基于DPI-C的脈動陣列模塊驗證平臺
2023-07-06 12:42:24王鑫,陳博
計算機測量與控制 2023年6期
王 鑫,陳 博
(江南大學 物聯網工程學院,江蘇 無錫 214122)
0 引言
人工智能(AI,artificial intelligence)加速芯片[1]很大一部分的算法涉及到矩陣運算,在矩陣運算過程中,其中的數學算術包括乘法運算,加法運算。矩陣乘法是一種計算量很大的算術運算,它被認為是許多信號處理應用的關鍵。同時,隨著AI加速芯片的巨大進步,邊緣計算[2]開始進入人們的視野,邊緣設備功能也變得強大,AI向邊緣的移動更是一種必然。研發人員在開發AI芯片時需要設計并實現有關AI算法單元,對于AI算法而言主要進行的數學運算是卷積操作。在硬件上經常使用到的卷積硬件結構有加法樹、Eyeriss和脈動陣列,其中的脈動陣列就常常應用于AI加速芯片領域之中[3]。
在芯片設計人員設計并實現芯片內部模塊時,后續的驗證工作也是不可忽略的,設計的模塊只有經過了驗證人員的全面驗證,排查一切可能出錯的點并加以改正之后,才可以讓它應用于芯片中,否則在后續流片時可能會出現致命的錯誤,從而導致之前的努力和投入的金錢都付之一炬。對脈動陣列模塊進行驗證時,其參考模型在整個驗證平臺的實現中較為繁瑣和耗時,主要原因出現在浮點數乘加運算。為了解決這一問題并鑒于C/C++等高級語言可以更加方便的實現激勵讀取、參考模型構建等功能,本文采用C語言來輔助完成參考模型的編寫。本文的驗證環境使用UVM(universal verification methodology)[4-5]來搭建,利用SystemVerilog的DPI[6-8]技術將C 代碼與驗證環境連接起來,有效地提高驗證效率,實現驗證平臺的重用。
1 所驗脈動陣列結構
脈動陣列(systolic array)的架構是簡單的、有規律的、模塊化的和并發的,它可以有效計算矩陣-向量相乘或者矩陣-矩陣相乘[9-11],它是一種應用在片上多處理器的體系結構。在這一節中,主要簡單列舉兩個矩陣相乘的具體計算過程從而引出脈動陣列,并介紹本文中所使用脈動陣列的具體結構。
1.1 基本矩陣運算及PE單元
給出兩個2×2階的A矩陣和B矩陣,兩矩陣相乘如式(1)所示。C矩陣由A、B矩陣相乘得出,其元素的具體計算過程如式(2)所示:
圖1為A、B矩陣相乘得出C矩陣的空間表示法,呈正方體結構。每個節點上執行乘加運算,在脈動陣列的體系結構中這些節點稱為處理元素(PEs,processing elements)。在圖1中可以看出A矩陣中的元素都是從正面進入,B矩陣的元素是從左側面進入,C矩陣元素從正方體上方得出。其中A矩陣的單個元素經過一個處理元素運算后,并不會即刻消失,而是繼續與走向下一個處理元素,同理B矩陣的元素也是以這種方式進行運動。