雙感知門控交互的多任務推薦模型
2023-06-07 08:30:38陳育康
計算機與生活 2023年6期
林 建,吳 云,陳育康
貴州大學 計算機科學與技術學院,貴陽550025
+通信作者E-mail:wuyun_v@126.com
多任務學習(multi-task learning,MTL)[1]已成功地應用于許多推薦應用場景中。例如,在微視頻的多任務推薦中,需要同時優化微視頻的點贊、轉發、關注和讀評論等多目標任務。然而,像微視頻這種的多任務推薦問題中,多任務之間復雜的相關性,使模型難以同時學習到每個任務的最優。在之前大多數的工作中,如多門混合專家(multi-gate mixture of experts,MMOE)[2]在硬參數[3]的基礎上考慮使用門控來學習不同任務的參數,一定程度上解決了任務之間的沖突。MTL 模型往往會出現性能負遷移的問題。在PLE(progressive layered extraction)[4]中指出,一個任務的性能通常會通過降低其他一些任務的性能而得到提高,PLE將學習參數分離成共享和專有的方式,通過參數共享和專有參數學習到多任務中的共性和差異性。盡管這些經典的模型在多任務的表現中取得了較好的結果,然而過去的工作中沒有探索底層特征學習的方式,另外多任務之間的參數經過門控網絡后每個任務的參數是獨立的,沒有考慮到任務之間的學習參數可以互補。為了進一步有效解決多任務負遷移的問題,本文提出了一種雙感知門控交互的多任務推薦模型(multi-task recommendation model of dual perception gated interaction,DPGIMTRM)。DPGI-MTRM模型具有多個任務共享的組件和任務特定的組件,主要包括雙感知專家層、門控層、交互層、輸出層。雙感知專家層對輸入特征學習不同層級的表示,從元素級和向量級的雙感知方面提取更豐富的特征隱含表示。同時通過門控層來選擇不同任務學習到的共享參數和特定任務參數。然后任務門控的輸出經過交互層之后,提取多任務之間復雜的相關性。另外,在多任務優化中一個重要的問題就是多目標損失函數的優化。傳統的解決方法采用手動設置不同任務的權重,這種靠經驗去調節的參數不具有泛化性,難以解決不同的多任務的優化問題。本文使用梯度歸一化的多目標函數優化方法,將不同任務類型、不同尺度的損失統一,使多個目標的優化較一致地收斂。
本文主要的貢獻如下:(1)針對輸入特征學習的方式,設計了雙感知專家層提取更豐富的特征表達;(2)創造性地在特定任務門控網絡的基礎上設計了交互層,使特定任務得到更深層次的語義信息,利用多任務之間復雜的相關性來學習參數;(3)使用一種梯度歸一化的多目標優化方法,將多個目標損失統一到同一尺度,使多個目標的優化較一致地收斂。
