基于社交關系和時序信息的團購推薦方法
2023-07-03 14:11:42孫男男樸春慧馬新娜
計算機應用 2023年6期
孫男男,樸春慧,馬新娜
(1.石家莊鐵道大學 信息科學與技術學院,石家莊 050043;2.北京全路通信信號研究設計院集團有限公司,北京 100070;3.河北省電磁環境效應與信息處理重點實驗室(石家莊鐵道大學),石家莊 050043)
0 引言
近年來,隨著團購模式的發展與移動終端數量的激增,傳統的商品推薦機制在團購推薦問題上逐漸顯出弊端。團購一般指消費者通過聚集消費需求實現降價目標的一種動態制定商品價格的電子商務模式[1]。團購平臺的用戶可以分為單個用戶和群組用戶。
從用戶的角度,目前的團購推薦方法中,綜合研究單個用戶和群組用戶的方法較少。其中,向單個用戶推薦的研究有很多,群組推薦也是推薦系統領域關注的一個熱點。從團購平臺的角度,存在很多單個用戶獨自成團的現象,而且很多群組也存在臨時性的特點。所以綜合考慮對兩種用戶進行個性化推薦,具有研究意義和實用價值。從商家的角度,最終的目的是平臺的用戶多參與到團購活動中,進而提高商家的銷售額,所以分別設計兩種具有針對性的個性化推薦算法具有很好的應用場景。
在對單個用戶進行推薦時,雖然目前基于循環神經網絡(Recurrent Neural Network,RNN)中門控循環單元(Gated Recurrent Unit,GRU)的推薦算法[2-3]可以建模更為復雜的序列關系,但沒有考慮用戶行為之間的時間間隔信息,對推薦結果的多樣性有很大的影響;之前的研究多是按照交互次數排序的方法計算商品對用戶的重要性,僅考慮交互次數,不同商品可能對于同一用戶的重要性相同;用戶-商品交互數據中存在噪聲,導致推薦精度降低。
盡管目前團購推薦是推薦系統領域關注的一個熱點,具有研究意義和實用價值,但是對群組進行推薦時仍面臨如下挑戰:1)目前群組偏好融合策略大多是預定義、啟發式的方式,不足以體現復雜、動態的群組決策過程;2)忽略了群組與項目交互的時間信息,人們通常認為群組用戶更傾向于花更多的時間在其感興趣的項目上,并且這些感興趣的項目普遍與當前的目標項密切相關;3)用戶易受到朋友的影響,在面對不同的項目時通常會對不同的朋友產生依賴。
因此,針對上述問題,在對單個用戶進行推薦時,本文同時考慮了個性化時間間隔和自注意力網絡,提出了融合時序感知GRU 和自注意力的團購推薦模型(group buying Recommendation model integrating Time-series aware GRU and Self-Attention,RTSA)。在對群組用戶進行推薦時,本文利用門控循環單元、社交網絡和分層自注意力網絡,提出了融合社交網絡和分層自注意力的團購推薦模型(Group buying Recommendation model integrating Social network and hierarchical Self-Attention,SSAGR)。
1 相關研究
1.1 序列推薦
傳統的序列推薦模型包括序列模式挖掘[4]和馬爾可夫鏈(Markov Chain,MC)模型[5-6]。基于序列模式挖掘的方法雖然簡單直觀,但通常會產生大量冗余模式;其次,序列模式挖掘利用用戶的歷史交互數據中出現較為頻繁的特征,進行學習并推薦,導致推薦的商品相似性較高,容易使用戶感到疲倦。基于MC 的模型假設用戶下一次的交互行為只受最近幾次交互的影響,一般只能捕獲短期依賴。如個性化馬爾可夫鏈分解(Factorizing Personalized Markov Chains,FPMC)[6]將一階MC 與矩陣分解方法相結合,對用戶的興趣偏好和動態轉換進行了建模,只考慮了當前項與前一項之間的關系,不能在復雜的場景下利用其他輔助信息挖掘更多的隱式關系。
1.2 群組推薦
隨著團購模式的發展,群組推薦任務逐漸成為研究熱點。這些群組用戶或具有相似的興趣偏好,或具有相同的需求,同質性較高。如果只是將群組用戶的偏好進行簡單的融合來產生最終的推薦結果,會導致部分群組用戶的興趣偏好被忽略。因此團購推薦系統既需要考慮群組的一般偏好,還需要綜合、動態地考慮群組中用戶的個人偏好,即團購推薦任務的核心問題是融合策略的選擇。
常用的融合策略包括平均策略[7]、最少痛苦策略[8]、最大滿意度策略[9]、專家知識策略[10]等。與這些基于內存的方法不同,基于模型的方法建模用戶間的交互信息,具有更好的推薦效果 。如 AGR(Attention-based Group Recommendation)[11]通過考慮群組內成員間的影響學習用戶的權重,但是它只利用了項目的ID 信息。AGREE(Attentive Group REcommEndation)[12]采用了注意力網絡得到群組的嵌入表示,但此模型僅從用戶的角度考慮群組的表示方法。
1.3 深度學習推薦
隨著深度學習的快速發展,基于RNN 的方法[13-14]在推薦領域獲得了成功。如Hidasi 等[13]首次提出了GRU4Rec(GRU-based RNN approach for session-based Recommendations)模型,利用了RNN 學習用戶點擊序列之間的順序關系。Chen 等[14]針對基于RNN 的模型中項目之間關聯性不強的問題,提出了基于用戶記憶網絡的序列推薦模型。雖然這些基于RNN 的序列推薦模型可以建模更為復雜的序列關系,但仍存在兩方面的問題[15-16]:一是沒有考慮用戶行為之間的時間間隔信息,它對實現推薦結果的多樣性有很大的影響;二是用戶的歷史交互序列中,存在一些無意義的行為,這些不相關的數據會產生噪聲,影響推薦結果的準確性。
近幾年來,自注意力機制已被應用于各種任務中,并取得了巨大的成效。本質上,這種機制的輸出部分依賴于輸入中特定的內容,通過計算各部分輸入信息的權重使設計的模型更具備解釋性。目前自注意力機制已被廣泛應用于推薦系統[15,17-20],用于強調用戶的交互序列中真正相關和重要的商品信息,從而處理序列中的噪聲問題。Sun 等[15]提出了雙向基于Transformer 的推薦模型,從用戶-商品交互序列左右兩個方向提取用戶的交互信息,對目標用戶進行下一個商品的推薦。Kang 等[17]提出了自注意力序列推薦模型,既能夠捕捉較長的用戶-商品歷史交互序列信息,也能夠針對相對較少的用戶交互行為序列進行預測。Li 等[18]提出了一個明確的對交互時間進行建模的序列推薦模型,探索了時間因素對下一個商品預測的影響。Zhang 等[20]分別對屬性間的特征關系建模,更深層次地挖掘用戶潛在偏好,提出了特征級自注意力網絡序列推薦模型。但是自注意力機制只是模型中的一個模塊,本身不包括循環層或者卷積層,并不知道序列中商品的位置等信息;同時,在現有的基于自注意力機制的模型中,大部分都未添加輔助信息進行建模。
2 RTSA設計
RTSA 的結構如圖1 所示。此模型主要包括3 個部分:1)利用時序感知GRU(Time-series aware GRU,TGRU)層學習用戶偏好復雜的動態時序特征;2)通過融合個性化時間間隔的自注意力層TSA(Time-aware Self-Attention)捕捉時間間隔、商品位置與商品嵌入信息之間的關系模式;3)將自注意力層的輸出表示輸入全連接層,與所有商品的嵌入表示點積,預測下一個商品的輸出。
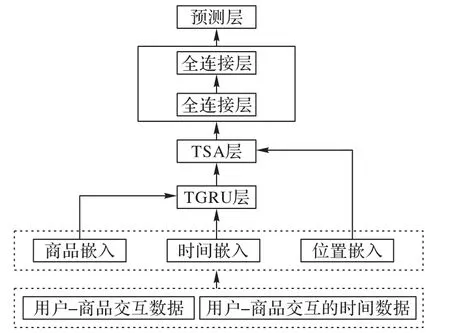
圖1 RTSA的結構Fig.1 Structure of RTSA
2.1 公式化描述
2.2 時序感知GRU
在進行商品推薦時,融合時間上下文信息可以在一定程度上提高商品推薦的準確性和多樣性。因此本文在GRU 模型的基礎上加入時間門,提出了時序感知GRU 模型。在此模型中,時間門主要是控制當前交互商品的時間信息對下一個商品推薦的影響。通過輸入用戶-商品交互序列中商品的嵌入表示矩陣EI和個性化時間間隔矩陣Ru,使交互時間的遠近被考慮在內。TGRU 如圖2 所示。

