基于網(wǎng)頁源碼結(jié)構(gòu)理解的自適應(yīng)爬蟲代碼生成方法
2023-07-03 14:11:56劉耀,劉茹,翟雨
計(jì)算機(jī)應(yīng)用 2023年6期
關(guān)鍵詞:結(jié)構(gòu)模型
劉 耀,劉 茹,翟 雨
(1.中國科學(xué)技術(shù)信息研究所 信息技術(shù)支持中心,北京 100038;2.北京大學(xué) 軟件與微電子學(xué)院,北京 102600)
0 引言
網(wǎng)絡(luò)信息資源中存在著大量極具參考價(jià)值的學(xué)術(shù)信息、社會(huì)信息,大數(shù)據(jù)浪潮推動(dòng)了網(wǎng)絡(luò)資源的爆發(fā)式增長,使網(wǎng)絡(luò)資源的分類、聚合、組織與展示形態(tài)以更具多樣化的方式呈現(xiàn),給網(wǎng)絡(luò)信息的自動(dòng)化采集與挖掘技術(shù)帶來了挑戰(zhàn)。一方面,現(xiàn)存面向單一語境的網(wǎng)頁信息提取方法適應(yīng)性和泛化能力較差,難以滿足高度自動(dòng)化的網(wǎng)頁信息采集需求;另一方面,網(wǎng)頁改版事件頻繁發(fā)生,導(dǎo)致爬蟲代碼中網(wǎng)頁實(shí)體抽取模塊代碼失效,需要大量人力進(jìn)行修復(fù)和維護(hù)。
由于實(shí)體抽取模塊代碼基本以XPath(XML Path language)或CSS(Cascading Style Sheets)選擇器代碼為主,這部分代碼反映了網(wǎng)頁源碼中目標(biāo)實(shí)體的位置結(jié)構(gòu)、文本標(biāo)識等信息,是爬蟲待獲取的目標(biāo)實(shí)體在網(wǎng)頁源碼中的直接反映。本文提出基于網(wǎng)頁源碼結(jié)構(gòu)理解的自適應(yīng)爬蟲代碼生成方法,從網(wǎng)頁源碼變動(dòng)的泛化感知能力、自適應(yīng)性生成爬蟲代碼能力方面對通用網(wǎng)絡(luò)爬蟲的自適應(yīng)性展開研究,旨在針對網(wǎng)頁改版實(shí)現(xiàn)網(wǎng)頁信息自動(dòng)化采集,提高爬蟲系統(tǒng)的自適應(yīng)能力。
本文的主要工作包括3 個(gè)方面:1)通過分析爬蟲業(yè)務(wù)流程和面向網(wǎng)頁改版事件的爬蟲代碼報(bào)錯(cuò)類型,揭示網(wǎng)頁源碼的結(jié)構(gòu)變動(dòng)類型和爬蟲代碼的適應(yīng)性修改間的關(guān)聯(lián);2)依據(jù)網(wǎng)頁源碼變動(dòng)的結(jié)構(gòu)、內(nèi)容特征、爬蟲代碼特征和目標(biāo)實(shí)體文本特征,采用樹節(jié)點(diǎn)分類、語義相似度等方法從自動(dòng)生成和相似推薦兩個(gè)角度提出基于網(wǎng)頁源碼結(jié)構(gòu)變動(dòng)程度的爬蟲代碼生成方案;3)提出用于表征網(wǎng)頁源碼變動(dòng)的、編碼器-解碼器(Encoder-Decoder,ED)與網(wǎng)絡(luò)表示學(xué)習(xí)相結(jié)合的嵌入表示方法,有效地提高了代碼生成模型的準(zhǔn)確率和對網(wǎng)頁源碼變動(dòng)感知的泛化能力。
1 相關(guān)研究
爬蟲研究在廣義上指基于對網(wǎng)絡(luò)通信和網(wǎng)頁源碼理解的自動(dòng)化工具研究,通過一定的策略沿著由網(wǎng)頁鏈接節(jié)點(diǎn)構(gòu)成的拓?fù)渚W(wǎng)絡(luò)中的信息采集工具。狹義上指面向單個(gè)網(wǎng)頁的網(wǎng)頁信息抽取技術(shù)。
爬蟲軟件的自適應(yīng)性研究方面,一些以自適應(yīng)為標(biāo)題的研究[1-4]并未從自適應(yīng)性系統(tǒng)的角度切入,仍停留在提出實(shí)現(xiàn)爬蟲某一環(huán)節(jié)的自動(dòng)實(shí)現(xiàn)方法研究階段,如網(wǎng)頁信息自動(dòng)抽取、網(wǎng)頁自動(dòng)下載等。爬蟲技術(shù)相關(guān)研究中,針對網(wǎng)頁變動(dòng)的爬蟲研究較少。Cohen 等[5]提出針對網(wǎng)頁變動(dòng)從子樹匹配的角度提出XPath 生成方法;Choudhary 等[6]從Web 應(yīng)用自動(dòng)化測試的角度對網(wǎng)頁源碼的變動(dòng)進(jìn)行研究,將變動(dòng)前后的網(wǎng)頁源碼進(jìn)行關(guān)聯(lián)研究。目前較為主流且工程性的網(wǎng)頁信息自動(dòng)抽取方法仍多以XPath 路徑表達(dá)式模板為主,因此針對XPath的自動(dòng)生成研究也較多,如Cohen 等[5]提出DOM(Document Object Mode)樹子樹匹配的方法自動(dòng)化地生成XPath 代碼;Jundt等[7]提出基于規(guī)則生成XPath 后與檢索詞之間關(guān)聯(lián)程度的排序機(jī)制;吳共慶等[8]同樣對XPath 進(jìn)行研究,提出了區(qū)分噪聲的網(wǎng)頁正文提取方法。