基于注意力機(jī)制和遷移學(xué)習(xí)的古壁畫(huà)朝代識(shí)別
2023-07-03 14:12:06張慧斌馮麗萍郝耀軍王一寧
計(jì)算機(jī)應(yīng)用 2023年6期
張慧斌,馮麗萍,郝耀軍,王一寧
(1.忻州師范學(xué)院 計(jì)算機(jī)系,山西 忻州 034000;2.燕山大學(xué) 信息科學(xué)與工程學(xué)院,河北 秦皇島 066004)
0 引言
中國(guó)敦煌古代壁畫(huà)作品是中國(guó)重要的文化遺產(chǎn),敦煌古壁畫(huà)的朝代分類更是學(xué)者們研究的首要因素。敦煌莫高窟壁畫(huà)始建于中國(guó)古代前秦朝時(shí)期,擁有將近1 600 年歷史,先后經(jīng)歷北魏、西魏、北周、隋朝、唐朝、五代十國(guó)等朝代的興建,但是受上千年風(fēng)雨侵蝕和人為因素的影響,古代壁畫(huà)都遭到了不同程度的損壞,因此對(duì)壁畫(huà)朝代的判別變得困難,成為了歷史文化研究中的一大阻礙。利用深度學(xué)習(xí)智能技術(shù)對(duì)古代壁畫(huà)朝代識(shí)別分類鑒定成為學(xué)者們研究的重要方向之一。
深度卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)在圖像處理方面取得了巨大的成功[1],在藝術(shù)繪畫(huà)識(shí)別分類問(wèn)題上也取得了很大突破。文獻(xiàn)[2]中使用遷移學(xué)習(xí)(Transfer Learning)方法在CNN 模型上對(duì)敦煌古壁畫(huà)進(jìn)行朝代識(shí)別分類,分類準(zhǔn)確率達(dá)到88.7%。文獻(xiàn)[3]中使用遷移學(xué)習(xí)方法把已經(jīng)預(yù)訓(xùn)練好的殘差網(wǎng)絡(luò)ResNet(Residual Network)模型ResNet50[4]以及VGGNet 模型[1]進(jìn)行再訓(xùn)練,先后預(yù)測(cè)了10 位以及20 位藝術(shù)家的畫(huà)作,分別達(dá)到了90.75%以及87.8%的測(cè)試準(zhǔn)確率。文獻(xiàn)[5]中收集了6 個(gè)朝代的3 860 張敦煌壁畫(huà),并提出了DunNet 模型對(duì)敦煌壁畫(huà)朝代分類。文獻(xiàn)[6]中對(duì)膠囊網(wǎng)絡(luò)進(jìn)行適應(yīng)性增強(qiáng),在提高梯度平滑度基礎(chǔ)上,利用自適應(yīng)學(xué)習(xí)率優(yōu)化模型,提高模型的分類精度,提出了適應(yīng)性增強(qiáng)膠囊網(wǎng)絡(luò),對(duì)敦煌壁畫(huà)所屬朝代進(jìn)行分類達(dá)到了84.44%的測(cè)試準(zhǔn)確率。文獻(xiàn)[7]中對(duì)ResNet50 第49 層的平均池化用最大池化代替,對(duì)敦煌壁畫(huà)朝代進(jìn)行分類達(dá)到了88.46%的準(zhǔn)確率。
基于深度學(xué)習(xí)的古代壁畫(huà)分類方法比傳統(tǒng)算法在準(zhǔn)確率上有了很大的提高,但是CNN需要大量的訓(xùn)練學(xué)習(xí)樣本,然而古代壁畫(huà)的數(shù)量有限,一般采用數(shù)據(jù)增強(qiáng)方法解決訓(xùn)練學(xué)習(xí)不足問(wèn)題。但是,數(shù)據(jù)增強(qiáng)方法存在兩個(gè)缺點(diǎn):一是有些數(shù)據(jù)增強(qiáng)方法在擴(kuò)充訓(xùn)練集的數(shù)量的同時(shí),增加了訓(xùn)練時(shí)間;二是有些數(shù)據(jù)增強(qiáng)方法改變了訓(xùn)練集的數(shù)據(jù)概率分布,使得訓(xùn)練和測(cè)試數(shù)據(jù)的概率分布差異變大,反而降低了預(yù)測(cè)準(zhǔn)確率。當(dāng)數(shù)據(jù)增強(qiáng)方法無(wú)效甚至可能降低分類性能的情況下,使用小樣本遷移學(xué)習(xí)方法[8]成為解決上述問(wèn)題的一個(gè)選擇。遷移學(xué)習(xí)是將一個(gè)領(lǐng)域?qū)W到的知識(shí)轉(zhuǎn)移到另一個(gè)標(biāo)注數(shù)據(jù)為小樣本的領(lǐng)域,遷移學(xué)習(xí)能夠在標(biāo)注數(shù)據(jù)小樣本的情況下獲得比較好的測(cè)試結(jié)果。