圖2 TGRU模型Fig.2 TGRU model
由圖2 可知,TGRU 模型是在基礎GRU 模型上添加了時間因素。故在基礎GRU 模型(式(1)~(4))的基礎上,添加了式(5),并對式(3)進行了修改如式(6):
其中:⊙是點積運算;σ是sigmoid 激活函數;更新門zt、重置門rt和時間門Tt控制每個隱層的信息更新;W**表示權重系數矩陣;b*是偏差參數;Δtt表示任意兩個商品之間的個性化時間間隔;xt和ht-1分別表示當前時間t的輸入向量和上一時間t-1 的輸入向量;h~t中的rt⊙ht-1表示通過重置門rt控制上一時間的輸入需保留的信息量;ht的前半部分通過更新門zt控制當前時間輸入的信息量,后半部分通過1 -zt控制上一時間輸入的信息量。
2.3 融合個性化時間間隔的自注意力網絡
用戶-商品交互序列中,不同的商品對下一次推薦的重要性不同;用戶-商品交互數據中混雜著一些噪聲,導致推薦精度降低[21],因此本文引入了自注意力機制,從眾多信息中找到對下一次推薦貢獻最大的關鍵信息,提出了融合個性化時間間隔信息、商品位置信息和商品序列信息的自注意力模型TSA。該模型結構如圖3 所示。