1 相關工作
近年來,深度神經網絡(deep neural network,DNN)[5-7]模型已經成功地應用于許多現實大規模應用中,然而這些模型只能建立單個目標任務,面對多任務問題時需要建立多個模型。如推薦系統[8-9],這種推薦系統通常需要同時優化多個目標,往往只能對多個目標單獨建立模型。例如,當向用戶推薦觀看微視頻時,可能希望用戶不僅瀏覽點擊后點贊、關注,還希望用戶瀏覽點擊其他微視頻,甚至對微視頻進行讀評論和轉發。在同一個樣本空間中,傳統的方法創建了多個模型預測多個任務。這在大規模的推薦場景中是一項巨大的工作,在實際生產部署中也是耗費大量成本的。事實上,許多大規模的推薦系統已經采用了DNN模型的多任務學習。
推薦系統(recommender systems,RS)[10]需要結合各種用戶反饋,以建模用戶的興趣,并最大限度地提高用戶的參與度和滿意度。然而,由于問題的高維性,用戶滿意度通常很難通過學習算法直接解決。同時,用戶滿意度和參與度有許多可以直接學習的主要因素,例如在微視頻中,點擊、完成、分享、點贊和評論等的可能性。因此,在RS中應用MTL來同時建模用戶滿意度或參與的多個方面的趨勢越來越大。實際上,MTL已經是主要行業應用程序[11-13]的主流方法。文獻[11-12]中的工作都使用了矩陣分解與序列學習相結合的聯合訓練方式構建點擊率預測的多任務推薦模型,文獻[13]采用MMOE 模型思想應用在視頻的多任務推薦中。
硬參數共享[3],如圖1(a)是最基本和最常用的MTL 結構,但任務之間直接共享參數,由于任務沖突,可能會發生負轉移。為了處理任務沖突,交叉縫合網絡[14]及閘網[2]兩者都提出學習線性組合的權重,以有選擇性地融合來自不同任務的表示。圖1(b)針對不同的任務定義了特定任務的學習參數,同時保留共享的參數,但依然存在任務沖突的問題。圖1(c)MMOE針對每個特定任務增加了一個門控網絡,特定任務的門控對專家系統[15]進行選擇,一定程度上解決了任務沖突,但模型的底層參數都是共享的,學習不到多任務的差異性,往往存在負遷移的問題。圖1(d)的PLE 模型采用具有門結構的漸進路由機制,基于輸入融合知識,實現了不同輸入的自適應組合,然而PLE 模型忽略了任務之間帶來的影響。盡管這些模型在解決推薦中的多任務問題提供了范式,但依然存在一些問題。首先,在底層參數學習時只得到單一的特征表達。另外,這些模型在多任務的復雜相關性上沒有進行建模。本文提出了雙感知專家層對特征提取得到兩個層級的特征表達,同時設計門控交互層使得模型學習到多任務之間復雜的相關性。
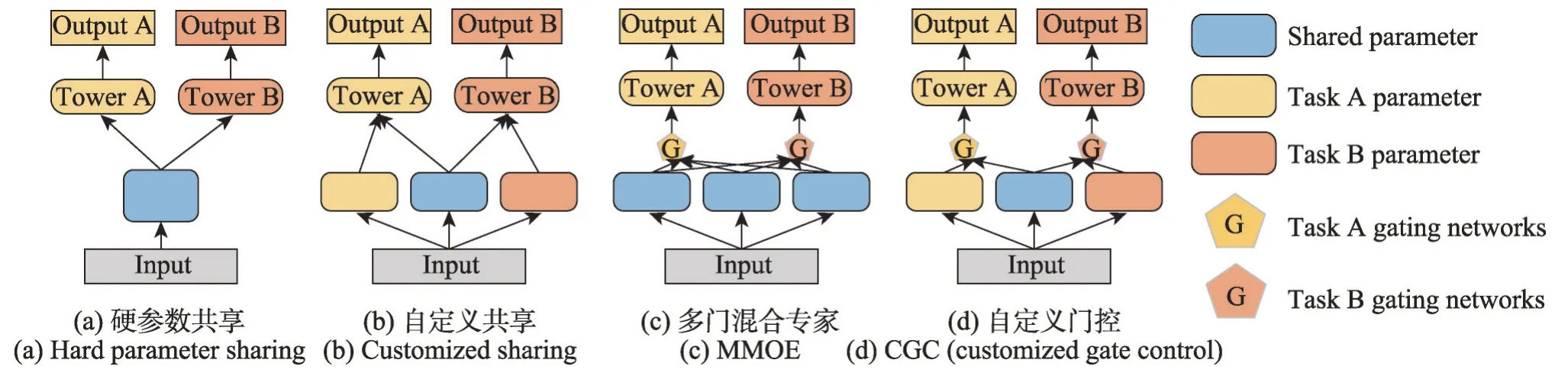