從數(shù)據(jù)分析的角度,預(yù)訓(xùn)練的數(shù)據(jù)集和任務(wù)目標(biāo)數(shù)據(jù)集相關(guān)性越強(qiáng),遷移學(xué)習(xí)的先驗(yàn)知識(shí)獲取的效果越好;而古代壁畫(huà)數(shù)據(jù)集本身的樣本數(shù)很少,與之相關(guān)的數(shù)據(jù)集更難獲得,因此需要把沒(méi)有相關(guān)性的數(shù)據(jù)集作為預(yù)訓(xùn)練的數(shù)據(jù)集進(jìn)行遷移學(xué)習(xí),通過(guò)改進(jìn)網(wǎng)絡(luò)模型、改進(jìn)分類器算法和訓(xùn)練方法構(gòu)造域適應(yīng)(domain adaption)方法以解決源域(source domain)和目標(biāo)域(target domain)數(shù)據(jù)分布不相關(guān)問(wèn)題,使得目標(biāo)域盡可能利用源域知識(shí)提高任務(wù)目標(biāo)分類的性能,這是本文研究探索的方向。
針對(duì)上述深度學(xué)習(xí)對(duì)古代壁畫(huà)朝代識(shí)別任務(wù)中存在標(biāo)注數(shù)據(jù)嚴(yán)重不足的問(wèn)題,提出一種基于注意力機(jī)制的ResNet20 模型[4]對(duì)古代壁畫(huà)進(jìn)行朝代分類識(shí)別,同時(shí)改進(jìn)了ResNet 的殘差連接方式,然后在不相關(guān)性的CIFAR10 數(shù)據(jù)集[9]上進(jìn)行預(yù)訓(xùn)練,在目標(biāo)數(shù)據(jù)集訓(xùn)練時(shí),改進(jìn)分類器的算法,用以加大不同類之間數(shù)據(jù)分布的差異性。實(shí)驗(yàn)結(jié)果表明,本文的基于小樣本遷移學(xué)習(xí)的網(wǎng)絡(luò)模型在敦煌古代壁畫(huà)朝代分類任務(wù)中獲得了很高的分類準(zhǔn)確率,表明了基于注意力機(jī)制和遷移學(xué)習(xí)的ResNet20 網(wǎng)絡(luò)模型在古代壁畫(huà)朝代識(shí)別任務(wù)中的有效性。
1 相關(guān)理論
1.1 遷移學(xué)習(xí)
文獻(xiàn)[10-11]中指出,在圖像分類任務(wù)中,CNN 通過(guò)訓(xùn)練數(shù)據(jù)從而獲得數(shù)據(jù)的分層特征表達(dá)能力,CNN 的深層用于語(yǔ)義分類,CNN 的底層用于描述低級(jí)語(yǔ)義特征(邊緣信息、顏色信息等局部特征),這樣的特征實(shí)際上在不同的分類任務(wù)中沒(méi)有太大的區(qū)別,而真正有區(qū)別的是深層特征。
文獻(xiàn)[12]中認(rèn)為遷移學(xué)習(xí)是利用有大量標(biāo)注數(shù)據(jù)的源域(預(yù)訓(xùn)練數(shù)據(jù)集)映射到任務(wù)目標(biāo)域(任務(wù)目標(biāo)數(shù)據(jù)集)的知識(shí)遷移方法。域之間的差異使得在不同域之中使用預(yù)測(cè)模型時(shí)存在障礙,需要通過(guò)域適應(yīng)解決該問(wèn)題,即對(duì)來(lái)自兩個(gè)相關(guān)域但服從不同分布的數(shù)據(jù),建立模型學(xué)習(xí)這兩個(gè)域的域不變特征(domain-invariant feature)。遷移學(xué)習(xí)的目標(biāo)是從數(shù)據(jù)中學(xué)習(xí)域不變特征,從而溝通源域和目標(biāo)域在一個(gè)同構(gòu)的隱特征空間。文獻(xiàn)[13]中認(rèn)為,域適應(yīng)方法旨在通過(guò)學(xué)習(xí)域不變特征把源域和目標(biāo)域連接起來(lái),從而能夠利用源域所學(xué)到的知識(shí)對(duì)目標(biāo)域進(jìn)行預(yù)測(cè)。源域和目標(biāo)域上的數(shù)據(jù)分布偏差較大,這是域適應(yīng)要解決的問(wèn)題,也是遷移學(xué)習(xí)核心要解決的問(wèn)題。將域適應(yīng)問(wèn)題轉(zhuǎn)換為尋找公共特征表示空間的問(wèn)題,也就是尋找學(xué)習(xí)域的不變特征。
在理論上,任何領(lǐng)域之間都可以作遷移學(xué)習(xí);但是,如果源域和目標(biāo)域之間數(shù)據(jù)分布差別太大、相似度不夠,遷移學(xué)習(xí)效果會(huì)很不理想。當(dāng)源域與目標(biāo)域相關(guān)度較小或互不相關(guān)時(shí),遷移學(xué)習(xí)可能失敗,甚至表現(xiàn)為負(fù)遷移。域適應(yīng)方法在一定程度上可以解決這個(gè)問(wèn)題,它的基本思想是保證域差異最小,具體方法都是改進(jìn)損失函數(shù),或者在損失函數(shù)上添加一些約束項(xiàng),或者對(duì)分類器的算法進(jìn)行改進(jìn)。