基于機(jī)器學(xué)習(xí)的網(wǎng)頁信息自動(dòng)抽取方面,在利用機(jī)器學(xué)習(xí)或深度學(xué)習(xí)的爬蟲技術(shù)研究中,有些學(xué)者利用了網(wǎng)頁超文本標(biāo)記語言(Hyper Text Markup Language,HTML)源碼的強(qiáng)結(jié)構(gòu)性特征,利用深度學(xué)習(xí)中的圖論對網(wǎng)頁源碼進(jìn)行表示學(xué)習(xí),如Gogar等[9]提出基于卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)的DCNN(Deep CNN)圖像分類器,結(jié)合機(jī)器視覺的方法進(jìn)行網(wǎng)頁信息抽取;Tan 等[10]提出將網(wǎng)頁中的鏈接構(gòu)建成網(wǎng)絡(luò),提取釣魚網(wǎng)頁的超鏈接文本特征,從而建立網(wǎng)絡(luò)釣魚檢測的隨機(jī)森林分類器,并通過對比支持向量機(jī)、樸素貝葉斯等分類器,驗(yàn)證了隨機(jī)森林算法在圖模型分類任務(wù)中效果相對最好。
代碼表示學(xué)習(xí)大多采用word2vec(word to vector)、doc2vec(document to vector)或基于長短期記憶(Long Short-Term Memory,LSTM)的序列網(wǎng)絡(luò)模型,如code2seq(code to sequence)方法[11]主要通過LSTM 網(wǎng)絡(luò)對代碼文本進(jìn)行表示,對代碼片段進(jìn)行序列化向量表示。Li 等[12]提出的word2API(word to API)則通過詞嵌入技術(shù)對自然語言中的詞組與程序語言中的應(yīng)用程序編程接口(Application Programming Interface,API)進(jìn)行聯(lián)合建模,以解決跨語言匹配過程中出現(xiàn)的詞不匹配問題。但這些代碼的語義表示方法通常只利用代碼的淺層文本語義特征,未能結(jié)合代碼本身的強(qiáng)結(jié)構(gòu)性特征。文獻(xiàn)[13-14]在網(wǎng)絡(luò)表示學(xué)習(xí)方法上提出不同的改進(jìn)機(jī)制,其中PGE(Property Graph Embedding)模型使用節(jié)點(diǎn)聚類以分配偏差區(qū)分節(jié)點(diǎn)的鄰居,并利用基于鄰居的有偏采樣機(jī)制融合更多的屬性信息,相較于DeepWalk 的基線模型提升了10 個(gè)百分點(diǎn),比圖卷積網(wǎng)絡(luò)(Graph Convolutional Network,GCN)提升了3 個(gè)百分點(diǎn)。文獻(xiàn)[15]提出對圖模型之間的映射關(guān)系建模的Graph-to-Graph 算法。
網(wǎng)絡(luò)表示學(xué)習(xí)的基本原理如圖1,不同灰度用于區(qū)分不同節(jié)點(diǎn),首先按需生成隨機(jī)游走,將網(wǎng)絡(luò)中的節(jié)點(diǎn)當(dāng)作句子的詞,節(jié)點(diǎn)的連接信息當(dāng)作句子在模型中進(jìn)行訓(xùn)練,最后獲得每個(gè)節(jié)點(diǎn)地位稠密的向量表示。本文認(rèn)為可通過構(gòu)建代碼的圖模型,采用圖神經(jīng)網(wǎng)絡(luò)研究中的網(wǎng)絡(luò)表示學(xué)習(xí)模型對網(wǎng)頁的HTML源碼及爬蟲的代碼及XPath等結(jié)構(gòu)表達(dá)式進(jìn)行表示學(xué)習(xí)。

圖1 網(wǎng)絡(luò)表示學(xué)習(xí)原理Fig.1 Principle of network representation learning
本文結(jié)合自適應(yīng)軟件理論思想[16-17],提出了自適應(yīng)爬蟲可借鑒自適應(yīng)軟件的控制理論。一方面,通過建立深度結(jié)構(gòu)化的源碼知識庫和代碼決策庫,將HTML 網(wǎng)頁源碼和爬蟲代碼各自表示為融合標(biāo)簽和語義結(jié)構(gòu)信息的圖嵌入表示;另一方面,針對網(wǎng)頁源碼的結(jié)構(gòu)性變動(dòng)特征進(jìn)行表示學(xué)習(xí),采用深度學(xué)習(xí)技術(shù)建立從HTML 源碼的變動(dòng)到爬蟲代碼間的映射生成模型,從而實(shí)現(xiàn)具備自適應(yīng)感知、自適應(yīng)代碼生成更新及激活能力的自適應(yīng)爬蟲系統(tǒng)。并且連通自適應(yīng)系統(tǒng)的各個(gè)環(huán)節(jié),形成完整的“感知-決策-執(zhí)行-評價(jià)”業(yè)務(wù)閉環(huán),以有效解決真實(shí)的場景問題。