圖1 經典多任務學習模型的網絡結構Fig. 1 Network structure of classic multi-task learning model
在共享參數和分離參數的模型結構中,每個任務的收斂程度不一致,使用簡單的各個任務的損失總和作為優化目標不能提升多個任務的準確度。文獻[16]提出了一種有原則的方法,結合多個損失函數,以同時學習多個目標使用同方差不確定性,將同方差不確定性解釋為任務相關的權重,推導出一個有原則的多任務損失函數,該函數可以學習平衡各種回歸和分類損失。文獻[17]引入了一種隨機多梯度下降方法來解決這個問題,通過梯度歸一化,可以將不同尺度的目標組合成一個單一連貫的框架。
2 本文方法
2.1 問題定義
為了便于后續形式化描述,在此給出了一些會用到的符號。本文用X表示輸入的特征向量,用Ek和Es分別表示任務專家系統和共享專家系統的輸出,用表示多任務交互的輸出,任務門控輸出和共享專家門控輸出分別用Gk和Gs表示,任務塔網絡的輸出用tk表示。本文的目標是構建一個多任務預測模型,yk表示每個特定任務的輸出表示。
2.2 模型描述
多任務問題中受不同任務間的相關性的影響,多任務模型的效果往往不如對任務單獨建立模型的效果好。現有的方法雖然將多任務的參數分離為共享參數和專有參數一定程度上解決了任務沖突和負遷移的問題,但是模型并沒有考慮任務之間復雜的相關性,忽略了任務之間的聯系。另外,對多任務模型中的門控輸出沒有考慮來自底層特征的輸入影響。基于以上不足之處,本文提出了DPGI-MTRM模型。該模型考慮了底層輸入特征對多任務的影響,在底層參數的學習中設計了雙感知專家層(dual perception expert layer,DPE-Layer),從元素級和向量級對特征進行提取。同時,在門控網絡的基礎上,創新性地提出了門控交互層(gating interaction layer,GILayer),交互層將多個任務的門控輸出進行元素相乘得到任務之間的交互相關值。另外,為了減少其他任務帶來的沖突,通過殘差的方式加上當前特定任務輸出的值,最終得到特定任務的輸出表示。在模型訓練時,采用了梯度歸一化多目標優化的方法對模型的參數進行優化,能夠將不同尺度的梯度值歸一化到統一尺度,減小了多目標中損失值差異較大帶來的模型收斂問題。
DPGI-MTRM 模型結構如圖2 所示,模型由DPGI 模塊和Outputs 輸出層構成,其中DPGI 模塊包含雙感知專家層(DPE-Layer)和門控交互層(GILayer),輸出層對應不同任務的多層感知機輸出預測模型。
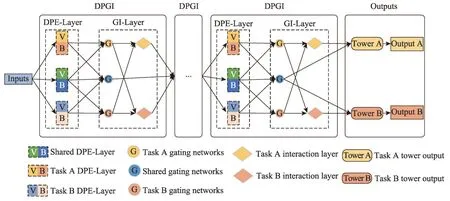
