作物病害智能診斷與處方推薦技術研究進展
2023-06-20 04:40:10張領先韓夢瑤丁俊琦李凱雨
農業機械學報 2023年6期
關鍵詞:方法
張領先 韓夢瑤 丁俊琦 李凱雨
(1.中國農業大學信息與電氣工程學院, 北京 100083;2.農業農村部農業信息化標準化重點實驗室, 北京 100083)
0 引言
作物病害是制約農業可持續發展的主要因素之一。在種植過程中,作物會受到其他生物的侵害或不適宜環境的影響而引發病害,造成作物品質下降和產量減損,進而影響生產者的效益。研究和掌握不同品種作物多種病害發生的規律和特點,及時幫助生產者對病害及時診斷、對癥防治、科學用藥和輔助決策,在未來農業生產中具有重要意義[1]。
傳統的作物病害防治方案主要依賴于人工經驗,基本處于定性階段,受人為主觀性判斷影響較大。隨著計算機技術發展,專家系統實現了自動推薦作物病害防治方案。主要是利用計算機技術和人工智能技術,根據作物病害領域的專家知識和經驗,進行推理和判斷,模擬人類專家的決策過程,能夠根據受害作物的癥狀等信息逐步推斷,最終得到包含診斷結果以及農藥的防治方案,即病害處方。但是專家系統存在不足:①系統構建成本較高,需要收集并整理作物病害領域的專家知識和經驗,并據此編寫推理程序。由于受害作物屬性包括作物種類、發育階段、受害部位等,編寫詳細的推理程序費時費力。②普適性不足,大多數專家系統只能對個別種類的作物進行推理和判斷,對于不同種類的作物往往需要多個系統,在實際應用中受到限制[2]。
由“植物診所”形成的電子病歷(Plant electronic medical records,PEMRs)為作物病害處方推薦提供了新的思路[3]。現有的作物處方數據包括作物、環境和病害信息以及診斷知識,為作物病害診斷提供了新的分析視角:通過已有的處方數據挖掘出有效信息,輔助植物醫生開具作物病害處方,緩解當前作物病害處方的困境。在生物醫學研究領域,多項研究證明電子病歷數據具有回溯性和可預測性,以及輔助構建臨床決策支持系統的能力[4-5]。基于此,本文對作物病害診斷與處方推薦技術國內外的研究進展進行綜述,分析作物病害診斷與處方推薦研究中面臨的關鍵問題,并對作物病害診斷與處方推薦技術的未來發展加以展望。
1 作物病害診斷與處方推薦技術概述
1.1 作物病害三角關系原理
作物病害的產生原因可以由植物病理學中的病害三角原理解釋為環境、病原物和作物三者相互作用[6]。病害大多數是由真菌、病毒、細菌等病原物引起的,加之合適的土壤環境、氣候環境和栽培條件等。病原體的毒力、宿主的遺傳易感性和有利于感染的非生物環境決定了作物病害的表現形式[7]。對于侵染性病害,當條件有利于病原物生長時,病原物就會侵染寄主植物。病原物侵入寄主植物到表現病癥的連續過程稱為病程,具體分為接觸期、侵入期、潛育期和發病期4個時期。病菌孢子發育過程能夠表示病原物侵染過程,通過作物病菌孢子侵染特征識別與行為分析,能夠為作物病害早期預警和防控提供理論支撐。
1.2 作物病害診斷方法
作物在遭受病害侵襲時,外部形態特征和內部生理特征均會發生細微的變化。外部表現出諸如退綠、變色、變形、卷曲、枯萎等特征,而作物內部的水分、色素含量、光合作用、呼吸作用、防御酶系統等也會發生多種生理變化[8]。通過檢測病害發生后作物的外部形態特征和內部生理特征變化,可以獲取作物的染病情況。傳統的病害癥狀觀察法,結合病原菌的形態特征以及過往經驗進行識別,這種方法主觀性強,且對專家的依賴性較大;20世紀 70 年代興起的酶聯免疫法,可以靈敏地檢測作物中病毒蛋白的含量,但價格昂貴,在細菌和真菌病害檢測方面應用較少。隨著信息技術的快速發展以及各種儀器設備的不斷出現,多種傳感器應用于作物病害的識別診斷中。
從病原物侵染過程和病害診斷數據獲取的角度可以將作物病害診斷方法歸納為:基于顯微圖像的作物病害病菌孢子識別和基于光譜成像的作物病害診斷,前者主要是病原物侵染過程接觸期、侵入期和潛育期前3個階段對病菌孢子的個體和群體特征識別及其定量表達,后者是發病期對作物內外部表現的病癥進行識別、定量表達與診斷。
1.2.1基于顯微圖像的作物病害病菌孢子識別
借助顯微設備獲取顯微圖像,實現作物病害病菌孢子的識別。可以搭建病菌孢子顯微圖像采集平臺,平臺一般由體視顯微鏡、光源、CCD彩色相機和計算機組成(圖1)。平臺能夠實時采集病菌孢子侵染過程圖像,并通過數據轉換傳到計算機中,通過計算機來保存孢子圖像并用于實時查驗,進一步通過軟件系統進行病菌孢子形態特征識別和動態特征定量表征分析。
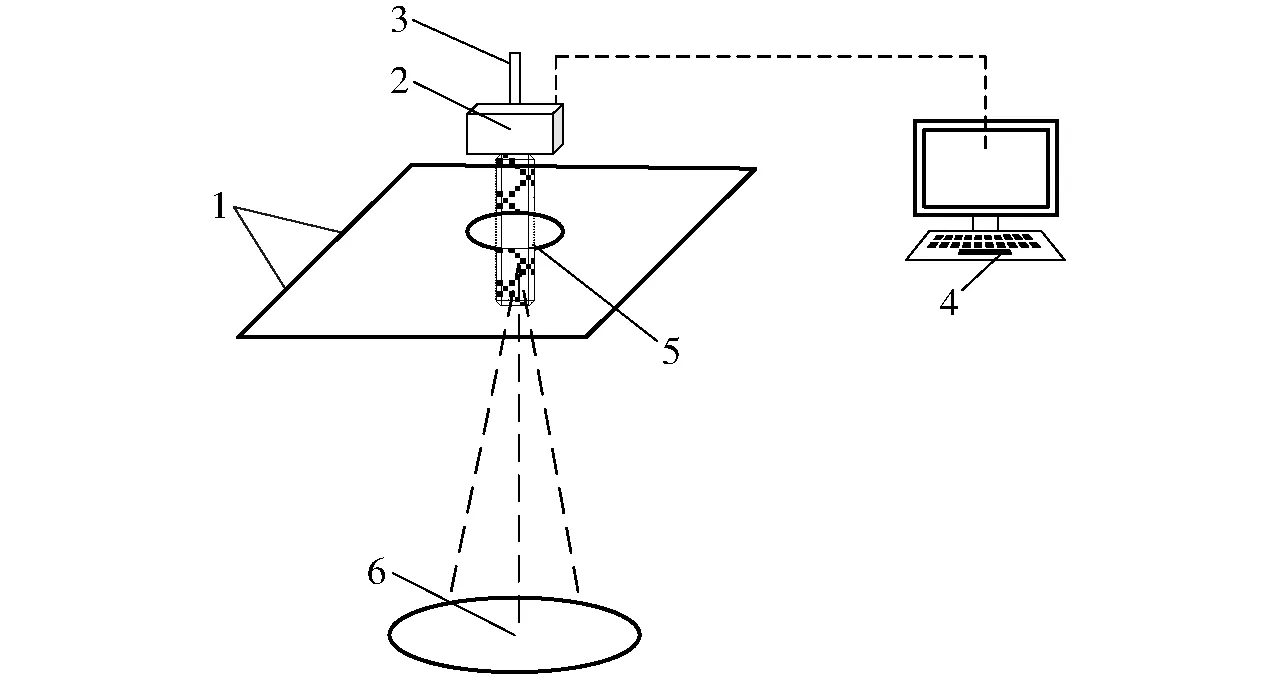
圖1 病菌孢子顯微圖像采集平臺Fig.1 Pathogen spore microscopic image acquisition platform1.光源 2.CCD相機 3.相機固定桿 4.計算機 5.顯微鏡 6.載物臺
1.2.2基于光譜成像的作物病害診斷
作物在遭受病菌侵襲后,作物色素、水分等內部物質的濃度或分布發生了改變,表現出不同的病斑[9]。研究表明,作物內部特性改變后,對于光譜的反射特性亦會隨之改變,從而為作物病害的光譜特性定量分析提供了理論基礎[10],如多光譜和高光譜傳感器、熱成像或葉綠素熒光成像能夠檢測到內部生理變化,已被應用于病害的早期檢測和定量識別中,RGB傳感器能夠根據病斑圖像的顏色、形狀和紋理等特征,結合機器視覺方法進行病害識別和定量診斷,基于光譜成像的作物病害診斷基本步驟如圖2所示。