2 基于源碼變動(dòng)的爬蟲生成模型
自適應(yīng)代碼生成之前需要經(jīng)過網(wǎng)頁源碼(下文簡稱源碼)解析及其變動(dòng)感知過程,而對源碼變動(dòng)的感知建立在對源碼結(jié)構(gòu)及其語義特征深度理解的基礎(chǔ)上,本章以HTML DOM 樹和Java 抽象語法樹為指導(dǎo),通過源代碼結(jié)構(gòu)化解析方法實(shí)現(xiàn)網(wǎng)絡(luò)資源獲取過程中網(wǎng)站樣式改版問題必需的資源深度解析任務(wù)。為了完成對資源的深層語義加工,為后續(xù)的源代碼映射建模提供數(shù)據(jù)基礎(chǔ),首先需要在理解源碼的基礎(chǔ)上進(jìn)行元素節(jié)點(diǎn)分類,其次需要完成結(jié)構(gòu)相似度計(jì)算。待分類的對象是源碼中的一個(gè)元素標(biāo)簽及其屬性和文本,通常屬于篇幅較小的短文本分類問題。考慮圖表示學(xué)習(xí)算法可以對構(gòu)建好的代碼DOM 樹進(jìn)行向量訓(xùn)練,利用圖神經(jīng)網(wǎng)絡(luò)中的節(jié)點(diǎn)分類算法更適合本文的研究任務(wù)。本文采用XGBoost(Extreme Gradient Boosting)梯度提升樹[18]的改進(jìn)算法。
2.1 源碼變動(dòng)特征研究
網(wǎng)頁改版前后HTML 源碼的變動(dòng)特征與改版前的爬蟲代碼特征是修復(fù)停滯的爬蟲業(yè)務(wù)流程、生成新爬蟲代碼的重要依據(jù)。本文從源碼結(jié)構(gòu)性變動(dòng)程度、布局類型變動(dòng)和局部節(jié)點(diǎn)變動(dòng)(橫向、縱向變動(dòng))這3 個(gè)層面對源碼變動(dòng)進(jìn)行度量,將網(wǎng)頁源碼的變化特征結(jié)合其對應(yīng)代碼特征,將源碼變化類型分為兩種:1)父級元素不變化,目標(biāo)元素在父級元素范圍內(nèi)的變化;2)父級元素發(fā)生改變的大規(guī)模源碼變化。
如表1 所示,源碼結(jié)構(gòu)性變動(dòng)以出錯(cuò)的目標(biāo)實(shí)體為具體對象,變動(dòng)程度分為結(jié)構(gòu)性變動(dòng)和非結(jié)構(gòu)性變動(dòng)。結(jié)構(gòu)性變動(dòng)又代表布局結(jié)構(gòu)類型變動(dòng),意味著網(wǎng)頁改版事件不僅導(dǎo)致某幾處實(shí)體發(fā)生局部的橫向或縱向移動(dòng)或?qū)傩詢?nèi)容變化,而且整篇源碼的結(jié)構(gòu)和內(nèi)容均發(fā)生多處改變,最直接的影響是原本的XPath 代碼所對應(yīng)的父節(jié)點(diǎn)與子節(jié)點(diǎn)均在新源碼中找不到對應(yīng)。區(qū)分方法以源碼的結(jié)構(gòu)性差異為特征,采用特征融合方法訓(xùn)練結(jié)構(gòu)差異閾值,作為網(wǎng)頁源碼變動(dòng)類型的判斷依據(jù)。本文涉及的網(wǎng)頁布局結(jié)構(gòu)類型是基于對HTML 源碼結(jié)構(gòu)理解、目標(biāo)實(shí)體在源碼中分布的次序信息等先驗(yàn)知識的總結(jié)與歸納,對修剪后的網(wǎng)頁源碼DOM 樹進(jìn)行分類,從而得到布局結(jié)構(gòu)的源碼特征。
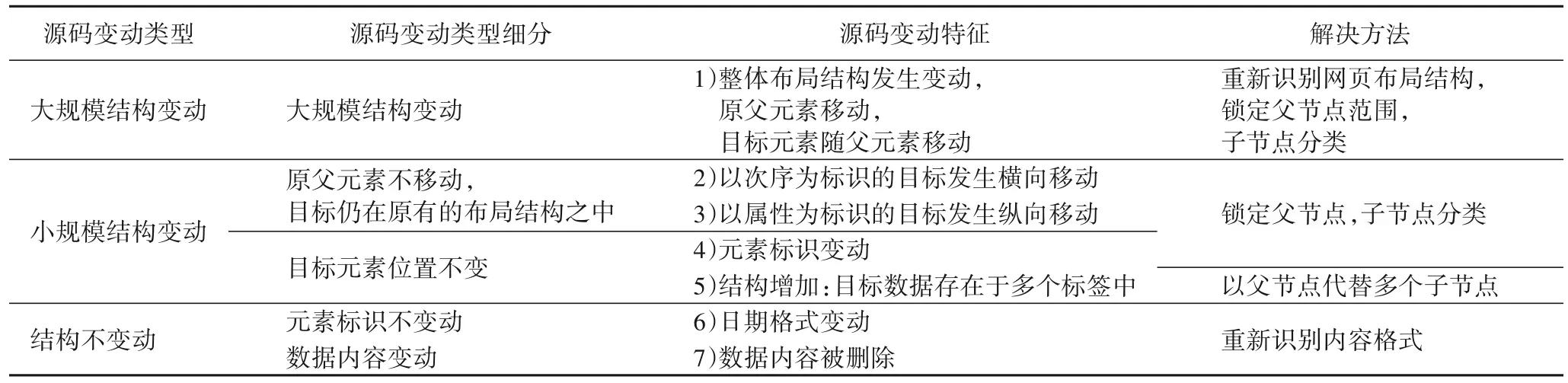
表1 源碼的7種變動(dòng)類型Tab.1 Seven change types of source code
2.2 基于源碼變動(dòng)的代碼生成模型
對于爬蟲代碼的生成方式,實(shí)體抽取、實(shí)體解析代碼分別采用不同的方法生成。實(shí)體抽取代碼一方面依據(jù)源碼的變動(dòng)特征,可通過計(jì)算發(fā)生相似變動(dòng)的源碼集合推薦這些源碼所對應(yīng)的變動(dòng)類型,進(jìn)而確定源碼變動(dòng)范圍;另一方面,可通過分類算法對源碼中的節(jié)點(diǎn)進(jìn)行分類預(yù)測,結(jié)合源碼變動(dòng)特征確定待分類的節(jié)點(diǎn)集合范圍,從而得到分類為目標(biāo)實(shí)體標(biāo)簽的元素對應(yīng)XPath,最終經(jīng)排序?qū)W習(xí)得到最準(zhǔn)確的實(shí)體抽取代碼。解析代碼與實(shí)體抽取代碼類似,可依據(jù)網(wǎng)頁改版特征推薦最相似的變動(dòng)類型所對應(yīng)的代碼變動(dòng)類型,只不過需要廣泛地從網(wǎng)絡(luò)資源中獲取相關(guān)代碼,作為排序與推薦計(jì)算的數(shù)據(jù)基礎(chǔ)。