從圖中可以看出,整個矩陣的運算是從正方體的底面開始,在頂面結束,正方體的每一面的每一個橫邊所表示的是A、B矩陣內的元素,而豎邊所表示的是中間運算結果,可以看出底面的4個處理單元經過計算得出結果后,各自把得到的結果發射到上面的處理元素作為被加數。經過這種空間表示法可以形象地解釋矩陣相乘其實是以向量的形式進行運算,同時又把向量拆分至元素,從而更加形象地描述了矩陣運算過程。
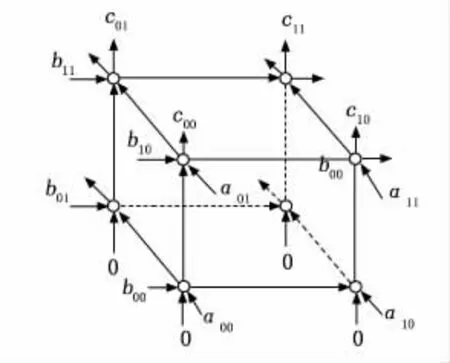
圖1 A×B矩陣的空間表示法
A、B矩陣在陣列中的運算方式以及矩陣元素在PE中的運算過程如圖2所示。在圖2中,左圖可以看出A、B矩陣內的元素是以西、北方向進入陣列中進行運算,輸出結果在南方;右圖是C矩陣中的元素在PE單元中具體運算過程剖析圖,其中的橢圓表示一個PE單元。
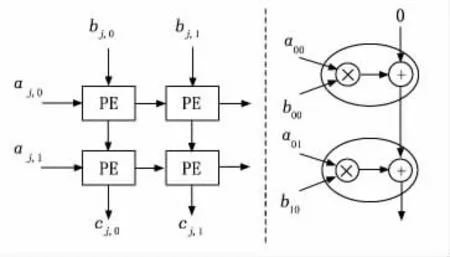
圖2 二維陣列和PE單元運算過程
在圖2中,B矩陣以列向量的形式送進陣列中,4個元素分布在對應的位置,如圖2左圖中的左上角是b0,0,右下角是b1,1,A矩陣則以行向量的形式進入陣列與排布好的B矩陣進行運算。我們可以看出A矩陣的行向量進入陣列后,它在未完全涉及所有陣列之前,并不會發生變化,例如a0,0元素在向右游走時,是貫穿兩個PE單元后變為無效,這樣才能保證A矩陣的行向量與B矩陣的列向量進行運算,A、B矩陣完成了標準的矩陣運算。
1.2 脈動陣列內部結構
脈動陣列是由多個PE單元編排而成。本文中的待測設計(DUT,design under test)是由32×32個PE 單元組成的脈動陣列,其二維空間分布如圖3所示,呈正方形結構。此陣列把每列的32個PE單元劃分為一個DOT(vector dot product unit),每一個DOT 運算后會產生1個運算結果作為新矩陣的元素。
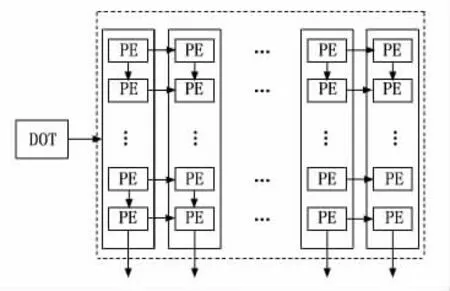
圖3 脈動陣列內部結構
劃分后的DOT 是執行一次矩陣乘運算中一個矩陣的行向量乘一個矩陣的列向量的運算操作。選擇的行向量會不斷的向右方向進行延續并與下一個列向量進行運算,即一個行向量需要游歷32個DOT 后才會失效,此時下一個行向量便會進入。脈動陣列中參與運算的數都是浮點數,經過脈動陣列運算之后,最終會形成一個由32個浮點數所組成的向量,每經過32 次運算就會組成一個32×32 矩陣。1.3小節詳細地描述了矩陣是如何在脈動陣列中進行運算的。
1.3 矩陣送入脈動陣列進行運算
在脈動陣列中,實現32×32矩陣運算分為以下步驟:
1)先將一個n=32的B矩陣分成32個列向量送入脈動陣列中的每一個DOT,等待另一個行向量a的進入,a向量與每一個DOT 進行運算。經過32個DOT 的運算之后可以得到新向量。
