深度學習應用于時序預測研究綜述
2023-06-07 08:30:04梁宏濤杜軍威
計算機與生活 2023年6期
關鍵詞:模型
梁宏濤,劉 碩,杜軍威,胡 強,于 旭
青島科技大學 信息科學技術學院,山東 青島266061
隨著社會中物聯網傳感器的廣泛接入,幾乎所有科學領域都在以不可估量的速度產生大量的時間序列數據。傳統參數模型和機器學習算法已難以高效準確地處理時間序列數據,因此采用深度學習算法從時間序列中挖掘有用信息已成為眾多學者關注的焦點。
分類聚類[1-4]、異常檢測[5-7]、事件預測[8-10]、時間序列預測[11-14]是時間序列數據的四個重點研究方向。已有的時序預測綜述文章,概括了經典的參數模型以及傳統機器學習算法的相關內容,但缺少對Transformer 類算法最新成果的介紹和在各行業常用數據集的實驗對比分析。余下內容將以深度學習的視角重點分析闡述有關時間序列預測方向的內容,并在多種GPU環境下對不同數據集采用多個評價指標進行實驗對比分析。基于深度學習的時間序列預測算法發展脈絡如圖1所示。
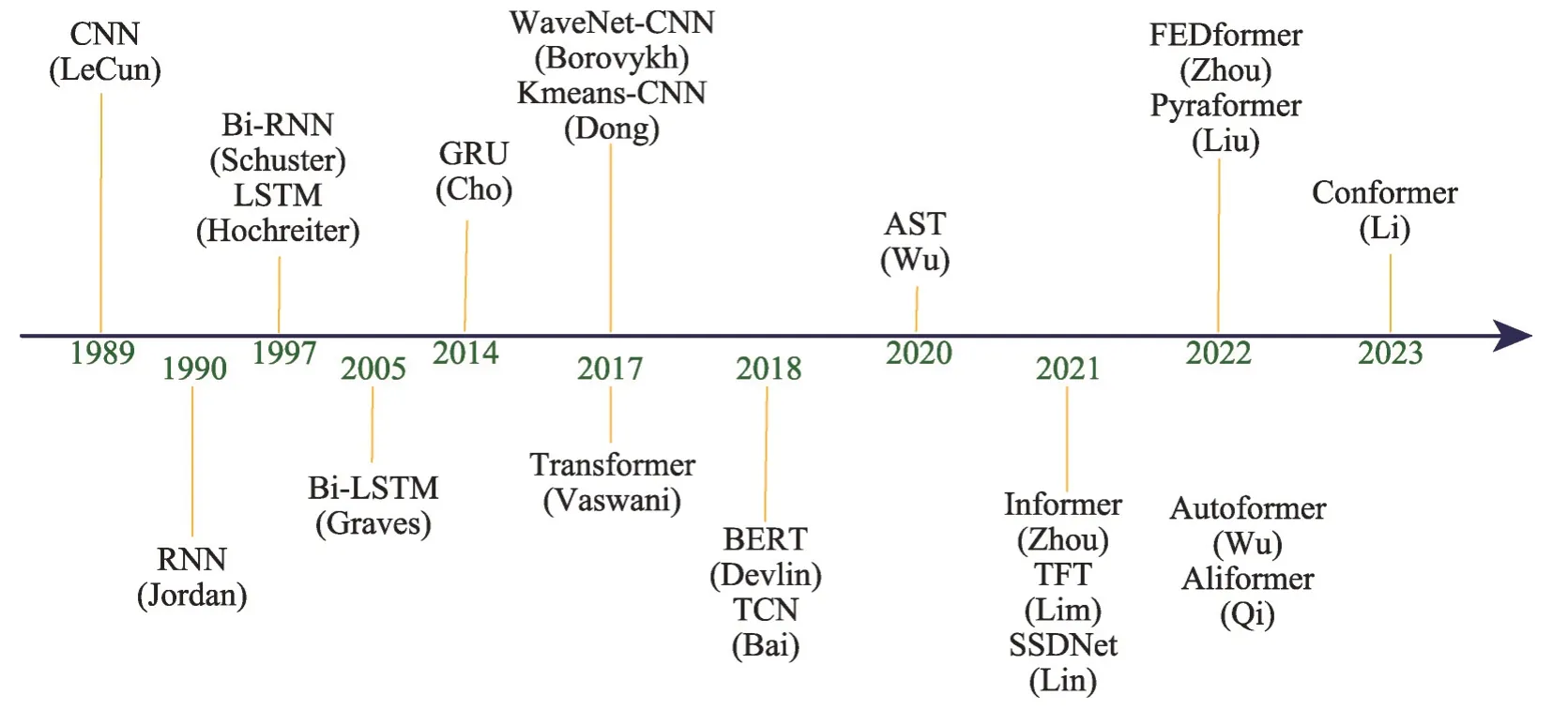
圖1 基于深度學習的時間序列預測算法時間表Fig. 1 Development history of time series prediction algorithms based on deep learning
時間序列預測是時間序列任務中最常見和最重要的應用,通過挖掘時間序列潛在規律,進行類推或者延展用于解決在現實生活中面臨的諸多問題,包括噪聲消除[15]、股票行情分析[16-17]、電力負荷預測[18]、交通路況預測[19-20]、流感疫情預警[21]等。
當時間序列預測任務提供的原始數據僅為目標數據的歷史數據時,為單變量時間序列預測,當提供的原始數據包含多種隨機變量時,為多變量時間序列預測。
時間序列預測任務根據所預測的時間跨度長短,可劃分為四類,具體如圖2所示。
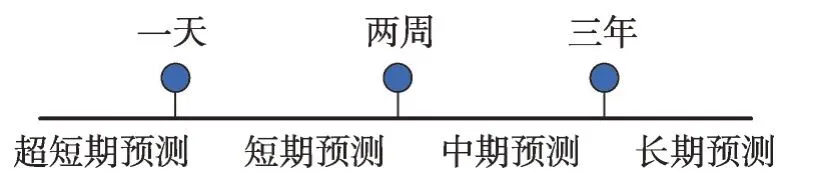
圖2 預測任務以時間跨度分類圖Fig. 2 Prediction tasks categorized by time span
1 時間序列數據的特性
時間序列預測是對前t-1 個時刻的歷史數據學習分析來估計出指定未來時間段的數據值。時間序列數據由于其各變量間固有的潛在聯系,常表現出一種或多種特性,為對時序預測有更全面的認識,本章將對這些常見特性進行詳細介紹。
(1)海量性:隨著物聯網傳感器設備的升級、測量頻率的提高、測量維度的增加,時間序列數據爆炸性增長,高維度的時間序列數據占據主流[22]。在數據集層面進行有效的預處理工作,是高質量完成時間序列預測任務的關鍵。
(2)趨勢性:當前時刻數據往往與前一段時刻數據有著密切的聯系,該特點暗示了時間序列數據受其他因素影響通常有一定的變化規律,時間序列可能在長時間里展現出一種平穩上升或平穩下降或保持水平的趨勢。
(3)周期性:時間序列中數據受外界因素影響,在長時間內呈現出起起落落的交替變化[23],例如,漲潮退潮,一周內潮水高度不符合趨勢性變化,并不是朝著某一方向的近似直線的平穩運動。
(4)波動性:隨著長時間的推移和外部多因素影響,時間序列的方差和均值也可能會發生系統的變化,在一定程度上影響時間序列預測的準確度。
(5)平穩性:時間序列數據個別為隨機變動,在不同時間上呈統計規律,在方差與均值上保持相對穩定。
(6)對稱性:若某段時間周期內,原始的時間序列和其反轉時間序列的距離控制在一定的閾值以內,曲線基本對齊,即認定該段時間序列具有對稱性[24],例如港口大型運輸車往復作業,起重機抬臂和降臂工作等。
各特性具體示例如圖3所示。
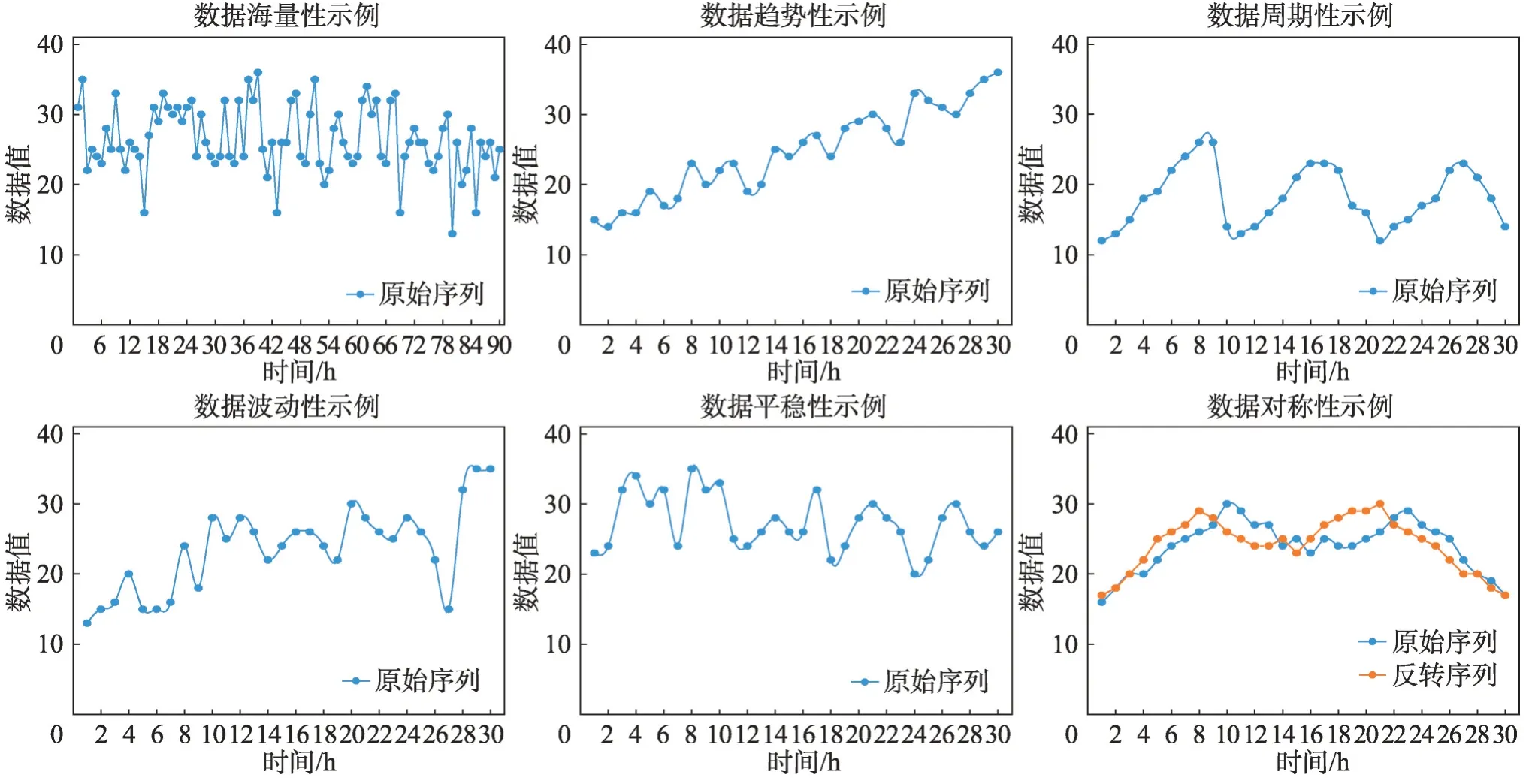
圖3 時間序列數據特性示例圖Fig. 3 Example graphs of time series data characteristics
2 時序預測數據集和評價指標
2.1 數據集
權威的數據集一直是衡量不同算法優劣的重要標準,數據集在使用前一般要進行子集選擇、噪音處理、缺失值補充和數據類型轉換等操作,來保證數據準確性、完整性和一致性。在解決實際任務時,對于一個給定的數據集,應當根據數據集的情況來選擇適當的模型算法進行處理,如果盲目選擇經典或最先進算法往往難以得到一個好的預測結果。研究人員可以根據數據集記錄條數的數量級和特征變量的多少以及任務要求的預測步長來選定合適的算法。