雖然基于源碼結(jié)構(gòu)理解與源碼變動(dòng)類型判斷的爬蟲代碼生成方法可以一定程度地提高代碼生成與推薦的準(zhǔn)確性(見3.3 節(jié)實(shí)驗(yàn)部分),但是這種多種傳統(tǒng)自然語言處理手段疊加的方法在自適應(yīng)感知與決策任務(wù)上仍存在一定的局限性,表現(xiàn)為缺乏靈活表征源碼變動(dòng)的能力,以及代碼生成模型的有限生成能力,無法面向未知的源碼變動(dòng)情況自適應(yīng)地生成爬蟲代碼。因此,本節(jié)在前文基礎(chǔ)上提出一種泛化的、自適應(yīng)的源碼變動(dòng)感知及爬蟲代碼自適應(yīng)生成模型。
如圖2 所示,首先以通用的、泛化的源碼變動(dòng)表示方法代替源碼變動(dòng)類型判定方法;其次基于深度學(xué)習(xí)模型中的端到端模型,將“變動(dòng)前源碼-變動(dòng)后源碼”的變動(dòng)內(nèi)容、變動(dòng)前爬蟲代碼作為代碼生成模型的嵌入層,以變動(dòng)后代碼為輸出層,構(gòu)建源碼變動(dòng)-代碼的映射模型。
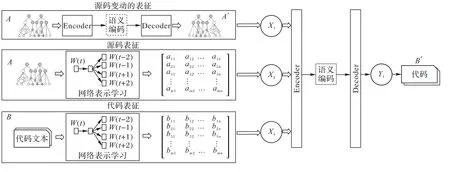
圖2 源碼變動(dòng)下的自適應(yīng)爬蟲代碼生成模型Fig.2 Adaptive Web crawler code generation model under source code changes
圖2 中,W(t)代表t時(shí)刻節(jié)點(diǎn);X1、X2和X3表示輸入變量,分別對應(yīng)模型提出的源碼變動(dòng)表征、源碼表征和代碼表征;Y1是輸出變量,即要預(yù)測的代碼對象。若將變化前源碼記為A,變化后記為A',變化前代碼記為B,變化后記為B',本文的目的即為構(gòu)建{[(A-A')+(AA')+(A-B)]-B′}的關(guān)聯(lián)映射模型。通過融合源碼變動(dòng)特征、源碼自身結(jié)構(gòu)語義特征、源碼-代碼關(guān)聯(lián)映射這3 種特征,利用網(wǎng)絡(luò)表示學(xué)習(xí)與ED 模型對源代碼的雙層表征,再利用Seq2Seq(Sequence to Sequence)模型以3 種特征為嵌入層,以爬蟲代碼為輸出層,構(gòu)建源代碼映射的代碼生成模型。
3 自適應(yīng)爬蟲代碼生成技術(shù)及實(shí)驗(yàn)
爬蟲代碼生成任務(wù)可分解為網(wǎng)頁改版類型判定與代碼生成兩部分。本章介紹源碼變動(dòng)程度計(jì)算以及代碼生成技術(shù),將前文提到的兩種代碼生成模型分別進(jìn)行實(shí)驗(yàn),展示傳統(tǒng)自然語言處理方法疊加的爬蟲代碼生成與不區(qū)分變動(dòng)類型的源代碼映射代碼生成模型結(jié)果。
3.1 基于源碼變動(dòng)的爬蟲代碼生成實(shí)驗(yàn)
表1 中3 種源碼變動(dòng)類型是基于源碼結(jié)構(gòu)性變動(dòng)程度劃分的。在源碼結(jié)構(gòu)性變動(dòng)度量方面,針對大規(guī)模結(jié)構(gòu)變動(dòng)和局部(即小規(guī)模)結(jié)構(gòu)變動(dòng),自然語言處理方法疊加的源碼結(jié)構(gòu)性變動(dòng)程度計(jì)算與爬蟲代碼生成方法如下。
第一,源碼變動(dòng)程度計(jì)算方法。針對大規(guī)模結(jié)構(gòu)變動(dòng),結(jié)合相似度計(jì)算、差異值計(jì)算的綜合結(jié)構(gòu)差異指標(biāo),并在源碼結(jié)構(gòu)表示的基礎(chǔ)上對源碼整體結(jié)構(gòu)進(jìn)行計(jì)算。其中,相似度計(jì)算由余弦相似度和KL 散度(Kullback-Leibler divergence)共同衡量,將二者相加作為綜合結(jié)構(gòu)差異指標(biāo)。余弦相似度是數(shù)學(xué)空間中的兩向量之間距離的衡量指標(biāo),以兩個(gè)向量夾角的余弦值來衡量個(gè)體間的差異。KL散度又稱相對熵,在信息論中,KL 散度可以有效地度量兩個(gè)概率質(zhì)量分布差異度,它在信息學(xué)、統(tǒng)計(jì)學(xué)和物理學(xué)等領(lǐng)域中得到了廣泛的應(yīng)用[19]。KL散度要求待對比的兩個(gè)分布具有相同的樣本數(shù)目,而本文待對比的對象是兩個(gè)網(wǎng)頁源碼,兩條數(shù)據(jù)中的節(jié)點(diǎn)數(shù)目即樣本數(shù)目難以完全相同,因此需依據(jù)重要性對HTML 源碼中的標(biāo)簽節(jié)點(diǎn)進(jìn)行排序,選取相同數(shù)目的節(jié)點(diǎn)作為計(jì)算對象。本文采用PageRank 方法對DOM 樹節(jié)點(diǎn)排序。