基于BERT-BILSTM-CRF的慢性支氣管炎中醫醫案實體識別
2023-06-22 23:25:01帥亞琦李燕陳月月徐麗娜鐘昕妤
現代信息科技 2023年5期
關鍵詞:數據挖掘
帥亞琦 李燕 陳月月 徐麗娜 鐘昕妤

摘? 要:隨著現代信息技術的飛速發展,人類社會開始進入大數據時代,如何高效快捷地從海量的中醫醫案文本數據中挖掘出我們所需要的信息,從而更好地應用于臨床工作,是目前亟待解決的問題。通過實驗對慢性支氣管炎中醫醫案進行研究,分析BERT、BILSTM、BILSTM-CRF和BERT-BILSTM-CRF四種模型的實體識別效果,結果表明,相比于其他模型,采用BERT-BILSTM-CRF模型可以更加準確有效地識別出慢性支氣管炎中醫醫案的實體類別,其F1、Precision和Recall均優于其他模型。
關鍵詞:數據挖掘;命名實體識別;中醫醫案;循環神經網絡
中圖分類號:TP391.1;R2-03 文獻標識碼:A 文章編號:2096-4706(2023)05-0145-05
Entity Recognition of Traditional Chinese Medical Cases of Chronic Bronchitis
Based on BERT-BILSTM-CRF
SHUAI Yaqi, LI Yan, CHEN Yueyue, XU Lina, ZHONG Xinyu
(School of Information Engineering, Gansu University of Chinese Medicine, Lanzhou 730000, China)
Abstract: With the rapid development of modern information technology, human society has begun to enter the era of big data. How to efficiently and quickly mine the information we need from the massive text data of traditional Chinese medicalcases, so as to better apply them to clinical work, which is an urgent problem to be solved at present. Based on the experimental study of traditional Chinese medicalcases of chronic bronchitis, the entity recognition effects of four models, BERT, BILSTM, BILSTM-CRF and BERT-BILSTM-CRF, are analyzed. The results show that compared with other models, the BERT-BILSTM-CRF model can more accurately and effectively identify the entity categories of traditional Chinese medicalcases of chronic bronchitis, and its F1, Precision and Recall are all better than that of other models.
Keywords: data mining; named entity recognition; traditional Chinese medical case; cyclic neural network