圖3 TSA模型Fig.3 TSA model
其中:n表示交互序列的長度;V表示值向量,是自注意力網絡中的表述;WV是值的輸入預測;v是V值向量的其中一個元素;WV∈Rd×d是可學習的權重參數,d表示用戶的嵌入向量維度。權重系數αij使用softmax 函數計算,如式(9)所示:
其中βij通過一個考慮輸入、關系和位置的函數計算。
其中:WQ∈Rd×d和WK∈Rd×d都是可學習的參數;用于維度過高時,避免內積值過大。上標Q、和K 分別表示查詢和鍵。
2.4 全連接層和預測層
為了增強模型的性能,本文在自注意力層后應用了層歸一化、正則化和以高斯誤差函數(Gaussian Error Linear Unit,GELU)為激活函數的全連接層,最終得到融合商品信息、位置信息和個性化時間間隔信息的聯合輸出表示z=(z1,z2,…,zn),如式(11)~(13)所示。
其中:W*表示權重系數矩陣,b*是偏差參數。
在經過全連接層之后,將此聯合表示zt輸入預測層。利用其與所有商品的嵌入表示矩陣EI∈R||I×d進行點積,得到目標用戶u對每個候選商品的偏好得分
3 SSAGR設計
SSAGR 的結構如圖4 所示。此模型主要包括3 個部分:1)采用RNN 學習用戶隨時間變化的復雜潛在興趣;2)利用用戶社交網絡和分層自注意力網絡,設計群組偏好融合策略;3)通過神經協同過濾(Neural Collaborative Filtering,NCF)學習群組-項目交互函數,完成團購推薦。
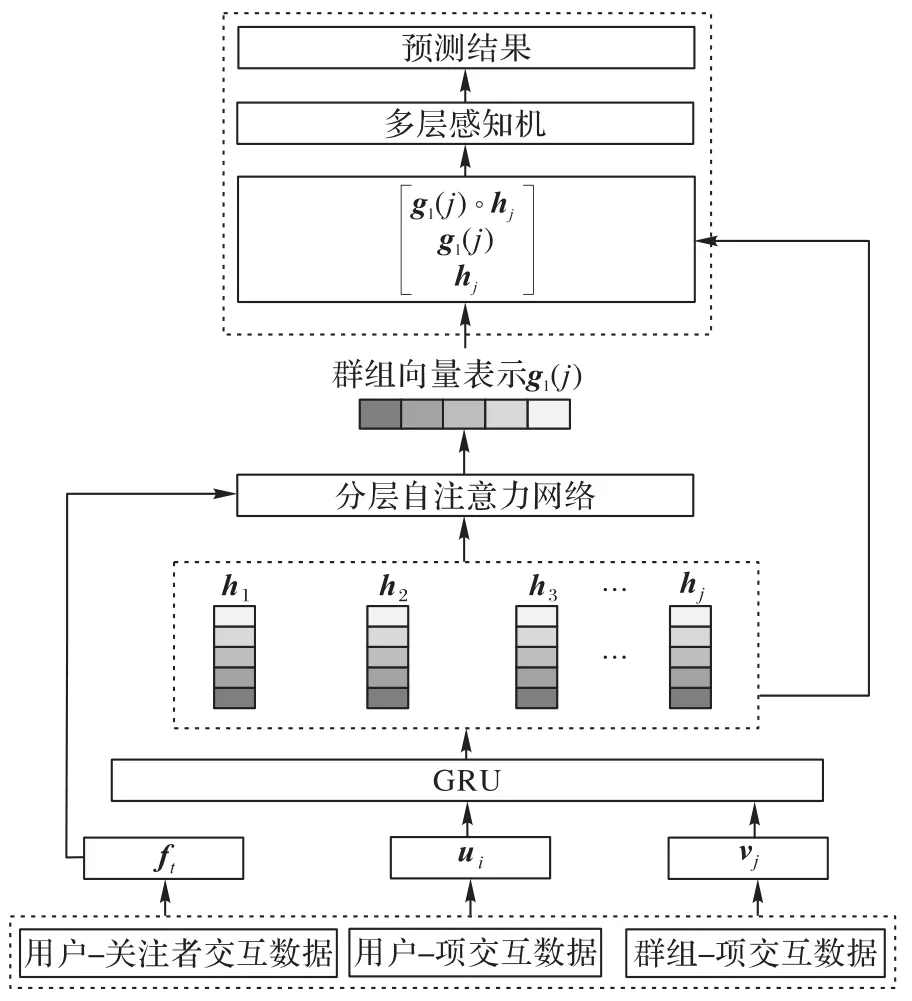
圖4 SSAGR的模型結構Fig.4 Model structure of SSAGR
3.1 公式化描述
3.2 分層自注意力網絡
分層自注意力網絡的結構如圖5 所示,展示了對用戶、社交關注者嵌入聚合策略的設計,通過向量ui、hj和ft,得到最終的群組嵌入表示gl。首先,通過用戶級自注意力網絡,將用戶的社交關注者信息納入到用戶表示中;然后,采用群組級自注意力網絡,融合成員用戶的向量表示,獲得每個群組的嵌入表示向量。
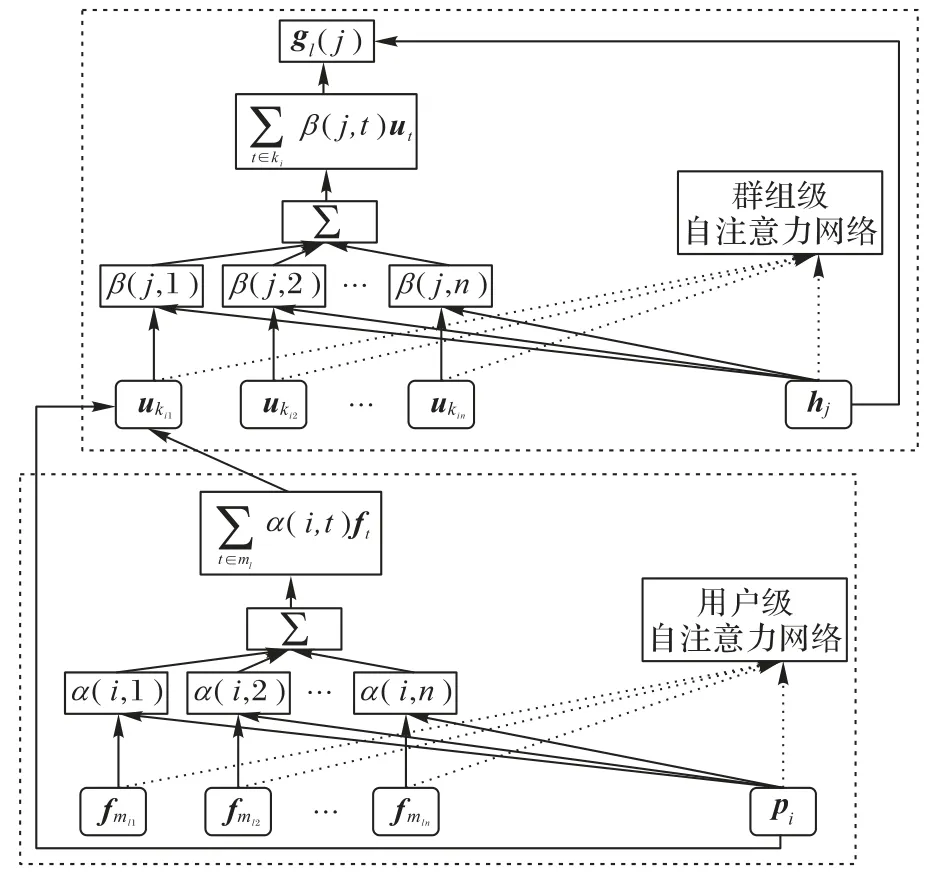
圖5 分層自注意力網絡的結構Fig.5 Structure of hierarchical self-attention network
3.2.1 用戶級自注意力網絡
在社交網絡中,用戶的興趣不僅和自身偏好相關,還受到朋友的影響;并且朋友的影響也不是一成不變的,在與不同的團購項目交互時,朋友的影響是動態變化的。將用戶的社交網絡數據輸入用戶級自注意力網絡中,結合用戶的一般偏好,得到用戶的向量表示。
具體地,根據圖5 中用戶級自注意力網絡的結構,本文將用戶嵌入表示分為其關注者嵌入融合表示和用戶自身偏好嵌入表示pi兩部分。
其中:α(i,t)是一個 可學習的參數,以ft和pi為輸入,如式(16)所示。
其中:WT表示預測層的權值矩陣,Wf和Wp表示將關注者的嵌入向量ft和用戶的一般偏好嵌入pi轉換到隱含層的權值矩陣,b表示偏差向量,GELU 作為隱層的激活函數,softmax 函數進行歸一化。
3.2.2 群組級自注意力網絡
群組級的自注意機制,基于用戶級的自注意力網絡學習融合策略。此群組級自注意力網絡的目標即通過成員用戶的嵌入表示ui,得到整個群組的表示gl。
具體地,與用戶級自注意力網絡類似,群組嵌入分為用戶嵌入融合和群組一般偏好嵌入qt兩部分,如式(18)所示:
摘 要:近年來,隨著“互聯網+”時代的來臨,新媒體在高等教育中得到廣泛應用,不僅有效提高了課堂教學質量,強化了大學生的學習效果,還進一步推動了高等院校的教育革新,對實現我國現代教育目標具有重要影響。思想政治是大學教育體系中的重要組成部分,新媒體的興起與發展既為大學生思想政治教育工作帶來前所未有的發展機遇,同時也提出了嚴峻的挑戰。現階段,如何有效運用新媒體提高大學生思想政治科目的教學效果,增強學生的核心素養,已經成為當今社會廣泛關注的首要課題,并受到人們的普遍重視。就新媒體環境下大學生思想政治教育展開探討,希望對日后的相關研究有所幫助。
其中:β(j,t)是一個可學習的參數,以ut和hj為輸入,如式(19)所示。
其中:W表示預測層的權值矩陣,Wu和Wh表示將用戶偏好嵌入ut和項目屬性嵌入hj轉換到隱含層的權值矩陣,b表示偏差向量,GELU作為隱層的激活函數,softmax函數進行歸一化。
3.3 多層神經網絡框架
神經協同過濾(NCF)是一個項目推薦的多層神經網絡框架[22]。它以分層自注意力網絡輸出的群組表示gl(j)和項目表示hj作為輸入,從數據中學習群組-項目交互。針對給定的群組-項目交互對(gl,hj),得到每個實體部分的嵌入向量,然后將它輸入多層感知機(Multi-Layer Perceptron,MLP),得到最終的群組預測得分。
其中:eh表示全連接層的第h層的輸出神經元。
4 仿真實驗與結果分析
4.1 RTSA實驗分析
4.1.1 實驗設計
1)實驗數據。
采用MovieLens-1M 和Amazon Beauty 數據集[18]評估本文模型。參照文獻[23]中的步驟進行預處理。將評級視作用戶的隱形反饋,即用戶與項目進行了交互。對于所有用戶,用其交互序列中的時間戳減去某個用戶的時間序列中最小的時間戳,并升序排序。此外,過濾了交互少于5 次的用戶和商品。數據集的統計特征如表1 所示。

