云邊環境下微服務組合系統的動態演化方法
2023-07-03 14:11:38辛建峰王桂玲郭陳虹
計算機應用 2023年6期
葉 盛,王 菁*,辛建峰,王桂玲,郭陳虹
(1.北方工業大學 信息學院,北京 100144;2.大規模流數據集成與分析技術北京市重點實驗室(北方工業大學),北京 100144;3.中國網絡安全審查技術與認證中心,北京 100013)
0 引言
微服務架構風格是應用程序被分解成小的獨立構建塊(微服務),每個構建塊都專注于單個業務能力。微服務以輕量級機制相互通信,它們可以獨立部署和維護。但是微服務分散性的風格無法獨立滿足一個完善的系統,需要組合微服務提供復雜而精細的功能。
微服務組合可以理解為:通過靈活組裝多個高度自治的微服務給用戶提供強大的功能或者滿足上層的各種復雜的業務需求。本文的微服務系統基于云邊環境下的微服務演化框架,并通過本文提出的方法進行微服務的組合和演化來滿足用戶的需求;但是,微服務組合的不確定性為云邊環境的有效利用帶來了新的挑戰。用戶需求具有不確定性,微服務組合邏輯會隨著業務需求的變化而動態調整,微服務組合系統需要隨著用戶需求的變化而快速演化。為了支持微服務組合的高效執行,保證服務質量,本文提出了一種云邊環境下的微服務組合系統的動態演化方法(Dynamic Evolution method for Microservice Composition system,DE4MC),通過業務流程中的發布/訂閱通信手段使云邊節點上的微服務之間建立協作,綜合考慮微服務實例的遷移代價、微服務與用戶的數據通信代價和微服務之間的數據流傳輸代價,支持業務流程的優化部署和動態調整。其中,包含了以業務流程運行時間和微服務系統演化開銷為目標優化的兩個階段的云邊調度算法:一是在業務流程部署階段,通過業務流程部署算法對流程和微服務進行優化部署;二是在業務流程動態調整階段,通過業務流程動態調整算法進行微服務組合系統的動態演化。這兩個階段的算法可保證微服務系統在演化開銷低和業務流程運行時間短的條件下及時演化,并提供用戶滿意的服務質量。
1 相關工作
1.1 微服務組合相關工作
傳統的服務組合風格有編制(Orchestration)和編排(Choreography)。很多微服務組合的相關研究借鑒了傳統的Web 服務組合的思想和策略。
編制風格(Orchestration)Cocconi 等[1]提出了一種依靠中心協調器的協作業務流程(Collaborative Business Processes)的方法組合微服務。Oberhauser[2]提出了一種微流程的方法,通過使用代理編制語義注釋的微服務。Ben Hadj Yahia 等[3]提出了基于事件驅動的輕量級服務編制平臺——Medley。Monteiro 等[4]提出了基于事件驅動的輕量級微服務編制平臺——貝多芬(Beethoven)。Gao 等[5]提出了一個微服務組的概念,用工作流的方式在多云環境下考慮服務質量和用戶的偏好以組合微服務。本文借鑒了編制風格的一些組合微服務的思想。
編排風格(Choreography)Valderas 等[6]用業務流程建模與標注(Business Process Model and Notation,BPMN)可視化為微服務組合的大圖,將大圖拆成BPMN 片段的小圖,允許每個微服務以解耦的方式運行,并采用BPMN2.0 原生自帶的消息任務和事件通信。Safina 等[7]介紹了一個將實現的編排操作通過編譯器轉換為可執行代碼并分發給參與者的程序。Decker 等[8]將BPMN 模型轉換為業務可編排的流程執行語言(Business Process Execution Language for Choreographies,BPEL4Chor)描述以 執行編 排 。