0? 引? 言
中醫醫案最早起源于周代,在明清時期,個人醫案專著大量增加,中醫醫案的撰寫量也達到了頂峰。中醫醫案的價值和意義不僅僅局限于現代西醫藥研究方法意義上的科學,它也是祖國醫學上臨床傳承的重要形式。如何從海量的醫案信息中快速準確地獲取用戶感興趣的知識已經成為亟待解決的問題。本文所使用的技術手段稱為命名實體識別技術,命名實體識別一直以來都是信息抽取、自然語言處理等領域中重要的研究任務,本文通過命名實體識別技術識別出慢性支氣管炎中醫醫案中表示實體的成分,并對其進行分類,從而更好地應用于醫療輔助系統、智能診斷系統中,為中醫藥的數字化臨床信息發展提供技術支持。
1? 相關研究
近年來,隨著數據挖掘技術的日益成熟,將數據挖掘技術應用于中醫藥領域成了現代數據挖掘技術研究的熱點話題,在中醫藥方面的研究也取得了優異的成果。面對海量的中醫醫案知識,人的精力和時間是有限的,因此通過自然語言處理技術對醫案里的非結構化數據進行數據挖掘,可以更加有效的提取出醫案里的隱性知識,并將其應用于知識圖譜和知識問答等實際應用中。
早期的實體識別主要是基于規則的方法,人工構建,再從文本中尋找匹配這些規則的字符串以達到實體識別的目的[1]。但是規則的制定是有限的而實體是變換無窮的,所以這樣的方法越來越笨重。統計機器學習的方法需要人工選取詞性、依存句法依賴等可能對任務結構有影響的特征作為模型的輸入[2],所以其命名實體識別效果也有待提高。研究學者們發現神經網絡模型可以自動學習句子特征,無需復雜的特征工程,并且可以通過神經網絡自動挖掘數據的深層次特征進行預測,所以眾多研究學者們開始將最新的深度學習技術應用于NER問題上。Peters[3]等人在2018年首次提出了ELMo(Embeddings from Language Models)模型,但是該模型無法并行計算。在該模型的基礎上,Devlin[4]通過BERT模使用掩蔽語言模型實現了基于預訓練的深度雙向表示,通過使用Transformer架構中的Encoder模塊,使得BERT模型擁有了雙向編碼能力和強大的特征提取能力。而隨著目前的實體識別研究已經將CNN、SVM、BERT等模型應用于語言預處理,并在模型中引用注意力機制來提高實體識別準確率[5]。
目前對于中醫醫案癥狀識別主要使用的是循環神經網絡技術,高佳奕[6]通過LSTM-CRF模型,應用LSTM層結合預訓練字向量抽取醫案的抽象特征,通過CRF進行序列標注,識別的F1值達到了0.85左右。李明浩[7]通過LSTM-CRF模型識別中醫醫案癥狀術語,在小規模訓練集上的訓練,使得F1值最高達到了0.78。肖瑞[8]基于BILSTM-CRF對中醫藥文本數據進行挖掘,使得F1值達到了80.92%。本將BERT模型與BILSTM-CRF模型結合,利用兩者的優勢對慢性支氣管炎中醫醫案進行實體識別。
2? 資料與方法
2.1? 數據來源
本文研究的數據主要來源于《岳美中醫案集》《顏德馨臨床經驗輯要》《世中聯名老中醫典型醫案》等古今部分名老中醫的中醫醫案著作。其中使用了300多條醫案數據。在選定了這些數據后,刪除文本中的特殊字符以及無效信息。以句號作為間隔符將原醫案文本內容進行切分。
2.2? 序列標注
命名實體識別是自然語言處理的一項最基本的任務,其主要目的是從文本中識別出特定命名指向的詞匯。在本文中設定了6種實體類型,并將疾病名、癥狀、證候、治則治法、方藥和舌脈信息,依此記為DIS、SYM、SYN、TRE、PRE和DIA,通過BIO標注,將B表示開始,I表示內部,O表示非實體。本文對標簽的類別以及特征進行了分類,如表1所示。