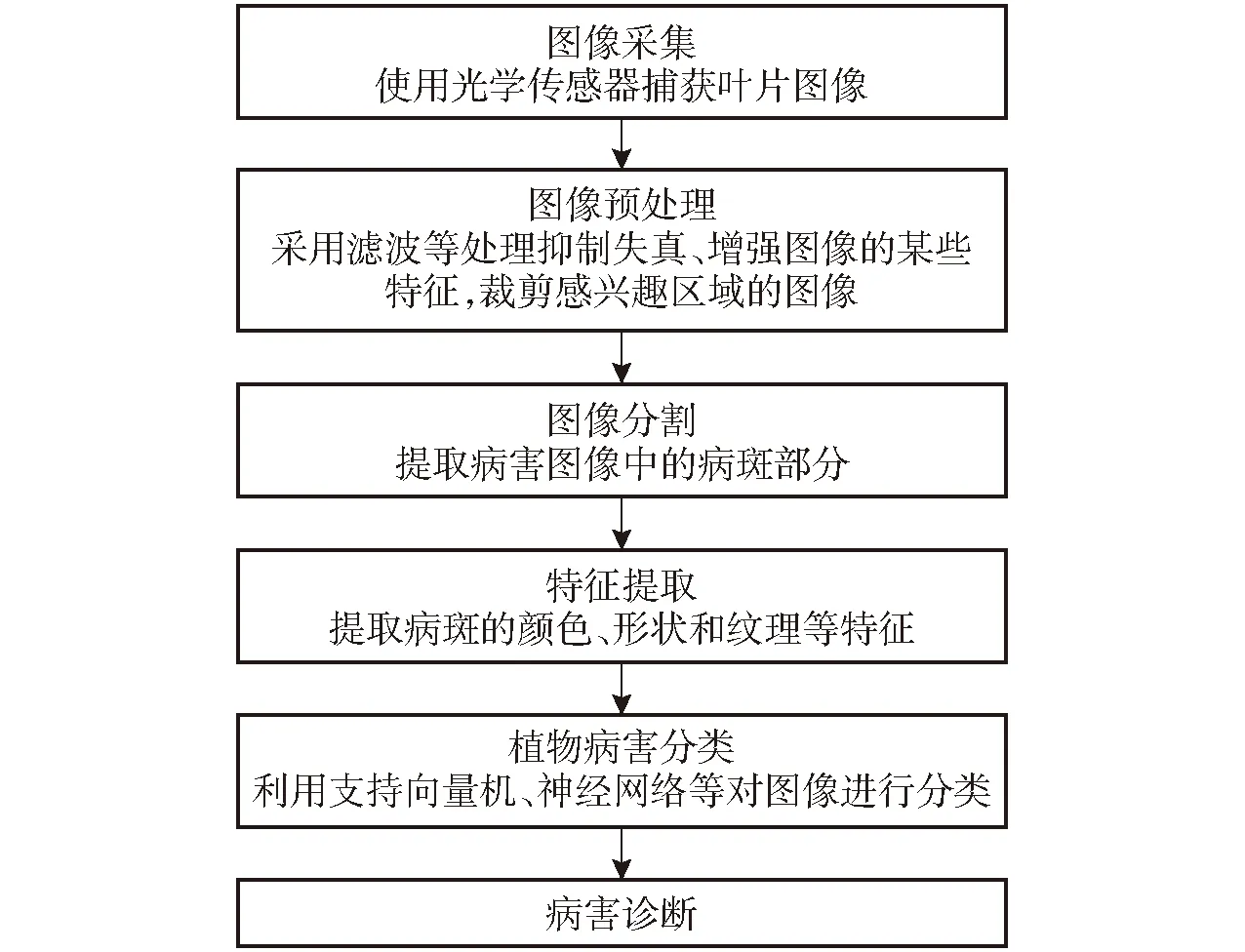
圖2 光譜成像檢測植物病害流程圖Fig.2 Flowchart for detection of plant diseases using an imaging technique
機器視覺技術是在數字圖像處理、人工智能、模式識別等技術基礎上逐漸發展形成的一種新的技術,為作物病害識別與診斷提供一種快速且有效的方法。可以利用數字圖像處理技術,分析葉片的這些癥狀來診斷作物病害并進一步估算病害發生的嚴重度。基于機器視覺的設施蔬菜診斷系統流程如圖3所示。
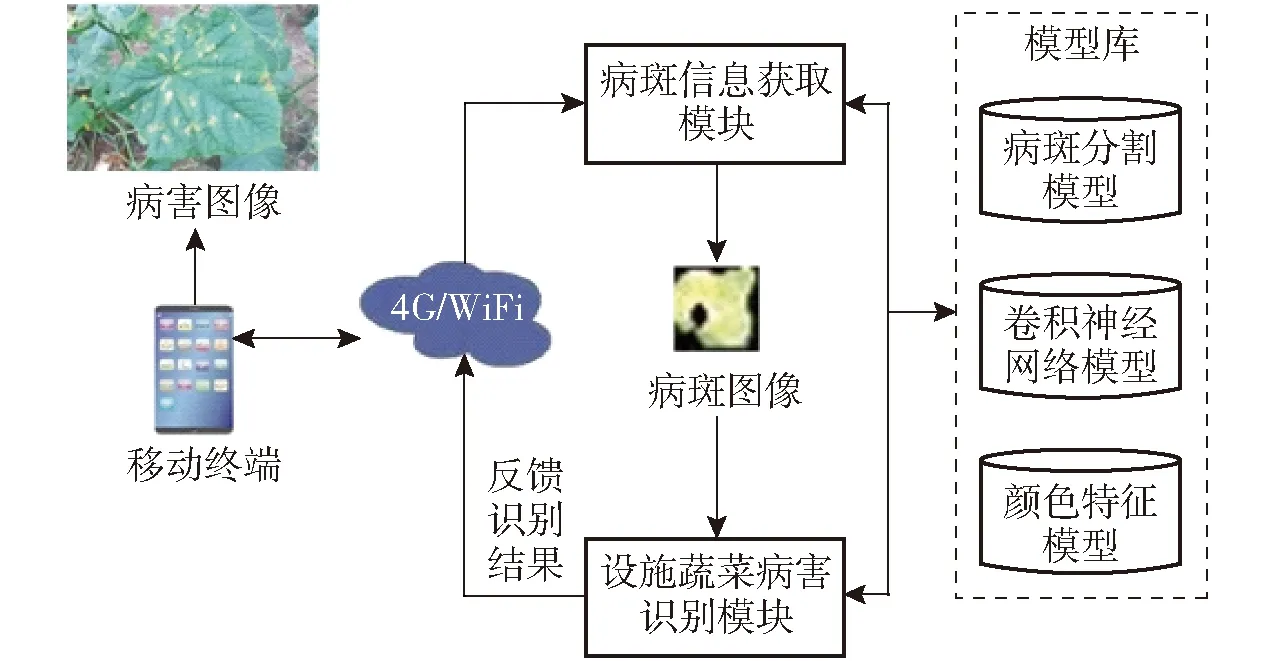
圖3 系統流程圖Fig.3 System flowchart
1.3 作物病害處方推薦技術原理
1.3.1“植物診所”形成的電子病歷
針對生產中面臨的病害識別診斷預警相對滯后,綠色植保技術落地難,公共植保服務難以全覆蓋等問題,北京市植物保護站聯合中國農業大學等4家單位,開展了基于生產實際需求的綠色智慧關鍵植保技術研究及應用。2012年北京市首次引入國際先進的植物診所理念,開始在全市范圍內建立市區鄉(村)三級植物健康服務體系。先后建立植物診所115個,區級二級植物醫院4個,北京市植物總醫院1個,植物醫生及培訓師665名,服務范圍覆蓋全市13個區,161個鄉鎮,1 744個村,還輻射到河北省廊坊市、張家口市、邢臺市以及天津市武清區等地區[11]。
植物醫生遵循有害生物綜合防治(Integrated pest management, IPM)原則,以開處方的形式,為農民提供病害診斷和防治技術咨詢[12],問診完成后的電子病歷都被備份在系統中(圖4),具體包括農戶、植物醫院、作物、病害性狀、診斷結果、處方等信息[13]。
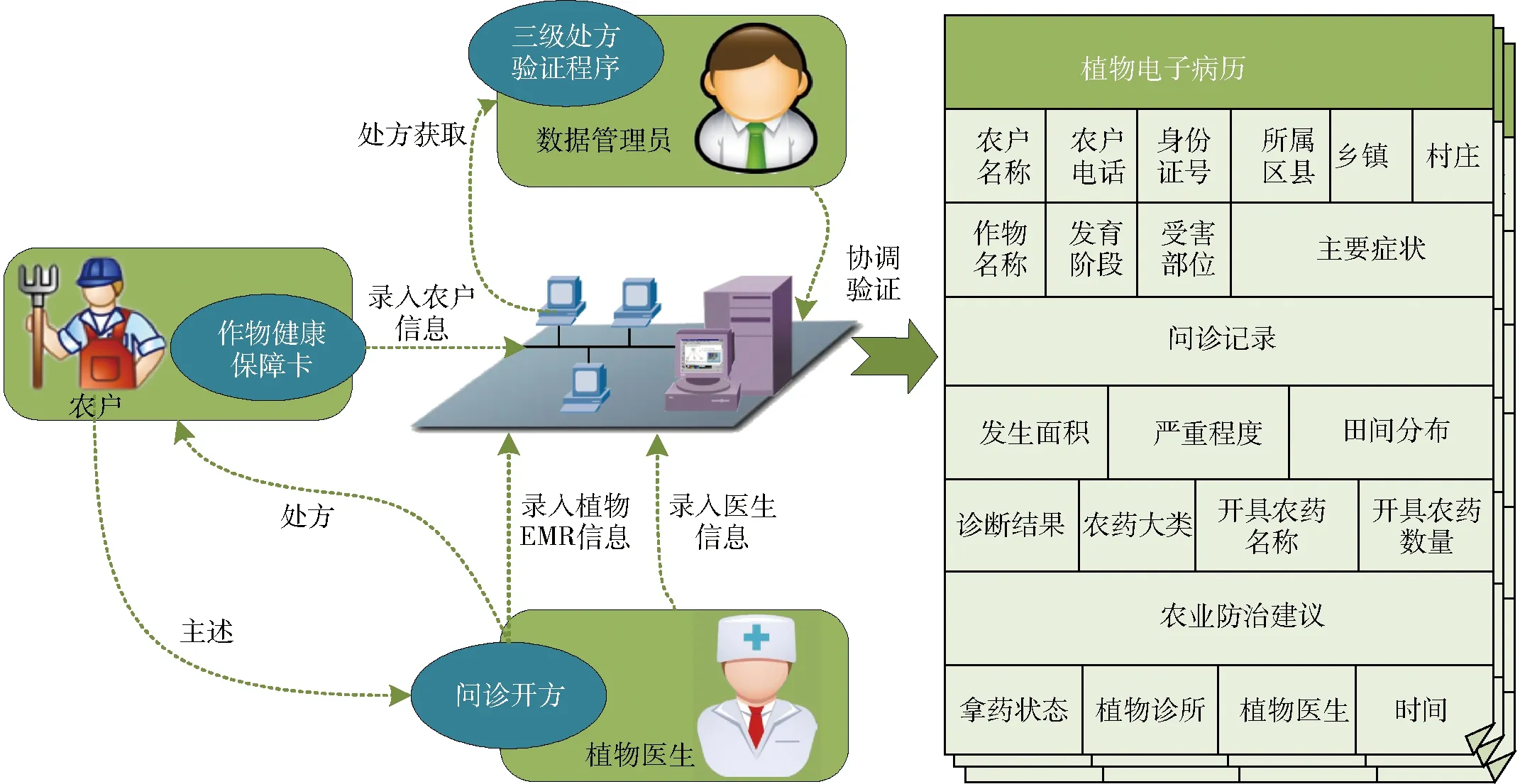
圖4 植物診所病歷填寫流程圖[13]Fig.4 Plant clinic medical record filling process
1.3.2處方數據預處理與擴充
處方數據預處理是將原始數據轉換為可理解的格式的過程,這也是數據挖掘的重要一步。處方數據預處理的一般步驟是:對源數據文件整理、轉換,數據清洗(刪除重復值、缺失值處理、一致化處理和異常值處理),數據統計,最后對輸出數據進行編碼(標簽編碼和One-hot編碼)(圖5)。
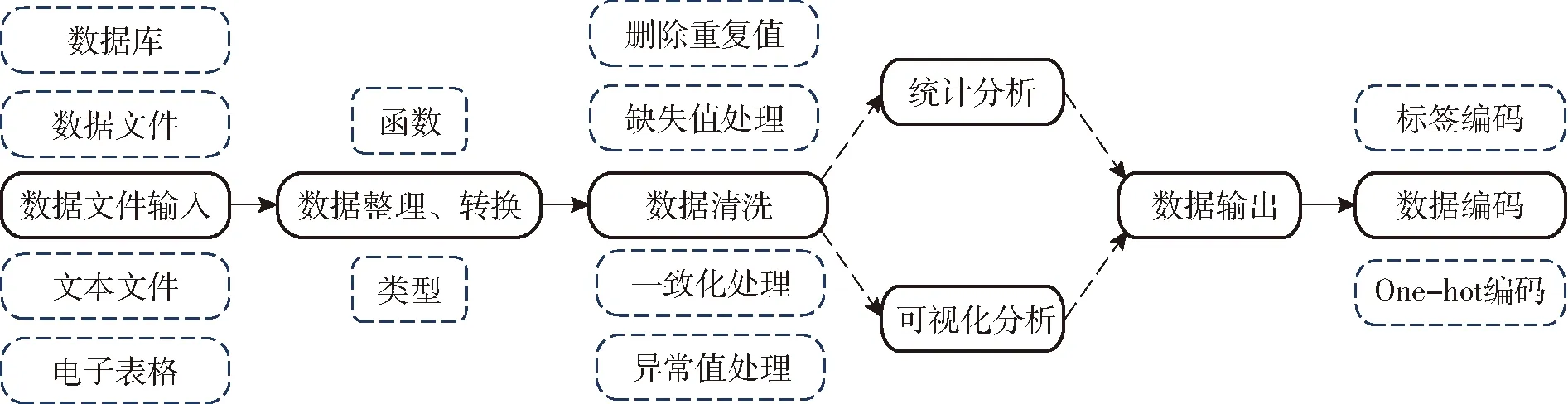
圖5 處方數據預處理流程圖Fig.5 Prescription data preprocessing process
處方數據擴充是在原有數據的基礎上進行修改,最終獲得相似但不相同的數據的方法,被廣泛應用于機器學習中[14-15]。對于作物病害處方數據,可以使用簡單數據增強(Easy data augmentation, EDA)[16],包括以下4種數據擴充方法:
(1)同義詞替換(Synonyms replace, SR):設句長為l個單詞,替換比例為α。不考慮停用詞,在句子中隨機選擇l×α個詞,然后在同義詞詞典中找到對應的同義詞,最后隨機選擇同義詞將原本的詞匯替換。
(2)隨機插入(Randomly insert, RI):將隨機抽取的某個單詞的同義詞插入到句子中任意位置,重復l×α次。
(3)隨機交換(Randomly swap, RS):將句子中l×α個單詞位置互換。
(4)隨機刪除(Randomly delete, RD):剔除句子中l×α個單詞。
此外,變分自動編碼器(Variational autoencoder, VAE)等文本生成模型[17]也可用于處方數據擴充,以學習文本中的潛在性解釋,生成具有特定語義的文本。
1.3.3電子病歷挖掘與處方推薦
作為最重要的臨床數據類型, 電子病歷以結構化和非結構化結合的形式記錄了大量關于疾病癥狀、統計數據、診療決策、藥物處方以及環境特征的信息,能夠提供完整準確的診療數據以及具備構建臨床輔助決策支持系統的能力[18-19]。國內外相關研究表明,對電子病歷數據進行相關分析具有一定的合理性和必要性,從而可以進一步揭示特征與病害間的深層聯系[20]。
通過處方數據分析可以獲取處方數據中有價值的信息,輔助人們開展處方推薦相關研究,實現智能化診療。有關處方數據挖掘的研究主要有病害診斷、數據檢索與管理,以及智能化處方推薦3個角度。其中處方推薦是解決信息超載問題的有效工具[21],即通過對歷史數據進行分析,發現處方數據中的規律,從而預測問診對象可能需要的處方。
處方推薦的思路比較如表1所示。

表1 不同處方推薦思路特點Tab.1 Comparison of different prescription recommendation ideas
2 作物病害診斷與處方推薦關鍵技術
2.1 基于顯微圖像的作物病害病菌孢子識別關鍵技術