2)每產生32次新的a向量并與之前在脈動陣列中排布好的B矩陣相乘,便可以得到C矩陣。
3)在完成一次C矩陣的計算后,開始更換新的B矩陣與新的a向量,這樣經過再一次的運算便形成新的C矩陣。
在每個DOT 中,每個PE 單元同時進行乘加運算。每兩個相鄰的積相加,參與一次加法的積不可以與另一個相鄰的數進行相加。得出的和再一次跟另一個和進行相加,逐步重復下去,便形成加法樹的形式。其運算過程如圖4表示。
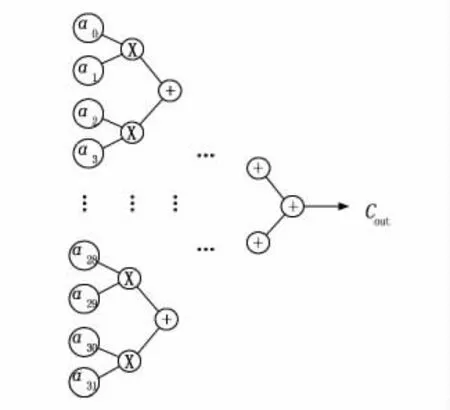
圖4 單個DOT 結果運算輸出過程
2 基于DPI-C的驗證方案
驗證人員在正常情況下,可以利用SystemVerilog直接完成參考模型的編寫,但是在一定情況下,利用C/C++是唯一解決參考模型編寫問題的途徑。例如,當遇到復雜的函數、SystemVerilog中不存在的、復雜的數據類型時,便可以使用C/C++來輔助完成驗證環境的搭建,這樣既快捷又高效。對于脈動陣列中的浮點數運算,主要是利用C程序進行建模,之后通過DPI技術把C 代碼放進驗證平臺所需的位置來輔助完成脈動陣列的驗證。
2.1 直接編程接口
DPI-C利用了SystemVerilog的直接編程接口連接C 編程語言,實現了SystemVerilog 和C 語言之間的數據通信[12]。一旦聲明或者使用了import語言 “導入”了一個子程序,就可以像調用SystemVerilog中的子程序一樣去調用它,使用起來非常方便。通過較為高級的編程語言實現復雜模型比使用HDL語言要輕便很多,并且仿真速度也比較快。比如,在C 語言中,它已經提供了很多庫函數,直接調用即可,無需重新編寫。這樣既保證了激勵編寫的正確性,又提高了可重用性。同時C 語言目標代碼的執行速度比HDL仿真速度至少要提高一個數量級。在本文中通過DPI技術實現C代碼的更高層次的復用。
在對特殊的DUT 進行驗證時,采用直接編程接口也可以很便利地把C 代碼與UVM 驗證環境連接起來,按照下面4個步驟進行。
1)編寫C代碼,實現所需算法。在編寫C 代碼時,需要聲明包含頭文件svdpi.h,是因為在svdpi.h 中包含了SystemVerilog DPI結構和方法的定義。
2)完成C 與SystemVerilog的通信。在UVM 驗證平臺中,通過導入函數或者任務的方式來調用C 代碼,DPI也允許在C代碼中通過導出函數和任務來調用SystemVerilog中的方法。
3)匹配數據類型映射。由于SystemVerilog與C 語言數據類型差異較大,SystemVerilog中定義了通過DPI傳遞的每個數據類型的匹配模式。需要注意的是,DPI并不會檢查數據類型的兼容性,需要使用者自己保證數據匹配的正確性。