在序列標注建模方法和序列標注體系下對于中文文本的命名實體識別模型就是要為序列中的每個變量預測出所屬的標簽類別[9]。
3? 模型結構
本文通過BERT-BILSTM-CRF模型進行命名實體識別,該模型主要包括三個部分,首先是BERT預訓練語言模型,慢性支氣管炎中醫醫案的非結構化文本數據轉化為向量形式并提取出蘊含在中醫醫案里的豐富語義特征,再通過BILSTM模型進一步提取出醫案中的上下文特征,最后通過CRF添加約束條件,減少錯誤序列的產生,并輸出最終的標記序列。
3.1? BERT預訓練語言模型
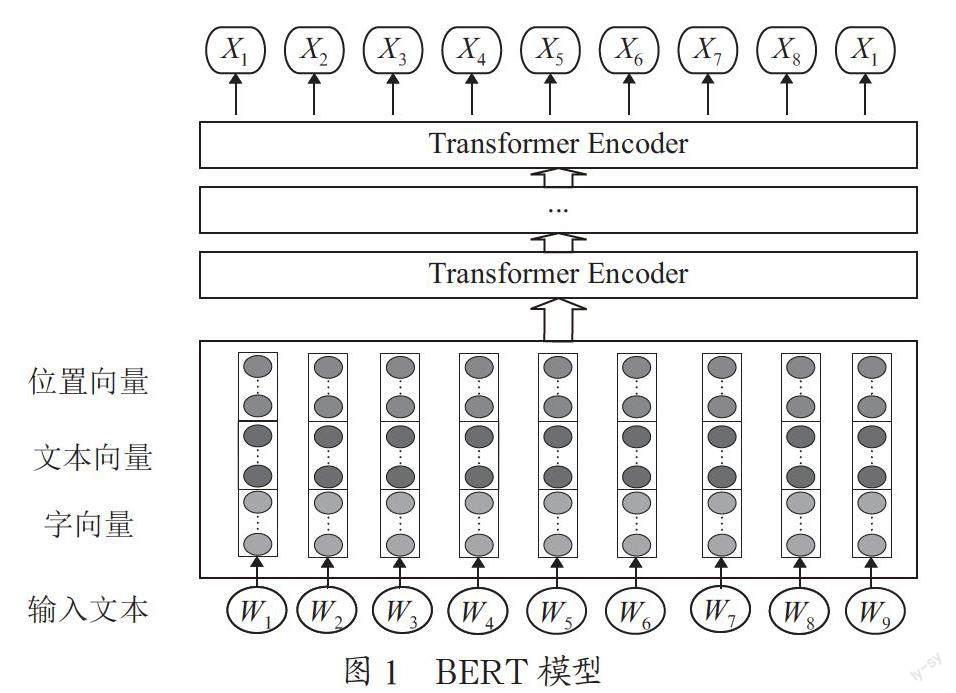
BERT(Bidirectional Encoder Representation from Transformers)模型是一種語言預訓練模型。該模型結構如圖1所示。
本文將原始的醫案文本數據進行數據篩選與標注后,對標注的文本數據進行切分,然后進行向量表示。Transformer結構是BERT的關鍵部分,是基于注意力機制的深度網絡,通過在同一個句子中計算每個詞與其他詞之間的關聯程度來調整權重稀疏矩陣,從而獲得詞的特征向量的表達。本文通過Transformer的Encoder層獲得具有上下文豐富語義特征的文本序列向量,然后輸出向量,,作為命名實體識別模型的Embedding層,輸入到BILSTM模型中。
3.2? BILSTM模型
LSTM(Long-Short Time Memory)模型最早由Hochreiter[10]
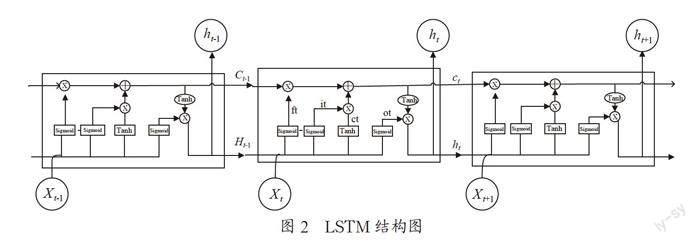
提出,是一種特殊的循環神經網絡,該網絡結構中隱藏單元的內部結構十分復雜,通過引入記憶單元和門控記憶單元保存歷史信息、長期狀態,使用門控來控制信息的流動,有效的實現了上下文信息的存儲和更新,如圖2所示。
每個LSTM單元都通過遺忘門、輸入門和輸出門三種結構來控制信息狀態,LSTM單元內部的計算公式為:
ft =Sigmoid(Wf×[ht-1, xt]+bf)? ? ? ? ? ? ? ? ? ?(1)
it =Sigmoid(Wi×[ht-1, xt]+bi)? ? ? ? ? ? ? ? ? ?(2)
ot =Sigmoid(Wo×[ht-1, xt]+bo)? ? ? ? ? ? ? ? ? (3)
Ct =ft*Ct-1+it*tanh(Wc×[ht-1, xt]+bc)? ? ? ? ? ? ? (4)
ht =ot*tanh(Ct)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (5)
如圖所示,LSTM的輸入有三個,當前時刻輸入xt、上一時刻LSTM的輸出值ht-1以及上一時刻的單元狀態Ct-1;輸出有兩個,當前時刻LSTM的輸出值ht和當前時刻的單元狀態。LSTM模型通過三個門結構實現了對信息狀態的選擇性輸出。其中,W和b表示權重和偏置項,式(1)為遺忘門狀態更新公式,[ht-1, xt]表示把兩個向量組成的一個更長的向量。Sigmoid函數的作用是將門的輸出值限制在0到1之間,當門輸出為0時,任何向量與之相乘都會得到0向量,這就相當于什么都不能通過;輸出為1時,任何向量與之相乘都不會有任何改變,這就相當于什么都可以通過[11]。
式(1)決定上一時刻的單元狀態Ct-1有多少保留到當前時刻Ct;式(2)為輸入門的狀態更新公式,決定當前網絡的輸出xt有多少保存到狀態單元Ct。式(3)為當前時刻單元的狀態計算公式;式(4)(5)為輸出門的計算公式,決定控制單元狀態Ct有多少輸出到LSTM的當前輸出值ht。顯然,當前LSTM單元的隱藏狀態ht依賴于先前的隱藏狀態ht-1,但與下一個隱藏狀態ht+1不相關,即信息僅在單向LSTM中向前流動。這使得LSTM模型存在梯度消失或梯度爆炸的現象。