下文用于衡量各類模型處理不同任務優劣的權威數據集如下:(1)Electricity Load 是一個從電力行業收集的大型電力負荷數據集,其中包含了2012 至2014 年超過140 萬條記錄,包括目標值“負荷”、位置信息、天氣信息、濕度信息和用戶數量等多個變量。(2)COVID-19是一個根據國家發布新冠肺炎感染情況的小數據集,包括從2020 年1 月22 日到2020 年6 月27 日的確診病例、死亡病例和康復病例數據。(3)ETTh1是北京航空航天大學收集的中國某縣的電力變壓器溫度數據集,包括從2016年7月1日至2018年6 月26 日超過1.7 萬條數據記錄,以1 h 為間隔,每條記錄包括目標值“油溫”和6 個電力負荷特征。(4)Electricity 收集了321 個電力用戶的耗電量,包括從2012 年1 月1 日至2014 年12 月31 日超過2.6 萬條數據記錄,以1 h為間隔。(5)Weather包含近1 600個美國地區的當地氣候數據,從2010 年1 月1 日至2013年12 月31 日超過3.5 萬條數據記錄,以1 h 為間隔,每條記錄包括目標值“濕球”和11個氣候特征。
第3 章將根據上述數據集的規模和不同算法的性能特點進行實驗。
2.2 評價指標
誤差評價指標是衡量一個時間序列預測模型性能的重要方法,一般而言,評價指標計算出的誤差越大,模型預測的準確率越低,進而表示所建立的預測模型性能表現也就越差。目前常用的時間序列預測算法評價指標如下:
(1)平均絕對誤差(mean absolute error,MAE)[25],是通過計算每一個樣本的預測值和真實值的差的絕對值得出,具體計算公式為:
MAE 的取值范圍為[0,+∞],當模型預測完全準確時,所計算出的MAE為0,代表模型預測準確度達到100%,模型是完美模型。公式中m為樣本數量,yi為真實值,為模型的預測值,下同。
(2)均方誤差(mean square error,MSE)[26],是一個很實用的指標,通過計算每一個樣本的預測值與真實值的差的平方再取平均值得出,具體公式為:
MSE 的取值范圍同樣是[0,+∞],計算速度快。一直作為時序預測算法的主要評價指標之一。
(3)均方根誤差(root mean square error,RMSE)[27],是均方誤差進行開方得到,具體公式為:
RMSE其取值范圍依然是[0,+∞],最終計算結果容易受數據集中的極端值影響。
(4)平均絕對百分比誤差(mean absolute percentage error,MAPE)[28],是相對誤差度量值,避免了正誤差和負誤差相互抵消,具體公式為:
該評價指標在有足夠數據可用的情況下常被選用,無法處理真實值存在0 的數據集,因為會出現分母為0的問題,值越小,說明預測模型擬合效果越好。
(5)決定系數R-squared[29]又叫可決系數(coefficient of determination),也叫擬合優度,其計算結果即為模型預測的準確度,取值范圍為[0,1]。R2值越接近1,模型性能越好;該模型等于基準模型時R2=0,R-squared公式為:
上述五種常見評價指標中,由于MAE、MSE 和RMSE等都缺少確定的上限和下限,無法有效判斷當前預測模型的性能好壞,然而R-squared 的計算結果位于[0,1]區間,使得對預測模型的評價有了更加統一的標準。研究人員在針對預測任務時所提出的各類算法往往采用不同的評價指標來證明算法的先進性。例如,在循環神經網絡類算法蓬勃發展時期,研究人員采用的評價指標較為多元化,而到了采用Transformer 類算法處理時序預測任務時,則更多地使用MAE和MSE兩個評價指標。
3 基于深度學習的時間序列預測方法
最初預測任務數據量小,淺層神經網絡訓練速度快,但隨著數據量的增加和準確度要求的不斷提高,淺層神經網絡已經遠不能滿足任務需求。近年來,深度學習引起了各領域研究者的廣泛關注,深度學習方法在時間序列預測任務中與傳統算法相比表現出了更強勁的性能,得到了長遠發展和普遍應用。
深度神經網絡與淺層神經網絡相比有更好的線性和非線性特征提取能力,能夠挖掘出淺層神經網絡容易忽略的規律,最終滿足高精度的預測任務要求[30]。本章余下部分將介紹可用于解決時間序列預測問題的三大類深度學習模型。
3.1 卷積神經網絡
3.1.1 CNN
卷積神經網絡(convolutional neural networks,CNN)是一類以卷積和池化操作為核心的深層前饋神經網絡,在設計之初,其用于解決計算機視覺領域的圖片識別問題[31-32]。