表1 MovieLens-1M和Amazon Beauty數據集的統計特征Tab.1 Statistical characteristics of MovieLens-1M and Amazon Beauty datasets
在對兩個數據集預處理后,采用了leave-one-out 方法[22]將其分別劃分為訓練集、驗證集和測試集。即使用與用戶進行最后一次交互的項目進行測試,倒數第二個交互項目用于驗證,其余的項目作為訓練集。
本文采用準確率(Precision,Pre)、召回率(Recall)、命中率(Hit Rate,HR)和歸一化折損累計增益(Normalized Discounted Cumulative Gain,NDCG)[24]作為評價指標。受推薦列表長度的限制,一般取前10 個商品作為推薦結果展示[25],評價指 標分別 為Pre@10、Recall@10、HR@10 和NDCG@10。
其中:L(u)是用戶u的推薦列表,C(u)是用戶u在測試集中真正感興趣的商品;| |GT是所有用戶測試集合的商品總數,Number_of_Hits@k表示的是每個用戶top-k列表中屬于測試集合的個數總和;Zk是歸一化參數,ri表示排序為i的推薦結果的相關性,k表示推薦列表的大小。
3)對比模型。
為了驗證RTSA 的有效性,將其與以下4 種模型對比:1)個性化馬爾可夫鏈分解(FPMC)模型[6];2)基于會話的RNN 推薦(GRU4Rec)模型[13];3)基于時間間隔感知自注意力的序列化推薦(Time interval aware Self-Attention for Sequential Recommendation,TiSASRec)模型[18];4)卷積序列嵌入推 薦模型(Convolutional sequence embedding recommendation model,Caser)[26]。
4)參數設置。
本文基 于 PyTorch 1.6.0 框架實 現 RTSA。在MovieLens-1M 和Amazon Beauty 數據集中,設置參數值如下:batch size 為128,正則化比例為0.2,學習率η為0.001,使用Adam 優化器。其中,在MovieLen-1M 數據集中,最大交互序列長度為50,最大時間間隔為2 048;在Amazon Beauty 數據集中,最大交互序列長度為25,最大時間間隔為512。
4.1.2 序列推薦模型性能對比
在MovieLens-1M 和Amazon Beauty 數據集上,對比RTSA與4 種代表性的序列推薦模型,結果如表2 所示。

