基于生存分析理論的電子資源用戶流失預測研究
2023-07-10 07:18:33刁羽薛紅
新世紀圖書館 2023年5期
刁羽?薛紅


摘 要 基于電子資源校外訪問系統用戶行為數據,運用生存分析理論中的Kaplan-Meier、COX比例風險模型研究用戶整體流失概率變化規律、用戶個體訪問行為與其流失概率之間的發展變化規律及相關關系,并在預測用戶流失臨界點的基礎上建立用戶流失預警機制,從而為進一步采取用戶流失干預措施提前布局。本研究能反映出用戶訪問行為與用戶流失概率之間的變化情況,具有較高的應用價值和推廣價值。
關鍵詞 用戶流失;流失預警;生存分析;校外訪問系統;電子資源行為數據
分類號 G252.62
DOI 10.16810/j.cnki.1672-514X.2023.05.009
Research on Electronic Resource User Churn Prediction: Taking Off-campus Access System of Electronic Resource as Example
Diao Yu, Xue Hong
Abstract Based on the user behavior data of the off-campus access system of electronic resources, the Kaplan-Meier and COX proportional risk models in the survival analysis theory were used to study the change law of the overall probability of user churn, the law of development change and the correlation between the individual user access behavior and the churn probability, and a user churn warning mechanism based on predicting the critical point of user churn was established. Therefore, the further implementation of user churn intervention measures in advance layout. This study can reflect the change between user access behavior and user churn probability, and has high application value and promotion value.
Keywords User churn. Churn prediction. Survival analysis. Off-campus access system. Electronic re-source behavior data.
0 引言
隨著數字化新技術的迅猛發展,傳統科學研究范式已悄然發生變革,電子資源已成為各種不同層次的用戶獲取信息的主要類型[1]。目前,各高校圖書館的電子資源購置費所占館藏的經費比例過半,自2006年以來均值與比例基本上呈抬升趨勢,雖然在2019年發生下滑,但2020年隨即恢復上升[2]。盡管各種類型電子資源在圖書館中不斷得到補充,較大地滿足了用戶需求,但即便如此,仍存在不少用戶在訪問電子資源過程中由積極使用轉向消極使用甚至徹底放棄的現象,這已成為高校圖書館電子資源服務運營面臨的挑戰和難題,對此采取用戶流失干預措施,滿足用戶需求,提升老用戶訪問資源行為是關鍵。通常情況下,拓展新用戶與挽留老用戶相比,無論在花費的成本上,還是在為企業或系統平臺帶來的價值上,后者皆優于前者[3]。因此,為最大程度挽留老用戶,有效預測瀕臨流失用戶的關鍵臨界點顯得尤為重要。為此,本文基于生存分析理論[4]重點研究用戶訪問行為與用戶流失概率之間的發展變化規律及相關關系,來預測用戶流失的臨界點,并在此基礎上形成用戶預警分析,從而為圖書館分析流失原因、挽留瀕臨流失用戶夯實基礎。