4)利用仿真工具編譯C程序的方法,生成最終的目標碼,并與SystemVerilog混合運行。
2.2 非標準化的浮點數
IEEE二進制浮點數算術標準(IEEE754)是20 世紀80年代以來最廣泛使用的浮點數運算標準[13],許多CPU以及浮點運算器都采用了這一標準。一個浮點數的表示方法可以為:
其中:sign為符號位,exponent為指數位,fraction為小數位。對于指數位而言,它實際上是指數的實際值加上某個固定值,這個固定值在IEEE754標準中被稱為偏置并規定該值為127,即2e-1-1,e取數字8。這里需要注意的是,IEEE754標準中存在3個特殊值:
1)如果指數位是0,并且小數位為0,那么這個數是±0(和符號位相關)。
2)如果指數位是255(2e-1),并且小數位為0,那么這個數是±∞(和符號位相關)。
3)如果指數位是255(2e-1),并且小數位不為0,那么這個數表示不為一個數(NaN)。
常見的浮點數有:半精度浮點數(16bit)、單精度浮點數(32bit)、雙精度浮點數(64bit)。在本文中的脈動陣列所運算的浮點數是半精度浮點數和單精度浮點數,其中單精度浮點數是定制的,即在IEEE754標準的基礎上進行了修改,把標準中特殊值NaN更改為無窮大或無窮小(和符號位相關)。
2.3 參考模型的編寫
參考模型用于完成和DUT 相同的功能,其輸出用于與DUT 的輸出相比較。根據脈動陣列內部體系結構以及定制化的浮點數算術運算規則,設計并完成驗證平臺中的參考模型。基于脈動陣列運算要求,需要實現乘法和加法的模型建設。
乘法模型使兩個16位半精度浮點數相乘能夠得到一個32位的單精度浮點數;加法模型是為了實現32位單精度浮點數相加的功能。在模型搭建之前就需要引入利用C 語言寫好的乘加運算模型,把它們當作函數來使用。
對于在參考模型中所使用的乘法和加法函數而言,在函數形式上這兩個函數后面都有3個參數,第一個參數表示結果輸出,第二和第三個參數都表示輸入。因為乘法器實現的是兩個半精度浮點數乘法運算,因此兩個輸入都是16bit,其輸出結果就變成了32bit的單精度浮點數。加法器的兩個輸入是乘法器的輸出,即都是32bit。在對加法樹進行建模時需要用到加法器。
由于在設計并考慮到對脈動陣列進行建模時整個代碼頁太多,我們在編寫參考模型時,使用了extern virtual task關鍵字。其中的extern是為了控制class的長度,如果在class中想使用一些函數或者任務,用這個關鍵字就可以另起一頁代碼去編寫代碼行較長的函數或者任務,這樣就可以避免一頁代碼行過多;virtual就是簡單的虛函數功能;task是簡單的任務關鍵字。這樣只需要在新的代碼頁中編寫有關脈動陣列的模型代碼即可。
