基于AUC的時間序列Shapelets提取方法
2023-06-22 13:54:08孫其法
現代信息科技 2023年3期
摘? 要:近年來,基于Shapelets的時間序列分類方法受到了廣泛關注。現有的基于Shapelets轉換的時間序列分類方法使用信息增益作為評價Shapelets的標準,并主要關注分類準確率,不能很好地適應不平衡時間序列分類。為了解決上述問題,使用AUC作為提取Shapelets的標準,并用于后續的數據集轉換和分類,最后使用不平衡評價指標F-measure和AUC值對分類結果進行評價。結果顯示,該方法能夠很好地適應不平衡時間序列分類。
關鍵詞:時間序列分類;Shapelets;不平衡數據分類;AUC
中圖分類號:TP311? ? 文獻標識碼:A? ? 文章編號:2096-4706(2023)03-0083-04
AUC-based Time Series Shapelets Extraction Method
SUN Qifa
(Xuzhou Finance and Economics Branch of Jiangsu Union Technical Institute, Xuzhou? 221008, China)
Abstract: In recent years, Shapelets-based time series classification methods have received extensive attention. Existing time series classification methods based on Shapelets transformation use information gain as a criterion for evaluating Shapelets, and mainly focus on classification accuracy, which cannot be well adapted to imbalanced time series classification. In order to solve the above problems, AUC (Area Under the Curve) is used as the criterion for extracting Shapelets and used for subsequent data set transformation and classification. Finally, the classification results are evaluated using the imbalanced evaluation index F-measure and AUC value. The results show that the method can adapt well to imbalanced time series classification.
Keywords: time series classification; Shapelets; imbalanced data classification; AUC
0? 引? 言
時間序列分類[1]問題已經引起了數據挖掘團體極大的興趣,是時間序列數據挖掘領域中的一個重要分支。由于時間序列數據的維度高、高度的特征關聯性和高度的噪聲數據[2],使時間序列分析成為一個感興趣的研究問題。幾乎所有的應用領域都在以前所未有的速度產生時間序列數據,比如,股票市場每天的股價波動[3],基于位置服務對象的位置更新數據[4],傳感器網絡[5]各種各樣的讀數。時間序列數據的高維性、高噪聲以及不平衡性給時間序列數據的分類造成了極大的阻礙[6]。
目前,基于時間序列Shapelets[7]以及Shapelets轉換[8]的分類方法主要使用信息增益來評價Shapelets,并主要關注時間序列Shapelets的提取[9]和篩選[10]。對于數據集的分類結果,多數人還是以數據集的整體分類準確率[11]來衡量分類效果。而對于不平衡數據集來說,盡管分類準確率非常高,這在實際應用中卻不是想要的結果。因此,找到有效的時間序列Shapelets提取方法對于不平衡數據的分類,特別是高維不平衡數據分類,有著重要的意義。
1? 基于AUC的時間序列Shapelets提取方法
在現有的研究工作中,大多數研究者采用了信息增益作為評價候選Shapelets的標準,并取得了不錯的分類準確率[11]。針對不平衡時間序列數據集,本文采用曲線下面積(Area Under the Curve, AUC)來對不同的Shapelets進行評估和提取,使得基于Shapelets的時間序列分類方法更適應不平衡數據集分類。為方便描述,本文將算法命名為DivAUCShapelet。算法偽代碼如下:
算法DivAUCShapelet (T, min, max)
輸入:訓練集T,最小長度min,最大長度max
輸出:所有的候選shapelets
(1)allShapelets =?
(2)for all time series Ti in T
(3)? ? shapelets=?