Gutiérrez-Fernández 等[9]采用BPM 語言開發微服務,用業務流程引擎執行它,并確定了業務流程集成到微服務體系結構的要求和流程引擎如何處理微服務之間的部署和通信。Ortiz 等[10]利用BPMN 可以描述控制流的方式編排組合微服務,并仔細描述了自底向上的方式,即對單個微服務進行改變會影響全局大圖。Jayawardana 等[11]提出了一種新的方法,在統一的規范中對業務流程和領域知識進行建模,該規范可以生成與微服務體系結構兼容的樣板代碼。Valderas等[12]使用靈活的微服務架構執行BPMN 并促進它與物理設備的集成,實現了兩者之間的解耦,并且不會增加BPMN 元模型的復雜性。Dai 等[13]提出了一種微服務編排分析方法,從給定的編排中生成參與復合服務的微服務。Giallorenzo等[14]討論了編排的不同解釋如何幫助開發正確的微服務系統架構,即那些真正實現所需的分布式交互,同時避免死鎖和競爭的微服務系統架構。受上述工作啟發,本文通過采用業務流程的方式編排微服務。
微服務組合方法[15]可分為三種:一是基于工作流模型的微服務組合方法,上述文獻多為這種方法,是微服務體系結構中使用較多的一種服務組合方式;二是基于狀態演化的微服務組合方法,本質上也是一種工作流的微服務組合方法,但主要完成微服務組合方案的可行性驗證和對微服務的形式化建模;三是基于形式化語言的微服務組合方法,其思想是為微服務組合定義一種特殊語言,讓用戶在更深的抽象層次描述微服務組合并實現。采用面向服務的編程語言Jolie[16]作為描述微服務組合的語言,通過定義描述服務行為的語法結構和服務部署的端口等信息解決服務組合等問題。在組合服務實現過程中,需要對Jolie 進行一定的擴展完成服務組合調用所需的條件,如數據傳輸等,所以相較于工作流形式的微服務組合方法更復雜。但是基于本文的研究背景,盡管統 一建模語言(Unified Modeling Language,UML)、BPMN、BPEL、Medley、Jolie 等方法都可以創建微服務,但它們很少關注微服務的演化[10],本文引入BPMN 片段解決這個問題,允許自上而下和自下而上的編排方式演化微服務。利用BPMN 建模的可視化性特點組合微服務的方式給開發者和用戶帶來良好的使用體驗[6]。
1.2 微服務調度和演化相關工作
為了解決不同微服務之間不同版本的復雜依賴關系,賀祥等[17]提出面向演化的微服務編程框架和微服務系統自適應架構,并設計基于貪婪的優化算法找到最優的微服務系統演化方案以實現微服務系統的自適應演化。在這兩個框架的基礎上,He 等[18]提出了云邊環境下的微服務自適應演化優化方法,滿足移動端用戶的質量需求。Wang 等[19]采用Java 中輕量級的方法實現了微服務演化編程框架,支持單個微服務的自適應演化。這些工作的自適應機制是由一個自適應控制回路參考模型MAPE-K(Monitor-Analyze-Plan-Execute-Knowledge)[20]實現的。但這些工作中并沒有考慮微服務組合系統的特殊演化需求。本文在這些工作的基礎上擴展了通過業務流程組合微服務的方法及技術。
微服務調度方面,Gao 等[21]提出了一種新的基于免疫記憶克隆和克隆選擇算法的人工免疫算法,在大量候選微服務中組成復雜的工作流,該算法通過構造與用戶相關的模糊權重將多最優問題轉換成單最優問題。該工作結合了工作流和微服務,但是該工作沒有考慮演化的問題。Lin 等[22]提出的一種蟻群算法,考慮物理節點的計算利用率、存儲資源的利用率、微服務請求的數量和物理節點的故障率以提供最優路徑的選擇概率。該算法在集群服務可靠性、集群負載均衡和網絡傳輸開銷優化等方面取得了較好的效果,但也沒有考慮微服務的演化問題,不過在服務可靠性和資源利用率等方面的部分工作可以借鑒。
以上的工作有結合微服務組合和調度、微服務組合和演化、微服務演化和調度,但是本文方法結合了微服務的組合、演化和調度。