圖2 DPGI-MTRM模型Fig. 2 DPGI-MTRM model
2.3 雙感知專家層
經典的多任務模型的底層參數包含共享參數和專有參數,門控模塊利用這種專有和共享的參數來學習特定任務的輸出,直接利用這種專家模塊輸出會導致底層參數對任務的噪音干擾。多任務之間的不確定性關系往往很難捕獲,模型學習不到有益的參數就會帶來負面的影響。IFMs(input-aware factorization machine for sparse prediction)[18]中指出特征的多層級表達可以提升推薦性能,根據不同的輸入實例自適應地學習給定特征的靈活表示,將不同層級的輸入因素重加權原始特征表示。多層級的特征表達從多方面學習特征的隱含表示,比單一的特征表達語義更加豐富。為了更好地使用共享參數和專有參數,在專家模塊學習參數時,受IFMs工作的啟發設計了雙感知專家層。雙感知專家層主要的作用是從特征的元素級和向量級兩個層面得到多層級表達(多層級是元素級和向量級的統稱),得到同一特征的不同表達形式。首先在特征向量級方面,根據Google 2017 年提出的注意力機制[19],特征向量計算過程如圖3中Vector Wise Part所示,特征向量輸出的自注意力值形式化定義如式(1)所示:
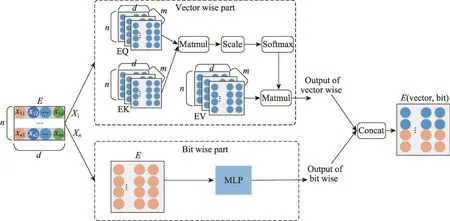
圖3 雙感知專家層Fig. 3 Dual perception expert layer
在特征元素級方面,利用多層感知機(multilayer perceptron,MLP)對元素級的特征進行提取,如圖3中Bit Wise Part所示,元素級的特征輸出如式(2)所示:
其中,δ(·)是非線性激活函數;是任務k可訓練的權重矩陣,輸出維度為d;bk是偏置參數。
利用多層感知機作為元素級特征的提取模型,可以得到更加復雜的特征表達形式,提升了模型的學習能力。
最后,將向量級的輸出特征與元素級輸出特征進行拼接作為下一步的輸入。雙感知專家層通過對特征多級別的提取之后,得到更豐富的特征表達,從而提升多任務差異性和共性的參數優化學習,減少負遷移問題。
2.4 門控交互層
在多任務模型中,大多數先進的模型都在結構上有特定任務的參數和多個任務共享的參數兩部分。同時,對于各個任務的輸出之前增加了一個門控網絡,選擇不同的專家模塊來學習參數,如圖4(a)所示。本文考慮了不同任務之間具有復雜的相關性,除了通過特定任務的雙感知專家層學習特征差異性之外,同時利用任務之間不確定性的關系提升任務的性能。在通過門控網絡學習任務特征的深層次的語義之后,將特定任務的門控輸出與其他任務的門控輸出經過交互層來捕獲任務之間的相關性。多任務交互層結構圖如圖4(b)所示。多任務交互的輸出形式化定義如式(3)所示:
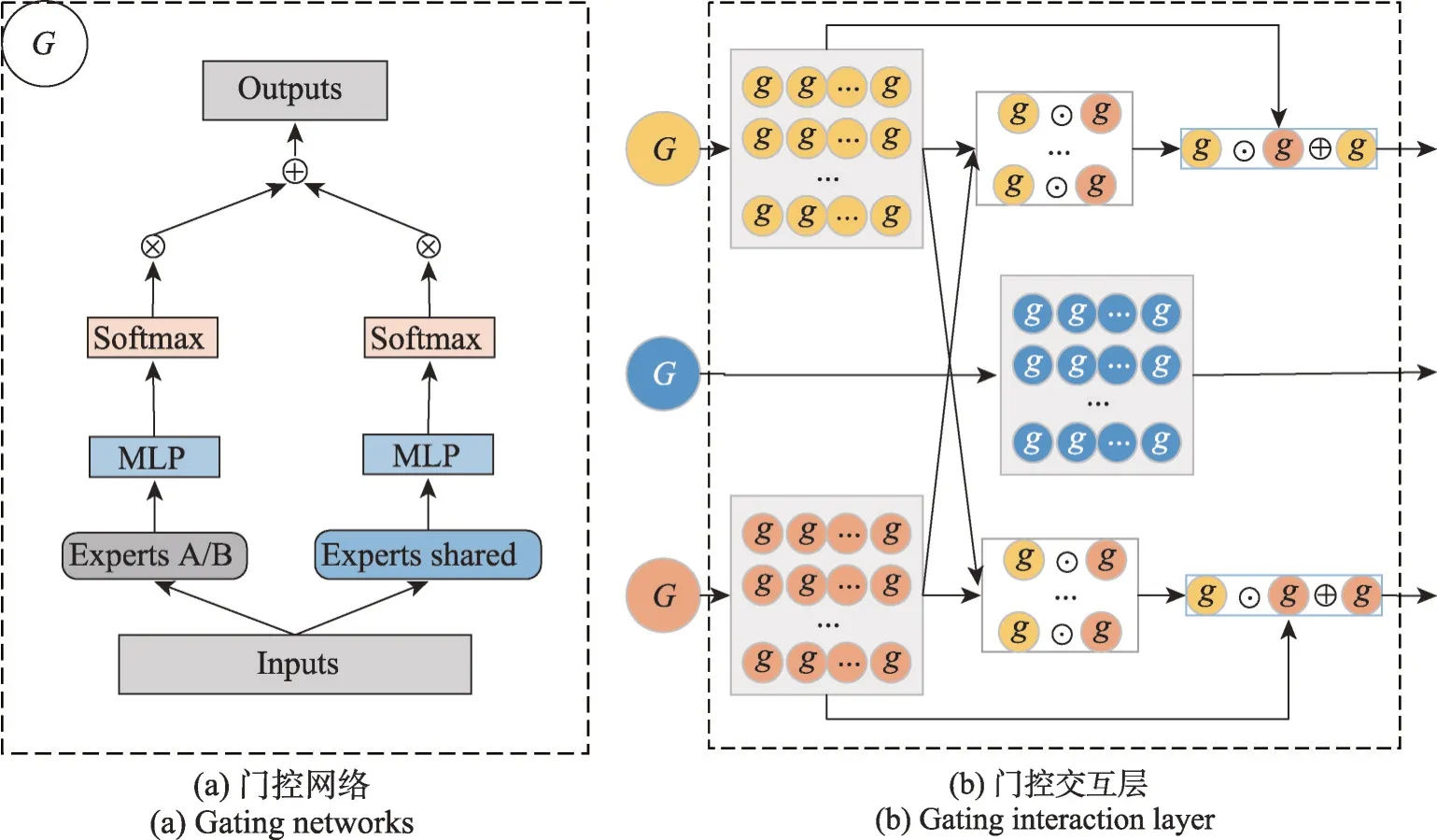
圖4 門控網絡和門控交互層Fig. 4 Gating networks and gating interaction layer
其中,Wm是交互模塊輸出的特征變換矩陣,符號⊙表示逐元素相乘,Gi是任務k之外的其他任務的門控輸出。在式(3)中,Gk的形式化定義如式(4)所示:
其中,g(·)是門控輸出的函數,這里使用多層感知機的神經網絡,Wg表示神經網絡的權重矩陣。和分別是任務k的專家模塊輸出和共享專家模塊的輸出。特別地,在共享門控中,包含了全部任務的專家模塊和共享專家模塊的輸出作為輸入,形式化定義如式(5)所示:
門控交互層漸進地學習了多任務的差異性的專有參數,利用任務之間的差異性建模了多任務之間復雜的相關性。同時,采用殘差的方式加上原始特定任務學習到的專有參數。這樣既保留了原有的任務特定參數,也利用了其他任務的復雜相關性。
2.5 損失函數優化
由前面幾節的介紹,DPGI-MTRM模型的最后輸出表示為模型中單個任務的損失函數為:
其中,?θLk(·)是任務k的目標函數梯度,任務k的目標函數根據任務的輸出類型決定,當為分類任務時目標函數為交叉熵損失函數,當為回歸任務時目標函數為均方誤差(MSE)。yk和y^k分別為任務k的目標真實值和目標預測值。綜上,多任務模型最終的損失函數可以形式化定義為式(7)所示:
其中,?θL(θ)是模型共同的梯度向量,K是多任務的目標數量。根據文獻[20],多目標優化問題是一個帕累托求解的問題,文獻中使用QCOP(quadratic constrained optimization problem)方法優化多個任務的損失權重wi。特別地,式(7)滿足幾個條件:(1)wi,wi+1,…,wK≥0;(2);(3)存在但是僅僅考慮單目標優化問題時,梯度為零是必要的條件。然而在多目標優化中,是多個目標梯度組合為零的問題。根據文獻[21],帕累托的解是一個集合,優化多目標就是在解集里面尋找最優的一個。根據QCOP定義,考慮兩個任務目標優化的情況下如式(8)所示,最后得到式(8)中w的一個解析解,如式(9)所示:
根據DPGI-MTRM模型的損失函數,使用梯度歸一化的多目標優化算法得到DPGI-MTRM 模型參數的優化算法,如算法1所示。
算法1DPGI-MTRM參數優化算法
DPGI-MTRM 模型的參數優化主要來自雙感知專家層和門控交互層的參數學習。雙感知層從差異性和共性方面進行參數優化學習,門控交互層從差異性方面進行參數優化學習。