表2 2個數據集上5種推薦模型的對比結果Tab.2 Comparison results of five recommendation models on two datasets
1)在MovieLens-1M 數據集中,基于神經網絡的推薦模型(GRU4Rec、Caser)比基于馬爾可夫鏈的模型(FPMC)在Pre@10、Recall@10、HR@10 和NDCG@10 指標上均表現較好;在Amazon Beauty 數據集上,相較于GRU4Rec 和Caser,FPMC 在Recall@10 和NDCG@10 指標上性能更好。由此可見,各模型在不同稀疏度的數據集上有不同的推薦效果。
2)在兩個數據集中,基于時間間隔自注意力的推薦模型(TiSASRec)在4 個評價指標上比基于神經網絡的推薦模型(GRU4Rec、Caser)性能更好,表明基于自注意力機制的推薦模型能夠自適應地為不同的商品分配不同的權重,比基于神經網絡的推薦模型能更好地捕捉商品之間的依賴關系。同時,在一定程度上說明了時間間隔信息作為輔助信息對于提高模型推薦性能的積極作用。
在兩個數據集中,RTSA 在4 個指標上均優于其他對比模型。在MovieLens-1M 數據集中,相較于對比模型中最優的基線模型TiSASRec,RTSA 在Pre@10、Recall@10、HR@10 和NDCG@10 指標上 分別提高了2.91%、2.61%、5.52% 和5.78%。在Amazon Beauty 數據集中,相較于最優的基線模型,RTSA 在Pre@10、Recall@10、HR@10 和NDCG@10 指標上分別提高了10.34%、5.97%、11.73%和7.69%。
4.1.3 潛在維度d對模型的影響
在RTSA 中,潛在特征維度d是一個重要的參數。當d越大,向量表示越復雜,向量有更好的特征表達能力。圖6展示了MovieLens-1M 數據集中各個模型在{10,20,30,40,50}不同維度下的HR@10 和NDCG@10 值。

圖6 MovieLens-1M數據集上HR@10和NDCG@10隨著維度d的變化Fig.6 HR@10 and NDCG@10 changing with different dimension d on MovieLens-1M dataset
從圖6 可以看出,RTSA 在兩個評價指標上都超過了其他的基線模型;隨著特征維度的增加,RTSA 的HR@10 和NDCG@10 值也逐漸增加。
4.1.4 最大交互序列長度n對模型的影響
圖7 是在保持其他參數最優情況的前提下,在MovieLens-1M 數據集中,RTSA 在{10,20,30,40,50}不同交互序列長度下的NDCG@10 值。結果顯示了RTSA 當考慮較長的序列時,NDCG@10 值逐漸有所提高。由此可知當用戶的交互序列是長序列時,模型能夠更好地捕捉商品和時間間隔之間的關系模式,從而提升模型的推薦性能。

圖7 在Movielens-1M數據集上n對RTSA模型的影響Fig.7 Influence of n on RTSA model on MovieLens-1M dataset
4.1.5 個性化時間間隔思想的有效性
為了證明本文個性化時間間隔思想的有效性,本文進行了有無融合個性化時間間隔的對比實驗。當考慮個性化時間間隔因素時,即RTSA;當不考慮個性化時間間隔時,即不輸入個性化時間間隔矩陣。實驗結果如表3所示。
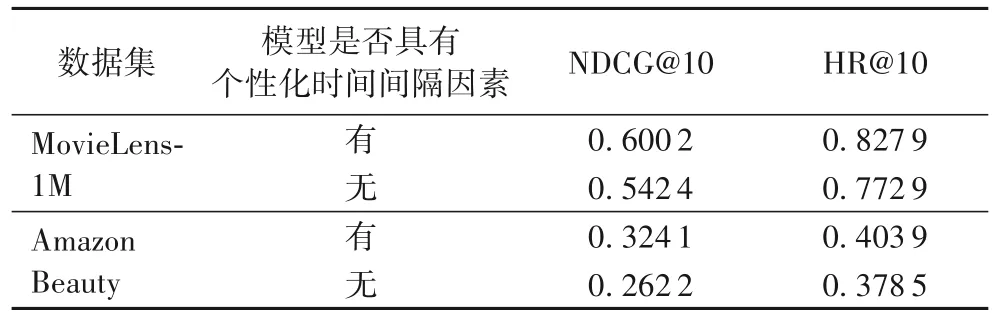
表3 時間間隔因素對模型的影響Tab.3 Influence of time interval factor on different models
由表3 可以看出,在兩個數據集上,具有個性化時間間隔因素的模型比不考慮個性化時間間隔思想的模型具有更好的推薦效果。這可能是因為融合個性化時間間隔的模型能準確、全面地刻畫用戶偏好的變化趨勢。把時間間隔信息作為輔助信息輸入模型中,能夠挖掘商品和時間間隔信息之間的隱式關聯,進一步從時間間隔的角度預測用戶在未來的興趣偏好。
4.1.6 TGRU對模型的影響
為了驗證TGRU 層在RTSA 中的有效性,進行了有無TGRU 層的消融實驗。當有TGRU 層時,即RTSA;當無TGRU層時,即個性化時間間隔嵌入表示直接輸入TSA 層。在MovieLens-1M 數據集上以HR@10 和NDCG@10 為例,實驗結果如圖8 所示。
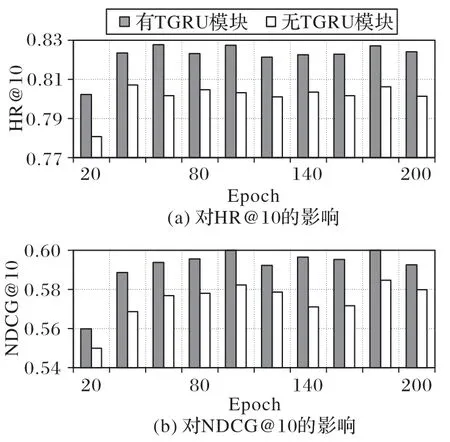
圖8 TGRU層對模型的影響Fig.8 Influence of TGRU layer on different models
4.2 SSAGR實驗分析
4.2.1 實驗設計
1)實驗數據。
本文采用MaFengWo 和Douban Book 數據集來評估提出的模型SSAGR。MaFengWo 是一個從旅游網站抓取的數據集,用戶記錄自己的旅行地點,創建或者加入群組。此數據集保留了至少包含2 個成員、去過3 個地點的群組信息,同時收集了每個群組的所有旅行地點以及每位群組成員的旅行地點。Douban Book,用戶一起閱讀書籍,項目對應于書籍。在預處理過程中,過濾了交互少于10 個的用戶和書籍。數據集的詳細信息如表4 所示。