卷積神經網絡做時間序列預測的原理是利用卷積核的能力,可以感受歷史數據中一段時間的變化情況,根據這段歷史數據的變化情況做出預測。池化操作可以保留關鍵信息,減少信息的冗余,卷積神經網絡可以有效減少以往算法提取特征的人力資源消耗,同時避免了人為誤差的產生。卷積神經網絡所需的樣本輸入量巨大,多用于預測具備空間特性的數據集,其網絡結構一般有五層,具體結構如圖4所示。
2017年,Li等[33]通過將時間序列的數值按一定規律排列轉化為圖像進行處理,使用CNN 模型將輸入數據進行聚類,再將天氣數據等外部影響因素考慮其中,來進行電力負荷預測。
3.1.2 WaveNet-CNN
2017 年,Borovykh 等[34]受WaveNet 這種語音序列生成模型的啟發,使用ReLU激活函數并采用參數化跳過連接,在結構上進行了簡化,改進了CNN 模型。該模型在金融分析任務中實現了高性能,證明卷積網絡不僅更簡單更容易訓練,同時在有噪聲的預測任務上也能有優異的表現。
3.1.3 Kmeans-CNN
隨著數據集規模越來越大,CNN 在處理大數據集中表現不佳。2017 年,Dong 等[35]選擇將可以學習更多有用特征的CNN 和分割數據的K均值聚類算法結合,通過將大數據集中的相似樣本聚類,分成多個小樣本來訓練,在百萬級大規模電力負荷數據集中表現良好。
3.1.4 TCN
2018年,Bai等[36]基于CNN提出了一種內存消耗更低而且可并行的時間卷積網絡架構(temporal convolutional networks,TCN)。TCN 引入因果卷積,保證了未來信息在訓練時不會被提前獲取到,其反向傳播路徑與時間方向不同,避免了梯度消失和梯度爆炸問題。為解決CNN在層數過多時導致的信息丟失問題,TCN 引入殘差連接使得信息在網絡間傳遞時可以跨層傳遞。
3.1.5 小結
卷積神經網絡類模型在樣本數量足夠的情況下可用于時間序列短期預測任務,上述算法實驗性能對比和總體分析如表1及表2所示。
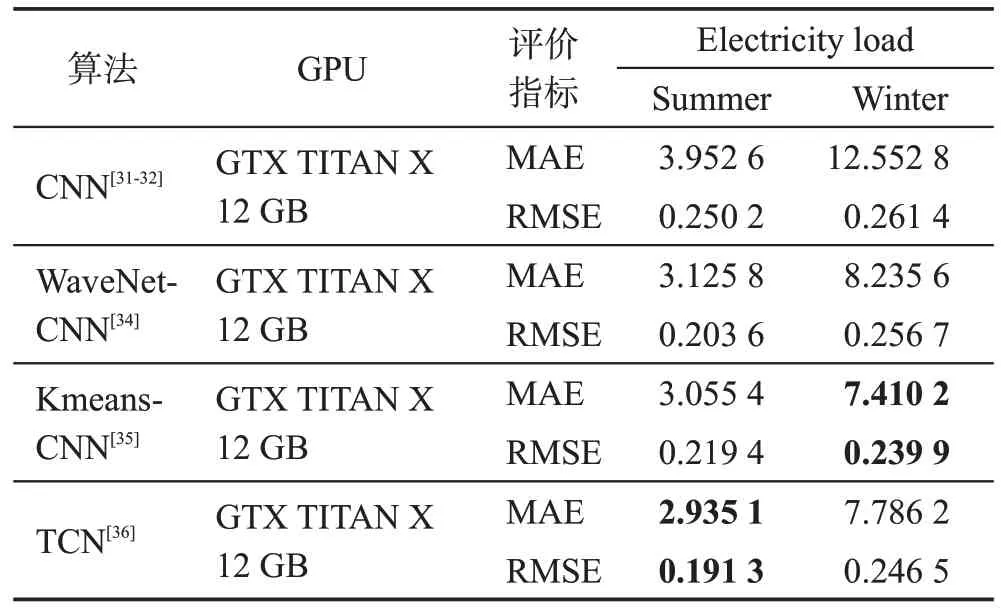
表1 卷積神經網絡類算法多變量預測性能對比Table 1 Comparison of multivariate prediction performance of convolutional neural network-like algorithms
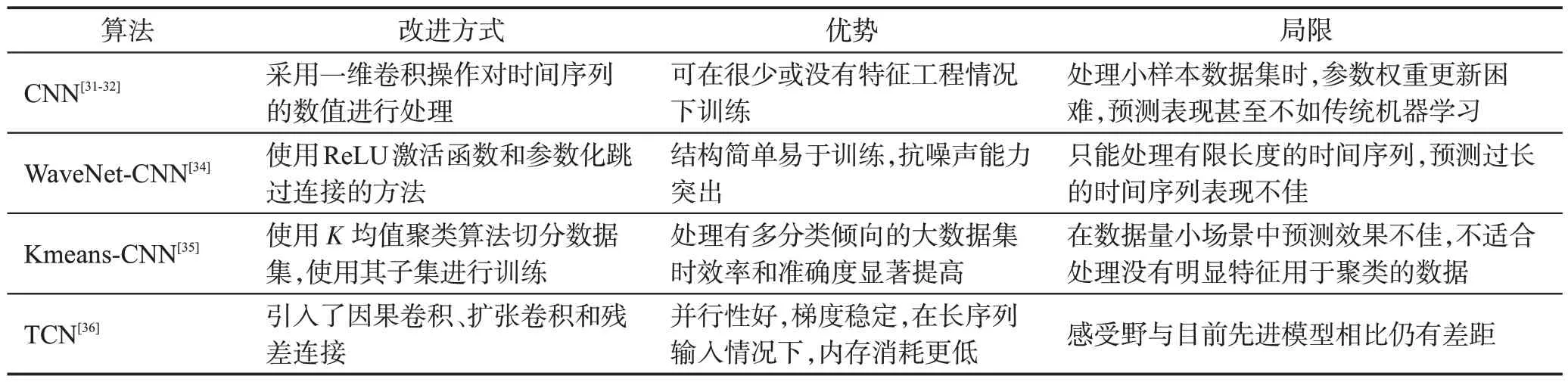
表2 卷積神經網絡類算法總體分析Table 2 Overall analysis of convolutional neural network-like algorithms
從表1中可以看出,模型在樣本量巨大的多變量數據集上處理短期預測任務時,Kmeans-CNN采用先聚類分類再由模型訓練的思路取得了比較理想的預測效果,后續也有不少研究人員在解決時序預測問題時進行類似處理。引入了擴展卷積和殘差連接等架構元素的TCN 能保有更長的有效歷史信息,同樣達到了不錯的預測效果,而且其網絡較為簡單清晰。
目前,CNN 的預測精度與循環神經網絡等其他網絡結構相比已不占優勢,難以單獨處理步長較長的時序預測問題,但常作為一個功能強大的模塊接入其他先進算法模型中用于預測任務。
3.2 循環神經網絡
3.2.1 RNN
循環神經網絡(recurrent neural networks,RNN)是由Jordan在1990年提出的用于學習時間維度特征的深度學習模型[37]。
RNN的各單元以長鏈的形式連接在一起按序列發展的方向進行遞歸,模型的輸入是序列數據,可用于處理自然語言處理的各種任務(例如文本情感分類、機器翻譯等)。RNN 同CNN 一樣,參數是共享的,因此在處理時間序列數據、語音數據時能體現出較強的學習能力,通過識別數據的順序特征并使用先前的模式來預測,具體結構如圖5所示。
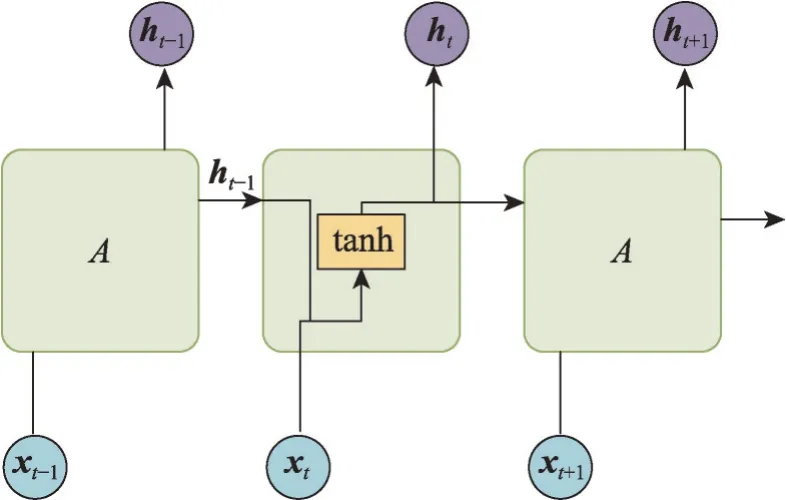
圖5 循環神經網絡結構示意圖Fig. 5 Schematic diagram of RNN structure
圖5中xt表示t時刻的輸入向量,ht表示t時刻的隱藏向量,可以看到傳統RNN 神經元會接受上一時刻的隱藏狀態ht-1和當前輸入xt。
使用RNN訓練容易出現很嚴重的梯度消失問題或者梯度爆炸問題。梯度消失問題主要是因為在神經網絡模型中位于最前面層的網絡權重無法及時進行有效的更新,訓練失敗;梯度爆炸問題是指由于迭代參數的改變幅度太過劇烈,學習過程不平衡。隨著數據長度的提升,該問題愈加明顯,導致RNN只能有效捕捉短期規律,即僅具有短期記憶。