基于顯微圖像的作物病害病菌孢子識別涉及的關鍵技術包括作物病菌孢子個體目標識別技術、作物病害病菌孢子群體目標識別技術和作物病害病菌侵染行為分析技術。
2.1.1作物病菌孢子個體目標識別技術
作物病害病菌多以有序的狀態進行生長繁殖,不同時期孢子形態特點明顯,但也可能受外界因素的影響發生形態變異和部分殘缺[22]。通過檢測病菌孢子,提取病菌孢子動態特征是病害早期診斷的重要環節。傳統的顯微鏡觀察主要依賴于人眼觀察識別,效率低下,耗時費力,且要求專業人員持續觀察。隨著計算機技術、圖像處理技術、模式識別技術的發展,將機器視覺技術引入到病菌孢子的識別中,提高了病菌孢子檢測效率。基于機器視覺技術的病菌孢子識別算法主要通過對病菌孢子圖像進行圖像分割、特征提取與構建分類器模型完成對病菌孢子的識別[23]。其中在病菌孢子圖像分割中,學者常用基于閾值、邊緣檢測[24]、區域生長和聚類分析等圖像分割方法,獲得病菌孢子圖像,進而提取病菌孢子的周長、面積、圓形度、半徑和弧長等形態特征[25],紋理特征,HOG特征,SIFT特征[26-27],Haar算子,Harris角點等特征,并結合決策樹、支持向量機(SVM)、基于規則的粗糙集、LDA(Latent dirichlet allocation)主題模型、K-means、貝葉斯分類以及人工神經網絡等機器學習方法進行病菌孢子的識別,均取得了良好的識別效果[28-29]。但是,隨著數據量的劇增,上述方法在特征提取方面存在計算復雜和特征不可遷移性等不足,并且需要人為提取特征和普適性不強等問題。近年來,深度學習中的卷積神經網絡的出現已經徹底改變了圖像識別在相關領域的應用,陸續實現了病菌孢子識別,識別率也有很大提高[30-31]。LI等[32]提出使用多頭注意力優化YOLO v5檢測黃瓜灰霉病菌孢子,對模糊、多形態的孢子有較好的檢測效果。但是實際采集的顯微圖像中也存在復雜噪聲,且病原目標物比較小等系列問題給實際應用帶來巨大挑戰。而且病菌孢子是一種生物,本身發育過程中存在形態變異,且由于外界因子的影響,也會發生形態變異和部分殘缺,因此有必要結合病菌孢子發育過程,對不同侵染期狀態的病菌孢子展開深入研究,為病害早期預警提供理論支撐。
2.1.2作物病害病菌孢子群體目標識別技術
在病菌孢子計數的研究中,目前大多采用顯微鏡觀察法、分子生物學方法和基于顯微圖像處理法等。通過孢子捕捉儀捕捉到病菌孢子之后,光學顯微鏡下通過肉眼觀測以確定孢子個數,存在工作量大、效率低且隨工作時間延長而準確性降低等缺點[33-34]。利用分子生物學檢測方法(PCR)鑒定DNA序列來定量檢測具有客觀、準確和高通量等優點[35-37],但是,基于PCR 技術的孢子計數方法操作復雜,成本較高,也耗費時間[38-40]。基于顯微圖像處理的孢子計數方法是在傳統顯微鏡計數方法的基礎上,利用計算機技術實現孢子的自動計數。圖像處理方法首先對孢子顯微圖像進行灰度化、中值濾波去噪等預處理;其次使用閾值分割、邊緣檢測、分水嶺分割和K-means 聚類等分割處理獲取孢子目標區域[41],然后常用形態學處理消除孢子區域的背景噪聲和孔洞;最后通過標記計數法、平均面積法和角點檢測法等實現孢子的自動計數。上述方法對未粘連的孢子能很好的計數,具有快捷、高效等特點。對于粘連孢子的情況,也有相關改進研究,如基于符號對數高斯混合模型相似度(SLGS)的水平集法、基于距離變換的改進分水嶺算法、改進Harris角點檢測法和循環標記腐蝕法[42],但對復雜的多粘連情況下的魯棒性和準確性不高,導致計數不準確是一個亟待解決的問題。研究表明深度學習方法相比于傳統的手工提取特征的方法在圖像識別領域具有巨大優勢,逐漸應用到病菌孢子定量分析[43],但是現有的通用深度學習模型在多形態、粘連和小目標孢子顯微圖像中并不能取得很好的識別效果,需要構建一個適合孢子顯微圖像的深度學習模型。作物病害致病過程與葉片上病菌孢子密度相關[44],而上述開展的研究大多是針對孢子捕捉儀捕捉到的病菌孢子進行定量計數,文獻少有探究病菌孢子侵染過程各個時期動態變化和時序演化規律。
2.1.3作物病害病菌侵染行為分析技術
作物病害是病菌、環境和寄主作物3方面的統一體,當環境條件有利于病菌生長時,病菌進入細胞,通過病菌分泌的毒素和細胞壁降解酶致病[45],進而引起葉綠素含量、氣孔導度、葉表溫度和孔隙結構等發生變化[46],作物病菌的相關研究主要集中在生物學特性[47-48]、抗病機制[49]以及侵染特性[50]等方面。遵循病害三角關系,在研究作物病害發病的預測過程中,應該利用環境條件與致病真菌生長發育的關系,綜合考慮影響病害的主導因素(溫度、濕度和結露時間),其次還有一些其他的因子(病情指數、作物是否具有抗病性、菌源數或病菌孢子濃度和栽培條件等)[51]。分析病情指數等病情預測模型大致可分為3類:①經驗模型。基于生產經驗、多點多年觀察或從已有文獻中歸納總結適宜的發病條件,通過定性、定量或數理統計構建模型表達式。使用最大空氣濕度、最大空氣溫度、活動積溫、活動積濕、累積相對濕度與氣溫的比值、晝夜溫差等因子[52-53]。②機理模型。能夠詳細地描述病害發展的各個階段,從而更好地了解寄主與病原物之間的關系。③數理統計模型。通過與現代信息技術相結合,提高模型的準確率,并嘗試自我學習來對病害進行模擬,如構建多元線性回歸、Logistic回歸等模型。近年來,BP 神經網絡、決策樹和馬爾科夫鏈等機器學習方法在病害預測的應用中也取得了階段性研究成果。但是缺乏綜合考慮作物病害三角關系及病菌孢子侵染過程動態演化規律的研究,無法滿足當前作物綠色生產對病害時序化、數字化、精準化早期預警和防控的需求。