表4 MaFengWo和Douban Book數據集的統計特征Tab.4 Statistical characteristics of MaFengWo and Douban Book datasets
以MaFengWo為例,它包括5 275個用戶、995個群組、1 513 個項目、39 761 個用戶-項目交互和3 595 個群組-項目交互。平均每個群組有7.19 個用戶,每個用戶去過7.54 個地點,每個群組去過3.61 個地點。用戶-項目交互矩陣的稀疏度是99.50%,群組-項目交互矩陣的稀疏度為99.76%。另外,此數據集還包括社交關注信息,收集其中5 275 個用戶的關注數據。最終此數據集還包括13 076 個關注人、53 235個用戶-關注者交互。平均每個用戶有10.09 個關注者,每個關注者被4.06 個用戶關注。
2)評價指標。
本文最終的目標是將推薦列表采用top-k方式推薦,因此為了評價推薦模型的有效性,采用了leave-one-out 方法[22]。為了直觀體現SSAGR 的改進效果,本文參照文獻[24]采用了兩個廣泛使用的top-k評價指標,命中率(HR)和歸一化折現累積增益(NDCG)。受推薦列表長度的限制,一般取前5 或10 個商品作為推薦結果展示[25],故本文評價指標分別為HR@5、NDCG@5、HR@10 和NDCG@10。
3)對比模型。
為了證明本文提出模型SSAGR 的有效性,將它與以下基線模型進行了對比實驗。
AGREE[12]采用了注意力網絡得到群組嵌入表示,通過NCF 框架建模群組-項目間的交互。與其他的群組推薦模型GroupIM(Group Information Maximization)[27]、DRGR(Deep Reinforcement learning based Group Recommender system)[28]等相比,AGREE 有著更優的性能。SIGR(Social Influence-based Group Recommender)[29]根據用戶-項目圖和群組-項目圖的嵌入模型,利用注意力機制學習不同組中用戶的影響。
為了驗證本文融合策略的有效性,對比了幾種預定義融合策略。NCF[22]將群組當作用戶進行推薦。NCF+avg[7]采用平均融合策略,群組偏好分數為個體偏好得分的均值。NCF+lm[8]采用最小痛苦策略,群組偏好分數為成員的最低分數。NCF+ms[9]采用最大滿意度策略,群組偏好分數為成員的最高分數。NCF+exp[10]采用專家策略,本文考慮的專家知識為用戶在訓練集中交互的項目數量[29]。
SSAGR-G 為SSAGR 的變體,它僅考慮群組級自注意力網絡,不考慮社交網絡的影響,即不輸入用戶-社交關注者交互數據。SSAGR-F 為SSAGR 的另一個變體,它僅考慮用戶級自注意力網絡,對于群組用戶的融合表示過程采用統一的權重。
4)參數設置。
為了優化SSAGR 的參數,本文對兩個數據集進行了網格搜索[30],參數的搜索范圍為:在[128,256,512,1 024]和[0.001,0.005,0.01,0.05,0.1]中分別選擇批量大小和學習率。同時本文參照文獻[22]將負采樣比設置為4;對于嵌入層,采用了Glorot 初始化策略;對于隱藏層,所有參數均使用均值為0、標準差為0.1 的高斯分布進行初始化;在分層自注意力網絡和NCF 中,將第一個隱藏層的尺寸與嵌入層的尺寸設置為32。
4.2.2 群組推薦模型性能對比
在MaFengWo 和Douban Book 數據集上,本文將SSAGR與其他基線模型進行了對比,結果如表5 所示。

表5 各推薦模型在兩個數據集上的性能對比Tab.5 Performance comparison of recommendation models on two datasets
從表5 中可見:1)在MaFengWo 和Douban Book 數據集上,SSAGR 相較于其他群組推薦模型,在兩個評價指標上具有更好的推薦效果,驗證了本文模型的有效性。在MaFengWo 數據集中,相較于最優的基線模型AGREE,SSAGR 在HR@5、NDCG@5、HR@10、NDCG@10 指標上分別提高了3.53%、2.63%、1.81%、2.17%。在Douban Book 數據集中,相較于最優的基線模型AGREE,SSAGR 在在HR@5、NDCG@5、HR@10、NDCG@10 指標上分別 提高了2.92%、2.52%、1.49%、2.04%。2)NCF+avg、NCF+lm、NCF+mp 和NCF+exp 這4 種模型中,沒有明顯更優的模型,說明了預定義的靜態融合策略不能準確地對群組決策過程建模,也側面說明了自注意力網絡動態學習用戶權重的必要性。3)上述各種推薦模型在兩個評價指標上,當推薦個數為10 時均取得更好的推薦結果。
4.2.3 迭代次數c對模型的影響
在SSAGR 中,迭代次數c是一個重要的參數。以MaFengWo 數據集為例,圖9 展示了SSAGR 和AGREE 在兩個推薦指標上,隨c變化的性能對比結果。