首先,通過源碼屬性名稱白名單對網(wǎng)頁源碼進(jìn)行語義信息的刪減、合并源碼中的最小結(jié)構(gòu)體,從而排除網(wǎng)頁內(nèi)容的語義差異和非HTML 語言的外部信息,構(gòu)建修剪后的DOM 結(jié)構(gòu)樹;其次,利用樹編輯距離指標(biāo)衡量源碼結(jié)構(gòu)的變化程度,用余弦相似度和KL散度綜合計(jì)算變化前后源碼的相似程度;每個(gè)網(wǎng)站訓(xùn)練出一個(gè)平均閾值代表對結(jié)構(gòu)變動(dòng)的容忍值,當(dāng)某一時(shí)刻,兩個(gè)網(wǎng)頁源碼之間的樹編輯距離值大于該閾值時(shí),則認(rèn)為源碼發(fā)生了較大的結(jié)構(gòu)差異。網(wǎng)頁源碼的非結(jié)構(gòu)性變動(dòng)即為源碼差異小于閾值時(shí)的情況,表現(xiàn)為網(wǎng)頁結(jié)構(gòu)變動(dòng)幅度較小,則實(shí)體抽取代碼失效的原因在于元素的屬性標(biāo)識發(fā)生變化,在原父節(jié)點(diǎn)的子節(jié)點(diǎn)集合中重新識別目標(biāo)實(shí)體。
第二,代碼生成方法。XPath 代碼的本質(zhì)是通過一系列規(guī)則符號、針對目標(biāo)實(shí)體的、對源碼中目標(biāo)實(shí)體的位置屬性標(biāo)識等特性的邏輯表達(dá),因此網(wǎng)頁改版事件導(dǎo)致的源碼文本及結(jié)構(gòu)變化中,與目標(biāo)實(shí)體關(guān)聯(lián)的部分直接映射在了XPath代碼中,只要掌握了源碼的變動(dòng)方向,再通過局部源碼的分類與判定如DOM 樹節(jié)點(diǎn)分類方法,即可得到目標(biāo)實(shí)體的位置、屬性標(biāo)識等一系列特征,通過這些特征又可直接轉(zhuǎn)換為XPath 模板代碼,重新激活爬蟲流程,爬取更多的網(wǎng)頁數(shù)據(jù)。
爬蟲原始資源基本分為網(wǎng)頁源碼資源、爬蟲代碼資源、日志數(shù)據(jù)這3 方面資源,這些資源達(dá)成了本文所面向的自適應(yīng)感知、爬蟲生成以及決策激活的目標(biāo)。具體包括網(wǎng)頁HTML 源碼、系統(tǒng)內(nèi)爬蟲項(xiàng)目代碼、外部網(wǎng)絡(luò)資源中的爬蟲代碼、爬蟲日志數(shù)據(jù)庫的資源。
爬蟲完成獲取網(wǎng)頁源碼的原始資源數(shù)據(jù)后,將網(wǎng)頁源碼連同它對應(yīng)的獲取和解析代碼共同存儲在Mongo 數(shù)據(jù)庫(MongoDB)中,以時(shí)間戳標(biāo)記源碼及代碼的入庫時(shí)間,以便統(tǒng)計(jì)網(wǎng)頁改版事件引起的網(wǎng)頁源碼變動(dòng)特征。網(wǎng)頁源碼資源庫充分結(jié)合了語料特點(diǎn)和爬蟲業(yè)務(wù)目標(biāo),一方面依據(jù)HTML 的DOM 樹結(jié)構(gòu)特征存儲樹狀的資源結(jié)構(gòu),另一方面按照網(wǎng)頁源碼特點(diǎn)存儲網(wǎng)頁布局結(jié)構(gòu)字段,以及爬蟲待獲取的目標(biāo)實(shí)體字段。代碼資源庫則利用抽象語法樹(Abstract Syntax Tree,AST)一方面從Java 代碼中提取樹狀結(jié)構(gòu)語義,以及核心的方法名、類名、依賴等文本語義信息;另一方面則結(jié)合爬蟲業(yè)務(wù)特點(diǎn),設(shè)置了爬蟲下載器、解析器、調(diào)度器、存儲管道等字段。代碼資源庫的資源由爬蟲采集各大網(wǎng)絡(luò)博客網(wǎng)站所構(gòu)成。通過人工數(shù)據(jù)清洗與信息抽取,獲取網(wǎng)頁中的代碼片段及自然語言描述。爬蟲日志數(shù)據(jù)庫記錄的是以網(wǎng)頁為單元的每個(gè)爬蟲線程在爬蟲業(yè)務(wù)鏈條各階段的行動(dòng)軌跡,包括線程停止時(shí)的運(yùn)行狀態(tài)、出錯(cuò)類型、捕獲異常、獲取到的中間數(shù)據(jù)等單個(gè)爬蟲線程的全部生命歷程。
本節(jié)所提出的源碼變動(dòng)特征標(biāo)引與實(shí)體抽取代碼生成方法重點(diǎn)在于:1)通過節(jié)點(diǎn)分類方法識別目標(biāo)實(shí)體,自動(dòng)生成XPath 代碼;2)通過計(jì)算源碼結(jié)構(gòu)變化閾值特征,鎖定目標(biāo)節(jié)點(diǎn)的變動(dòng)范圍,縮減待分類節(jié)點(diǎn)的候選集合;3)通過定位父級元素、合并最小結(jié)構(gòu)體等DOM 樹修剪方法,縮減待分類的節(jié)點(diǎn)范圍,提高代碼生成效率。
爬蟲代碼生成實(shí)驗(yàn)的具體步驟如下:
步驟1 數(shù)據(jù)準(zhǔn)備。依據(jù)網(wǎng)頁源碼資源庫,即標(biāo)引好源碼及其XPath 抽取代碼對應(yīng)關(guān)系的數(shù)據(jù)庫,可進(jìn)一步標(biāo)引DOM 樹中節(jié)點(diǎn)的分類標(biāo)簽。