1997年,Schuster等[38]將常規循環神經網絡RNN擴展到雙向循環神經網絡(bidirectional recurrent neural networks,Bi-RNN)。Bi-RNN 通過同時在前向和后向上訓練,不受限制地使用輸入信息,直到預設的未來幀,可同時獲得過去和未來的特征信息。在人工數據的回歸預測實驗中,Bi-RNN與RNN訓練時間大致相同并取得了更好的預測效果。
3.2.2 長短期記憶網絡
長短期記憶網絡(long short-term memory,LSTM)于1997 年被Hochreiter 提出,用于解決RNN 模型的諸多問題[39]。LSTM循環單元結構如圖6所示。
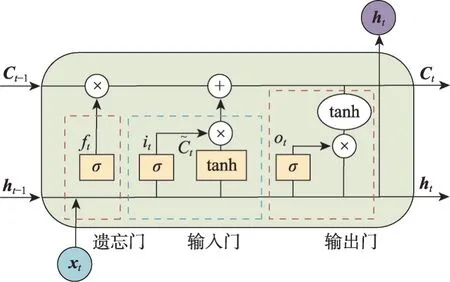
圖6 LSTM單元結構示意圖Fig. 6 Schematic diagram of LSTM cell structure
LSTM的神經元在RNN的基礎上還增加了一個cell 狀態Ct-1,與RNN 中h的作用相似,都是用來保存歷史狀態信息的。LSTM 采用三個門來選擇忘記和記住一些關鍵信息。
遺忘門和輸入門都作用于單元的內部狀態,分別控制遺忘多少前一個時間步內部狀態的信息和吸收多少當前時刻的輸入信息,若門的值為0,即不遺忘和完全不吸收,若門的值為1,即完全遺忘和全部吸收。輸出門在隱層ht發揮作用,主要決定該單元的內部狀態對系統整體狀態的影響多少[40]。
王鑫等[41]提出了一種基于LSTM 的單變量故障時間序列預測算法,應用于航空領域的飛機數據案例,對比多元線性回歸模型、支持向量回歸等多個模型,最終LSTM模型表現出更好的性能。
2005年,Graves等[42]提出的雙向長短期記憶網絡(bidirectional long short-term memory,Bi-LSTM)結構類似于Bi-RNN,其由兩個獨立的LSTM 拼接而成。Bi-LSTM 的模型設計初衷是克服LSTM 無法利用未來信息的缺點,使t時刻所獲得特征數據同時擁有過去和將來的信息[43]。由于Bi-LSTM 利用額外的上下文而不必記住以前的輸入,處理較長時間延遲的數據時表現出更強大的能力。經實驗表明,沒有時間延遲的LSTM幾乎返回同樣的結果,這代表著在部分時間序列數據中向前訓練和向后訓練兩個方向上的上下文同樣重要,Bi-LSTM 的特征提取能力明顯高于LSTM。
3.2.3 門控循環單元
門控循環單元(gated recurrent unit,GRU)是由Cho等[44]在2014年通過改進LSTM模型提出的,具體循環單元結構如圖7所示。
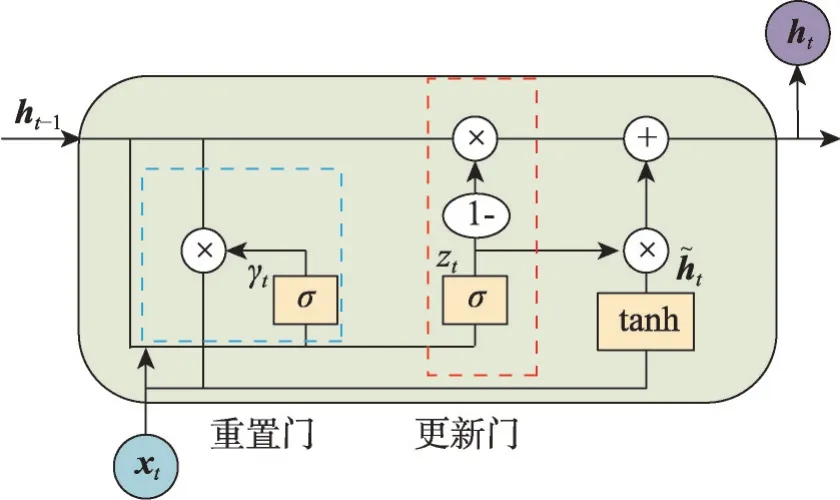
圖7 GRU單元結構示意圖Fig. 7 Schematic diagram of GRU cell structure
GRU相較于LSTM簡化了結構,圖7中的γt和zt分別表示GRU僅有的重置門和更新門。重置門決定著前一狀態的信息傳入候選狀態的比例。更新門是將LSTM的遺忘門和輸出門的功能組合在一起,用于控制前一狀態的信息ht-1有多少保留到新狀態ht中,GRU的門的計算方式和LSTM類似,因此參數比LSTM少得多,從而訓練時間更少,而且在多個數據集中的表現證明GRU有不亞于LSTM的準確度表現。
文獻[45]首次將GRU 應用于交通流量預測并與LSTM 模型作對比進行實驗,在MAE 評價指標下,GRU的表現比LSTM模型低5%左右。
對于電子商務中廣泛存在的促銷銷售預測任務,Qi 等[46]提出了一種基于GRU 的算法來明確建模目標產品與其替代產品之間的競爭關系。Xin等[47]提出的另一項工作將異構信息融合到修改后的GRU單元中,以了解促銷活動前的預售階段的狀態。
3.2.4 小結
RNN循環神經網絡類算法自提出就一直是解決時間序列預測任務的重要方法,常常作為一個模塊嵌入到其他算法中來獲得更好的預測效果,在2017年以前一直作為解決時間序列數據預測問題的主力模型,得到廣泛應用。主要循環神經網絡類算法實驗性能對比和總體分析如表3和表4所示。
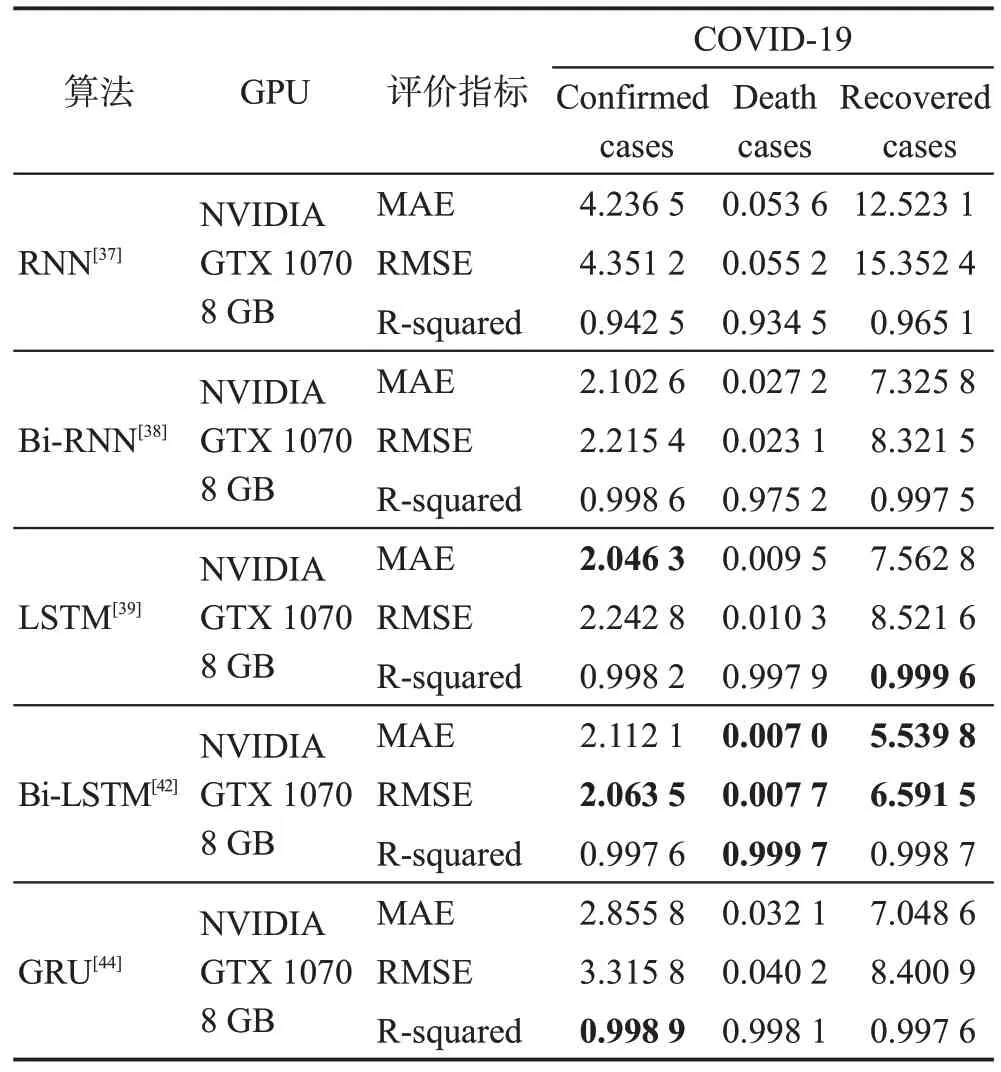
表3 循環神經網絡類算法單變量預測性能對比Table 3 Comparison of univariate prediction performance of recurrent neural network-like algorithms
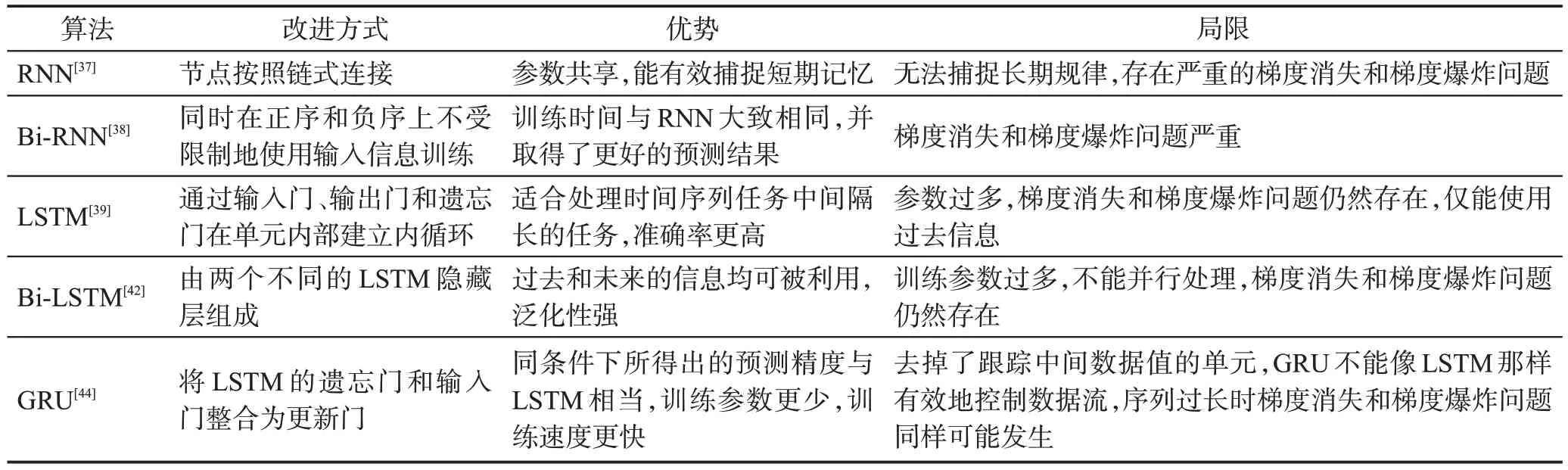