1 研究綜述
用戶流失最早由Keaveney和Parthasarathy于2010年針對在線服務提出[5],流失類型主要分為兩種,一是用戶中斷在線服務,即在使用一段時間后停止使用該服務;二是用戶“服務切換”,即改變所使用服務的提供商或運營商。對于流失用戶的定義依行業或訪問方式的不同而不同,移動設備App領域以用戶一定時期內不再登錄、卸載軟件及二次安裝或選擇其他同類替代為界定標準[6]。
近年來,業界關于用戶流失的研究主要是以S-O-R理論、扎根理論等為基礎,利用訪談設計、問卷調查等方式來統計分析研究不同類型平臺用戶流失的重要因素。對于用戶流失預測研究也有一些學者利用用戶訪問系統時留下的客觀行為數據進行分析,如賀芳以“新浪微博”為例,在用戶細分的基礎上采用典型判別分析法構建用戶流失預測模型, 并通過交叉驗證法判別預測精度[7]。王若佳,嚴承希,郭鳳英等使用LDA抽取用戶關注主題的文本向量,使用SMOTE算法對模型進行修正,以解正數據集中流失與非流失用戶比例失衡的問題,并使用C4.5決策樹等6個算法對比研究預測用戶流失情況的優劣,對比顯示Gradient Boosting和ExtraTrees模型效果較好[8]。在圖書館領域,有些學者基于生存分析理論對文獻采購、引文分析、關鍵詞等方面展開分析研究,如:Jiang Z、 Fitzgerald S R、Walker K W等學者使用生存分析法分析出版者、出版時間、價格、美國國會圖書館分類法等與圖書館文獻采購的相關關系[9]。朱世琴,蔣辛未等利用生存分析的Cox回歸研究CSSCI來源期刊中2000-2014年9個學科的論文被引頻度的年代分布,以確定文獻的老化風險率[10]。劉智鋒,李信通過生存分析方法對作者關鍵詞進行分析,以反映作者關鍵詞生存情況[11]。孫佳佳,李雅靜通過客戶價值細分RFM模型對CSSCI收錄的圖情檔文獻的作者關鍵詞建模,在此基礎上利用Kaplan-Meier曲線挖掘熱點主題[12]。也有學者將生存分析應用于信息系統用戶流失的研究,但總體數量較少。賴院根等為反映國家科技圖書文獻中心(NSTL)的總體運行狀況,對NSTL在2003-2008年間的用戶進行了用戶流失分析,并使用壽命表方法揭示了NSTL用戶的生存時間分布[13];賴院根,劉礪利在通過利用SPSS生存分析模塊中的壽命表分析了NSTL用戶生存時間的基礎上,使用Kaplan-Meier模塊對贈卡用戶和無贈卡用戶進行了生存時間比較,并使用COX模塊分析了流失用戶的影響因素[14]。
2 用戶訪問電子資源行為數據分析的相關性理論和分析模型
在大數據時代,如何通過電子資源行為數據有效揭示其與用戶流失概率的相關性,如何發掘瀕臨流失的用戶并建立預警信號,不僅是進一步分析用戶流失原因并精準施策的基礎,也是提高電子資源服務效能的根本。基于這樣的考慮,那么能夠真實反映用戶對校外訪問系統黏性的用戶訪問電子資源行為數據即成為研究用戶檢索行為和科研方向的重要信息源。高質量的電子資源行為數據不僅是用戶獲取電子文獻資源時與平臺自然產生的最為客觀的數據,也是新數據范式下快捷高效地發現事物間的內在關聯,明確用戶的使用規律和關注焦點,對此相關性的研究分析可為圖書館預防電子資源用戶流失提供科學依據。