2.2 基于內部光譜成像的作物病害診斷技術
基于光譜成像的作物病害診斷涉及關鍵技術包括:基于熱紅外成像的作物病害檢測技術、基于多光譜成像的作物病害檢測技術、基于病癥可見光圖像的作物病害識別技術和基于病癥可見光圖像的作物病害嚴重度估算技術。
2.2.1基于熱紅外成像的作物病害檢測技術
熱紅外成像技術利用作物染病后的溫度變化差異來對病害進行識別區分,該技術已開始應用于農作物病害的檢測中,并取得了良好的效果。KIM等[54]利用數字紅外熱像儀研究了紫薇感染煙煤病后葉片溫度場的空間分布規律,發現在熱紅外圖像中,健康區域和染病區的平均溫度分別為26.98℃和28.44℃,表明染病區的平均溫度明顯高于健康區域。LPEZ-LPEZ 等[55]通過熱成像和高光譜成像計算得出冠層溫度和植被指數,并分析了它們在早期發現疾病的能力。結果顯示,線性模型顯示出更高的區分無癥狀樹和紅葉斑塊發展后期樹的能力,而非線性模型則更好地將無癥狀植物與紅葉斑塊發展的早期植物區分開。MASTRODIMOS等[56]為了評估空間溫度的異質性,該研究利用熱紅外成像技術,計算了漿果表面的平均溫度以及漿果表面受感染區域和未感染區域之間的最大溫度差。研究發現,漿果中的真菌菌絲體發育期間的葡萄葉片平均溫度明顯低于健康的葡萄,而在真菌定殖過程中的最大溫度差卻增加了。最后將熱成像的溫度數據分部進行擬合得出病害感染估計因子,實現了葡萄生理狀態的無損監測。FAROKHZAD等[57]使用熱像儀和加熱箱獲取熱圖像,研究處于不同階段(感染后1~7 d)的健康馬鈴薯塊莖和被真菌污染的塊莖溫度,通過線性和二次判別分析方法提取并分類了一些溫度統計特征。最終建立了一種基于主動熱成像的可靠、無損、快速的方法來檢測馬鈴薯塊莖中的真菌。
由于歐美國家對我國的技術進出口限制,我國的紅外熱成像技術起步較晚。李小龍等[58]通過連續采集小麥不同生理健康狀態的植株熱紅外圖像,分析葉片溫度隨銹病病害接種天數的變化趨勢,實現了對小麥條銹病潛伏期葉片的檢測與識別。朱文靜等[59]以感染葉銹病的小麥葉片為研究對象,分別采集健康組、潛伏期組和發病組的紅外熱圖像,并利用邊緣檢測算法提取病斑的區域,根據病斑面積占比實現對小麥葉銹病的病害嚴重度分級。陳欣欣等[60]利用熱紅外成像技術檢測受菌核病侵染的油菜,發現利用熱紅外圖像可在接種病害24 h后,觀察到微小的病斑,且隨著侵染時間的增加,病斑面積逐漸變大;但直到第3天肉眼才可以清晰地識別出病斑,表明熱紅外圖像可以更早、更直觀、更清晰地識別出作物染病早期的病害情況。溫冬梅等[61]通過熱紅外成像技術,記錄了不同濕潤持續時間下黃瓜霜霉病顯癥后葉片溫度的變化,并分析了其溫度變化規律,建立了黃瓜霜霉病流行趨勢模型。姚志鳳等[62]進行了將熱紅外成像技術用于小麥條銹病早期檢測的可行性研究。實驗發現,隨著接種時間的增加,接種病害的小麥植株冠層的平均溫度會逐漸降低,葉片間的最大溫差會不斷加大。結果顯示,熱紅外成像技術可觀測到小麥條銹病病斑,較肉眼觀察時間提前,可實現基于熱紅外成像技術的小麥條銹病早期檢測。
熱紅外成像能更容易地觀察到被病害侵染葉片的溫度變化,將其作用于農作物病害檢測,有著廣闊的應用前景。但由于熱紅外成像受到光照、環境干擾較大,且由于熱紅外圖像的像素質量限制,圖像存在邊緣模糊、信噪比較低等缺點,因此,基于熱紅外圖像技術的作物病害診斷研究還需要進一步深入展開。
光譜成像技術是基于成像學和光譜學發展起來的一種技術,光譜成像技術可以同時從光譜維和空間維獲取被測目標的信息等。一幅多光譜圖像是由一系列灰度圖像組成的三維數據立方體,二維圖像記錄了樣本的形態信息,三維坐標則記錄光譜信息,映射出葉片每個像素點的組分含量和內部特性,有利于病害的精準定位以及早期診斷。
劉鑫等[63]用波段指數法提取多光譜圖像的特征波段進行彩色合成,能快速獲取馬鈴薯葉片的最佳波段。近年來更多的學者將多光譜相機與無人機結合[64-65],大面積診斷病害,相關文獻表明將該技術應用在病害檢測方面取得了較好的效果(表2)。
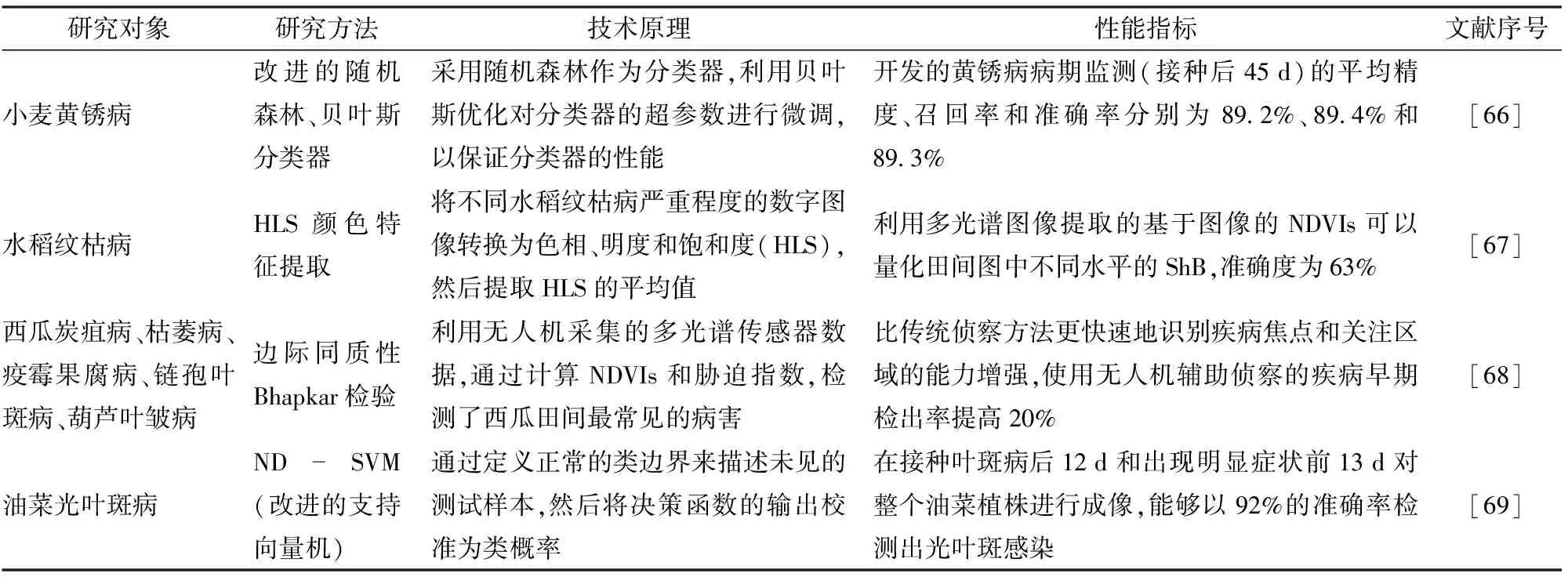
表2 基于多光譜成像的作物病害檢測研究成果Tab.2 Research results of crop disease detection based on multispectral imaging
2.2.3基于病癥可見光圖像的作物病害識別技術
按照特征提取的方法可以將以往的基于病癥可見光圖像的作物病害識別技術研究劃分為機器學習方法和深度學習方法。
