合,而且在FKGC和關系提取的少樣本數據集上都超過了當時的模型。但是wRAN模型在識別不相關樣本時,會對語義相似樣本給予不正確的權重,這也影響了模型的最終結果,在未來的研究中,可以將注意力機制引入到模型中,與關系門控機制一起合理分配權重。
現如今,注意力機制已經被廣泛應用于各個領域中。Xie 等人在2019 年提出了一種基于注意力機制的模型(因為原文中并沒有給出模型名稱,所以下文皆用AMmodel代表此模型)[49],與FAAN 模型獲取關系嵌入信息相比,該模型直接利用注意力機制構建了一種新的匹配函數。首先將Gmatching 模型的1-shot匹配處理器升級成為少樣本匹配處理器;接著利用注意力機制對隱藏層狀態進行處理,這樣的操作為模型引入了更多的信息;最后集合所有少樣本信息得到相似度分數。與其他模型相比,新的匹配函數不僅可以獲取到更為豐富的關系表示,還在訓練的過程中減少了大量的參數。在基于Nell-One 的實驗中,該模型與Gmatching 相比,性能提高了0.03。但是由于該模型在獲取關系實體對的嵌入信息時,只是單純地將實體關系信息拼接,沒有考慮到鄰域中的噪音信息。
表3匯總了本節所提到的基于其他模型的FKGC方法,可以看出CogKR模型[46]、Know-CoTuning模型[47]、wRAN模型[48]、AMmodel模型[49]分別在搜索和推理效率、結合預訓練語言模型、降低不相關信息權重、減少參數和優化匹配函數等方面都發揮了各自的優勢,提高FKGC方法的效果。但是由于它們都來源于不同的理論方法,它們的局限性也互不相同,例如CogKR模型的理論源自推理模型,從數學角度分析,路徑越長推理出結果的概率就越小,因此CogKR 模型在長路徑的推理上效果不好;wRAN模型的理論源自對抗遷移學習,對于對抗網絡而言,語義相似但是字符不同的語句就是不相同的兩句話,這樣就會導致wRAN 模型初始在語義相似樣本上的效果不好。總體來說,這些模型的提出不僅推動了FKGC領域的進步,還豐富了FKGC 方法的研究,為后續的研究者提供了廣泛的思路。