目前,在業界相關研究中,數據驅動的科學研究第四范式開始注重分析數據間的相關關系,即某數據的發生與其他數據變化規律間的關系[15],而非拘泥于揭示現實的“實體性的物與發生性的事”之間的因果關系[16]。目前,數據相關分析已然有效地應用于推薦系統、商業分析、公共管理、醫療診斷等領域,通過時序分析、空間分析等方法進行數據分析[17]。故此,本研究基于生存分析理論利用用戶訪問系統時留下的客觀行為數據進行的分析,不是探究用戶訪問電子資源各行為特征變量與造成用戶流失之間的直接因果關系,而是基于大數據思維,分析用戶行為數據特征值隨著時間變化與其流失概率之間的發展變化情況及相關關系,以期為下一步找出造成用戶流失的關鍵性原因打下堅實基礎。
基于電子資源校外訪問系統(以下簡稱校外訪問系統)用戶流失概率及流失臨界點的計算,本文運用生存分析理論中的Kaplan-Meier和COX比例風險模型來研究用戶整體隨時間推移流失概率的變化規律,解析用戶個體訪問行為與其流失概率之間發展變化情況及相關關系,以及預測用戶流失臨界點,并最終形成用戶流失預警分析。
首先定義用戶的生存變化規律,用生存函數(survival function)來表示。將用戶定義為r;將用戶使用校外訪問系統的時間長度定義為T,即用戶生存時長;將t定義為計算r生存概率的隨機時間。生存函數值反映T≥指定時間t時,用戶繼續使用校外訪問系統的概率,其公式[4]如下:
從公式一可以看出,生存函數是t的單調下降函數,代表用戶流失的風險隨著時間的增加而增加。函數下降快慢,反映了用戶使用校外訪問系統流失速率的總體情況。
在本研究中,由于用戶開始使用校外訪問系統的時間以及在觀察期間處于流失或刪失的狀態各有差異,單純地使用生存函數或危險率函數對含有刪失數據的樣本數據評估校外訪問系統用戶的流失規律顯然偏差較大。為此,針對存在刪失數據的生存分析,可使用1958年由卡普蘭和梅爾聯合提出的一種基于不完全樣本估計總體生存函數的非參數估計量(Kaplan-Meier estimator)進行計算,公式[4]如下:
其中i=(1,2,…,n)為用戶集合,y(1)≤y(2)≤…≤y(n)是y1,y2,…,yn的順序量,y為出現用戶流失事件的時間點,δ(1),δ(2),…,δ(n)是與之相對應的y1,y2,…,yn的δ值。從公式二可以看出,Kaplan-Meier的每個時間節點的生存概率都是以上一個時間節點為基礎并剔除刪失數據進行計算的,因此能較好地解決刪失問題。
雖然使用Kaplan-Meier可以預估用戶在指定時間節點流失的概率,但沒有考慮相關變量在其中的作用,因此還需采用COX比例風險模型(cox proportional-hazards model,以下簡稱COX模型)。COX模型是一種半參數回歸模型,考慮了一種或多種因素對用戶生存時長的影響。設與用戶生存的相關的因素:X=(X1,X2,…,Xm),則根據COX模型,可以建立以h(t,X)為因變量的指數回歸方程[18]:
其中1,…,m為導致用戶死亡的因素X1,…,Xm的回歸系數,h(t,X)為風險率函數,計算當用戶在時間t時仍然在使用校外訪問系統,那么計算其在t至?t(?t無限趨近于0)之間流失的概率,公式如下[19]:
本研究的重要目的是預測用戶流失的臨界點,其原理是在擴展公式一的基礎上計算用戶在時間s的生存概率。因此在預測生存時間的計算上,設s為用戶已經存活的時長,可利用公式五計算該用戶已經存活到s時間的條件下,還能存活到t時的概率,其中因在s前用戶尚未流失,所以在計算概率時需將s前用戶的生存概率設置為1.0[20]:
3 數據來源與數據結構