步驟2 預(yù)訓(xùn)練向量準(zhǔn)備。采用網(wǎng)絡(luò)表示學(xué)習(xí)算法對HTML 源碼進(jìn)行表示學(xué)習(xí),得到源碼中各個(gè)節(jié)點(diǎn)對應(yīng)的向量表示。
步驟3 分類模型訓(xùn)練。從網(wǎng)絡(luò)表示學(xué)習(xí)得到的doc2vec 向量中提取對應(yīng)節(jié)點(diǎn)的向量矩陣,輸入XGBoost 監(jiān)督學(xué)習(xí)的分類模型。
步驟4 XPath 自動(dòng)生成。對網(wǎng)頁源碼中的節(jié)點(diǎn)進(jìn)行分類,得到候選節(jié)點(diǎn)集合,每個(gè)節(jié)點(diǎn)自動(dòng)生成其XPath 代碼。
本文從源碼庫81 393 條結(jié)構(gòu)化解析完畢的源碼數(shù)據(jù)中,按照網(wǎng)頁信息抽取代碼的差異統(tǒng)計(jì)網(wǎng)頁源碼樣式種類,自2019年7月爬蟲平臺上線以來,統(tǒng)計(jì)來自190個(gè)網(wǎng)站的526種樣式,其中包含有效XPath代碼的樣式506種。本文依據(jù)樣式類型每種樣式隨機(jī)選取50 條源碼,從25 300 條源碼數(shù)據(jù)中再依據(jù)結(jié)構(gòu)化的分類體系提取各分類標(biāo)簽對應(yīng)的源碼中節(jié)點(diǎn)文本。經(jīng)網(wǎng)絡(luò)表示學(xué)習(xí)訓(xùn)練后,得到融合源碼拓?fù)浣Y(jié)構(gòu)信息、節(jié)點(diǎn)的語義信息以及節(jié)點(diǎn)的分類信息的300 維向量表示,以此訓(xùn)練得到節(jié)點(diǎn)分類器模型。本文依據(jù)爬蟲日志數(shù)據(jù)庫記錄的錯(cuò)誤數(shù)據(jù)展開統(tǒng)計(jì),選取2021 年連續(xù)7 d 內(nèi)的每日報(bào)錯(cuò)數(shù)據(jù)作為實(shí)驗(yàn)對象,以檢驗(yàn)本文提出的實(shí)體抽取規(guī)則代碼生成方法的有效性,具體數(shù)據(jù)以及實(shí)驗(yàn)結(jié)果如表2所示。

表2 爬蟲日志庫的數(shù)據(jù)統(tǒng)計(jì)Tab.2 Data statistics of Web crawler log database
從表2 可知,爬蟲自適應(yīng)生成實(shí)體抽取代碼方法整體表現(xiàn)出了較強(qiáng)的修復(fù)能力,在標(biāo)題、日期、正文這3 個(gè)目標(biāo)實(shí)體的抽取代碼生成上具有較好的適應(yīng)性;在分類模型準(zhǔn)確率方面,XGBoost 模型在驗(yàn)證集上的準(zhǔn)確率達(dá)到88%左右,系統(tǒng)平臺中真實(shí)預(yù)測的準(zhǔn)確率平均在82.9%。基于布局結(jié)構(gòu)判定和子節(jié)點(diǎn)分類得到的目標(biāo)元素及其父節(jié)點(diǎn)在XPath 代碼的轉(zhuǎn)換率方面表現(xiàn)良好,基本維持在90%以上(如表3所示),主要出錯(cuò)原因在于部分元素的標(biāo)識不唯一,轉(zhuǎn)換的XPath 代碼常常難以定位到目標(biāo)元素。

表3 自適應(yīng)生成實(shí)體抽取代碼方法的準(zhǔn)確率Tab.3 Accuracy of adaptive entity extraction code generation method
通過上述正文錯(cuò)誤類型感知及正文抽取代碼生成實(shí)驗(yàn),本節(jié)所構(gòu)建的錯(cuò)誤感知器在實(shí)體抽取錯(cuò)誤感知方面,對于捕獲為空的情況具有良好的感知能力,但對于捕獲內(nèi)容正誤的感知能力比較一般;因此后續(xù)可以訓(xùn)練噪聲分類器模型對爬蟲流程中的錯(cuò)誤類型作出進(jìn)一步判斷。就實(shí)體抽取代碼生成能力而言,源碼變動(dòng)類型判定與子節(jié)點(diǎn)分類造成的錯(cuò)誤累積,使得最終代碼生成平均準(zhǔn)確率在78%。源碼的節(jié)點(diǎn)分類模型仍有提升空間。
雖然實(shí)驗(yàn)生成了可用的推薦代碼結(jié)果,但基于多種傳統(tǒng)自然語言處理疊加的方法一方面可能造成誤差累積,降低代碼生成的準(zhǔn)確率;另一方面,傳統(tǒng)的自然語言處理手段雖然可以建立源代碼間的知識關(guān)聯(lián),但在自適應(yīng)感知與決策任務(wù)上仍存在一定的局限性。因此,下文的實(shí)驗(yàn)中引入了自適應(yīng)感知器以及多層源碼特征表示手段,實(shí)現(xiàn)泛化爬蟲代碼生成過程。
3.2 源碼改版自適應(yīng)感知器