表3 其他方法匯總Table 3 Summary of other methods
3 少樣本知識圖譜實驗比較
本章介紹了在少樣本知識圖譜補全任務中常使用的數據集,介紹了實驗中常用的評價指標,對上述模型的常用數據集、評價指標、模型特點和實驗結果進行了總結歸納。最后以NELL-One 和Wiki-One 數據集為例,展示了上述模型在少樣本知識圖譜補全任務上的實驗結果。
3.1 常用數據集介紹
隨著研究者對少樣本知識圖譜補全任務的探索,逐漸出現了一些針對少樣本知識圖譜補全任務的數據集,其中Xiong 等人構建的兩個數據集NELL-One和Wiki-One頻繁被用于少樣本知識圖譜補全任務。
NELL-One和Wiki-One分別源自NELL和Wikidata數據集。NELL數據集[2]是一個通過閱讀網絡持續收集結構化知識的數據集,而NELL-One數據集刪除了NELL中的反向關系并篩選出其中擁有少于500個大于50個的實體關系三元組。但是NELL-One數據集不能測試出模型在大規模KG 上運行的能力,同時,Xiong等人也希望有足夠多數據可以對此進行評估,因此他們用同樣的方法構建一個基于Wikidata[3]的FKGC數據集Wiki-One。從表4中可知,就實體和三元組的數量而言,Wiki-One數據集比NELL-One數據集都要大一個數量級。
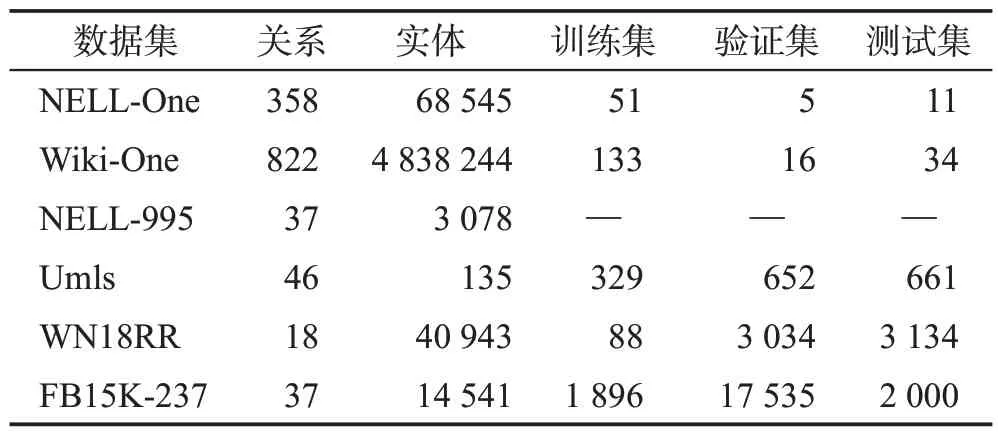
表4 少樣本知識圖譜補全常用數據集Table 4 Often-used datasets of FKGC
除了上述兩種經常被使用的數據集外,還有一些在FKGC 任務中使用過的數據集,其中包括具有多種關系類別的Umls[77]數據集、基于WordNet[78]的WN18RR 數據集、基于Freebase[79]的FB15K-237 數據集和基于NELL的NELL-995數據集。本文收集了出現在FKGC 任務中的數據集,總共6 個,每個數據集的實際數據見表4。
3.2 評價指標