參考模型的編寫思路如下:
首先是實現一個DOT 中的乘法運算,并把運算結果寄存到一個數組中,這種數組需要聲明32個,數組的位寬為32bit。完成一個DOT 中的乘法運算后,便是開始建立加法樹模型,從而得出最終結果。經過上文的介紹后,我們可以得知,加法樹的底部是由32個乘法運算結果而組成的,而這些結果已經存入了所聲明的數組中。從數組中取出這32個乘法運算結果并作為加法器的輸入,按照兩兩結合的方式進行相加,其過程如1.3小節中所描述的一致,此時所需要的加法器數量為16個。經過相加后便可以得出16個數據,這16個數據會存入到新聲明的數組中去,然后從新聲明的數組中取出數據,繼續兩兩相加,這時候會比上次減少8個加法器,以此類推,最終會得到一個輸入結果,即一個DOT 的輸出,最終使用了32 個乘法器,31 個加法器。
其次,由于脈動陣列中劃分了32個DOT,因此只需要在上述步驟情況下,利用一個for循環即可實現整個脈動陣列的運算過程。經過運算后,32個DOT 會產生32個運算結果,這些運算結果也會根據DOT 的排列順序而進行排序,從而組成一個向量。例如,處于脈動陣列中最左邊的DOT,那么它產生的結果就會在結果向量的第一個位置,同理,其它DOT 產生的結果就會在結果向量中相對應的位置,這一功能只需要利用移位便可以實現。具體的實現過程是,每得到一個32bit的數據時,都把它排在向量的最左端,然后把它和向量的高992 位進行組合,利用System-Verilog中的{},以此往復32次。
上述的步驟就可以實現脈動陣列的模型建立,高效且簡潔明了,對于其他人而言也方便理解。如果存在相似結構的脈動陣列,此模型也可以直接進行移植使用,達到復用的效果。
3 UVM 驗證結構
使用DPI可以很方便地連接C 代碼,這些C 代碼可以讀取激勵、包含一個參考模型或僅僅擴展SystemVerilog的功能。此外,驗證平臺還使用到了UVM,它是由Cadence、Mentor和Synopsys聯合推出的新一代驗證方法學。
3.1 關于UVM
UVM 主要是一個以SystemVerilog語言為基礎的一個庫。因為UVM 具有層次化的結構、可隨機化的激勵、可高度復用的驗證平臺等優點廣泛應用于數字集成電路(IC,integrated circuit)的驗證過程之中[14-15]。驗證平臺因為使用了SystemVerilog這一面向對象語言來構建,所以UVM也繼承這一特點。在UVM 中,是通過樹形結構來管理各個類,各個類是派生于uvm _object或者uvm _component[16],而UVM 中常用類的繼承關系如圖5所示。這些通用驗證部件不僅具有可配置性、封裝性、可重用等優點而且還具有phase自動執行特性。Phase是將component分割成幾個不同的執行階段并且按照一定的先后順序來執行。Phase的引入,在很大程度上避免了由代碼書寫不規范而引發的問題。Phase中最常用的由build_phase、connect_phase、run_phase等。在3.2和3.3小節中,詳細講述了本實驗的驗證平臺結構。