對比的基準模型中,參數差異性方面只有來自元素級的特征輸入到門控網絡中,參數共性也只是元素級的特征參數學習。本文提出的模型,首先在雙感知專家層中,從元素級和向量級的雙感知特征表達來學習底層參數的差異性,在參數量上主要增加來自計算向量級的部分,空間復雜度是d,d為輸入維度。從時間復雜度上來看,提出的雙感知層在元素級和向量級的計算是并行的,幾乎不增加時間復雜度。其次在門控交互層中,每個任務門控網絡單獨學習到各自任務的差異性。從多方面學習到多任務參數差異性,提升了模型的泛化性。在參數共性上,雙感知專家層得到兩個層級的特征表達,得到豐富的特征語義,為門控交互層提供了增強型的特征表達輸入。
3 實驗
3.1 實驗設置
所有實驗均在Intel CoreTMi5-4690 CPU@3.5 GHz和16 GB 內存,11 GB 顯存的GTX1080Ti 顯卡的64位Ubuntu 系統中完成,所有代碼均使用Python 語言編寫,計算各評價指標依賴的是Python 的第三方庫scikit-learn 0.23.2。本文模型基于Tensorflow 1.15 實現,使用Adam優化器進行訓練,初始學習率設為1E-3且每隔25輪下降到原來的10%,訓練模型100輪約需要3.5 h。
3.2 數據集
為了評估本文模型的性能,本文在Synthetic Data、Census-income(http://archive.ics.uci.edu/ml)和Ali-CCP(https://tianchi.aliyun.com/dataset/dataDetail?dataId=408)數據集上進行實驗驗證。
Synthetic Data 數據集是根據文獻[22]的數據合成過程生成的,用來控制任務之間的相關性。按照標準正態分布隨機采樣αi和βi,并且設置c=1,m=10,d=512,分別生成相關性為0.20、0.50、0.75、1.00的兩個目標的多任務樣本,每個相關性生成100萬個具有連續標簽的樣本數據。
Census-income 數據集是美國UCI 從1994 年人口普查收入數據庫中提取的包含299 285 個美國成年人的人口統計信息,由40 個特征組成的數據集。從中選擇兩組多任務目標進行實驗,多任務目標如表1 所示。具體地說,第一組任務中預測收入是否超過5 萬美元和個人婚姻狀況是否從未結婚;第二組任務將第一組的預測收入換為是否接受過高等教育;第三組任務是將第一組和第二組的首個任務進行組合。
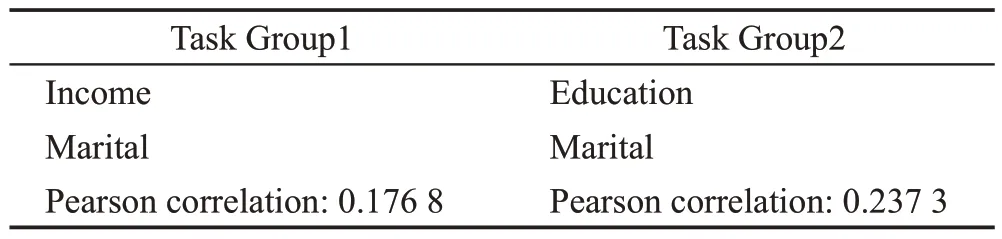
表1 Census-income多任務Table 1 Census-income multi-task
Ali-CCP 數據集是從淘寶的推薦系統中提取的8 400 萬個樣本的公共數據集,其中點擊率(clickthrough rate,CTR)和轉化率(conversion rate,CVR)是在此數據集上需要建模的點擊和購買的兩個任務目標。