表4 循環神經網絡類算法總體分析Table 4 Overall analysis of recurrent neural network-like algorithms
從表3 可以看出,GRU 和LSTM 在性能上相當,但都受限于只能從一個方向上學習訓練,在預測精度上要低于可以從兩個方向上獲取信息的Bi-LSTM模型。Bi-LSTM在解決短期時序預測任務時的優勢包括所需的樣本數量少、擬合速度快、預測精度高,如今依然有眾多學者研究使用。
循環神經網絡類方法可以捕獲并利用長期和短期的時間依賴關系來進行預測,但在長序列時間序列預測任務中表現不好,并且RNN多為串行計算,導致訓練過程中對內存的消耗極大,而且梯度消失和梯度爆炸問題始終沒有得到徹底解決。
3.3 Transformer類模型
介紹Transformer模型之前先要介紹一下注意力機制,人類眼睛的視角廣闊,但局限于視覺資源,往往重點關注視線中的特定部分,注意力機制就是以此為靈感提出,重點關注數據中更有價值的部分[48-49]。
3.3.1 Transformer
Vaswani 等[50]提出了Transformer這種與以往的CNN 或者RNN 結構不同的新的深度學習框架。Transformer 所采用的自注意力機制所解決的情況是:神經網絡的輸入是很多大小不一的向量,不同時刻的向量往往存在著某種潛在聯系,實際訓練的時候無法充分捕捉輸入之間的潛在聯系而導致模型訓練結果較差。自注意力機制的輸入(Query,Key)計算公式為:
一個自注意力模塊接收n個輸入,然后返回n個輸出,其中的所有輸入都會彼此作用,挖掘出其中作用明顯的注意力點,這些相互作用的聚合和注意力分數即為模塊給出的輸出。Transformer是完全依賴注意力機制來表征模型的輸入和輸出之間的全局依賴關系,具體結構如圖8所示。
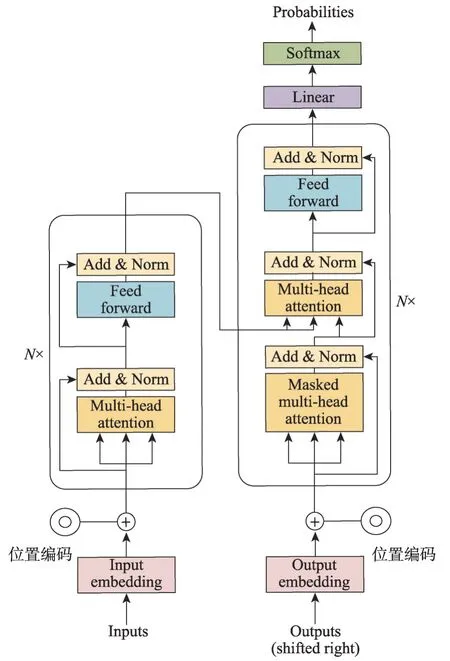
圖8 Transformer結構示意圖Fig. 8 Schematic diagram of Transformer structure
圖8中的N是一個超參數,表示編碼器和解碼器部分是由多個相同的層疊起來。
Transformer 的核心是自注意力模塊,它可以被視為一個完全連接層,其權重是基于輸入模式的成對相似性而動態生成的。其參數數量少,同條件下所需計算量更少,使其適合建模長期依賴關系[51]。
相較于RNN的模型,使用LSTM和GRU也不能避免梯度消失和梯度爆炸的問題:隨著網絡往后訓練,梯度越來越小,要走n-1 步才能到第n個詞,而Transformer的最長路徑僅為1,解決了長期困擾RNN的問題。Transformer捕捉長期依賴和彼此交互的突出能力對于時間序列建模任務有巨大吸引力,能在各種時間序列任務中表現出高性能[52]。
3.3.2 BERT
2018 年10 月,Google 的BERT(bidirectional encoder representation from transformers)模型[53]橫空出世,并橫掃自然語言處理領域11 項任務的最佳成績,隨后Transformer模型運用于各大人工智能領域。
2021 年,Jin 等[54]為克服交通流量預測所需道路天氣數據繁雜、通用性差和應用局限等缺點,提出了trafficBERT 這種適用于各種道路的模型。該模型通過多頭自注意力來代替預測任務常用的RNN來捕獲時間序列信息,還通過分解嵌入參數化來更有效地確定每個時間步之前和之后狀態之間的自相關性,只需要有關交通速度和一周內幾天的道路信息,不需要當前時刻相鄰道路的流量信息,應用局限性小。
3.3.3 AST
2020 年,Wu 等[55]應用生成對抗思想在Sparse Transformer[56]基礎上提出了對抗稀疏Transformer(adversarial sparse Transformer,AST)。
大多數點預測模型只能預測每個時間步的準確值,缺乏靈活性,難以捕捉數據的隨機性,在推理過程中常常被網絡自己的一步超前輸出代替,導致推理過程中的誤差累積,由于誤差累積,它們可能無法預測長時間范圍內的時間序列。大多數時間序列預測模型會優化特定目標,例如最小化似然損失函數或分位數損失函數,然而這種強制執行步級精度的精確損失函數無法處理時間序列中的真實隨機性,從而導致性能下降。
AST模型通過對抗訓練和編碼器-解碼器結構可以更好地表示時間序列,在序列級別以更高的保真度預測時間序列的多個未來步驟來緩解上述問題,并使用鑒別器來提高序列級別的預測性能。實驗表明,時間序列步驟之間的依賴關系具有一定的稀疏性,AST 采用的對抗訓練可以從全局角度改善時間序列預測,基于編碼器-解碼器的Transformer的性能優于僅采用自回歸解碼器的Transformer。