2005年,GRAVES[12]根據LSTM和雙向RNN模型,提出了BILSTM模型,該模型可以同時使用時序數據中某個輸入的歷史和未來的信息,從而增加循環神經網絡中可以利用的信息,使得模型具有更加強大的特征提取能力。本文在BERT預訓練語言模型的基礎上使用了BILSTM模型,通過慢性支氣管炎醫案數據中的雙向語義信息即潛在的語義關系,優化了循環神經網絡(RNN)模型的迭代性問題,緩解了梯度消失或梯度爆炸的現象,提高了對序列數據的長期記憶能力。
3.3? CRF模型概述
條件隨機場(Conditional Random Fields,CRF)作為一種條件概率分布模型被用于命名實體識別。在命名實體識別領域,其最主要的功能上在多種可能的標注序列中,挑選出一個概率最大的標注序列作為我們對這句話的標注。雖然BILSTM模型能夠輸出標簽取值的概率值,但是直接用BILSTM模型輸出的標簽有些并不是合理的,原因是未考慮標簽與標簽之間的關聯性,比如實體的頭部必不可能是I開頭,O標簽后的下一個標簽必不可能是I,B-Dis標簽后面必為I-Dis等,因此在BILSTM模型后面加入CRF層加入約束機制,這樣就可以調整輸出的標簽,使得標簽的結果順序更加的合理,從而提高模型的準確率。在本文任務中,主要應用的是線性鏈條件隨機場,其原理如式(6)為[13]:
(6)
其中,Z(x)表示歸一化因子,Z(x)和s(x, y)的計算公式為:
(7)
s(x, y)=∑ i Emit(xi, yi)+Trans( yi-1, yi)(8)
其中,Emit(xi, yi)表示LSTM的輸出概率,Trans( yi-1, yi)表示對應的轉移概率,也是CRF轉移概率對應的數值。
4? 實驗結果及分析
4.1? 評估指標
本次命名實體識別任務通過查準率(Precision,P)、召回率(Recall,R)和F1值作為飾演的評價指標。其計算公式為:
(9)
(10)
(11)
其中,TP為實際為正被預測為正的樣本數量,表中FP為實際為負但被預測為正樣本數量,FN為實際為正但被預測為負的樣本的數量[14]。
4.2? 實驗方案
本文首先對慢性支氣管炎醫案數據進行了爬取,然后在眾多的醫案數據中,篩選出慢性支氣管炎中醫醫案數據,刪除掉醫案中的數據來源等冗余信息,然后對醫案數據進行分詞和BIO標注,將標注好的醫案數據輸入到命名實體識別模型中,進行實體識別。為驗證本文所使用模型在慢性支氣管炎中醫醫案的優勢,與下列幾種模型進行了實驗對比。
4.2.1? BERT模型
實驗使用的是Googel提供的預訓練好的中文BERT模型,獲取上下文本中的豐富語義信息,采用Transformers進行預訓練,以此生成深層的雙向語言表征信息。本文所使用的BERT模型的相關參數設置為:學習率為0.001,12個編碼層,12個注意力機制和768個隱藏單元,預先迭代100個epoch測試,然后根據結果調參。
4.2.2? BILSTM模型
將標注好的信息輸入到雙向的BILSTM模型,然后將前向和后向提取的字特征向量拼接到一起作為最終的字向量特征,最后輸入分類層,softmax函數后得到每個標簽的分值,其中分值最大的就是該字的標簽,用交叉熵作為損失,梯度下降方法更新整個模型參數。本文BILSTM模型的相關參數設置為:輸入層的batch_size為300,每個詞用128維的向量表示,隱藏層的維度為256,學習率為0.001,也用交叉熵損失。
4.2.3? BILSTM-CRF模型
