一種基于層疊指針網絡的實體關系抽取
2023-06-25 18:39:52李世龍張浩軍李大嶺王家慧齊晨陽
現代信息科技 2023年7期
李世龍 張浩軍 李大嶺 王家慧 齊晨陽

摘? 要:通過對知網上252篇有關新工科的典型教育研究文獻進行實體關系人工標注,建立了高等教育領域新工科視角下實驗數據集NEDS(New Engineering Data Set),設計了一種層疊指針網絡模型。實驗結果表明,在高等教育領域NEDS上該模型表現突出,其精確率、召回率和F1值分別達到了83.56、76.25和79.74,很好地解決了關系重疊問題。
關鍵詞:新工科;實體關系抽取;層疊指針;關系重疊
中圖分類號:TP391? 文獻標識碼:A? 文章編號:2096-4706(2023)07-0011-05
Abstract: By artificially labeling the entity relationship of 252 typical educational research literatures on new engineering on CNKI, the experimental dataset NEDS (New Engineering Data Set) from the perspective of new engineering in the field of higher education is established, and a cascading pointer network model is designed. The experimental results show that the model performs well in NEDS in the field of higher education, and its accuracy, recall and F1 values reach 83.56, 76.25 and 79.74 respectively, and solve the problem of relationship overlap.
Keywords: new engineering; entity relationship extraction; cascading pointer; relationship overlap
0? 引? 言
近年來,新工科等教育改革人才培養模式被提出,大量教育學者在該領域進行探索研究。本文聚焦新工科教育改革領域,建立了高等教育領域新工科視角下實驗數據集NEDS,通過引入實體關系抽取技術,實現人工智能輔助,來提高高等教育研究者的研究效率。