3.3 評價指標
實驗中將數據集按照8∶1∶1分為訓練集、驗證集和測試集。對于分類任務采用AUC 來評估模型的CTR 預測性能,對于回歸任務采用MSE 作為評價指標,其中MSE的計算指標如下所示:
3.4 結果分析與比較
3.4.1 實驗結果比較
表2 和圖5 分別展示了本文在Census-income、Ali-CCP 以及Synthetic Data 數據集上兩個評價指標AUC 和MSE 上的對比結果。使用MMOE 和PLE 作為對比模型,為了公平地比較模型的性能,對比模型和DPGI-MTRM 模型的專家數n設置為8,模型層數都為3。從表2 中看到,本文的模型在兩個數據集上的AUC 指標表現都優于對比的模型。圖5 展示了DPGI-MTRM 模型和對比模型在Synthetic Data 數據集上,在不同相關性任務上的MSE 表現。從圖5 中可以看出本文方法具有明顯的優勢。

表2 Census-income和Ali-CCP 數據集上的實驗結果(AUC)Table 2 Experimental results(AUC)on Census-income and Ali-CCP datasets
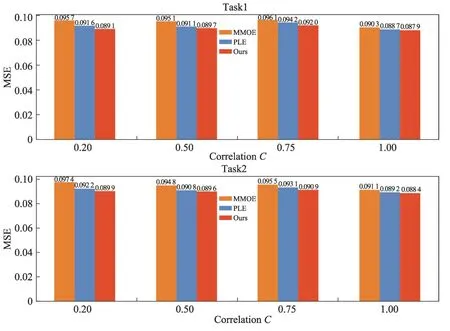
圖5 Synthetic Data數據集上相關性多任務的實驗結果Fig. 5 Experimental results of correlated multi-task on Synthetic Data dataset
3.4.2 各參數對模型的影響
DPGI-MTRM 模型里的參數專家數n是一個很重要的參數,用于對模型的寬度進行控制,能影響多任務的性能。圖6(a)展示了不同n取值下,DPGIMTRM 模型在Census-income 數據集上預測Education 和Marital 多任務的AUC 表現性能。設置了4 組參數n分別進行實驗,從圖中可以看到,當n取12時,模型在AUC 指標上表現最好。模型的層數l同樣是一個重要的參數,當l越大,模型在Census-income 數據集上的AUC 指標表現越好,考慮到模型參數量問題,實驗分別設置了l取值為2、3、6、9 和12,且n=8。圖6(b)展示了不同l取值下的AUC指標表現性能,可以看到當深度為6時,AUC表現最好,隨著深度增加,模型表現逐漸變差,這是因為訓練樣本不足造成過擬合。
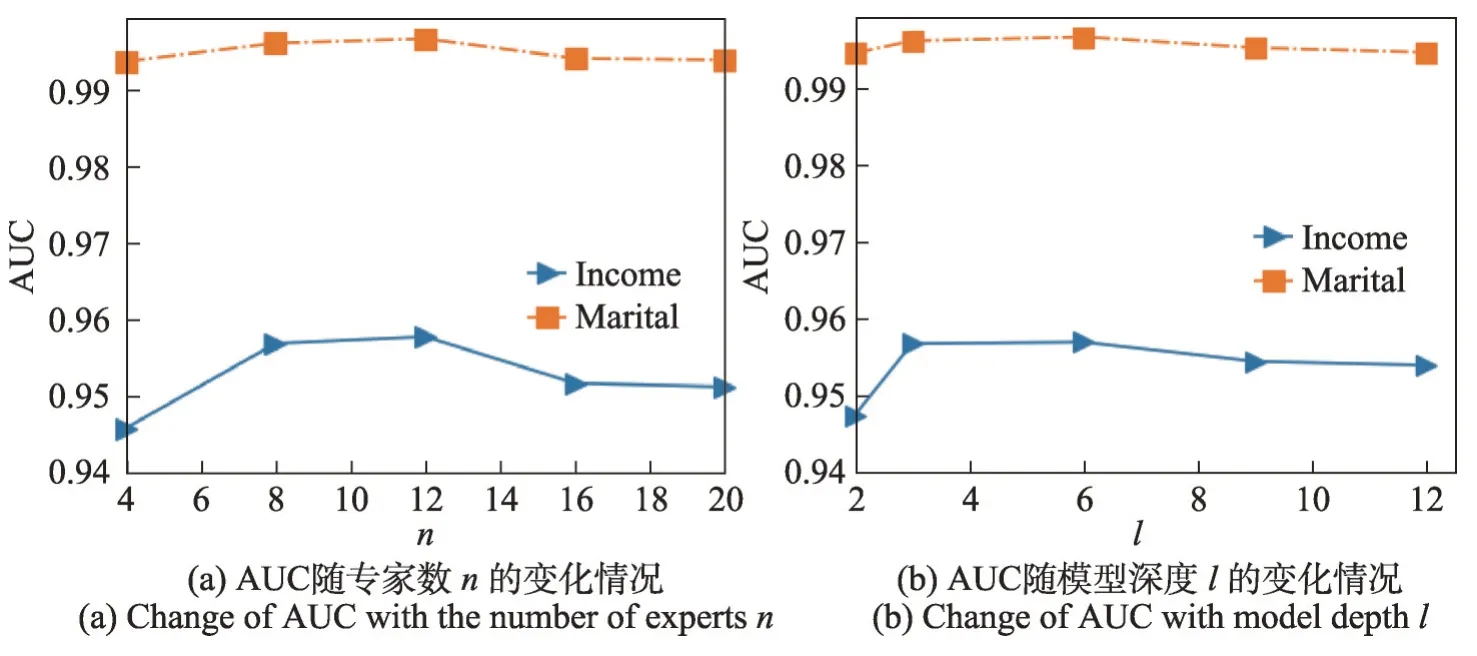
圖6 參數n和l對模型的影響Fig. 6 Influence of parameters n and l on model