圖9 MaFengWo數據集上迭代次數c對HR@10和NDCG@10的影響Fig.9 Influence of the number of iterations c on HR@10 and NDCG@10 on MaFengWo dataset
從圖9 中可見:1)相較于AGREE,SSAGR 方法在HR@10和NDCG@10 兩個評價指標上具有更好的效果,表明利用分層自注意力網絡融入用戶的社交網絡數據,在一定程度上提高了推薦模型的有效性;2)與AGREE 的收斂速度相似,SSAGR 基本在迭代次數為20 時趨于穩定。與AGREE 相比,本文還使用另一個自注意力網絡加權社交關注者的嵌入向量。在不影響收斂速度的情況下提高了模型的泛化性,為SSAGR的有效性提供了依據。
4.2.4 推薦序列長度k對模型的影響
在團購推薦模型中,推薦列表長度k也是一個重要的參數。以MaFengWo 數據集為例,圖10 展示了SSAGR 和AGREE 在兩個推薦指標上,隨k變化的性能對比結果。

圖10 推薦列表長度k對HR@k和NDCG@k的影響Fig.10 Influence of recommendation list length k on HR@k and NDCG@k
從圖10 中可以看出,對于SSAGR 和AGREE 的top-k性能問題,當推薦個數k為10 時均取得更好的推薦結果,隨著k值增加,HR 和NDCG 兩個評價指標越來越高。因此,推薦列表長度的增加可在一定程度上提高推薦準確性。
4.2.5 模型組件的影響
為了驗證SSAGR 在用戶級和群組級考慮的全面性,本文提出了SSAGR-G 和SSAGR-F 兩種變體模型,在MaFengWo數據集上進行了對比實驗,結果如圖11 所示。

圖11 MaFengWo數據集上3種模型的性能對比Fig.11 Performance comparison of three models on MaFengWo dataset
從圖11 中可見:1)相較于其他兩種考慮較為單一的算法,SSAGR 利用了兩個自注意力網絡,同時考慮了群組與用戶、用戶與關注者之間的關系,具有更優的推薦效果。這說明社交關注者嵌入聚合和用戶嵌入聚合都有利于群組決策,組合起來可以獲得更好的性能。2)SSAGR-G 的性能優于SSAGR-F,說明在SSAGR 框架下,用戶偏好嵌入學習的重要性大于社交關注者的嵌入融合學習。
4.2.6 分層自注意力網絡的作用
SSAGR 除了具有更好的推薦性能外,還能解釋群組成員的注意權重。為了深入了解分層自注意力網絡的注意力權重學習過程,本文在一個兩部分的方案中,對隨機選擇的測試群組和測試用戶進行了案例分析。
為了驗證群組級自注意力網絡的作用,分析群組對正實例和負實例的預測得分,首先在數據集MaFengWo 中隨機選擇了1 個測試群組(G49),其中包括3 個成員用戶(U837、U838 和U839),該群組一起參觀了3 個正實例地點(I54、I284和I462),設目標值為1(正實例為1,負實例為0)。除了3 個正實例地點外,本文還隨機選取了3 個負實例(I52、I346 和I591),其目標值設為0。表6 展示了SSAGR 和SSAGR-F 中群組用戶的注意力權重和抽樣群組對實例地點的預測得分R。

表6 抽樣群組對群組級自注意力的影響Tab.6 Influence of sampled groups on group-level self-attention
由表6 可見:1)對于不同的地點,群組成員的注意權重有明顯的差異。2)對于正實例,SSAGR 的預測得分遠大于SSAGR-F,更接近目標值1;對于負實例,SSAGR 的預測得分小于SSAGR-F,更接近目標值0。由于SSAGR-F 為群組中的所有成員用戶分配了相同的權重,因此模型的能力相對有限。這說明了將群組級自注意力網絡融入SSAGR 的有效性和考慮用戶關系的全面性。
為了深入了解用戶級的注意權重學習,本文對一個隨機選擇的測試用戶(U127)進行了案例分析,獲得了此用戶的社交關注者(F43、F328 和F739),并隨機選擇了3 個正實例(I31、I297 和I521)和3 個負實例(I81、I189 和I542)。表7 展示了SSAGR 和SSAGR-G 中各社交關注者的注意力權重和抽樣用戶對實例地點的預測得分R。

表7 抽樣用戶對用戶級自注意力的影響Tab.7 Influence of sampled users on user-level self-attention
由表7 可見:1)對于不同的地點,各社交關注者的注意力權重具有明顯的差異。例如,對于地點I297、I521 和I189,關注者F739 的注意力權重相較于其他用戶較高,這可能是因為人們的旅游場館和觀察到的場館相似。2)相較于模型SSAGR-G,SSAGR 的預測得分更接近目標值(正實例為1,負實例為0)。這說明了將用戶級自注意力網絡融入本文框架的有效性。
4.3 RTSA與SSAGR對比實驗分析
4.3.1 實驗設計
1)實驗數據。
為了對比本文所提模型RTSA 和SSAGR 的性能,本文在Douban Book 數據集上進行對比實驗與分析。在預處理過程中,過濾掉交互少于10 個的用戶和書籍。
2)評價指標。
在評價指標的選擇上,本文采用HR 和NDCG。同時受推薦列表長度的限制,一般取前10 個商品作為推薦結果展示[25],故本節實驗的評價指標為HR@10 和NDCG@10。
3)對比模型。
在對比模型的選擇上,由于本文在SSAGR 的NCF 框架中集成了用戶-項目交互數據來提高群組推薦的性能,學習了同一嵌入空間中用戶-項目交互與群組-項目交互,所以在同一框架NCF 中能夠同時處理群組推薦和項目推薦[15]。本節對比了RTSA 與SSAGR 對單個用戶進行項目推薦的性能,并分析了SSAGR 在群組推薦SSAGR(Group)和用戶推薦SSAGR(User)兩個方面的性能差異。
4.3.2 實驗結果分析
在Douban Book 數據集上,本文將RTSA 與SSAGR 推薦模型進行了對比,結果如表8 所示。