本文通過(guò)改進(jìn)分類器算法和訓(xùn)練方法解決域適應(yīng)問(wèn)題,使用與古代壁畫(huà)沒(méi)有相關(guān)性的CIFAR10 數(shù)據(jù)集[9]作為源域,在古代壁畫(huà)目標(biāo)域上進(jìn)行遷移學(xué)習(xí)。
1.2 注意力機(jī)制
注意力機(jī)制(attention mechanism)是神經(jīng)網(wǎng)絡(luò)研究中的一個(gè)非常重要的研究領(lǐng)域,已經(jīng)被廣泛地應(yīng)用在自然語(yǔ)言處理、統(tǒng)計(jì)學(xué)習(xí)語(yǔ)音識(shí)別和計(jì)算機(jī)視覺(jué)等人工智能相關(guān)領(lǐng)域[14]。
Bahdanau 等[15]首次將注意力機(jī)制應(yīng)用到機(jī)器翻譯的任務(wù)中,實(shí)現(xiàn)了翻譯和對(duì)齊同時(shí)進(jìn)行,解決了語(yǔ)句長(zhǎng)度不同的問(wèn)題。Vaswani 等[16]提出了以自注意力為基本單元的Transformer 模型,使得注意力機(jī)制得到真正的成功運(yùn)用。此后,學(xué)者們 提出了Non-local neural network[17]、Triplet Attention[18]和cosFormer Attention[19]等注意力機(jī)制。
沒(méi)有注意力機(jī)制的CNN 一般對(duì)圖像的所有信息都要處理,無(wú)法對(duì)重要的信息進(jìn)行選擇,缺乏辨別學(xué)習(xí)的能力,并且不會(huì)重點(diǎn)注意圖像中的關(guān)鍵信息。
網(wǎng)絡(luò)模型需要提取壁畫(huà)的紋理、細(xì)節(jié)特征,也要提取壁畫(huà)的輪廓、形狀特征,壁畫(huà)的細(xì)節(jié)特征、紋理等表現(xiàn)在網(wǎng)絡(luò)模型的通道上,而壁畫(huà)的輪廓形狀等全局特征表現(xiàn)在網(wǎng)絡(luò)模型的空間通道上,因此在卷積網(wǎng)絡(luò)中加入通道空間的極化自注意力(POlarized Self-Attention,POSA)模塊[20],如圖1 所示。POSA模塊在通道和空間注意力計(jì)算中具有較高的內(nèi)部分辨率。

圖1 POSA模塊的結(jié)構(gòu)Fig.1 Structure of POSA module
2 網(wǎng)絡(luò)結(jié)構(gòu)模型
2.1 基于注意力機(jī)制的改進(jìn)的ResNet網(wǎng)絡(luò)模型
標(biāo)準(zhǔn)的ResNet 中,對(duì)于特征圖大小不一致的殘差連接使用1×1 卷積核(步長(zhǎng)為2)進(jìn)行卷積計(jì)算,顯然輸入特征圖像的一半像素沒(méi)有卷積計(jì)算,這樣會(huì)丟失一些圖像特征信息。本文用3×3 卷積核(步長(zhǎng)為2)進(jìn)行卷積計(jì)算的殘差連接方式代替,如圖2 所示。
設(shè)輸入向量為yl-1,殘差塊輸出向量為yl,關(guān)系可表示為:
其中:函數(shù)F(·)表示的是圖2 殘差連接⊕前的兩個(gè)卷積運(yùn)算、批歸一 化(Batch Normalization,BN)運(yùn)算和ReLU(Rectified Linear Unit)激活函數(shù)運(yùn)算。
因?yàn)槎鼗捅诋?huà)的樣本數(shù)較少,不適用于深度和寬度比較大的網(wǎng)絡(luò)模型,否則很容易產(chǎn)生過(guò)擬合,致使分類性能不足,所以使用參數(shù)量較少的小網(wǎng)絡(luò)模型,故選用ResNet20 作為網(wǎng)絡(luò)模型。本文在ResNet20 模型中引入POSA 模塊加強(qiáng)敦煌壁畫(huà)的邊緣關(guān)鍵信息特征抽取。一般地,在深度學(xué)習(xí)的分類任務(wù)中,淺層網(wǎng)絡(luò)提取的是圖像的細(xì)節(jié)特征,因此把POSA模塊插入網(wǎng)絡(luò)模型的淺層的卷積層中用來(lái)提取圖像的細(xì)節(jié)特征;而網(wǎng)絡(luò)模型深層的卷積層提取的是具有概括性、全局性的圖像數(shù)字特征信息。