2 DE4MC
本文提出了一種云邊環境下的微服務組合系統的動態演化方法(DE4MC)去支持微服務組合和及時演化。
2.1 相關定義
一個云邊環境下的微服務組合系統由一組邏輯服務組成,每個邏輯服務都有部署在不同云邊節點的物理實例。一個業務流程是一組邏輯的特定服務,根據優化算法(詳情見第3 章)選擇這些服務的特定實例滿足業務需求。
定義5 業務流程定向狀態。業務流程定向狀態BP(b)記錄了業務流程片段與微服務實例之間的映射。對于?r∈V(b),假定r=s,u,c,為r選擇一個請求的服務s的實例τ(s)和該服務相關的功能接口Ii(s),(τ(s),Ij) ∈BP(b)。一個合法的業務流程定向狀態必須滿足微服務實例τ(s)提供的質量等級Li(s)必須大于等于用戶的要求的條件。
定義6 微服務演化操作。
OPS={Composite,Split,Keep}:
1)Composite(…,Ii(si),…) ?(s,I1(s)):表示把不同原子服務通過業務流程組合成一個新的服務。
2)Split(s,Ii(s)):表示把一個組合服務切成不同的原子服務。
3)Keep(s):表示該服務的接口不改變。
定義7 微服務實例演化操作。
OPI={Adjust,Add,Remove,Retain}:
1)Adjust(τ(s),Li(s),Lj(s)):調整該微服務實例的質量等級。
2)Add(τ(s),n,Lj(s)):在節點n上創建一個質量等級要求為Lj的微服務s的實例。
3)Remove(τ(s)):刪除該實例。
4)Retain(τ(s)):保持該實例不發生改變。
定義8 業務流程定向狀態的演化操作。
OPU={Deploy,Switch,Keep},其中:Deploy(b,τ(s))表示把流程片段b跟微服務s實例建立映射;Switch(b,τi(s),τj(s))表示業務流程片段b跟微服務s的實例τi的映射關系轉移到另一個實例τj上。
定義9 部署狀態。一個微服務系統在時間t的部署狀態可以 表示為Θ(t)=S(t),E(t),N(t),V(t),BP(t),S、E、N、V和BP分別是微服務集合、節點集合、微服務實例集合、業務流程集合和業務流程定向狀態。
2.2 微服務組合系統演化框架
本文動態演化方法基于EI4MS 的微服務系統基礎架構和EPF4M 微服務自適應編程框架的擴展,該架構有7 個組件如圖1 所示。
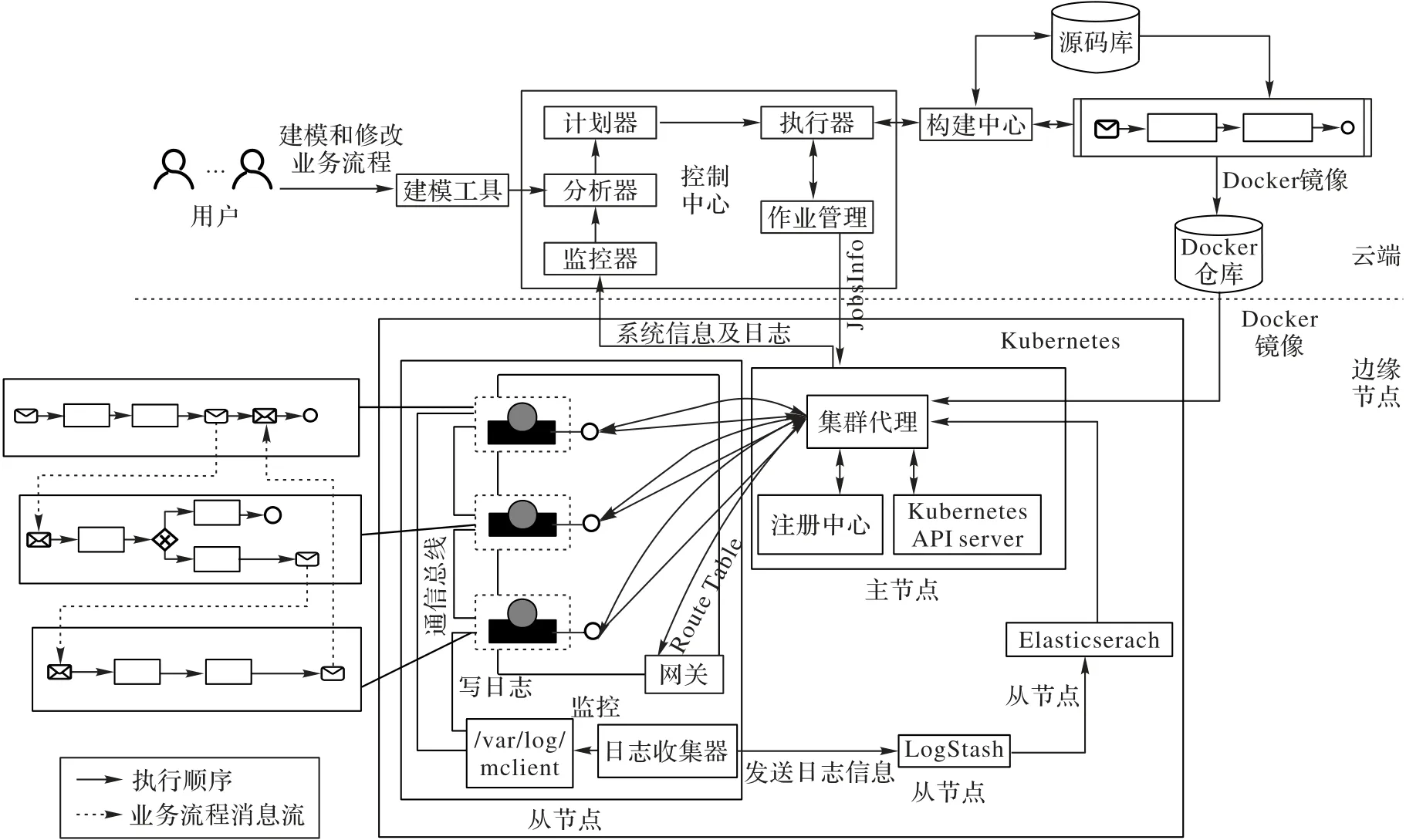
圖1 微服務系統的演化架構Fig.1 Evolution architecture of microservice system
1)控制中心。用戶直接通過可視化建模工具創建新的業務流程或者修改已運行的微服務實例,該工具把用戶建模或修改的信息直接提交給分析器,它能識別業務流程文件和業務流程實例并轉化成算法需要的輸入格式,再通過計劃器中的兩個算法計算得出一組系統演化操作,然后放到執行器上執行。
2)日志收集器。收集每個節點上微服務實例的運行日志,并把所有日志傳遞到邊緣集群中的日志數據庫。
3)微服務構建中心。把自動生成相關的流程片段描述信息、服務功能語義描述和流程引擎語義描述打包構建相應的Docker 鏡像,為Composite 和Split 演化操作提供支持。它從控制中心接收Composite 和Split 的作業,生成 Docker 鏡像并推送到鏡像倉庫進行添加操作。它部署在一個集中的云節點上。
4)集群代理。負責獲取邊緣節點的運行時信息并傳遞給控制中心,包括日志數據庫的日志、注冊表、Kubernetes API 服務器的信息和微服務的實例信息。Kubernetes API 服務器和網關能夠接收控制中心的演化操作并部署到相應節點。它必須部署在一個邊緣節點上。