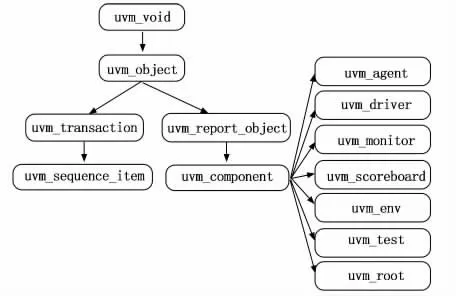
圖5 UVM 中常用類的繼承關系
3.2 UVM 驗證平臺組件
UVM 中各個組件有著不同的功能,包括產生激勵、發送激勵、采集信號、模擬待驗模塊以及輸出接口數據對比等。基于本文脈動陣列的結構,其驗證平臺采用UVM 組件進行設計,具體各個組件的名稱及其功能見表1。這些組件的繼承關系會在1.3小節中進行描述。
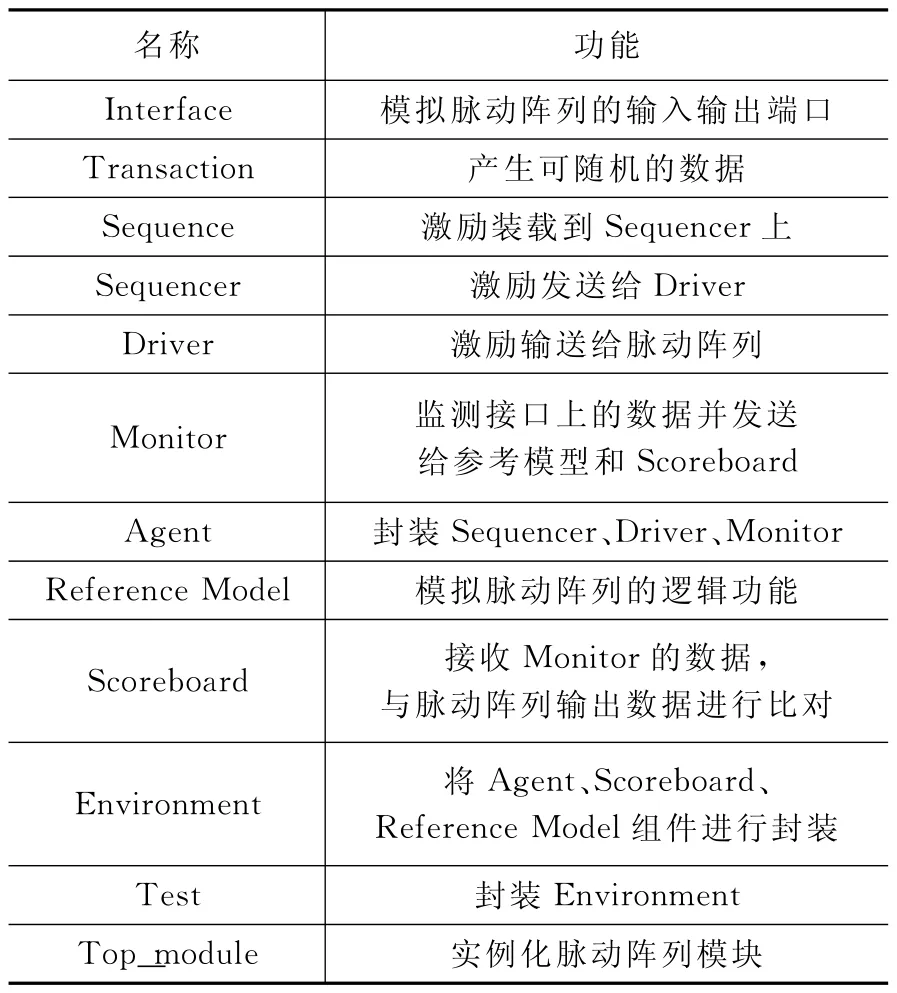
表1 驗證平臺組件及其功能
3.3 驗證平臺內部通信
當設計一個基于UVM 的驗證平臺時,需要完成各個組件的代碼編寫,其次把編寫好的各個組件進行實例化并利用事務級建模(TLM,transaction level modeling)[17-18]方法進行組件之間的通信。其組件之間具體的通信以及驗證平臺部分功能實現過程:
1)首先是輸入階段,在Transaction中聲明受約束的激勵,激勵通過Sequence發送給Driver,之后再由Driver發送給接口,此時Monitor對輸入接口進行監測,并把監測結果傳送給Reference Model,這一步便完成了驗證平臺的輸入數據包發送過程以及脈動陣列的激勵產生。
2)輸入階段完成后,脈動陣列和Reference Model便會產生各自的輸出。脈動陣列的輸出結果也是由Monitor進行監測脈動陣列輸出接口上的數據得到的。Reference Model的輸出結果和脈動陣列的輸出結果會各自寫入預置好的FIFO(先入先出,first input first output)中,在Scoreboard會把兩個FIFO 中的數據進行讀取并進行對比,這一階段便完成了輸出階段。
3)由于一些信號在時序上需要滿足特定的情況,采用在Interface 中添加斷言的方式去保證信號時序符合要求[19-20]。
根據3.1小節圖5中UVM 類的繼承關系、3.2小節表1中的驗證平臺組件以及上述的內部通信過程,本文設計的驗證平臺框架如圖6所示。每個組件名字下面括號內的標簽就是其父類,例如Driver繼承于uvm_driver,Reference mode繼承與uvm_component,其他組件同理。
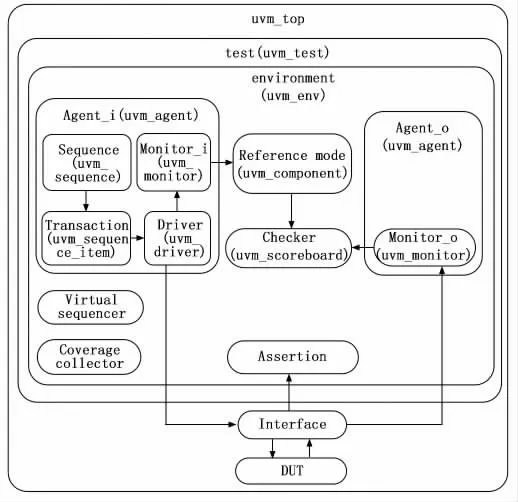
圖6 基于UVM 的驗證框架
4 實驗結果與分析