雙向的BILSTM模型可以捕捉正向信息和反向信息,使得模型對文本的利用效果更佳的全面,然后通過CRF層添加約束條件,使得模型的y預測結果更加的精確減少錯誤序列的出現。本文所使用的BILSTM-CRF模型的相關參數設置為:輸入層的單句文本長度為300,每個詞用128維的向量表示,隱藏層的維度為256,學習率為0.001,也用交叉熵損失,優化器選擇Adam優化算法。
4.3? 實驗結果對比及分析
本文的所有實驗模型都是基于PyTorch框架,使用GPU為GTX1650,為驗證模型的效果,本文將BERT-BILSTM-CRF模型與BERT、BILSTM、BILSTM-CRF三種模型進行對比,通過評價指標來驗證BERT-BILSTM-CRF模型的效果。實驗對比結果如表2所示。
根據表2可以看出,本文所采用的BERT-BILSTM-CRF模型整體效果優于其他模型。表中的所有實驗數據是在不同的迭代次數下所取得最優值,通過比較發現,BERT-BILSTM-CRF模型在各個測量指標上都能達到最優值。從表中可以看出,BILSTM-CRF模型的效果比BILSTM模型的識別效果好,這是因為CRF層不同于BILSTM模型,CRF計算序列時計算的是聯合概率,考慮的整個句子的局部特征的線性加權組合,優化的是整個序列,而不是僅僅的將每個時刻的最優拼接起來,因此,CRF層的添加使得BILSTM-CRF模型的整體效果優于BILSTM模型。在表中,雖然BERT模型的識別效果不如BILSTM模型,但是BERT模型的動態詞向量的獲取能力很強,在詞向量的表現上優于BILSTM-CRF模型的embedding層,借助BERT預訓練模型的優點,使得BERT-BILSTM-CRF模型的識別效果整體優于BILSTM-CRF模型。BERT-BILSTM-CRF模型的評價指標變化趨勢如圖3所示。
從圖中可以看出,該模型在迭代了100次后,三種評價指標在一定范圍內上下波動,開始出現震蕩,表明該模型訓練趨于穩定,不會出現大幅度波動。該模型的訓練集損失函數和驗證集損失函數如圖4所示。
從圖中可以看出,該模型在從0個Epoch開始,Loss開始大幅度下降,當到達100個Epoch后,開始趨于穩定狀態,也驗證了圖三的評價指標變化趨勢是在100個Epoch后模型的評價指標開始在一定范圍內上下波動,評價指標沒有出現大幅度上升或下降。從圖四中可以看出,在150個Epoch后,隨著Epoch的增加,Dev_loss開始有上升趨勢,在圖三的同一Epoch上,評價也同時上升,這說明開始出現過擬合現象。在模型訓練過程中,模型的狀態變化為從最開始的不擬合狀態,進入優化擬合狀態,當隨著Epoch的增加,當到達一定程度時,神經網絡開始出現過擬合現象。所以該模型的Epoch應該設置為100~150次左右。
5? 結? 論
本文基于BERT-BILSTM-CRF模型對慢性支氣管炎中醫醫案進行命名實體識別,通過該模型,實現了對慢性支氣管炎中醫醫案的實體識別并獲得了良好的效果。首先通過BERT預訓練模型抽取出了豐富的文本特征,然后通過BILSTM模型提取出實體所需要的特征信息,最后通過CRF層計算出最優的序列標注,并輸識別結果。然后將該模型與BERT、BILSTM和BILSTM-CRF進行對比實驗,通過對比我們發現BERT-BILSTM-CRF模型對慢性支氣管炎中醫醫案上的實體識別效果最好,其F1值、P值和R值相比于其他模型的都高。命名實體識別模型較多,但用于中醫藥相關命名實體識別模型數量微乎其微,構建中醫藥相關命名實體識別模型,將更加有效地推動中醫藥文本挖掘發展。本文提出的方法解決了慢性支氣管炎中醫醫案實體識別效率一般的問題,也為深度挖掘慢性支氣管炎中醫醫案里的隱性知識提供了技術支撐。
參考文獻:
[1] 吳信東,李嬌,周鵬,等.碎片化家譜數據的融合技術[J].軟件學報,2021,32(9):2816-2836.