信息抽取是知識圖譜構建的重要環節,將非結構化或半結構化文本轉換為結構化的數據。命名實體識別和關系抽取是信息抽取的兩個重要子任務。命名實體識別是從文本中識別出具有特別意義的實體信息,而關系抽取是從本文中實體的語義關系,得到(主體,關系,客體)三元組信息。
1? 相關工作
實體關系抽取,主要包含流水線式和聯合式兩種方法。
1.1? 流水線式方法
流水線式方法分為兩步,先進行命名實體識別再關系抽取,最后整合成三元組信息。
1.1.1? 命名實體識別
命名實體識別是指識別文本中有意義、有價值的實體并將其歸入到指定類別的任務,是理解文本意義的基礎,是構建知識圖譜的核心技術。早期命名實體識別主要以統計模型作為主流方法,常用的統計方法有隱馬爾科夫模型(HMM)和條件隨機場(CRF)[1]等,它們的準確率在很大程度上依賴于自然語言處理(NLP)工具和人工標注特征。隨著深度學習在不同領域的普及,越來越多的深度學習模型被提出解決實體識別問題。Collcbert等人[2]采用卷積神經網絡(CNN)和條件隨機場(CRF)疊加在單詞嵌入中來處理NLP任務。然后,循環神經網絡(RNN)在命名實體識別任務中表現出比其他神經網絡更好的性能。Chiu和Nichols[3]使用混合雙向LSTM和CNN架構來學習單詞和字符級特征,減少了特征工程的需要。Shen等人[4]采用深度學習與主動學習相結合來進行命名實體識別,取得了較好的表現。Huang等人[5]提出將BI-LSTM和CRF聯合模型作為NLP序列標注工作。
1.1.2? 關系抽取
實體關系描述了存在實物之間的關聯關系,它被定義為兩個或兩個以上實體之間的某種聯系,是知識圖譜構建的基礎。關系抽取就是從文本中自動檢測和識別出實體之間的某種語義關系。閆雄[6]等人采用自注意力機制和CNN相融合計算序列中詞之間的相互關系,提升了關系抽取的效果。Gan等人[7]提出了了子序列實體注意LSTM網絡(EA-LSTM)用于關系抽取,具有較好的效果。流水線方式存在誤差傳播問題,忽略命名實體識別和關系抽取兩個任務之間的相關性。
1.2? 聯合式抽取方法
聯合式抽取方法的出現,改善了誤差傳播問題并且能夠有效地利用兩個任務之間的相關性。Miwa和Bansal[8]提出了基于端對端的神經網絡模型來進行實體關系聯合抽取,他們通過在雙向序列LSTM-RNNs上疊加雙向樹狀LSTM-RNNs來捕獲詞序列和依賴樹子結構信息,但忽略了實體標簽之間的遠距離依賴。Zheng[9]等人提出了一種混合神經網絡模型來提取實體及其關系,而不需要任何手工特征,該混合神經網絡包含用于實體提取的雙向編碼器-解碼器LSTM模塊(BiLSTM-ED)和用于關系分類的CNN模塊,BiLSTM-ED得到的實體上下文信息再傳遞給CNN模塊,以改進關系分類。Li等人[10]將混合神經網絡應用在生物醫學文本中進行實體關系聯合抽取。