表8 在Douban Book數據集上模型性能對比Tab.8 Models performance comparison on Douban Book dataset
從表8 中可見:1)在對單個用戶進行項目推薦時,RTSA的性能優于SSAGR。這在一定程度上說明,在使用RNN 和自注意力網絡對目標用戶進行項目推薦時,個性化時間間隔因素的重要性大于用戶社交關系因素。2)在使用SSAGR 對User 和Group 進行推薦時,SSAGR(User)的性能優于SSAGR(Group)。這在一定程度上說明,群體推薦需考慮群組內每個用戶的興趣偏好生成群體推薦模型,推薦結果可能是在犧牲部分用戶特有偏好的基礎上完成的;而個體推薦是基于用戶自身的交互數據構建的偏好模型,與用戶的需求一致,故準確率更高。由此說明,群體推薦的研究以個體推薦的研究為基礎,但遠復雜于個體推薦。
4.3.3 單個抽樣用戶對推薦結果的影響
為了深入了解提出的兩個推薦模型,本文對隨機選擇的測試用戶進行了實例分析。首先在Douban Book 數據集上隨機選擇了1 個測試用戶(U851),并隨機選擇了包含此用戶的3 個群組(G105、G175 和G209)。表9 以實例的形式展示了RTSA 與SSAGR 的top-5 推薦結果。

表9 Douban Book數據集上抽樣用戶與群組的top-5結果Tab.9 Top-5 results for sampled users and groups on Douban Book dataset
由表9 可見:1)RTSA 與SSAGR 對單個用戶U851 進行推薦的top-5 推薦結果不同。因為RTSA 在進行單個推薦時,性能優于SSAGR。故RTSA 的top-5 推薦結果結合了用戶U851的興趣偏好(懸疑、影視),推薦的書籍類型是懸疑、影視。而由表8 可以看出SSAGR 模型進行單個用戶推薦時較差,故推薦的top-5 在懸疑、影視外還包括言情類型(怦然心動)。2)在SSAGR 模型中,隨機選取了包含用戶U851 的3 個群組(G105、G175 和G209)。在3 個群組的top-5 推薦結果中,與對單個用戶U851 進行推薦的結果并不完全相同。因為SSAGR 構建了分層自注意力網絡,群組嵌入分為用戶偏好嵌入融合和群組一般偏好嵌入兩部分,用戶嵌入表示分為關注者嵌入融合表示和用戶自身偏好嵌入表示兩部分。故在進行群組推薦時,SSAGR 的結果并非只是考慮用戶U851 的興趣偏好(懸疑、影視),還需結合群組內其他成員的偏好(如群組G209 的興趣偏好還包括科幻),動態聚合后進行最終的群組推薦。3)在3 個群組中,由于G105、G175 和G209 成員個數分別為4、7、14,故在進行群組推薦時,成員用戶較少的群組中,用戶U851 在構建群組興趣模型時起到的作用更大,與對單個用戶推薦結果的相似度更高。
4.3.4 不同抽樣用戶對推薦結果的影響
為了分析用戶參與群組的個數對推薦效果的影響,本文利用SSAGR 在Douban Book 數據集中進行了實驗分析。以均值重復率作為指標展示了用戶參與群組個數對推薦結果的影響。其中,均值重復率定義為此用戶所在多個群組的top-5 推薦結果與此單個用戶top-5 推薦結果中重復率的均值,如式(26)所示:
其中:R表示均值重復率;n表示測試用戶參與群組個數;k表示推薦列表長度;mi表示用戶所在群組top-k推薦列表中與個體推薦結果中重復的個數。
當用戶分別參與5、10 和20 個群組時,其均值重復率的值依次為0.381 2、0.204 3 及0.231 9。由此可見:1)隨著用戶參與群組的個數越來越多,重復率基本呈現下降的趨勢。這主要是因為用戶在不同的群組內,他的興趣偏好多樣化,故在進行目標群組推薦時,在群組偏好模型構建過程中產生的影響力降低,從而影響最終的推薦結果,導致重復率下降。2)當用戶參與群組個數為20 時,重復率稍高于用戶參與群組個數為10 時的情況。這可能是由于推薦中歧義情況所在,雖然此用戶參與的群組個數較多,但他與項目的交互數據也很多,故他在群組中的影響力相較于交互數據少的用戶更高。所以推薦平臺若對此類用戶的興趣模型進行深層次的分析,能夠進一步挖掘此類用戶的商業價值,對推薦平臺分析用戶的興趣偏好在維持現有用戶群體的基礎上吸引新的用戶,具有一定的意義。
5 結語
本文在團購場景下,研究了基于社交關系和時序信息的團購推薦方法。
對于團購中的單個用戶,提出了融合TGRU 和自注意力的團購推薦模型RTSA。首先通過計算用戶購買的任意兩個商品之間的個性化時間間隔,構建了TGRU 模塊;進一步地,考慮到用戶-商品交互序列中不相關數據會產生噪聲,采用自注意力網絡,研究了商品位置及個性化時間間隔的影響。
對于團購中的群組用戶,提出了融合社交網絡和分層自注意力的團購推薦模型SSAGR。首先,采用RNN,獲取了團購中用戶隨時間變化的潛在興趣;然后,利用用戶級自注意力網絡,將用戶的社交網絡信息整合到用戶表示中;進一步地,通過群組級自注意力網絡,動態調整群組中用戶的權重,得到了群組表示向量;最后,通過NCF 框架挖掘群組-項目交互,完成了團購群組推薦。
實驗結果表明,RTSA 和SSAGR 在各評價指標上均有明顯提高,驗證了兩個模型的有效性;在對單個用戶進行項目推薦時,RTSA 性能優于SSAGR,且SSAGR 對單個用戶進行推薦時性能優于對群組進行推薦,說明了群體推薦的研究是以個體推薦的研究為基礎,但比個體推薦更復雜。
在之后的研究中,可以將社交關系分解為多個方面,如同事、家庭等,然后將每個方面的社交影響編碼為分離的用戶嵌入,以提高團購推薦的準確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