目前針對少樣本知識圖譜補全算法,還沒有特定的評價指標,而是使用傳統的知識圖譜補全算法的評價指標MRR 以及Hits@n,其中MRR 是每個少樣本知識圖譜補全算法普遍使用的評價指標,此外,不同的少樣本知識圖譜補全算法也會采用不同的Hits@n指標。
(1)MRR
MRR指標代表在所有預測的三元組中正確實體在預測結果中的平均排名的倒數,該指標數值越大代表正確實體的排名越靠前,是評價少樣本知識圖譜補全算法的重要指標。
(2)Hits@n
Hits@n指標代表在所有預測的三元組中正確的缺失實體排名在前n名的概率,例如Hits@1 代表正確的缺失實體在所有預測結果中排名第一的概率。該指標的數值越大代表少樣本知識圖譜補全算法的性能越好,常見的指標參數為Hits@10、Hits@3 和Hits@1。
3.3 方法比較
本文將FKGC方法分為三類,并針對每種方法所述模型,從方法分類、發表年份、數據集、評價指標、模型優點、局限性和模型思路上進行比較,具體的比較結果見表5。
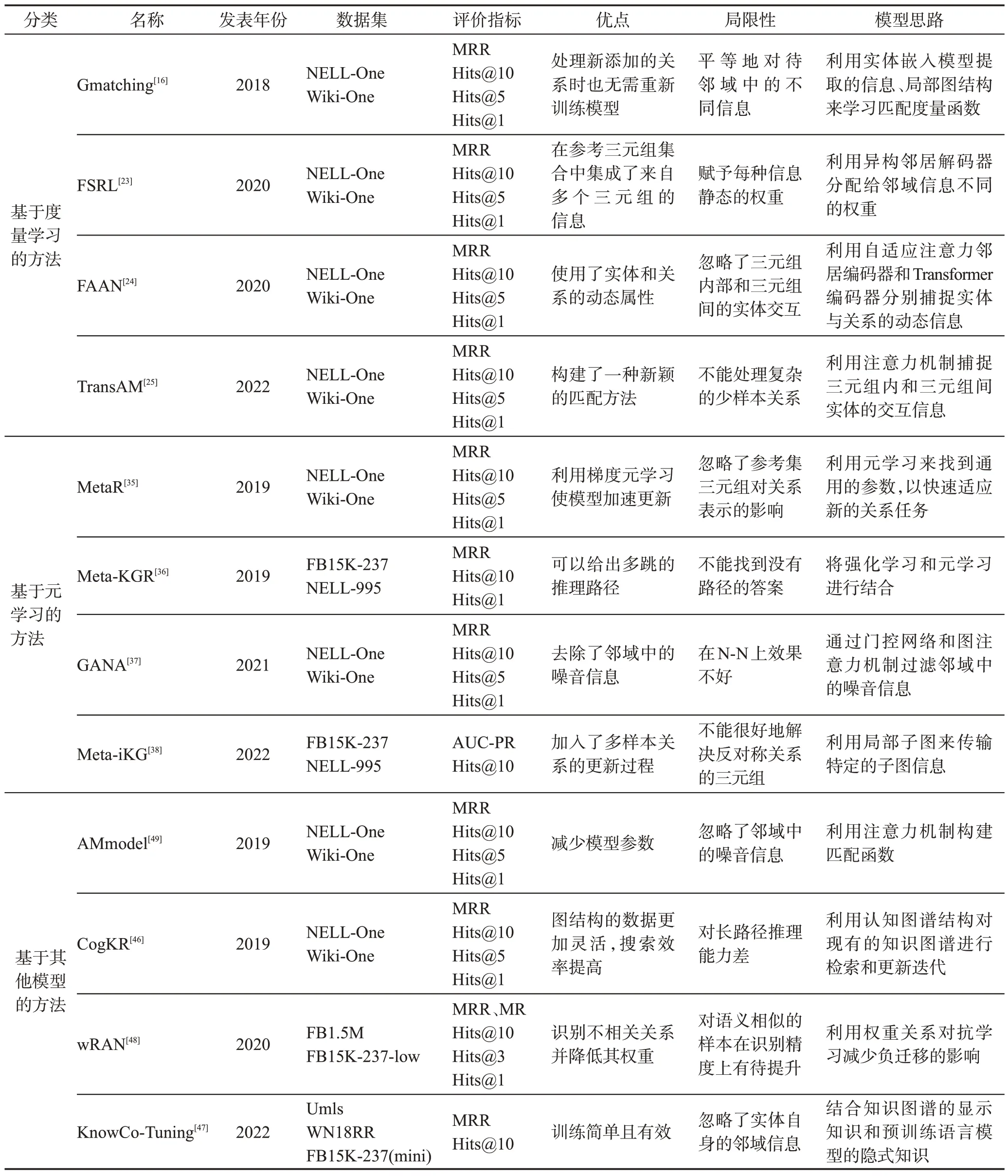
表5 少樣本知識圖譜補全模型比較Table 5 Comparison of FKGC models
從論文的發表時間可以看出,自從FKGC任務在2018 年被提出后,有越來越多的研究者開始探索如何完善FKGC 方法或者是提出新的方法來完成FKGC任務;從數據集的使用上可以看出,NELL-One和Wiki-One 數據集是FKGC 任務中的常用數據集,但是隨著時間的發展,一些新的數據集也被用于此任務,例如2022年KnowCo-Tuning[47]模型使用umls、WN18RR、FB15K-237(mini)數據集,這些數據集第一次出現在FKGC任務中;從評價指標的使用上可以看出,MRR、Hits@n已經成為FKGC方法通用的評價指標,但是一些模型也在使用新的評價指標,這些新出現的評價指標也可能成為以后的通用評價指標;從模型的局限性分析,可以看出早期模型的局限性問題已經被新的模型所解決,但是對于最新的模型來說,少樣本中復雜的關系、對稱與反對稱問題一直是一個難點。
3.4 實驗結果