本文的網(wǎng)絡(luò)模型在ResNet20[4]的淺層加POSA 機(jī)制,結(jié)構(gòu)如表1 所示。

表1 基于注意力機(jī)制的ResNet20結(jié)構(gòu)Tab.1 ResNet20 structure based on attention mechanism
2.2 改進(jìn)的遷移學(xué)習(xí)
數(shù)據(jù)增強(qiáng)方法可以增加訓(xùn)練數(shù)據(jù)集的樣本數(shù),然而有些數(shù)據(jù)增強(qiáng)方法可能使得某些訓(xùn)練集和測(cè)試集數(shù)據(jù)的概率分布產(chǎn)生比較大偏差,致使網(wǎng)絡(luò)模型分類性能下降,因此本文的網(wǎng)絡(luò)模型訓(xùn)練不使用數(shù)據(jù)增強(qiáng)技術(shù)。
通常使用基于模型微調(diào)的遷移學(xué)習(xí)解決標(biāo)注數(shù)據(jù)嚴(yán)重不足問(wèn)題,它的訓(xùn)練過(guò)程為:首先在大數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練,訓(xùn)練完成后,對(duì)應(yīng)小樣本目標(biāo)數(shù)據(jù)任務(wù),固定淺層的權(quán)重參數(shù)值,僅對(duì)深層的權(quán)重參數(shù)進(jìn)行訓(xùn)練。模型微調(diào)小樣本學(xué)習(xí)方法在訓(xùn)練數(shù)據(jù)集和測(cè)試數(shù)據(jù)集概率分布相差很小情況下,學(xué)習(xí)效果非常有效,當(dāng)二者數(shù)據(jù)概率分布相差較大時(shí),則學(xué)習(xí)效果性能較低。
文獻(xiàn)[21]中提出了一種稱為Baseline++的基于模型微調(diào)的小樣本圖像分類方法,改進(jìn)的分類器算法更適合模型微調(diào)的遷移學(xué)習(xí)。
因?yàn)楣糯诋?huà)數(shù)量較少,相關(guān)的數(shù)據(jù)集幾乎沒(méi)有,使用模型微調(diào)的遷移學(xué)習(xí)方法學(xué)習(xí)性能必然很低,所以本文對(duì)預(yù)訓(xùn)練后的網(wǎng)絡(luò)模型的權(quán)重參數(shù)進(jìn)行全部再訓(xùn)練。在圖像分類任務(wù)中,在卷積層構(gòu)成的特征提取器后,把每個(gè)特征map平均池化為一個(gè)特征神經(jīng)元,然后使用Softmax 分類器把特征神經(jīng)元構(gòu)成的特征向量與線性層的權(quán)重矩陣作向量積,得到一個(gè)類別向量,再比較類別向量的標(biāo)量數(shù)值大小以預(yù)測(cè)樣本的類別。有大量訓(xùn)練數(shù)據(jù)集的前提下,Softmax 分類器方法可以充分訓(xùn)練到同類別的數(shù)字特征值,因此能獲得較好的分類效果;但是當(dāng)訓(xùn)練數(shù)據(jù)集是小樣本時(shí),訓(xùn)練出來(lái)的不同類之間的特征向量的數(shù)字特征差異不明顯,故降低了網(wǎng)絡(luò)模型分類性能。
使用沒(méi)有相關(guān)性的CIFAR10 數(shù)據(jù)集作為預(yù)訓(xùn)練,遷移到任務(wù)目標(biāo)數(shù)據(jù)集上訓(xùn)練,僅僅微調(diào)網(wǎng)絡(luò)模型是無(wú)法獲得較好分類性能的,所以再對(duì)網(wǎng)絡(luò)模型的權(quán)重參數(shù)進(jìn)行訓(xùn)練更新。同時(shí),為了適用目標(biāo)數(shù)據(jù)集的圖像分類任務(wù),需要對(duì)分類器的算法進(jìn)行改進(jìn)。網(wǎng)絡(luò)模型特征提取器特征map 經(jīng)過(guò)BN 層和ReLU 激活函數(shù)計(jì)算后,再經(jīng)過(guò)平均池化輸出一個(gè)一維特征向量。由概率論與統(tǒng)計(jì)學(xué)的2σ法則可知,一維向量中的數(shù)據(jù)95.44%的概率在[0,2),為了增加特征向量數(shù)據(jù)間的差異性,本文對(duì)分類器的特征向量作線性映射,把特征向量中的數(shù)據(jù)的值映射到[0,3]上。設(shè)特征向量元素最大值為xmax,最小值為xmin,特征向量的任一數(shù)據(jù)值為x,關(guān)系可表示為:
為了增加不同類之間的特征值的差異性,對(duì)線性層的分類層的每個(gè)神經(jīng)元數(shù)值的概率分布進(jìn)行正態(tài)分布的標(biāo)準(zhǔn)化處理,線性變換后的表達(dá)式表示為:
其中:μ是輸出層神經(jīng)元的均值,σ是輸出層神經(jīng)元的方差。
3 網(wǎng)絡(luò)參數(shù)設(shè)置
3.1 實(shí)驗(yàn)數(shù)據(jù)集
實(shí)驗(yàn)數(shù)據(jù)集是敦煌壁畫(huà)圖像數(shù)據(jù)集(DH1926),出自《中國(guó)敦煌壁畫(huà)全集》電子資源畫(huà)冊(cè)。壁畫(huà)的朝代分別是北魏、北周、隋代、唐朝、五代和西魏這6 個(gè)不同的朝代時(shí)期,總共有1 926 張壁畫(huà)圖像,各朝代壁畫(huà)示例如圖3 所示。

圖3 敦煌古壁畫(huà)各朝代圖像示例Fig.3 Examples of images of ancient murals from Dunhuang in different dynasties
本文網(wǎng)絡(luò)模型沒(méi)有對(duì)訓(xùn)練集作數(shù)據(jù)增強(qiáng)處理。從每個(gè)朝代的壁畫(huà)隨機(jī)抽取128 個(gè)作為測(cè)試數(shù)據(jù)集、剩余部分為訓(xùn)練集,這樣訓(xùn)練集有1 158 個(gè)樣本、測(cè)試集有768 個(gè)樣本,每個(gè)朝代的壁畫(huà)訓(xùn)練集、測(cè)試集和壁畫(huà)總數(shù)如表2 所示。

表2 DH1926數(shù)據(jù)集中的各朝代圖像數(shù)量Tab.2 Numbers of images in different dynasties in DH1926 dataset
3.2 學(xué)習(xí)率和訓(xùn)練輪次
在預(yù)訓(xùn)練階段,用CIFAR10 數(shù)據(jù)集作為源域數(shù)據(jù)集,它的訓(xùn)練集有50 000 個(gè)彩色圖片,測(cè)試集有10 000 個(gè),網(wǎng)絡(luò)模型訓(xùn)練的batchsize 設(shè)置為128,訓(xùn)練200 輪。
學(xué)習(xí)率是卷積神經(jīng)網(wǎng)絡(luò)的最重要的超參數(shù),對(duì)網(wǎng)絡(luò)的收斂速度和性能有重要的作用。在預(yù)訓(xùn)練階段和目標(biāo)域訓(xùn)練的遷移學(xué)習(xí)階段,學(xué)習(xí)率的衰減方法都采用余弦退火衰減下降法[22]。余弦函數(shù)中隨著訓(xùn)練輪次和迭代次數(shù)的增加,學(xué)習(xí)率首先緩慢下降,然后加速下降,再次緩慢下降,這種下降模式可以使神經(jīng)網(wǎng)絡(luò)產(chǎn)生很好的學(xué)習(xí)效果。本文實(shí)驗(yàn)最后一輪的最后一次迭代的學(xué)習(xí)率降為0。其關(guān)系可表示為:
其中:ηmax是神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練學(xué)習(xí)的初始學(xué)習(xí)率,也是實(shí)驗(yàn)的最大學(xué)習(xí)率;ηmin是神經(jīng)網(wǎng)絡(luò)衰減到最小的學(xué)習(xí)率,設(shè)置ηmin=0;Tmax=200 是總共訓(xùn)練的輪次數(shù);Tcur為當(dāng)前正在訓(xùn)練的輪次數(shù);iters為訓(xùn)練一輪的迭代次數(shù);iter為當(dāng)前訓(xùn)練輪次的當(dāng)前迭代數(shù)。實(shí)驗(yàn)的學(xué)習(xí)率衰減如圖4 所示。
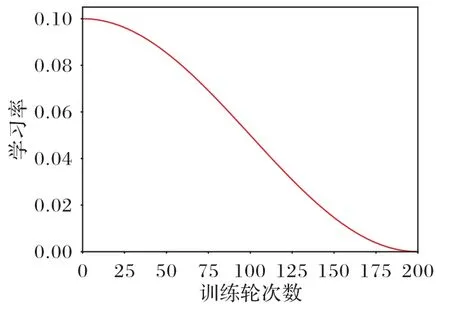
圖4 使用余弦衰減法的學(xué)習(xí)率Fig.4 Learning rate with cosine decay method
在預(yù)訓(xùn)練階段,初始學(xué)習(xí)率設(shè)置為0.1;在目標(biāo)域訓(xùn)練的遷移學(xué)習(xí)階段,初始學(xué)習(xí)率設(shè)置為0.005,網(wǎng)絡(luò)模型訓(xùn)練的batchsize 設(shè)置為16,訓(xùn)練200 輪。
3.3 網(wǎng)絡(luò)的初始化
深度CNN 優(yōu)化是一個(gè)非常復(fù)雜的非線性模型,網(wǎng)絡(luò)的初始化直接影響模型的收斂和模型訓(xùn)練的準(zhǔn)確率。初始化是CNN 的基礎(chǔ)研究,Kaiming 初始化[23]是CNN 最常用的初始化方法,近兩年出現(xiàn)新的研究方向,如通過(guò)算法尋找初始化值的GradInit[24]和通過(guò)縮放因子進(jìn)行初始化的SkipInit[25]。