5)網關。將用戶請求重定向到服務實例,并依賴于用戶請求的路由表。來源控制中心的Switch 演化操作會讓路由表發生改變。它必須部署在邊緣節點上。
6)用戶可視化建模工具。用戶可以在上面建模自己的業務流程,也可以動態修改業務流程。
7)通信總線。用通信總線的方式支持部署在云邊節點上的業務流程的消息事件傳遞和消息任務的執行。
2.3 方法原理
如圖2 所示,DE4MC 分為業務流程部署和業務流程動態調整兩個階段。
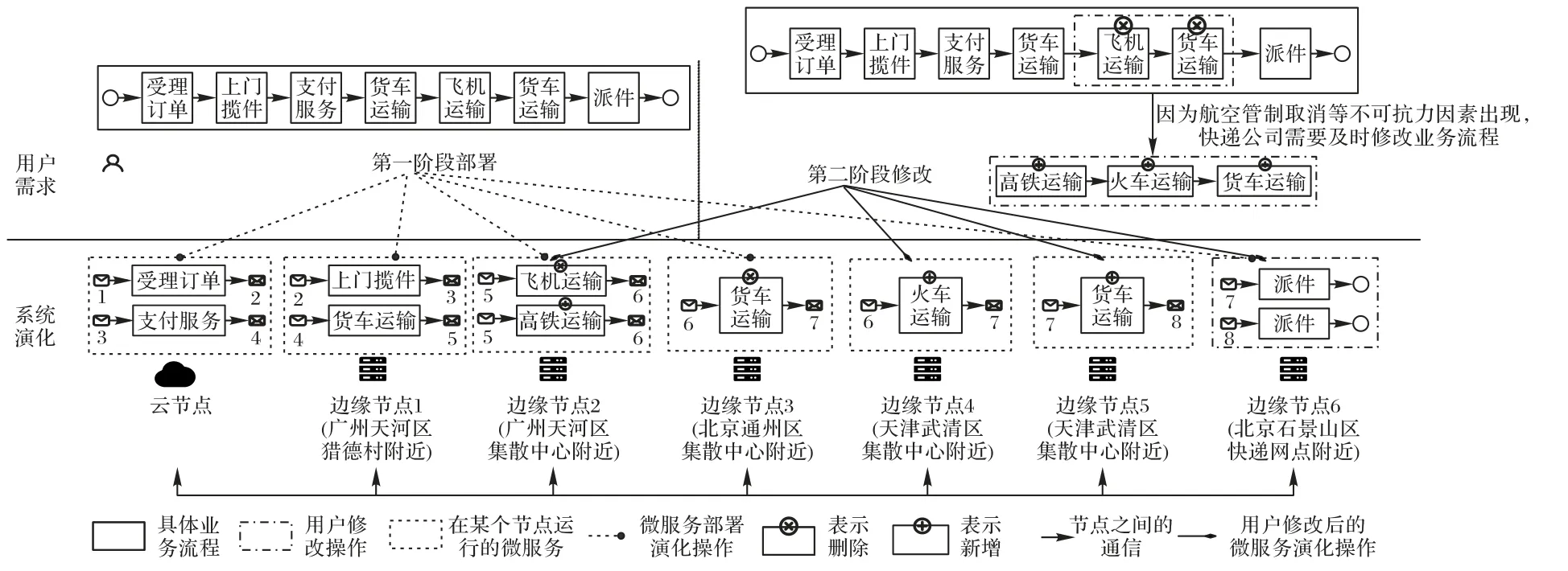
圖2 微服務組合系統的動態演化方法Fig.2 Dynamic evolution method of microservice composition system
業務流程部署階段 用戶提交業務流程后,系統根據云邊節點的狀況采用業務流程部署調度算法(詳見第3 章)合理切分業務流程并部署在相應的節點上,使業務流程運行的時間最短和微服務演化開銷最低。
由于全國快遞運輸量巨大且每個快遞公司各地的營業網點數量多,如果在云上部署相應的微服務會導致響應速度慢和云邊節點信息不匹配。為了更好地安排人員和交通工具,應把相關的微服務部署到附近邊緣節點進行準確且快速的計算。首先,快遞公司在公司云節點收到用戶寄快遞的訂單后會創建一個最初的流程,其中指派快遞員、支付訂單和貨車運輸服務都在同一個邊緣節點且有連續的控制流和數據流關系;然后,演化系統根據微服務演化操作Composite 把這3 個功能組合成一個新的復合服務以減少數據流傳輸和縮短響應時間,通過Add 生成相應的實例;最后,通過Deploy 操作建立實例和流程片段的關系。系統對應的演化操作如表1所示。

表1 部署和調整階段演化操作Tab.1 Evolution operations in deployment and adjustment stages
業務流程動態調整階段 用戶提交的業務流程已經部署運行,但是用戶需求臨時發生改變,用戶想要修改正在運行的流程,系統需要及時演化響應用戶修改后的流程。例如,由于原定的路線上北京通州區發生疫情導致快遞公司不得不及時修改業務流程,把原定從廣州白云區運到北京通州區的飛機服務和之后的貨車運輸服務刪除,然后根據實際業務需求重新添加高鐵服務、火車服務等。系統對應演化操作如表1 所示。
3 微服務組合系統演化算法
本章描述用戶在建模業務流程和修改業務流程兩個階段下系統運行的演化算法,兩種情況下的問題定義是一致的。
其中:A、B和C分別為OP(I)、OP(U)和OP(S)的數量。
進一步,整個流程的運行時間可以被定義為:
其中:n為該流程中服務實例的數量,rt(·)為每個微服務的運行時間,ct(·,·)為業務流程片段之間的通信時間。
本文算法優化的調度目標如下:
其中:eij是滿足用戶ui提交的業務流程wj需求的一個微服務實例;Q()表示獲得的服務級別協議(Service Level Agreement,SLA);r()用來計算資源的大小;rmax()代表該節點所有的資源大小;ns()代表當前使用該微服務實例用戶的數量;nsmax()表示該實例設定的最大用戶數;δ表示自上次演化以來經過的時間間隔。
3.1 算法原理
本文方法由兩個階段的算法組成,兩個算法由兩個原子算法組成:一是追求反應快速但可能只得到局部最優解的啟發式算法(Heuristic Algorithm,HA),二是能得到全局最優的遺傳算法,該算法以系統的演化開銷和業務流程的運行時間為優化目標。如式(4)所示,系統演化操作必須滿足3 個約束,分別是節點上的資源不能被使用完、微服務的質量必須大于用戶的要求和微服務的實例數量不能超過服務最大實例數。需要注意的是,由于本文采用業務流程的方式組合微服務,業務流程中各個元素之間可能存在數據流關系,在綜合其他約束條件下,算法也會考慮把兩個具有數據流關系的微服務部署在同一個物理節點上以降低通信傳輸的開銷。如果一個微服務的輸出是另外一個微服務的輸入且兩者都被頻繁調用,根據本文提出的微服務演化框架,這兩個微服務通過Composite 演化操作聚合成一個功能更強大的微服務,方便實例化和調度。