基于機器學習方法的研究多是分割病斑、提取病斑特征、構建病害識別分類器的一個流程,目前文獻研宄已表明此類方法己經取得了較好的識別效果(表3)。首先通過條件隨機場[76]、Otsu分割[77]等分割方法獲得病斑圖像,進而提取病斑圖像的顏色、紋理、形狀等特征[70-71,78],基于支持向量機、BP神經網絡、決策樹等分類模型識別病害類別[72,76-77]。所有上述用于病害識別的方法都是基于從病斑圖像中提取的手工設計的特征,而人工設計的病斑特征難以完整的描述病害類別間的差異,容易出現圖像語義鴻溝問題。這些局限性直接導致了該方法很難滿足實際場景中病害識別的要求。

表3 基于機器學習的病害識別研究成果Tab.3 Research on disease recognition based on machine learning
深度學習卷積神經網絡的主要思想是通過深度神經網絡的層層映射,來自主學習圖像像素特征、底層特征、高層抽象特征直至最終類別間的隱式表達關系,更加有利于捕獲數據本身的豐富內涵信息,同時也避免了復雜的人工設計過程。卷積神經網絡的發展為圖像處理技術提供了新的契機。現今,卷積神經網絡已在農業各領域得到了廣泛應用[73],如植物病蟲害識別分類[74-75,79]、植物器官計數[75,80]、雜草識別[81]等農業領域,并取得了令人欣喜的成果。在病害識別問題中,基于AlexNet、VGGNet、GoogleNet和ResNet等架構,結合遷移學習方法訓練病害識別模型[82-86],實驗證明,遷移學習能夠提高模型的準確率。除了現有CNN架構的應用之外,還提出了幾種定制架構用于作物葉部病害檢測,如三重損失的FSL網絡[87]、多尺度特征融合網絡[88]、無監督卷積自動編碼器[89]、注意力機制優化的網絡[90],在簡單背景下的病害圖像中均取得了較高的識別準確率。采集自建的數據集應用于特定作物類型病害的研究也很常見,翟肇裕等[91]也做了相關研究和綜述。但是實際環境下的圖像背景復雜、光照條件多樣、病斑小且不明顯、病斑與背景對比度不大,兩者很難區分。現有方法在面向實際場景復雜背景和噪聲條件下的作物病害識別時,識別準確率往往會大大降低,識別速度也會變慢,難以滿足實際應用需求。
2.2.4基于病癥可見光圖像的作物病害嚴重度估算技術
一般在衡量病害發生程度時主要有兩個指標:發病率和嚴重度,發病率是指同類被侵染的單位(葉片、植株、莖、果實)占同類總測量單位的百分比(0~100%),嚴重度則指病害的嚴重程度,對葉部病害來說,通常使用定性量表和定量量表進行評估。其中,定性量表使用描述性術語將病害嚴重程度描述為幾種類別,如輕度、中度和重度。定量量表通常以百分比表示,即病斑面積與整個葉片面積的比值來表示。
更進一步,則是20世紀下半葉到21世紀初期,高科技、新材料的大量涌現,加上信息爆炸和傳播的全球化,藝術對社會生活各個領域的介入成為勢不可擋的趨勢。早期與綜合材料藝術發展軌跡重合的現成品藝術在此一階段發展成獨立的裝置藝術。而另一個值得注意的現象是,綜合材料作為教學科目普遍進入藝術院校,成為必修和主修課程。這些都說明綜合材料藝術在當代藝術創作中的作用,是非常值得關注。
隨著計算機視覺技術的發展,許多研究者通過圖像處理和機器學習方法進行作物病害的嚴重度評估,該方法具有相同的評估程序[92]。李井祝等[93]利用掃描儀掃描黃瓜霜霉病葉片得到掃描圖像,采用線性運算得到病情指數,平均識別正確率達到98.3%。鮑文霞等[94]提出一種滑窗最大值特征提取方法,對分割后的感染小麥白粉病的葉片圖像采用滑窗法提取HSV顏色特征和LBP紋理特征,以此來識別葉部病害的嚴重度,準確度顯著高于傳統方法。GALLEGO-SANCHEZ等[95]開發了一個開源且用戶友好型的腳本工具RUST,基于顏色特征半自動評估葉銹病。通過以上研究可以發現,嚴重程度的計算結果依賴于圖像分割技術,且已有的研究中大多基于簡單背景的葉片,有的方法只能適用于單一的病害種類,難以應用到實際農業場景下采集的多噪聲、復雜背景的病害葉片中。
深度學習在病害識別方面已經取得重大進展,在病害嚴重度估算方面也有應用。將定性量表和定量量表估算嚴重度轉化為計算機學科問題,可以將嚴重度估算方法劃分為基于分類、基于回歸和基于深度分割的嚴重度估算方法,嚴重度估算研究成果如表4所示。基于分類的方法是指通過定義嚴重度的類別或區間將其轉化為分類問題,采用卷積神經網絡(CNN)建立輸入圖像與嚴重度類別的關聯關系。文獻[96-100]將病害嚴重程度劃分為不同等級進行識別,取得了準確的結果,但是病害的分級難以具體量化病害嚴重度。基于回歸和深度分割的嚴重度估算方法可以得到百分比的病害嚴重度,更具有說服力。基于回歸的嚴重度估算方法是將輸入的病害圖像直接與嚴重度百分比對應起來。張領先等[101]構建一個CNN模型估計黃瓜霜霉病的嚴重度,以手動去除背景的病害圖像作為輸入,證明了CNN的準確性優于淺層機器學習模型,決定系數R2達到0.919 0。然而,這種方法對背景噪聲比較敏感。基于深度分割的嚴重度估算方法是指通過語義分割或實例分割方法為每個像素分配適當的標簽,實現病斑、健康葉片的自動化分割,以獲得百分比的嚴重度。常用的分割網絡包括DeepLab V3+[102]、U-Net[103]、PSPNet和Mask R-CNN。相關研究表明語義分割模型在病害嚴重度估算中的應用是可行的,然而當數據量較小、圖像存在大量復雜背景干擾時,這仍然是一個挑戰。