本研究所采集、利用用戶特征數據與用戶訪問電子資源的行為數據(以下簡稱行為數據),是指用戶在利用校外訪問系統過程中登錄、檢索、瀏覽、下載等隨著時間變化的歷次會話的集合。這些數據是用戶對校外訪問系統用戶黏性的真實體現,它們中每個特征值的變化情況,皆可體現校外訪問系統對用戶的吸引力,即校外訪問系統價值[21]。之所以選取校外訪問系統行為數據作為數據來源之一,首先在于該系統具備廣泛的使用率,能確保采集的樣本數據的多樣性及準確性,且只涉及用戶訪問電子資源的行為數據,提取容易;其次該系統詳細、全面記錄了用戶每次訪問的不同維度的行為數據,能客觀、真實地反映出用戶利用校外訪問系統情況;第三在技術保障方面,筆者在前期研究成果中已經提出并實現了基于電子資源校外訪問系統的數據采集關鍵技術和實施方案[22]。
3.1 圖書館集成管理系統數據結構
圖書館集成管理系統(以下簡稱LIS)中的“讀者庫”表存儲了用戶基本人口統計學特征數據。而校外訪問系統的登錄名為用戶在LIS中的“借書證號”,因此,可方便地將登錄名與LIS的借書證號進行關聯,并從LIS中獲取本研究所需要的數據。根據學校的實際情況,本研究提取了借書證號、姓名、讀者類別字段作為數據來源。
3.2 行為數據來源及其數據結構
本館購置的校外訪問系統用戶行為日志數據以JSON格式存儲,每條JSON數據代表用戶與校外系統的一次會話,JSON數據的文件名為用戶的登錄名,同一天所有用戶的日志數據存儲在以當天日期命名的文件夾中。單條JSON日志數據結構如圖1所示。
在校外訪問系統中,本研究涉及的主要數據有:(1)文件夾名,用于提取用戶的訪問時間;(2)JSON日志名,用于提取用戶的登錄名;(3)日志文件的RES元素,通過其SEARCH、DOWNLOAD、VIEW4個子元素獲取每次會話用戶檢索、下載、瀏覽的次數。
3.3 數據融合
因為校外訪問系統的登錄名與LIS的借書證號完全一致,故將借書證號作為主鍵,登錄名作外鍵進行連接,從而可以融合上述兩個系統中的數據并存儲在以“SurvivalDataset”命名的數據庫中。該數據庫各表及表間關系如圖2所示。
SurvivalDataset數據庫涉及的表及其中字段含義如表1所示:
4 校外訪問系統用戶數據相關性流失分析
本文根據校外訪問系統的實際使用情況,將用戶在6個月內不再使用校外訪問系統定義為“流失”,其余情況則被定義為“刪失”。此外,本研究由于學生在校時間有一定時間限制,必然出現自然流失的現象,故本文僅選擇以本校教職工為研究對象。其分析思路如圖3所示。
首先,使用Kaplan-Meier分析用戶整體行為數據在不同時期其生存概率的變化情況,并以此揭示出用戶整體流失風險變化趨勢;其次,通過使用COX比例風險模型,分析用戶各行為數據特征值與用戶流失概率之間發展變化規律及相關關系。當特征值的變化與用戶流失概率呈正相關時,則可以將之視為用戶瀕臨流失的重要信號;第三,通過公式五預測用戶流失臨界點(日期),為預防用戶瀕臨流失提前布局;第四,以python 3.8.3+lifelines 0.26.3為工具進行上述生存分析。
4.1 基于Kaplan-Meier的用戶整體流失風險分析
通過LIS讀者庫的用戶級別字段篩選出1165名教職工的行為數據,研究時間范圍為2017年3月14日至2021年8月31日。根據前文公式二,從SurvivalDataset中提取以下數據并以xlsx格式保存。為了對不同時間階段校外訪問系統的運行態勢進行對比,本環節將數據分割為2017年3月14日至2020年8月31日、2018年3月14日至2021年8月31日兩組數據。數據結構見表2。
通過Kaplan-Meier分析,并利用python的lifelines庫進行對比,形成不同時間段用戶生存曲線對比圖(圖4)。圖4中“At_risk”表示生存時長與橫坐標不一致的用戶數;“Censored”表示刪失用戶數;“Events”表示在此及以前的累積流失用戶數。