3.1.1 基于啟發算法改造后的算法原理
本文針對業務流程具有數據流的特點改造了傳統HA,提出了業務流程管理啟發式算法(Business process management Heuristic Algorithm,BpmHA)算法,通過節點評估函數選擇節點進行部署。評估函數如下:
該評估函數綜合考慮三方面因素,分別是遷移代價(微服務實例從云邊節點到另一個節點的代價,否則代價為0)、通信代價(微服務實例部署節點跟所分配用戶通信的代價,如果該微服務不需要跟用戶交互就為0)和微服務之間通信代價(微服務之間可能存在數據流交互的通信)。根據實際用戶的需要或者經驗分別配置權重,本文按照各占1/3的權重進行實驗驗證,后期通過不斷實驗得出經驗再進行權重的合理分配。
算法1 BpmHA。
輸入 業務流程文件或實例BP,所有節點的運行狀態SN;
輸出 業務流程定向狀態的演化操作OP(U),微服務實例演化操作OP(I),微服務演化操作OP(S)。
如算法1 所示,系統首先把用戶提交的業務流程文件分成一個個最小的微服務,遍歷所有云邊節點查找目標微服務加入微服務集合,并查找資源能滿足目標微服務部署的節點放入備選節點(第3)~4)行),在這些備選節點上遍歷計算NE,選最小值的節點與目標服務關聯。如果滿足算法1 所有IF 語句中的微服務演化操作要求,就進行相應的演化操作(第10)~23)行)。如果所需的目標服務是已組合服務的一部分且別的節點沒有目標服務的鏡像,就需要把目標服務從已組合的服務通過Split 操作拆解出來。如果目標微服務在目標節點已存在實例,就通過Switch 演化操作把相關流程片段與該實例形成映射。如果目標節點的資源不滿足目標微服務所需要的資源,通過Adjust 操作進行資源的動態調整。如果目標服務需要被幾個服務組合且滿足定義6 的條件,就通過Composite 操作組合幾個服務。如果目標節點沒有該實例,則需要遷移目標服務鏡像并重新通過Add 操作創建一個目標服務實例。
啟發算法相較于遺傳算法,執行時間較短。算法的時間復雜度為O(mn),m是需要部署的目標服務的數量,n是所有微服務的數量,如果邊緣節點上沒有相應的微服務實例,系統會去云端查找該實例,但是平均響應時間會變長。
3.1.2 基于遺傳算法改造后的算法原理
本文使用第二代非支配排序遺傳算法(Non-dominated Sorting Genetic Algorithm-Ⅱ,NSGA-Ⅱ)[23],部署狀態和運行實例轉換成種群基因的詳情請參考文獻[18]。
算法2 NSGA-Ⅱ。
輸入 所有節點的運行狀態SN;
輸出 業務流程定向狀態的演化操作OP(U),微服務實例演化操作OP(I),微服務演化操作OP(S)。
NSGA-Ⅱ引入了精英策略,達到保留優秀個體淘汰劣等個體的目的。精英策略通過將父代與子代個體混合形成新的群體,擴大了產生下一代個體的篩選范圍。P0表示最初的父代,Q0表示最初的子代,N代表個體數。算法具體步驟如下:將父代種群和子代種群形成新的群體,對新種群進行非支配排序,生成新的父代,先將Pareto 等級為1 的非支配個體放入新的父代集合中,之后將Pareto 等級為2 的個體放入新的父代種群中,以此類推。若等級為i的個體全部放入新的父代集合中后,集合中個體的數量小于N,而等級為i+1 的個體全部放入新的父代集合中后,集合中的個體數量大于N,則對i+1 等級的全部個體計算擁擠度并將所有個體擁擠度進行降序排列,之后將等級大于i+1 的個體全部淘汰。對生成后的父代種群計算適應度,fitness=θ1*T+θ2*C,其中演化開銷和運行總時間的權重各占一半,選擇適應度大的父代進行交叉、變異操作生成子代種群。最后判斷代數是否等于最大進化代數,否則就繼續執行循環迭代。最終的演化操作規則見算法2 第15)~29)行。