Zheng[11]等人提出了一種新的標記方案,該標記策略將涉及序列標注任務和分類任務的關系抽取轉化為序列標注任務,并且采用端到端的神經網絡模型直接抽取實體-關系-實體三元組信息。Eberts等人[12]采用的共同聯合范式為特征,該范式共享相同的編碼器并為所有任務提及表示,同時為實體識別和關系抽取保留獨立的解碼器,以多任務方式聯合訓練,但該方法并未解決關系重疊問題。
關系重疊是指一個實體與另一個實體之間存在多種關系,或者一個實體與多個不同的實體間存在多種關系。針對這種情況,Wei[13]等人提出了一種新的標記框架CASREL,該框架通過一種級聯二進制表示將關系看作為主體和客體所映射出的函數,來處理關系重疊問題。
2? 一種基于層疊指針網絡實體關系抽取模型
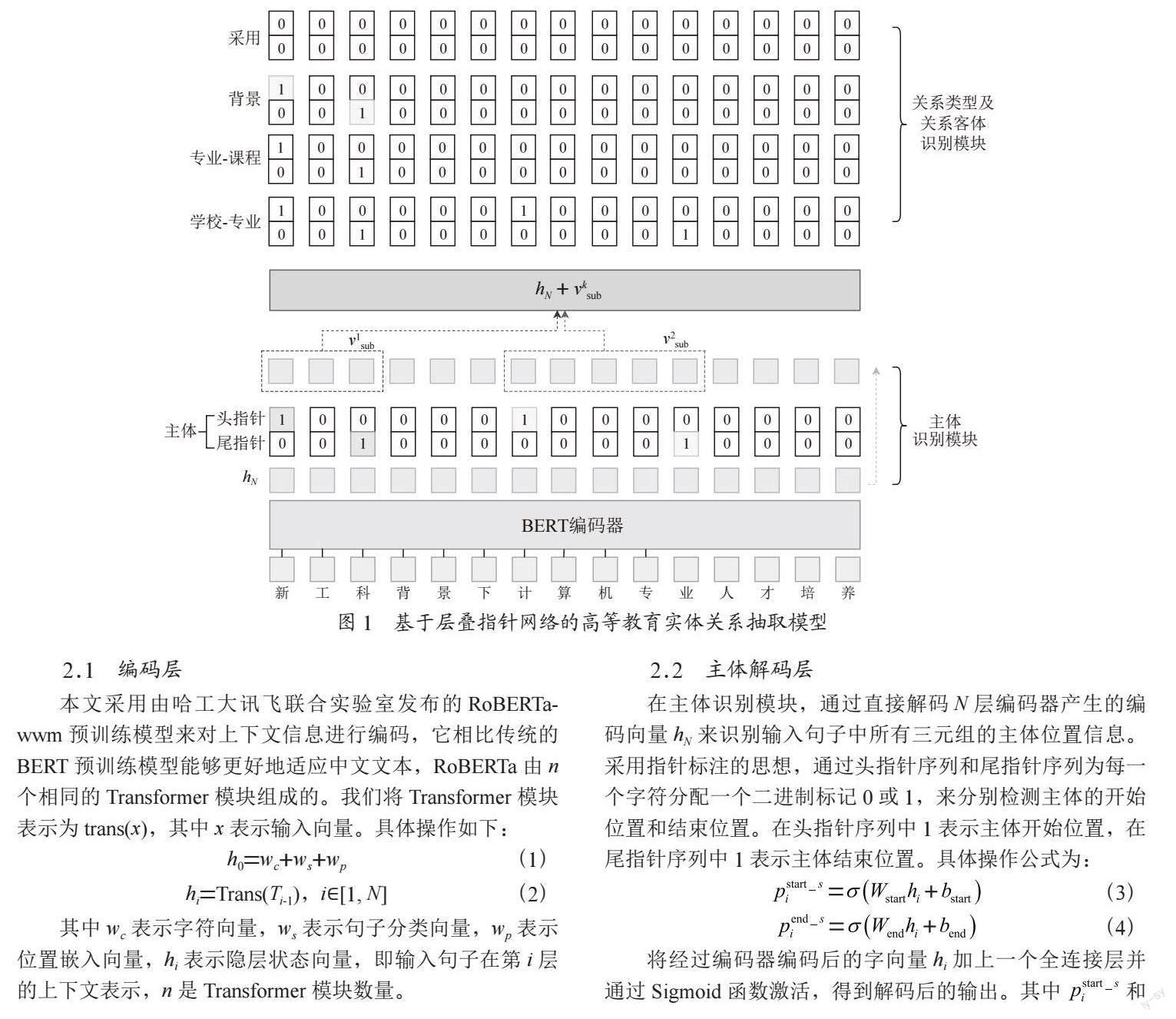
Liu等人[14]提出的RoBERTa模型,該模型在BERT的基礎上提高了模型規模、算力和數據量。Wei[13]等人提出的級聯指針二進制標記框架將關系看作為主體和客體所映射出的函數。綜合上述方法設計一種層疊指針網絡的高等教育領域實體關系抽取模型,該模型包含三個模塊,我們通過梯度下降以參數共享的方式共同訓練。首先,基于BERT的編碼器將句子嵌入到潛在空間中;其次,主體識別模塊來預測主體的頭和尾的位置序列,通過BERT詞向量加上一個全連接層去預測一個二分類的問題;最后,關系及客體識別模塊隨機拿一個主體來預測關系和客體的關系位置矩陣,如圖1所示。
2.1? 編碼層
本文采用由哈工大訊飛聯合實驗室發布的RoBERTa-wwm預訓練模型來對上下文信息進行編碼,它相比傳統的BERT預訓練模型能夠更好地適應中文文本,RoBERTa由n個相同的Transformer模塊組成的。我們將Transformer模塊表示為trans(x),其中x表示輸入向量。具體操作如下:
其中wc表示字符向量,ws表示句子分類向量,wp表示位置嵌入向量,hi表示隱層狀態向量,即輸入句子在第i層的上下文表示,n是Transformer模塊數量。
2.2? 主體解碼層
在主體識別模塊,通過直接解碼N層編碼器產生的編碼向量hN來識別輸入句子中所有三元組的主體位置信息。采用指針標注的思想,通過頭指針序列和尾指針序列為每一個字符分配一個二進制標記0或1,來分別檢測主體的開始位置和結束位置。在頭指針序列中1表示主體開始位置,在尾指針序列中1表示主體結束位置。具體操作公式為:
將經過編碼器編碼后的字向量hi加上一個全連接層并通過Sigmoid函數激活,得到解碼后的輸出。其中? 和? 分別表示將輸入序列中的第i個標識為主體的開始和結束位置的概率。如果概率超過某個閾值,則被標記為1,否則將被標記為0。hi表示輸入序列中第i個位置的編碼表示,即:hi=hN[i],其中W表示可訓練權重,b是偏置σ表示Sigmoid激活函數。