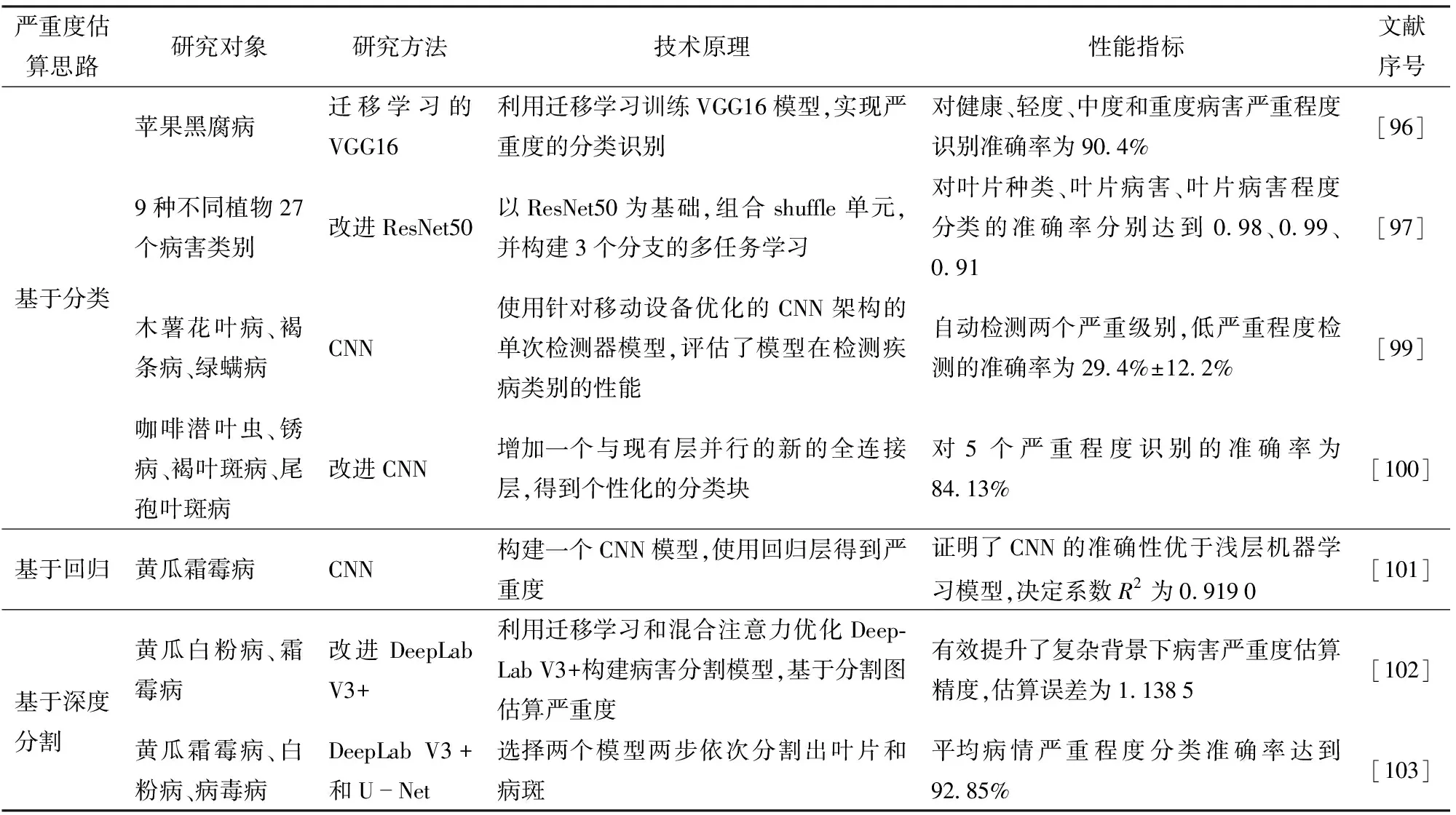
表4 基于深度學習的嚴重度估算研究成果Tab.4 Research on severity estimation based on deep learning
基于深度學習嚴重度估算的思路比較如表5所示。

表5 基于深度學習的嚴重度估算思路特點Tab.5 Characteristics of severity estimation based on deep learning
2.3 基于電子病歷的作物病害處方推薦技術
作物病害處方推薦涉及的關鍵技術包括基于實體關聯的病害機理解析、基于診斷推理的作物病害處方推薦、基于交互式語義匹配的作物病害處方推薦以及面向農戶的作物病害在線問診。
2.3.1基于實體關聯的病害機理解析
作物病害積累的基礎數據可以提供病害的發病癥狀、發病階段、用藥方案等重要信息。作物病害處方數據包含的作物信息、環境信息、病害信息對于作物病害機理解析間接提供了全方位真實數據源,同時基于宿主、病原體和環境的傳統流行病學和植物病理學知識為處方數據分析提供了新的研究視角。
近年來,知識圖譜作為一種語義網絡,具有可擴展性強、支持智能應用等優點,因此在自然語言處理、智能問答系統、智能推薦系統等領域得到了廣泛的應用。知識圖譜(Knowledge graph)的本質是一個由大量實體及其之間的關系組成的大規模知識庫。知識圖譜包含了豐富的語義信息,作為一個龐大的基于知識系統,它相比于結構化數據庫可以敏銳地獲取領域實體間的復雜關聯關系,并將其可視化展示,同時還可將分布于不同信息系統中的零碎知識連接起來。知識圖譜基于圖模型將知識抽象,可以為各領域提供簡潔和直觀的知識展示,其中邊和路徑可以捕獲實體之間不同的、潛在的復雜關系[104],解決了碎片化數據存儲和關聯關系挖掘的問題。
現有的研究已經從各種數據源中確定了藥物和疾病之間的實體[105-107]和關系[108-109],如圖6所示。在下游任務中,知識圖譜可以與機器學習等算法相結合,實現處方推薦[110-112]。同時,基于知識圖譜的推薦面臨著高計算復雜性、缺乏長尾實體、規則沖突、擴展困難和在非結構化EMR中應用的局限性等挑戰[113]。

圖6 作物病害知識圖譜部分展示Fig.6 Part of crop disease knowledge map
2.3.2基于診斷推理的作物病害處方推薦
處方推薦與作物病害的診斷息息相關,一些研究通過機器學習、深度學習或者基于特征融合的多輸入多輸出方法挖掘電子病歷信息,實現作物病害的準確診斷,最后結合規范的病害治療方案來實現有效的作物病害處方推薦。
(1)機器學習方法
機器學習可以從大量數據中挖掘出能夠代表一類事物的規律,從而對事物進行預測、分類和推薦,是挖掘處方數據中有效信息的有力工具。機器學習算法具有計算時間短、精度高、可移植性強的優點,各種有監督和無監督的機器學習方法已經被應用于疾病診斷的研究。例如,VENKATESH等[114]使用大數據預測分析模型,基于樸素貝葉斯(BPA-NB),對不同的診斷結果概率分類,進而給出治療建議,對于UCI機器學習庫中的疾病數據預測準確率為97.12%。WANG等[115]基于處方數據開發的智能處方系統能夠從藥物信息中提取特征,根據問診對象的癥狀預測藥劑,對于同時確診多種病的問診對象減少重復藥劑,給出適當的處方,能夠減少14%潛在的重復處方。GALVEIA等[116]提出了基于隨機森林的分類器模型,用于推薦診療建議。
但是隨著現實應用場景中數據量的激增和多元化,尤其是面對作物處方等具有復雜性和專業性的數據,傳統的分類算法已經不能契合現存實際問題的需求。集成方法被認為是增強機器學習效果的高級解決方案[117],尤其對于分類問題具有較強的優勢[118]。集成學習通過利用基礎算法的多樣性提高模型的分類準確度、泛化能力和魯棒性[119]。機器學習中提出了各種集成學習算法,其中最具代表性的方法是Bagging、Boosting和Stacking。Bagging算法生成并行基學習器,并使用隨機抽樣(bootstrapping)訓練模型[120-121]。Boosting方法依次訓練一系列分類器,將弱分類器提升為強分類器,使錯分的樣本得到更多的關注。其代表性算法有Adaboost、梯度上升決策樹(GDBT)、極限梯度提升(XGBoost)和輕量級梯度提升機(LightGBM)。在以上集成方法中,Stacking模型在分類問題上表現良好,特別是對不平衡數據分類。Stacking模型主要目的是減少泛化誤差。由于單一分類器種類復雜且各具優勢[122],基于不同分類器的Stacking集成備受國內外學者的關注,經研究證明它能夠在不同的應用場景下提高模型分類精度[117-123]。但是機器學習模型仍然沒有解決EMR中的自由文本語義理解問題。
(2)深度學習方法