(4)? ? for? l=min to max do
(5)? ? ? ? Wi,l=generateCandidates(Ti, min, max)
(6)? ? ? ? for all subsequence S in Wi,l
(7)? ? ? ? ? ? for m=0 to |T|
(8)Ds=calcDistance(S,Tm)
(9)? ? ? ? ? ? end for
(10)? ? ? ? ? ? sort(Ds)
(11)AUCvalue=0
(12)for i=0 to | Ds |
(13)? ? ? ? ? ? ? ? ? ? for j=0 to i
(14)Tn=Ds[ j].ts
(15)? ? ? ? ? ? ? ? ? ? ? ? if Tn. label=positive
(16)tp=tp+1
(17)? ? ? ? ? ? ? ? ? ? ? ? else
(18)fp=fp+1
(19)? ? ? ? ? ? ? ? ? ? end for
(20)tpr[i]=tp/#positive
(21)fpr[i]=fp/#negtive
(22)end for
(23)? ? ? ? ? ? AUCvalue=calcAUC(tpr, fpr)
(24)allShapelets.add(shapelets, AUCvalue)
(25)? ? ? ? end for
(26)? ? end for
(27)end for
(28)return allShapelets
算法DivAUCShapelet的第一行是對所有候選shapelets的初始化;第2~5行是對訓練集中的所有時間序列,生成長度最小為min,最大為max的候選shapelets,第5行的generateCandidates()函數使用了SAX技術對時間序列進行降維;第6~10行是對所有的候選shapelets計算它們與訓練集中每一條時間序列之間的距離,然后從小到大排序;第12~22行表示,依次增大閾值,計算閾值下的TPR和FPR值,計算方法如下:使用距離作為閾值,由于Ds中的距離已經排好序,依次選取Ds中的距離作為閾值,小于或等于此閾值的時間序列均被預測為正類,其余的被預測為負類,第14行的Tn表示距離向量Ds第j個位置所對應的時間序列,如果Tn實際的類標號為正類,那么TP的個數加1,否則FP的個數加1,這樣就可以計算出TP和FP的個數,進而得出TPR和FPR值;第23和24行是根據之前計算的多個TPR和FPR值計算每個候選shapelets的AUC值,并把帶有AUC值的shapelets放入allShapelets中;最后返回所有的shapeletsallShapelets。
以上為時間序列shapelets的提取過程,接下來,采用和文獻[12]相同的方法,構造多樣化圖并進行查詢選取出最優的k個多樣化shapelets。最后,利用選出的k個shapelets將原始的數據集轉換并進行分類。
2? 實驗結果及分析
2.1? 數據集
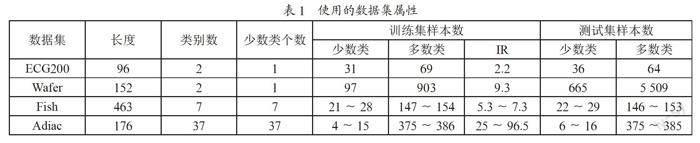
實驗數據選用了來自UCR[13]的ECG200、Wafer、Fish和Adiac共四個數據集,數據集中所有的數據均為實數類型。
表1給出了本次實驗使用的數據集的相關信息,包括數據集名稱、數據集中每條時間序列的長度、類別個數、用作少數類的個數、訓練集和測試集中的樣本數以及不平衡比率IR。
從表1可知,ECG200和Wafer數據集只包含2類數據,多數類和少數類的IR值均大于2,可以視為不平衡的數據集。在Fish和Adiac數據集中,分別包含7類和37類數據,并且多數類和少數類樣本之間的IR值分別在5.3和7.3、25和96.5之間。對于包含多個類的數據集,可以把其中一個樣本數小于1/3的類視為少數類,同時將所有其他類的樣本視為多數類,以此類推。以Fish數據集為例,該數據集共包含7類樣本,每個類的樣本數均在21~28之間。因此,可以將這7類樣本均分別視為少數類,剩下的其他樣本視為多數類,并進行分類操作,最終對所有7類樣本分別進行分類后的結果求平均值。這樣,就可以把包含多類的數據集分類問題轉換為二分類問題。
為了驗證算法的有效性,將DivTopKShapelet方法和DivAUCShapelet方法分別作為時間序列shapelets的提取方法,并利用提取結果分別與C4.5、1NN、Naive Bayes、Bayesian Network、Random Forest和Rotation Forest六種分類算法進行結合,并使用以上數據集運行10遍,最后對結果求平均值。下面將從分類的準確率、分類結果的AUC值以及F-measure值三個維度進行分析。
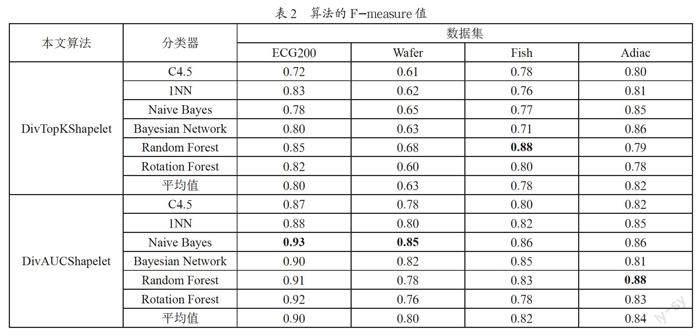
2.2? F-measure值分析