以圖4中2018—2021年生存期為10個月的數據為例,在前0~10月期間,校外訪問系統累積流失人數為287人,有178名用戶的使用時長正好為10個月,因沒有后續統計數據揭示用戶體整體是否趨于流失,故這些標記為刪失數據,另有522名用戶的使用時長超過10個月。在此基礎上,調用Kaplan-Meier的logrank_test函數對上述兩組時間段的用戶(按時間劃分的兩組數據)的生存曲線做Log-rank 檢驗,p值均等于0.21,表明這兩條生命曲線沒有統計學意義上的差異。從圖4的生存對比還可以看出,雖用戶整體生存概率在2018年至2021年間的略高于2017年至2020年間,但總體來看,兩個時間段用戶生存概率走勢幾乎一致,表明校外訪問系統運行狀態穩定且在2018—2021年期間用戶流失風險還略有降低。總之,結果表明:通過對比不用時期校外訪問系統用戶整體的生存概率,可從宏觀層面上有效監測系統各時期其流失風險變化情況;當各時期校外訪問系統用戶整體生存概率趨于平穩時,則可將瀕臨流失的用戶個體作為重點監測目標。以下將利用COX模型解析用戶訪問行為與其流失概率之間發展變化規律及相關關系。
4.2 基于COX模型的用戶流失概率相關特征分析
本研究從最能反映用戶粘性的訪問頻率、有效訪問行為,以及用戶對系統掌握的熟練度等角度出發,根據經驗提取了登錄頻繁度等7個指標作為可能反映用戶流失概率變化的相關特征值,再融合用戶名等基礎數據生成進行COX分析所使用數據。數據結構見表3。
通過分析計算,其結果如表4所示。表4中,coef欄為COX回歸方程中各自變量的回歸系數。exp(coef)代表風險比(HR,hazard ratio),coef欄的值為此欄的自然對數。當HR=1時,coef的值為0,則變量對用戶流失概率沒有影響;當HR>1時,coef的值為正,表示變量值越大,則用戶流失風險也越大;當HR<1時,coef的值為負,表示變量越大用戶流失風險越小。se(coef)為系數的標準誤差。表中后面4列分別代表coef和exp(coef)在95%置信區間的上限與下限。
從表4中可得出以下結論:用戶活躍度為用戶流失概率的不良相關因素,即每次登錄后進行大量檢索操作的用戶更具有流失風險。其余為良性相關因素,即它們所代表的用戶訪問行為指標越活躍,流失風險越低,其中登錄頻繁度尤為突出。
為評估COX模型的精準度,本研究通過一致性指數(Concordance Index,C-index)進行評價。其值在0.5到1之間,數值越大,模型的準確性越高。當為0.5時,表示模型的預測完全隨機,無任何意義;當等于1時,則表示模型與實際情況完全符合。其原理為將樣本數據隨機進行兩兩配對,并比較他們的協變量與其生存時長的關系是否相符,即協變量顯示生存時間更短的用戶實際生存時長也更短,則為相符,反之,為不相符[23]。最后計算相符的結果在所有情況中的比例。經過計算,本研究的C-index值等于0.82,準確度良好。
5 預測用戶流失臨界點(critical point)及預警分析
利用lifelines可以計算留存用戶在最后一次登錄時間(d)后每一天的生存概率,在此基礎上即可簡捷地預測用戶流失臨界點(以p表示)。首先,根據公式五計算用戶生存概率剛剛小于0.5時距離d的時長(即剩余生存時間),以t_s表示;其次,計算用戶流失臨界點的公式為:p=d+t_s。在該日期,用戶的生存概率剛剛小于0.5,用戶留存概率剛好低于用戶流失概率。需要注意的是,lifelines默認最多計算1640天的生存概率,如果用戶在1640天時的生存概率仍然未小于0.5,則它不再計算t值,而是將用戶的生存時長標記為無窮大。在這種情況下就無法預測流失臨界點,故予以剔除。本環節使用的數據與基于COX模型的用戶流失概率計算使用的數據一致,具體結果如下:
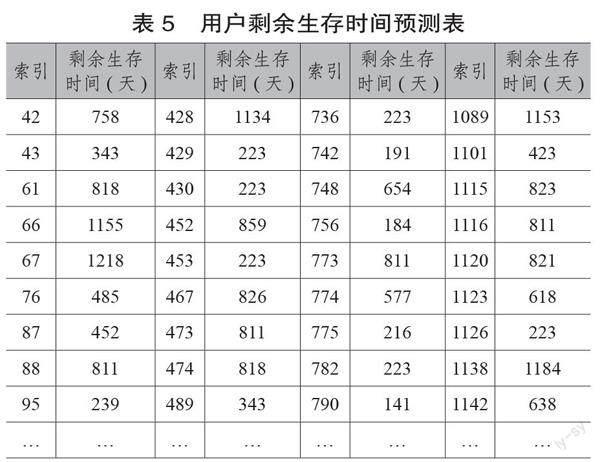
第一步,通過調用CoxPHFitter對象的predict_survival_function函數預測用戶剩余生存時間。結果顯示可預測160名用戶的剩余生存時間,其中最長時間為1308天,最短為56天,平均剩余時間約為568天。預測部分結果見表5。