3.3.4 Informer
2021 年,北京航空航天大學的Zhou 等[57]在經典的Transformer 編碼器-解碼器結構的基礎上提出了Informer 模型來彌補Transformer 類深度學習模型在應用于長序列時間預測問題時的不足。在此之前,解決預測一個長序列的任務往往采用多次預測的方法,而Informer 可以一次給出想要的長序列結果,Informer具體結構如圖9所示。
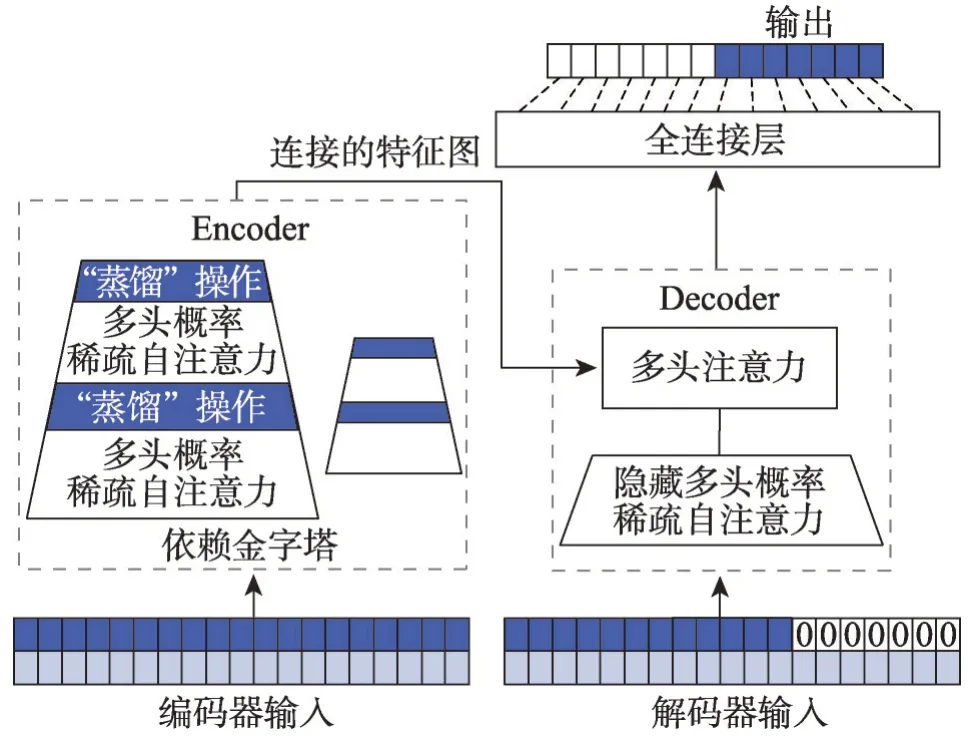
圖9 Informer結構示意圖Fig. 9 Schematic diagram of Informer structure
Informer具有三個顯著特點:(1)ProbSparse自注意力機制。在Informer的整體結構圖中,編碼器部分采用多頭稀疏自注意力替換了Transformer模型傳統的自注意力,可以有效處理較長的序列輸入。(2)自注意力提煉。藍色梯形部分是提取主導注意力的自注意力蒸餾部分,大大減少了網絡的層數,并且提高了層堆疊部分的魯棒性。(3)生成式解碼器。解碼器部分將預測序列及之后的數據置為0來進行遮擋,分析特征圖的注意力權重,隨后生成預測的結果,序列輸入只需要一個前向步驟,有效避免了誤差的累積。
Informer在自我注意模型中引入了稀疏偏差,以及Logsparse 掩碼,從而將傳統Transformer 模型的計算復雜度從O(L2)降低到O(LlogaL),它沒有顯式引入稀疏偏差,而是根據查詢和關鍵相似性選擇O(LlogaL)占主導地位的查詢,從而在計算復雜度上實現較好的改進。長序列的預測在極端天氣的預警和長期能源消耗規劃等實際應用中尤為重要,Informer能在長時間序列任務上表現出優越的性能。
3.3.5 TFT
2021 年,Lim 等[58]提出的TFT(temporal fusion transformers)設計了一個包含靜態協變量編碼器、門控特征選擇模塊和時間自注意力解碼器的多尺度預測模型。
已經提出的幾種深度學習方法,通常都是“黑盒”模型,沒有闡明它們如何使用實際場景中存在的全部輸入。TFT 編碼可以從協變量信息中選擇有用的信息來執行預測,它還保留了包含全局、時間依賴性和事件的可解釋性。
3.3.6 SSDNet
2021 年,Lin 等[59]提出的空間狀態空間分解神經網絡(state space decomposition neural network,SSDNet),將Transformer 深度學習架構和狀態空間模型(state space models,SSM)相結合,兼顧了深度學習的性能優勢和SSM的可解釋性。
SSDNet 采用Transformer 架構來學習時間模式并直接估計SSM的參數。為了便于解釋,使用固定形式的SSM來提供趨勢和周期性成分以及Transformer的注意力機制,以識別過去歷史的哪些部分對預測最重要。
評估SSDNet在太陽能、電力、交易所等五個數據集的時間序列預測任務上的性能,結果表明,SSDNet比最先進的深度學習模型DeepAR(deep autoregressive recurrent)[60]、DeepSSM(deep state space models)[61]、LogSparse Transformer、Informer 和N-BEATS(neural basis expansion analysis for interpretable time series forecasting)[62]以及統計模型SARIMAX(seasonal autoregressive integrated moving average with exogenous factor)[63]和Prophet[64]的預測準確度更高。
3.3.7 Autoformer
2021 年,Wu 等[65]提出的Autoformer 設計了一種簡單的周期性趨勢分解架構。Autoformer 繼承使用Transformer的編碼器-解碼器結構。通過Autoformer采用的獨特內部算子能夠將變量的總體變化趨勢與預測的隱藏變量分離,這種設計可以使模型在預測過程中交替分解和細化中間結果。其采用獨特的自相關機制,這種逐級機制實現了長度L系列的O(LlogaL)復雜度,并通過在子序列級別進行依賴關系發現和表示聚合來打破信息利用瓶頸,在多個公開數據集中表現出優異的性能。