2.3? 關系及客體解碼層
該模塊同時識別關系以及相對應的客體。其結構和主體識別模塊類似,將主體編碼器的頭、尾指針向量序列變換為關系和客體位置矩陣。解碼方式與主體識別模塊直接對編碼向量hN進行解碼不同,關系及客體解碼器還考慮了主體特征。具體操作公式為:
其中? 和? 分別表示為在當前關系下,輸入序列中的第i個標識為客體的開始和結束位置的概率, 表示在主體識別模塊中檢測到的第k個主體的編碼向量。實體通常由多個漢字組成,為了保證主體的向量維度一致性,將構成主體的每個漢字編碼向量的平均值來作為主體的特征表示。
2.4? 損失函數
在主體識別模塊中,目標函數的定義如下:
其中Pθ (s|x)是主體識別模塊中輸入文本序列為x,參數θ={Wstart, bstart, Wend, bend}預測主體s的目標函數;L是輸入句子長度; 是文本x中第i個標記的主體開始或結束位置的二進制標記。
在關系客體識別模塊中,目標函數的定義如下:
其中Pr (o|s, x)表示當關系類別為r,并且在輸入文本x和所選主體為s的條件下預測客體o的目標函數;L是輸入句子長度, 是文本x中第i個標記的主體開始或結束位置的二進制標記。
結合兩個目標函數,模型的最終損失函數為:
其中N是輸入樣本的數量。綜合上述公式可知,0≤P≤1使得q接近于0,當標簽y=1時,則放大了損失的權重;當標簽y=0時,所對應的? 就更小,使得初始狀態符合目標分布,最終實現加速收斂。
3? 實驗分析
3.1? 數據集
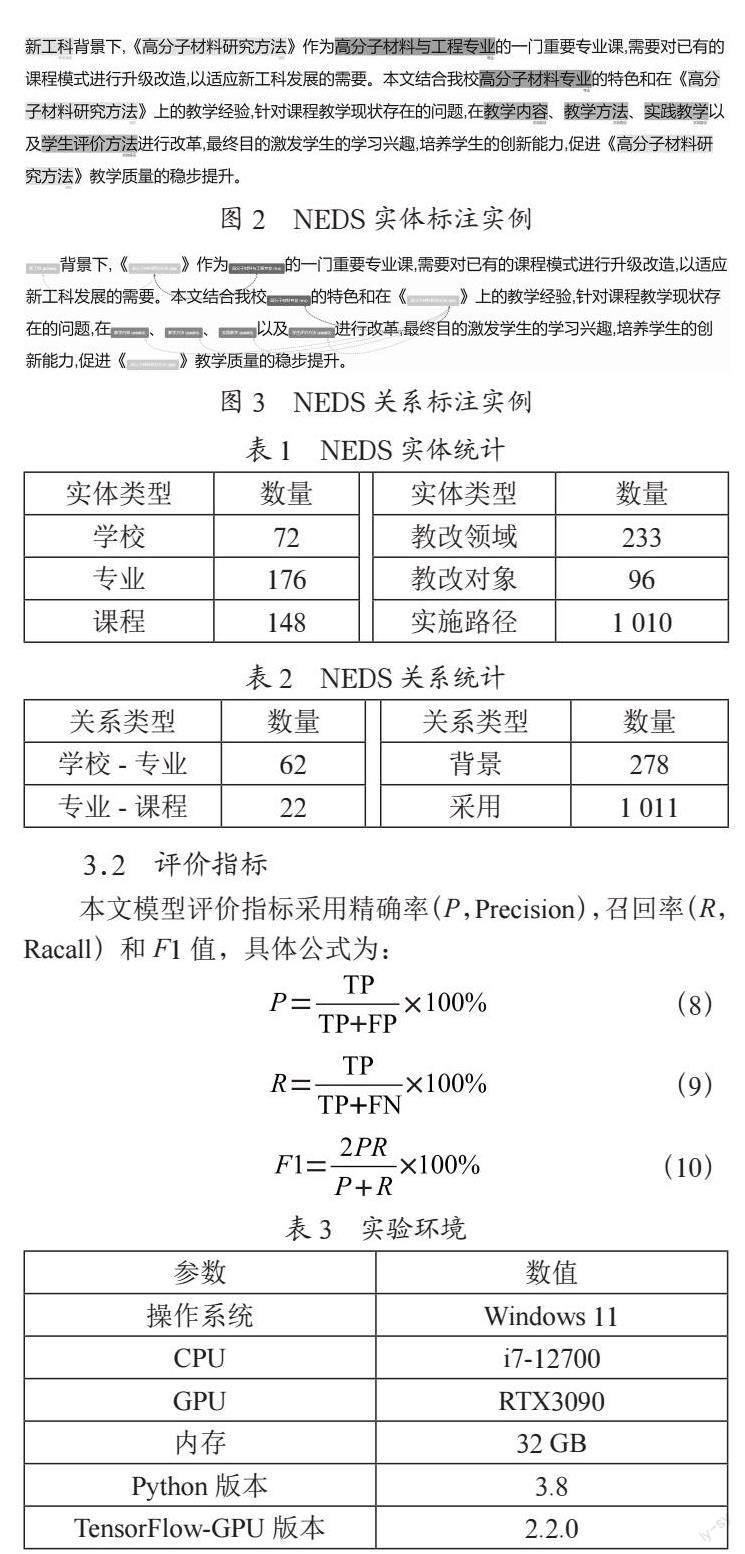
實驗原始數據來自中國知網,選自高等教育領域新工科視角下的北大核心文獻,共計252篇構成新工科數據集NEDS對其摘要部分進行人工標注,將其劃分為訓練集162篇,測試集45篇,驗證集45篇。由小組討論定義實體與關系類型,通過標注工具進行人工標注,如圖2、圖3所示。NEDS數據集包含六個實體類型、四個關系類型,統計情況如表1和表2所示。
3.2? 評價指標
本文模型評價指標采用精確率(P,Precision),召回率(R,Racall)和F1值,具體公式為:
其中,TP為模型預測出的三元組信息與文本數據中正確的三元組信息相同的個數,FP為模型預測出的三元組信息不屬于文本數據中正確的三元組信息的個數,FN為模型未能預測出正確三元組的個數。
3.3? 實驗環境
本文實驗環境如表3所示。
3.4? 參數設計
本文模型參數設計:BERT預訓練模型Chinese_Roberta_wwm_ext_L-12_H-768_A-12,學習率為0.000 01,批量大小為8,句子最大長度為512,模型優化器選擇Adam,Sigmoid函數閾值0.5,字嵌入維度768。