自適應(yīng)爬蟲系統(tǒng)的核心是基于深度感知、自動(dòng)判別的服務(wù)模型,通過構(gòu)建智能化工具定時(shí)監(jiān)控爬蟲應(yīng)用的內(nèi)外部環(huán)境,實(shí)現(xiàn)網(wǎng)頁源碼與爬蟲代碼兩類資源的交互與協(xié)同計(jì)算,如表4。前文對實(shí)體抽取與解析代碼生成的技術(shù)探討,此節(jié)將不再區(qū)分源碼變動(dòng)的具體類型,而是從受到影響的目標(biāo)實(shí)體、出錯(cuò)的爬蟲節(jié)點(diǎn)兩方面自適應(yīng)感知源碼變動(dòng)。

表4 網(wǎng)頁源碼變動(dòng)事件判定的內(nèi)外部依據(jù)Tab.4 Internal and external basis for judging webpage source code change events
排除網(wǎng)絡(luò)通信條件等硬性外部環(huán)境,本文所研究的爬蟲應(yīng)用的外部環(huán)境主要指網(wǎng)站的軟件運(yùn)行狀態(tài)及數(shù)據(jù)內(nèi)容更新情況;爬蟲的內(nèi)部環(huán)境則來自于對爬蟲日志信息的讀取和統(tǒng)計(jì)、爬蟲運(yùn)行狀態(tài)的監(jiān)督。外部環(huán)境的變化一方面直接體現(xiàn)在實(shí)體抽取模塊的XPath 代碼上,因?yàn)閄Path 本質(zhì)上是對HTML 源碼信息的表達(dá),XPath 代碼是否成功解析直接反映出網(wǎng)頁源碼是否發(fā)生變動(dòng);另一方面,通過結(jié)合內(nèi)外部信息,對比網(wǎng)站實(shí)際更新數(shù)目、爬蟲捕獲成功并存儲在Redis(Remote dictionary server)緩存池中的鏈接數(shù),以及爬蟲實(shí)際解析成功存儲在MongoDB 的鏈接數(shù),也是判斷網(wǎng)頁源碼變動(dòng)與否的重要依據(jù)。網(wǎng)頁源碼變動(dòng)事件判定的內(nèi)外部依據(jù)見表4。
例如,網(wǎng)頁樣式變化導(dǎo)致信息抽取代碼失效,當(dāng)爬蟲日志數(shù)據(jù)庫中讀取的數(shù)據(jù)滿足條件“status=‘ERROR’ AND type≠‘DOWNLOADER’ AND message ‘content str is empty’”時(shí),判定目標(biāo)實(shí)體“正文”所對應(yīng)的信息抽取代碼失效,未能在源碼中定位出“正文”對應(yīng)的元素標(biāo)簽。
3.3 自適應(yīng)爬蟲生成實(shí)驗(yàn)及其系統(tǒng)應(yīng)用
本文以源碼變動(dòng)前后兩條源碼數(shù)據(jù)即兩個(gè)DOM 樹結(jié)構(gòu)中、同一分類標(biāo)簽的兩個(gè)節(jié)點(diǎn)為一組訓(xùn)練數(shù)據(jù),對變動(dòng)前后的一組源碼數(shù)據(jù)進(jìn)行DOM 樹結(jié)構(gòu)化解析、網(wǎng)絡(luò)表示學(xué)習(xí),抽取發(fā)生變動(dòng)的節(jié)點(diǎn)對應(yīng)的向量,構(gòu)成一組變動(dòng)前后的節(jié)點(diǎn)對,作為ED 模型的輸入。爬蟲代碼的變動(dòng)特征以同樣的思路得到表征代碼變動(dòng)的映射模型。
在ED 模型訓(xùn)練至第20 次時(shí),模型損失值最低為49.905,BLEU(BiLingual Evaluation Understudy)值最高 為55.58,測試數(shù)據(jù)的準(zhǔn)確率達(dá)到92.3%。
實(shí)驗(yàn)從前文針對源碼變動(dòng)的代碼生成結(jié)果中抽取來自121個(gè)不同網(wǎng)站,236次變動(dòng)記錄,由不同版本的網(wǎng)頁源碼構(gòu)成7 813 組源碼變動(dòng)記錄數(shù)據(jù),包含源碼版本信息、變動(dòng)前后源碼、變動(dòng)前后代碼、變動(dòng)實(shí)體類型等。與僅用TriDNR(Tri-party Deep Network Representation)網(wǎng)絡(luò)表示學(xué)習(xí)作為嵌入層的實(shí)驗(yàn)結(jié)果對比,發(fā)現(xiàn)利用源代碼表征、源碼變動(dòng)作為雙層嵌入的方法的實(shí)驗(yàn)結(jié)果中有一定的提升,具體實(shí)驗(yàn)結(jié)果如表5。
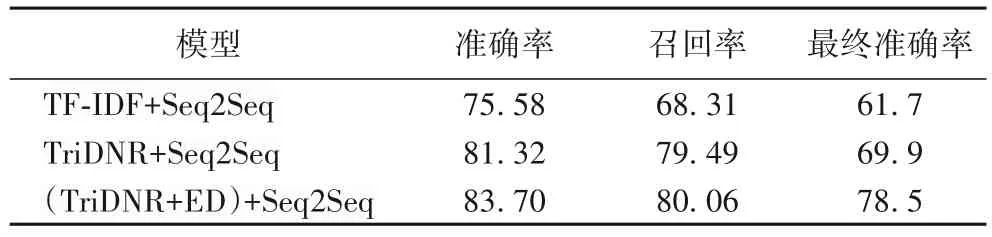
表5 自適應(yīng)爬蟲代碼生成結(jié)果 單位:%Tab.5 Results of adaptive Web crawler code generation unit:%