3.2 業務流程部署和動態調整算法
用戶根據自己實際的業務需求建模自己需要的業務流程,通過該部署算法計算演化操作,交由執行器作微服務實例部署。兩個算法的策略如圖3 所示。
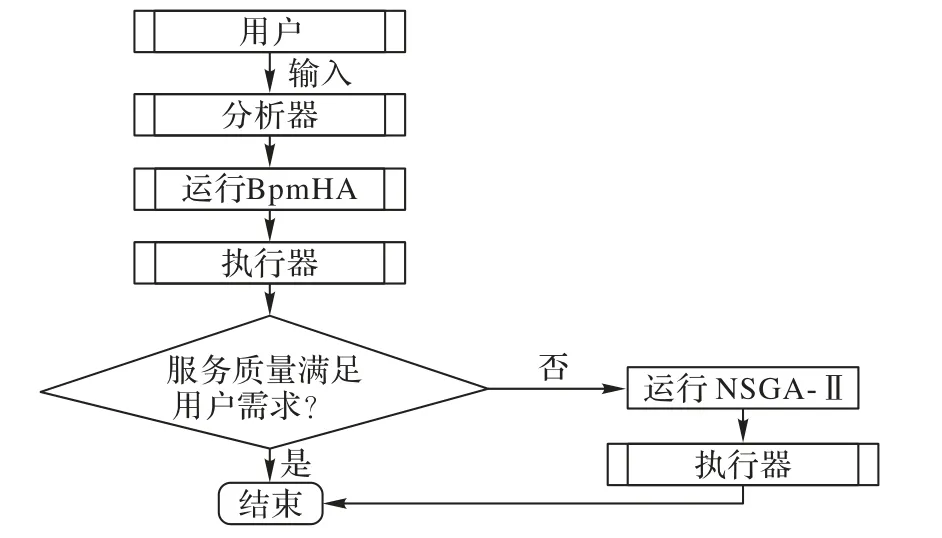
圖3 算法策略Fig.3 Algorithmic strategy
業務流程部署算法 本文改進HA 提出了BpmHA,微服務實例的遷移代價、微服務與用戶的數據通信代價和微服務之間的數據流傳輸代價是影響微服務部署效率的三大因素,因此在選擇部署節點時綜合計算三者代價來選擇最優的部署方案,BpmHA 經過后期實驗能得到一個近似全局最優的解,無需重復多次運行。如果BpmHA 不滿足用戶的服務質量(Quality of Service,QoS),系統會采用NSGA-Ⅱ迭代計算演化操作方案。算法的輸入是用戶提交的業務流程和各節點的部署狀態(所有節點的狀態),算法的輸出是演化方案(OP(U),OP(I),OP(S))。
業務流程動態調整算法 與部署算法不同,該算法的輸入是對云邊節點上已有運行的業務流程實例動態調整后的實例;雖然已經運行完的流程片段不再經過算法重新部署,但是動態調整的部分仍會參考已部署的流程狀態進行綜合優化部署。動態調整算法在遺傳算法上也作了改進,演化系統記錄兩個算法已運行計算出的一些較優解(使本文的兩個優化目標效果不錯的解集會被記錄下來),NGSA-Ⅱ不需要從最初種群開始迭代計算,可以從記錄的解集中挑選一批作為父代和子代,提高了種群的迭代速度,用戶修改業務流程后演化系統能及時動態演化。
4 實驗與結果分析
4.1 仿真平臺介紹
本文使用仿真軟件CloudSim 和WorkflowSim,其中CloudSim 提供了云計算相關的資源建模和任務調度方面的仿真;WorkflowSim 在CloudSim 基礎上引入了工作流級別的仿真,通過模擬真實工作流的運行機制來調度任務。用戶可以把設計好的調度算法放到該工具上執行,實現真實模擬云邊環境下的工作流調度。WorkflowSim 被廣泛應用于工作流調度的科研學習上。
WorkflowSim 中的工作流形式通過有向無環圖(Directed Acyclic Graph,DAG)的形式表示,本文中的業務流程表示為有向無環圖,其中業務流程中的每個活動表示為圖中的一個活動,業務流程的控制流順序相當于圖上的邊。
4.2 數據集準備
為了驗證本文算法在業務流程微服務部署和調整兩個階段的可行性和效率,實驗中需要使用大量不同的工作流。由于公共的數據集有限,為了模擬現實生活中各種需求的業務流程,本文實驗中業務流程表示為帶有數據流的DAG,參照文獻[23]中提出的DAG 構造方法,本文設計了一種帶有數據流的DAG 生成算法,通過添加一些約束并采用編碼方式生成兩組工作流,其中一組工作流在初始的一組工作流的基礎上隨機修改以模擬用戶修改后的業務流程,再通過動態調整算法重新計算部署。簡而言之,一組初始的工作流用于測試業務流程部署算法的效率,隨機修改的工作流用于測試動態調整算法的效率。通過表2 所示的自定義參數,程序自動生成滿足實驗條件的工作流。

表2 工作流參數設置Tab.2 Workflow parameters setting
DAG 生成算法隨機標注DAG 的每個節點的模擬地理位置,目的是模擬用戶的移動。該算法首先隨機生成節點與用戶之間的傳輸開銷,再生成一條最長路徑的工作流,然后通過隨機的最大并行度值將剩余的任務個數加入DAG 中,接著逐層連接下層節點,確保形成一個連通圖。確定完DAG 所有節點后,該算法會在隨機節點之間生成有輸入輸出指向性的數據訪問關系和具體數據值,從而模擬出節點之間數據流關系。
4.3 實驗環境配置