3.5? 實驗結果與分析
為驗證本文模型的有效性,在自建數據集NEDS上與其他三種方法進行了實驗對比。可分為兩類:流水線式抽取方法和聯合式抽取方法。
對于流水線式的抽取方法,先命名實體識別然后進行關系抽取,本文模型與以下兩種流水線式的方法進行對比:
1)BERT+LSTM:使用BERT-CRF進行命名實體識別,然后使用LSTM進行關系抽取。
2)BERT+BiLSTM:使用BERT-CRF進行命名實體識別,然后使用BiLSTM進行關系抽取。
對于聯合式的抽取方法,本文模型與Casrel進行了實驗對比。
3)Casrel:Wei[13]等人提出的新的級聯二進制標記框架的聯合抽取模型,它將關系建模為映射到句子中對象的函數,很好的解決了關系重疊問題。
從表4可以看出本文模型與流水線式抽取方法BERT+LSTM和BERT+BiLSTM相比在NEDS數據集上表現更為優秀,F1值分別提高了23.37%和14.17%,這是因為本文模型沒有誤差傳播問題,加強了命名實體識別和關系抽取兩個子任務之間的依賴性,并且本文模型所使用的指針網絡相比序列標注能夠更好地解決關系重疊問題。Casrel模型和本文模型對關系重疊問題都有著不錯的表現,本文模型與Casrel模型在精確值、召回率和F1值分別有2.03%、0.82%和1.39%的提升。主要原因是在編碼層上本文模型使用了RoBerta對輸入句子進行編碼,與BERT模型相比,能夠更好地適應中文語料并且在模型規模、算力和數據量上都有所提高;在解碼層上本文采用層疊指針標注策略,提高了對關系重疊問題的識別率。
為了更形象的表示本文模型性能,將上述模型的實驗迭代過程進行對比,如圖4所示,本文模型相比其他模型在更短的訓練周期達到穩定,并且能夠在最短的訓練周期達到最高的F1值,進一步體現了本文模型的有效性。
4? 結? 論
本文在高等教育領域新工科視角下定義了6種實體類型和4種關系類型并構建了NEDS數據集。設計了一種基于指針網絡的實體關系抽取方法,通過實驗,本文模型在自建數據集NEDS上的精確率、召回率和F1值分別達到了83.56、76.25、79.74,為后續構建教育改革類知識圖譜提供了數據支持。
參考文獻:
[1] LAMPLE G,BALLESTEROS M,SUBRAMANIAN S,et al. Neural Architectures for Named Entity Recognition [J/OL].arXiv:1603.01360 [cs.CL].[2022-10-06].https://arxiv.org/abs/1603.01360v1.