為了加深對FKGC方法的理解,本節匯總了上述模型在NELL-One 和Wiki-One 數據集上的實驗結果。此外,為了與傳統的KGC方法進行比較,表中還加入了TransE 模型、TransH 模型、DisMult 模型等經典的傳統KGC模型結果。為了保證實驗結果的公平和客觀,本文只選用了這些模型中在NELL-One 和Wiki-One 數據集上的結果,并保證它們在訓練時的嵌入維度分別是100和50。
傳統KGC方法的最佳參數源自相關文獻[26,37];FSRL模型中LSTM層隱藏狀態維度為200和100,匹配網絡的遞歸步數為2;FAAN 模型中transformer 層數為3和4;GANA模型中BiLSTM層數為2;TransAM模型中transformer層數為3和4(其中傳統KGC方法實驗結果來自文獻[26]和文獻[37],Gmatching 模型、MetaR模型、FSRL模型、GANA模型結果來自文獻[37],其余模型結果均源自相關文獻。表6、表7 中加粗為最好結果,下劃線為次好結果,“—”代表此模型并沒有相關的實驗結果)。
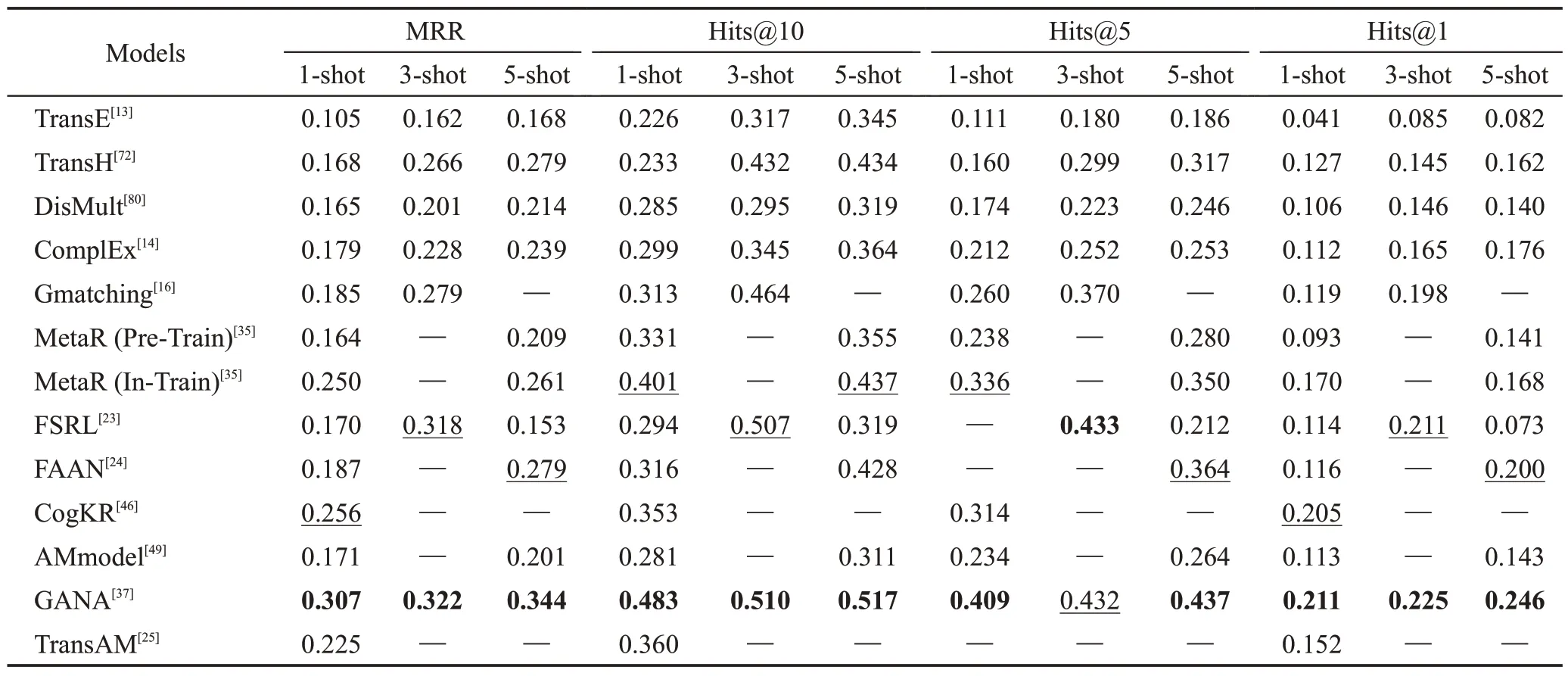
表6 在NELL-One數據集上FKGC實驗結果Table 6 Experimental results of FKGC on NELL-One dataset
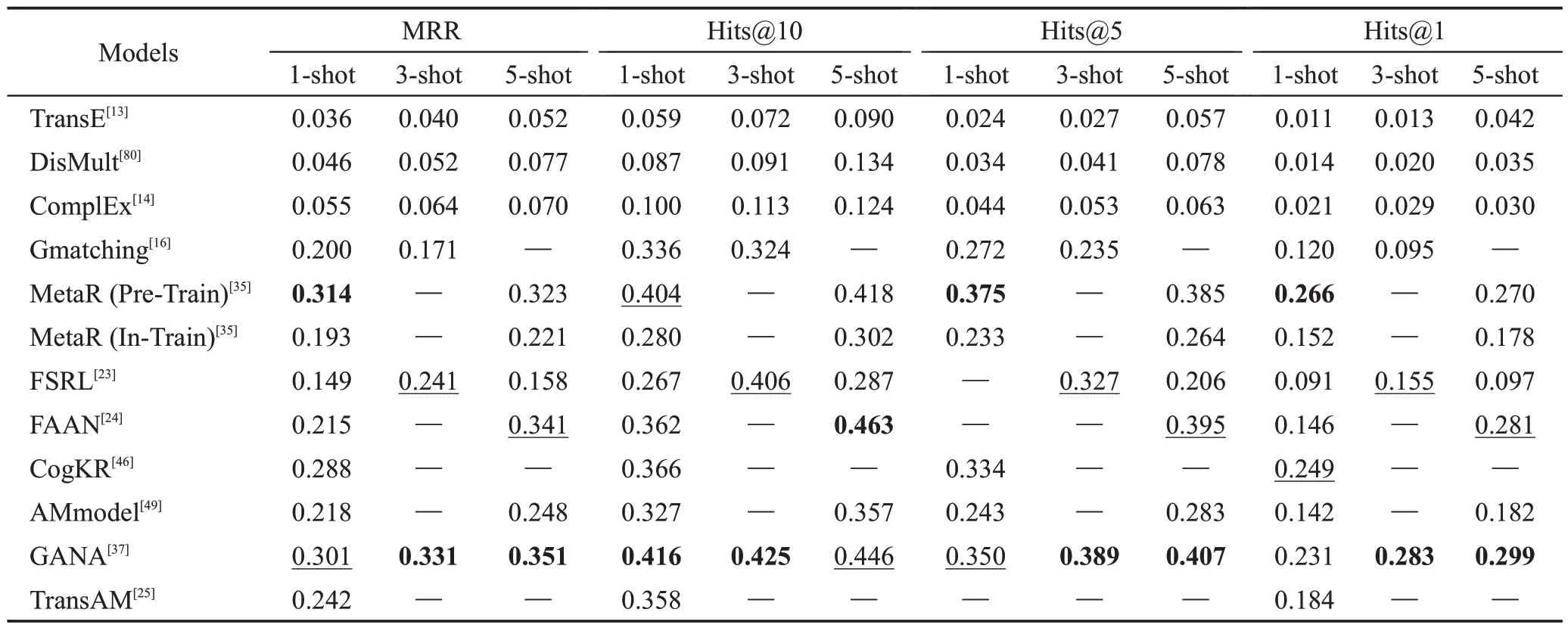
表7 在Wiki-One數據集上FKGC實驗結果Table 7 Experimental results of FKGC on Wiki-One dataset
從表6可以看出,在NELL-One數據集上,FKGC的方法在5-shot 的條件下,每個指標都優于傳統的KGC模型,在其他shot的條件下,大多數指標都優于傳統的KGC 模型,這證明了FKGC 方法在FKGC 任務上的優越性;在基于度量的方法中,1-shot 的條件下,TransAM的效果最好,其MRR指標優于其他的方法;整體而言,GANA 模型的效果最好,因為其大部分指標都是最好的結果,只有3-shot 條件下,Hits@5的結果是次好結果。