3.4.3 模型方法的消融實驗
為了驗證本文提出的雙感知專家層和門控交互層對多任務中負遷移的有效解決,設置以下實驗進行對比驗證。
(1)將DPGI-MTRM模型去掉雙感知專家層和門控交互層作為基線模型,記為Base 模型。在Base 模型基礎上增加雙感知專家層,記為Base-DP模型。兩種模型在數據集Census-income 上的AUC 指標的表現如表3所示,可以看到使用了雙感知專家層在AUC指標上對比Base 模型在第一組任務上最大提升了0.94%。使用了雙感知專家層,讓任務的共享參數和專有參數能更好地得到學習,從元素級和向量級得到參數的多層級優化,得到豐富的特征語義表達。由實驗可以得出本文提出的雙感知專家層,可以解決多任務中負遷移問題,從而提升多任務的性能。

表3 Census-income數據集上的實驗結果(AUC)Table 3 Experimental results(AUC)on Census-income dataset
(2)對比Base模型,在Base模型的基礎上增加門控交互層,記為Base-GI 模型。兩種模型在數據集Census-income 上的AUC 指標的表現如表3 所示,可以看到使用了門控交互層在第一組任務上AUC指標最大提升了0.89%。設計的門控交互層,將多任務的專有參數漸進地優化學習,將第一階段中雙感知專家層學習的差異參數進一步優化。同時,使用任務之間差異性進行交互,對任務之間復雜相關性進行建模,增強了共性參數的優化學習。由實驗可以得到本文提出的門控交互層,可以解決多任務中負遷移問題,從而提升多任務的性能。
(3)對比Base模型,在Base模型的基礎上同時增加雙感知專家層和交互層,即為DPGI-MTRM 模型。兩種模型在數據集Census-income 上的AUC 指標的表現如表3 所示,可以看到AUC 指標最大提升了2.06%,由此可以得出本文提出的雙感知門控交互的多任務推薦模型是有效可行的,能解決多任務負遷移問題。
4 結束語
為提升多任務推薦中點擊率預測的準確性,解決多任務中負遷移的問題,本文提出了一種雙感知門控交互的多任務推薦模型(DPGI-MTRM)。模型考慮到底層特征提取的方式,設計了雙感知專家層,其得到元素級和向量級的雙感知特征表達。同時針對多任務的負遷移問題,提出門控交互層,增強了多任務交互學習,有效利用了多任務的專有參數,從而提升多任務的模型性能。通過在三個數據集上的實驗,結果表明提出的模型在預測準確性上較基準模型有明顯的提升,驗證了模型方法的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