使用傳統(tǒng)Seq2Seq模型的代碼生成方法中,輸入為網(wǎng)頁源碼,輸出為XPath選擇器,由此生成的代碼形如XPath表達(dá)式如“time/@text” “*/@text”等,這樣的代碼能夠獲取網(wǎng)頁中的元素,但大部分不是爬蟲待獲取的目標(biāo)元素。原因在于,基于TF-IDF(Term Frequency-Inverse Document Frequency)+Seq2Seq的生成模型僅利用詞袋模型為特征,這樣訓(xùn)練出的模型依賴于詞袋中的語料,當(dāng)新的源碼輸入時(shí),難以依據(jù)新源碼中的標(biāo)簽屬性等詞匯生成針對性的爬蟲代碼,這樣的基線模型存在較大的缺陷。
結(jié)合本文的研究目標(biāo)——針對網(wǎng)頁源碼變動(dòng)的爬蟲代碼生成這一任務(wù),可從兩方面進(jìn)行評價(jià)本節(jié)提出的(TriDNR+ED)+Seq2Seq 模型:源碼變動(dòng)的表示和代碼生成的有效性。對比前文劃分具體變動(dòng)類型的方法發(fā)現(xiàn),不區(qū)分變動(dòng)類型,只對變動(dòng)進(jìn)行抽象表示的方法,在代碼生成準(zhǔn)確率上略有降低,但在泛化性有一定的提升。另外在代碼的準(zhǔn)確率方面,即生成的XPath 代碼正確獲取到爬蟲的目標(biāo)元素的準(zhǔn)確程度方面,本節(jié)的模型表現(xiàn)較優(yōu),原因在于網(wǎng)絡(luò)表示學(xué)習(xí)模型對網(wǎng)頁源碼的結(jié)構(gòu)語義表征具有良好的效果,日期、正文等實(shí)體在源碼中的布局結(jié)構(gòu)、與其他元素相關(guān)聯(lián)的拓?fù)浣Y(jié)構(gòu)信息等都得到了有效表示,因此模型在預(yù)測這些實(shí)體的能力上表現(xiàn)出一定的優(yōu)越性。
在系統(tǒng)應(yīng)用方面,爬蟲代碼生成的過程激活以網(wǎng)頁改版事件為觸發(fā),連通自適應(yīng)系統(tǒng)感知、決策、響應(yīng)等核心決策元件,以成功獲取與存儲數(shù)據(jù)為終點(diǎn),構(gòu)成自適應(yīng)系統(tǒng)完整閉環(huán)。由于自適應(yīng)爬蟲生成的結(jié)果是包含實(shí)體抽取與解析兩部分核心代碼在內(nèi)的Java 方法體,爬蟲代碼更新涉及以groovy 腳本為載體的Java 類代碼集成、與以數(shù)據(jù)庫存儲為方法的XPath 代碼集成,而爬蟲激活則主要指自適應(yīng)生成代碼完畢后的爬蟲線程啟動(dòng)工作。基本流程如圖3 所示。

圖3 爬蟲代碼更新與激活流程Fig.3 Flow of Web crawler code update and activation
以USCC 網(wǎng)站局部源碼結(jié)構(gòu)性變動(dòng)為例,USCC 網(wǎng)站發(fā)生日期元素結(jié)構(gòu)性變動(dòng),日期元素從<div class=”field--type--datetime”>變?yōu)椋紅ime>。對此,自適應(yīng)爬蟲系統(tǒng)正確定位了新的日期元素,并轉(zhuǎn)換為XPath 代碼發(fā)送給校驗(yàn)平臺。在存儲至爬蟲數(shù)據(jù)庫正式啟動(dòng)爬蟲前,對自適應(yīng)修改的爬蟲代碼進(jìn)行自動(dòng)測試和人機(jī)交互校對,從而有效降低人工識別錯(cuò)誤、人工修改爬蟲代碼的系統(tǒng)運(yùn)維成本,自適應(yīng)修改的代碼以及校對界面。
4 結(jié)語
本文在源代碼資源結(jié)構(gòu)及內(nèi)容語義理解的基礎(chǔ)上,探討了針對源碼變動(dòng)的代碼生成模型,并以源碼結(jié)構(gòu)變動(dòng)為出發(fā)點(diǎn),對問題進(jìn)行建模,提出相應(yīng)的代碼生成或推薦模型,實(shí)現(xiàn)了針對錯(cuò)誤類型的爬蟲代碼自動(dòng)生成,并且在此基礎(chǔ)上提出一種泛化的、自適應(yīng)的源碼變動(dòng)感知及爬蟲代碼自適應(yīng)生成方法,解決了爬蟲技術(shù)面臨的網(wǎng)頁頻繁改版導(dǎo)致代碼失效的實(shí)際問題。但本文解決的是源碼局部結(jié)構(gòu)性變動(dòng),大規(guī)模源碼結(jié)構(gòu)變動(dòng)的感知與爬蟲代碼生成方案則有待研究;此外,本文研究目標(biāo)網(wǎng)站大多屬于智庫網(wǎng)站,因此所提出的特征或許存在一定的領(lǐng)域獨(dú)特性,有待其他類型網(wǎng)站布局結(jié)構(gòu)的補(bǔ)充。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學(xué)評論(2021年2期)2021-08-22 01:53:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