為了驗證本文提出的業務流程動態演化算法的有效性,需要同其他算法進行比較。為了減少其他因素對實驗結果的影響,實驗環境均保持一致。本文實驗環境如下。
實驗所用的服務器操作系統版本為Windows 10,內存32 GB,實驗仿真工具WorkflowSim1.0,Java 環境為JDK1.8,Python 版本3.6。WorkflowSim 模擬生成的10 個邊緣節點的參數:CPU 運算法能力TOPS(Tera Operations Per Second)或者MIPS(Million Instructions Per Second)為3 000,內存5 GB,外存20 GB,通信帶寬10 MB/s。WorkflowSim 模擬生成的1個云節點的參數:CPU 運算法能力:TOPS 或 者MIPS 為20 000,內存20 GB,外存100 GB,通信帶寬20 MB/s。
為了簡化實驗,把DAG 的每個頂點當作WorkflowSim 工具中的一個虛擬機資源,它的大小和所需要的計算資源都一樣,具體參數為:虛擬機所需CPU 運算能力資源TOPS 或者MIPS 為20,虛擬機所占外存大小區間0.5~1.0 MB。
4.4 算法性能分析
4.4.1 實驗參數設置
本文的優化目標主要有兩個,一個是最小化業務流程的運行時間,另一個是最小化微服務系統的演化開銷。業務流程的運行時間包括算法的執行時間和業務流程的執行時間。具體演化操作開銷如表3 所示。
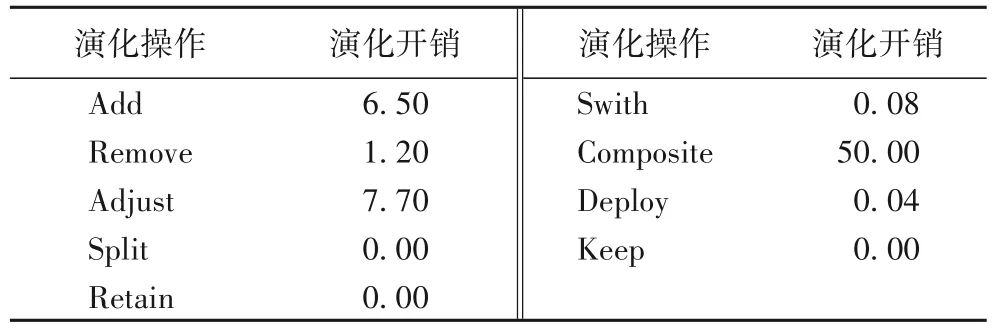
表3 演化操作開銷Tab.3 Evolution operation cost
4.4.2 對比實驗設置
本文實驗對比的算法包括GA,NGSA-Ⅱ,HA+NGSA-Ⅱ的算法組合,和本文提出的算法BpmHA+NSGA-Ⅱ的算法組合,表4 是實驗中算法的相關參數設置。

表4 遺傳算法參數設置Tab.4 Genetic algorithm parameter setting
算法1 和算法2 的輸出是3 組具體的演化操作,每一種操作的演化開銷都在表6 中具體表示。本文只需要把算法算出來的演化操作開銷進行相加,就能計算得到總的演化開銷。
4.4.3 實驗結果展示
DAG 生成算法隨機組成了1 000 個DAG,按照固定的順序排列仿真業務流程部署的測試。另外1 000 個DAG 在原先的DAG 基礎上進行微小的改變,用作動態修改業務流程的測試。本文通過仿真實驗控制該調度環境中DAG 的數量規模,對比這幾個主流算法的總運行時間(調度完所有的DAG 所用的總時間)和綜合調度開銷(調度完所有的DAG 所消耗的開銷資源)。在部署階段,部署算法(BpmHA+NSGA-Ⅱ)與HA+NSGA-Ⅱ的算法組合相比,各個規模的平均運行時間低9.7%,演化總開銷低16.8%;在動態調整階段,動態調整算法(BpmHA+NSGA-Ⅱ)與HA 加NSGA-Ⅱ的算法組合相比,各個規模平均運行時間低6.3%,演化總開銷低21.7%。
為了更好地驗證本文算法的有效性和效率,本文設置DAG 的規模為自變量,比較本文算法和對比算法在部署階段和調整階段的運行時間,如圖4 所示。
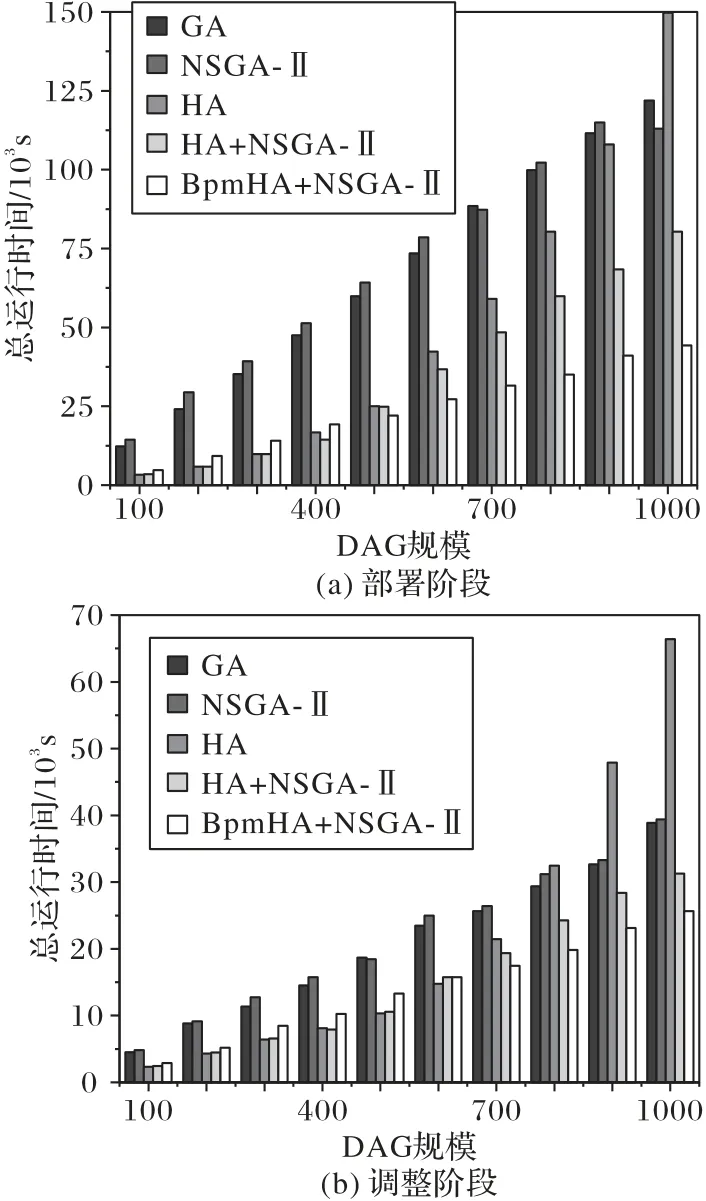
圖4 各算法在不同階段的運行時間Fig.4 Running time of each algorithm in different stages