[2] COLLOBERT R,WESTON J,BOTTOU L,et al. Natural Language Processing (almost) from Scratch [J].The Journal of Machine Learning Research,2011,12:2493-2537.
[3] CHIU J P C,NICHOLS E. Named Entity Recognition with Bidirectional LSTM-CNNs [J].Computer Science,2016,4:357-370.
[4] SHEN Y Y,YUN H,LIPTON Z C,et al. Deep Active Learning for Named Entity Recognition [J/OL].arXiv:1707.05928 [cs.CL].[2022-10-06].https://arxiv.org/abs/1603.01360v1.
[5] HUANG Z H,WEI X,KAI Y. Bidirectional LSTM-CRF Models for Sequence Tagging [J/OL].arXiv:1508.01991 [cs.CL].[2022-10-06].https://arxiv.org/abs/1508.01991.
[6] 閆雄、段躍興、張澤華.采用自注意力機制和CNN融合的實體關系抽取 [J].計算機工程與科學,2020,42(11):2059-2066.
[7] GAN T,GAN Y Q,HE Y M. Subsequence-Level Entity Attention LSTM for Relation Extraction [C]//2019 16th International Computer Conference on Wavelet Active Media Technology and Information Processing.Chengdu:IEEE,2019:262-265.
[8] MIWA M,BANSAL M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures [J/OL].arXiv:1601.00770 [cs.CL].[2022-10-06].https://arxiv.org/abs/1601.00770v2.
[9] ZHENG S C,HAO Y X,LU D Y,et al. Joint Entity and Relation Extraction Based on A Hybrid Neural Network [J].Neurocomputing,2017,257:59-66.
[10] LI F, ZHANG M S,FU G H,et al. A neural joint model for entity and relation extraction from biomedical text [J/OL].BMC Bioinformatics,2017,18:1-11[2022-10-06].https://link.springer.com/content/pdf/10.1186/s12859-017-1609-9.pdf.
[11] ZHENG S C,WANG F,BAO H Y,et al. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme [J/OL].arXiv:1706.05075 [cs.CL].[2022-10-09].https://arxiv.org/abs/1706.05075v1.
[12] EBERTS M,ULGES A. An End-to-end Model for Entity-level Relation Extraction using Multi-instance Learning [J/OL].arXiv:2102.05980 [cs.CL].[2022-10-09].https://arxiv.org/abs/2102.05980v2.
[13] WEI Z P,SU J L,WANG Y,et al. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction [C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.[S.I.]:Association for Computational Linguistics,2020:1476-1488.
[14] LIU Y H,OTT M,GOYAL N,et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach [J/OL].arXiv:1907.11692 [cs.CL].[2022-10-09].https://arxiv.org/abs/1907.11692.
作者簡介:李世龍(1997—),男,回族,河南平頂山人,碩士研究生在讀,研究方向:自然語言處理;張浩軍(1969—),男,漢族,浙江杭州人,博士,教授,碩士生導師,研究方向:人工智能;李大嶺(1997—),男,漢族,河南濮陽人,碩士研究生在讀,研究方向:自然語言處理;王家慧(1997—),女,漢族,河南開封人,碩士研究生在讀,研究方向:光網絡故障定位;齊晨陽(1998—),男,漢族,河南周口人,碩士研究生在讀,研究方向:數據挖掘。