3.3.8 Aliformer
電子商務中,產品的趨勢和周期性變化很大,促銷活動嚴重影響銷售導致預測難度較大,對算法要求更高。
2021 年,阿里巴巴的Qi 等[66]為解決電子商務中準確的時間序列銷售預測問題,提出基于雙向Transformer 的Aliformer,利用歷史信息、當前因素和未來知識來預測未來的數值。Aliformer設計了一個知識引導的自注意力層,使用已知知識的一致性來指導時序信息的傳輸,并且提出未來強調訓練策略,使模型更加注重對未來知識的利用。
對四個公共基準數據集(ETTh1、ETTm1、ECL2、Kaggle-M53)和一個大規模的天貓商品銷售數據集(TMS)進行的廣泛實驗表明,Aliformer 在銷售預測問題中可以比最先進的時間序列預測方法表現更好。
3.3.9 FEDformer
2022 年,Zhou 等[67]提出的FEDformer(frequency enhanced decomposed Transformer)設計了兩個注意模塊,分別用傅里葉變換[68]和小波變換[69]處理頻域中應用注意力操作。
FEDformer 將廣泛用于時間序列分析的周期性趨勢分解方法[70]融入到基于Transformer 的方法中,還將傅里葉分析與基于Transformer 的方法結合起來,沒有將Transformer應用于時域,而是將其應用于頻域,這有助于Transformer 更好地捕捉時間序列的全局特征。
圖10 中頻率增強塊(frequency enhanced block,FEB)和頻率增強注意力(frequency enhanced attention,FEA),二者用于在頻域中進行表示學習,周期趨勢分解塊用于從輸入數據中提取周期趨勢特征。
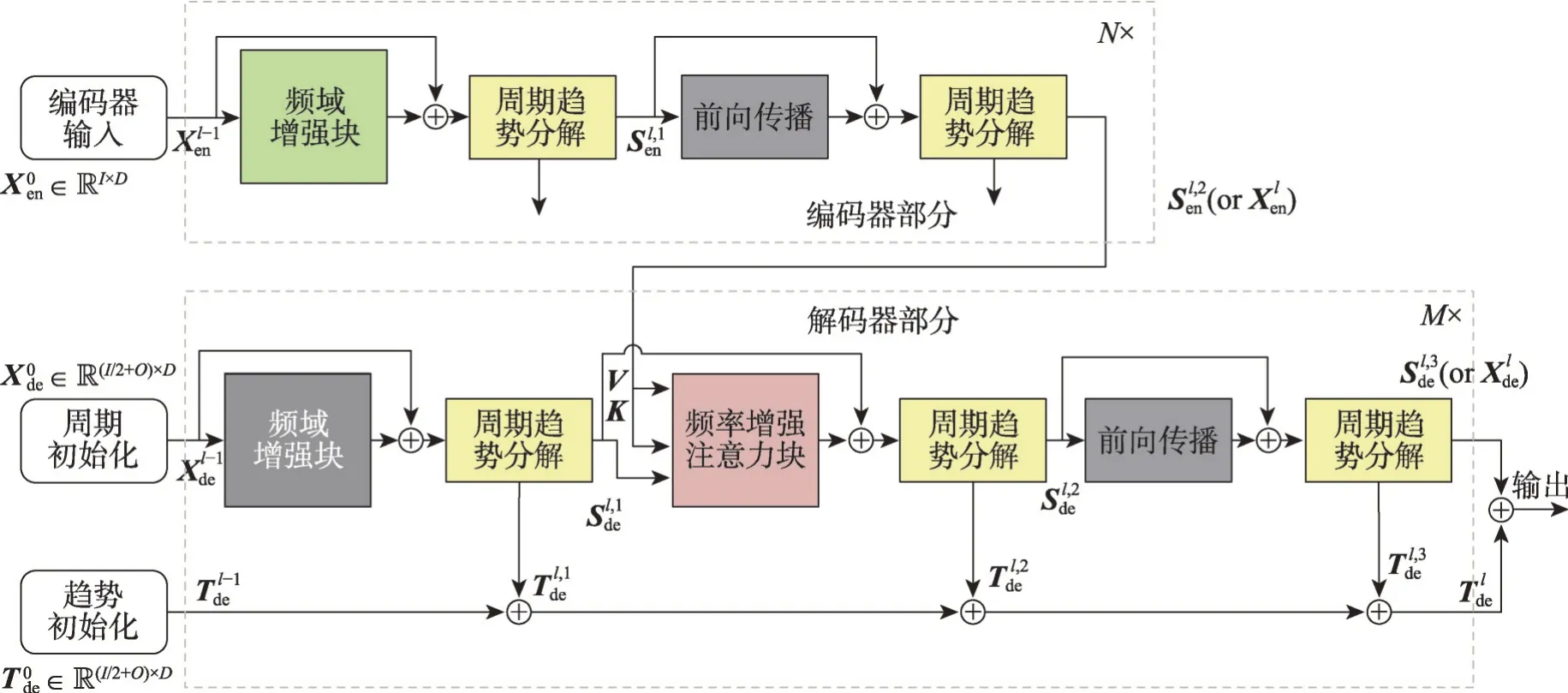
圖10 FEDformer結構示意圖Fig. 10 Schematic diagram of FEDformer structure
FEDformer通過傅里葉變換中的隨機模式部分實現了線性復雜度,部分相關算法復雜度分析如表5所示。
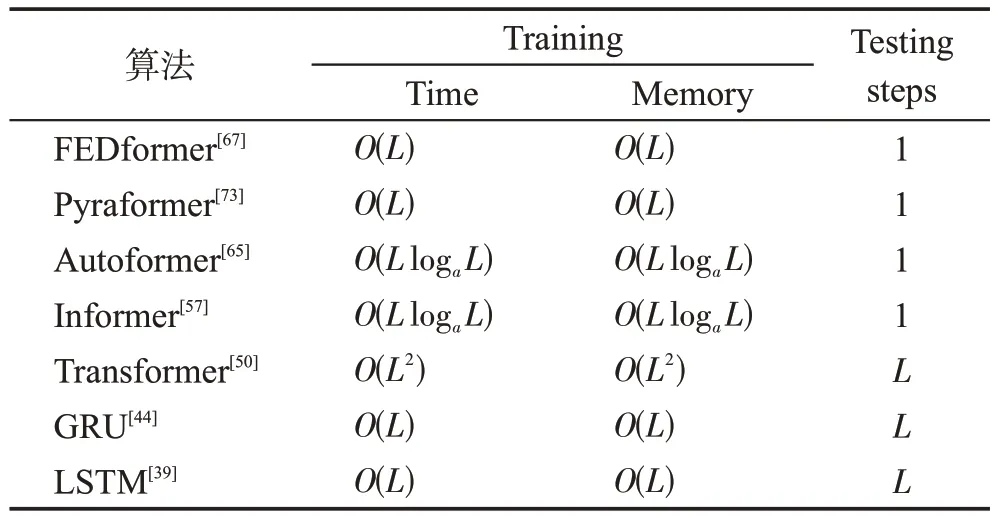
表5 不同預測模型的復雜度分析Table 5 Complexity analysis of different forecasting models
需要指出的是,自FEDformer 提出以來,時間序列數據在頻域或時頻域中的獨特屬性在時間序列預測領域中引起了廣泛的關注。
3.3.10 Pyraformer
2022年,Liu等[73]提出Pyraformer,這是一種基于金字塔注意力的新型模型,可以有效地描述短期和長期時間依賴關系,且時間和空間復雜度較低。
Pyraformer 首先利用更粗尺度構造模塊(coarser scale construction module,CSCM)構造多分辨率C叉樹,然后設計金字塔注意模塊以跨尺度和尺度內的方式傳遞消息,當序列長度L增加時,通過調整C和固定其他參數,Pyraformer可以達到理論O(L)復雜度和O(1) 最大信號遍歷路徑長度。實驗結果表明,Pyraformer 模型在單步和多步預測任務中都優于最先進的模型,而且計算時間和內存成本更少。
3.3.11 Conformer
2023年,Li等[74]為解決有明顯周期性的長序列預測任務的效率和穩定性問題,提出了一種針對多元長周期時序預測的Conformer模型。
該模型采用快速傅里葉變換對多元時間做處理,以此來提取多元變量的相關性特征,完成了多個變量之間關系的建模,以及月、周、天、小時等不同頻率下規律性的提取。為了提升長周期預測的運行效率,Conformer 采用了滑動窗口的方法,即每個位置只和附近一個窗口內的鄰居節點結算attention,犧牲了全局信息提取和復雜序列模型建模能力,從而將時間復雜度降低到O(L)。Conformer又提出了靜止和即時循環網絡模塊,使用GRU編碼輸入時間序列,來提取全局信息彌補滑動窗口方法造成的全局信息損失。
為解決高位多元時間序列聯合建模所形成的分布復雜的問題,Conformer采用標準化流操作,即用GRU產出的全局信息和解碼器信息進行標準化流的初始化,然后進行一系列映射得到目標分布后進行預測。
3.3.12 小結
Transformer 類算法如今廣泛用于人工智能領域的各項任務,在Transformer 基礎上構建模型可以打破以往算法的能力瓶頸,可以同時具備良好的捕捉短期和長期依賴的能力,有效解決長序列預測難題,并且可以并行處理。上述算法性能對比和總體分析如表6和表7所示。