一些研究將疾病診斷問題轉化為病歷文本的分類問題,通過自然語言處理(NLP)方法挖掘電子病歷信息,實現對疾病的診斷或風險評級。許多研究使用了深度學習方法,如神經網絡(CNN)、循環神經網絡(RNN)和自動編碼器(AE),幫助計算機更好地理解電子醫療記錄的語義[124-126]。例如,ZHANG等[127]提出的無監督深度學習框架能夠注釋電子病歷中的表型異常數據,并使用不同的先驗分布學習文本數據的語義潛在表示,預測診斷結果與處方內容。程銘等[128]基于電子病歷數據,構建混合注意力機制模型,分析病歷文本之間的語義關系,展開處方推薦,同時采用自注意力機制從病歷文本中識別特定病種的病歷表示,將二者進行有機地融合,生成最終的病歷表示,最后構建多標簽分類器進行處方推薦。
深度學習方法通過訓練大量帶有標簽的電子病歷數據,在醫學領域取得了良好的效果。但是在基于植物電子病歷的作物疾病診斷中使用深度學習方法的缺點是缺乏足夠的訓練數據。原因在于CEMRs需要由專業的植物醫生進行標注和記錄,導致樣本量小。變換器和預訓練語言模型[129]的提出為解決訓練數據的局限性提供了一個突破口。預訓練語言模型可以從大量的語料庫中學習通用的語言表征,而不需要人工標注[130]。一些研究在任務領域的數據集上對語言表示模型進行了領域適應性預訓練[131]。例如,DING等[132]提出基于作物疾病領域BERT和RCNN(CdsBERT-RCNN)的作物疾病診斷模型,為進一步實現基于診斷推理的作物病害處方推薦打下基礎。
(3)多輸入多輸出模型
植物電子病歷不是簡單的文本描述,而是經過科學設計的、符合植物病理學中病害診斷基本原理的規范結構,包含結構化的地理、時間、環境、分布等特征。研究證明,病害發生的環境特征、時空分布等信息對病害的準確識別意義重大,但是這些信息在病害智能診斷的研究中尚未得到有效利用[133-134]。如果僅聚焦于植物電子病歷中的單一類型數據,僅對問診記錄文本或者結構化數據進行特征抽取,將會造成大量的信息損失。丁俊琦等[13]提出基于多類型數據融合的病害診斷模型用于解決這個問題。
得到診斷結果后,可以進一步實現處方的推薦,即用藥名稱和數量的確定,一些研究使用多輸出(Multi-output)方法結合機器學習模型實現此功能。以多輸出結合機器學習進行預測的方法在聲學、力學以及通信領域被廣泛應用。ZHOU等[135]將多輸出支持向量機(M-SVM)和多任務學習(MTL)算法相結合,通過解決區域預測中常見的誤差積累問題,有效提高區域多步提前預測的準確性。應啟帆等[136]通過對單種粒徑預測的梯度提升決策樹算法進行組合構建多輸出回歸算法對粒徑分布進行預測。
2.3.3基于語義匹配的作物病害處方推薦
語義匹配是NLP領域的基礎問題之一,被廣泛應用于信息檢索、推薦系統和問答系統等下游任務。基于處方內容語義匹配的處方推薦方法是通過對處方文本展開分析,根據歷史處方數據生成推薦列表,推薦結果更具多樣性,可擴展性更強。語義匹配包括交互型和表示型兩種匹配方式。
(1)交互型語義匹配
基于文本相似度的處方推薦方法是通過分析處方文本中的語義信息,計算向量得到語義相似度,生成推薦列表。ZHANG等[137]提出的電子病歷相似度計算方法,根據檢查項目將電子病歷劃分為不同部分,篩選有效部分后運用詞向量與詞移距離(Word mover’s distance,WMD)計算相似度,最后利用KNN聚類對電子病歷間的相似性進行評價,與LDA和LSI等傳統的疾病分類方法相比,該方法具有較高的召回值,能夠改進處方推薦效果。趙明等[138]基于雙向門控循環單元神經網絡(BiGRU)構建病蟲害問句分類模型,利用問句的語義信息,輔助實現番茄病蟲害智能診療。YE等[139]使用詞嵌入將處方文本語義上相似的詞投射到向量空間中的鄰近點,提升了診療系統的檢索與決策支持功能,證明使用語義相似的術語,可以更快速地檢索和推薦診療建議。邱碩等[140]使用聚類的方法挖掘電子病歷中的處方關聯,依據問診對象相似度實現處方推薦的多樣化,同時程序執行時間有所提升。對于文本相似度計算,深度語義匹配模型(DSSM)通過多層次的語義分析表現更好。XIE等[141]提出的主題增強的語義匹配模型在有關語義匹配的問答庫任務中獲得了21個系統中的第3名,表現出較強的語義分析能力。LARIONOVA等[142]基于推薦系統構建DSSM,學習推薦目標之間的相似性,對不同類別內的推薦對象進行排序,結果表明,DSSM相比傳統相似度推薦方法顯著提高了推薦的總體質量。交互計算更好地把握了語義焦點和上下文重要性,但是計算成本很高。
(2)表示型語義匹配
基于表示型語義匹配的作物病害處方推薦方法核心是句嵌入,在表示層將文本轉換成整體的表示向量之后再進行匹配。在推薦系統中,基于表示的模型可以通過句子嵌入對文本預處理,構建索引,大幅度降低在線計算耗時。基于BERT,REIMERS提出了Sentence-BERT[143],它是目前最常用的BERT式雙塔模型,效果較好,提供方便的開源工具,可以有效緩解處方推薦中的在線計算耗時問題。GAO等[144]提出了一個簡單的句子嵌入的對比學習框架(SimCSE),包括無監督和有監督的版本,實現了基于對比學習和輟學數據增強的句子級語義表示的SOTA性能。
2.3.4面向農戶的作物病害在線問診