第二步,計算用戶流失臨界點。表5中的索引欄為用戶在導出數據的excel文件中的行號(以0開始),可用于定位具體用戶并獲得該用戶的最后一次登錄時間(d)。以790號用戶為例,其d值為2021年4月26日,t_s值為141,則可以計算出其流失臨界點為p=t_s+d,即2021年9月14日。
當用戶流失臨界點計算值出來后,即可進行預警。用戶流失預警分析是指通過建立操作性強、可實現的流失識別指標體系,衡量流失跡象是否存在以及存在的邊界狀態[24]。主要涉及以下三個方面。
(1)監測用戶整體的生存概率變化情況。通過Kaplan-Meier對比不同時期用戶整體生存概率的變化情況。當近期用戶組生存曲線下降幅度增加,同時與前期對照組用戶生存曲線作Log-rank檢驗時且p值<0.05,則表示用戶整體生存概率總體趨于惡化,校外訪問系統的用戶粘性降低,這時就需發出用戶整體的流失預警信號;反之,除此之外,還可將瀕臨流失的用戶個體作為重點監測目標。
(2)監測反映用戶個體流失概率的相關特征值變化。通過COX定時監測行為數據中反映用戶個體流失概率變化的相關特征值的變化情況,有助于及時發現瀕臨流失的用戶個體。當用戶流失概率的良性相關因素在一定時間內持續走低時,或不良因素持續升高的情況下,可以認定該用戶正處于疲憊瓶頸期,且具有較高的流失風險,需及時發出預警信號。
(3)預測用戶流失預警日期。根據用戶流失臨界點(p)確定用戶流失預警日期(churn warning date,以w表示)。當用戶位于流失臨界點時,其留存的概率剛剛小于流失的概率。此時,可認定該用戶已處于瀕臨流失的狀態。但如前文所述,判斷用戶流失的標準是在提取用戶行為數據的截止日期前推6個月內未登錄,會出現用戶流失臨界點早于完成數據分析的時間(以ad表示),如790號用戶的p值為9月14日,而本次實證的分析完成之日為9月20日),為精準統計,這部分用戶也需要納入預警范圍。另外,因本研究只能發現用戶可能流失的相應征兆,而不能明確造成用戶流失的具體原因,為真正實現在相對精確的時期介入干預避免用戶流失,需耗費一定時間做量的用戶調研、數據分析工作,故需在p日前置某個時間段(pd)進行提前預警。該時間可以根據實際情況自定,本研究擬設置為7(天),則計算用戶流失預警日期(w)的公式如下:
當p-ad- pd ≤0時:
w= ad
如790號用戶的流失預警期為數據分析完成之日,即9月20日。
當p-ad- pd >0時:
w=p- pd
如279號用戶的最后登錄時間為2021年8月9日,剩余生存時間為272天,則p等于2022年5月8日,流失預警之日為2022年5月1日。
6 結語
本研究采用Kaplan-Meier、COX對用戶整體流失風險變化趨勢、用戶訪問行為與用戶流失概率之間的變化情況,揭示了電子資源用戶流失變化規律, 可及時發現用戶對校外訪問系統電子資源黏性降低時的行為表征,并在此基礎上顯現瀕臨流失用戶,不僅在生存函數的基礎上進一步拓展了關于預測用戶流失的研究,填補了該研究領域的空白,具有較好的可行性及普及推廣價值,還能從用戶整體和個體兩個層面有效發現電子資源用戶瀕臨流失的預兆,為及時改進與完善圖書館電子資源服務工作提供參考依據。然而,本研究還存在諸多不足:其一,實證研究的對象較為單一,方法可能存在缺陷,在今后的研究中應根據具體情況適當的擴大研究范圍。其二,在本研究的基礎上,尚需過濾出瀕臨流失用戶,進一步挖掘出導致其可能流失的真正原因。其三,在判斷用戶瀕臨流失的標準方面,尚未經過實踐反復復檢驗,后期需采集用戶主觀數據并結合經驗來進行多角度的綜合分析及判斷。這些探索點將是筆者后續努力研究的方向。
參考文獻
孔青青.科研人員電子資源需求調查分析[J].圖書情報工作,2016,60(10):47-54.