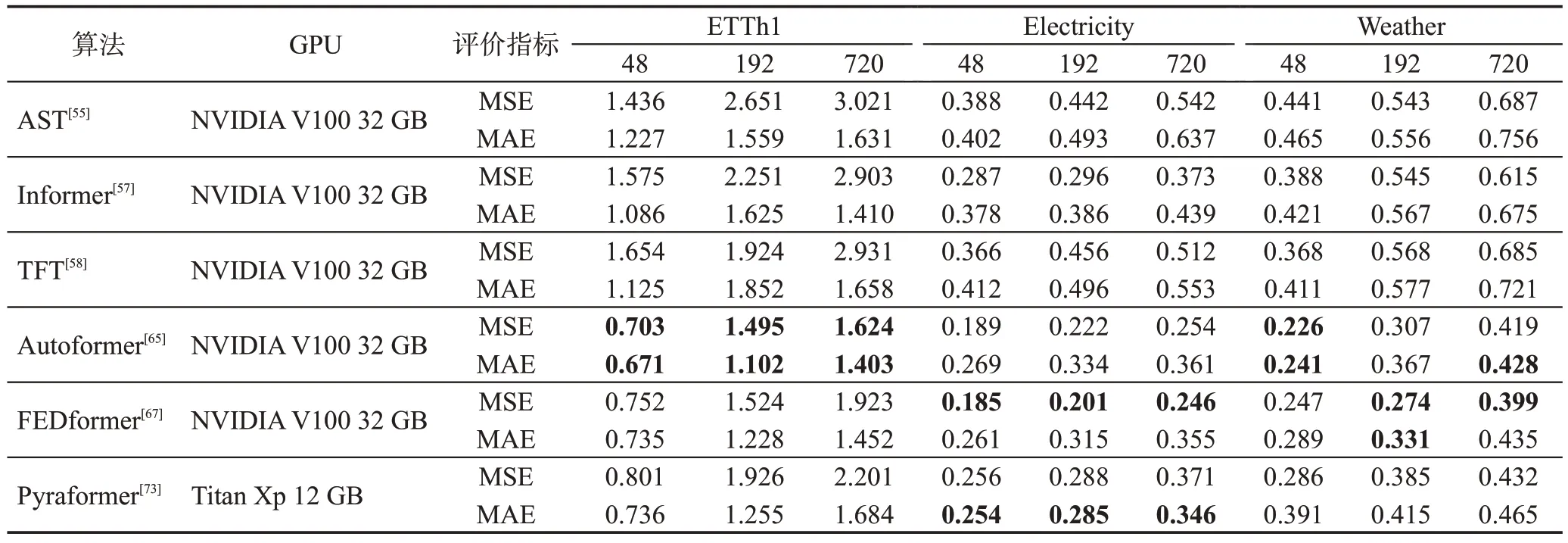
表6 Transformer類算法多變量預測性能對比Table 6 Comparison of multivariate prediction performance of Transformer-like algorithms

表7 Transformer類算法總體分析Table 7 Overall analysis of Transformer-like algorithms
從表6可以看出,Transformer類算法為避免過擬合需要大量數據來進行自身的訓練,在中期和長期預測任務上都有著不錯的性能表現。
目前,部分Transformer 類算法在保留編碼器-解碼器架構的同時,開始重新審視注意力機制的作用,因為在錯綜復雜的長序列預測任務中自注意力機制可能不可靠。Informer 等在降低復雜度的同時選擇犧牲了一部分的有效信息,Conformer 使用局部注意力與全局的GRU進行功能互補。
Pyraformer 在相對較低的配置下依然表現出不錯的性能,一定程度上緩解了Transformer 類算法設備要求高的問題,適合在欠發達地區普及使用。
4 總結與展望
文章在對時間序列數據相關理論、常用數據集和算法評價指標簡單介紹后,系統總結了基于深度學習的時間序列預測算法,其中以基于Transformer的模型為主,深入分析了Transformer 類算法的網絡架構優缺點,在注意力機制被提出以來,時間序列預測任務發展進入快車道,取得了令人矚目的成果。下面列出了時間序列預測領域的重點問題和進一步的研究方向,以促進時間序列預測算法的研究和完善。
(1)采用隨機自然啟發優化算法優化深度學習模型的多個超參數。深度學習算法愈發復雜,需要處理的超參數越來越多,超參數的選擇往往決定著算法能不能突破局部最優陷阱達到全局最優。隨機自然啟發優化算法靈感來自群體智能的各種現象、動物行為、物理定律以及進化定律。優化算法首先基于問題的約束隨機生成一定數量的可解,然后利用算法的各階段重復尋找全局最優解,在限制范圍內尋找最優的超參數以提升模型預測能力。因此,采用隨機自然啟發優化算法用于模型最優超參數尋找,將成為未來研究熱點之一。
(2)研究適合時間間隔不規則的小數據集的網絡架構。現有Transformer模型架構復雜,參數多,在周期性好的數據集上表現出優越的性能,但在數據量小、時間間隔不規則的數據集中表現不理想。Transformer類模型為在小數據上的過擬合問題值得進一步思考和解決。處理時間間隔不規則的數據集時,在模型架構中引入重采樣、插值、濾波或其他方法是處理時間序列數據和任務特征的新思路,會是未來一個新的研究方向。
(3)引入圖神經網絡(graph neural network,GNN)用于多變量時序預測建模。由于多變量時序預測任務的潛在變量相關性十分復雜,且在現實世界中的數據相關性是變化的,導致準確多變量預測具有挑戰性。最近不少學者采用時間多項式圖神經網絡將動態變量相關性表示為動態矩陣多項式,可以更好地理解時空動態和潛在的偶然性,在短期和長期多變量時序預測上都達到了先進的水平。因此GNN對多變量時序預測的強大建模能力值得進一步研究。
(4)研究同時支持精確形狀和時間動態的可微損失函數作為評價指標。在時間序列預測領域中已經使用了許多測量度量,并且基于歐氏距離的點誤差損失函數,例如MSE,被廣泛用于處理時間序列數據,但是其逐點映射,對形狀和時間延后失真不具有不變性。損失函數不僅要最小化預測和目標時間序列之間的差距,還應該考慮整個輸出序列和基本事實之間的相關性,從而幫助模型生成更及時、更穩健和更準確的預測,而不是僅僅逐點優化模型。如果損失函數能在曲線形狀和時間感知上對模型進行評價能更有利于訓練出高效準確的時間序列預測模型。
5 結束語
數據維度擴張、數據量級別增大、應用場景需求變換依舊給時間序列預測任務帶來巨大的挑戰。基于深度學習的時間序列預測算法,目前看來具有一定的性能優勢,但仍需要進一步的提升和完善。本文以時序數據特性、常用數據集和評價指標為引,以基于深度學習時序預測算法發展時間線為主線,將卷積神經網絡類算法、循環神經網絡類算法和Transformer 類算法進行性能分析和優缺點綜述,最后對深度學習應用于時間序列預測算法的發展趨勢進行了總結與展望。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