原因分析 GA 通過不斷迭代產生最優解,需要一定的時間。NSGA-Ⅱ相較于GA 多了精英策略和尋找非支配解的過程,所以比GA 時間長。HA 較簡單,會搜尋每個節點已在運行的DAG 部分活動,只要資源足夠,就直接生成實例部署,不需要考慮綜合調度代價,所以時間短;但是在該節點資源臨界情況,該啟發式算法沒考慮負載均衡,導致執行時間變長。HA+NSGA-Ⅱ可以很好地解決這個問題,如果HA 導致運行時間變長,系統會啟動NSGA-Ⅱ進行總的迭代部署,所以總運行時間比GA 短。而BpmHA 改進了HA,考慮到負載均衡和業務流程數據流的特性,綜合選擇最優節點部署,雖然需要一定的時間代價,但是真正執行的時間是所有算法中最短的。如果BpmHA 并沒有使兩個目標得到很好的優化,就會啟動NSGA-Ⅱ進行總體優化,NSGA-Ⅱ不會從最初狀態開始迭代,會從HA 產生的局部最優解中挑出一些作為初代,開始迭代計算,這樣大幅縮短了演化時間。另外從圖4 中可以明顯看出,調整階段的算法策略跟部署階段的效果是差不多的,調整階段在資源充足的情況下,BpmHA 的效果不錯,因為只是局部改動,無須用NSGA-Ⅱ迭代計算最優解。如果NSGA-Ⅱ不考慮演化時間,整體的執行時間較短。
本文仿真了在云邊環境協同下的業務流程微服務調度,相較于傳統的DAG,本文生成的DAG 多活動之間會有數據傳輸,跟用戶之間也有數據的交互。部署階段和調整階段的調度總開銷如圖5 所示,可以看出本文針對業務流程和微服務特性對啟發式算法改進的BpmHA+NSGA-Ⅱ的組合算法的演化總開銷較低,節省了資源。
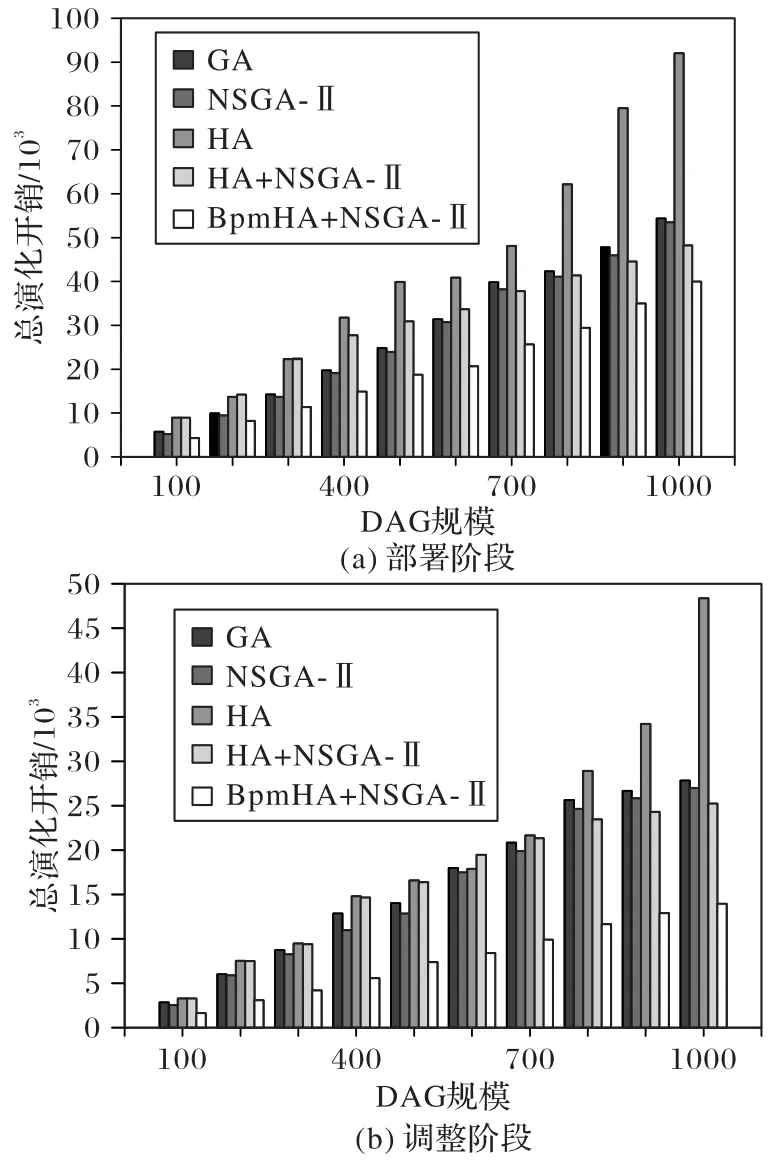
圖5 各算法在不同階段上的總演化開銷Fig.5 Total evolution cost of each algorithm in different stages
原因分析 GA 需要迭代找出最優解,不斷迭代重新部署會導致遷移代價較大,會帶來一定的開銷。NSGA-Ⅱ通過引入精英策略得到較好的解,因此開銷比GA 低。HA 為了追求更短的時間,遍歷找到活動所在的節點直接部署,遷移代價低,但是沒有綜合考慮數據流的傳輸代價和微服務與用戶之間的傳輸代價,所以最后產生的演化總開銷通常較大。而HA+NSGA-Ⅱ的組合算法會在HA 無法縮短時間的時候啟動NSGA-Ⅱ,負載均衡相關已部署節點,但是總開銷跟GA 和NSGA-Ⅱ差不多。而本文針對HA 改進的BpmHA 考慮了業務流程多個節點存在數據流的特性和微服務的組合演化特性,綜合計算NE后選出值最小的節點進行調度,確保總調度開銷是最小的,從而縮短運行時間。
5 結語
相較于傳統的服務,微服務更小、更敏捷。由于微服務功能單一,需要通過傳統工作流、BPEL 和BPMN 等編排方式組合微服務。本文采用業務流程的方式組合微服務。本文針對云邊下的微服務組合的動態演化的問題,結合了實驗室對業務流程主動式探索和服務組合的研究上的積累和文獻[18]中提出的微服務演化框架和基礎架構,提出了一種在云邊協同環境下基于業務流程的微服務組合的動態演化方法。該方法包含了支持業務流程部署和調整的動態演化算法,其中本文設計的啟發式算法BpmHA 綜合考慮微服務實例的遷移代價、微服務與用戶的數據通信代價和微服務之間的數據流傳輸代價,能得到一個近似全局最優的解,無需多次運行,既縮短了算法的執行時間又提高了算法的效率。在NSGA-Ⅱ的基礎上,增加了把節點上的狀態轉化種群基因的形式,并把兩個算法已計算的較優解作為初始種群,加速迭代計算出最優解,及時演化滿足用戶的需求。通過實驗驗證了該算法在云邊環境下微服務組合動態演化特定問題上有不錯的表現,總運行時間和總演化開銷均有所降低。
本文還存在以下不足之處。
1)由于實驗設備等問題,并沒有在真實集群環境上運行該演化框架和本文提出的演化算法,只是在仿真環境上驗證了算法的合理性和效率。以后會逐步在真實的環境中去運行該算法。
2)本文采用特定的DAG 簡單模擬業務流程,而DAG 業務流程復雜,有許多別的元素。本文只是用DAG 的活動表示了業務流程中的服務任務,并沒有考慮別的任務、事件等元素。在以后的真實環境中,需要把業務流程其他元素考慮進去。
猜你喜歡
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