本文網(wǎng)絡(luò)模型根據(jù)文獻(xiàn)[26]中的CNN 收斂的必要性條件和卷積核的初始化公式進(jìn)行初始化,卷積核按照式(5)初始化:
其中:wl表示神經(jīng)網(wǎng)絡(luò)第l層的卷積核權(quán)重參數(shù);nl=cl×kl2,cl是神經(jīng)網(wǎng)絡(luò)第l層的輸出通道數(shù),kl是神經(jīng)網(wǎng)絡(luò)第l層卷積核的維數(shù)。第l層的卷積核按照式(5)作均值為0 方差為3.0/nl的隨機(jī)高斯分布初始化,同時(shí)把偏置值(bias)初始化為0。
在目標(biāo)域訓(xùn)練的遷移學(xué)習(xí)階段,初始學(xué)習(xí)率設(shè)置為0.005,對(duì)網(wǎng)絡(luò)模型的線性分類器按照式(6)初始化:
其中:w表示線性分類器的權(quán)重參數(shù);m是線性分類器的輸出通道數(shù)。
3.4 損失函數(shù)
在深度學(xué)習(xí)中,損失函數(shù)至關(guān)重要,通過(guò)最小化損失函數(shù)使模型達(dá)到收斂狀態(tài),減小模型預(yù)測(cè)值的誤差。本文實(shí)驗(yàn)的神經(jīng)網(wǎng)絡(luò)使用的交叉熵?fù)p失(Cross-entropy Loss)函數(shù),又稱為對(duì)數(shù)似然損失(Log-likelihood Loss)函數(shù),是神經(jīng)網(wǎng)絡(luò)的多分類損失函數(shù),可以表示為:
其中:p(xi)表示真實(shí)標(biāo)記的分布,q(xi)為訓(xùn)練后的模型的預(yù)測(cè)標(biāo)記分布。交叉熵?fù)p失函數(shù)可以衡量p(xi)與q(xi)的相似性。
PyTorch 的交叉熵?fù)p失函數(shù)加上了Softmax 函數(shù),關(guān)系表達(dá)式如式(8)所示:
其中:x表示CNN 輸出層的輸出分類向量,class表示分類的類別。
3.5 網(wǎng)絡(luò)優(yōu)化器設(shè)置
CNN 的優(yōu)化器Adam 算法[27]是目前公認(rèn)的優(yōu)秀自適應(yīng)學(xué)習(xí)優(yōu)化器之一,它不僅考慮了一階動(dòng)量更新,還考慮了二階動(dòng)量,收斂速度非常快;但是在壁畫(huà)樣本數(shù)較少的圖像分類中,本文使用基礎(chǔ)的優(yōu)化方法隨機(jī)梯度下降(Stochastic Gradient Descent,SGD)優(yōu)化器。實(shí)驗(yàn)結(jié)果顯示,SGD 優(yōu)化器泛化能力強(qiáng),有一定的防過(guò)擬合能力,分類準(zhǔn)確率更高,同時(shí)設(shè)置SGD 優(yōu)化器的momentum 為0.9,神經(jīng)網(wǎng)絡(luò)的激活函數(shù)采用ReLU 函數(shù)。
3.6 遷移學(xué)習(xí)訓(xùn)練方法
網(wǎng)絡(luò)模型的訓(xùn)練過(guò)程如下。首先,在CIFAR10 數(shù)據(jù)集上對(duì)網(wǎng)絡(luò)模型進(jìn)行飽和預(yù)訓(xùn)練,即訓(xùn)練數(shù)據(jù)集的包含的信息量要大于網(wǎng)絡(luò)模型的參數(shù)所能學(xué)到的信息量,這樣把網(wǎng)絡(luò)模型的參數(shù)接近最優(yōu)化狀態(tài);然后,在任務(wù)目標(biāo)數(shù)據(jù)集上,用改進(jìn)的分類器算法(式(2)(3))代替原先的標(biāo)準(zhǔn)線性分類器算法,對(duì)網(wǎng)絡(luò)模型的所有參數(shù)再進(jìn)行訓(xùn)練更新,對(duì)改進(jìn)的分類器按照式(6)初始化。
3.7 實(shí)驗(yàn)環(huán)境
實(shí)驗(yàn)使用深度學(xué)習(xí)框架PyTorch 1.3 版本,Linux 的Ubuntu 版本20.0 操作系統(tǒng),Python3.7 作為神經(jīng)網(wǎng)絡(luò)編程語(yǔ)言,實(shí)驗(yàn)使用的GPU 是NVIDIA GTX 1070ti GPU。
4 實(shí)驗(yàn)與結(jié)果分析
4.1 與其他模型結(jié)果對(duì)比分析