吳漢華,王波.文獻2020年中國高校圖書館基本統計數據報告[J]. 大學圖書館學報,2021,39(4):5-7.
零客戶流失:服務業的質量革命[EB/OL].[2021-10-04].https://wenku.baidu.com/view/38f0e71275232f60ddccda38376baf1ffc4fe38d.html.
《數學辭海》編輯委員會.數據辭海:第四卷[M].太原:山西教育出版社,2002.8.
KEAVENEY S M,PARTHASARATHY M.Journal of the Academy of Marketing Science [J].2001,29(4):374-390.
陳靜,余建波,李艷冰.基于隨機森林的用戶流失預警研究[J].精密制造與自動化,2021(2):21-24,51.
賀芳.基于用戶細分的微博社區用戶流失預測研究[J].情報探索,2018(12):21-27.
王若佳,嚴承希,郭鳳英,等.基于用戶畫像的在線健康社區用戶流失預測研究[J].數據分析與知識發現, 2022(Z1):1-16.
JIANG Z, FITZGERALD S R, WALKER K W. Modeling time-to-trigger in library demand-driven acquisitions via survival analysis[J]. Library & Information Science Research, 2019, 41(3): 100968.
朱世琴,蔣辛未.基于CSSCI的人文社科期刊文獻老化風險率研究[J].情報學報,2017,36(10):1031-1037.
劉智鋒,李信.作者關鍵詞生存分析:以國內圖情領域為例[J].圖書館雜志,2020,39(7):48-57.
孫佳佳,李雅靜.基于關鍵詞價值細分的高價值熱點主題識別方法研究[J].情報學報,2022,41(2):118-129.
賴院根,劉敏健,王星.網絡環境下的信息用戶流失分析[J].情報科學,2011,29(11):1736-1741.
賴院根,劉礪利.基于生存分析的信息用戶流失研究與實證[J].情報雜志,2011,30(4):129-132,171.
程學旗,梅宏,趙偉,等.數據科學與計算智能:內涵、范式與機遇[J].中國科學院院刊,2020,35(12):1470-1481.
陳志偉.大數據方法論的新特征及其哲學反思[J].湖南師范大學社會科學學報,2020,49(1):24-31.
數據相關性[EB/OL].[2022-04-04].https://baike.so.com/doc/26482622-27741494.html.
Cox回歸生存分析[EB/OL].[2021-09-01].https://www.jianshu.com/p/e80eb4168043.
劉桂琴,許新華.基于機器學習的圖書館用戶流失影響因素研討[J].新世紀圖書館,2020(1):9-13.
Prediction on censored subjects[EB/OL].[2021-09-01].https://lifelines.readthedocs.io/en/latest/Survival%20Regression.html#prediction-on-censored-subjects.
刁羽,薛紅.高校圖書館用戶校外訪問系統電子資源滿意度畫像研究:基于小數據的視角[J].圖書館工作與研究,2021(9):76-83.
刁羽,賀意林.用戶訪問電子資源行為數據的獲取研究:基于創文圖書館電子資源綜合管理與利用系統[J].圖書館學研究,2020(3):40-47.
How the concordance index is calculated in Cox model if the actual event times are not predicted? [EB/OL].[2021-09-01].https://stats.stackexchange.com/questions/478294/how-the-concordance-index-is-calculated-in-cox-model-if-the-actual-event-times-a/478305#478305.
董堅峰. 經濟不發達地區公共圖書館用戶穩定機制研究[J]. 現代情報,2012,32(5):25-29.