本節介紹在完成脈動陣列的驗證平臺搭建后,DUT 和參考模型的輸出結果在Scoreboard中進行對比的過程,并對比對結果進行分析。
4.1 結果對比過程
激勵經過輸入給脈動陣列和參考模型后,脈動陣列以及參考模型會把各自的輸出結果送進預先定義好且不同的FIFO 中。把脈動陣列的輸出結果定義為actual放進一個FIFO 中,參考模型的輸出結果定義為expect放進一個FIFO 中,之后分別從兩個FIFO 中取數據來進行比對。
在出現錯誤的時候,先記錄下actual與expect,定位所發送出現對比錯誤的數據并記錄下來。找到目標數據后,根據設定的浮點數算術運算標準進行人工計算,把人工計算結果分別與脈動陣列和參考模型輸出的結果進行對比,然后以此來分析錯誤原因并修正錯誤。修正錯誤后,把記錄下的數據以定向激勵的形式再一次發送給驗證平臺,若此時輸出為正確結果,則繼續進行驗證,否則重復上述工作。
4.2 驗證結果分析
在本次測試用例中,給出一個隨機種子,其中有1 000個受約束的隨機數據。在所給的隨機數據中包括vain(A矩陣)、vbin(B矩陣)、ainvld(A矩陣有效信號)、binvld(B矩陣有效信號)。vain、vbin接口在測試的時候分為符號位、指數位、尾數位。把這三部分進行隨機約束遍歷,進行這一操作是為了實驗后階段能夠收取較好的覆蓋率。隨機約束遍歷情況如表2所示。
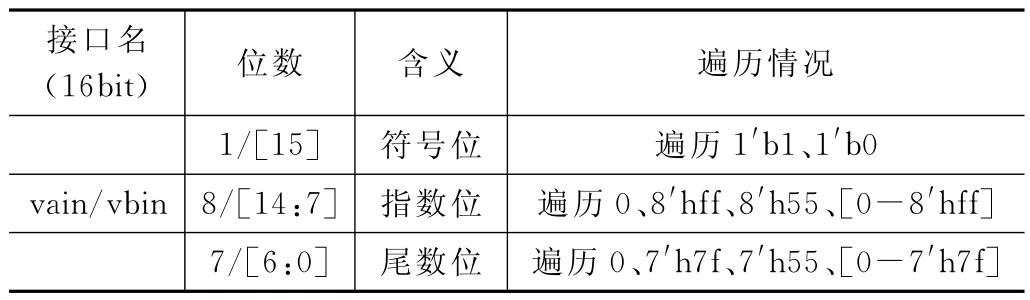
表2 不同接口數據遍歷情況
在實驗測試用例里的隨機數據包全部使用完之后,需要查看FIFO 中是否還有殘留的未發送的隨機數據包。在實驗中,經過多次隨機種子后,其FIFO 中的殘余數據結果如表3。
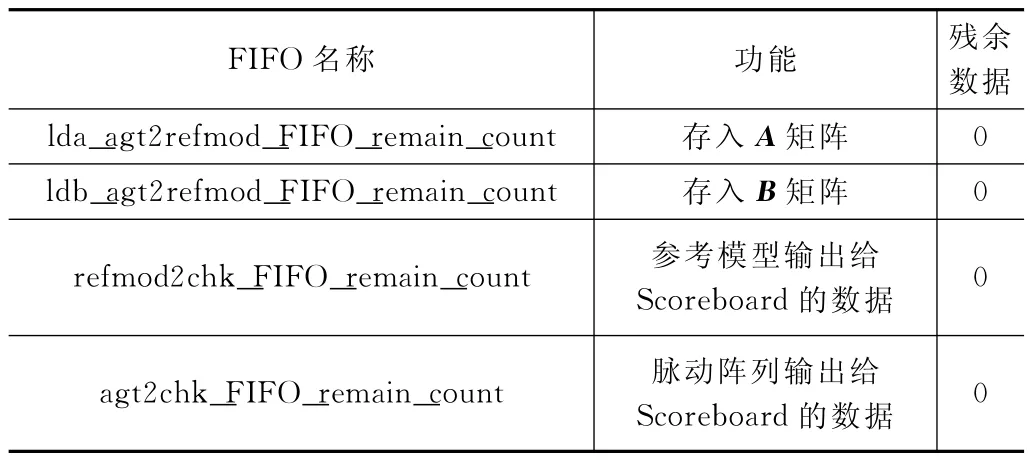
表3 各個FIFO 內數據情況
運行不同的測試用例的仿真或者不同的種子都會生成專屬的覆蓋率數據。經多次仿真且覆蓋率經過合并后,根據覆蓋率情況證明達到了驗收要求。表4所展示的是最終的總的覆蓋率結果,每個覆蓋組代表著脈動陣列中的一個功能點。
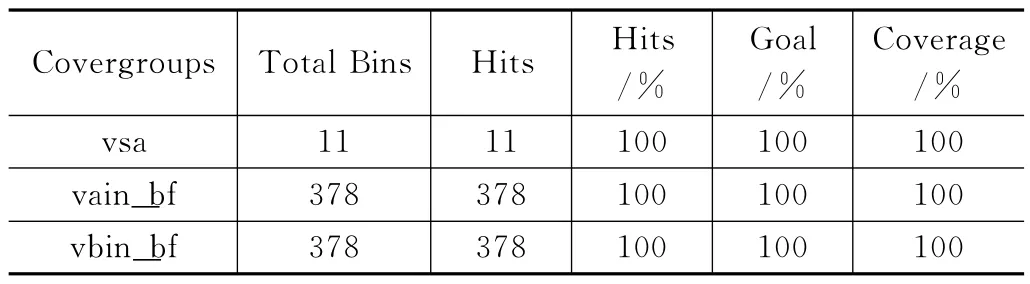
表4 功能覆蓋率結果
5 結束語
本文利用DPI-C 技術與UVM 相結合的方法搭建一個脈動陣列的驗證環境。該驗證環境利用了SystemVerilog事務處理能力強大的優點以及C 實現模型成熟、穩定、重用性高的優點,相對于傳統的驗證方法,平臺結構較為簡單,可以快速搭建參考模型。本文實驗通過運用覆蓋率驅動策略,將驗證進度進行量化,最終達到功能覆蓋率100%的驗證目標,提高了驗證的完備性和準確性。另外,本文的驗證方案不僅能夠實現驗證環境的復用,而且測試用例也能實現更高驗證層次的復用,可以大幅縮短片上系統芯片的開發周期。