為了驗(yàn)證本文提出的基于注意力機(jī)制和遷移學(xué)習(xí)的網(wǎng)絡(luò)模型在古壁畫(huà)朝代識(shí)別分類中的性能和有效性,與文獻(xiàn)[2,5-7]算法的預(yù)測(cè)準(zhǔn)確率進(jìn)行對(duì)比,結(jié)果見(jiàn)表3。

表3 不同網(wǎng)絡(luò)模型的實(shí)驗(yàn)結(jié)果對(duì)比Tab.3 Comparison of experimental results of different network models
文獻(xiàn)[2,5,7]把數(shù)據(jù)集分為訓(xùn)練集、驗(yàn)證集和測(cè)試集,也就是分別把數(shù)據(jù)集分為970 張圖片的訓(xùn)練集、160 張圖片的驗(yàn)證集和254 張圖片的測(cè)試集,其中160 張驗(yàn)證集圖片在模型訓(xùn)練中檢驗(yàn)?zāi)P偷臓顟B(tài)和收斂情況。由表3 可以看到,其他對(duì)比文獻(xiàn)用于古壁畫(huà)朝代識(shí)別的網(wǎng)絡(luò)模型的訓(xùn)練數(shù)據(jù)集樣本數(shù)遠(yuǎn)大于本文網(wǎng)絡(luò)模型的訓(xùn)練數(shù)據(jù)集樣本數(shù),然而分類準(zhǔn)確率卻遠(yuǎn)低于本文網(wǎng)絡(luò)模型的分類準(zhǔn)確率。文獻(xiàn)[7]中采用標(biāo)準(zhǔn)的ResNet50 網(wǎng)絡(luò)模型對(duì)古代壁畫(huà)進(jìn)行朝代分類,網(wǎng)絡(luò)模型的寬度和深度都遠(yuǎn)大于本文網(wǎng)絡(luò)模型的寬度和深度,但是其朝代分類準(zhǔn)確率比較低,原因可能如下:一是網(wǎng)絡(luò)模型對(duì)圖像特征提取能力不足;二是過(guò)大的網(wǎng)絡(luò)模型造成了過(guò)擬合。文獻(xiàn)[6]中采用數(shù)據(jù)增強(qiáng)技術(shù)擴(kuò)充了訓(xùn)練數(shù)據(jù)集,然而準(zhǔn)確率較低,有可能是采用的數(shù)據(jù)增強(qiáng)技術(shù)使得訓(xùn)練集和測(cè)試集數(shù)據(jù)的概率分布差異變大,從而降低了識(shí)別準(zhǔn)確率。
4.2 改進(jìn)的分類器性能對(duì)比分析
在訓(xùn)練方法一致的前提下,將本文改進(jìn)的分類器、基本的分類器Baseline 和Baseline++小樣本遷移學(xué)習(xí)分類器[21]進(jìn)行性能對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表4 所示。
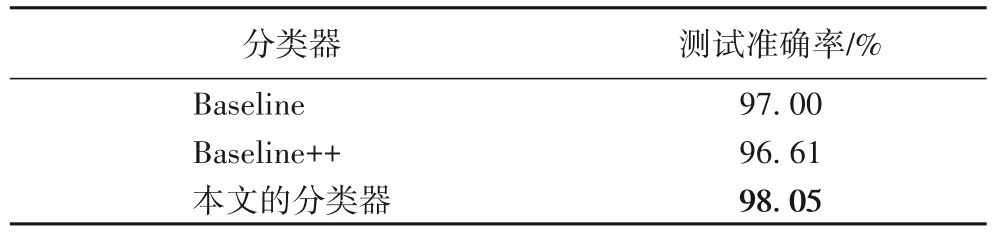
表4 分類器性能對(duì)比分析Tab.4 Comparative analysis of classifier performance
由表4 可以看出,本文的分類器在敦煌古代壁畫(huà)的分類效果優(yōu)于Baseline++小樣本遷移學(xué)習(xí)分類器。本文實(shí)驗(yàn)中的Baseline++分類器性能低于基本的分類器性能的可能原因是Baseline++分類器是基于微調(diào)的遷移學(xué)習(xí),而本文的遷移學(xué)習(xí)的源域和目標(biāo)域幾乎不相關(guān),因此使用基于模型微調(diào)的Baseline++出現(xiàn)負(fù)遷移現(xiàn)象。
4.3 不同訓(xùn)練樣本數(shù)對(duì)比分析
為進(jìn)一步驗(yàn)證基于注意力機(jī)制和遷移學(xué)習(xí)的ResNet 的學(xué)習(xí)能力,分別隨機(jī)抽取總樣本數(shù)的50.1%、60.1% 和80.1%作為訓(xùn)練集,剩余樣本作為測(cè)試集,實(shí)驗(yàn)結(jié)果如表5所示。

表5 不同樣本數(shù)的訓(xùn)練集和測(cè)試集的測(cè)試準(zhǔn)確率對(duì)比Tab.5 Comparison of test accuracy on training sets and testing sets with different sample sizes
由表5 可以看出,基于注意力機(jī)制和遷移學(xué)習(xí)的殘差網(wǎng)絡(luò)對(duì)訓(xùn)練集的樣本數(shù)并不敏感,即使訓(xùn)練集的樣本數(shù)相差較大,測(cè)試準(zhǔn)確率也只相差1 個(gè)百分點(diǎn)左右,說(shuō)明本文網(wǎng)絡(luò)模型具有較強(qiáng)的學(xué)習(xí)能力,可以通過(guò)少量的數(shù)據(jù)集獲得古代壁畫(huà)朝代分類識(shí)別的能力。