F-measure值是Precision和Recall的加權調和平均,綜合考慮了準確率和召回率,能夠衡量不平衡數據集的分類效果,值越接近1表示分類效果越好。表2為DivTopKShapelet和DivAUCShapelet方法與六種分類器結合使用后的F-measure值,加粗數據為兩種方法對同一個數據集分類得到的最高F-measure值。由表中可知,相比DivTopKShapelet方法,DivAUCShapelet方法在與六種分類器結合使用后,對四個數據集分類的F-measure平均值分別提高了0.10、0.17、0.04和0.02,并使用Naive Bayes分類器在ECG200數據集和Wafer數據集、使用Random Forest分類器Adiac數據集上取得了最好的結果。因此,DivAUCShapelet方法在對不平衡數據集進行分類時相比DivTopKShapelet擁有更好的結果。
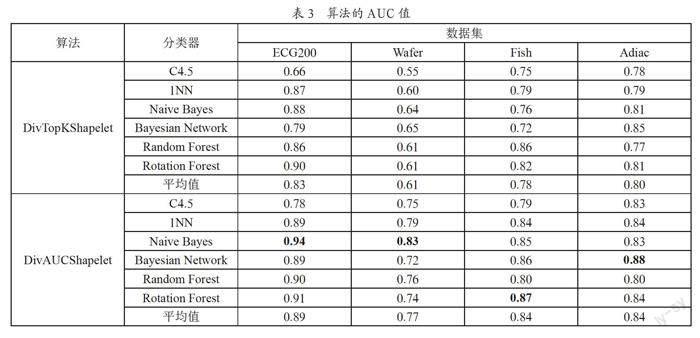
2.3? AUC值分析
表3給出了DivTopKShapelet和DivAUCShapelet方法與六種分類器結合使用后的AUC值,加粗數據為兩種方法對同一個數據集分類得到的最高AUC值。相比DivTopKShapelet方法,DivAUCShapelet方法在與六種分類器結合使用后,對四個數據集分類的AUC平均值分別提高了0.06、0.16、0.06和0.04,并使用Naive Bayes分類器在ECG200數據集和Wafer數據集、使用Rotation Forest分類器在Fish數據集、使用Bayesian Network分類器在Adiac數據集上取得了最好的結果。因此,DivAUCShapelet方法在對不平衡數據集進行分類時相比DivTopKShapelet擁有更好的結果。
3? 結? 論
針對基于時間序列shapelets轉換的算法不能很好地使用不平衡數據集的分類問題,本文使用AUC作為衡量shapelets好壞的標準,提出了一種基于多樣化top-k shapelets的不平衡數據集分類方法,并從分類結果的準確率、AUC值以及F-measure值三個方面進行分析。實驗表明,該方法在不平衡數據集上分類時在多數情況下均優于原本的DivTopkShapelet方法,具有較大的實際應用價值。
參考文獻:
[1] FAOUZI J. Time Series Classification:A review of Algorithms and Implementations [J/OL].Machine Learning(Emerging Trends and Applications),2022:1-34[2022-09-21].https://hal.inria.fr/hal-03558165/document.
[2] 楊海民,潘志松,白瑋.時間序列預測方法綜述 [J].計算機科學,2019,46(1):21-28.
[3] 劉恒,侯越.貝葉斯神經網絡在股票時間序列預測中的應用 [J].計算機工程與應用,2019,55(12):225-229+244.
[4] 潘曉,馬昂,郭景峰,等.基于時間序列的軌跡數據相似性度量方法研究及應用綜述 [J].燕山大學學報,2019,43(6):531-545.
[5] 付國慶.傳感器網絡時間序列數據計算及可視化研究 [D].大連:大連理工大學,2019.
[6] 楊夢晨,陳旭棟,蔡鵬,等.早期時間序列分類方法研究綜述 [J].華東師范大學學報:自然科學版,2021(5):115-133.
[7] GRABOCKA J,SCHILLING N,WISTUBA M,et al. Learning time-series shapelets [C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining.New York:Association for Computing Machinery,2014:392-401.
[8] HILLS J,LINES J,BARANAUSKAS E,et al. Classification of time series by shapelet transformation [J].Data Mining and Knowledge Discovery,2014,28(4):851-881.
[9] 金海波.一種時間序列shapelets快速發現算法 [J].太原科技大學學報,2019,40(3):229-235.
[10] YAN W H,LI G L,Wu Z D,et al. Extracting diverse-shapelets for early classification on time series [J].World Wide Web,2020,23(6):3055-3081.
[11] 閆汶和,李桂玲.基于shapelet的時間序列分類研究 [J].計算機科學,2019,46(1):29-35.
[12] 孫其法,閆秋艷,閆欣鳴.基于多樣化top-k shapelets轉換的時間序列分類方法 [J].計算機應用,2017,37(2):335-340.
[13] Hexagon.The UCR Time Series Classification Archive [EB/OL].[2022-08-25].https://www.cs.ucr.edu/~eamonn/time_series_data_2018.
作者簡介:孫其法(1991—),男,漢族,山東棗莊人,初級職稱,碩士研究生,研究方向:數據挖掘、計算機網絡。
收稿日期:2022-10-20