從表7 可以看出,在Wiki-One 數據集上,FKGC方法的指標沒有全部優于傳統的KGC 模型,這是因為Wiki-One 數據集比NELL-One 數據集大一個數量級,使得傳統的KGC 模型學習到了更多的信息。在基于其他模型的方法中,CogKR模型的效果在1-shot的條件下最好;在基于度量學習的方法中,TransAM模型的效果在1-shot 的條件下最好;整體而言,GANA模型的效果要優于其他FKGC模型。
4 研究與展望
本文對目前FKGC任務的研究現狀進行了闡述,對目前FKGC 領域中經典的模型和最新的成果進行了總結和歸納。本章討論了目前FKGC 研究的難點問題,并對少樣本知識圖譜補全技術的發展方向進行了展望。
基于各種方法的FKGC 任務雖然已經取得了一些成果,但是依然面臨著一些問題:
一是鄰域信息的使用和去噪。目前大部分的FKGC 方法都是集合實體的鄰域信息得到關系表示最終完成任務,這就導致在集合實體鄰域信息的過程中,很多方法只選用了實體的一階鄰居信息,而忽略了三元組周圍的高階鄰域信息。其次,在集合實體鄰域信息時,有些實體并沒有很多鄰居信息,但是伴隨編碼范圍的擴大,就需要引入很多無關的信息甚至是噪音信息,這就導致得到的實體鄰域信息質量不高甚至嚴重影響最終模型效果。目前研究者已經開始研究如何獲取和使用更高階的鄰域信息同時降低鄰域信息中的噪音,例如GANA 模型中使用門控網絡處理了一部分的噪音信息并取得了很好的效果。后續的研究者還需要探索更好的方法。
二是復雜的關系。對于三元組的關系而言,可分為1-1、1-N、N-1 以及N-N 的關系;對于模型而言,越復雜的關系越需要更多的樣本來學習,但是少樣本知識圖譜補全任務又無法提供大量的樣本,這就導致了復雜的關系對于所有FKGC 方法而言都是困難且充滿挑戰的。因此如何設計一種針對復雜關系的表示方法,讓模型在少量樣本下也能識別出復雜關系,仍是今后研究難點。
隨著FKGC技術的不斷發展,越來越多的研究者開始關注此任務,未來的發展方向可以從以下幾方面考慮:
一是少樣本時序知識圖譜的補全。現有的大多數知識圖譜都是靜態的圖結構[81],但在實際使用的過程中,知識圖譜的圖結構往往會伴隨著時間而發生變化,例如增加實體或者刪除實體之間的關系。這種結構變化雖然短時間內對全局影響不大,但在長期的改變下,為了靜態圖而研究的方法無法適用于動態的變化。文獻[82]提供了一種新穎的思路,利用自我注意力機制來編碼實體間的時序信息,通過一次性學習框架來完成少樣本時序知識圖譜的補全任務。除此之外,還有很多少樣本時序知識圖譜的補全方法[83-84]。因此如何對少樣本時序知識圖譜進行補全具有較大的顯示意義和應用價值,同時可能也是未來的研究方向之一。
二是知識圖譜嵌入方法的結合。知識圖譜嵌入的方法被廣泛應用在FKGC 的方法中,例如:Gmatching模型[16]中利用知識圖譜嵌入的各種方法作為預訓練得到實體和關系的嵌入信息;MetaR 模型[35]中利用TransE[13]的思想求出梯度元信息,并對最終的結果進行打分;GANA模型[25]在局部階段將TransH[72]與元學習結合建模復雜的關系信息。知識圖譜嵌入方法的質量對FKGC方法的效果具有顯著的影響[22],因此研究FKGC 中如何更好地結合知識圖譜嵌入方法具有重要的意義。
三是對零樣本方法的研究。零樣本學習[85-86]的目的在于預測出沒有在訓練數據中出現的數據。在現實生活中,知識圖譜每次更新都有可能加入新的數據,那么這些沒有被模型見過的數據,會影響到模型的實際效果[86-87],如文獻[88]利用GAN(generative adversarial networks)的思想,創建了一種生成類的零樣本學習框架,對不可見數據進行預測以完成零樣本知識圖譜補全任務。因此,對零樣本知識圖譜補全任務的關注和研究也具有一定的意義。此外,為了更加有效地評估零樣本知識圖譜補全方法,根據具體的任務定義,制作通用的數據集和評價指標也有著一定的必要性[89]。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