4.4 優(yōu)化器對(duì)比分析
本文對(duì)優(yōu)化器Adam 和SGD 作了實(shí)驗(yàn)對(duì)比,如圖5 所示,雖然兩個(gè)優(yōu)化器的損失函數(shù)值在訓(xùn)練200 輪次后非常接近,但是網(wǎng)絡(luò)模型使用優(yōu)化器Adam 的測(cè)試準(zhǔn)確率為95.23%,使用優(yōu)化器SGD 的測(cè)試準(zhǔn)確率為98.05%,可見(jiàn)優(yōu)化器SGD 在圖像分類方面泛化能力更強(qiáng),分類準(zhǔn)確率更高。
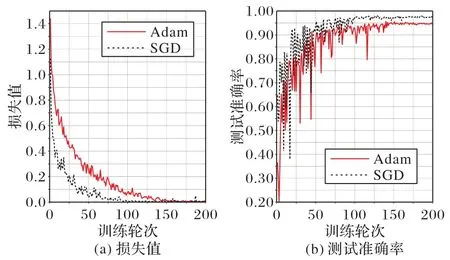
圖5 優(yōu)化器SGD和Adam的損失值和測(cè)試準(zhǔn)確率對(duì)比Fig.5 Comparison of loss value and test accuracy between optimizer SGD and Adam
4.5 POSA極化自注意力模塊的性能分析
為了驗(yàn)證POSA 模塊在古壁畫(huà)朝代分類識(shí)別網(wǎng)絡(luò)模型中所起的作用和性能,本文對(duì)POSA 模塊作消融實(shí)驗(yàn),該實(shí)驗(yàn)沒(méi)有進(jìn)行遷移學(xué)習(xí)預(yù)訓(xùn)練,實(shí)驗(yàn)結(jié)果如表6 所示。

表6 POSA模塊的性能分析Tab.6 Performance analysis of POSA module
由表6 可以看出,在ResNet20 模型的淺層引入POSA 模塊使古壁畫(huà)分類準(zhǔn)確率提高了3.16 個(gè)百分點(diǎn),表明POSA 模塊對(duì)古壁畫(huà)的分類性能有所提升。在此基礎(chǔ)上再進(jìn)行遷移學(xué)習(xí),由表4 可知有98.05%的朝代分類準(zhǔn)確率,與標(biāo)準(zhǔn)的ResNet20 網(wǎng)絡(luò)模型相比,朝代識(shí)別準(zhǔn)確率提高了5.21 個(gè)百分點(diǎn)。
5 結(jié)語(yǔ)
遷移學(xué)習(xí)對(duì)圖像分類具有很重要的研究?jī)r(jià)值和學(xué)術(shù)意義,本文提出了一種基于注意力機(jī)制和遷移學(xué)習(xí)的殘差網(wǎng)絡(luò)模型對(duì)莫高窟古代壁畫(huà)朝代進(jìn)行識(shí)別分類。首先,改進(jìn)了ResNet 的殘差連接方式,可以把淺層的信息無(wú)損地送入深層;其次,把用于圖像分割的POSA 模塊放到ResNet 的淺層中,有效地獲取圖片邊緣信息,故有較強(qiáng)的圖像特征抽取能力;然后,采用遷移學(xué)習(xí)方法,在CIFAR10 數(shù)據(jù)集上進(jìn)行了飽和預(yù)訓(xùn)練;最后,改進(jìn)了分類器算法,加大不同類之間數(shù)據(jù)分布的差異性,從而提高了網(wǎng)絡(luò)模型的分類能力。通過(guò)實(shí)驗(yàn)對(duì)比分析,本文的網(wǎng)絡(luò)模型展現(xiàn)了良好的性能,測(cè)試準(zhǔn)確率高于其他網(wǎng)絡(luò)模型10 個(gè)百分點(diǎn),表明了網(wǎng)絡(luò)模型的有效性和可行性。
在今后的工作中,研究的重點(diǎn)將考慮遷移學(xué)習(xí)的域泛化(Domain Generalization,DG)學(xué)習(xí)方法,使得在小數(shù)據(jù)集上進(jìn)行目標(biāo)域訓(xùn)練的網(wǎng)絡(luò)模型可以更深更寬,測(cè)試準(zhǔn)確率更高。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03

- 計(jì)算機(jī)應(yīng)用的其它文章
- “跨媒體表征學(xué)習(xí)及認(rèn)知推理”專欄征文通知
- 圖自動(dòng)編碼器上二階段融合實(shí)現(xiàn)的環(huán)狀RNA-疾病關(guān)聯(lián)預(yù)測(cè)
- 基于TrustZone的區(qū)塊鏈智能合約隱私授權(quán)方法
- 深度學(xué)習(xí)在天氣預(yù)報(bào)領(lǐng)域的應(yīng)用分析及研究進(jìn)展綜述
- 基于殘差編解碼-生成對(duì)抗網(wǎng)絡(luò)的正弦圖修復(fù)的稀疏角度錐束CT圖像重建
- 面向小目標(biāo)的YOLOv5安全帽檢測(cè)算法