[2] 鐘華帥.基于深度學習的實體和關系聯合抽取模型研究與應用[D].廣州:華南理工大學,2020.
[3] PETERS M E,NEUMANN M,IYYER M,etal. Deep Contextualized Word Representations[J/OL].arXiv:1802.05365[cs.CL].[2022-10-03].https://arxiv.org/abs/1802.05365v1.
[4] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers forLanguage Understanding[J/OL].arXiv:1810.04805 [cs.CL].[2022-10-03].https://arxiv.org/abs/1810.04805.
[5] GAJENDRAN S,MANJULA D,SUGUMARAN V. Character level and word level embedding with bidirectional LSTM–Dynamic recurrent neural network for biomedical named entity recognition from literature[J/OL].Journal of Biomedical Informatics,2020,112[2022-10-02].https://linkinghub.elsevier.com/retrieve/pii/S1532046420302367.
[6] 高佳奕,楊濤,董海艷,等.基于LSTM-CRF的中醫醫案癥狀命名實體抽取研究[J].中國中醫藥信息雜志,2021,28(5):20-24.
[7] 李明浩,劉忠,姚遠哲.基于LSTM-CRF的中醫醫案癥狀術語識別[J].計算機應用,2018,38(S2):42-46.
[8] 肖瑞,胡馮菊,裴衛.基于BiLSTM-CRF的中醫文本命名實體識別[J].世界科學技術-中醫藥現代化,2020,22(7):2504-2510.
[9] 顧溢.基于BiLSTM-CRF的復雜中文命名實體識別研究[D].南京:南京大學,2019.
[10] HOCHREITER S,SCHMIDHUBER J. Long Short-Term Memory [J].Neural computation,1997,9(8):1735-1780.
[11] 山夢娜.基于深度學習的遙測數據異常檢測[D].西安:西安工業大學,2020.
[12] GRAVES A,SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures [J].Neural Networks,2005,18(5-6):602-610.
[13] 楊云,宋清漪,云馨雨,等.基于BiLSTM-CRF的玻璃文物知識點抽取研究[J].陜西科技大學學報,2022,40(3):179-184.
[14] 高經緯,馬超,姚杰,等.基于機器學習的人體步態檢測智能識別算法研究[J].電子測量與儀器學報,2021,35(3):49-55.
作者簡介:帥亞琦(1998—),男,漢族,山東濰坊人,碩士研究生在讀,主要研究方向:知識圖譜;通訊作者:李燕(1976—),女,漢族,甘肅蘭州人,教授,碩士研究生,主要研究方向:中醫藥數據挖掘、中醫藥知識圖譜;陳月月(1997—),女,漢族,山東濱州人,碩士研究生在讀,主要研究方向:知識圖譜;徐麗娜(1996—),女,漢族,甘肅定西人,碩士研究生在讀,主要研究方向:數據挖掘;鐘昕妤(1996—)女,漢族,浙江嘉興人,碩士研究生在讀,主要研究方向:數據挖掘。
收稿日期:2022-10-26
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