問答系統的應用涉及諸多領域,如醫藥、電力、交通等各方面[145]。問答系統技術在農業領域發展迅速,并已經形成了一些相對完整的體系。傳統的農業信息服務多為上網搜索、電話咨詢和專家現場指導等方式,張博凱等[146]基于網絡爬蟲得到的大量農業問答知識數據形成的語料庫,結合命名體識別和知識圖譜查詢推薦算法,設計實現Android端的智能問答機器人,為農業領域智能信息服務提供了一種新的解決方案。張領先等[147]開發了面向移動終端的作物病害處方推薦系統。用戶輸入受害作物的癥狀描述后,系統輸出診斷結果及相應處方,實現了面向實際應用場景的作物病害處方推薦。
3 作物病害診斷與處方推薦研究難點與發展趨勢
3.1 作物病害診斷與處方推薦研究難點
國內外學者在作物病害診斷與處方推薦方面開展了廣泛的研究,既取得了較多的研究成果,也面臨著一些亟需解決的難點。
(1)目前,計算機視覺技術可以實現病原物的持續監測。但是在實際應用中,病菌侵染作物是一個動態的過程,病菌孢子形態和數量在侵染過程中會受到作物抗病性以及環境溫度和濕度等因素影響,使得基于機器視覺技術準確提取與分析病菌孢子形態特征、動態變化規律及其病害三角關系等成為研究的關鍵科學問題和難點。尤其是病菌孢子交叉、遮擋、動態變化等特點導致病菌孢子定量化識別困難等。
(2)熱成像和多光譜成像技術能夠根據內部生理變化檢測發病期之前的早期侵染。但是熱成像受環境影響較大,檢測植物病害時需要嚴格控制環境溫濕度,而對于多光譜成像,許多學者采用光譜指數或者需要選取感興趣區域、圖像分割等處理,過程復雜且受限于人工選取特征。文獻[148-149]證明通過結合各種傳感器系統中包含的豐富光譜,空間、結構和熱信息的優勢來改善植物性狀估計。因此,研究基于多源圖像的病害早期檢測方法,提高病害侵入期的檢測效果。
(3)卷積網絡有強大的特征學習能力,基于卷積神經網絡的作物病害識別方法可以快速、準確地識別病害種類。但是現有研究大都針對公開數據集,部分自己采集的數據也都是簡單背景,在實際應用時受環境等因素影響導致識別精度不夠,因此,針對農業領域復雜背景,高精度、泛化性強的病害識別方法有待于進一步研究。
(4)作物病害嚴重度定量估算效果受病斑分割和特征提取的影響,分割操作繁瑣,易受光照影響,提取特征又有一定的主觀性,會影響模型的泛化能力。因此,研究基于深度學習的自動化作物病害分割方法,可以提高分割精度并計算作物病害嚴重度。
(5)目前關于作物病害的研究大多以設施溫室(小氣候)環境為基礎,多停留在單一數據源的獲取或基于單一作物的小尺度分析,而缺乏從宏觀角度基于數據挖掘解析病害三角原理的研究。而作物病害處方數據幾乎未被應用于輔助處方推薦,其中包含了大量區域性作物信息、環境信息和病害信息及其防治知識,可以解決多源數據采集難的問題。
(6)基于診斷推理的作物病害處方推薦鮮有研究。與常規推薦算法使用的場景不同,處方數據大多為結構化數據,且為多變量數據。Multi-output 結合機器學習模型已廣泛應用于聲學、力學以及通信領域,但是在作物病害治療方案推薦方面鮮有研究。深度學習算法可以根據采集的環境信息及作物生長信息輔助病害診斷,即對應計算機領域的多分類問題,其中集成學習算法對于不平衡數據集的處理具有一定的優勢。同時,還未有研究從多尺度角度利用數據和深度學習算法根據病害發生機理進行病害診斷的研究。
(7)基于語義匹配的處方推薦方法的推薦結果更具多樣性,可擴展性更強。但是,目前相關研究大多是生物醫學領域,農業領域的應用偏少,實現深度語義匹配在農業領域的處方推薦應用將有助于提高病害治理效果。因此,基于語義匹配,尤其是表示型語義匹配的處方推薦是重要的研究方向。
(8)對于我國區域作物生產和小農戶分散種植國情,由于受到數據獲取困難和物聯網技術實施成本高以及作物病害發生態勢復雜和傳播途徑多樣等因素的限制,多應用場景、時空遷移和多目標決策的作物病害早期診斷、預測與主動防控成為難點。因此,基于電子病歷多模態數據的作物病害關聯挖掘與多目標決策研究,將對農業病害防治領域具有更大的實際意義,為實際應用復雜生產場景作物病害早期預警與主動防控提供決策支持和參考。
3.2 作物病害診斷與處方推薦發展趨勢
(1)開展作物病害早期檢測以及定量識別診斷方法的研究是必要的。在病害發病之前,深入挖掘可見光、熱成像、多光譜圖像數據對病害早期特征的解析能力,同時探索多源圖像對侵入期病害檢測的新思路;在病害發病期,提高復雜背景下病害的識別精度,準確量化病害嚴重度,為精準施藥提供依據,對提高作物病害精細化管理水平,提升作物品質有重要意義。
(2)針對作物病害處方推薦過程中,存在由于作物病害致病機理復雜、作物品種及病害種類多、病害病癥動態變化等特點導致缺乏可行的數據挖掘技術等問題,以作物病害處方為研究對象,針對電子病歷數據特點,開展基于機器學習和知識圖譜的作物病害致病機理解析、診斷推理、處方智能化推薦及其應用策略研究;攻克基于知識圖譜分析、大數據挖掘和機器學習算法推理等關鍵技術在作物病害處方數據挖掘分析研究;可視化分析作物病害病癥形態特征、時空變化及其與種植環境和作物品種的病害三角關系,從區域宏觀視角解析作物病害致病機理及其與特征間的關聯關系,面向不同實際應用場景需求實現作物病害精準診斷與處方推薦。研究成果可為作物種植智能診斷提供科學依據和方法支撐,推進農業科技服務新模式、新業態。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
